Todos os anos, em Moscou, é realizada a conferência
Dialogue , na qual participam linguistas e especialistas em análise de dados. Eles discutem o que é linguagem natural, como ensinar uma máquina a entendê-la e processá-la. A conferência tradicionalmente organizava competições (faixas) de
Diálogo Avaliação . Eles podem ser assistidos por representantes de grandes empresas que criam soluções no campo do processamento de linguagem natural (Natural Language Processing, PNL), além de pesquisadores individuais. Pode parecer que, se você é um estudante simples, compete com os sistemas que grandes especialistas de grandes empresas vêm criando há anos. Avaliação de Diálogo - esse é exatamente o caso quando, na classificação final, um aluno simples pode ser superior a uma empresa famosa.
Este ano será o 9º consecutivo quando a Avaliação do Diálogo for realizada no Diálogo. A cada ano, o número de competições é diferente. Tarefas de PNL, como Análise de sentimento, Indução de sentido da palavra, Correção automática de ortografia, Reconhecimento de entidade nomeada e outras, já se tornaram tópicos de trilhas.

Este ano, quatro grupos de organizadores prepararam essas faixas:
- Geração de manchetes para reportagens.
- Resolução de anáfora e coreferência.
- Análise morfológica do material de linguagens de baixo recurso.
- Análise automática de um dos tipos de elipse (gapping).
Hoje falaremos sobre o último deles: o que é uma elipse e por que ensinar o carro a restaurá-lo no texto, como criamos um novo prédio para resolver esse problema, como foram realizadas as competições e quais resultados os participantes conseguiram alcançar.
AGRR-2019 (resolução de gap automático para russo)
No outono de 2018, enfrentamos uma tarefa de pesquisa relacionada a uma elipse - uma omissão intencional de uma cadeia de palavras em um texto que pode ser restaurado do contexto. Como encontrar automaticamente essa lacuna no texto e preenchê-la corretamente? É fácil para um falante nativo, mas ensinar este carro não é fácil. Muito rapidamente ficou claro que este é um bom material para a concorrência, e começamos a trabalhar.
A organização de competições sobre um novo tópico tem características próprias e, para nós, elas parecem ser em grande parte vantagens. Uma das principais coisas é a criação do corpus (muitos textos com marcação nas quais você pode aprender). Como deve ser e quanto deve ser? Para muitas tarefas, existem padrões para a apresentação de dados a partir dos quais se basear. Por exemplo, para a
tarefa de identificar entidades nomeadas , os esquemas de marcação IO / BIO / IOBES foram desenvolvidos, pois as tarefas de análise sintática e morfológica do formato CONLL são tradicionalmente usadas, nada precisa ser inventado, mas as diretrizes devem ser rigorosamente seguidas.
No nosso caso, cabia a nós montar o corpo e formular a tarefa.
Aqui está essa tarefa ...
Aqui, inevitavelmente, teremos que fazer uma introdução linguística popular sobre o que é a elipse em geral e como um de seus tipos.
Quaisquer que sejam suas idéias sobre o idioma, é difícil argumentar que o nível superficial da expressão (texto ou fala) não é o único. A frase dita é a ponta do iceberg. O próprio iceberg inclui uma avaliação pragmática, a construção de uma estrutura sintática, a seleção de material lexical e assim por diante. A elipse é um fenômeno que conecta lindamente o nível da superfície com a profundidade. Essa é a omissão de elementos duplicados da sintaxe. Se apresentarmos a estrutura sintática de uma sentença na forma de uma árvore e as mesmas subárvores puderem ser selecionadas nessa árvore, muitas vezes (mas nem sempre), para que a sentença seja natural, os elementos duplicados serão excluídos. Essa remoção é chamada de reticências (exemplo 1).
(1)
Eles não me ligaram de volta, e eu não entendo por que eles não me ligaram de volta .As lacunas obtidas pelas reticências podem ser inequivocamente restauradas a partir do contexto da linguagem. Compare o primeiro exemplo com o segundo (2), onde há um passe, mas o que está faltando exatamente não é claro. Este caso não é uma elipse.
2)
Gapping é um dos tipos de elipses de frequência. Considere o exemplo (3) e entenda como ele funciona.
(3)
Eu a confundi com um italiano e ele com um sueco.Em todos os exemplos, existem mais de duas frases (cláusulas), elas são compostas entre si. Na primeira cláusula, há um verbo (é mais provável que os linguistas digam "predicado") e seus participantes o
aceitaram :
eu ,
ela e
italiano . Na segunda cláusula, não há verbo expresso, existem apenas "remanescentes" (ou remanescentes)
dele e
para o sueco que não estão relacionados sintaticamente, mas entendemos como o passe é restaurado.
Para restaurar o passe, passamos para a primeira cláusula e copiamos toda a estrutura (exemplo 4). Substituímos apenas as partes para as quais existem remanescentes "paralelos" em uma cláusula incompleta. Copiamos o predicado, substituímos por
ele ,
pelo italiano substituímos por remanescente
para o sueco . Para
mim, não havia remanescente paralelo, o que significa que o copiamos sem substituição.
(4)
Eu a confundi com italiano, e com um sueco.Parece que, para restaurar a lacuna, basta determinar se há uma lacuna nesta sentença, encontrar a cláusula incompleta e toda a cláusula associada a ela (da qual o material para restauração é retirado) e depois entender o que "remanescentes" (restos) estão na cláusula incompleta e o que eles correspondem na íntegra. Parece que essas condições são suficientes para efetivamente preencher a lacuna. Assim, tentamos imitar o processo na cabeça de uma pessoa que lê ou ouve um texto no qual possa haver omissões.
Então, por que isso é necessário?
É claro que para uma pessoa que ouve pela primeira vez sobre elipses e as dificuldades de processamento associadas a ela, pode surgir uma pergunta legítima: "Por quê?" Os céticos gostariam de
convidar os pais da ciência linguística a
lerem para explicar que, se a solução de um problema aplicado fornece material que pode ser útil na pesquisa teórica, essa já é uma resposta suficiente à pergunta sobre o objetivo de tal atividade.
Os teóricos estudam elipses em diferentes idiomas há cerca de 50 anos, descrevem as limitações, destacam padrões gerais em diferentes idiomas. Ao mesmo tempo, não temos conhecimento da existência de um corpus ilustrando qualquer tipo de elipse com mais de algumas centenas de exemplos. Isso se deve em parte à raridade do fenômeno (por exemplo, em nossos dados, o grapping é encontrado em não mais que 5 frases em 10 mil). Portanto, a criação desse corpo já é um resultado importante.
Nos sistemas de aplicativos que trabalham com dados de texto, a raridade do fenômeno permite que você simplesmente os ignore. A incapacidade do analisador sintático de restaurar as lacunas ausentes não traz exatamente muitos erros. Mas a partir de eventos raros, uma periferia lingüística extensa e heterogênea é formada. Parece que a experiência de resolver esse problema em si deve ser de interesse para quem deseja criar sistemas que não funcionem apenas em textos simples, curtos e limpos, com vocabulário comum, ou seja, em textos esféricos em um vácuo que praticamente não ocorre na natureza.
Poucos analisadores possuem um sistema eficaz para detectar e resolver reticências. Porém, no analisador interno ABBYY, há um módulo responsável pela restauração de passes e ele é baseado em regras escritas manualmente. Graças a essa capacidade do analisador, conseguimos criar um grande corpo para a competição. O benefício potencial para o analisador original é substituir um módulo de execução lenta. Além disso, enquanto trabalhamos no caso, realizamos uma análise detalhada dos erros do sistema atual.
Como criamos o corpo
Nosso prédio é destinado principalmente ao treinamento de sistemas automáticos, o que significa que é extremamente importante que seja volumoso e diversificado. Guiados por isso, construímos o trabalho de coleta de dados da seguinte maneira. Para o corpo, selecionamos textos de vários gêneros: de documentação técnica e patentes a notícias e publicações das mídias sociais. Todos eles foram marcados pelo analisador ABBYY. Em um mês, distribuímos dados entre linguistas-escritores. Os marcadores foram convidados, sem alterar a marcação, a avaliar em uma escala:
0 - não há mapeamento na frase, a marcação é irrelevante.
1 - existe um mapeamento e sua marcação está correta.
2 - existe uma lacuna, mas algo está errado com a marcação.
3 - um caso complicado, é um mapeamento?
Como resultado, cada um dos grupos foi útil. Os exemplos da categoria 1 se enquadram na classe positiva do nosso conjunto de dados. Basicamente, não queremos repetir manualmente os exemplos das categorias 2 e 3 para economizar tempo, mas esses exemplos nos foram úteis posteriormente para avaliar nosso caso resultante. Deles, pode-se julgar quais casos o sistema marca de maneira consistente incorreta, o que significa que eles não caem em nosso corpo. E, finalmente, incluindo nos exemplos de casos classificados pelos marcadores como categoria 0, demos aos sistemas a oportunidade de "aprender com os erros dos outros", ou seja, não apenas simular o comportamento do sistema original, mas funcionar melhor que ele.
Cada exemplo foi avaliado por dois marcadores. Depois disso, pouco mais da metade das propostas entrou no corpo a partir dos dados de origem. Toda a classe positiva de exemplos e parte do negativo consiste deles. Decidimos tornar a classe negativa duas vezes mais positiva, de modo que, por um lado, as classes sejam comparáveis em volume e, por outro, a preponderância da classe negativa que existe no idioma seja preservada.
Para cumprir essa proporção, tivemos que adicionar mais exemplos negativos ao caso, além dos exemplos descritos da categoria 0. Vamos dar um exemplo (5) da categoria 0, que pode confundir não apenas o carro, mas também a pessoa.
(5)
Mas então Jack estava apaixonado por Cindy Page, agora Sra. Jack Svaytek.Na segunda cláusula, ela não está se recuperando, porque quero dizer que agora Cindy Page se tornou a sra. Jack Svaytek porque se casou com ele.
Em geral, para um fenômeno sintático relativamente raro, como gapping, um exemplo negativo é quase qualquer sentença aleatória da linguagem, porque a probabilidade de que haja uma pequena lacuna em uma sentença aleatória. No entanto, o uso desses exemplos negativos pode levar à reciclagem de sinais de pontuação. No nosso caso, exemplos para a classe negativa foram obtidos de acordo com critérios simples: a presença de um verbo, a presença de vírgula ou hífen, o comprimento mínimo da frase não é inferior a 6 tokens.
Para a competição, selecionamos a parte do desenvolvedor do edifício de treinamento (na proporção de 1: 5), que os participantes foram convidados a usar para configurar seus sistemas. As versões finais dos sistemas foram treinadas nas partes combinadas de trem e desenvolvedor. Rotulamos manualmente o caso de teste (teste) por conta própria, em termos de volume, é a 10ª parte do train + dev. Aqui está o número exato de exemplos de classe:
Além dos dados de treinamento verificados manualmente, adicionamos um arquivo de marcação bruto recebido do sistema de origem. Existem mais de 100 mil exemplos, e os participantes podem usar esses dados como opção para complementar a amostra de treinamento. Olhando para o futuro, dizemos que apenas um participante descobriu como aumentar significativamente o edifício do treinamento usando dados sujos sem perder a qualidade.
Formato de marcação
Recusamos deliberadamente o uso de analisadores de terceiros e desenvolvemos uma marcação na qual todos os elementos de nosso interesse são marcados linearmente na linha de texto. Usamos dois tipos de marcação. O primeiro, legível por humanos, foi projetado para funcionar com marcação e é conveniente analisar os erros dos sistemas resultantes. Com esse método, todos os elementos de espaço são marcados com colchetes dentro da frase. Cada par de colchetes é marcado com o nome do elemento correspondente. Usamos a seguinte notação:

Damos exemplos de frases com lacunas entre parênteses.
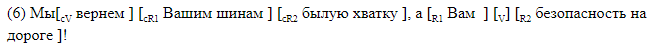
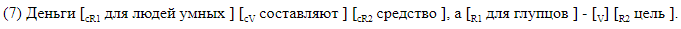

A marcação do suporte é adequada para análise de material. No caso, os dados são armazenados em um formato diferente, que, se desejado, pode ser facilmente convertido em colchetes. Uma linha corresponde a uma frase. As colunas indicam a presença de lacunas na sentença e, para cada etiqueta possível em sua coluna, são fornecidos deslocamentos simbólicos do início e do final do segmento correspondente ao elemento. É assim que a marcação de deslocamento é exibida, correspondendo à marcação de colchete em ().
Tarefas para participantes
Os participantes do AGRR-2019 podem resolver qualquer um dos três problemas:
- Classificação binária É necessário determinar se há uma lacuna na frase.
- Permissão aberta. É necessário restaurar a posição do passe (V) e a posição do controlador de verbo (cV).
- Marcação completa. Você precisa definir compensações para todos os elementos da lacuna.
Cada próxima tarefa deve, de alguma forma, resolver a anterior. É claro que qualquer marcação é possível apenas em sentenças em que a classificação binária mostra uma classe positiva (existe um mapeamento), e a marcação completa também inclui a localização dos limites dos predicados ausentes e controladores.
Métricas
Para o problema de classificação binária, usamos métricas padrão: precisão e completude, e os resultados dos participantes foram classificados por f-measure.
Para as tarefas de resolução de gapping e marcação completa, decidimos usar uma medida f simbólica, uma vez que os textos de origem não eram tokenizados e não queríamos que a diferença nos tokenizadores usados pelos participantes afetasse os resultados. Exemplos verdadeiros negativos não contribuíram para a medida f simbólica, para cada elemento de marcação foi considerada sua própria medida f, o resultado final foi obtido por macro-média em todo o corpo. Graças a esse cálculo da métrica, os casos falso-positivos foram multados significativamente, o que é importante quando há muitas vezes menos exemplos positivos em dados reais do que negativos.
Curso de competição
Paralelamente à montagem do edifício, aceitamos pedidos de participação no concurso. Como resultado, registramos mais de 40 participantes. Em seguida, montamos o prédio de treinamento e lançamos a competição. Os participantes tiveram 4 semanas para construir seus modelos.
A etapa de avaliação dos resultados foi a seguinte: os participantes receberam 20 mil ofertas sem marcação, dentro das quais estava envolvido um caso de teste. As equipes tiveram que marcar esses dados com seus sistemas, após o que avaliamos os resultados das marcações no edifício de teste. A mistura do teste em uma grande quantidade de dados nos garantiu que, com todos os nossos desejos, o caso não poderia ser marcado manualmente nos poucos dias que foram dados para a execução (marcação automática).
Resultados da Competição
Nove equipes chegaram à final, incluindo representantes de duas empresas de TI, pesquisadores da Universidade Estadual de Moscou, Instituto de Física e Tecnologia de Moscou, HSE e IPPI RAS.
Todas as equipes, exceto uma, participaram das três competições. Sob os termos do AGRR-2019, todas as equipes publicaram um código para suas decisões. Uma tabela de resumo com os resultados é fornecida em
nosso repositório , onde você também pode encontrar links para as soluções estabelecidas de equipes com breves descrições.
Quase todos mostraram bons resultados. Aqui estão as avaliações das decisões das equipes vencedoras:
Uma descrição detalhada das principais soluções estará disponível em breve nos artigos dos participantes da coleção Dialogue.
Assim, neste artigo, falamos sobre como, tomando como base um fenômeno linguístico raro, formular uma tarefa, preparar um corpo e conduzir competições. Também há benefícios desse trabalho para a comunidade da PNL, porque as competições ajudam a comparar diferentes arquiteturas e abordagens entre si em material específico, e os linguistas obtêm um caso de um fenômeno raro com a possibilidade de reabastecê-lo (usando as decisões dos vencedores). O corpo montado é várias vezes maior que os volumes do corpo atualmente existentes (além disso, para lacunas, o volume do corpus é uma ordem de magnitude maior que os volumes do corpo, não apenas para o russo, mas para todas as línguas em geral). Todos os dados e links para decisões dos participantes podem ser encontrados no nosso github.
Em 30 de maio, na sessão especial do
Diálogo dedicada à análise automática de competições abertas, os resultados do AGRR-2019 serão resumidos. Falaremos sobre a organização da competição e abordaremos o conteúdo do edifício criado, e os participantes apresentarão a arquitetura selecionada com a qual resolveram o problema.
Grupo de Pesquisa Avançada em PNL