O curso completo em russo pode ser encontrado
neste link .
O curso de inglês original está disponível
neste link .
 Novas palestras são agendadas a cada 2-3 dias.
Novas palestras são agendadas a cada 2-3 dias.Entrevista com Sebastian Trun, CEO da Udacity
"Então, ainda estamos com você e conosco, como antes, Sebastian." Nós apenas queremos discutir camadas totalmente conectadas, essas mesmas camadas densas. Antes disso, eu gostaria de fazer uma pergunta. Quais são os limites e quais são os principais obstáculos que atrapalharão o aprendizado profundo e terão maior impacto nos próximos 10 anos? Tudo muda tão rápido! O que você acha que será a próxima "grande coisa"?
Eu diria duas coisas. A primeira é a IA geral para mais de uma tarefa. Isso é ótimo! As pessoas podem resolver mais de um problema e nunca devem fazer a mesma coisa. O segundo é trazer a tecnologia ao mercado. Para mim, a peculiaridade do aprendizado de máquina é que ele fornece aos computadores a capacidade de observar e encontrar padrões nos dados, ajudando as pessoas a se tornarem melhores no campo - no nível de especialista! O aprendizado de máquina pode ser usado em leis, medicina e carros autônomos. Desenvolva esses aplicativos porque eles podem gerar uma enorme quantia de dinheiro, mas o mais importante é que você tem a oportunidade de tornar o mundo um lugar muito melhor.
“Gosto muito da maneira como você diz tudo em uma única imagem do aprendizado profundo e de sua aplicação - essa é apenas uma ferramenta que pode ajudá-lo a resolver um problema específico.
Sim, exatamente! Ferramenta incrível, certo?
- Sim, sim, concordo plenamente com você!
"Quase como um cérebro humano!"
- Você mencionou aplicações médicas em nossa primeira entrevista, na primeira parte do curso em vídeo. Em quais aplicações, na sua opinião, o uso da aprendizagem profunda causa o maior prazer e surpresa?
Muito! Muito! A medicina está na pequena lista de áreas que usam ativamente o aprendizado profundo. Perdi minha irmã há alguns meses, ela estava com câncer, o que é muito triste. Eu acho que existem muitas doenças que podem ser detectadas mais cedo - nos estágios iniciais, tornando possível curá-las ou retardar o processo de seu desenvolvimento. A idéia, de fato, é transferir algumas ferramentas para a casa (casa inteligente), para que seja possível detectar tais desvios na saúde muito antes do momento em que a própria pessoa os vê. Eu também acrescentaria - tudo é repetido, qualquer trabalho de escritório, no qual você executa o mesmo tipo de ações repetidamente, por exemplo, contabilidade. Até eu, como CEO, faço muitas ações repetitivas. Seria ótimo automatizá-los, até trabalhar com correspondência por email!
- Eu não posso discordar de você! Nesta lição, apresentaremos aos alunos um curso com uma camada de rede neural chamada camada densa. Você poderia nos dizer com mais detalhes o que pensa sobre as camadas totalmente conectadas?
- Então, vamos começar com o fato de que cada rede pode ser conectada de maneiras diferentes. Alguns deles podem ter conectividade muito estreita, o que permite obter alguns benefícios no dimensionamento e na "vitória" contra grandes redes. Às vezes, você não sabe quantas conexões precisa e conecta tudo com tudo - isso é chamado de camada totalmente conectada. Acrescento que essa abordagem tem muito mais poder e potencial do que algo mais estruturado.
- Concordo plenamente com você! Obrigado por nos ajudar a aprender um pouco mais sobre as camadas totalmente conectadas. Estou ansioso pelo momento em que finalmente começamos a implementá-los e escrever código.
- Divirta-se! Vai ser muito divertido!
1. Introdução
- Bem vindo de volta! Na última lição, você descobriu como construir sua primeira rede neural usando o TensorFlow e Keras, como as redes neurais funcionam e como o processo de treinamento (treinamento) funciona. Em particular, vimos como treinar o modelo para converter graus Celsius em graus Fahrenheit.

- Também nos familiarizamos com o conceito de camadas totalmente conectadas (camadas densas), a camada mais importante nas redes neurais. Mas nesta lição, faremos coisas muito mais legais! Nesta lição, desenvolveremos uma rede neural capaz de reconhecer elementos e imagens de roupas. Como mencionamos anteriormente, o aprendizado de máquina usa entradas chamadas "recursos" e saídas chamadas "rótulos", pelas quais o modelo aprende e encontra um algoritmo de transformação. Portanto, em primeiro lugar, precisaremos de muitos exemplos para treinar a rede neural para reconhecer vários elementos da roupa. Deixe-me lembrá-lo de que um exemplo de treinamento é um par de valores - um recurso de entrada e um rótulo de saída, que são alimentados na entrada de uma rede neural. Em nosso novo exemplo, a entrada será uma imagem e a etiqueta de saída deve ser a categoria de roupa à qual o item de roupa mostrado na imagem pertence. Felizmente, esse conjunto de dados já existe. Chama-se Moda MNIST. Examinaremos mais de perto esse conjunto de dados na próxima parte.
Conjunto de dados MNIST de moda
Bem-vindo ao mundo do conjunto de dados MNIST! Portanto, nosso conjunto consiste em imagens de 28x28, cada pixel representando um tom de cinza.

O conjunto de dados contém imagens de camisetas, blusas, sandálias e até botas. Aqui está uma lista completa do que o nosso conjunto de dados MNIST contém:
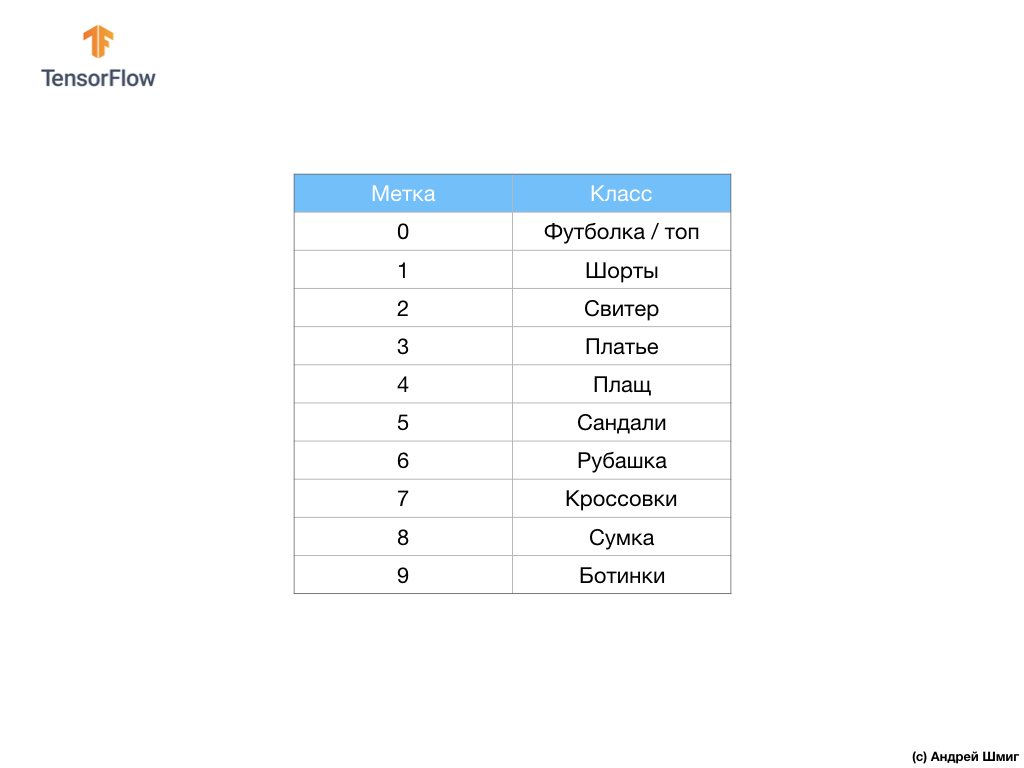
Cada imagem de entrada corresponde a um dos rótulos acima. O conjunto de dados Fashion MNIST contém 70.000 imagens, portanto, temos um local para começar e trabalhar. Desses 70.000, usaremos 60.000 para treinar a rede neural.
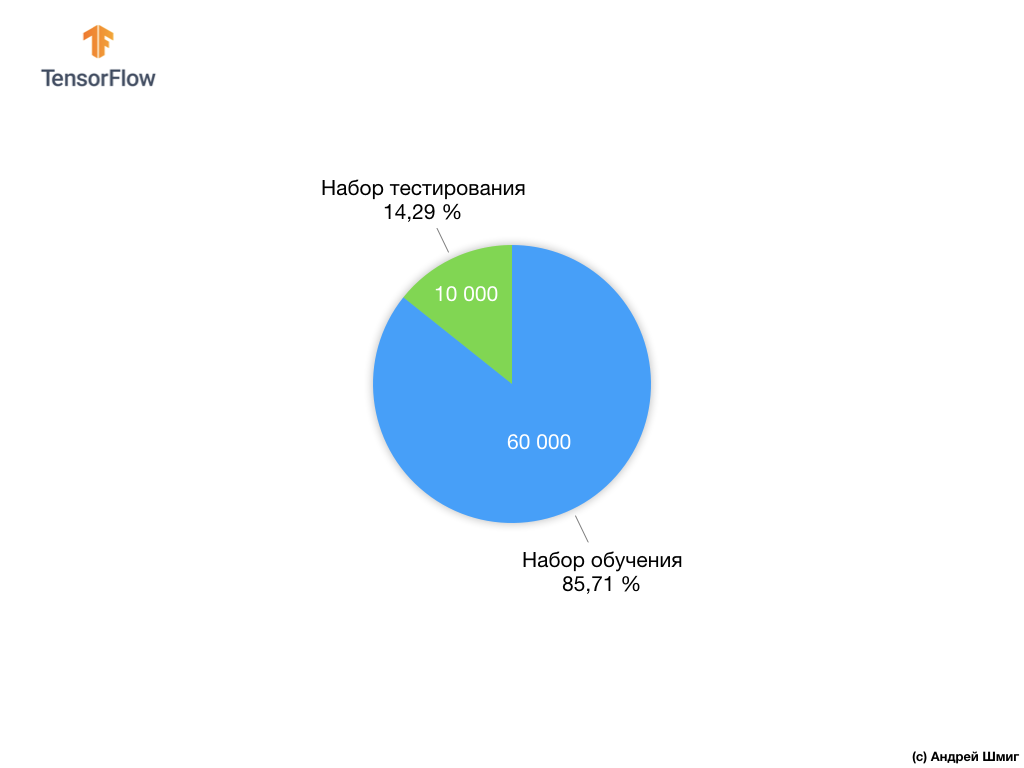
E usaremos os 10.000 elementos restantes para verificar até que ponto nossa rede neural aprendeu a reconhecer elementos da roupa. Mais tarde, explicaremos por que dividimos o conjunto de dados em um conjunto de treinamento e um conjunto de testes.
Então, aqui está o nosso conjunto de dados do Fashion MNIST.
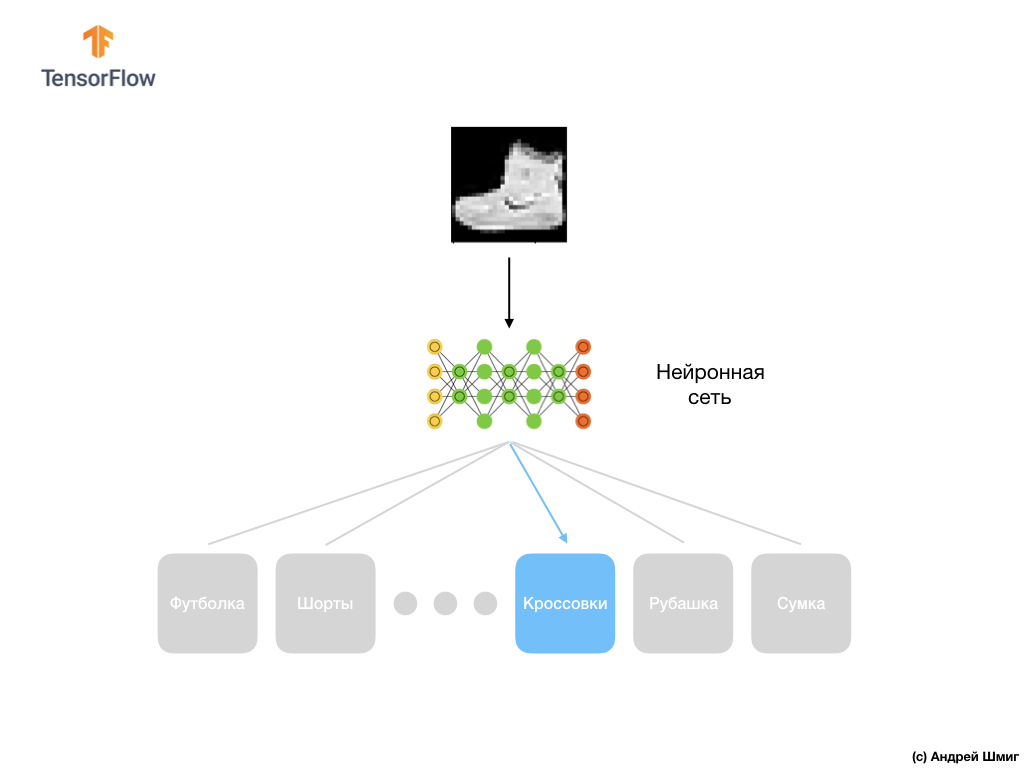
Lembre-se de que cada imagem no conjunto de dados é uma imagem de tamanho 28x28 em tons de cinza, o que significa que cada imagem tem 784 bytes de tamanho. Nossa tarefa é criar uma rede neural, que receba esses 784 bytes na entrada e na saída retorne a qual categoria de roupas dentre 10 disponíveis, o elemento aplicado na entrada pertence.
Rede neural
Nesta lição, usaremos uma rede neural profunda que aprende a classificar imagens do conjunto de dados Fashion MNIST.
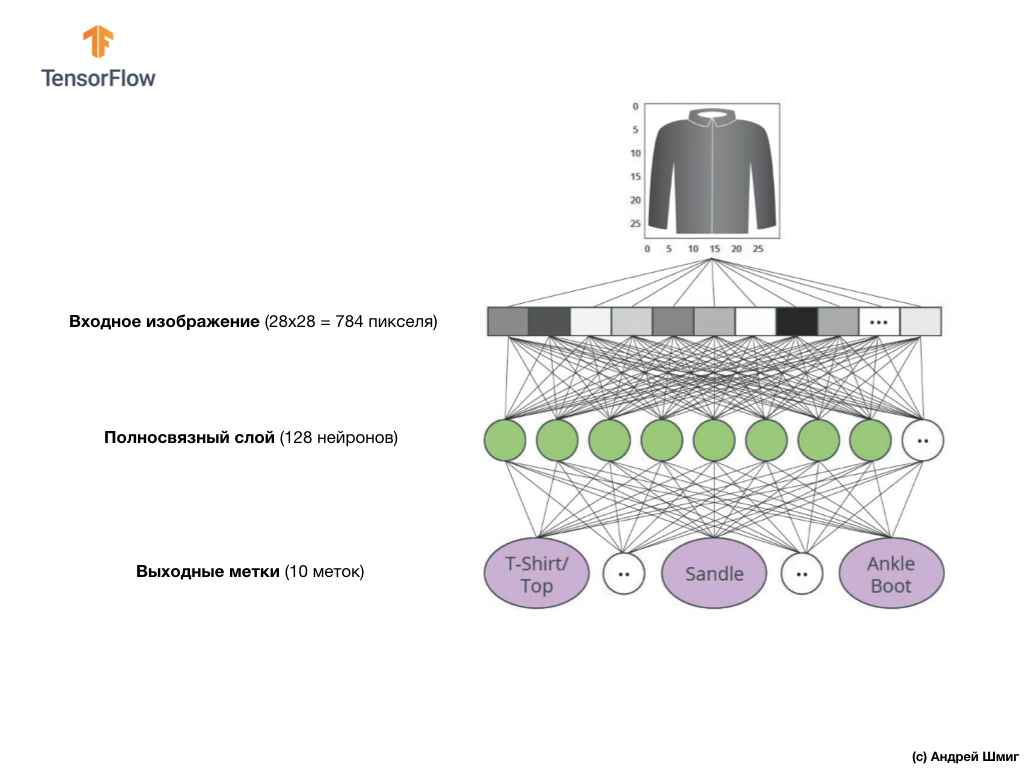
A imagem acima mostra como será nossa rede neural. Vamos dar uma olhada em mais detalhes.
O valor de entrada da nossa rede neural é uma matriz unidimensional com um comprimento de 784, uma matriz exatamente desse comprimento pelo motivo de cada imagem ter 28x28 pixels (= 784 pixels no total na imagem), que converteremos em uma matriz unidimensional. O processo de conversão de uma imagem 2D em um vetor é chamado nivelamento e é implementado através de uma camada de nivelamento - uma camada de nivelamento.
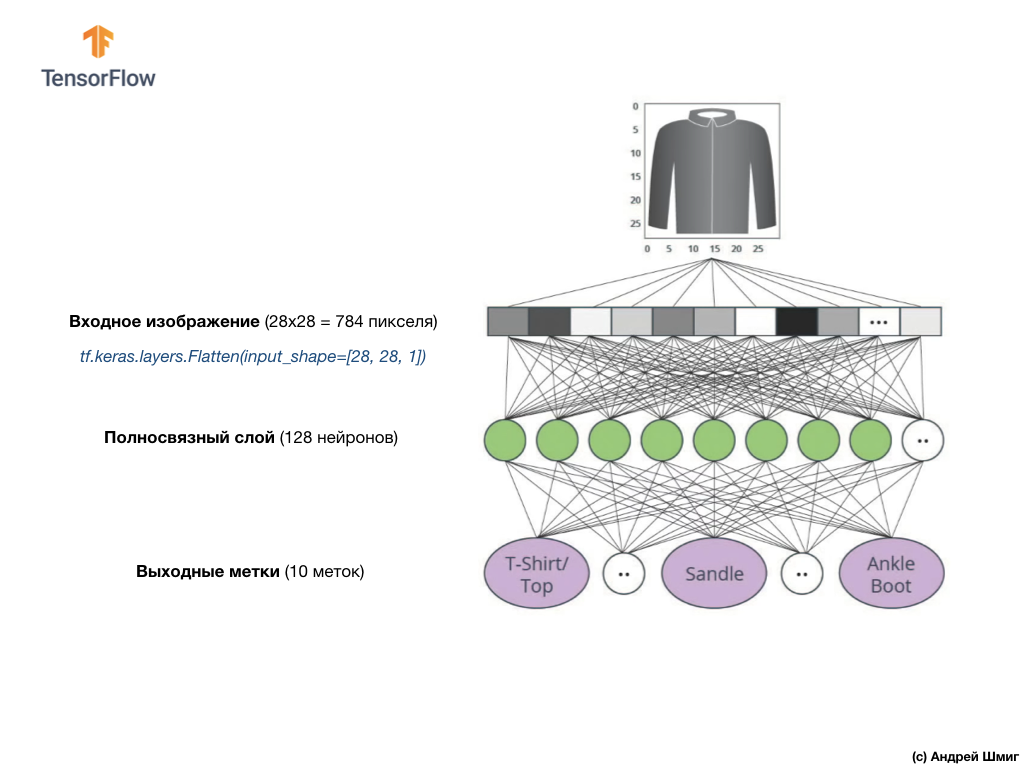
Você pode executar a suavização criando a camada apropriada:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Essa camada converte uma imagem 2D de 28x28 pixels (1 byte para tons de cinza para cada pixel) em uma matriz 1D de 784 pixels.
Os valores de entrada serão totalmente associados à nossa primeira camada de rede
dense , cujo tamanho escolhemos igual a 128 neurônios.
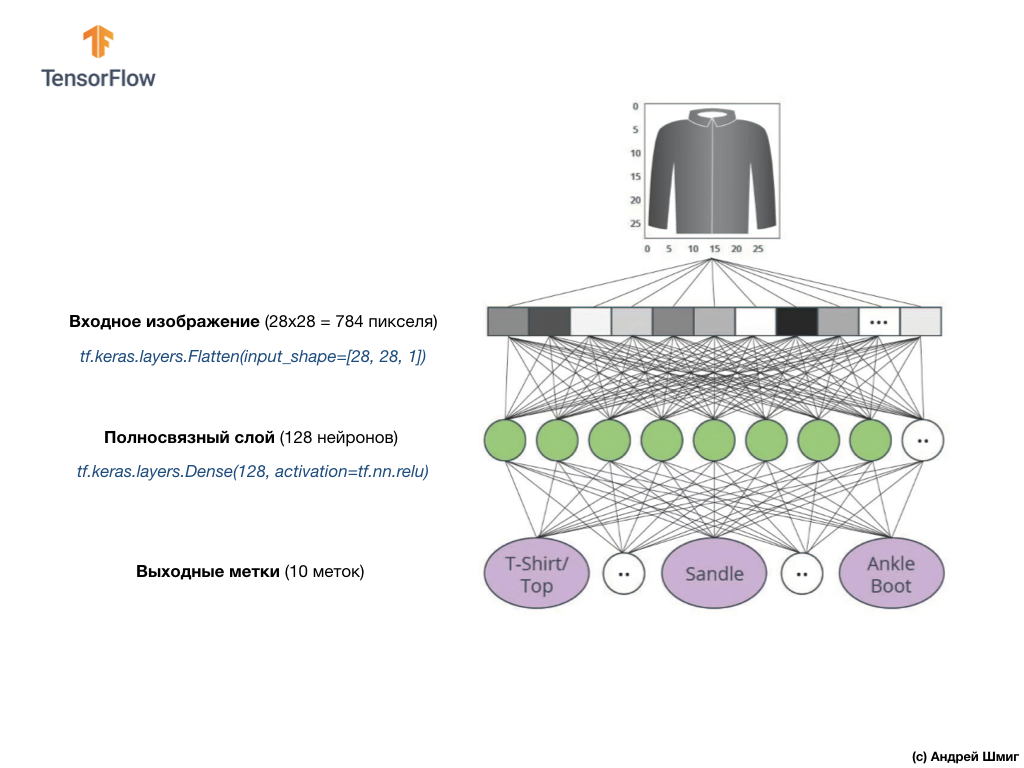
Aqui está como será a criação dessa camada no código:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Pare com isso! O que é um
tf.nn.relu ? Não usamos isso em nosso exemplo anterior de rede neural ao converter graus Celsius em graus Fahrenheit! O ponto principal é que a tarefa atual é muito mais complicada do que a que foi usada como exemplo de descoberta de fatos - a conversão de graus Celsius em graus Fahrenheit.
ReLU é uma função matemática que adicionamos à nossa camada totalmente conectada e que dá mais poder à nossa rede. De fato, essa é uma pequena extensão para nossa camada totalmente conectada, o que permite que nossa rede neural resolva problemas mais complexos. Não entraremos em detalhes, mas informações um pouco mais detalhadas podem ser encontradas abaixo.
Finalmente, nossa última camada, também conhecida como camada de saída, consiste em 10 neurônios. Consiste em 10 neurônios porque nosso conjunto de dados Fashion MNIST contém 10 categorias de roupas. Cada um desses 10 valores de saída representará a probabilidade de a imagem de entrada estar nessa categoria de roupas. Em outras palavras, esses valores refletem a “confiança” do modelo na correção da previsão e correlação da imagem arquivada com uma de 10 categorias de roupas específicas na saída. Por exemplo, qual é a probabilidade de a imagem mostrar um vestido, tênis, sapatos etc.
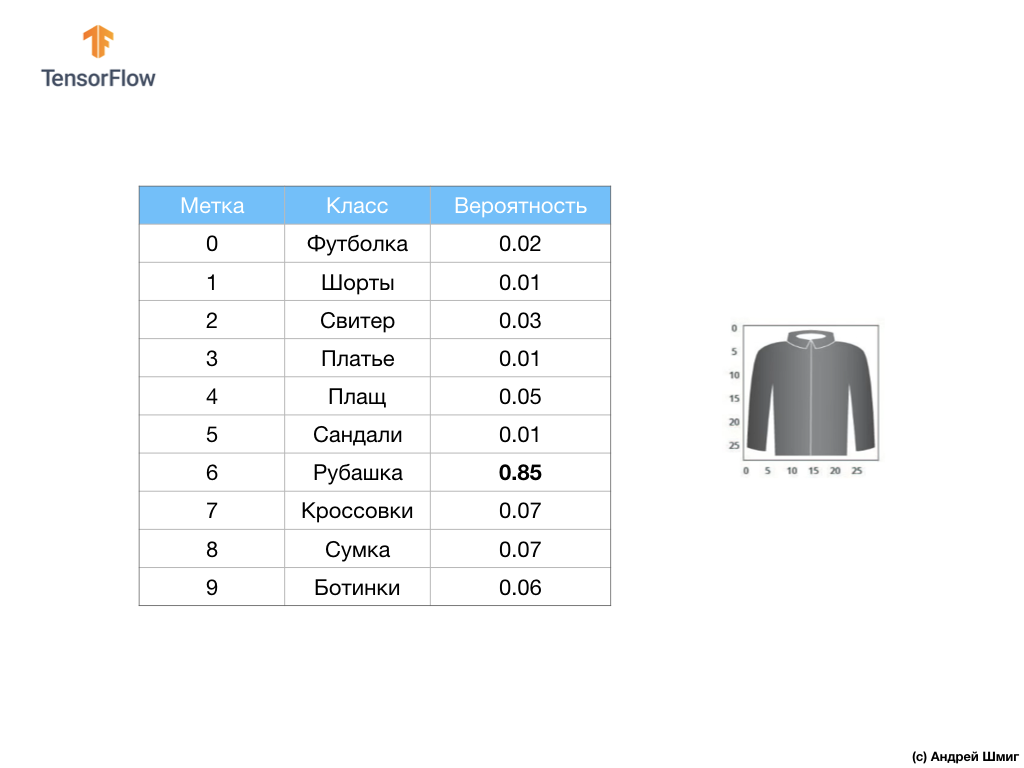
Por exemplo, se uma imagem de camisa é enviada para a entrada da nossa rede neural, o modelo pode nos fornecer resultados como os que você vê na imagem acima - a probabilidade da imagem de entrada corresponder ao rótulo de saída.
Se você prestar atenção, notará que a maior probabilidade - 0,85 refere-se à etiqueta 6, que corresponde à camisa. O modelo tem 85% de certeza de que a imagem na camiseta. Normalmente, coisas que parecem camisas também terão uma alta probabilidade e coisas menos semelhantes terão uma menor probabilidade.
Como todos os 10 valores de saída correspondem a probabilidades, ao somar todos esses valores, obtemos 1. Esses 10 valores também são chamados de distribuição de probabilidade.
Agora precisamos de uma camada de saída para calcular as próprias probabilidades para cada etiqueta.

E faremos isso com o seguinte comando:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
De fato, sempre que criamos redes neurais que resolvem problemas de classificação, sempre usamos uma camada totalmente conectada como a última camada de uma rede neural. A última camada da rede neural deve conter o número de neurônios igual ao número de classes, às quais determinamos a
softmax e usamos a função de ativação do softmax.
ReLU - função de ativação de neurônios
Nesta lição, falamos sobre a
ReLU como algo que amplia os recursos de nossa rede neural e lhe fornece energia adicional.
ReLU é uma função matemática que se parece com isso:
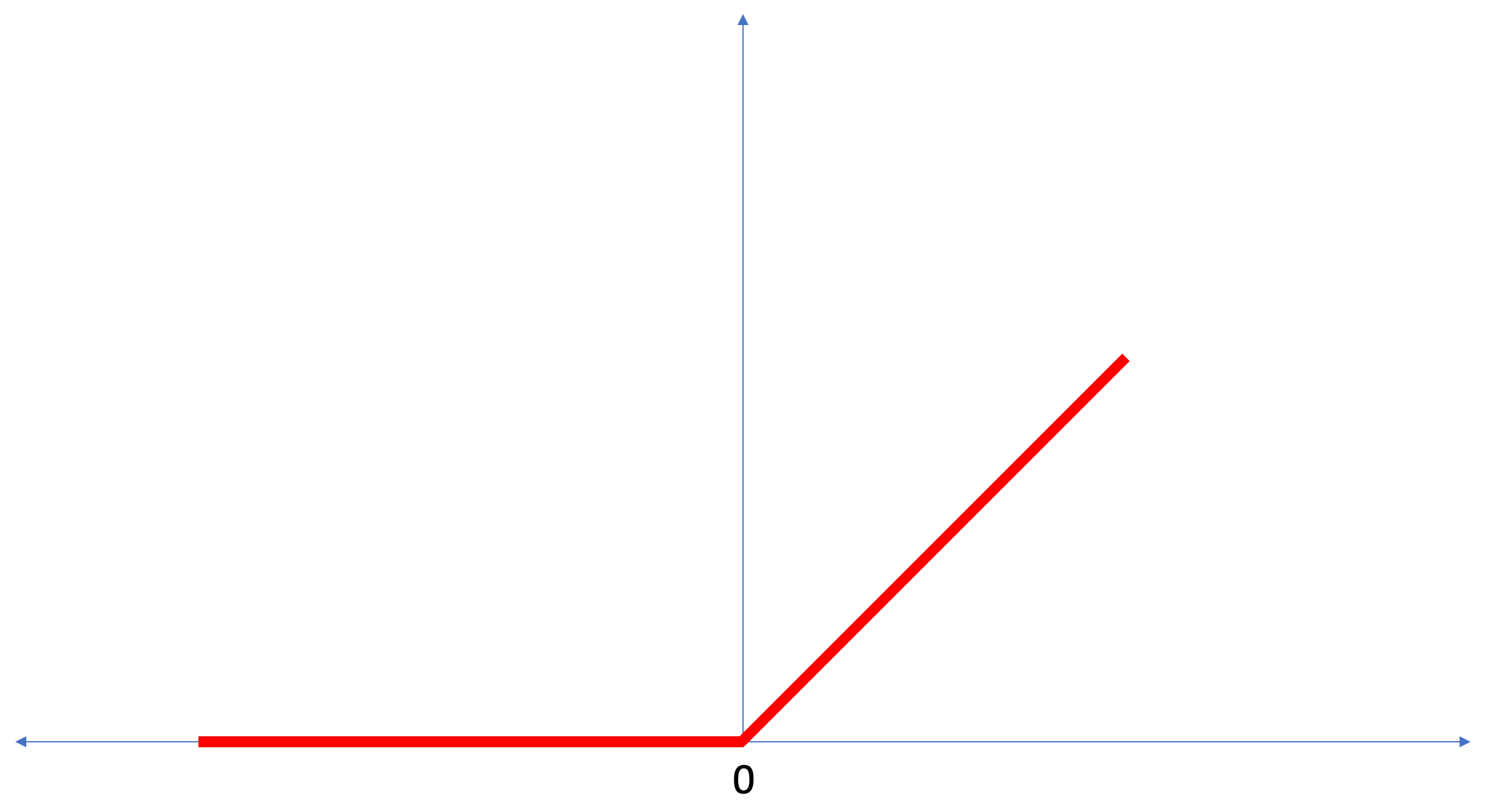
A função
ReLU retorna 0 se o valor de entrada for um valor negativo ou zero; em todos os outros casos, a função retornará o valor de entrada original.
ReLU torna possível resolver problemas não lineares.
Converter graus Celsius em graus Fahrenheit é uma tarefa linear, porque a expressão
f = 1.8*c + 32 é a equação da reta -
y = m*x + b . Mas a maioria das tarefas que queremos resolver é não linear. Nesses casos, adicionar a função de ativação ReLU à nossa camada totalmente conectada pode ajudar nesse tipo de tarefa.
ReLU é apenas um tipo de função de ativação. Existem funções de ativação, como sigmoid, ReLU, ELU, tanh, no entanto, é o
ReLU que
ReLU mais frequentemente usado como a função de ativação padrão. Para criar e usar modelos que incluem ReLU, você não precisa entender como ele funciona internamente. Se você ainda deseja entender melhor, recomendamos
este artigo .
Vamos revisar os novos termos introduzidos nesta lição:
- Suavização - o processo de conversão de uma imagem 2D em um vetor 1D;
- ReLU é uma função de ativação que permite ao modelo resolver problemas não lineares;
- Softmax - uma função que calcula as probabilidades para cada classe de saída possível;
- Classificação - uma classe de tarefas de aprendizado de máquina usadas para determinar as diferenças entre duas ou mais categorias (classes).
Treinamento e teste
Ao treinar um modelo, qualquer modelo no aprendizado de máquina, é sempre necessário dividir o conjunto de dados em pelo menos dois conjuntos diferentes - o conjunto de dados usado para treinamento e o conjunto de dados usado para teste. Nesta parte, entenderemos por que vale a pena fazer isso.
Vamos lembrar como distribuímos nosso conjunto de dados do Fashion MNIST, composto por 70.000 cópias.
Propusemos dividir 70.000 em duas partes - na primeira parte, deixamos 60.000 para treinamento e na segunda parte 10.000 para testes. A necessidade dessa abordagem é causada pelo seguinte fato: após o modelo ter sido treinado em 60.000 cópias, é necessário verificar os resultados e a eficácia de seu trabalho em exemplos que ainda não estavam no conjunto de dados em que o modelo foi treinado.
À sua maneira, assemelha-se a passar em um exame na escola. Antes de passar no exame, você está empenhado em resolver problemas de uma classe específica. Em seguida, no exame, você encontra a mesma classe de problemas, mas com dados de entrada diferentes. Não faz sentido enviar os mesmos dados que estavam durante o treinamento; caso contrário, a tarefa será reduzida a lembrar decisões e não procurar um modelo de solução. É por isso que nos exames você se depara com tarefas que não estavam anteriormente no currículo. Somente dessa maneira podemos verificar se o modelo aprendeu a solução geral ou não.
O mesmo acontece com o aprendizado de máquina. Você mostra alguns dados que representam uma determinada classe de tarefas que você deseja aprender a resolver. No nosso caso, com um conjunto de dados do Fashion MNIST, queremos que a rede neural seja capaz de determinar a categoria à qual o elemento vestuário na imagem pertence. É por isso que treinamos nosso modelo em 60.000 exemplos que contêm todas as categorias de itens de vestuário. Após o treinamento, queremos verificar a eficácia do modelo, para alimentar os 10.000 itens restantes de roupas que o modelo ainda não “viu”. Se decidíssemos não fazer isso, não testar com 10.000 exemplos, não poderíamos dizer com certeza se nosso modelo foi realmente treinado para determinar a classe do item de vestuário ou se ela se lembrava de todos os pares de valores de entrada + saída.
É por isso que no aprendizado de máquina sempre temos um conjunto de dados para treinamento e um conjunto de dados para teste.
O TensorFlow é uma coleção de dados de treinamento prontos para uso.
Os conjuntos de dados geralmente são divididos em vários blocos, cada um dos quais é usado em um determinado estágio do treinamento e teste da eficácia da rede neural. Nesta parte, falamos sobre:
- conjunto de dados de treinamento : um conjunto de dados destinado ao treinamento de uma rede neural;
- conjunto de dados de teste : um conjunto de dados projetado para verificar a eficiência de uma rede neural;
Considere outro conjunto de dados, que eu chamo de conjunto de dados de validação. Este conjunto de dados não é usado
para treinar o modelo, apenas
durante o treinamento. Assim, depois que nosso modelo passou por vários ciclos de treinamento, alimentamos nosso conjunto de dados de teste e analisamos os resultados. Por exemplo, se durante o treinamento o valor da função de perda diminuir e a precisão se deteriorar no conjunto de dados de teste, isso significa que nosso modelo simplesmente se lembra dos pares de valores de entrada e saída.
O conjunto de dados de verificação é reutilizado no final do treinamento para medir a precisão final das previsões do modelo.
Para obter mais
informações sobre conjuntos de dados de treinamento e teste, consulte o curso de falha do Google .
Parte prática no CoLab
Link para o CoLab original em inglês e um
link para o Russian CoLab .
Classificação de imagens de itens de vestuário
Nesta parte da lição, construiremos e treinaremos uma rede neural para classificar imagens de elementos de vestuário, como vestidos, tênis, camisas, camisetas, etc.
Tudo bem se alguns momentos não estiverem claros. O objetivo deste curso é apresentar o TensorFlow e ao mesmo tempo explicar os algoritmos de seu trabalho e desenvolver um entendimento comum de projetos usando o TensorFlow, em vez de investigar os detalhes da implementação.
Nesta parte, usamos o
tf.keras , uma API de alto nível para criar e treinar modelos no TensorFlow.
Instalando e Importando Dependências
Vamos precisar de
um conjunto de dados TensorFlow , uma API que simplifique o carregamento e o acesso a conjuntos de dados fornecidos por vários serviços. Também precisaremos de algumas bibliotecas auxiliares.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
Importar o conjunto de dados Fashion MNIST
Este exemplo usa o conjunto de dados Fashion MNIST, que contém 70.000 imagens de itens de vestuário em 10 categorias em escala de cinza. As imagens contêm itens de vestuário em baixa resolução (28x28 pixels), conforme mostrado abaixo:

O Fashion MNIST é usado como um substituto para o conjunto de dados clássico do MNIST - geralmente usado como "Olá, Mundo!" em aprendizado de máquina e visão computacional. O conjunto de dados MNIST contém imagens de números escritos à mão (0, 1, 2 etc.) no mesmo formato que os itens de vestuário em nosso exemplo.
Em nosso exemplo, usamos o Fashion MNIST por causa da variedade e porque esta tarefa é mais interessante do ponto de vista da implementação do que resolver um problema típico no conjunto de dados MNIST. Ambos os conjuntos de dados são pequenos o suficiente, portanto, são usados para verificar a operacionalidade correta do algoritmo. Ótimos conjuntos de dados para iniciar o aprendizado de máquina, teste e código de depuração.
Usaremos 60.000 imagens para treinar a rede e 10.000 imagens para testar a precisão do treinamento e da classificação de imagens. Você pode acessar diretamente o conjunto de dados Fashion MNIST através do TensorFlow usando a API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
Ao carregar um conjunto de dados, obtemos metadados, um conjunto de dados de treinamento e um conjunto de dados de teste.
- O modelo é treinado em um conjunto de dados de `train_dataset`
- O modelo é testado em um conjunto de dados de `test_dataset`
As imagens são matrizes bidimensionais de
2828 , onde os valores em cada célula podem estar no intervalo
[0, 255] . Etiquetas - uma matriz de números inteiros, onde cada valor está no intervalo
[0, 9] . Esses rótulos correspondem à classe de imagem de saída da seguinte maneira:
Cada imagem pertence a uma tag. Como os nomes das classes não estão contidos no conjunto de dados original, vamos salvá-los para uso futuro quando desenharmos as imagens:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
Pesquisamos dados
Vamos estudar o formato e a estrutura dos dados apresentados no conjunto de treinamento antes de treinar o modelo. O código a seguir mostrará que 60.000 imagens estão no conjunto de dados de treinamento e 10.000 imagens no conjunto de dados de teste:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
Pré-processamento de dados
O valor de cada pixel na imagem está no intervalo
[0,255] . Para que o modelo funcione corretamente, esses valores devem ser normalizados - reduzidos a valores no intervalo
[0,1] . Portanto, um pouco menor, declaramos e implementamos a função de normalização e, em seguida, aplicamos a cada imagem nos conjuntos de dados de treinamento e teste.
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
Estudamos os dados processados
Vamos desenhar uma imagem para dar uma olhada nela:
Exibimos as 25 primeiras imagens do conjunto de dados de treinamento e, em cada imagem, indicamos a qual classe pertence.
Verifique se os dados estão no formato correto e se estamos prontos para começar a criar e treinar a rede.
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

Construindo um modelo
Construir uma rede neural requer camadas de ajuste e, em seguida, montar um modelo com funções de otimização e perda.
Personalizar camadas
O elemento básico na construção de uma rede neural é a camada. A camada extrai a visualização dos dados que entraram em sua entrada. O resultado do trabalho de várias camadas conectadas, temos uma visão que faz sentido para resolver o problema.
Na maioria das vezes, aprendendo profundamente, você criará links entre camadas simples. A maioria das camadas, por exemplo, como tf.keras.layers.Dense, possui um conjunto de parâmetros que podem ser "ajustados" durante o processo de aprendizado.
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
A rede consiste em três camadas:
- entrada
tf.keras.layers.Flatten - essa camada converte imagens de 28 x 28 pixels em um array 1D com o tamanho 784 (28 * 28). Nesta camada, não temos parâmetros para treinamento, pois essa camada lida apenas com a conversão de dados de entrada. - camada oculta
tf.keras.layers.Dense - uma camada firmemente conectada de 128 neurônios. Cada neurônio (nó) pega todos os 784 valores da camada anterior como entrada, altera os valores de entrada de acordo com os pesos e deslocamentos internos durante o treinamento e retorna um único valor para a próxima camada. - camada de saída
ts.keras.layers.Dense - ts.keras.layers.Dense - softmax consiste em 10 neurônios, cada um dos quais representa uma classe específica de elemento de vestuário. Como na camada anterior, cada neurônio recebe os valores de entrada de todos os 128 neurônios da camada anterior. Os pesos e deslocamentos de cada neurônio nesta camada mudam durante o treinamento, de modo que o valor resultante esteja no intervalo [0,1] e represente a probabilidade de a imagem pertencer a essa classe. A soma de todos os valores de saída de 10 neurônios é 1.
Compilar o modelo
Antes de começarmos a treinar o modelo, vale mais algumas configurações. Essas configurações são feitas durante a montagem do modelo quando o método de compilação é chamado:
- função de perda - um algoritmo para medir a distância entre o valor desejado e o previsto.
- função de otimização - um algoritmo para “ajustar” os parâmetros internos (pesos e compensações) do modelo para minimizar a função de perda;
- métricas - usadas para monitorar o processo de treinamento e testes. O exemplo abaixo usa métricas como
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Treinamos o modelo
Primeiramente, determinamos a sequência de ações durante o treinamento em um conjunto de dados de treinamento:
- Repita o conjunto de dados de entrada um número infinito de vezes usando o método
dataset.repeat() (o parâmetro epochs , descrito abaixo, determina o número de todas as iterações de treinamento a serem executadas) - O método
dataset.shuffle(60000) todas as imagens para que o treinamento do nosso modelo não seja afetado pela ordem de entrada dos dados de entrada. - O método
dataset.batch(32) informa ao model.fit treinamento model.fit usar blocos de 32 imagens e rótulos sempre que as variáveis internas do modelo são atualizadas.
O treinamento ocorre chamando o método
model.fit :
- Envia
train_dataset para a entrada do modelo. - O modelo aprende a combinar a imagem de entrada com a etiqueta.
- O parâmetro
epochs=5 limita o número de sessões de treinamento a 5 iterações completas de treinamento em um conjunto de dados, o que nos dá treinamento em 5 * 60.000 = 300.000 exemplos.
(você pode ignorar o parâmetro
steps_per_epoch , em breve esse parâmetro será excluído do método).
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
E aqui está a conclusão:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Durante o treinamento do modelo, o valor da função de perda e a métrica de precisão são exibidos para cada iteração de treinamento. Este modelo atinge uma precisão de cerca de 0,88 (88%) nos dados de treinamento.
Verifique a precisão
Vamos verificar a precisão que o modelo produz nos dados de teste. Usaremos todos os exemplos que temos no conjunto de dados de teste para verificar a precisão.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
Conclusão:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
Como você pode ver, a precisão no conjunto de dados de teste acabou sendo menor que a precisão no conjunto de dados de treinamento. Isso é normal, pois o modelo foi treinado em dados train_dataset. Quando um modelo descobre imagens que nunca viu antes (do conjunto de dados train_dataset), é óbvio que a eficiência da classificação diminuirá.
Preveja e explore
Podemos usar o modelo treinado para obter previsões para algumas imagens.
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
Conclusão: No exemplo acima, o modelo previu rótulos para cada imagem de entrada de teste. Vejamos a primeira previsão:(32, 10)
predictions[0]
Conclusão: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
Lembre-se de que as previsões do modelo são uma matriz de 10 valores. Esses valores descrevem a “confiança” do modelo de que a imagem de entrada pertence a uma determinada classe (item de vestuário). Podemos ver o valor máximo da seguinte maneira: np.argmax(predictions[0])
Conclusão: 6
Isso significa que o modelo estava mais confiante de que esta imagem pertence à classe rotulada 6 (class_names [6]). Podemos verificar e garantir que o resultado seja verdadeiro e correto: test_labels[0]
6
Podemos exibir todas as imagens de entrada e as previsões de modelo correspondentes para 10 classes: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
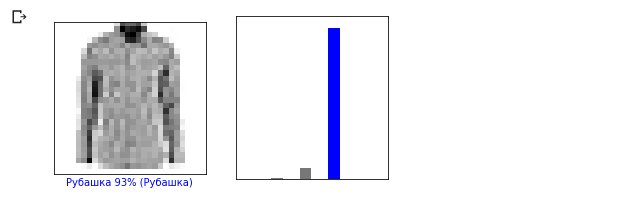
Vamos dar uma olhada na 0ª imagem, o resultado da previsão do modelo e a matriz de previsões. i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
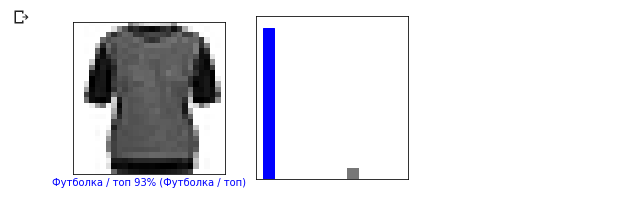 Vamos agora exibir algumas imagens com suas respectivas previsões. As previsões corretas são azuis, as previsões incorretas são vermelhas. O valor abaixo da imagem reflete a porcentagem de confiança de que a imagem de entrada corresponde a esta classe. Observe que o resultado pode estar incorreto mesmo se o valor de "confiança" for alto.
Vamos agora exibir algumas imagens com suas respectivas previsões. As previsões corretas são azuis, as previsões incorretas são vermelhas. O valor abaixo da imagem reflete a porcentagem de confiança de que a imagem de entrada corresponde a esta classe. Observe que o resultado pode estar incorreto mesmo se o valor de "confiança" for alto. num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 Use o modelo treinado para prever o rótulo para uma única imagem:
Use o modelo treinado para prever o rótulo para uma única imagem: img = test_images[0] print(img.shape)
Conclusão: (28, 28, 1)
Os modelos são tf.kerasotimizados para previsões por blocos (coleções). Portanto, apesar de usarmos um único elemento, você precisa adicioná-lo à lista: img = np.array([img]) print(img.shape)
Conclusão:(1, 28, 28, 1)Agora vamos prever o resultado: predictions_single = model.predict(img) print(predictions_single)
Conclusão: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
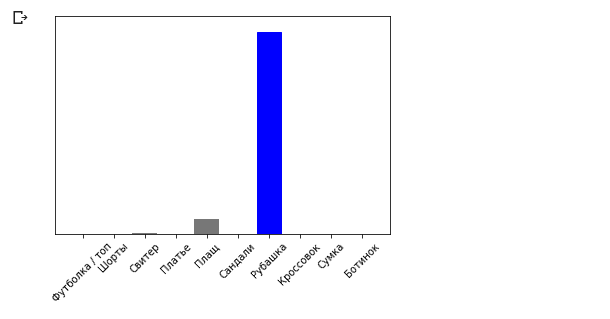 O método model.predict retorna uma lista de listas (uma matriz de matrizes), cada uma para uma imagem de um bloco de entrada. Obtemos o único resultado para nossa imagem de entrada única:
O método model.predict retorna uma lista de listas (uma matriz de matrizes), cada uma para uma imagem de um bloco de entrada. Obtemos o único resultado para nossa imagem de entrada única: np.argmax(predictions_single[0])
Conclusão: 6
Como anteriormente, o modelo previu a etiqueta 6 (camisa).Exercícios
Experimente modelos diferentes e veja como a precisão mudará. Em particular, tente alterar as seguintes configurações:- defina o parâmetro epochs como 1;
- altere o número de neurônios na camada oculta, por exemplo, de um valor baixo de 10 a 512 e veja como a precisão do modelo de previsão mudará;
- adicione camadas adicionais entre a camada achatada (camada de suavização) e a camada densa final; experimente o número de neurônios nessa camada;
- não normalize os valores de pixel e veja o que acontece.
Lembre-se de ativar a GPU para que todos os cálculos sejam mais rápidos ( Runtime -> Change runtime type -> Hardware accelertor -> GPU). Além disso, se você encontrar problemas durante a operação, tente redefinir as configurações do ambiente global:Edit -> Clear all outputsRuntime -> Reset all runtimes
Graus Celsius VS MNIST
- Nesta fase, já encontramos dois tipos de redes neurais. Nossa primeira rede neural aprendeu a converter graus Celsius em graus Frenheit, retornando um valor único que pode estar em uma ampla gama de valores numéricos.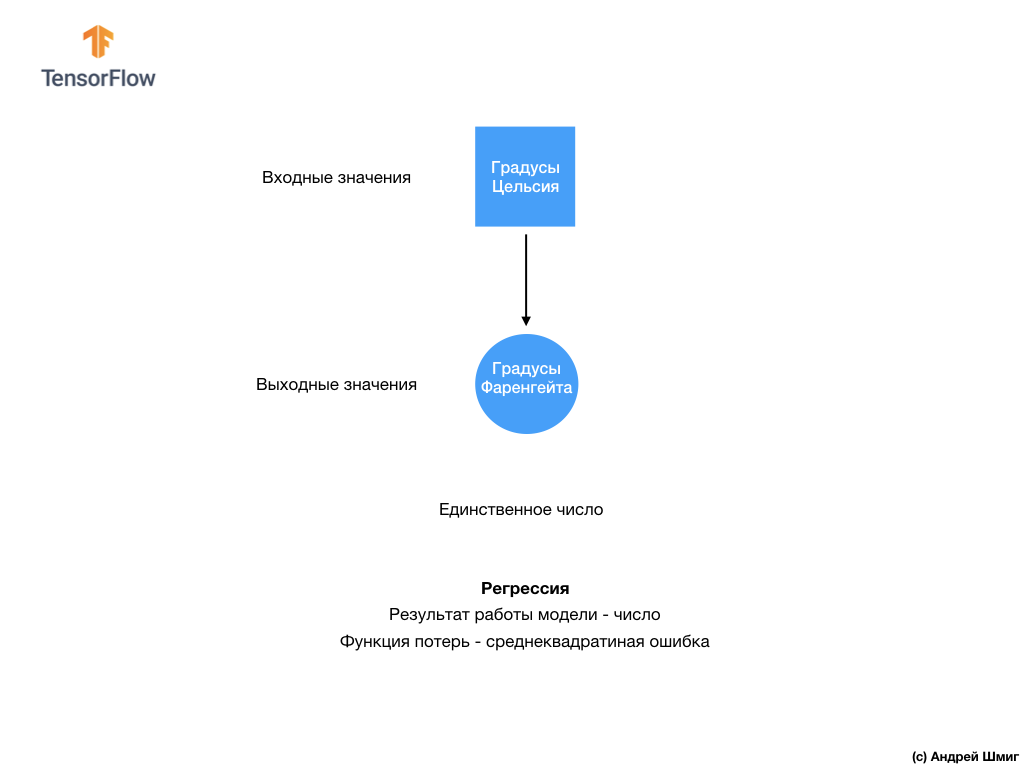 Nossa segunda rede neural retorna 10 valores de probabilidade que refletem a confiança da rede de que a imagem de entrada corresponde a uma determinada classe.Redes neurais podem ser usadas para resolver vários problemas.
Nossa segunda rede neural retorna 10 valores de probabilidade que refletem a confiança da rede de que a imagem de entrada corresponde a uma determinada classe.Redes neurais podem ser usadas para resolver vários problemas.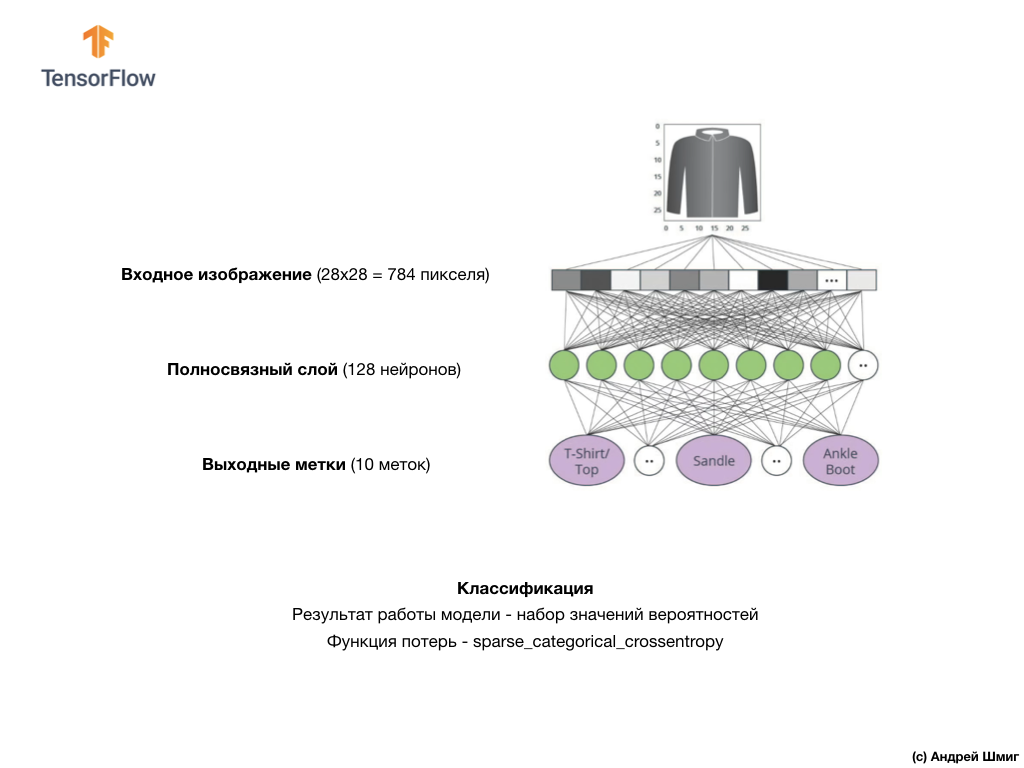 A primeira classe de problemas que resolvemos com a previsão de um único valor é chamada de regressão. Converter graus Celsius em graus Fahrenheit é um exemplo da tarefa desta classe. Outro exemplo dessa classe de tarefas pode ser a tarefa de determinar o valor de uma casa pelo número de cômodos, área total, localização e outras características.A segunda classe de tarefas que examinamos nesta lição, classificando imagens em categorias disponíveis, é chamada de classificação . De acordo com os dados de entrada, o modelo retornará a distribuição de probabilidade (a “confiança” do modelo de que o valor de entrada pertence a essa classe). Nesta lição, desenvolvemos uma rede neural que classificou os elementos de vestuário em 10 categorias e, na próxima lição, aprenderemos a determinar quem é mostrado na fotografia - um cachorro ou um gato, essa tarefa também pertence à tarefa de classificação.Vamos resumir e observar a diferença entre essas duas classes de problemas - regressão e classificação .
A primeira classe de problemas que resolvemos com a previsão de um único valor é chamada de regressão. Converter graus Celsius em graus Fahrenheit é um exemplo da tarefa desta classe. Outro exemplo dessa classe de tarefas pode ser a tarefa de determinar o valor de uma casa pelo número de cômodos, área total, localização e outras características.A segunda classe de tarefas que examinamos nesta lição, classificando imagens em categorias disponíveis, é chamada de classificação . De acordo com os dados de entrada, o modelo retornará a distribuição de probabilidade (a “confiança” do modelo de que o valor de entrada pertence a essa classe). Nesta lição, desenvolvemos uma rede neural que classificou os elementos de vestuário em 10 categorias e, na próxima lição, aprenderemos a determinar quem é mostrado na fotografia - um cachorro ou um gato, essa tarefa também pertence à tarefa de classificação.Vamos resumir e observar a diferença entre essas duas classes de problemas - regressão e classificação .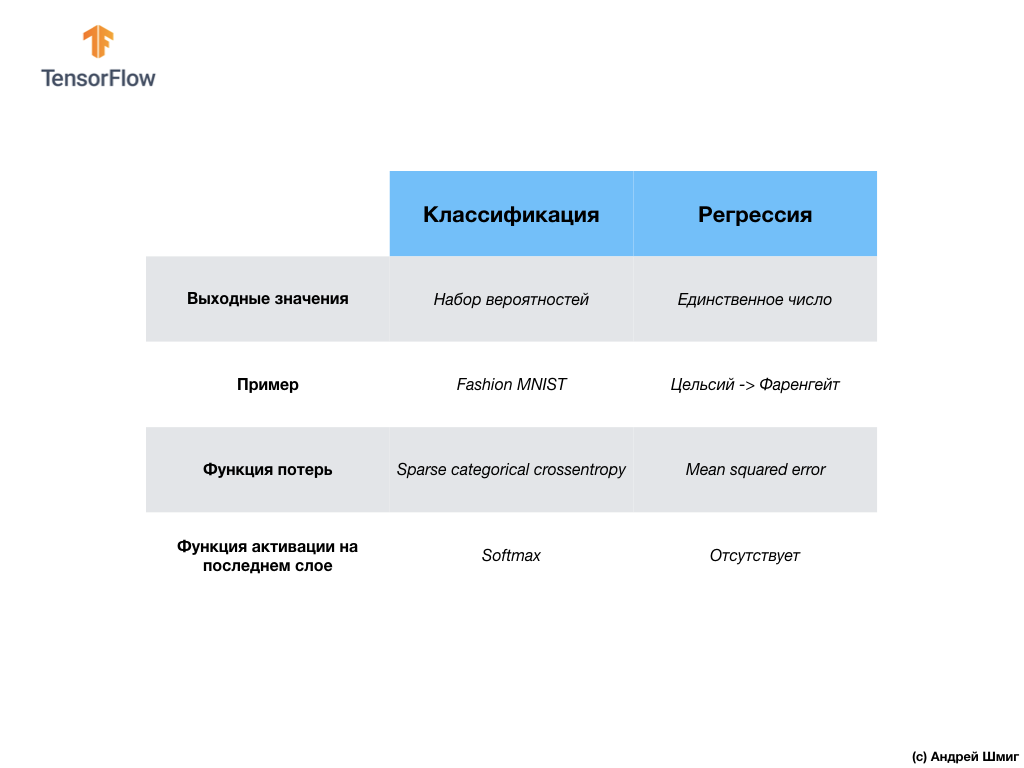 Parabéns, você estudou dois tipos de redes neurais! Prepare-se para a próxima palestra, onde estudaremos um novo tipo de redes neurais - redes neurais convolucionais (CNN).
Parabéns, você estudou dois tipos de redes neurais! Prepare-se para a próxima palestra, onde estudaremos um novo tipo de redes neurais - redes neurais convolucionais (CNN).Sumário
Nesta lição, treinamos a rede neural para classificar imagens com elementos de vestuário. Para fazer isso, usamos o conjunto de dados Fashion MNIST, que contém 70.000 imagens de itens de vestuário. 60.000 dos quais costumávamos treinar a rede neural e os 10.000 restantes para testar a eficácia de seu trabalho. Para enviar essas imagens para a entrada de nossa rede neural, precisávamos convertê-las (suavizadas) de um formato 2D de 28x28 para um formato 1D de 784 elementos. Nossa rede consistia em uma camada totalmente conectada de 128 neurônios e uma camada de saída de 10 neurônios, correspondendo ao número de etiquetas (classes, categorias de itens de vestuário). Esses 10 valores de saída representaram a distribuição de probabilidade para cada classe. Função de ativação Softmaxcontou a distribuição de probabilidade.Também aprendemos sobre as diferenças entre regressão e classificação .- Regressão : um modelo que retorna um único valor, como o valor de uma casa.
- Classificação : um modelo que retorna a distribuição de probabilidade entre várias categorias. Por exemplo, em nossa tarefa com o Fashion MNIST, os valores de saída eram 10 valores de probabilidade, cada um dos quais associado a uma classe específica (categoria de item de vestuário). Lembro que usamos a função de ativação softmax apenas para obter uma distribuição de probabilidade na última camada.
Versão em vídeo do artigoO vídeo sai alguns dias após a publicação e é adicionado ao artigo.
... e call to action padrão - inscreva-se, coloque um plus e compartilhe :)
YouTubeTelegramVKontakte