
Algum tempo atrás, uma história desagradável aconteceu comigo, que serviu de gatilho para um pequeno projeto no github e resultou neste artigo.
Um dia típico, uma liberação normal: todas as tarefas são verificadas para cima e para baixo pelo nosso engenheiro de controle de qualidade, portanto, com a calma da vaca sagrada, “rolamos” para o palco. O aplicativo se comporta bem, nos logs - silêncio. Decidimos fazer a troca (estágio <-> prod). Mudamos, olhamos para os dispositivos ...
Demora alguns minutos, o voo é estável. O engenheiro de controle de qualidade faz um teste de fumaça, percebe que o aplicativo está desacelerando de alguma forma não natural. Escrevemos para aquecer os caches.
Alguns minutos se passam, a primeira reclamação é da primeira linha: os dados são baixados dos clientes por muito tempo, o aplicativo fica mais lento, leva muito tempo para responder, etc. Começamos a nos preocupar ... olhamos para os logs, procuramos por possíveis razões.
Alguns minutos depois, chega uma carta dos administradores do banco de dados. Eles escrevem que o tempo de execução das consultas no banco de dados (doravante denominado banco de dados) quebrou todos os limites possíveis e tende ao infinito.
Abro o monitoramento (uso
JavaMelody ), encontro esses pedidos. Inicio o PGAdmin, reproduzo. Muito longo. Acrescento "explique", olho para o plano de execução ... é, esquecemos os índices.
Por que a revisão de código não é suficiente?
Esse incidente me ensinou muito. Sim, eu "extinguiu o fogo" por uma hora, criando o índice certo diretamente no produto de alguma forma (não se esqueça da opção CONCURRENTLY):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
Concordo que isso equivale a uma implantação com tempo de inatividade. Para o aplicativo em que estou trabalhando, isso é inaceitável.
Eu tirei conclusões e adicionei um ponto em negrito especial à lista de verificação para revisão de código: se eu constatar que durante o processo de desenvolvimento uma das classes Repository foi adicionada / alterada - eu verifico as migrações sql para a presença de um script que cria e altera o índice lá. Se ele não estiver lá, estou escrevendo uma pergunta ao autor: ele tem certeza de que o índice não é necessário aqui?
É provável que um índice não seja necessário se houver poucos dados, mas se trabalharmos com uma tabela na qual o número de linhas é contado em milhões, um erro de índice pode se tornar fatal e levar à história descrita no início do artigo.
Nesse caso, peço ao autor da solicitação pull (a seguir PR) que tenha 100% de certeza de que a consulta que ele escreveu no HQL é pelo menos parcialmente coberta pelo índice (a Verificação de Índice é usada). Para isso, o desenvolvedor:
- lança o aplicativo
- procurando consulta convertida (HQL -> SQL) nos logs
- abre o PGAdmin ou outra ferramenta de administração de banco de dados
- gera no banco de dados local, para não incomodar ninguém com seus experimentos, uma quantidade de dados aceitável para testes (registros mínimos de 10K a 20K)
- atende à solicitação
- solicita plano de execução
- estuda cuidadosamente e tira conclusões apropriadas
- adiciona / modifica o índice, garantindo que o plano de execução seja adequado
- cancela a inscrição no PR que a cobertura da solicitação verificou
- Ao avaliar habilmente os riscos e a gravidade da solicitação, posso verificar novamente suas ações
Muitas ações rotineiras e o fator humano, mas por algum tempo fiquei satisfeito e vivi com isso.
A caminho de casa
Eles dizem que é muito útil, pelo menos às vezes, sair do trabalho sem ouvir música / podcasts ao longo do caminho. Neste momento, apenas pensando na vida, você pode chegar a conclusões e idéias interessantes.
Um dia, voltei para casa e pensei no que aconteceu naquele dia. Houve algumas análises, verifiquei cada uma delas com uma lista de verificação e realizei uma série de ações descritas acima. Fiquei tão cansado dessa vez, pensei, que diabos? É impossível fazer isso automaticamente? Dei um passo rápido, querendo rapidamente "cortar" essa idéia.
Declaração do problema
O que é mais importante para o desenvolvedor no plano de execução?
Obviamente, a verificação seq em grandes quantidades de dados é causada pela falta de um índice.
Assim, foi necessário fazer um teste que:
- Executado em um banco de dados com uma configuração semelhante ao prod
- Intercepta uma consulta ao banco de dados feita por um repositório JPA (Hibernate)
- Obtém o plano de execução
- Analisar o Plano de Execução, colocando-o em uma estrutura de dados conveniente para verificações
- Usando um conjunto conveniente de métodos Assert, verifica as expectativas. Por exemplo, essa verificação seq não é usada.
Foi necessário testar rapidamente essa hipótese criando um protótipo.
Arquitetura da solução
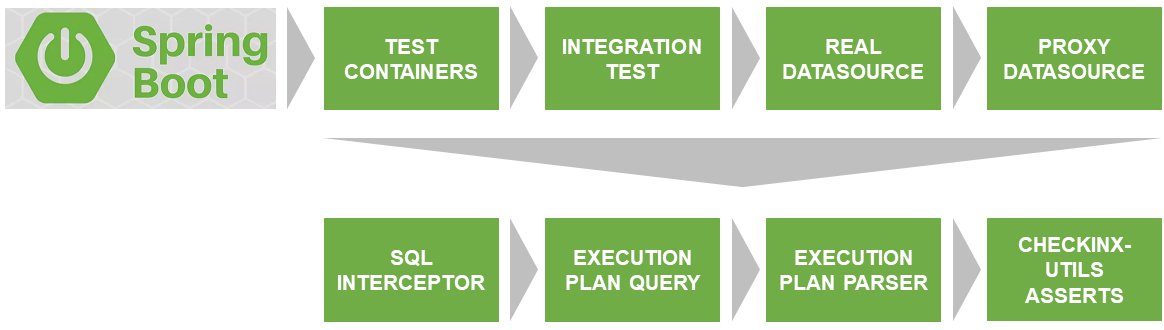
O primeiro problema a ser resolvido foi o lançamento do teste em um banco de dados real que corresponda à versão e às configurações usadas no produto.
Graças ao
Docker & TestContainers , eles resolvem esse problema.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse e AssertService são as interfaces que eu implementei atualmente para o Postgres. Os planos são implementados para outros bancos de dados. Se você quiser participar - seja bem-vindo. O código está escrito em Kotlin.
Tudo isso juntos,
publiquei no GitHub e chamei
checkinx-utils . Você não precisa repetir isso, basta conectar a dependência ao checkinx no maven / gradle e usar declarações convenientes. Como fazer isso, descreverei mais detalhadamente abaixo.
Descrição da interação dos componentes CheckInx
ProxyDataSource
O primeiro problema a ser resolvido foi a interceptação de consultas ao banco de dados prontas para execução. Já com os parâmetros estabelecidos, sem perguntas, etc.
Para fazer isso, você precisa agrupar o dataSource real em um determinado Proxy, o que permitiria integrar o pipeline de execução da consulta e, consequentemente, interceptá-los.
Esse ProxyDataSource já foi implementado por muitos. Usei a solução
ttddyy pronta, que permite instalar meu ouvinte interceptando a solicitação de que preciso.
Substituo o DataSource de origem usando a classe DataSourceWrapper (BeanPostProcessor).
SqlInterceptor
De fato, seu método start () define seu Listener em proxyDataSource e começa a interceptar solicitações, armazenando-as na lista de instruções internas. O método stop (), respectivamente, remove o Ouvinte instalado.
ExecutionPlanQuery
Aqui, a solicitação original é transformada em uma solicitação de um plano de execução. No caso do Postgres, isso é uma adição à palavra-chave de consulta "EXPLAIN".
Além disso, essa consulta é executada no mesmo banco de dados a partir de testcontainders e um plano de execução "bruto" (lista de linhas) é retornado.
ExecutionPlanParser
É inconveniente trabalhar com um plano de execução bruto. Portanto, analiso-o em uma árvore composta por nós (PlanNode).
Vamos analisar os campos do PlanNode usando um exemplo de um ExecutionPlan real:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
Já é possível trabalhar normalmente com a estrutura de dados retornada pelo analisador. CheckInxAssertService é um conjunto de verificações da árvore PlanNode descrita acima. Ele permite que você defina suas próprias lambdas de cheques ou use as predefinidas, na minha opinião, as mais populares. Por exemplo, para que sua consulta não tenha o Seq Scan, ou você deseja garantir que um índice específico seja usado / não usado.
Coveragelevel
Muito importante Enum, vou descrevê-lo separadamente:
A seguir, veremos alguns exemplos de uso.
Exemplos de teste usando o CheckInx
Eu fiz um projeto separado no GitHub
checkinx-demo , onde implementei um repositório JPA para a tabela pets e testes para esse repositório, verificando a cobertura, índices, etc. Será útil olhar lá como ponto de partida.
Você pode ter um teste como este:
@Test fun testFindByLocation() {
O plano de implementação pode ser o seguinte:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
... ou assim, se nos esquecemos do índice (os testes ficam vermelhos):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
No meu projeto, uso principalmente a declaração mais simples, que diz que não há verificação de Seq no plano de execução:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
A presença desse teste sugere que eu, pelo menos, estudei o plano de implementação.
Também torna o gerenciamento de projetos mais explícito, e a documentabilidade e previsibilidade do código aumentam.
Modo experienteEu recomendo usar o CheckInxAssertService, mas se necessário, você pode ignorar a árvore analisada (ExecutionPlanParser) ou, em geral, analisar o plano de execução bruto (o resultado da execução de ExecutionPlanQuery).
@Test fun testFindByLocation() {
Conexão ao projeto
No meu projeto, aloquei esses testes para um grupo separado, chamando-o de Testes Intensivos de Integração.
Conectar e começar a usar o checkinx-utils é fácil. Vamos começar com o script de construção.
Conecte o repositório primeiro. Algum dia eu enviarei o checkinx para o maven, mas agora você pode fazer o download do artefato apenas no GitHub via jitpack.
repositories { // ... maven { url 'https://jitpack.io' } }
Em seguida, adicione a dependência:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
Concluímos a conexão adicionando a configuração. Atualmente, o Postgres é suportado atualmente.
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
Preste atenção ao perfil do teste. Caso contrário, você encontrará o ProxyDataSource no seu produto.
O PostgresConfig conecta vários beans:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
Se você precisar de algum tipo de personalização que a API atual não fornece, sempre poderá substituir um dos beans por sua implementação.
Problemas conhecidos
Às vezes, um DataSourceWrapper falha ao substituir o dataSource original devido ao proxy Spring CGLIB. Nesse caso, não um DataSource trata do BeanPostProcessor, mas ScopedProxyFactoryBean e há problemas com a verificação de tipo.
A solução mais fácil seria criar manualmente o HikariDataSource para testes. Então sua configuração será a seguinte:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
Planos de desenvolvimento
- Eu gostaria de entender se alguém além de mim precisa disso? Para fazer isso, crie uma pesquisa. Ficarei feliz em responder honestamente.
- Veja o que você realmente precisa e expanda a lista padrão de métodos de afirmação.
- Escreva implementações para outros bancos de dados.
- A construção do sqlInterceptor.statements [0] não parece muito óbvia, quero melhorá-lo.
Eu ficaria feliz se alguém quiser participar e ganhar algum crédito praticando em Kotlin.
Conclusão
Estou certo de que haverá comentários:
é impossível prever como o planejador de consultas se comportará no produto, tudo depende das estatísticas coletadas .
Na verdade, um planejador. Usando as estatísticas coletadas anteriormente, ele pode criar um plano diferente do que está sendo testado. O significado é um pouco diferente.
A tarefa do planejador é melhorar, e não piorar, a solicitação. Portanto, sem motivo aparente, ele não usará de repente o Seq Scan, mas você pode, sem saber.
Você precisa do CheckInx para que, ao escrever um teste, não se esqueça de estudar o plano de execução da consulta e considere a possibilidade de criar um índice, ou vice-versa, mostre claramente com um teste que nenhum índice é necessário aqui e que você está satisfeito com o Seq Scan. Isso pouparia perguntas desnecessárias na revisão de código.
Referências
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki