Olá pessoal. Meu nome é Danila, trabalho em uma equipe que desenvolve infraestrutura analítica no Avito. O ponto central dessa infraestrutura é o teste A / B.
Os experimentos A / B são uma ferramenta essencial para a tomada de decisão no Avito. Em nosso ciclo de desenvolvimento de produtos, um teste A / B é obrigatório. Testamos todas as hipóteses e lançamos apenas mudanças positivas.
Coletamos centenas de métricas e podemos detalhar as seções de negócios: verticais, regiões, usuários autorizados, etc. Fazemos isso automaticamente usando uma única plataforma para experimentos. No artigo, mostrarei em detalhes suficientes como a plataforma está organizada e abordaremos alguns detalhes técnicos interessantes.

As principais funções da plataforma A / B são formuladas da seguinte maneira.
- Ajuda você a executar experiências rapidamente
- Controla interseções indesejadas da experiência
- Conta métricas, stat. testa, visualiza resultados
Em outras palavras, a plataforma ajuda a tomar decisões sem erros mais rapidamente.
Se deixarmos de lado o processo de desenvolvimento de recursos enviados para teste, o ciclo completo do experimento será semelhante a este:

- O cliente (analista ou gerente de produto) configura os parâmetros da experiência através do painel de administração.
- O serviço de divisão, de acordo com esses parâmetros, distribui o grupo A / B necessário para o dispositivo cliente.
- As ações do usuário são coletadas em logs brutos que passam por agregação e se transformam em métricas.
- As métricas são executadas através de testes estatísticos.
- Os resultados são visualizados no portal interno no dia seguinte ao lançamento.
Todo o transporte de dados em um ciclo leva um dia. Como regra, os experimentos duram uma semana, mas o cliente recebe um incremento de resultados todos os dias.
Agora vamos mergulhar nos detalhes.
Gerenciamento de experiências
O painel do administrador usa o formato YAML para configurar experimentos.

Esta é uma solução conveniente para uma equipe pequena: a finalização dos recursos da configuração ocorre sem uma frente. O uso de configurações de texto simplifica o trabalho do usuário: você precisa fazer menos cliques com o mouse. Uma solução semelhante é usada pela estrutura Airbnb A / B.
Para dividir o tráfego em grupos, usamos a técnica comum de hash de sal.
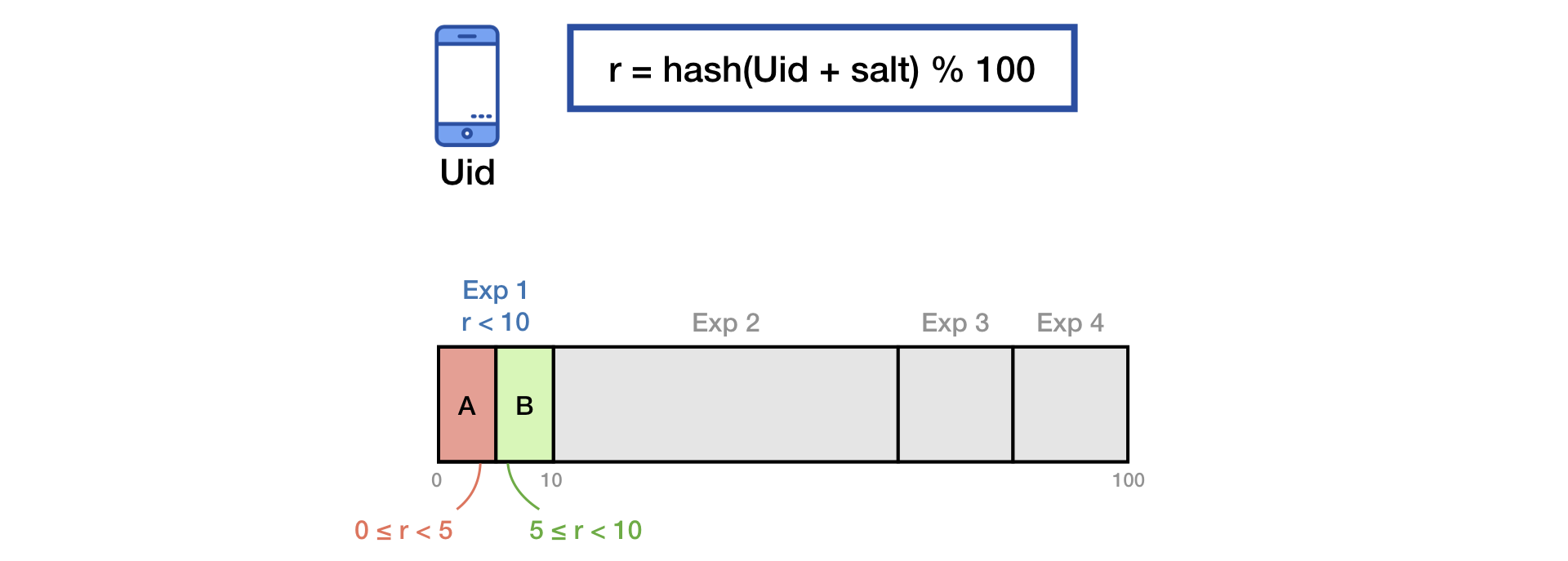
Para eliminar o efeito de "memória" dos usuários, ao iniciar um novo experimento, fazemos uma mistura adicional com o segundo sal:

O mesmo princípio é descrito na apresentação do Yandex .
Para evitar interseções potencialmente perigosas de experimentos, usamos uma lógica semelhante a "camadas" no Google .
Coleção de métricas
Colocamos logs brutos no Vertica e os agregamos em tabelas de preparação com a estrutura:

As observações são geralmente simples contadores de eventos. As observações são usadas como componentes na fórmula de cálculo da métrica.
A fórmula para calcular qualquer métrica é uma fração, cujo numerador e denominador é a soma das observações:
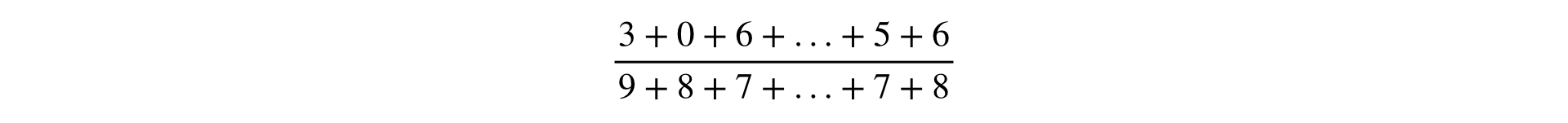
Em um dos relatórios da Yandex, as métricas foram divididas em dois tipos: por usuários e Proporção. Isso faz sentido para os negócios, mas na infraestrutura é mais conveniente considerar todas as métricas da mesma maneira que a Ratio. Essa generalização é válida, porque a métrica "posyuzerny" é obviamente representável como uma fração:
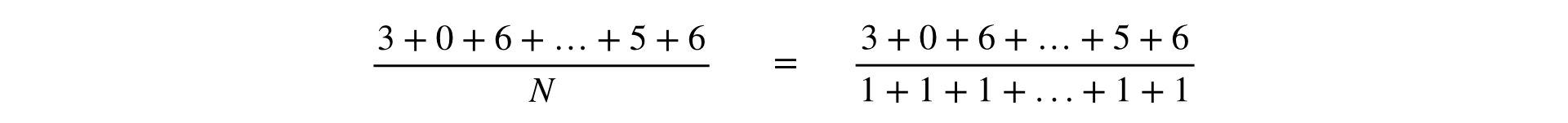
Resumimos as observações no numerador e denominador da métrica de duas maneiras.
Simples:
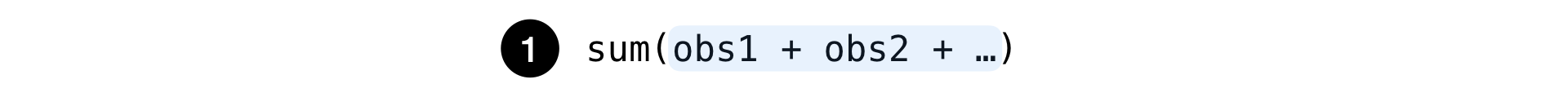
Essa é a quantidade usual de qualquer conjunto de observações: o número de pesquisas, cliques em anúncios etc.
E mais complicado:

Um número exclusivo de chaves, no agrupamento pelo qual o total de observações é maior que um determinado limite.
Essas fórmulas são facilmente definidas usando a configuração YAML:

Os parâmetros groupby e threshold são opcionais. Apenas eles determinam o segundo método de soma.
Os padrões descritos permitem configurar quase todas as métricas online que você puder imaginar. Ao mesmo tempo, é preservada uma lógica simples que não impõe uma carga excessiva na infraestrutura.
Critério Estatístico
Medimos a significância dos desvios por métricas usando os métodos clássicos: teste T, teste U de Mann-Whitney . A principal condição necessária para a aplicação desses critérios é que as observações na amostra não dependam uma da outra. Em quase todas as nossas experiências, acreditamos que os usuários (Uid) atendem a essa condição.

Agora, surge a pergunta: como realizar o teste T e o teste MW para métricas de relação? Para o teste T, você precisa ler a variação da amostra e, para MW, a amostra deve ser "definida pelo usuário".
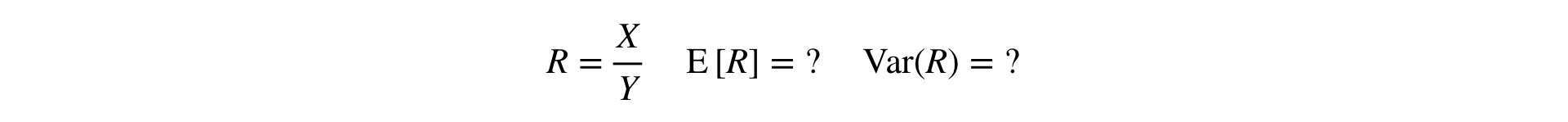
Resposta: você precisa expandir a Relação em uma série de Taylor para a primeira ordem em um ponto :
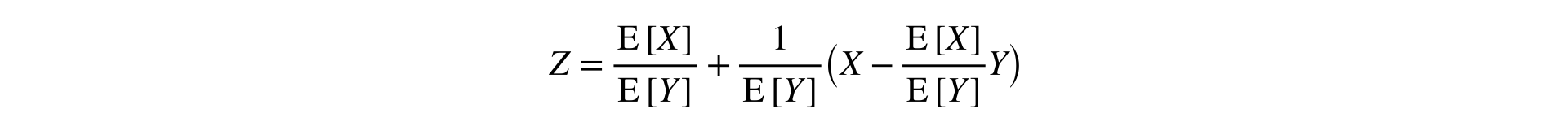
Essa fórmula converte duas amostras (numerador e denominador) em uma, preservando a média e a variância (assintoticamente), o que permite o uso de estatísticas clássicas. testes.
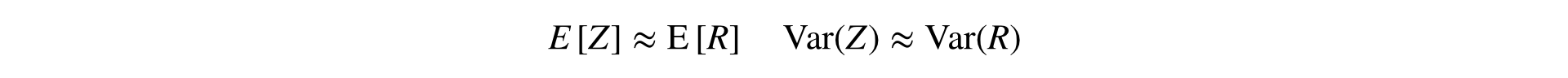
Uma idéia semelhante é chamada pelos colegas de Yandex de método de linearização da relação (aparições únicas e duas vezes ).
Escalando o desempenho
Usando rápido para o status da CPU. O critério permite realizar milhões de iterações (comparações de tratamento versus controle) em minutos em um servidor completamente comum com 56 núcleos. Porém, no caso de grandes volumes de dados, o desempenho repousa, antes de tudo, no armazenamento e no tempo de leitura do disco.
O cálculo diário das métricas Uid gera amostras com um tamanho total de centenas de bilhões de valores (devido ao grande número de experimentos simultâneos, centenas de métricas e acumulação acumulada). É problemático extrair esses volumes do disco todos os dias (apesar do grande cluster da base da coluna Vertica). Portanto, somos forçados a reduzir a cardinalidade dos dados. Mas fazemos isso quase sem perda de informações sobre a variação usando uma técnica chamada "Bucket".
A idéia é simples: nós temos os Uids e, de acordo com o restante da divisão, “os dispersamos” em vários baldes (denotamos seu número por B):
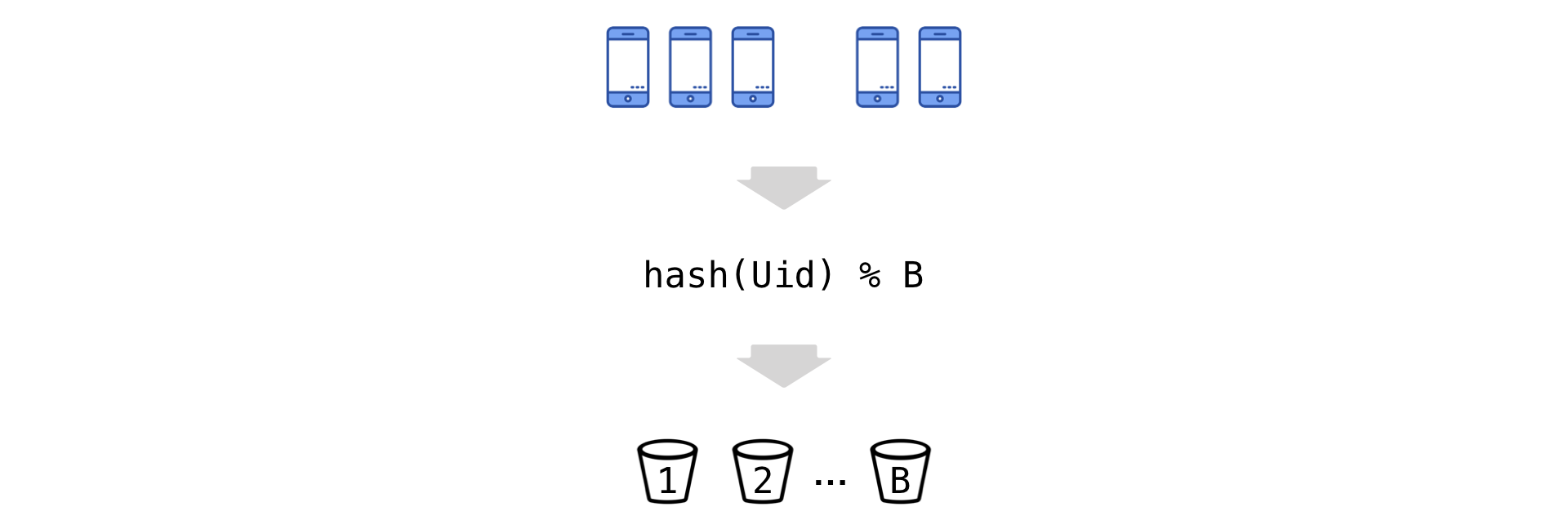
Agora passamos para a nova unidade experimental - o balde. Resumimos as observações no intervalo (o numerador e o denominador são independentes):

Com essa transformação, a condição de independência das observações é cumprida, o valor da métrica não muda e é fácil verificar se a variação da métrica (média sobre a amostra de observações) é preservada:

Quanto mais balde, menos informações são perdidas e menor o erro de igualdade. No Avito, tomamos B = 200.
A densidade da distribuição métrica após a conversão do bucket sempre se torna semelhante ao normal.
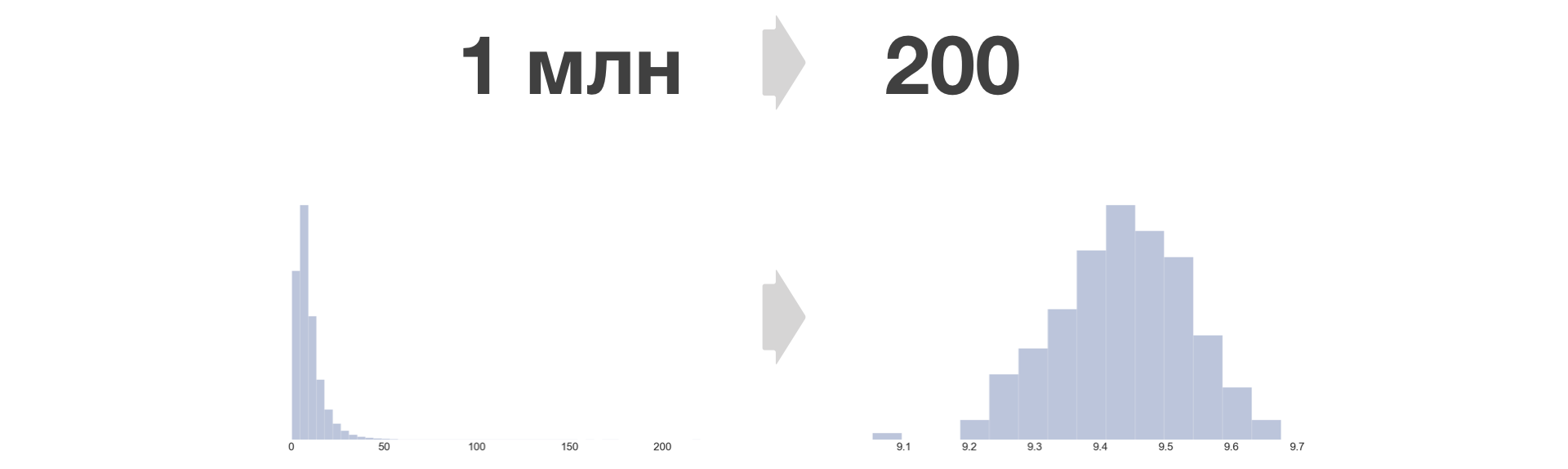
O número de amostras grandes que você quiser pode ser reduzido para um tamanho fixo. O crescimento da quantidade de dados armazenados neste caso depende apenas linearmente do número de experimentos e métricas.
Visualização de Resultados
Como ferramenta de visualização, usamos o Tableau e a visualização na web no Tableau Server. Todo funcionário da Avito tem acesso lá. Observe que o Tableau faz bem o trabalho. Implementar uma solução semelhante usando um desenvolvimento completo de trás / frente seria uma tarefa muito mais intensiva em recursos.
Os resultados de cada experimento são uma folha de vários milhares de números. A visualização deve permitir minimizar conclusões incorretas no caso da implementação de erros de primeiro e segundo tipos e, ao mesmo tempo, não "perder" as alterações em métricas e seções importantes.
Primeiro, monitoramos as métricas de "saúde" dos experimentos. Ou seja, respondemos às perguntas: "É verdade que os participantes foram" despejados "em cada um dos grupos?", "É igual aos usuários novos ou autorizados?"
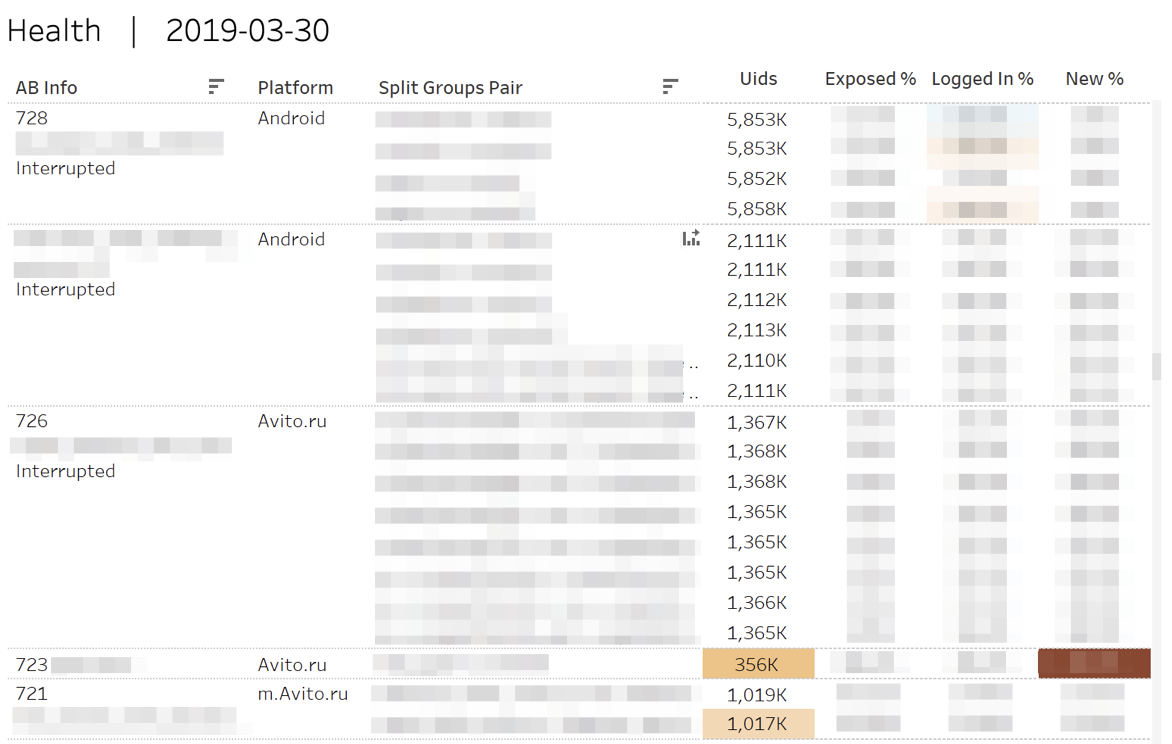
No caso de desvios estatisticamente significativos, as células correspondentes são destacadas. Quando você passa o mouse sobre qualquer número, a dinâmica cumulativa do dia é exibida.
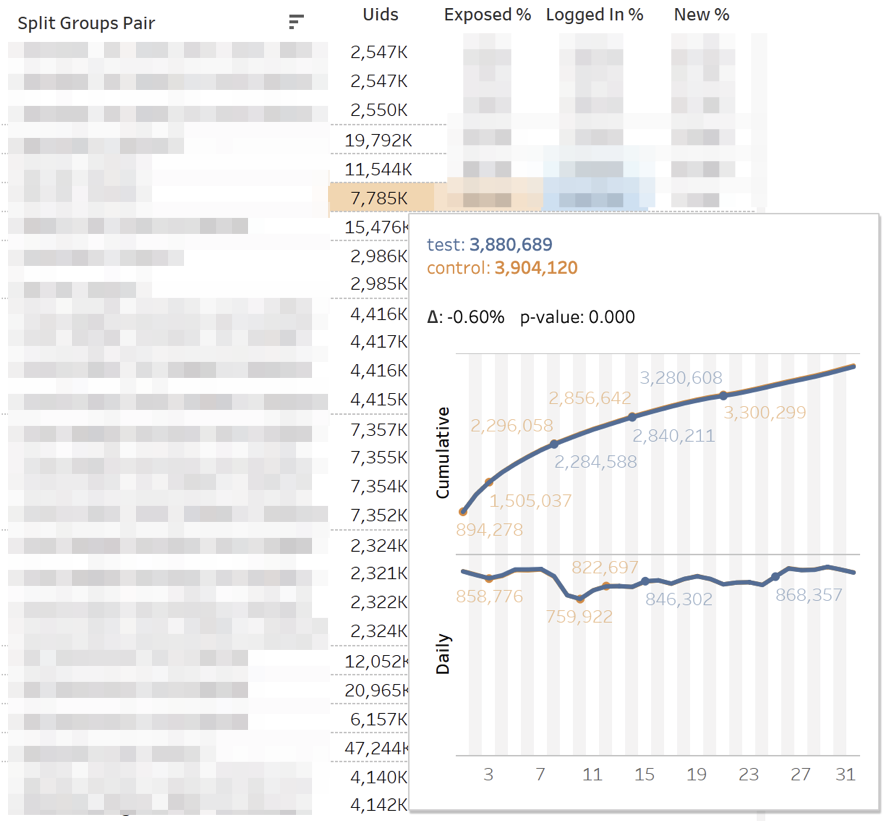
O painel principal com métricas fica assim:
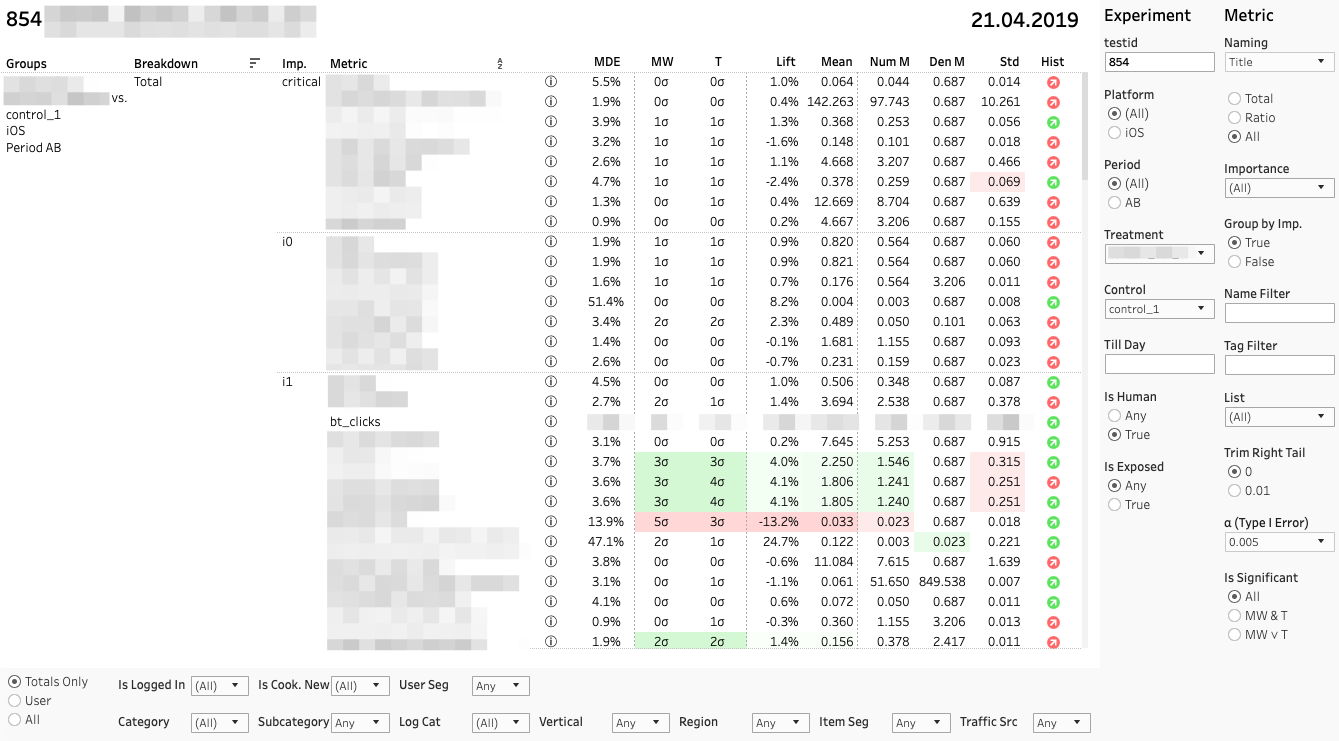
Cada linha é uma comparação de grupos por uma métrica específica em uma seção específica. À direita, há um painel com filtros para experimentos e métricas. Painel de filtro da seção inferior.
Cada comparação de métricas consiste em várias métricas. Vamos analisar seus valores da esquerda para a direita:
1. MDE. Efeito Detectável Mínimo

⍺ e β são probabilidades de erro pré-selecionadas do primeiro e do segundo tipo. O MDE é muito importante se a alteração não for estatisticamente significativa. Ao tomar uma decisão, o cliente deve se lembrar da falta de estatísticas. significância não é equivalente a nenhum efeito. De maneira confiável, podemos apenas dizer que o possível efeito não passa de MDE.
2. MW | Resultados dos testes U e T T. Mann-Whitney
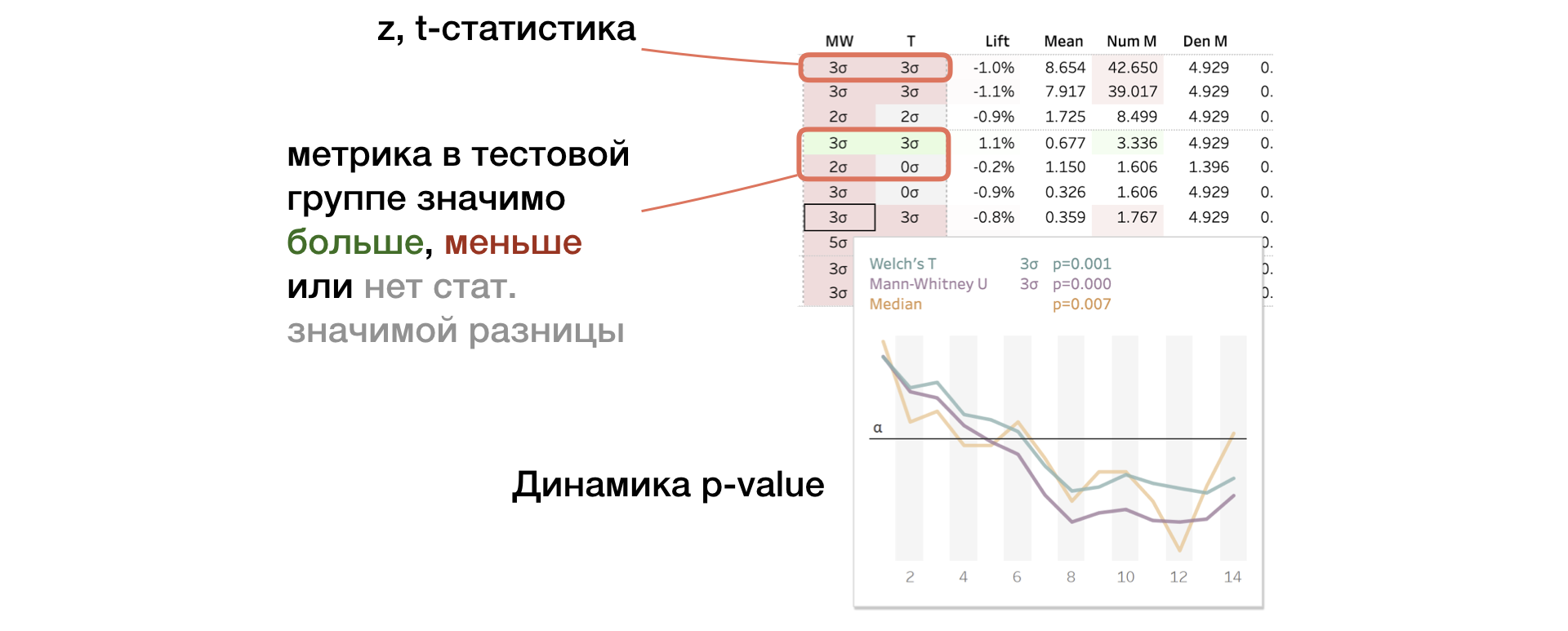
O painel exibe o valor das estatísticas z e t (para MW e T, respectivamente). Em uma dica de ferramenta - dinâmica de valor p. Se a alteração for significativa, a célula será destacada em vermelho ou verde, dependendo do sinal da diferença entre os grupos. Nesse caso, dizemos que a métrica é "colorida".
3. Levante. Diferença percentual entre grupos
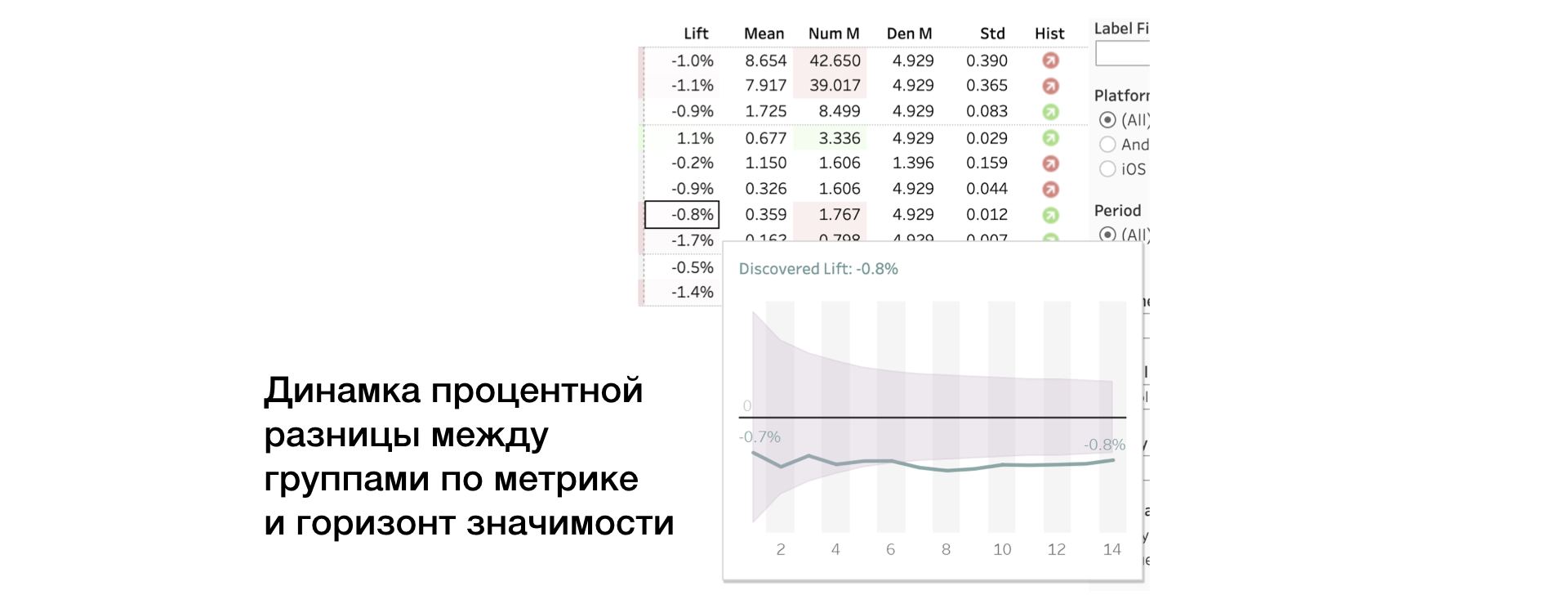
4. média | Num | Den Valor métrico, bem como numerador e denominador separadamente
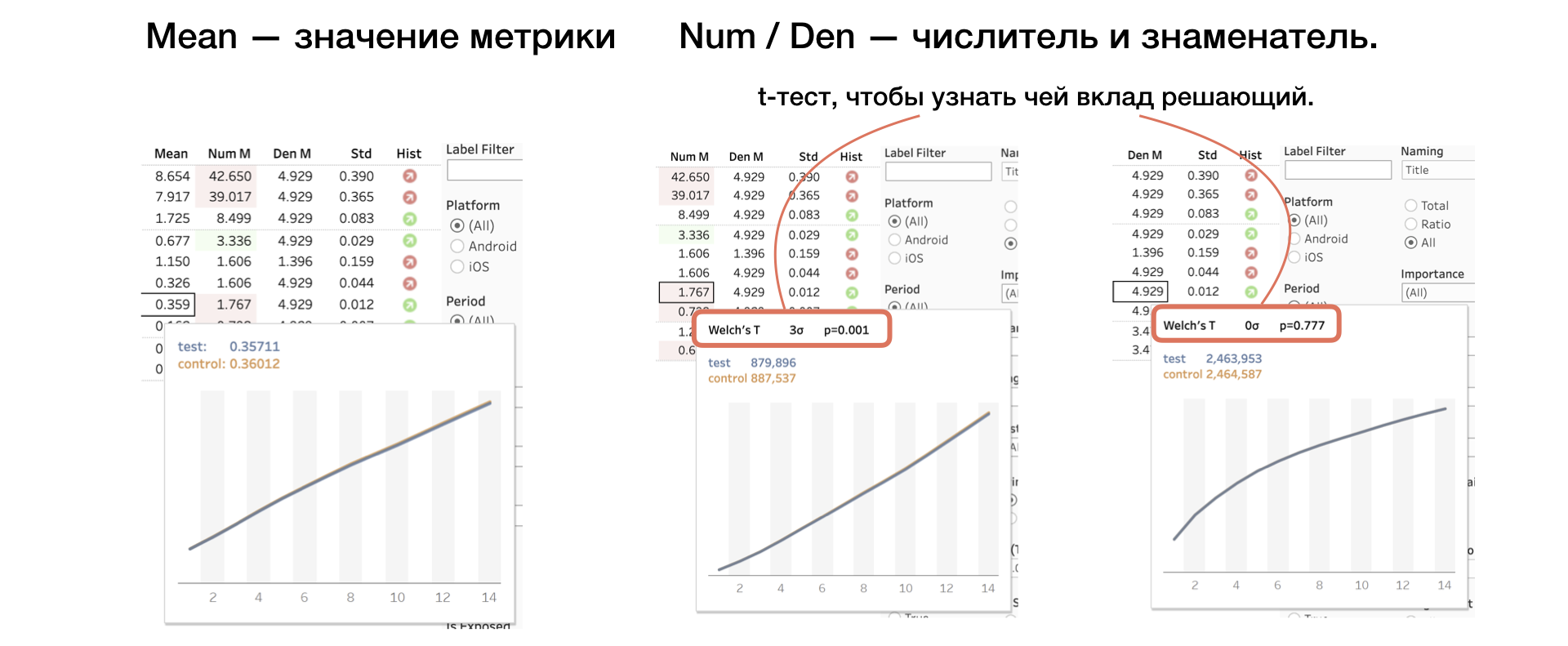
Aplicamos outro teste T ao numerador e denominador, o que ajuda a entender cuja contribuição é decisiva.
5. Padrão Desvio padrão seletivo
6. Hist. Teste de Shapiro-Wilk para normalidade da distribuição "bucket".
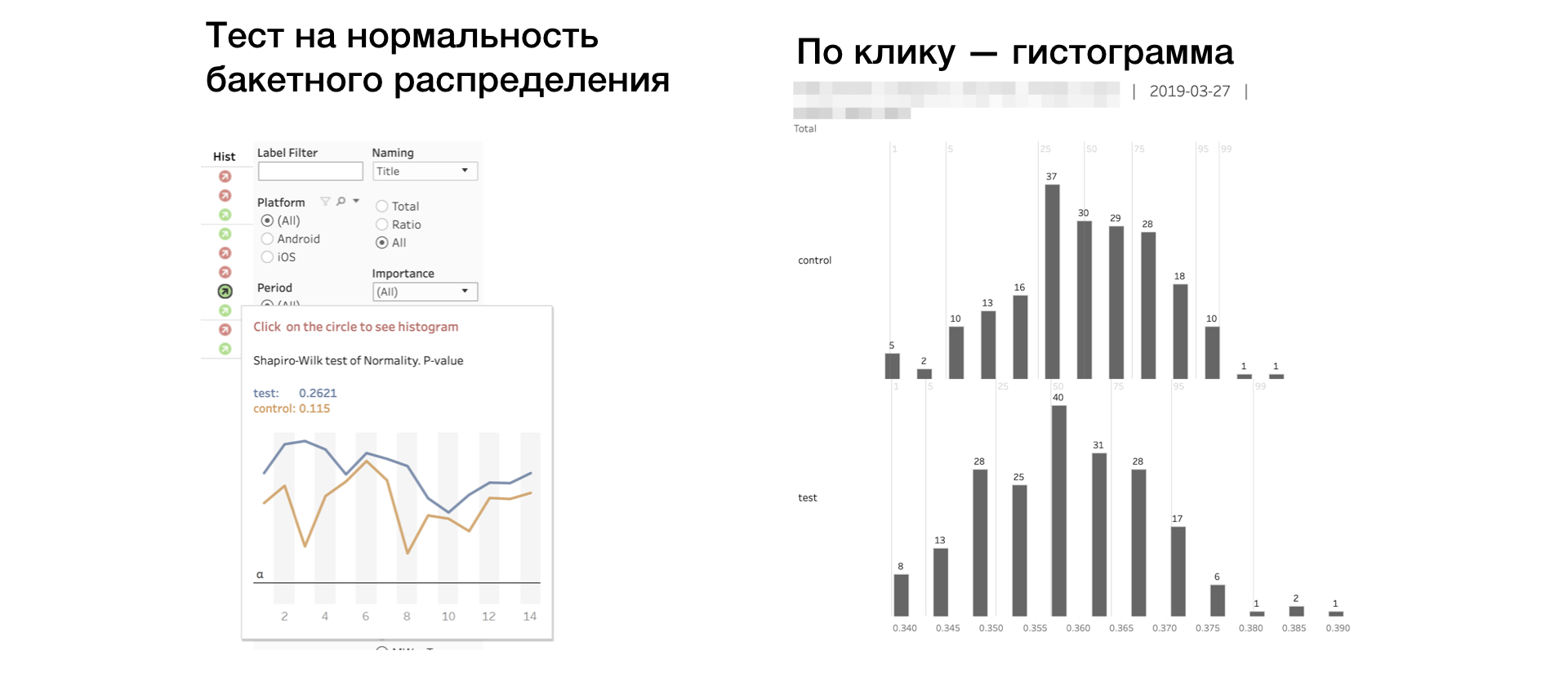
Se o indicador estiver vermelho, talvez a amostra tenha valores discrepantes ou cauda anormalmente longa. Nesse caso, você precisa levar o resultado de acordo com essa métrica com cuidado, ou de modo algum. Clicar no indicador abre o histograma da métrica por grupo. O histograma mostra claramente anomalias - é mais fácil tirar conclusões.
Conclusão
O surgimento da plataforma A / B em Avito é um divisor de águas quando nosso produto começou a crescer mais rapidamente. Todos os dias fazemos experimentos ecológicos que cobram à equipe; e "vermelhos", que fornecem alimento saudável para o pensamento.
Conseguimos construir um sistema eficaz de testes e métricas A / B. Muitas vezes, resolvíamos problemas complexos com métodos simples. Devido a essa simplicidade, a infraestrutura possui uma boa margem de segurança.
Tenho certeza de que aqueles que vão construir a plataforma A / B em sua empresa encontraram algumas idéias interessantes no artigo. Tenho o prazer de compartilhar nossa experiência com você.
Escreva perguntas e comentários - tentaremos respondê-las.