Em um artigo anterior, examinamos a abordagem que aplicamos à questão do processamento de dados computacional (agregação) para visualização em painéis interativos. O artigo abordou o estágio de entrega de informações de fontes primárias aos usuários no contexto de casos analíticos, o que possibilita a rotação do cubo de informações. O modelo de conversão de dados apresentado em tempo real cria uma abstração, fornecendo um único formato de consulta e construtor para descrever os cálculos, agregação e integração de todos os tipos de fontes conectadas - tabelas, serviços e arquivos de banco de dados .
As fontes listadas são mais propensas a serem estruturadas, implicando a previsibilidade do formato dos dados e a exclusividade dos procedimentos para o processamento e visualização. Mas para o analista, os dados não estruturados não são menos interessantes, que quando os primeiros resultados aparecem, às vezes superestimam as expectativas de tais sistemas. O apetite vem com a comida, e a perda de cautela pode repetir exatamente o conto ...
Mais! Mais ouro!
Mas seu chiado era quase inaudível e horror apareceu em seus olhos
(conto de fadas "Antílope Dourado")

O artigo descreve os principais recursos e o design de um cluster multifuncional e rastreador comportamental de usuários virtuais que automatizam a rotina de coleta de informações de recursos complexos da Internet. E apenas a questão do limite de tais sistemas é levantada.
Ao considerar os métodos de rastreamento, qualquer recurso hipotético da Internet do qual precisamos extrair informações pode ser colocado em uma escala com dois extremos - de simples recursos estáticos e APIs a sites interativos dinâmicos que exigem alto envolvimento do usuário. Os primeiros incluem a geração antiga de robôs de busca (os modernos, pelo menos, aprenderam a processar JavaScript ); os últimos incluem sistemas com farms de navegador e algoritmos que simulam o trabalho do usuário ou o atraem na coleta de informações.
Em outras palavras, as tecnologias de rastreamento podem ser colocadas em uma escala de complexidade:

Por um lado, a complexidade da fonte pode ser entendida como uma cadeia de ações necessárias para obter informações primárias e, por outro lado, tecnologias que devem ser aplicadas para obter dados legíveis por máquina adequados para análise.
Mesmo a extração aparentemente simples de textos de páginas estáticas nem sempre é trivial na prática - é necessário desenvolver e manter regras de planarização HTML para todos os tipos de páginas, ou automatizar e inventar heurísticas e soluções complexas. Até certo ponto, a estruturação é simplificada pelo desenvolvimento de micromarcações ( em particular, Schema.org , RDFa , Linked Data ), mas apenas em casos especiais estreitos, para baixar cartões de empresa, produtos, cartões de visita e outros produtos de otimização de mecanismo de pesquisa e dados abertos.
Abaixo, restringiremos deliberadamente o escopo e focaremos no componente tecnológico de um subconjunto de rastreadores de navegador projetados para baixar informações de sites complexos, em particular redes sociais - esse é exatamente o caso quando outros métodos simples de rastreamento não funcionam.
Considere uma abordagem que reduza a tarefa de coletar informações das redes sociais para a formação de uma fita da linha do tempo das informações - uma coleção ou fluxo atualizado de objetos com atributos e carimbos de hora. A lista de tipos de objetos e seus atributos é diferente, modificável e expansível, por exemplo: postagens, curtidas, comentários, republicações e outras entidades que são adicionadas ao sistema por desenvolvedores e operadores analíticos e carregadas por rastreadores.
Como a fita é um fluxo de objetos estruturados, surge a questão de seu preenchimento. Apoiamos dois tipos de fitas:
- uma fita simples cheia de conteúdo de fontes fixas;
- um feed de tópico preenchido com conteúdo de acordo com palavras-chave, frases e termos de pesquisa.
Um exemplo de um feed simples com fontes fixas ( listas de URLs para perfis e páginas são definidas ):

Um tipo simples de fita envolve o rastreamento periódico desses perfis e páginas em várias redes sociais com uma determinada profundidade de rastreamento e o carregamento de objetos selecionados pelo usuário. À medida que é preenchida, a fita fica disponível para visualização, análise e upload de dados:

A fita de tópico é uma extensão simples, fornece pesquisa de texto completo e filtragem de objetos carregados na fita. O sistema controla automaticamente o conjunto de fontes de fita e a profundidade do desvio, analisando a relevância e os relacionamentos das fontes. Esse recurso da implementação se deve à ausência ou ao trabalho "estranho" da pesquisa interna de palavras-chave nas redes sociais. Mesmo quando essa função está disponível, na maioria das vezes os resultados não são completamente gerados e de acordo com algum algoritmo interno, que é completamente incompatível com os requisitos do rastreador.
Um mecanismo especial com uma certa heurística é responsável pelo gerenciamento da fita no sistema - ele analisa dados e histórico, adiciona fontes relevantes (perfil e feeds da comunidade), nas quais as expressões especificadas são mencionadas ou são de alguma forma relacionadas a elas e remove as irrelevantes.
Um exemplo de fita temática:

No futuro, as fitas são usadas como fonte em transformações analíticas com visualização subsequente dos resultados, por exemplo, na forma de um gráfico:

Em alguns casos, o processamento de streaming de objetos recebidos é realizado com o salvamento em coleções de destino especializadas ou o upload através da API REST para usar o conteúdo coletado em sistemas de terceiros ( exemplo ). Em outros, o processamento de blocos por timer é realizado. O operador descreve o script de processamento com um script ou constrói um processo com sinais de controle e blocos de funções, por exemplo:

Conjunto de tarefas
As fitas ativas definem o conjunto de tarefas principal, cada qual forma tarefas relacionadas. Por exemplo, uma tarefa transversal de um único perfil pode gerar muitas subtarefas relacionadas - ignorando amigos, assinantes ou fazendo o download de novas postagens e informações detalhadas, etc. Há também uma etapa de pré-processamento de novos objetos da fita temática, que também forma tarefas relacionadas a novas fontes relevantes.
Como resultado, obtemos um grande número de diferentes tipos de tarefas relacionadas entre si, com prioridades, tempo e condições de execução - todo esse zoológico precisa ser gerenciado corretamente para que não haja situações em que algumas tarefas arrastem todos os recursos do cluster para si, em detrimento das tarefas de outras fitas. .
Para resolver as inconsistências, o sistema implementa recursos virtuais compartilhados e um mecanismo de priorização dinâmica, que leva em consideração os tipos de tarefas, o horário atual e a probabilidade de lançamento na forma de uma "cúpula". Em termos gerais - a prioridade em um determinado ponto se torna máxima, mas logo desaparece, a tarefa "azeda", mas sob certas circunstâncias, pode crescer novamente.
A fórmula para essa cúpula leva em consideração vários fatores, em particular: a prioridade das tarefas pai, a relevância da fonte associada e a hora da última tentativa (com rastreamentos repetidos para rastrear alterações ou quando ocorre um erro).
Usuários virtuais
No sentido amplo, um usuário virtual pode ser entendido como a imitação máxima de ações humanas, em termos práticos - um conjunto de propriedades que um rastreador deve ter:
- execute o código da página usando as mesmas ferramentas do usuário - SO, navegador, UserAgent, plugins, conjuntos de fontes e muito mais;
- interaja com a página, simulando o trabalho de uma pessoa com teclado e mouse - mova o cursor na página, faça movimentos aleatórios, faça uma pausa, pressione as teclas ao imprimir texto e muito mais ( não se esqueça dos dispositivos móveis );
- interaja com um centro de decisão que leva em consideração o contexto e o conteúdo da página:
- levar em conta duplicatas, a relevância dos objetos na página, a profundidade do rastreamento, os prazos e muito mais;
- responda a situações incomuns - em caso de captcha ou erro, faça uma solicitação e aguarde uma solução usando um serviço de terceiros ou com o envolvimento de um operador de sistema;
- tenha uma lenda crível - salve o histórico de navegação e os cookies (perfil do navegador), use determinados endereços IP, leve em consideração os períodos de maior atividade (por exemplo, de manhã ou no almoço).
Em uma visão idealizada, um usuário virtual pode ter várias contas, usar vários navegadores em períodos diferentes e se conectar com outros usuários virtuais, além de possuir o comportamento e os hábitos de navegação na Internet característicos de uma pessoa.
Por exemplo, imagine uma situação como essa - virtual usa um navegador e um IP como se estivesse no trabalho (o mesmo IP pode ser usado por "colegas"), outro navegador e um IP como se estivesse em casa (os "vizinhos" os usam) e, de tempos em tempos, telefone celular Com essa visão do problema, combater a coleta automatizada pelos serviços da Internet parece ser uma tarefa não trivial e, possivelmente, impraticável.
Na prática, tudo é muito mais simples - a luta contra os rastreadores é como uma onda e inclui um pequeno conjunto de técnicas: moderação manual, análise do comportamento do usuário (frequência e uniformidade das ações) e exibição de captcha. O Claruler, possuindo pelo menos até certo ponto as propriedades da lista acima, implementa totalmente o conceito de usuários virtuais e, com a devida atenção do operador, pode cumprir sua função por um longo tempo, permanecendo " Joe indescritível ".
Mas e o lado ético e legal do uso de usuários virtuais?
Para não brincar com os conceitos de dados públicos e pessoais, cada uma das partes tem seus próprios argumentos de peso, abordaremos apenas os pontos fundamentais.
A publicação automatizada de conteúdo, envio de spam, registro de conta e outras atividades "ativas" de usuários virtuais pode ser facilmente considerada ilegal ou afetar os interesses de terceiros. Nesse sentido, o sistema implementa uma abordagem na qual os usuários virtuais são apenas observadores curiosos representando o usuário (seu operador) e executando uma rotina para coletar informações.
Gerenciamento compartilhado de recursos virtuais
Como descrito acima, um usuário virtual é uma entidade coletiva que usa vários recursos virtuais do sistema e no processo. Alguns recursos são usados sozinhos, enquanto outros são compartilhados e usados por vários usuários virtuais, por exemplo:
- endereço do nó de saída (IP externo) - associado a um ou mais usuários virtuais;
- perfil do navegador - associado a um único usuário virtual;
- recurso de computação - conectado ao servidor, define as limitações do servidor como um todo e para cada tipo de tarefa;
- tela virtual - define as restrições do servidor, mas é usado pelo usuário virtual.
Cada recurso virtual possui um tipo e um grupo de instâncias chamado slots. Em cada nó do cluster, é definida a configuração de recursos e slots virtuais, que são adicionados ao conjunto de recursos virtuais e são acessíveis a todos os nós do cluster. Além disso, para um tipo de recurso virtual, é possível adicionar um número fixo e variável de slots.
Cada slot pode ter atributos que serão usados como condições ao vincular e alocar recursos. Por exemplo, podemos associar cada usuário virtual a certos tipos de tarefas, servidores, endereços IP, contas, períodos da maior atividade de rastreamento e outros atributos arbitrários.
No caso geral, o ciclo de vida de um recurso consiste em certos estágios:
- Quando um nó de cluster é iniciado no conjunto compartilhado de recursos virtuais, são registrados slots abertos adicionais, bem como links entre recursos;
- Quando uma tarefa é iniciada por um despachante a partir de um conjunto de recursos virtuais, um slot livre adequado é selecionado e bloqueado. Por sua vez, o bloqueio do recurso pai leva ao bloqueio de recursos relacionados e, na ausência de slots livres, é gerada uma falha;
- Após a conclusão da tarefa, o slot principal de recursos e os slots associados são liberados.
Além dos especificados na configuração do nó, também existem recursos virtuais do usuário - entidades com as quais o operador do sistema trabalha. Em particular, o operador usa a interface de registro do usuário virtual, que suporta várias funções úteis ao mesmo tempo:
- gerenciamento de detalhes e atributos adicionais indicando as especificidades de uso, em particular, os usuários virtuais podem ser divididos em grupos e utilizados para diferentes fins;
- rastreando o status e as estatísticas dos usuários virtuais;
- conexão com a tela virtual - rastreamento em tempo real do trabalho, executando ações no navegador em vez do usuário virtual (widget da área de trabalho remota).
Exemplo de registro de recursos virtuais do usuário:

Caso legal que não se enraizou
Além das fitas informativas como um “assassino de fitchi”, desenvolvemos um gráfico de protótipo de pesquisa para realizar pesquisas complexas e conduzir investigações on-line. A idéia principal é construir um gráfico visual no qual os nós sejam os modelos de objetos (pessoas, organizações, grupos, publicações, gostos etc.) e os links sejam os padrões de conexões entre os objetos encontrados.
Um exemplo de um gráfico simples de pesquisa de pessoas e os relacionamentos entre elas:

Essa abordagem pressupõe que a pesquisa comece com um mínimo de informações conhecidas. Após a pesquisa inicial, o usuário examina os resultados e adiciona gradualmente condições adicionais ao gráfico de pesquisa, restringindo a seleção e aumentando a profundidade do rastreamento e a precisão do resultado. Por fim, o gráfico assume a forma em que cada um dos nós é um feed de informações separado com os resultados. Essa fita também pode ser usada como fonte para análises e visualizações adicionais em painéis e widgets.

Por exemplo ...Como exemplo, podemos considerar alguns casos simples:
- encontre todos os amigos da pessoa com o nome dado;
- Encontre todas as postagens de amigos de uma pessoa com um nome e outros atributos;
- encontre todos os assinantes das páginas em que as frases-chave especificadas são mencionadas ou reúna o ambiente em torno de certas postagens ou autores;
- ou encontre interseções - autores de comentários em todas as postagens escritas por autores que uma vez publicaram postagens sobre tópicos específicos.
Quando anunciamos o desenvolvimento desse ajuste, nossos clientes e parceiros apoiaram calorosamente essa idéia, parecia exatamente o que faltava em soluções semelhantes existentes. Porém, após a conclusão do protótipo em funcionamento, na prática, os clientes não estavam prontos para alterar seus processos internos, e as investigações na Internet foram consideradas como algo que poderia ser útil se de repente fosse necessário. Ao mesmo tempo, do lado tecnológico, a funcionalidade é séria e requer refinamento e suporte adicionais. Como resultado, devido à falta de demanda e interesse prático de nossos parceiros, essa demanda teve que ser congelada temporariamente até tempos melhores.
Reencarnação
Dado o vetor atual de desenvolvimento de nossas soluções, esse recurso ainda parece relevante, mas do ponto de vista técnico, ele já é visto de maneira diferente. Em vez disso, é uma extensão da funcionalidade do Cubisio, a saber, o editor do modelo de domínio e o editor dos processos de processamento de dados, que até agora foram implementados como protótipo, mas fornecem uma abordagem semelhante de forma generalizada.
Um exemplo do modelo ontológico da área de assunto "Redes sociais" (clique na imagem do editor):

Um exemplo de um gráfico analítico de pesquisa baseado na ontologia acima (clicar na imagem abre o editor):

Pilha de tecnologia de cluster

O sistema descrito foi desenvolvido em conjunto com a plataforma (denominada dWires) há vários anos, está funcionando e ainda está em uso. As principais soluções bem-sucedidas migraram naturalmente para nossos novos desenvolvimentos. Em particular, a plataforma descrita representa a primeira geração do projetista de sistemas analíticos da informação, a partir dos quais a plataforma jsBeans e nossos outros desenvolvimentos foram gerados.
Em resumo, o sistema é baseado no cluster Akka, no interpretador Rhino e no servidor da web incorporado Jetty. Alguns recursos arquiteturais úteis podem ser vistos no diagrama acima. , , , JavaScript- , jsBeans .
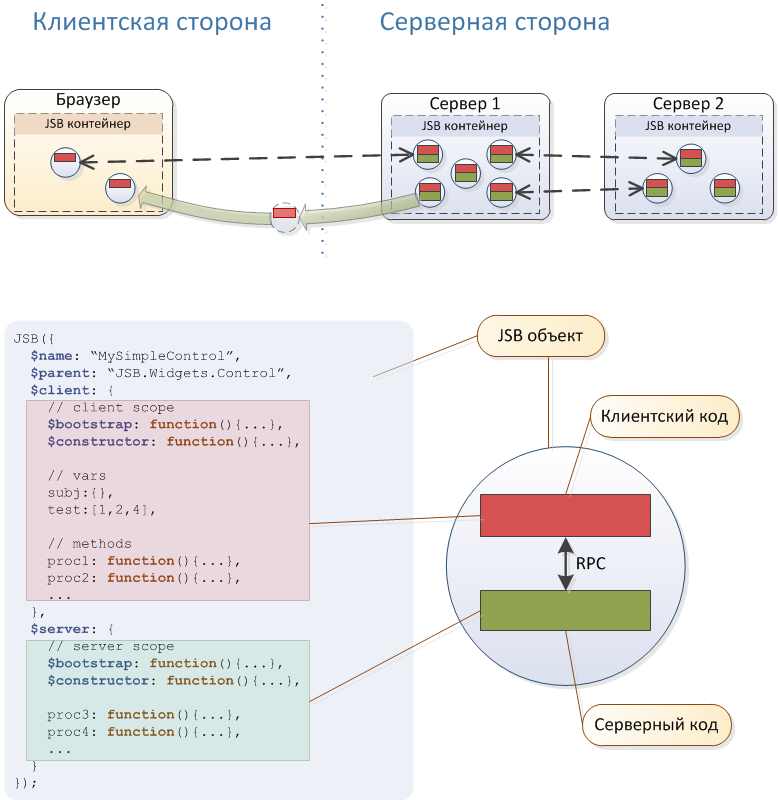
, – .
Java. , , – - JavaScript. JavaScript ( ), , , . – , , , , , - .
Akka - . - Akka Cluster , . , " " ( ) .
Selenium WebDriver , : , , API . WebDriver ( , IP ).
( ):
- , , Xvfb;
- VNC , , x11vnc;
- VNC Web Viewer , , noVNC -.
MongoDB, – . Elasticsearch, MongoDB. (H2, EhCache, Db4o).
" ", , bash , ( ). . , .
, .
. – . , " ".
, .
,
( « »)