
Você está familiarizado com uma situação em que passa muito tempo escolhendo um filme comparável ao tempo em que o assistiu? Para os usuários de cinemas on-line, esse é um problema comum e, para os próprios cinemas - lucros perdidos.
Felizmente, temos o Rekko - um sistema de recomendações pessoais que ajuda com sucesso os usuários de Okko há um ano a escolher filmes e séries de mais de dez mil unidades de conteúdo. No artigo, mostrarei como está organizado do ponto de vista algorítmico e técnico, como abordamos seu desenvolvimento e como avaliamos os resultados. Bem, também vou falar sobre os resultados do teste A / B anual.
Primeiro, um pouco de história. Okko começou sua existência em 2011 como parte de Iota, começando com o nome Yota Play.
Já em 2011, os usuários aceitaram com entusiasmo a ideia de assistir a um filme legalmente na Internet O Yota Play era um serviço exclusivo para a época: ele se integrava estreitamente às redes sociais e usava informações sobre filmes vistos e classificados por amigos em várias partes do serviço, incluindo recomendações.

Em 2012, foi decidido complementar as recomendações sociais com as algorítmicas. Foi assim que o "Oracle" apareceu - o primeiro sistema de recomendação do cinema online Okko. Aqui estão alguns trechos de seu documento de design:
Uma abordagem semelhante foi usada no sistema implementado de recomendações pessoais. A escala de níveis é usada do “nada” (vazio, ausência) ao “tudo” (completamente, no máximo). No intervalo [127 .. + 127] 0 - é o meio ou "norma". Nesta escala, também são avaliados o grau de simpatia pelo personagem principal e o preço subjetivo do produto e o grau de cor "vermelha". Por exemplo, o tamanho do universo é estimado em +127 (na escala de dimensões) e a escuridão é estimada em 127 (na escala de intensidade da luz).
Ao fazer recomendações, é importante não apenas os antecedentes, mas também a natureza do usuário em particular. O perfil pessoal também contém quatro escalas de tipos de caracteres (de acordo com K. Leonhard - demonstrativo, pedante, travado, empolgado).
Os limites fisiológicos do cérebro não dependem das propriedades do caráter de uma pessoa e de quão amigável e sociável ele é. Segundo o professor, existem restrições no neocórtex, o departamento responsável por pensamentos e fala conscientes. Essa restrição também é levada em consideração no sistema implementado, especialmente no desenvolvimento de recomendações para um tipo de caráter pedante e na formação de uma amostra desses usuários entre as conexões sociais.

Como você já entendeu, os tempos eram selvagens, os limites fisiológicos do cérebro não se limitavam a nada e o próprio neocórtex com overclock podia gerar recomendações pessoais à velocidade da luz. Portanto, o modelo foi decidido entrar imediatamente em produção.
Tanto quanto se pode julgar pelos artefatos sobreviventes da civilização antiga, "Oracle" era uma mistura selvagem de algoritmos de filtragem colaborativa, temperados generosamente com as regras de negócios.

Em meados de 2013, todos começaram a desistir um pouco e finalmente foi decidido verificar a qualidade da máquina de recomendação. Para fazer isso, um editor especialmente treinado preencheu as seções principais do aplicativo e o teste A / B foi lançado: metade dos usuários viu a saída do algoritmo, metade - a escolha do editor.
É agora que estamos lendo artigos sobre as próximas vitórias da inteligência artificial e, horrorizados, imaginamos o dia em que ele perderá nosso trabalho. Então, em 2013, a situação era diferente: uma pessoa derrotou heroicamente o carro, criando ainda mais empregos no departamento de conteúdo. O Oracle foi desligado e nunca foi ligado novamente. Logo, todas as fichas sociais desapareceram e o Yota Play se transformou em Okko.
O período de 2013 a 2016 foi marcado pelo “inverno” da inteligência artificial e pelo regime totalitário do departamento de conteúdo: não houve recomendações pessoais no serviço.
Em meados de 2017, ficou claro que você não pode mais viver assim. Os sucessos da Netflix eram bem conhecidos de todos e todo o setor estava se movendo rapidamente para a personalização. Os usuários não estavam mais interessados em serviços estáticos "burros", eles já estavam começando a se acostumar com interfaces "inteligentes", entendendo-os perfeitamente e prevendo todos os seus desejos.
Como primeira iteração, decidimos nos integrar com dois grandes fornecedores russos de recomendações. Uma vez por dia, os dois serviços pegavam os dados necessários de Okko, carregavam suas caixas pretas em servidores distantes e carregavam os resultados.
De acordo com os resultados do teste A / B de seis meses, não foram encontradas diferenças estatisticamente significativas nos grupos controle e teste.
No final deste teste A / B, vim para Okko para começar a tornar o serviço verdadeiramente pessoal com o chefe de análise, Mikhail Alekseev ( malekseev ). Menos de um ano depois, Danil Kazakov ( xaph ) se juntou a nós, finalmente formando a equipe atual.
Considerações gerais
Quando um problema de negócios que há muito tempo é estudado pela comunidade mundial surge à sua frente, o que, além disso, precisa ser resolvido rapidamente, é tentador tomar a primeira solução popular de rede neural profunda que é empurrada para ele, enfiar os dados nela com uma pá, empurrá-la e jogá-la no produto.

O principal é não sucumbir a essa tentação. A tarefa da comunidade científica - atingir velocidade máxima em conjuntos de dados podres e sintéticos - geralmente não coincide com a tarefa comercial - ganhar mais dinheiro, gastando menos recursos.

Não, isso não significa que você não precisa de redes recorrentes e pode arrecadar bilhões usando o método k vizinhos mais próximos. Pode acontecer que, nos seus dados, a decomposição clássica da matriz permita que você ganhe 100 milhões adicionais condicionais por ano e redes recorrentes - 105 milhões por ano. Ao mesmo tempo, a manutenção de um rack de servidores com placas de vídeo para essas mesmas redes custará 10 milhões por ano e levará vários meses extras para ser desenvolvida e implementada, e a simples integração de uma decomposição de matriz pronta em outra seção da lista de serviços e mala direta exigirá um mês de melhorias e dará outros 100 milhões condicionais por ano.
Portanto, é importante começar com o básico - métodos básicos comprovados - e avançar para abordagens cada vez mais modernas, certifique-se de medir e prever que efeito cada novo método terá sobre os negócios, quanto custará e quanto permitirá ganhar.
Okko pode medir bem. Literalmente, todo novo recurso, toda inovação que passamos por um teste A / B, é examinada no contexto de uma variedade de grupos de usuários, os efeitos são verificados quanto à significância estatística e somente depois que é tomada a decisão de aceitar ou rejeitar a nova funcionalidade.

O painel atual da Rekko, por exemplo, compara os grupos de controle e teste para mais de 50 métricas, incluindo receita, tempo gasto no serviço, tempo para selecionar um filme, número de visualizações por assinatura, conversão para compra e renovação automática e muitas outras. E sim, ainda mantemos um pequeno grupo de usuários que nunca receberam recomendações personalizadas (desculpe).

Sobre sistemas de recomendação
Para começar, uma pequena introdução aos sistemas de recomendação.
O objetivo do sistema de recomendação é que, para cada usuário em sua história de interagir com elementos para construir uma relação de ordem no conjunto de todos os elementos. Isso significa o seguinte: independentemente dos dois elementos arbitrários que usamos, sempre podemos dizer qual é o mais preferível para o usuário e qual é o menor.
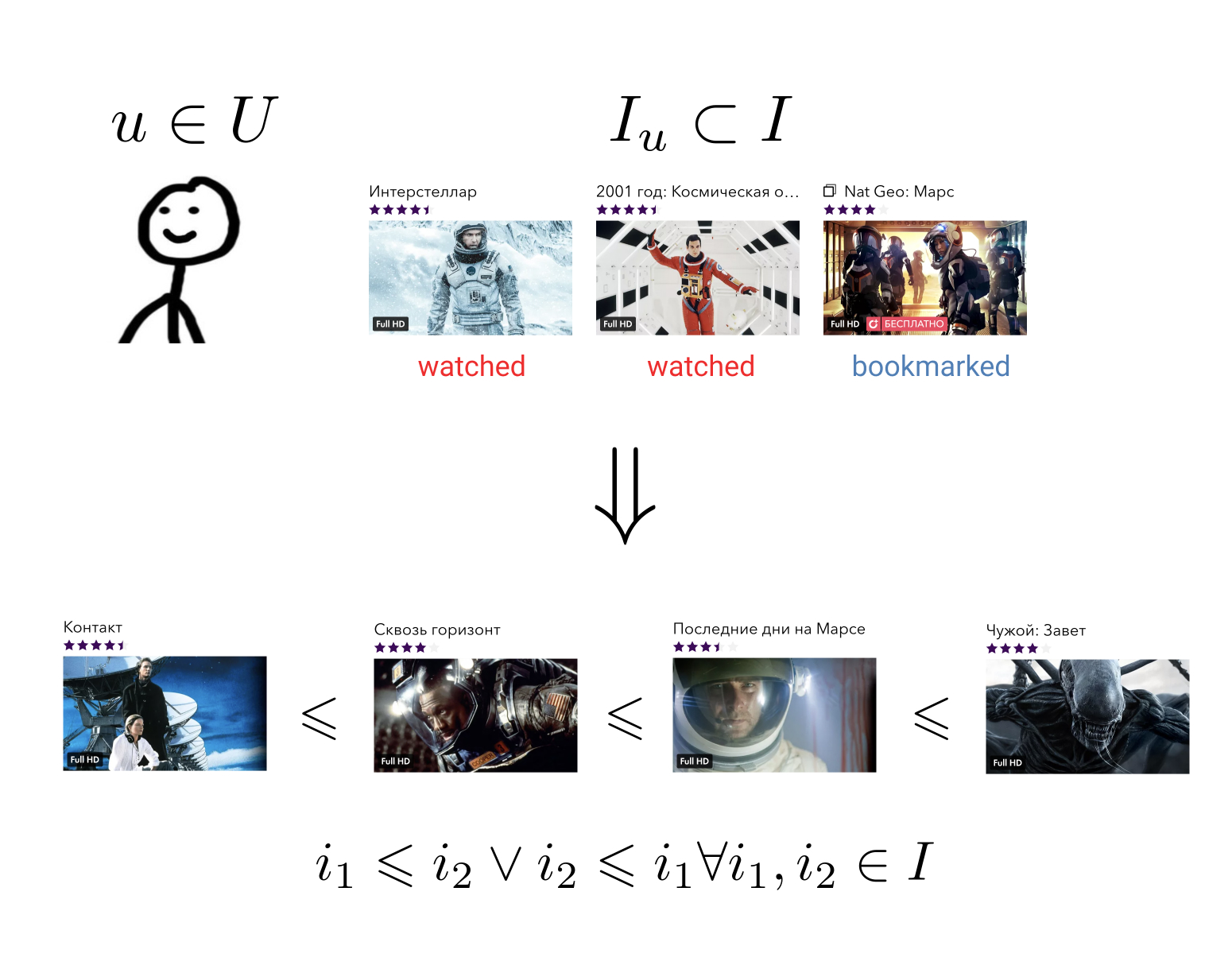
Essa tarefa bastante geral pode ser reduzida para uma mais simples: mapear elementos para um conjunto no qual uma relação de ordem já está definida. Por exemplo, em um conjunto de números reais. Nesse caso, é necessário que cada usuário e cada elemento consiga prever um certo valor - quanto esse usuário prefere esse elemento.

Tendo uma relação de pedidos em nossos elementos, somos capazes de resolver muitos problemas de negócios, por exemplo, escolher entre todos os elementos N os mais relevantes para o usuário ou classificar os resultados da pesquisa de acordo com suas preferências.
Idealmente, precisamos de toda uma família de relacionamentos de ordem sensíveis ao contexto. Se o usuário inseriu a coleção "Ação", ele provavelmente preferirá o filme "Destruidor" ao filme "Oscar", mas na coleção "Filmes com Sylvester Stallone", a preferência pode muito bem ser o oposto. Exemplos semelhantes podem ser dados para o dia da semana, hora do dia ou dispositivo a partir do qual o usuário entrou no serviço.

Tradicionalmente, todos os métodos para construir recomendações pessoais são divididos em três grandes grupos: filtragem colaborativa (CF), modelos de conteúdo (modelos de conteúdo, CM) e modelos híbridos que combinam as duas primeiras abordagens.
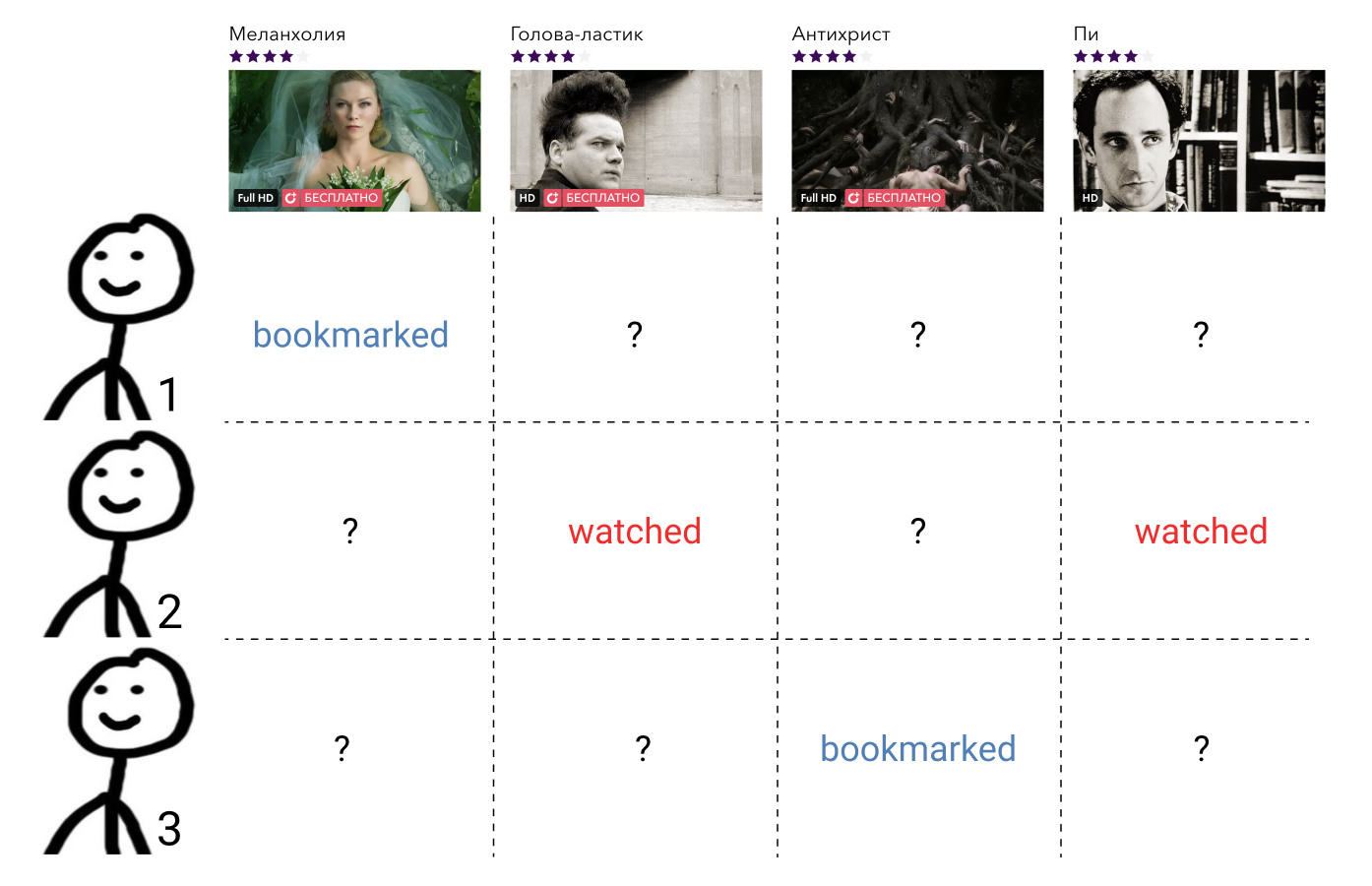
Os métodos de filtragem colaborativa usam informações sobre as interações de todos os usuários e todos os elementos. Essas informações, como regra, são apresentadas na forma de uma matriz esparsa, em que as linhas correspondem aos usuários, as colunas aos elementos e o usuário e o elemento contêm o valor que caracteriza a interação entre eles ou uma lacuna se não houver essa interação. A tarefa de construir uma relação de ordem aqui se reduz à tarefa de preencher os elementos ausentes da matriz.
Esses métodos, como regra, são fáceis de entender e implementar, rápidos, mas não mostram o melhor resultado.
Modelos de conteúdo - métodos arbitrários de aprendizado de máquina para resolver problemas de classificação ou regressão, parametrizados por um determinado conjunto de parâmetros . Na entrada, eles aceitam os atributos do usuário e os atributos do elemento, e a saída é o grau de relevância do elemento fornecido para esse usuário. Esses modelos não são ensinados sobre as interações de todos os usuários e todos os elementos, como métodos de filtragem colaborativa, mas apenas sobre precedentes individuais.

Esses modelos, em regra, são muito mais precisos que os métodos de filtragem colaborativa, mas são muito mais lentos. Imagine se tivermos uma função de alguma forma geral que aceite sinais de usuários e elementos como entrada, ela deverá ser chamada para cada par . No caso de mil usuários e dez mil elementos, esse é um milhão de chamadas.
Os modelos híbridos combinam os pontos fortes de ambas as abordagens, oferecendo recomendações de qualidade em um período de tempo razoável.
A abordagem híbrida mais popular atualmente é uma arquitetura de duas camadas, em que o modelo de filtragem colaborativa seleciona um pequeno número (100 - 1000) de candidatos de todos os elementos possíveis, que são classificados por um modelo de conteúdo muito mais poderoso. Às vezes, pode haver vários estágios de seleção de candidatos e um modelo cada vez mais complexo é usado em cada novo nível.

Essa arquitetura tem muitas vantagens:
- As partes colaborativas e de conteúdo não estão interconectadas e podem ser treinadas separadamente com diferentes frequências;
- A qualidade é sempre melhor do que a de um modelo colaborativo separadamente;
- A velocidade é muito maior que a do modelo de conteúdo separadamente;
- "Grátis", obtemos vetores de um modelo colaborativo, que pode ser usado para resolver problemas relacionados.
Se falamos de tecnologias específicas, existem muitas combinações possíveis.
Como parte colaborativa, você pode levar assinaturas de usuários, conteúdo popular, conteúdo popular entre os amigos do usuário, aplicar fatoração de matriz ou tensor, treinar DSSM ou qualquer outro método com previsão bastante rápida.
Como modelo de conteúdo, qualquer abordagem pode ser usada em geral, da regressão linear às grades profundas.
No Okko, atualmente estamos focando em uma combinação de fatoração de matriz com perda de WARP e aumento de gradiente sobre as árvores, que discutirei agora em detalhes.
Etapa um: seleção de candidatos
Acho que não estou mentindo se disser que os algoritmos de fatoração de matriz são de longe os métodos mais populares de filtragem colaborativa. A essência do método é clara a partir do nome: estamos tentando apresentar a matriz já mencionada de interações do usuário com o conteúdo pelo produto de duas matrizes de classificação inferior, uma das quais será uma “matriz do usuário” e a outra uma “matriz de elementos”. Com essa decomposição, podemos restaurar a matriz original juntamente com todos os valores ausentes.

Nesse caso, é claro, somos livres para escolher um critério para a similaridade das matrizes disponíveis e restauradas. O critério mais simples é o desvio padrão.
Vamos - linha da matriz do usuário correspondente ao usuário e - coluna da matriz do elemento correspondente ao elemento . Então, ao multiplicar matrizes, seu produto significará a magnitude da interação pretendida entre o usuário especificado e o elemento. Agora calculando o desvio padrão entre essa quantidade e o valor conhecido a priori da interação para todos os pares de usuários e elementos em interação , obtemos uma função de perda que pode ser minimizada.
Como regra, a regularização ainda é adicionada a ela.
Tal problema não é convexo e NP-complexo. No entanto, é fácil perceber que, ao fixar uma das matrizes, a tarefa se transforma em regressão linear em relação à segunda matriz, o que significa que podemos procurar uma solução iterativamente, congelando alternadamente a matriz do usuário ou a matriz de elementos. Essa abordagem é chamada de mínimos quadrados alternados (ALS).

A principal vantagem do ALS é a velocidade e a capacidade de paralelizar facilmente. Por isso, ele é tão amado em Yandex.Zen e Vkontakte, onde usuários e elementos somam dezenas de milhões.
No entanto, se estamos falando sobre a quantidade de dados que cabe em uma máquina, o ALS não resiste às críticas. Seu principal problema é que ele otimiza a função de perda incorreta. Lembre-se da formulação da tarefa de construir um sistema de recomendação. Queremos obter a relação da ordem no conjunto e otimizar o desvio padrão.
É fácil dar um exemplo de matriz para o qual o desvio padrão será mínimo, mas a ordem dos elementos é irremediavelmente destruída.
Vamos ver o que podemos fazer sobre isso. Na cabeça do usuário, todos os elementos com os quais ele interagiu são organizados em alguma ordem. Por exemplo, ele sabe com certeza que Interstellar é melhor que Gravity, Gravity e Alien são igualmente bons filmes, e são todos um pouco piores que Terminator. Ao mesmo tempo, ele também experimenta uma certa atitude em relação aos filmes que o usuário ainda não assistiu e o mesmo para todos. Ele pode acreditar que esses filmes são a priori piores do que aqueles que ele assistiu. Ou ele pode considerar que, por exemplo, Prometeu é um filme ruim, e qualquer filme que ele ainda não assistiu será melhor que ele.
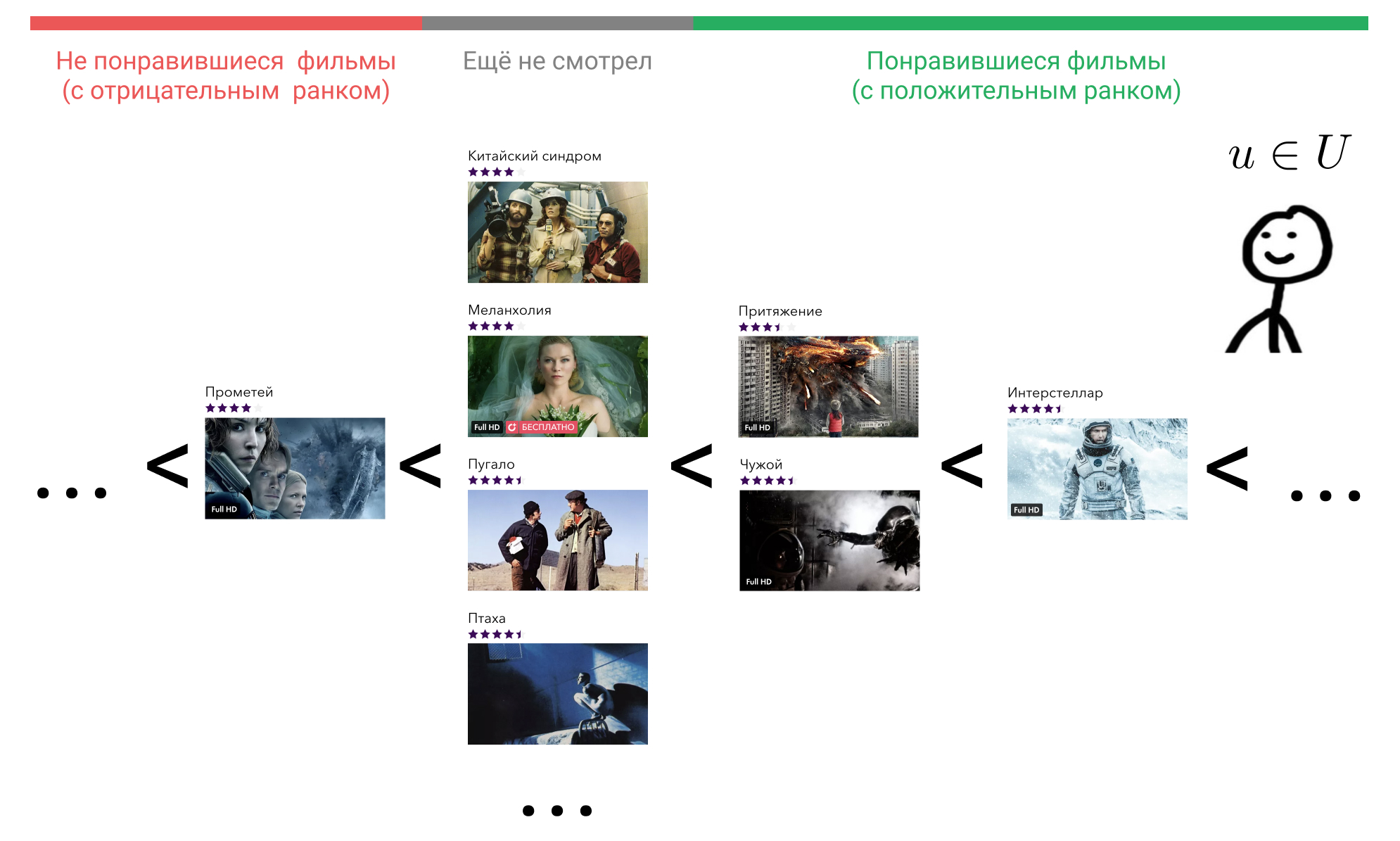
Imagine que, de acordo com alguns sinais de comportamento do usuário no serviço, possamos restaurar essa ordem exibindo o elemento com o qual ele interagiu, em um número inteiro usando a função . Muitos dos filmes com os quais o usuário interagiram, denotam como . Nós concordamos que se o usuário não interagiu com o filme isso é . Portanto, se o usuário considerou o filme ruim, então e se for bom, então .

Agora podemos entrar no ranking .
aqui denota a função do indicador e é igual à unidade se true e zero caso contrário.
Vamos parar por um minuto e pensar no que significa essa classificação.
Nós consertamos o usuário , este é um usuário específico, qual deles - não estamos interessados. Assim, seu vetor será corrigido.
Pegue agora qualquer filme que ele assistiu, por exemplo, Interestelar. Na fórmula, isso . Em seguida, encontramos um filme que o usuário considera pior que o Interestelar. Podemos escolher entre "Atração", "Alien", "Prometeu" ou qualquer filme que ele ainda não tenha assistido.

Pegue a "Atração". Na fórmula, isso . , «» , , «» . . «», «» , .
, , «». , .
.
— , . , . , , .
. ? , , , , .
: . , , . ,
onde — .
, , , .
WARP WSABIE: Scaling Up To Large Vocabulary Image Annotation . , , . 10%.
. Okko :
- ;
- ;
- ( );
- ;
- 0 10.
, , . 399 , , . , . -, .
— . , explicit : , . , , implicit .
, , . . , .
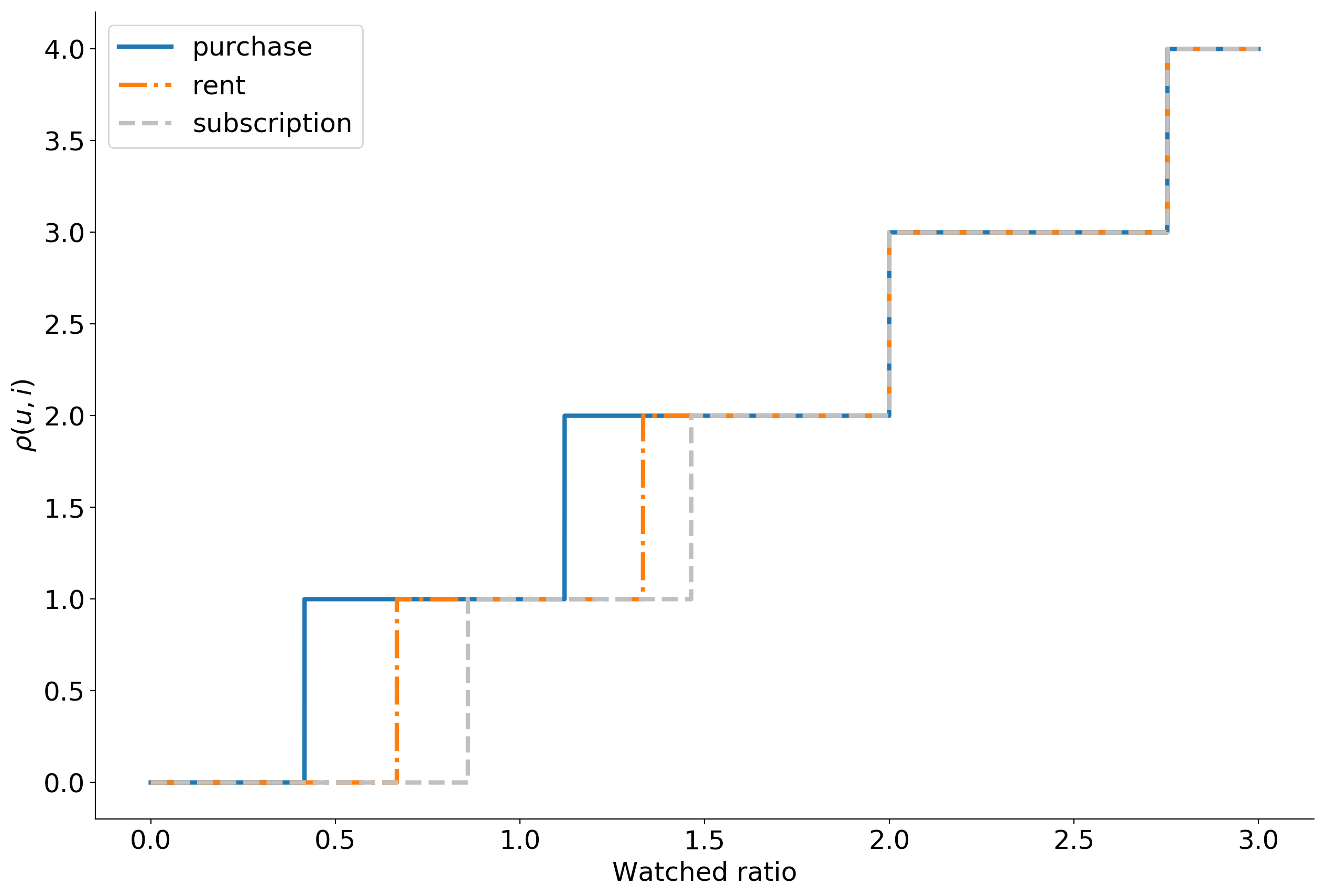
, , .
, Cython , LightFM .
:

, top-N : . , Approximate nearest neighbor algorithm based on navigable small world graphs .
, , , , . , - , . : , .
Esses problemas são evitados pelos modelos de conteúdo. Eles são poderosos, expressivos e você pode colocar quaisquer sinais neles, mas são extremamente lentos. A solução é executar o modelo de conteúdo não em todos os elementos, mas em candidatos obtidos da decomposição da matriz. Pode haver quantos candidatos você conseguir processar, mas de preferência pelo menos o dobro do que você mostra aos usuários. No nosso caso, para os 100 filmes recomendados, a melhor solução foi usar 400 candidatos.

Os atributos que enviamos ao modelo de conteúdo podem ser divididos em três grupos: atributos do usuário, atributos do elemento e sinais de interação. No total, são obtidos cerca de 50 sinais.
Como sinais dos usuários, usamos estatísticas agregadas de seu comportamento no serviço, por exemplo:
- Porcentagem de exibição da assinatura
- distribuição de dispositivos a partir dos quais o usuário efetua login no aplicativo,
- tempo de vida no serviço,
- etc.
Para filmes, usamos quase todas as meta-informações disponíveis: gênero, ano de lançamento, país, ator, diretor, limite de idade etc. As métricas agregadas de negócios também ajudam: porcentagem de visitas ao cartão, número de visualizações, adições a favoritos, distribuição por métodos de visualização, dispositivos etc.
Sinais de interação incluem rapidez na seleção de candidatos e estatísticas agregadas para todas as interações anteriores de usuários e filmes, com a participação dos mesmos atores, diretores e roteiristas do filme em questão.
A pergunta mais comum que surge quando se trata de classificar candidatos com um modelo de segundo nível é como treinar esse modelo. Somente no caso da fatoração matricial, precisávamos de dois conjuntos, separados por tempo - treinamento e teste. No caso de um sistema de dois estágios, precisaremos de três deles - dois de treinamento e um teste.
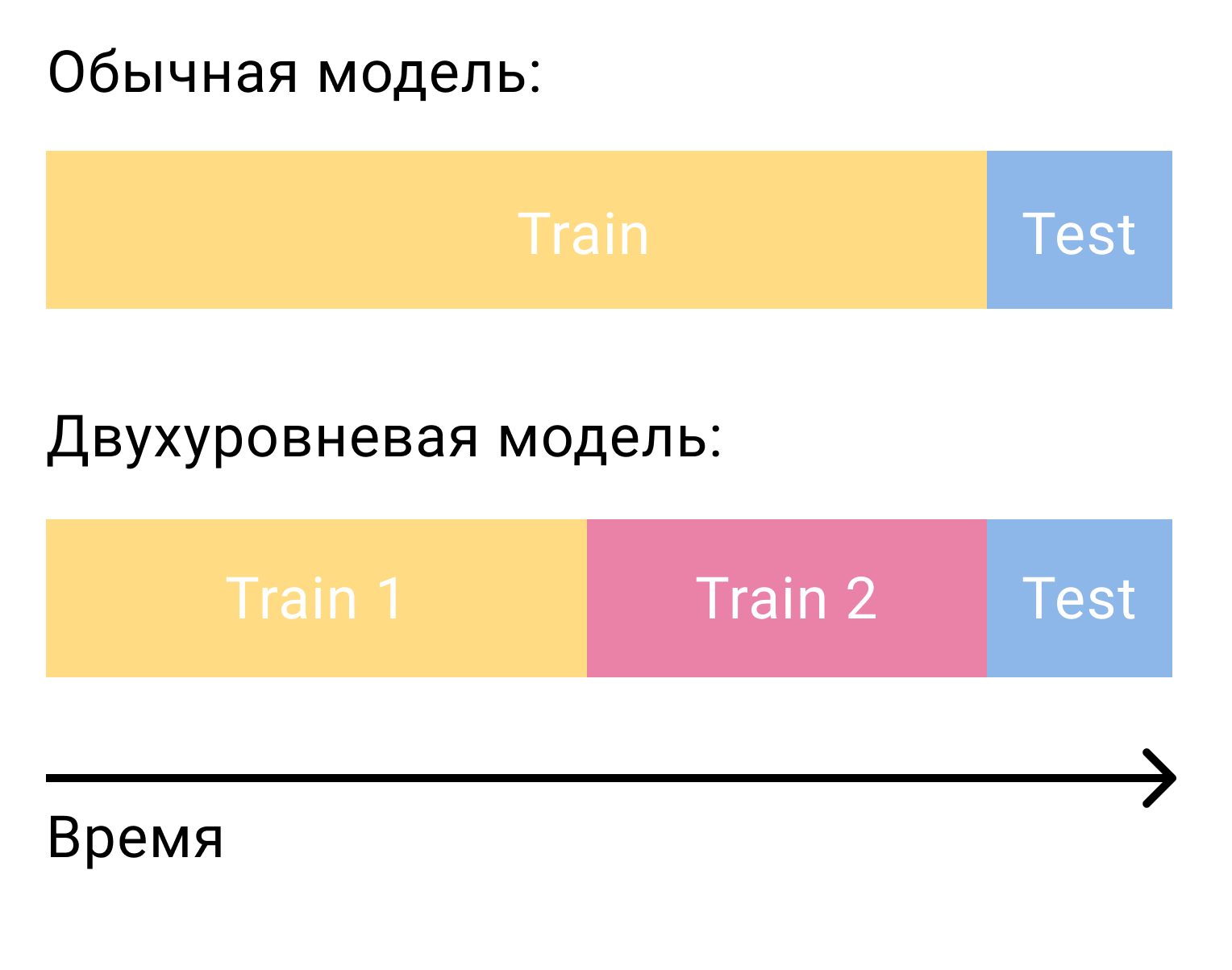
No primeiro conjunto de treinamento, treinaremos o modelo de primeiro nível e formaremos candidatos. Dos candidatos, é importante excluir os elementos com os quais o usuário interagiu neste conjunto. Em seguida, veremos com quais candidatos o usuário interagiu no segundo conjunto de treinamento. Nós os chamamos de positivos e os candidatos restantes de negativos. Este será o nosso conjunto de treinamento para o modelo de conteúdo.
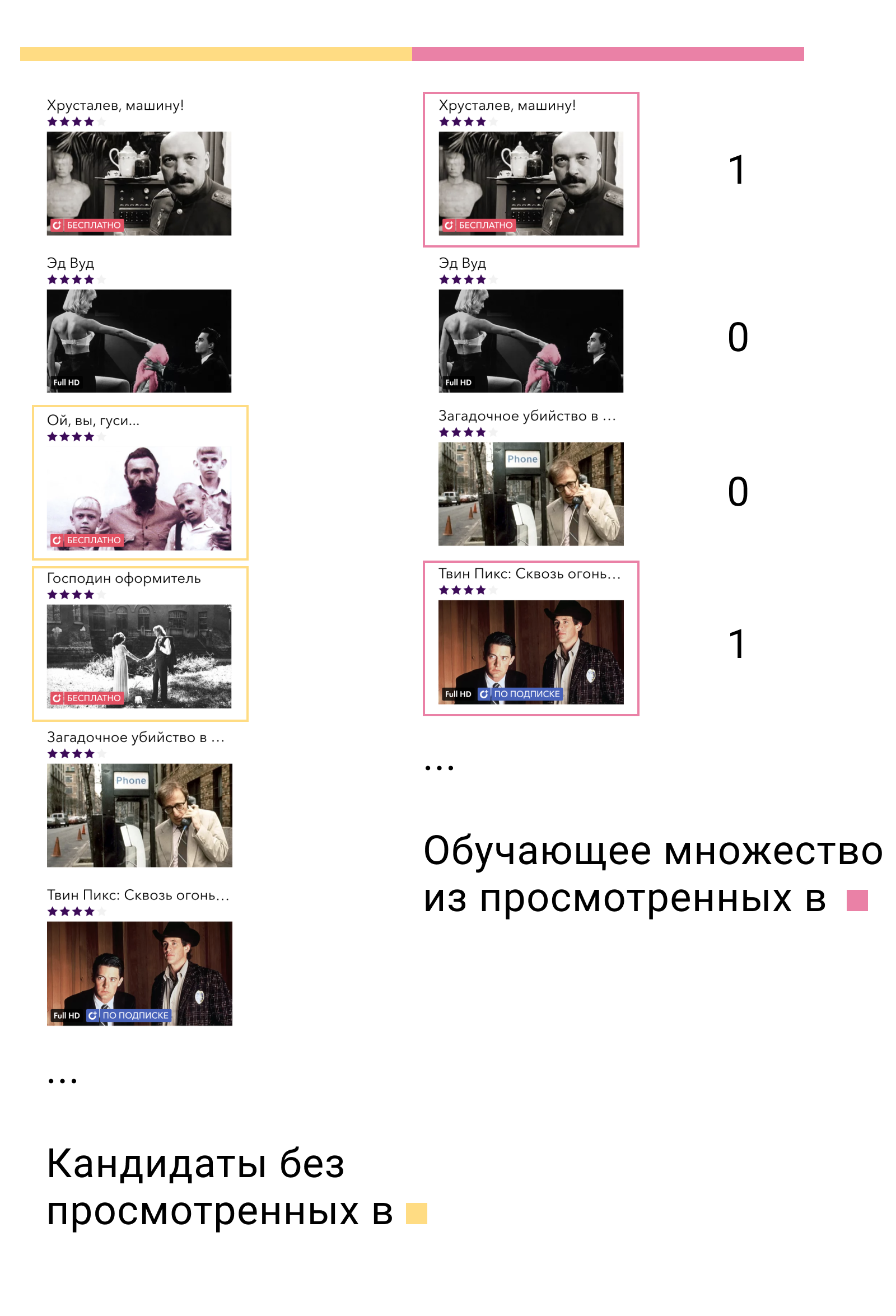
Por que isso funciona? Primeiramente, treinamos o modelo exatamente nos dados em que ele será usado - a saída do modelo de primeiro nível. Em segundo lugar, dentre todos os possíveis exemplos negativos, tomamos os mais complexos - aqueles que o modelo de primeiro nível chama de relevantes para o usuário, mas não são.
O que vem a seguir? A solução mais simples e mais óbvia é resolver o problema de classificação binária e classificar os elementos em ordem decrescente de probabilidade como um exemplo positivo. Mas podemos lembrar novamente a afirmação do problema de construir um sistema de recomendação, entender que a classificação binária não é o problema que estamos resolvendo e passar novamente ao problema de classificação.
No XGBoost e no LightGBM, a principal função de perda para tarefas de classificação é o LambdaMART. Se você não entrar em detalhes, a intuição por trás disso é bastante simples. Se - saída do modelo, por exemplo , então a probabilidade de o elemento terá uma classificação mais alta que o elemento será igual
A função de perda pode ser escrita da seguinte maneira.
aqui está a verdadeira probabilidade de classificação. Vamos defini-lo como 1 se 0 se e 0,5 no caso .
Um modelo de dois níveis oferece um aumento de 50% nas métricas em comparação com um modelo de nível único. A função de perda de classificação adiciona outros 10%.
Bônus: filmes relacionados
Lembre-se, nas vantagens de nossa abordagem, mencionei os vetores "livres" da fatoração matricial que podem ser usados para resolver problemas relacionados? Então, uma dessas tarefas - a busca por filmes semelhantes - decidimos.
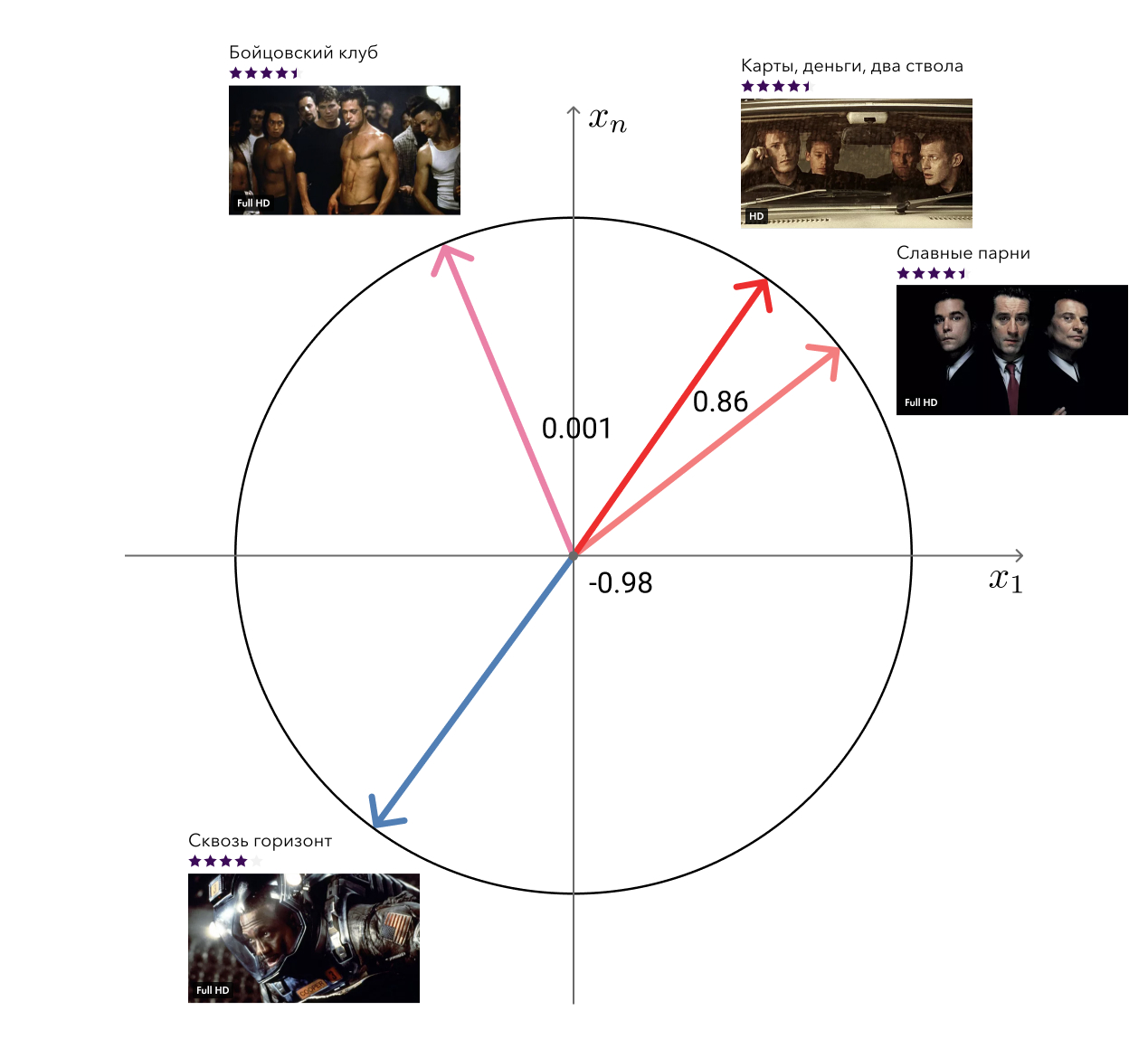
A solução para a desgraça é simples: para cada filme, pegamos seu vetor e procuramos os mais próximos na distância do cosseno. Parece bastante adequado aos olhos. O próximo nível é adicionar informações meta e usar algoritmos gráficos.

Implementação técnica
Além da parte algorítmica, quero falar um pouco sobre a implementação. O Rekko consiste em três componentes: lynch, rekko-tasks e rekko-service.
O Lynch roda em uma máquina poderosa, acorda periodicamente, prepara dados para o microsserviço e os coloca no S3.
Os microsserviços Rekko-tasks e rekko-service estão localizados no ambiente do produto Okko, junto com todos os outros microsserviços e bancos de dados. O primeiro deles monitora constantemente o S3 em busca de alterações, se houver, faz o download e as coloca em bases de compras. O segundo microsserviço usa esses resultados calculados para responder em tempo real às solicitações do usuário e calcular suas recomendações.

Os microsserviços são escritos em Python usando falcon, gunicorn e gevent e não representam nada de interessante, exceto a lógica de negócios. Como todos os outros microsserviços do ambiente do produto Okko, eles são fechados pelo balanceador.
Lynch é muito mais interessante.
O que precisa ser feito para calcular a próxima parte das recomendações para os usuários? Pelo menos:
- Baixe novos dados que apareceram desde a última recontagem;
- Processe-os;
- Fatoração da matriz do trem;
- Criar candidatos
- Reorganizar candidatos;
- Aplicar regras de negócios
- Descarregar.
Parece que não parece assustador, você pode colocar cada parte em uma função separada e simplesmente chamá-las por sua vez:
data = extract_data() data = transform_data(data) mf_model = train_mf_model(data) candidates = build_candidates(mf_model) predictions = build_predictions(content_model, candidates) upload_predictions(predictions)
Bem, tudo fez um ótimo trabalho, discordamos? Na verdade não. Mas e se a folha inteira cair em algum lugar? Bem, por exemplo, devido à falta de memória. Teremos que reiniciar tudo novamente, mesmo se já gastamos algumas horas treinando o modelo e construindo candidatos.
Bem, então vamos salvar todos os resultados intermediários em arquivos e, após a queda, verificar quais já existem, restaurar o estado e iniciar os cálculos no momento certo. De fato, essa ideia é ainda pior que a anterior. Um programa pode ser interrompido no meio da gravação em um arquivo e, embora exista, ele estará em um estado incorreto. Na melhor das hipóteses, todo o cálculo cairá; na pior das hipóteses, terminará com o resultado errado.
Ok, vamos escrever para o arquivo atômico. E retiramos cada função em uma entidade separada e indicamos as dependências entre elas. O resultado é uma cadeia de cálculos, sendo que cada elemento pode ser executado ou não.

Já não é ruim. Mas, na realidade, todos os cálculos necessários dificilmente serão descritos por uma lista. A fatoração da matriz de aprendizado exigirá não apenas dados de transação, mas também classificações de usuários, os candidatos à construção exigirão uma lista de filmes lembrados para excluí-los, o cálculo de filmes semelhantes exigirá fatoração matricial treinada e meta-informações do catálogo, e assim por diante. Nossas tarefas não são mais construídas em uma lista simplesmente conectada, mas em um gráfico direcionado sem ciclos (Gráfico Acíclico Dirigido, DAG).

O DAG é uma organização de computação extremamente popular. Existem duas estruturas principais para a construção de um DAG: Airflow e Luigi . Nós, em Okko, decidimos o último. O Luigi é desenvolvido no Spotify, está desenvolvendo-se ativamente, é completamente escrito em python, é facilmente extensível e permite que você organize cálculos com muita flexibilidade.
Uma tarefa no Luigi é definida por uma classe que herda do luigi.Task e implementa três métodos necessários: requires , luigi.Task e run . É assim que uma tarefa típica se parece:
Luigi garantirá que as tarefas sejam concluídas na ordem correta, sem exceder o consumo de recursos disponíveis. Se as tarefas puderem ser executadas em paralelo, elas serão executadas em paralelo, maximizando a utilização da CPU e minimizando o tempo geral de execução. Se alguma tarefa falhar, ele a reiniciará várias vezes e, em caso de falha, nos informará. Nesse caso, todas as tarefas que podem ser executadas serão executadas. Isso significa, por exemplo, que um erro na tarefa de classificar candidatos não impede a contagem e o upload de uma lista de filmes semelhantes.
Atualmente, o Lynch consiste em 47 tarefas únicas, produzindo cerca de 100 de suas cópias. Alguns deles estão ocupados com o trabalho direto, outros estão contando métricas e enviando-os para a nossa ferramenta Splunk BI. Lynch também envia periodicamente estatísticas básicas e relatórios sobre seu trabalho para nós por telegrama. Ele também escreve sobre erros, mas no PM.
Monitoramento, divisão e resultados

A primeira regra da Data Science: não conte a ninguém sobre salários na Data Science. A segunda regra da ciência de dados: aquilo que não pode ser medido não pode ser melhorado.
Tentamos acompanhar tudo. Antes de tudo, é claro que isso classifica métricas em dados históricos. Eles ajudam, mesmo na fase da pesquisa, a escolher o melhor modelo dentre vários e a escolher hiper parâmetros.
Para os modelos que trabalham em produção, também consideramos métricas, mas já no dia a dia. Essas métricas são bastante voláteis, mas elas podem ser ditas se o modelo de repente, por algum motivo, se degradar. Quando um novo modelo é lançado no produto, você pode deixá-lo em repouso por uma semana e garantir que as métricas não caiam. Depois disso, você pode habilitá-lo para alguns usuários, executar o teste A / B e monitorar as métricas de negócios.

Além disso, consideramos a distribuição de recomendações por gênero, país, ano, tipo etc. Isso nos permite entender a natureza atual das preferências do usuário, compará-la com dados reais de visualização e detectar erros nas regras de negócios.

Também é importante acompanhar as distribuições de todas as características usadas. Uma mudança acentuada neles pode ser causada por um erro na fonte de dados e levar a resultados imprevisíveis.
Mas, é claro, a coisa mais importante que requer muita atenção são as métricas de negócios. Como parte do sistema de recomendação, as principais métricas de negócios para nós são:
- Receita de modelos de consumo transacional e de assinatura (receita TVOD / SVOD);
- Receita média por visitante (receita média por visitante, ARPV);
- O cheque médio (preço médio por compra, APPP);
- Média de compras por usuário (APPU);
- Conversão para compra (CR para compra);
- Conversão para visualizar por assinatura (CR para assistir);
- Conversão durante o período de avaliação (CR para avaliação).
Ao mesmo tempo, analisamos separadamente as métricas das seções “Recomendações” e “Similares” e as métricas de todo o serviço como um todo, a fim de levar em consideração o efeito de redistribuição e considerar a situação de diferentes ângulos.
Pode parecer um painel comparando vários modelos:

Como eu disse no começo, comparamos não apenas modelos entre si, mas também um grupo de usuários com recomendações contra um grupo de usuários sem recomendações. Isso nos permite avaliar o efeito líquido da implementação do Rekko e entender onde estamos no momento e que margem de melhoria ainda permanece. De acordo com este teste A / B, atualmente temos:
- ARPV + 3,5%
- ARPV com margem + 5%
- APPU + 4,3%
- RC para julgamento + 2,6%
- CR para assistir + 2,5%
- APPP -1%
Os filmes em um cinema online podem ser divididos em dois grupos: novos itens e conteúdo antigo. Já sabemos como vender boas notícias. O principal objetivo das recomendações pessoais é obter o conteúdo antigo relevante para os usuários do catálogo. Isso leva a um aumento no número de compras e na subsidência do cheque médio, uma vez que esse conteúdo é naturalmente mais barato. Mas esse conteúdo também possui uma margem alta, que compensa a subsidência do cheque e aumenta a receita.
Conteúdo de assinatura mais relevante levou a um aumento da conversão durante o período de avaliação e visualização por assinatura.
Desafio Rekko
De 18 de fevereiro a 18 de abril de 2019, em conjunto com a plataforma Boosters, realizamos o Rekko Challenge, onde convidamos os participantes a criar um sistema de recomendação baseado em dados de produtos anônimos.

Espera-se que os participantes que construíram um sistema de dois níveis semelhante ao nosso estivessem no topo. Os vencedores que ocuparam o primeiro e o terceiro lugares conseguiram adicionar ao conjunto RNN. E o participante do oitavo lugar conseguiu subir nele usando apenas modelos de filtragem colaborativa.
Evgeni Smirnov, que ficou em segundo lugar na competição, escreveu um artigo onde falou sobre sua decisão.
No momento, a competição está disponível na forma de uma caixa de proteção, para que todos os interessados em sistemas de recomendação possam tentar e obter experiência útil.
Conclusão
Com este artigo, queria mostrar que os sistemas de recomendação em produção não são nada difíceis, mas divertidos e lucrativos. O principal é pensar em objetivos, não os meios para alcançá-los e medir constantemente tudo.
Em artigos futuros, falaremos ainda mais sobre a cozinha interna do Okko, portanto, não esqueça de se inscrever e curtir.