Olá colegas!
Talvez o título da publicação de hoje parecesse melhor com um ponto de interrogação - é difícil dizer. De qualquer forma, hoje queremos oferecer a você um breve tour que apresentará a biblioteca
Dask , projetada para paralelizar tarefas no Python. Esperamos retornar a esse tópico mais detalhadamente no futuro.
 Foto tirada em
Foto tirada emO Dask é, sem exagero, a ferramenta de processamento de dados mais revolucionária que já encontrei. Se você gosta de
Pandas e Numpy , mas às vezes não consegue lidar com dados que não cabem na RAM, o Dask é exatamente o que você precisa. O Dask suporta o quadro de dados do Pandas e as estruturas de dados Numpy (matrizes). O Dask pode ser executado no computador local ou em escala e, em seguida, no cluster. Em essência, você escreve o código apenas uma vez e, em seguida, escolhe se deseja usá-lo na máquina local ou implantá-lo em um cluster de muitos nós, usando a sintaxe Python mais comum para tudo isso. O recurso em si é ótimo, mas decidi escrever este artigo apenas para enfatizar: todo cientista de dados (pelo menos usando Python) deve usar o Dask. Do meu ponto de vista, a mágica do Dask é que, ao minimizar o código, você pode paralelizar usando o poder de computação que já está disponível, por exemplo, no meu laptop. Com o processamento paralelo de dados, o programa é executado mais rapidamente, você precisa esperar menos e, consequentemente, mais tempo resta para a análise. Em particular, neste artigo, falaremos sobre o objeto
dask.delayed e como ele se encaixa no fluxo de tarefas da ciência de dados.
Apresentando o Dask
Como uma introdução ao Dask, aqui estão alguns exemplos apenas para lhe dar uma idéia de sua sintaxe completamente discreta e natural. A conclusão mais importante que quero sugerir neste caso é que o conhecimento que você já possui será suficiente para funcionar; Você não precisa aprender uma nova ferramenta de big data como o Hadoop ou Spark.
O Dask oferece 3 coleções paralelas nas quais é possível armazenar dados que excedem o tamanho da RAM, nomeadamente quadros de dados, bolsas e matrizes. Em cada um desses tipos de coleções, você pode armazenar dados segmentando-os entre RAM e disco rígido, além de distribuir dados entre vários nós em um cluster.
Um Dask DataFrame consiste em quadros de dados fragmentados, como os do Pandas, permitindo que você use um subconjunto dos recursos da sintaxe de consulta do Pandas. Abaixo está um código de exemplo que baixa todos os arquivos CSV para 2018, analisa um campo com um carimbo de data e hora e inicia uma solicitação do Pandas:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Exemplo do Dask DataframeNo Dask Bag, você pode armazenar e processar coleções de objetos pitônicos que não cabem na memória. O Dask Bag é ótimo para processar logs e coleções de documentos no formato json. Neste exemplo de código, todos os arquivos json para 2018 são carregados na estrutura de dados do Dask Bag, cada registro json é analisado e os dados do usuário são filtrados usando a função lambda:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
Exemplo do Dask BagA estrutura de dados do Dask Arrays suporta fatias no estilo Numpy. No exemplo a seguir, um conjunto de dados HDF5 é dividido em blocos de dimensão (5000, 5000):
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Exemplo de matriz do DaskProcessamento paralelo no Dask
Outro título igualmente preciso para esta seção seria "Morte de um ciclo seqüencial". De vez em quando, encontro um padrão comum: itere sobre a lista de elementos e execute o método Python com cada elemento, mas com argumentos de entrada diferentes. Os cenários comuns de processamento de dados incluem o cálculo de agregados de recursos para cada cliente ou a agregação de eventos do log para cada aluno. Em vez de aplicar uma função a cada argumento em um loop seqüencial, o objeto Dask Delayed permite processar muitos elementos em paralelo. Ao trabalhar com o Dask atrasado, todas as chamadas de função são enfileiradas, colocadas no gráfico de execução, após o que planejam ser processadas.
Eu sempre tive um pouco de preguiça de escrever meu próprio mecanismo de encadeamento ou usar assíncrono, então nem mostrarei exemplos semelhantes para comparação. Com o Dask, você não pode alterar nem a sintaxe nem o estilo de programação! Você só precisa anotar ou agrupar o método, que será executado em paralelo com
@dask.delayed e chamar o método computacional após a execução do código do loop.
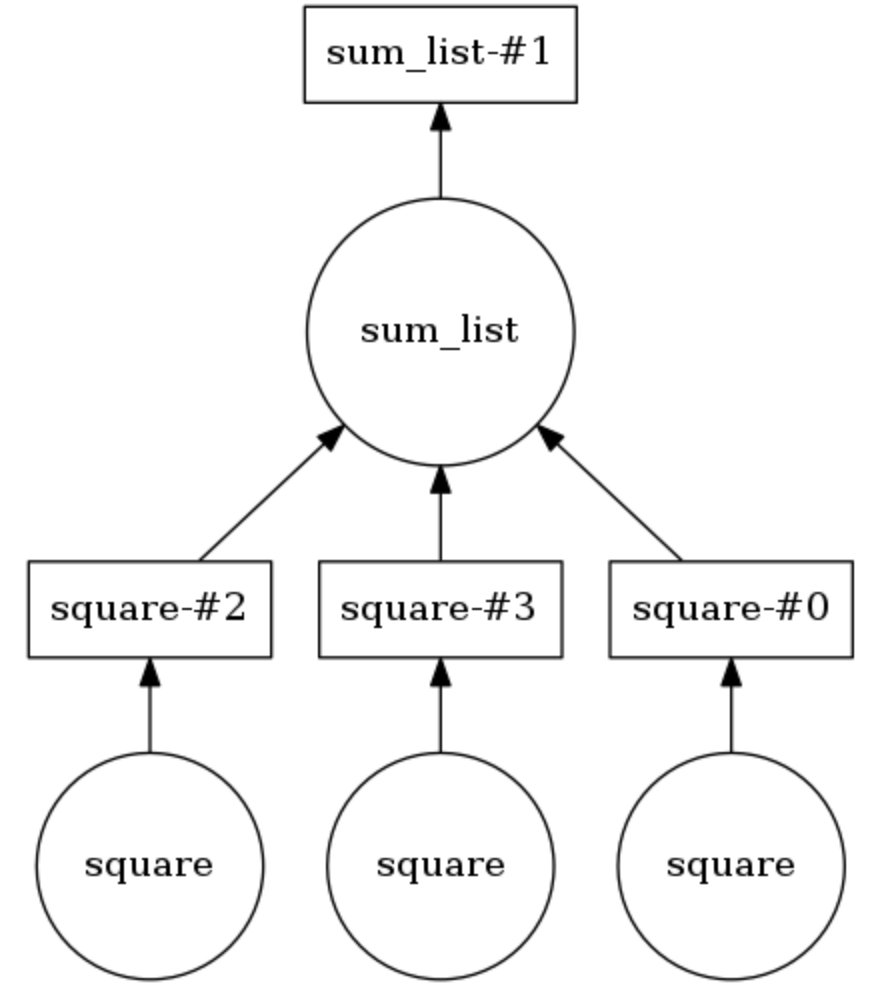
Exemplo de gráfico de computação dask
No exemplo abaixo, os dois métodos são anotados em
@dask.delayed . Três números são armazenados em uma lista, eles precisam ser elevados ao quadrado e depois somados. O Dask constrói um gráfico computacional que fornece execução paralela do método quadrático, após o qual o resultado dessa operação é passado para o método
sum_list . O gráfico computacional pode ser exibido chamando
calling .visualize() .
Calling .compute() executa o gráfico de computação. Como resulta da
conclusão , os itens da lista são processados não em ordem, mas em paralelo.
O número de threads pode ser definido (por exemplo,
dask.set_options( pool=ThreadPool(10) ) e também podem ser facilmente trocados para usar processos no seu laptop ou PC (por exemplo,
dask.config.set( scheduler='processes' ) .
Então, demonstrei como será trivial adicionar processamento paralelo de tarefas a um projeto do campo de Ciência de Dados usando o Dask. Pouco antes de escrever este artigo, usei o Dask para dividir os dados sobre fluxos de cliques do usuário (histórico de visitas) em sessões de 40 minutos e, em seguida, agregar os atributos de cada usuário para cluster adicional. Conte-nos como você usou o Dask!