O QlikView e seu irmão mais novo, QlikSense, são maravilhosas ferramentas de BI bastante populares em nosso país e no exterior. Muitas vezes, esses sistemas salvam resultados "intermediários" de seu trabalho - dados que visualizam seus "painéis" - nos chamados "arquivos QVD". Geralmente, os arquivos QVD são usados como armazenamento principal em processos ETL de vários estágios, criados com base no Qlik. E então alguns (por exemplo, eu - eu lido com engenharia de dados na empresa) têm uma pergunta - é possível e como usar esses dados sem o QlikView / QlikSense? Ou outro - e o que existe e é correto que tenha sido contado?
QVD é um formato de arquivo otimizado para o QlikView / QlikSense (a leitura das informações de gravação desses aplicativos nos arquivos desse formato é muito mais rápida do que nos arquivos de qualquer outro formato). A estrutura deste arquivo não é documentada e é coberta por uma "melancolia de propriedade"; praticamente não há aplicativos que possam trabalhar com esses arquivos (leia e, mais ainda, escreva). Nesta série de artigos, compartilharei minha experiência e conhecimento prático adquirido: sei como o QVD funciona, posso ler e escrever direta e rapidamente nele.
Quem estará interessado nessas informações: em primeiro lugar, aqueles que trabalham com o QlikView / QlikSense, bem como aqueles que (como eu) gostariam de usar os dados armazenados nos arquivos QVD. E, claro, para todos curiosos.
Tudo o que está escrito nesta série é baseado em minha experiência pessoal, que, é claro, não é uma "documentação" ou uma "garantia" (que seus arquivos serão exatamente os mesmos que eu descrevi. Ou serão para sempre ) Também não posso garantir que descobri todos os casos - com certeza pode haver arquivos que conterão algo que não foi descrito por mim (apenas porque não encontrei essas opções). No entanto, devo observar que as informações são verificadas em um grande (várias centenas) de arquivos criados por pessoas diferentes de sistemas diferentes usando versões diferentes do QlikView / QlikSense.
E um pouco sobre como eu fiz isso: comecei com um simples - um pequeno exemplo embutido salvo no QVD. Além disso - a análise do arquivo binário, esforços cerebrais, testes e erros. No futuro (falarei sobre isso com mais detalhes na conclusão da série), consegui ler e gravar arquivos QVD de tamanho médio (centenas de gigabytes) com bastante eficiência. O ponto de partida da minha jornada no mundo QVD foi este GitHub , muito obrigado ao autor (tentei entrar em contato com ele - não responde).
Qual era meu objetivo (além da curiosidade e do desejo de verificar a correção dos dados com os quais o QlikView / QlikSense trabalha), eu precisava ler o conteúdo do arquivo QVD, ou seja, recrie uma tabela relacional baseada nela. Por outro lado, carregue os dados da tabela relacional no QVD para que o QlikView possa carregá-los corretamente.
Como vejo esta série de artigos
- introdução, estrutura de arquivos, metadados (este artigo)
- armazenamento de informações da coluna
- armazenamento de informações de linha, realizações, planos
Estrutura de arquivo
O arquivo QVD é criado pelo script QlikView / QlikSense no processo de carregamento de dados na memória do aplicativo (o resultado do comando STORE) e corresponde a uma tabela (relacional) QlikView / QlikSense. Consiste em duas partes
- textual (metadados) e
- binário (colunas e linhas)
Os metadados são apresentados como XML (um exemplo será dado abaixo), a parte binária começa imediatamente após o texto e consiste em dois blocos
- valores exclusivos de todas as colunas (tabela de origem)
- linhas (tabela de origem) que fazem referência a valores exclusivos da coluna
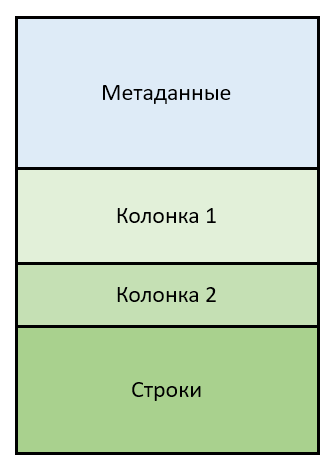
Assim, para uma tabela de N colunas, o arquivo conterá N + 1 blocos binários. Todas as partes do arquivo são “grudadas” e vão uma após a outra sem preenchimentos e “hastes”.
O arquivo QVD contém muitos metadados - "dados sobre dados". É quase auto-suficiente, julgue por si mesmo, aqui está uma pequena lista do que há nos metadados (descreverei-os com mais detalhes abaixo):
- versão do software que gerou o arquivo
- data e hora de criação do arquivo
- Arquivo QlikView / QlikSense, cujo script levou à criação do arquivo
- código fonte do script que gerou o arquivo QVD
- nome da tabela
- informações da coluna (nomes, tipos, quantidades de valores exclusivos)
- contagem de linhas
Os metadados são armazenados em um arquivo no formato de texto e podem ser vistos em qualquer programa que possa mostrar o arquivo no formato de texto (bem, quase todos ... em um que não tenha medo de arquivos grandes). Pessoalmente, olho para as meta-informações usando mais - é bastante conveniente.
Na apresentação a seguir, usarei a tabela de teste (uso a sintaxe do QlikView, mas acho que será fácil conjeturar):
SET NULLINTERPRET =<sym>; tab1: LOAD * INLINE [ ID, NAME 123.12,"Pete" 124,12/31/2018 -2,"Vasya" 1,"John" <sym>,"None" ];
Vou dar como exemplo os metadados para esta placa
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <QvdTableHeader> <QvBuildNo>7314</QvBuildNo> <CreatorDoc></CreatorDoc> <CreateUtcTime>2019-04-03 06:24:33</CreateUtcTime> <SourceCreateUtcTime></SourceCreateUtcTime> <SourceFileUtcTime></SourceFileUtcTime> <SourceFileSize>-1</SourceFileSize> <StaleUtcTime></StaleUtcTime> <TableName>tab1</TableName> <Fields> <QvdFieldHeader> <FieldName>ID</FieldName> <BitOffset>0</BitOffset> <BitWidth>3</BitWidth> <Bias>-2</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>4</NoOfSymbols> <Offset>0</Offset> <Length>40</Length> </QvdFieldHeader> <QvdFieldHeader> <FieldName>NAME</FieldName> <BitOffset>3</BitOffset> <BitWidth>5</BitWidth> <Bias>0</Bias> <NumberFormat> <Type>0</Type> <nDec>0</nDec> <UseThou>0</UseThou> <Fmt></Fmt> <Dec></Dec> <Thou></Thou> </NumberFormat> <NoOfSymbols>5</NoOfSymbols> <Offset>40</Offset> <Length>37</Length> </QvdFieldHeader> </Fields> <Compression></Compression> <RecordByteSize>1</RecordByteSize> <NoOfRecords>5</NoOfRecords> <Offset>77</Offset> <Length>5</Length> </QvdTableHeader>
Minha experiência com QVD mostra que a estrutura XML não muda de arquivo para arquivo.
Vou comentar os elementos de metadados mais importantes.
QvBuildNo
O número da compilação do aplicativo QlikView / QlikSense que gerou o arquivo QVD.
Creatordoc
Como regra, ele contém o nome do arquivo QVW, cujo script gerou o arquivo QVD. Este exemplo está em branco, possivelmente porque a Personal Edition foi usada.
CreateUtcTime
Hora de criação do arquivo QVD.
SourceCreateUtcTime, SourceFileUtcTime, SourceFileSize, StaleUtcTime
Não vi os arquivos nos quais esses campos seriam preenchidos. Penso que talvez estejam faltando algumas configurações?
Tablename
O nome da tabela no QlikView (veja o exemplo acima).
A propósito, as palavras "campo" e "coluna" são sinônimos para mim, não se assuste se eu usar os dois (vou tentar não fazer isso, mas ainda assim ...).
As informações sobre cada campo são armazenadas no QVD sobre
Nome do campo
O nome do campo (novamente em termos de QlikView, ou seja, levando em consideração "AS")
BitOffset, BitWidth, Polarização
Por enquanto, vamos pular - essas são informações para "decodificar strings", que consideraremos na terceira parte quando ele lidar com strings.
Tipo, nDec, UseThou, Fmt, Dec, Mil
Bem concebido (a julgar pelos nomes), mas absolutamente inútil do ponto de vista da obtenção das informações sobre minha meta (para mais detalhes, veja a segunda parte, onde falaremos sobre colunas). Por que é inútil? - a tag "Type" não se correlaciona com o tipo de dados armazenados na parte binária. É impossível restaurar o tipo de coluna a partir dele (parece que poderia ser mais fácil, existe uma tag Type!). Em 90% dos casos, o valor dessa tag será a string UNKNOWN ...
Nos metadados sobre as colunas ainda existem esses dados (nos metadados do exemplo, isso não ocorre, aparentemente, devido ao tamanho pequeno)
<Comment></Comment> <Tags> <String>$numeric</String> <String>$integer</String> </Tags>
O comentário não precisa de comentários (a propósito, os arquivos com os quais trabalhei estão 100% vazios ...).
Tags também são informações inúteis (do ponto de vista da restauração da estrutura da tabela). Mas a partir dele, você pode adivinhar aproximadamente que tipo de informação é armazenada na coluna. Vou abordar a digitação com mais detalhes na segunda parte - quando falarei sobre colunas: isso é importante. Mas um pouco mais complicado do que eu gostaria.
NoOfSymbols
O número de entradas na parte binária relacionada a esta coluna. Como vemos, em nosso exemplo, são 5. Informações muito importantes para descriptografia.
Deslocamento
O deslocamento do bloco de dados desta coluna em bytes em relação ao início da parte binária do arquivo. Também é muito importante.
Comprimento
O comprimento de todo o bloco de dados desta coluna em bytes. Observe que a representação binária de um elemento da coluna (célula da tabela) geralmente possui um comprimento variável (linha, por exemplo); portanto, o comprimento não pode ser calculado; você pode usar apenas essa tag (sorriso).
Compressão
Nunca preenchido (nos dados com os quais trabalhei). Talvez não estejamos usando esta opção ...
RecordByteSize
O tamanho da entrada da linha em bytes. Todas as strings são representadas no bloco binário de strings como um índice de bits (mais sobre isso na terceira parte), um índice de bits consiste em linhas do mesmo comprimento.
NoOfRecords
O número de linhas (no índice de bits e na tabela de origem).
Deslocamento
O deslocamento do índice de bits (bloco com informações da string) em bytes em relação ao início da parte binária do arquivo.
Comprimento
O comprimento do índice de bits em bytes.
Nos metadados sobre cadeias ainda existem esses dados (novamente - um pequeno exemplo não permite que você veja tudo, mas permite que você entenda o complexo)
<Lineage> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>LinkTable: LOAD SOURCE_NAME & '_' & SOURCE_ID as SYSKEY, HID_PARTY;SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Data Source=XXXX;Extended Properties=""</Discriminator> <Statement>SQL SELECT * FROM UNITED_VIEW</Statement> </LineageInfo> <LineageInfo> <Discriminator>STORE - \\xxx.ru\mfs\SPECIAL\Qlikview\QVData\LinkTable.qvd (qvd)</Discriminator> <Statement></Statement> </LineageInfo> </Lineage> <Comment></Comment>
Eu não entendo muito o assunto aqui, é bastante compreensível (os SELECTs originais que geraram a tabela no QlikView), ainda não descobri ainda (às vezes eles dobram) ... (exceto por um - 100% sem comentários (sorriso)) .
Resumir
- O arquivo QVD é independente (ou seja, pode ser analisado isoladamente de outros dados)
- O arquivo QVD consiste em partes de texto (metadados) e binárias (colunas e índice de bits)
- metadados são XML com semântica clara
Um leitor curioso tem o direito de perguntar aqui: "Até agora nada de novo foi ouvido, tudo o que foi dito acima pode ser capturado e exibido no cabeçalho XML do arquivo QVD ... Isso já foi escrito sobre isso muitas vezes em diferentes Internet, qual é a novidade?" Isso mesmo - a primeira parte é quase inteiramente dedicada aos metadados. Mas este não é o fim.
O que vem a seguir - na próxima parte, examinaremos em detalhes a estrutura da parte binária do arquivo QVD que contém informações sobre as colunas (valores exclusivos de todas as colunas da tabela).