Se você já trabalhou com linguagens de baixo nível como C ou C ++, provavelmente já ouviu falar sobre ponteiros. Eles permitem aumentar significativamente a eficácia de diferentes partes do código. Mas eles também podem confundir iniciantes - e até desenvolvedores experientes - e levar a erros de gerenciamento de memória. Existem ponteiros no Python, posso de alguma forma imitá-los?
Ponteiros são amplamente utilizados em C e C ++. De fato, são variáveis que contêm os endereços de memória nos quais outras variáveis estão localizadas. Para atualizar os ponteiros, leia esta
resenha .
Graças a este artigo, você entenderá melhor o modelo de objeto no Python e descobrirá por que os ponteiros não existem realmente nessa linguagem. Caso você precise simular o comportamento dos ponteiros, aprenderá como imitá-los sem o pesadelo que acompanha o gerenciamento de memória.
Com este artigo, você:
- Saiba por que o Python não tem ponteiros.
- Aprenda a diferença entre variáveis C e nomes no Python.
- Aprenda a emular ponteiros em Python.
- Use
ctypes experimentar ponteiros reais.
Nota : Aqui, o termo “Python” é aplicado à implementação do Python em C, conhecida como CPython. Todas as discussões sobre o dispositivo de idioma são válidas para o CPython 3.7, mas podem não corresponder às iterações subsequentes.
Por que não existem ponteiros no Python?
Eu não sei Os ponteiros podem existir nativamente no Python? Provavelmente, mas aparentemente, os indicadores contradizem o conceito de
Zen de Python , porque provocam mudanças implícitas em vez de explícitas. Os ponteiros geralmente são bastante complexos, especialmente para iniciantes. Além disso, eles o levam a tomar decisões malsucedidas ou a fazer algo realmente perigoso, como ler de uma área de memória, onde você não deveria ter lido.
O Python tenta abstrair os detalhes da implementação do usuário, como um endereço de memória. Geralmente, nesse idioma, a ênfase está na usabilidade, não na velocidade. Portanto, os ponteiros no Python não fazem muito sentido. Mas não se preocupe, o idioma padrão fornece alguns dos benefícios do uso de ponteiros.
Para entender os ponteiros no Python, vamos examinar brevemente os recursos da implementação da linguagem. Em particular, você precisa entender:
- O que são objetos mutáveis e imutáveis.
- Como as variáveis / nomes são organizados em Python.
Segure seus endereços de memória, vamos lá!
Objetos em Python
Tudo em Python é um objeto. Por exemplo, abra o REPL e veja como
isinstance() :
>>> isinstance(1, object) True >>> isinstance(list(), object) True >>> isinstance(True, object) True >>> def foo(): ... pass ... >>> isinstance(foo, object) True
Este código demonstra que tudo no Python é realmente um objeto. Cada objeto contém pelo menos três tipos de dados:
- Contador de referência.
- Tipo
- Valor.
Um contador de referência é usado para gerenciar a memória. Detalhes sobre esse gerenciamento estão escritos em
Gerenciamento de memória em Python . O tipo é usado no nível CPython para fornecer segurança de tipo durante o tempo de execução. E value é o valor real associado ao objeto.
Mas nem todos os objetos são iguais. Há uma diferença importante: os objetos são mutáveis e imutáveis. Entender essa distinção entre tipos de objetos o ajudará a entender melhor a primeira camada da cebola chamada "ponteiros em Python".
Objetos mutáveis e imutáveis
Existem dois tipos de objetos no Python:
- Objetos imutáveis (não podem ser alterados);
- Objetos modificáveis (sujeitos a alterações).
Reconhecer essa diferença é a primeira chave para viajar pelo mundo dos ponteiros em Python. Aqui está uma caracterização da imutabilidade de alguns tipos populares:
Como você pode ver, muitos dos tipos primitivos comumente usados são imutáveis. Você pode verificar isso escrevendo algum código Python. Você precisará de duas ferramentas da biblioteca padrão:
id() retorna o endereço de memória do objeto;
is retorna True se e somente se dois objetos tiverem o mesmo endereço de memória.
Você pode executar esse código em um ambiente REPL:
>>> x = 5 >>> id(x) 94529957049376
Aqui, definimos a variável
x como
5 . Se você tentar alterar o valor usando adição, você receberá um novo objeto:
>>> x += 1 >>> x 6 >>> id(x) 94529957049408
Embora possa parecer que esse código simplesmente mude o valor de
x , na realidade você está recebendo um
novo objeto como resposta.
O tipo
str também é imutável:
>>> s = "real_python" >>> id(s) 140637819584048 >>> s += "_rocks" >>> s 'real_python_rocks' >>> id(s) 140637819609424
E, neste caso,
s após a operação
+= obtém um endereço de memória
diferente .
Bônus : o operador
+= traduz em várias chamadas de método.
Para alguns objetos, como uma lista,
+= converte em
__iadd__() (anexo local). Ele será alterado e retornará o mesmo ID. No entanto,
str e
int não possuem esses métodos e, como resultado,
__add__() será chamado em vez de
__iadd__() .
Veja a
documentação do modelo de dados Python
para mais detalhes .Quando tentamos alterar diretamente o valor da string de
s obtemos um erro:
>>> s[0] = "R"
Rastreamento de retorno (as últimas chamadas são exibidas por último):
File "<stdin>", line 1, in <mdule> TypeError: 'str' object does not support item assignment
O código acima trava e o Python relata que
str não suporta essa alteração, o que corresponde à definição de imutabilidade do tipo
str .
Compare com um objeto mutável, por exemplo, com uma lista:
>>> my_list = [1, 2, 3] >>> id(my_list) 140637819575368 >>> my_list.append(4) >>> my_list [1, 2, 3, 4] >>> id(my_list) 140637819575368
Este código demonstra a principal diferença entre os dois tipos de objetos. Inicialmente,
my_list tem um ID. Mesmo depois de adicionar
4 à lista,
my_list ainda tem
o mesmo ID. O motivo é que a
list tipos é mutável.
Aqui está outra demonstração da mutabilidade da lista usando a atribuição:
>>> my_list[0] = 0 >>> my_list [0, 2, 3, 4] >>> id(my_list) 140637819575368
Nesse código, alteramos
my_list e o definimos como
0 como o primeiro elemento. No entanto, a lista manteve o mesmo ID após esta operação. O próximo passo no nosso caminho para
aprender Python será explorar seu ecossistema.
Lidamos com variáveis
Variáveis em Python são fundamentalmente diferentes das variáveis em C e C ++. Essencialmente, eles simplesmente não existem no Python.
Em vez de variáveis, existem nomes .
Pode parecer pedante, e na maioria das vezes é. Na maioria das vezes, você pode tomar nomes em Python como variáveis, mas precisa entender a diferença. Isso é especialmente importante quando você estuda um tópico tão difícil como ponteiros.
Para facilitar a compreensão, vamos ver como as variáveis funcionam em C, o que elas representam e depois comparar com o trabalho dos nomes no Python.
Variáveis em C
Pegue o código que define a variável
x :
int x = 2337;
A execução desta linha curta passa por várias etapas diferentes:
- Alocando memória suficiente para um número.
- Atribuição de
2337 para este local de memória.
- O mapeamento que
x indica esse valor.
Uma memória simplificada pode ser assim:

Aqui, a variável
x tem um endereço falso de
0x7f1 e um valor de
2337 . Se você desejar alterar posteriormente o valor de
x , faça o seguinte:
x = 2338;
Este código define a variável
x novo valor de
2338 , substituindo assim o valor
anterior . Isso significa que a variável
x mutável . Esquema de memória atualizado para o novo valor:

Observe que a localização de
x não mudou, apenas o valor em si. Isso é importante. Isso nos diz que
x é
um lugar na memória , e não apenas um nome.
Você também pode considerar esse problema como parte do conceito de propriedade. Por um lado,
x possui um lugar na memória. Primeiro,
x é uma caixa vazia que pode conter apenas um número inteiro, na qual valores inteiros podem ser armazenados.
Ao atribuir
x algum valor, você o coloca em uma caixa que pertence a
x . Se você deseja introduzir uma nova variável
y , você pode adicionar esta linha:
int y = x;
Esse código cria uma nova caixa chamada
y e copia o valor de
x para ele. Agora o circuito de memória fica assim:

Observe o novo local
y -
0x7f5 . Embora o valor
x sido copiado para
x , a variável
y possui um novo endereço na memória. Portanto, você pode substituir o valor de
y sem afetar
x :
y = 2339;
Agora o circuito de memória fica assim:

Repito: você alterou o valor de
y , mas não o local. Além disso, você não afetou a variável original
x .
Com nomes em Python, a situação é completamente diferente.
Nomes em Python
Não há variáveis no Python, nomes. Você pode usar o termo "variáveis" a seu critério, no entanto, é importante saber a diferença entre variáveis e nomes.
Vamos pegar o código equivalente do exemplo C acima e escrever em Python:
>>> x = 2337
Como em C, o código passa por várias etapas separadas durante a execução disso:
- PyObject é criado.
- O número do PyObject recebe um código de tipo.
2337 atribuído um valor para PyObject.
- O nome
x é criado. x aponta para o novo PyObject.- A contagem de referência do PyObject é incrementada em 1.
Nota :
PyObject não é o mesmo que um objeto em Python, esta entidade é específica para CPython e representa a estrutura básica de todos os objetos Python.
PyObject é definido como uma estrutura C, portanto, se você se pergunta por que não pode chamar diretamente o tipo de código ou o contador de referência, o motivo é que você não tem acesso direto às estruturas.
Chamar métodos como
sys.getrefcount () pode ajudar a obter algum tipo de material interno.
Se falamos de memória, pode ser assim:

Aqui, o circuito de memória é muito diferente do circuito em C mostrado acima. Em vez de ter
x um bloco de memória que armazena o valor
2337 , um objeto Python recém-criado possui a memória em que
2337 mora. O nome do Python
x não possui diretamente
nenhum endereço na memória, assim como uma variável C possui uma célula estática.
Se você deseja atribuir
x novo valor, tente este código:
>>> x = 2338
O comportamento do sistema será diferente do que acontece em C, mas não será muito diferente do vínculo original no Python.
Neste código:
- Um novo PyObject é criado.
- O número do PyObject recebe um código de tipo.
2 atribuído um valor para PyObject.
x aponta para o novo PyObject.
- A contagem de referência do novo PyObject é incrementada em 1.
- A contagem de referência do antigo PyObject é reduzida em 1.
Agora o circuito de memória fica assim:
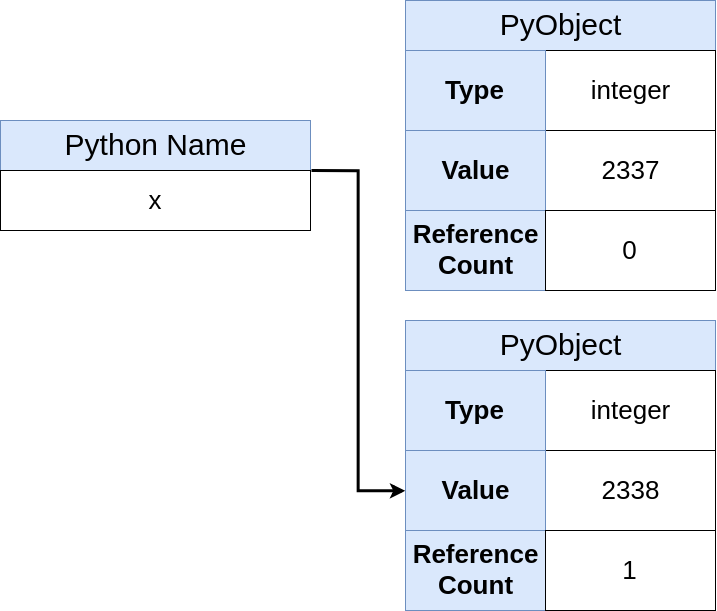
Esta ilustração demonstra que
x aponta para uma referência a um objeto e não possui a área de memória como antes. Você também vê que o comando
x = 2338 não é uma atribuição, mas uma ligação do nome
x ao link.
Além disso, o objeto anterior (contendo o valor
2337 ) agora está na memória com uma contagem de referência de 0 e será removido
pelo coletor de lixo .
Você pode inserir um novo nome
y , como no exemplo C:
>>> y = x
Um novo nome aparecerá na memória, mas não necessariamente um novo objeto:
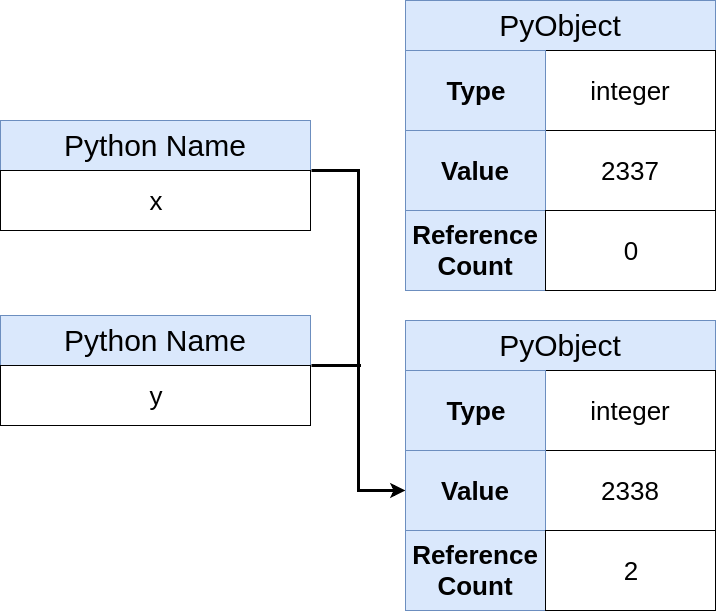
Agora você vê que um novo objeto Python
não foi criado, apenas um novo nome
foi criado que aponta para o mesmo objeto. Além disso, o contador de referência do objeto aumentou em 1. Você pode verificar a equivalência da identidade dos objetos para confirmar sua identidade:
>>> y is x True
Este código mostra que
y são um objeto. Mas não se engane:
y ainda é imutável. Por exemplo, você pode executar uma operação de adição com
y :
>>> y += 1 >>> y is x False
Após a adição ser chamada, você retornará um novo objeto Python. Agora a memória fica assim:
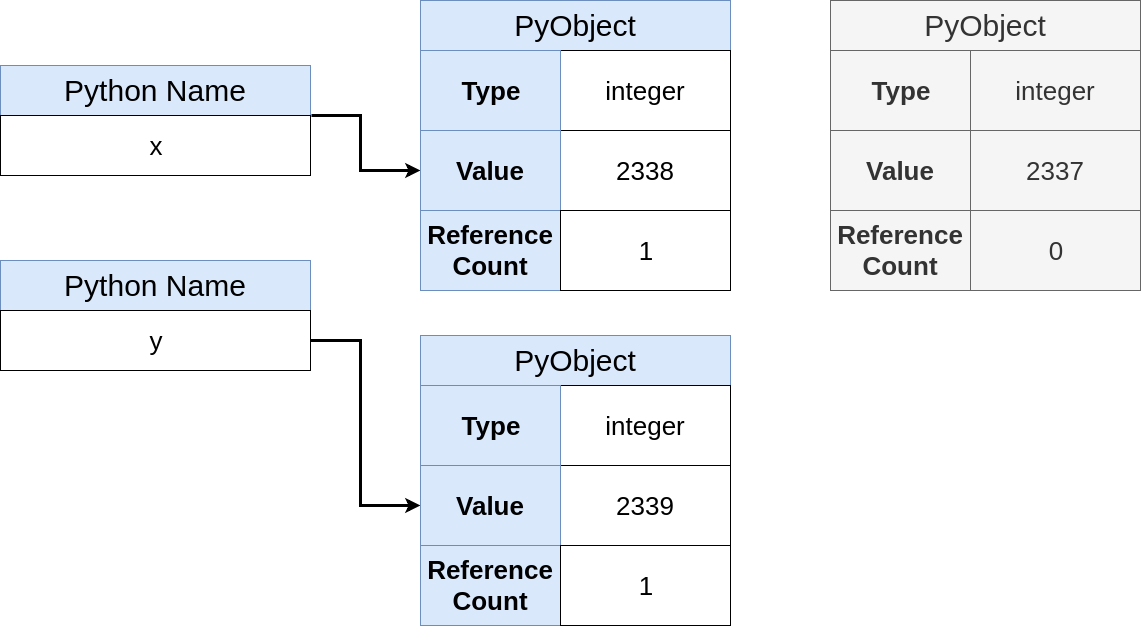
Um novo objeto foi criado e
y agora aponta para ele. É curioso que obteríamos exatamente o mesmo estado final se
2339 y diretamente a
2339 :
>>> y = 2339
Após essa expressão, obtemos um estado final de memória, como na operação de adição. Deixe-me lembrá-lo de que no Python você não atribui variáveis, mas vincula nomes aos links.
Sobre estagiários em Python
Agora você entende como novos objetos são criados no Python e como os nomes são anexados a eles. É hora de falar sobre objetos internados.
Temos este código Python:
>>> x = 1000 >>> y = 1000 >>> x is y True
Como antes,
x e
y são nomes apontando para o mesmo objeto Python. Mas esse objeto que contém o valor
1000 nem sempre pode ter o mesmo endereço de memória. Por exemplo, se você somar dois números e obter 1000, receberá outro endereço:
>>> x = 1000 >>> y = 499 + 501 >>> x is y False
Desta vez, a cadeia
x is y retorna
False . Se você está envergonhado, não se preocupe. Aqui está o que acontece quando esse código é executado:
- Um objeto Python é criado (
1000 ).
- É dado o nome
x .
- Um objeto Python é criado (
499 ).
- Um objeto Python é criado (
501 ).
- Esses dois objetos se somam.
- Um novo objeto Python é criado (
1000 ).
- Ele recebe o nome
y .
Explicações técnicas : As etapas descritas ocorrem apenas quando esse código é executado dentro do REPL. Se você pegar o exemplo acima, cole-o no arquivo e execute-o, então a linha
x is y retornará
True .
O motivo é o raciocínio rápido do compilador CPython, que tenta executar
otimizações de olho mágico que ajudam a salvar as etapas de execução de código o máximo possível. Detalhes podem ser encontrados no
código-fonte do otimizador de peyphole CPython .
Mas isso não é um desperdício? Bem, sim, mas você paga esse preço por todos os grandes benefícios do Python. Você não precisa pensar em excluir esses objetos intermediários e nem precisa saber sobre a existência deles! A piada é que essas operações são executadas relativamente rapidamente e você não saberia sobre elas até aquele momento.
Os criadores do Python sabiamente perceberam essa sobrecarga e decidiram fazer várias otimizações. O resultado é um comportamento que pode surpreender os iniciantes:
>>> x = 20 >>> y = 19 + 1 >>> x is y True
Neste exemplo, o código é quase o mesmo que acima, exceto que obtemos
True . É tudo sobre objetos internados. O Python pré-cria um subconjunto específico de objetos na memória e os armazena no espaço de nomes global para uso diário.
Quais objetos dependem da implementação do Python? No CPython 3.7, os internos são:
- Inteiros que variam de
-5 a 256 .
- Sequências contendo apenas letras ASCII, números ou sublinhados.
Isso ocorre porque essas variáveis são frequentemente usadas em muitos programas. Internando, o Python impede a alocação de memória para objetos persistentes.
Linhas com tamanho inferior a 20 caracteres e contendo letras, números ou sublinhados ASCII serão internadas porque devem ser usadas como identificadores:
>>> s1 = "realpython" >>> id(s1) 140696485006960 >>> s2 = "realpython" >>> id(s2) 140696485006960 >>> s1 is s2 True
Aqui
s1 e
s2 apontam para o mesmo endereço na memória. Se não inserirmos uma letra, número ou sublinhado ASCII, obteremos um resultado diferente:
>>> s1 = "Real Python!" >>> s2 = "Real Python!" >>> s1 is s2 False
Este exemplo usa um ponto de exclamação, portanto, as seqüências de caracteres não são internadas e são objetos diferentes na memória.
Bônus : se você deseja que esses objetos se refiram ao mesmo objeto interno, você pode usar
sys.intern() . Uma maneira de usar esse recurso é descrita na documentação:
A internação de strings é útil para um ligeiro aumento no desempenho da pesquisa no dicionário: se as chaves no dicionário e a chave a serem pesquisadas forem internadas, a comparação de chaves (após o hash) pode ser feita comparando ponteiros em vez de strings. ( Fonte )
Os internos frequentemente confundem os programadores. Lembre-se de que, se você começar a duvidar, sempre poderá usar
id() e determinar a equivalência dos objetos.
Emulação de ponteiro Python
O fato de os ponteiros estarem ausentes nativamente no Python não significa que você não pode tirar proveito dos ponteiros. Na verdade, existem várias maneiras de emular ponteiros no Python. Aqui nós olhamos para dois deles:
- Use como ponteiros para tipos mutáveis.
- Usando objetos Python especialmente preparados.
Use como ponteiros do tipo mutável
Você já sabe o que são tipos mutáveis. É graças à sua mutabilidade que podemos imitar o comportamento dos ponteiros. Digamos que você precise replicar este código:
void add_one(int *x) { *x += 1; }
Este código leva um ponteiro para um número (
*x ) e incrementa o valor em 1. Aqui está a função principal para executar o código:
No fragmento acima, atribuímos
y a
2337 ,
2337 o valor atual, aumentamos em 1 e depois exibimos um novo valor. O seguinte aparece na tela:
y = 2337 y = 2338
Uma maneira de replicar esse comportamento no Python é usar um tipo mutável. Por exemplo, aplique uma lista e altere o primeiro elemento:
>>> def add_one(x): ... x[0] += 1 ... >>> y = [2337] >>> add_one(y) >>> y[0] 2338
Aqui
add_one(x) se refere ao primeiro elemento e aumenta seu valor em 1. O uso da lista significa que, como resultado, obtemos o valor alterado. Então, existem indicadores em Python? Não. O comportamento descrito tornou-se possível porque a lista é do tipo mutável. Se você tentar usar uma tupla, você receberá um erro:
>>> z = (2337,) >>> add_one(z)
Rastreamento de retorno (as chamadas mais recentes duram por último):
File "<stdin>", line 1, in <module> File "<stdin>", line 2, in add_one TypeError: 'tuple' object does not support item assignment
Este código demonstra a imutabilidade da tupla, portanto, não suporta a atribuição de elementos.
list não
list o único tipo mutável; ponteiros de peças também são emulados usando
dict .
Suponha que você tenha um aplicativo que rastreie a ocorrência de eventos interessantes. Isso pode ser feito criando um dicionário e usando um de seus elementos como um contador:
>>> counters = {"func_calls": 0} >>> def bar(): ... counters["func_calls"] += 1 ... >>> def foo(): ... counters["func_calls"] += 1 ... bar() ... >>> foo() >>> counters["func_calls"] 2
Neste exemplo, o dicionário usa contadores para rastrear o número de chamadas de função. Após chamar
foo() contador aumentou 2, conforme o esperado. E tudo graças à
dict .
Não se esqueça, isso é apenas uma
emulação do comportamento do ponteiro, não tem nada a ver com ponteiros reais em C e C ++. Podemos dizer que essas operações são mais caras do que se fossem executadas em C ou C ++.
Usando objetos Python
dict é uma ótima maneira de emular ponteiros em Python, mas às vezes é entediante lembrar qual nome de chave você usou. Especialmente se você usar o dicionário em diferentes partes do aplicativo. Uma classe Python personalizada pode ajudar aqui.
Digamos que você precise acompanhar as métricas em um aplicativo. Uma ótima maneira de ignorar detalhes irritantes é criar uma classe:
class Metrics(object): def __init__(self): self._metrics = { "func_calls": 0, "cat_pictures_served": 0, }
Este código define a classe
Metrics . Ele ainda usa o dicionário para armazenar dados atualizados que estão na
_metrics membro
_metrics . Isso lhe dará a mutabilidade necessária. Agora você só precisa acessar esses valores. Você pode fazer isso usando as propriedades:
class Metrics(object):
Aqui usamos
@property . Se você é iniciante em decoradores, leia o artigo
Primer on Python Decorators . Nesse caso, o decorador
@property permite acessar
func_calls e
cat_pictures_served , como se fossem atributos:
>>> metrics = Metrics() >>> metrics.func_calls 0 >>> metrics.cat_pictures_served 0
O fato de você poder se referir a esses nomes como atributos significa que você é abstraído do fato de que esses valores são armazenados no dicionário. Além disso, você torna os nomes dos atributos mais explícitos. Obviamente, você deve poder aumentar os valores:
class Metrics(object):
:
inc_func_calls()inc_cat_pics()
metrics . , , :
>>> metrics = Metrics() >>> metrics.inc_func_calls() >>> metrics.inc_func_calls() >>> metrics.func_calls 2
func_calls inc_func_calls() Python. , -
metrics , .
: ,
inc_func_calls() inc_cat_pics() @property.setter int , .
Metrics :
class Metrics(object): def __init__(self): self._metrics = { "func_calls": 0, "cat_pictures_served": 0, } @property def func_calls(self): return self._metrics["func_calls"] @property def cat_pictures_served(self): return self._metrics["cat_pictures_served"] def inc_func_calls(self): self._metrics["func_calls"] += 1 def inc_cat_pics(self): self._metrics["cat_pictures_served"] += 1
ctypes
, - Python, CPython? ctypes , C. ctypes,
Extending Python With C Libraries and the «ctypes» Module .
, , . -
add_one() :
void add_one(int *x) { *x += 1; }
,
x 1. , (shared) . ,
add.c , gcc:
$ gcc -c -Wall -Werror -fpic add.c $ gcc -shared -o libadd1.so add.o
C
add.o .
libadd1.so .
libadd1.so . ctypes Python:
>>> import ctypes >>> add_lib = ctypes.CDLL("./libadd1.so") >>> add_lib.add_one <_FuncPtr object at 0x7f9f3b8852a0>
ctypes.CDLL ,
libadd1 .
add_one() , , Python-. , . Python , .
, ctypes :
>>> add_one = add_lib.add_one >>> add_one.argtypes = [ctypes.POINTER(ctypes.c_int)]
, C. , , :
>>> add_one(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> ctypes.ArgumentError: argument 1: <class 'TypeError'>: \ expected LP_c_int instance instead of int
Python ,
add_one() , . , ctypes . :
>>> x = ctypes.c_int() >>> x c_int(0)
x 0 . ctypes
byref() , .
:
.
, . , .
add_one() :
>>> add_one(ctypes.byref(x)) 998793640 >>> x c_int(1)
Ótimo! 1. , Python .
Conclusão
Python . , Python.
Python:
Python .