1. Introdução
Atenção, este não é outro artigo do “Hello world” sobre como piscar um LED ou entrar em sua primeira interrupção no STM32. No entanto, tentei dar explicações abrangentes sobre todas as questões levantadas, para que o artigo seja útil não apenas para muitos profissionais e que sonham em se tornar esses desenvolvedores (como espero), mas também para iniciantes em programadores de microcontroladores, já que esse tópico, por algum motivo, se espalha por inúmeros sites / blogs "Professores de programação MK".
Por que eu decidi escrever isso?
Embora eu tenha exagerado, tendo dito anteriormente que a faixa de bits de hardware da família Cortex-M não é descrita em recursos especializados, ainda existem lugares onde esse recurso é coberto (e até conheci um artigo aqui), mas esse tópico claramente precisa ser complementado e modernizado. Observo que isso também se aplica aos recursos em inglês. Na próxima seção, explicarei por que esse recurso do kernel pode ser extremamente importante.
Teoria
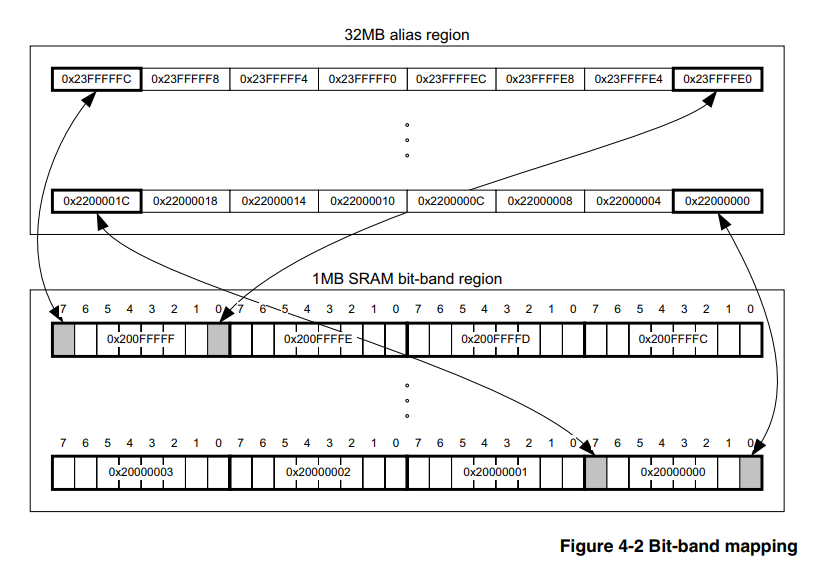
(e aqueles que a conhecem podem entrar em prática imediatamente)A banda de bits de hardware é um recurso do próprio núcleo e, portanto, não depende da família e da empresa do fabricante do microcontrolador, o principal é que o núcleo seja adequado. No nosso caso, seja Cortex-M3. Portanto, informações sobre esse assunto devem ser buscadas em um documento oficial no próprio núcleo, e existe um documento,
aqui está , a seção 4.2 descreve em detalhes como usar essa ferramenta.
Aqui, eu gostaria de fazer uma pequena digressão técnica para programadores que não estão familiarizados com o assembler, dos quais a maioria é agora, devido à complexidade propagandizada e à inutilidade do assembler para microcontroladores de 32 bits "sérios" como STM32, LPC, etc. Além disso, muitas vezes é possível encontrar tentativas censura pelo uso de montador nessa área, mesmo no Habr. Nesta seção, quero descrever brevemente o mecanismo de gravação na memória MK, que deve esclarecer as vantagens da banda de bits.
Vou explicar um exemplo simples e específico para a maioria dos STM32. Suponha que eu precise transformar PB0 em uma saída de uso geral. Uma solução típica seria assim:
GPIOB->MODER |= GPIO_MODER_MODER0_0;
Obviamente, usamos o "OR" bit a bit para não sobrescrever os bits restantes do registro.
Para o compilador, isso se traduz no seguinte conjunto de 4 instruções:
- Faça o download do GPIOB-> MODER no registro de uso geral (RON)
- Faça o upload dos valores para o outro RON no endereço indicado no RON da p1.
- Faça um OR bit a bit desse valor com GPIO_MODER_MODER0_0.
- Faça o download do resultado novamente em GPIOB-> MODER.
Além disso, não se deve esquecer que este kernel usa o conjunto de instruções thumb2, o que significa que eles podem ter diferentes volumes. Também observo que em todo lugar estamos falando sobre o nível de otimização O3.
Na linguagem assembly, fica assim:

Pode-se observar que a primeira instrução nada mais é do que uma pseudo-instrução com um deslocamento; encontramos o endereço do registrador no endereço do PC (dada a correia transportadora) + 0x58.
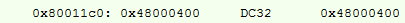
Acontece que temos 4 etapas (e mais ciclos de clock) e 14 bytes de memória ocupada por operação.
Se você quiser saber mais sobre isso, recomendo o livro [2], a propósito, também existe em russo.
Passamos para o método bit_banding.
A essência, segundo o camponês, é que o processador possui uma área de memória alocada especialmente, escrevendo os valores nos quais não alteramos outros bits do registro periférico ou da RAM. Ou seja, não precisamos preencher os pontos 2) e 3) descritos acima e, para isso, basta contar apenas o endereço de acordo com as fórmulas de [1].

Estamos tentando fazer uma operação semelhante, seu assembler:

Endereço recalculado:

Aqui, adicionamos uma instrução de gravação nº 1 no RON, mas, de qualquer forma, o resultado é 10 bytes, em vez de 14, e alguns ciclos de clock são menos.
Mas e se a diferença for ridícula?
Por um lado, as economias não são significativas, especialmente em ciclos, quando já é um hábito de fazer o overclock do controlador para 168 MHz. Em um projeto médio, os momentos em que você pode aplicar esse método serão de 40 a 80, respectivamente. Em bytes, a economia pode chegar a 250 bytes se os endereços forem diferentes. E se considerarmos que programar o MK diretamente nos registradores agora é considerado "zashkvar" e é "legal" usar todos os tipos de cubos de dados, a economia pode ser muito maior.
Além disso, a figura de 250 bytes é distorcida pelo fato de as bibliotecas de alto nível serem usadas ativamente na comunidade, o firmware inflado para tamanhos indecentes. Ao programar em um nível baixo, isso representa pelo menos 2 a 5% do volume de software para um projeto médio, com arquitetura competente e otimização de O3.
Novamente, não quero dizer que esse seja um tipo de ferramenta super-super-mega-mega legal que todo programador MK que se preze deve usar. Mas se eu posso cortar custos mesmo com uma parte tão pequena, por que não?Implementação
Todas as opções serão dadas apenas para configurar os periféricos, pois não encontrei uma situação em que seria necessário para a RAM. A rigor, para a RAM, a fórmula é semelhante, basta alterar os endereços base para o cálculo. Então, como você implementa isso?
Montador
Vamos de baixo, do meu amado Assembler.
Em projetos assembler, geralmente aloco alguns RONs de 2 bytes (de acordo com as instruções que funcionam com eles) sob os nºs 0 e 1 para todo o projeto, e os uso também em macros, o que me reduz outros 2 bytes continuamente. Observação, não encontrei o CMSIS no Assembler para STM, porque coloquei o número do bit na macro imediatamente e não o valor do registro.
Implementação para GNU Assembler @ . MOVW R0, 0x0000 MOVW R1, 0x0001 @ .macro PeriphBitSet PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4)) STR R1, [R3] .endm @ .macro PeriphBitReset PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4)) STR R0, [R3] .endm
Exemplos:
Exemplos de assembler PeriphSet TIM2_CCR2, 0 PeriphBitReset USART1_SR, 5
A vantagem indubitável dessa opção é que temos controle total, o que não pode ser dito sobre outras opções. E como a última seção do artigo mostrará, mais esta é
muito significativa.
No entanto, ninguém precisa de projetos para MK no Assembler, a partir do final do zero, o que significa que você precisa mudar para o SI.
Plain c
Honestamente, uma simples opção Sishny foi encontrada por mim no início do caminho, em algum lugar da vasta rede. Naquela época, eu já havia implementado bandas de bits no Assembler e, acidentalmente, deparei com um arquivo C, ele imediatamente funcionou e decidi não inventar nada.
Implementação para C simples #define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0 #define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A) #define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A) #define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A) #define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A) #define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A) #define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A) #define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A) #define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A) #define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A) #define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A) #define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A) #define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A) #define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A) #define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A) #define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A) #define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A) #define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A) #define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A) #define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A) #define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A) #define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A) #define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A) #define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A) #define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A) #define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A) #define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A) #define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A) #define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A) #define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A) #define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A) #define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A) #define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
Como você pode ver, um pedaço de código muito simples e direto escrito no idioma do processador. O principal trabalho aqui é a conversão dos valores do CMSIS em um número de bit, que estava ausente devido à necessidade de uma versão do assembler.
Ah, sim, use esta opção assim:
Exemplos para C simples BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0;
No entanto, as tendências modernas (massivamente, de acordo com minhas observações, aproximadamente a partir de 2015) são a favor da substituição de C por C ++, mesmo para MK. E as macros não são a ferramenta mais confiável, portanto a próxima versão estava destinada a nascer.
Cpp03
Aqui, de uma maneira muito interessante e discutida, mas pouco utilizada em vista de sua complexidade, com um exemplo hackeado de fatorial, a ferramenta é a metaprogramação.
Afinal, a tarefa de converter o valor de uma variável em um número de bits é ideal (já existem valores no CMSIS) e, nesse caso, é prático para o tempo de compilação.
Eu implementei isso da seguinte maneira usando modelos:
Implementação para C ++ 03 template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value { enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num }; }; template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)> { enum { bit_num = 31 }; }; #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
Você pode usá-lo da mesma maneira:
Exemplos para C ++ 03 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false;
E por que a macro foi deixada? O fato é que não conheço outra maneira de inserir essa operação com segurança sem precisar ir para outra área do código do programa. Eu ficaria muito feliz se eles me alertassem nos comentários. Nem modelos nem funções embutidas fornecem essa garantia. Sim, e a macro aqui lida perfeitamente com sua tarefa, não há sentido em alterá-la apenas porque o
conformista que alguém considera isso "não seguro".
Surpreendentemente, o tempo ainda não parou, os compiladores deram suporte cada vez mais ao C ++ 14 / C ++ 17, por que não aproveitar as inovações, tornando o código mais compreensível.
Cpp14 / cpp17
Implementação para C ++ 14 constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num) { return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1); } #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
Como você pode ver, substituí os modelos por uma função constexpr recursiva, que, na minha opinião, é mais clara para o olho humano.
Use da mesma maneira. A propósito, no C ++ 17, em princípio, você pode usar a função recursive lambda constexpr, mas não tenho certeza de que isso levará a pelo menos algumas simplificações e também não complicará a ordem do assembler.
Em resumo, todas as três implementações C / Cpp fornecem um conjunto igualmente correto de instruções, de acordo com a seção Teoria. Eu tenho trabalhado com todas as implementações no IAR ARM 8.30 e no gcc 7.2.0 por um longo tempo.A prática é uma vadia
Parece que foi tudo o que aconteceu. A economia de memória foi calculada, a implementação escolhida, pronta para melhorar o desempenho. Não aqui, era apenas um caso de divergência entre teoria e prática. E quando foi diferente?
Eu nunca o teria publicado se não o tivesse testado, mas quanto realisticamente o volume ocupado é reduzido nos projetos. Especificamente em alguns projetos antigos, substituí essa macro por uma implementação regular sem máscara e observei a diferença. O resultado surpreendeu desagradável.
Como se viu, o volume permanece praticamente inalterado. Escolhi especificamente projetos onde exatamente 40-50 dessas instruções foram usadas. Segundo a teoria, eu tive que salvar bem pelo menos 100 bytes e no máximo 200. Na prática, a diferença acabou sendo de 24 a 32 bytes. Mas porque?
Normalmente, quando você configura periféricos, configura de 5 a 10 registros quase seguidos. E, com um alto nível de otimização, o compilador não organiza as instruções exatamente na ordem dos registros, mas organiza as instruções como parecem corretas, às vezes interferindo com elas em locais aparentemente inextricáveis.
Vejo duas opções (aqui estão minhas especulações):
- Ou o compilador é tão inteligente que sabe para você como será melhor otimizar o conjunto de instruções
- Ou o compilador ainda não é mais esperto do que uma pessoa e se confunde quando encontra essas construções
Ou seja, verifica-se que esse método em linguagens de "alto nível", com um alto nível de otimização, só funciona corretamente se não houver operações semelhantes próximas a uma dessas operações.
Aliás, no nível O0, teoria e prática convergem em qualquer caso, mas não estou interessado nesse nível de otimização.
Eu resumo
Um resultado negativo também é um resultado. Eu acho que todo mundo vai tirar conclusões por si mesmo. Pessoalmente, continuarei a usar essa técnica, certamente não será pior.
Espero que tenha sido interessante e quero expressar um enorme respeito por aqueles que leram até o fim.
Lista de literatura
- "Manual de referência técnica do Cortex-M3", seção 4.2, ARM 2005.
- O guia definitivo para o ARM Cortex-M3, Joseph Yiu.
PS: Na minha bolsa, tenho uma pequena cobertura de tópicos relacionados ao desenvolvimento de eletrônicos embarcados. Deixe-me saber, se estiver interessado, vou obtê-los lentamente.
PPS De alguma forma, acabou por ser torto inserir seções de código, por favor, diga-me como melhorar, se possível. Em geral, você pode copiar um código de interesse para o bloco de notas e evitar emoções desagradáveis na análise.
UPD:
A pedido dos leitores, indico que a operação de bandas de bits em si é atômica, o que nos dá alguma segurança ao trabalhar com registradores. Esse é um dos recursos mais importantes desse método.