Como você sabe, o código é lido com muito mais frequência do que está escrito. Para que pelo menos alguém que não seja o autor possa lê-lo, e haja guias de estilo. Para R, este pode ser, por exemplo, o manual de Hadley.
Um guia de estilo não é apenas um acordo tácito entre desenvolvedores - muitas das regras têm um histórico curioso. Por que a seta
<- melhor que o sinal de igual
= , por que os veteranos R não gostam de sublinhados, como o comprimento recomendado da linha está associado a um cartão perfurado e muito mais - mais.
Isenção de responsabilidade: R Style GuidesAo contrário do Python, o R não possui um único padrão. Consequentemente, não existe um guia único. Além do
guia Hadley (ou de sua versão estendida do
tidyverse ), existem outros, como
Google ou
Bioconductor .
No entanto, o guia Hadley pode ser considerado o mais difundido (como a
verificação interna
do RStudio, por exemplo), o que é bastante facilitado pela popularidade das bibliotecas criadas pelo próprio Hadley (dplyr, ggplot, tidyr e outros da coleção tidyverse).
1. Operador de atribuição: <- vs =
Todos os guias disponíveis recomendam o uso do operador não padrão
<- , mas não o sinal de igual
= , que é comum em outros idiomas modernos. Três outros operadores (
<<- ,
-> ,
->> ) nem são mencionados (como o que existia nas versões anteriores
:= ). Parece, por que precisamos dessa flecha fora do padrão?
A história nos revela as cartas: em R, a flecha veio de S, que por sua vez a herdou da APL. Na APL, nos permitiu distinguir atribuição de igualdade. Em R, o operador de igualdade é padrão, portanto a diferença é diferente. Se a seta era inicialmente um operador de atribuição, o sinal de igual atribuía valores
apenas aos parâmetros nomeados. Em 2001, o sinal de igual se tornou o operador de atribuição, mas nunca se tornou sinônimo da seta.
O que nos permite considerar
= substituto completo para a flecha? Primeiro de tudo,
= como o operador de atribuição funciona apenas no nível superior. Por exemplo, dentro da função, tudo funcionará como antes:
mean(x = 1:5)
Aqui
= define apenas o parâmetro da função, enquanto
<- também atribui o valor à variável x. Podemos obter o mesmo efeito colocando a operação de atribuição entre parênteses
(não, isso ainda não é Lisp) :
mean ((x = 1:5))
... ou entre chaves:
mean ({x = 1:5})
Além disso, a seta tem precedência sobre o sinal de igual:
x <- y <- 1
A última expressão falhou porque é equivalente a
(x <- y) = 4 e o analisador a interpreta como
`<-<-`(x, y = 4, value = 4)
Em outras palavras, estamos tentando executar uma operação incorreta: primeiro atribua x a ye depois tente atribuir x e y a 4. A expressão será processada sem erros apenas se você alterar a prioridade das operações entre parênteses:
x <- (y = 4) .
2. Espaçamento
O guia recomenda colocar espaços entre os operadores (exceto, é claro, colchetes::, :: e :: :), bem como antes do colchete de abertura. Obviamente, isso faz parte dos padrões de codificação GNU. No entanto, esta cláusula está intimamente relacionada ao uso de
<- como um operador de atribuição. Por exemplo
x <-1
O que é isso X é menor que -1? Ou defina x como 1?
No entanto, o espaço extra não é melhor do que o ausente, por exemplo:
x <- 0 ifelse(x <-1, T, F)
No primeiro caso, não há espaço entre
< e
- , o que cria um operador de atribuição.
3. Nomes de funções e variáveis
Os guias de estilo discordam da questão dos nomes: o guia Hadley recomenda sublinhados para todos os nomes; Guia do Google - separação por pontos para variáveis e estilo de camelo com a primeira minúscula para funções; O biocondutor recomenda o LowerCamel para funções e variáveis. Não há unidade na comunidade R sobre esse problema, e todos os estilos possíveis podem ser encontrados:
lowerCamel period.separation lower_case_with_underscores allowercase UpperCamel
Não existe um estilo uniforme, mesmo para os nomes R básicos (por exemplo, nomes de nomes e linhas.nomes são funções diferentes!). Se você não levar em consideração a caixa de leitura ilegível (somente os usuários do Matlab podem adorar), existem três estilos mais populares: lowerCamel, letras minúsculas com _ e letras minúsculas com separação de pontos.
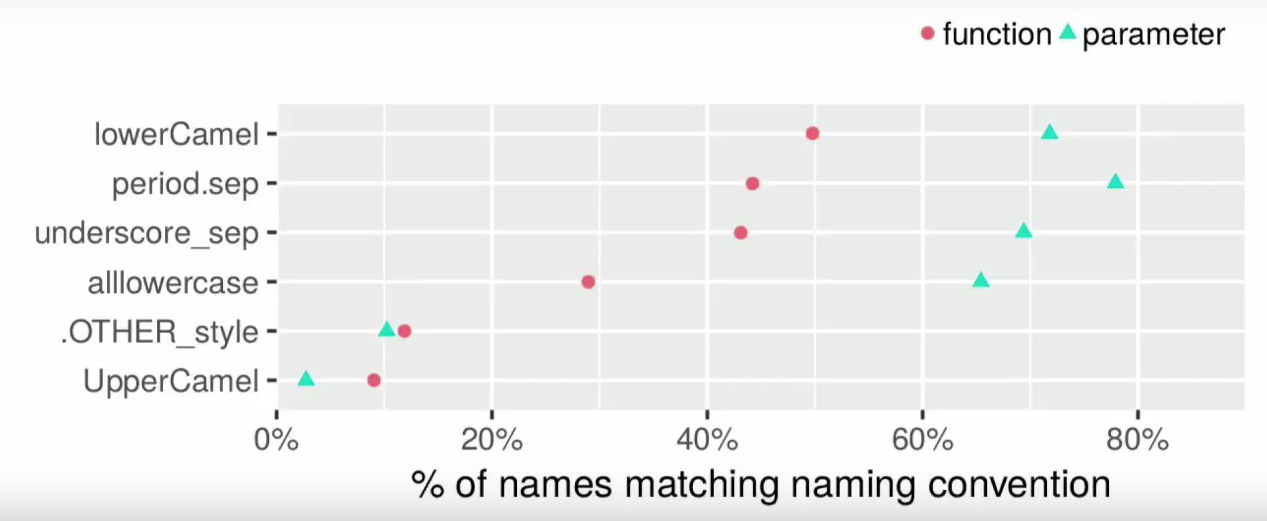
A popularidade de estilos diferentes para nomes de funções e parâmetros (um nome pode corresponder a estilos diferentes). Fonte: Rasmus Bååth
performance on useR! 2017.
A separação ponto a ponto é sinistramente reminiscente do uso de métodos na programação orientada a objetos, mas é historicamente comum. É tão comum que esse estilo em particular possa ser considerado verdadeiramente R'vsky. Por exemplo, a maioria das funções básicas o usa especificamente (e todos acabam de se reunir com data.table e as.factor).
Mas a separação é um dos estilos menos populares (e aqui Hadley vai contra a maioria). Para muitos usuários de R, os sublinhados serão irritantes: na popular extensão Emacs Speaks Statistics, ela é substituída por padrão pelo operador de atribuição
<- . E as configurações padrão, é claro,
quase ninguém muda.
No entanto, a influência do Emacs ESS ainda é uma explicação da categoria de "abanar a cauda do cachorro". Há uma razão mais antiga: nas versões anteriores do R, o sublinhado era sinônimo da seta
<- . Por exemplo, em 2000, você pode
encontrar o seguinte:
Aqui, em vez de criar a variável
c_mean R atribuiu o valor 3 primeiro à média da variável e depois à variável c. No R moderno, essas metamorfoses, é claro, não ocorrerão.
Devido à impopularidade, _ funções desse estilo quase não são encontradas entre as básicas:
Por fim, o estilo lowerCamel é pouco legível ao usar nomes longos:
Assim, em termos de nomes, as recomendações de guias não podem ser consideradas inequívocas; Afinal, isso é uma questão de gosto (desde que haja consistência nisso).
4. Aparelhos encaracolados
De acordo com o guia, uma nova linha deve seguir a chave de abertura e a de fechamento deve estar em uma linha separada (a menos que outra coisa a siga). I.e. algo como isto:
if (x >= 0) { log(x) } else { message("Not applicable!") }
Tudo aqui não é muito interessante: esse é o estilo padrão de recuo do K&R, que remonta à linguagem C e ao famoso livro de Kernigan e Ritchie “The C Programming Language” (ou K&R pelos nomes dos autores).
As origens desse estilo também são bastante óbvias: permite salvar linhas, mantendo a legibilidade. Para computadores antigos, o espaço vertical era um luxo demais. Por exemplo, o C foi desenvolvido no PDP-11, no terminal onde havia apenas 24 linhas. E, ao imprimir um livro de K&R, esse estilo economiza papel!
5. sequência de 80 caracteres
O comprimento da linha recomendado de acordo com o guia é de 80 caracteres. O número mágico 80 é encontrado não apenas em R, mas também em um grande número de outras linguagens (Java, Perl, PHP, etc., etc.). E não apenas idiomas: até a linha de comando do Windows consiste em 80 caracteres.
Pela primeira vez na programação, esse número apareceu em 1928, em vez de no cartão perfurado padrão da IBM, onde havia exatamente 80 colunas para dados. Uma pergunta muito mais interessante é por que esse padrão foi escolhido? Afinal, cartões perfurados de comprimento diferente (para 24 ou 45 colunas) foram usados anteriormente.

A resposta mais popular relaciona o comprimento de um cartão perfurado ao comprimento da linha das máquinas de escrever. As primeiras máquinas foram projetadas para o papel padrão americano 8½ x 11 polegadas e permitidas a impressão de 72 a 90 caracteres, dependendo do tamanho das margens. Portanto, a versão de 80 caracteres por linha parece bastante plausível, embora não seja verdadeira no último recurso. É possível que 80 caracteres sejam apenas o meio termo em termos de ergonomia.
6. Recuo da linha: espaços x tabulações
O estilo recomendado pelo guia é de dois espaços, não de uma guia. A recusa de tabulação é bastante compreensível: o comprimento da TAB varia em diferentes editores de texto (pode ser de 2 a 8 espaços). Recusando-os, obtemos duas vantagens ao mesmo tempo: primeiro, o código será exatamente o mesmo que o digitamos; segundo, não haverá violação acidental do comprimento recomendado da string. Nesse caso, é claro, aumentamos o tamanho do arquivo (quem deseja lidar com essas microoptimizações em 2k19?)
Os espaços de disputa versus guias têm uma longa história e podem ser equiparados a religiosos (como Win vs Linux, Android vs iOS e similares). No entanto, já sabemos quem ganhou: de acordo com o
estudo Stack Overflow, os desenvolvedores que usam espaços ganham mais do que aqueles que usam guias. Um argumento mais poderoso do que as regras de um guia de estilo, certo?
Em vez de uma conclusão: as regras dos guias de estilo podem parecer estranhas e ilógicas. De fato, por que a seta
<- se existe um operador padrão
= ? Mas se você se aprofundar, por trás de cada regra há alguma lógica, muitas vezes já esquecida.