Os sistemas de moderação automática são implementados em serviços e aplicativos da Web onde é necessário processar um grande número de mensagens do usuário. Esses sistemas podem reduzir os custos da moderação manual, acelerar e processar todas as mensagens do usuário em tempo real. No artigo, falaremos sobre a construção de um sistema automático de moderação para processar o inglês usando algoritmos de aprendizado de máquina. Discutiremos todo o trabalho do pipeline, desde as tarefas de pesquisa e a escolha dos algoritmos de ML até a produção. Vamos ver onde procurar conjuntos de dados prontos e como coletar dados para a tarefa.
Preparado com Ira Stepanyuk ( id_step ), cientista de dados do Poteha LabsDescrição da tarefa
Trabalhamos com bate-papos ativos para vários usuários, onde mensagens curtas de dezenas de usuários podem entrar em um bate-papo a cada minuto. A tarefa é destacar mensagens tóxicas e mensagens com comentários obscenos nas caixas de diálogo de tais chats. Do ponto de vista do aprendizado de máquina, essa é uma tarefa de classificação binária, em que cada mensagem deve ser atribuída a uma das classes.
Para resolver esse problema, antes de tudo, era necessário entender o que são mensagens tóxicas e o que exatamente as torna tóxicas. Para fazer isso, analisamos um grande número de mensagens típicas de usuário na Internet. Aqui estão alguns exemplos que já dividimos em mensagens tóxicas e normais.
Pode-se ver que as mensagens tóxicas geralmente contêm palavras obscenas, mas isso ainda não é um pré-requisito. A mensagem pode não conter palavras inapropriadas, mas ser ofensiva para alguém (exemplo (1)). Além disso, algumas vezes, mensagens tóxicas e normais contêm as mesmas palavras usadas em contextos diferentes - ofensivas ou não (exemplo (2)). Essas mensagens também precisam ser capazes de distinguir.
Depois de estudar várias mensagens, para o nosso sistema de moderação, chamamos de
tóxicas as mensagens que contêm declarações com expressões obscenas e ofensivas ou ódio a alguém.
Dados
Dados abertos
Um dos conjuntos de dados de moderação mais famosos é o conjunto de dados do Kaggle
Toxic Comment Classification Challenge . Parte da marcação no conjunto de dados está incorreta: por exemplo, mensagens com palavras obscenas podem ser marcadas como normais. Por esse motivo, você não pode simplesmente participar de competições do Kernel e obter um algoritmo de classificação que funcione bem. Você precisa trabalhar mais com os dados, ver quais exemplos não são suficientes e adicionar dados adicionais com esses exemplos.
Além das competições, existem várias publicações científicas com links para conjuntos de dados adequados (
exemplo ), mas nem todas podem ser usadas em projetos comerciais. Principalmente esses conjuntos de dados contêm mensagens da rede social Twitter, onde você pode encontrar muitos tweets tóxicos. Além disso, os dados são coletados no Twitter, pois determinadas hashtags podem ser usadas para pesquisar e marcar mensagens tóxicas para o usuário.
Dados manuais
Depois que coletamos o conjunto de dados de fontes abertas e treinamos nele o modelo básico, ficou claro que os dados abertos não são suficientes: a qualidade do modelo não é satisfatória. Além dos dados abertos para resolver o problema, uma seleção não alocada de mensagens de um messenger de jogo com um grande número de mensagens tóxicas estava disponível para nós.

Para usar esses dados em suas tarefas, eles precisavam ser rotulados de alguma forma. Naquela época, já havia um classificador de linha de base treinado, que decidimos usar para marcação semiautomática. Depois de executar todas as mensagens pelo modelo, obtivemos as probabilidades de toxicidade de cada mensagem e classificamos em ordem decrescente. No início desta lista foram coletadas mensagens com palavras obscenas e ofensivas. No final, pelo contrário, existem mensagens normais do usuário. Assim, a maioria dos dados (com valores de probabilidade muito grandes e muito pequenos) não pôde ser marcada, mas imediatamente atribuída a uma determinada classe. Resta marcar as mensagens que caíram no meio da lista, que foram feitas manualmente.
Aumento de Dados
Freqüentemente, nos conjuntos de dados, é possível ver as mensagens alteradas nas quais o classificador está errado, e a pessoa entende corretamente seu significado.
Isso ocorre porque os usuários ajustam e aprendem a enganar os sistemas de moderação para que os algoritmos cometam erros nas mensagens tóxicas e o significado permaneça claro para a pessoa. O que os usuários estão fazendo agora:
- erros de digitação geram: você é idiota, idiota ,
- substitua caracteres alfabéticos por números semelhantes na descrição: n1gga, b0ll0cks ,
- insira espaços extras: idiota ,
- remova os espaços entre as palavras: dieyoustupid .
Para treinar um classificador resistente a essas substituições, é necessário fazer o que os usuários fazem: gerar as mesmas alterações nas mensagens e adicioná-las ao conjunto de treinamento aos dados principais.
Em geral, essa luta é inevitável: os usuários sempre tentam encontrar vulnerabilidades e hacks, e os moderadores implementam novos algoritmos.
Descrição das subtarefas
Fomos confrontados com subtarefas para analisar mensagens em dois modos diferentes:
- modo online - análise de mensagens em tempo real, com velocidade máxima de resposta;
- modo offline - análise de logs de mensagens e alocação de diálogos tóxicos.
No modo online, processamos cada mensagem do usuário e a executamos no modelo. Se a mensagem for tóxica, oculte-a na interface de bate-papo e, se for normal, exiba-a. Nesse modo, todas as mensagens devem ser processadas muito rapidamente: o modelo deve dar uma resposta tão rapidamente que não atrapalhe a estrutura do diálogo entre os usuários.
No modo offline, não há limites de tempo para o trabalho e, portanto, eu queria implementar o modelo com a mais alta qualidade.
Modo online. Pesquisa no dicionário
Independentemente de qual modelo é escolhido a seguir, devemos encontrar e filtrar as mensagens com palavras obscenas. Para resolver esse subproblema, é mais fácil compilar um dicionário de palavras e expressões inválidas que não podem ser ignoradas e procurar essas palavras em cada mensagem. A pesquisa deve ser rápida, para que o algoritmo de pesquisa de substring ingênuo para esse período não se ajuste. Um algoritmo adequado para encontrar um conjunto de palavras em uma string é
o algoritmo Aho-Korasik . Devido a essa abordagem, é possível identificar rapidamente alguns exemplos tóxicos e bloquear mensagens antes que elas sejam transmitidas ao algoritmo principal. O uso do algoritmo ML permitirá "entender o significado" das mensagens e melhorar a qualidade da classificação.
Modo online. Modelo básico de aprendizado de máquina
Para o modelo base, decidimos usar uma abordagem padrão para classificação de texto: algoritmo de classificação clássica TF-IDF +. Novamente por motivos de velocidade e desempenho.
TF-IDF é uma medida estatística que permite determinar as palavras mais importantes para o texto no corpo usando dois parâmetros: a frequência de palavras em cada documento e o número de documentos que contêm uma palavra específica (em mais detalhes
aqui ). Tendo calculado para cada palavra na mensagem TF-IDF, obtemos uma representação vetorial dessa mensagem.
O TF-IDF pode ser calculado para palavras no texto, bem como para palavras e caracteres em n gramas. Essa extensão funcionará melhor, pois será capaz de lidar com frases e palavras que ocorrem com frequência que não estavam no conjunto de treinamento (fora do vocabulário).
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
Exemplo de uso do TF-IDF em n gramas de palavras e caracteresApós converter mensagens em vetores, você pode usar qualquer método clássico para classificação:
regressão logística, SVM ,
floresta aleatória, aumento .
Decidimos usar a regressão logística em nossa tarefa, pois esse modelo aumenta a velocidade em comparação com outros classificadores clássicos de ML e prevê probabilidades de classe, o que permite selecionar de maneira flexível um limite de classificação na produção.
O algoritmo obtido usando TF-IDF e regressão logística rapidamente funciona e define bem mensagens com palavras e expressões obscenas, mas nem sempre entende o significado. Por exemplo, muitas vezes as mensagens com as palavras '
preto ' e '
feminizm ' se
enquadravam na classe tóxica. Queria corrigir esse problema e aprender a entender melhor o significado das mensagens usando a próxima versão do classificador.
Modo offline
Para entender melhor o significado das mensagens, você pode usar algoritmos de rede neural:
- Incorporações (Word2Vec, FastText)
- Redes neurais (CNN, RNN, LSTM)
- Novos modelos pré-treinados (ELMo, ULMFiT, BERT)
Discutiremos alguns desses algoritmos e como eles podem ser usados com mais detalhes.
Word2Vec e FastText
Os modelos de incorporação permitem obter representações vetoriais de palavras a partir de textos. Existem
dois tipos de Word2Vec : Skip-gram e CBOW (Continuous Bag of Words). No Skip-gram, o contexto é previsto pela palavra, mas no CBOW, vice-versa: a palavra é prevista pelo contexto.
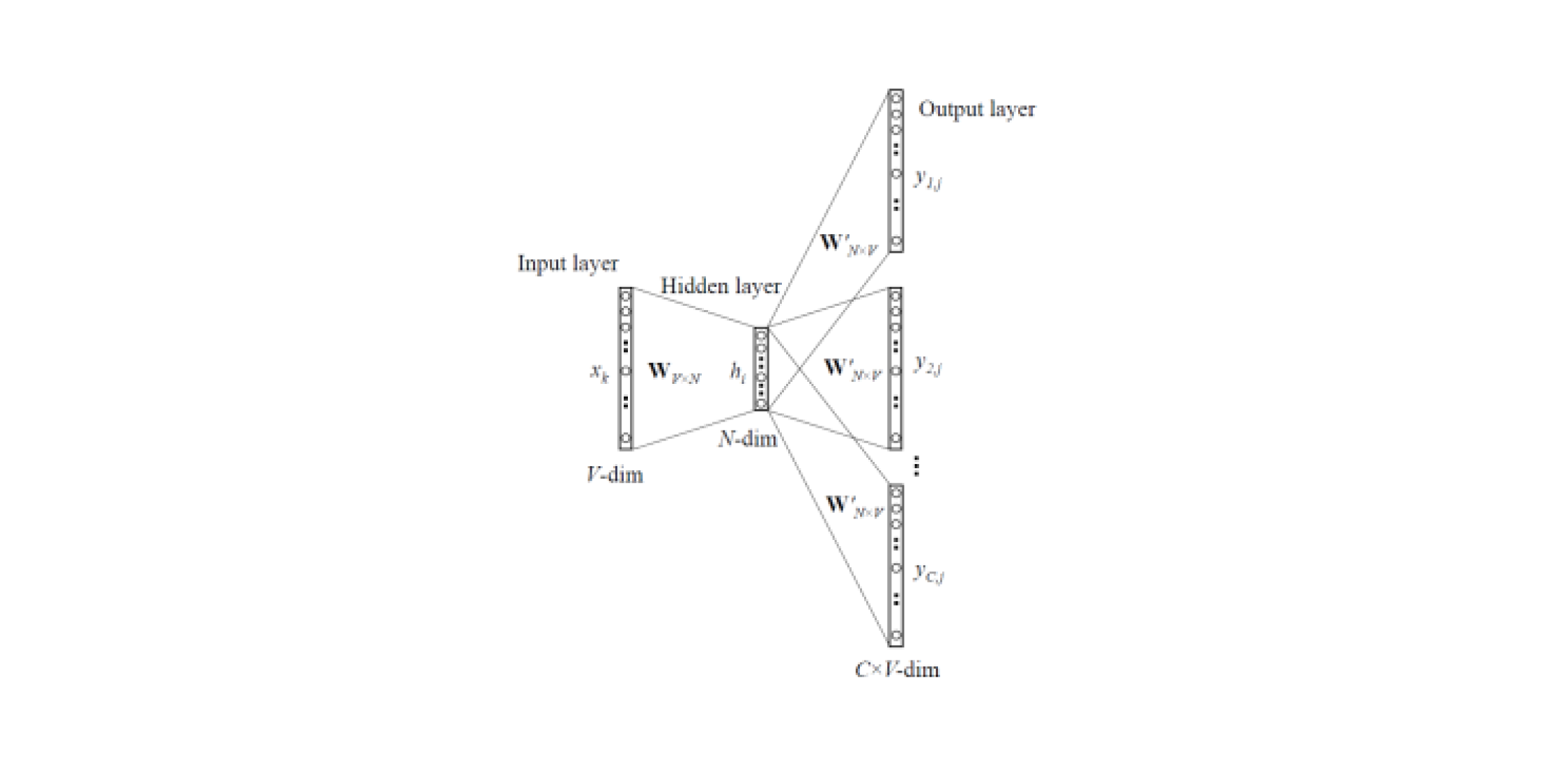
Esses modelos são treinados em grandes corpos de textos e permitem obter representações vetoriais de palavras a partir de uma camada oculta de uma rede neural treinada. A desvantagem dessa arquitetura é que o modelo aprende com um conjunto limitado de palavras contidas no corpus. Isso significa que, para todas as palavras que não estavam no corpo dos textos na fase de treinamento, não haverá incorporação. E essa situação geralmente ocorre quando modelos pré-treinados são usados para suas tarefas: para algumas das palavras não haverá incorporação, portanto, uma grande quantidade de informações úteis será perdida.
Para resolver o problema com palavras que não estão no dicionário (OOV, fora do vocabulário), existe um modelo de incorporação aprimorado -
FastText . Em vez de usar palavras únicas para treinar a rede neural, o FastText divide as palavras em n gramas (subpalavras) e aprende com elas. Para obter uma representação vetorial de uma palavra, você precisa obter representações vetoriais do n-grama dessa palavra e adicioná-las.
Assim, os modelos Word2Vec e FastText pré-treinados podem ser usados para obter vetores de recursos das mensagens. As características obtidas podem ser classificadas usando classificadores clássicos de ML ou uma rede neural totalmente conectada.
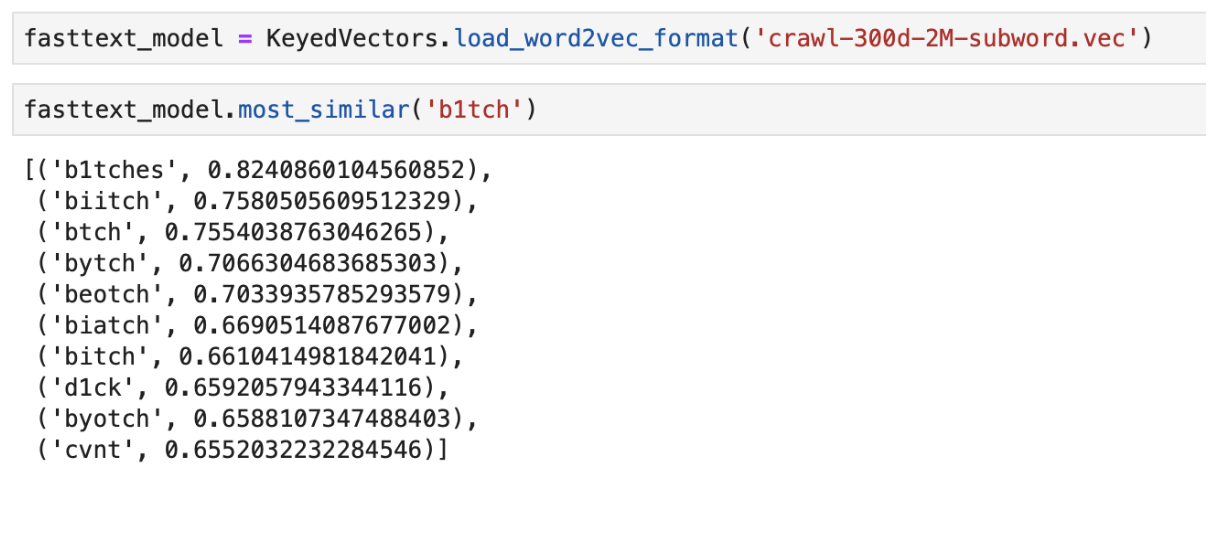 Um exemplo da saída das palavras “mais próximas” no significado usando o FastText pré- treinado
Um exemplo da saída das palavras “mais próximas” no significado usando o FastText pré- treinadoClassificador CNN
Para processamento e classificação de textos a partir de algoritmos de redes neurais, redes recorrentes (LSTM, GRU) são usadas com mais frequência, uma vez que funcionam bem com sequências. As redes convolucionais (CNNs) são usadas com mais frequência no processamento de imagens, mas também
podem ser usadas na tarefa de classificação de texto. Considere como isso pode ser feito.
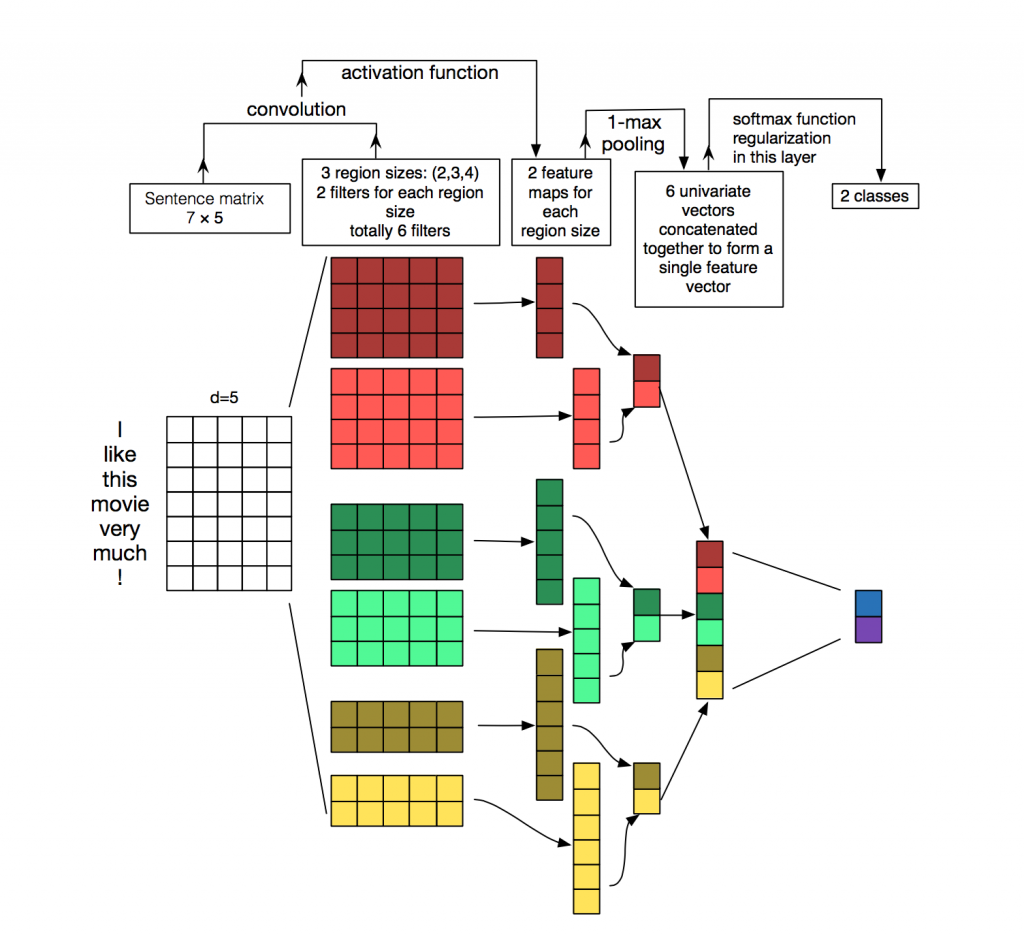
Cada mensagem é uma matriz na qual em cada linha do token (palavra) sua representação vetorial é gravada. A convolução é aplicada a essa matriz de uma certa maneira: o filtro de convolução "desliza" por linhas inteiras da matriz (vetores de palavras), mas captura várias palavras por vez (geralmente 2-5 palavras), processando as palavras no contexto de palavras vizinhas. Detalhes de como isso acontece podem ser vistos na
figura .
Por que usar redes convolucionais para processamento de texto quando você pode usar recorrentes? O fato é que as convoluções funcionam muito mais rapidamente. Utilizando-os para a classificação de mensagens, você pode economizar muito tempo no treinamento.
ELMo
O ELMo (Embeddings from Language Models) é um modelo de incorporação baseado em um modelo de linguagem que foi
introduzido recentemente . O novo modelo de incorporação é diferente dos modelos Word2Vec e FastText. Os vetores de palavras ELMo têm certas vantagens:
- A apresentação de cada palavra depende de todo o contexto em que é usada.
- A representação é baseada em símbolos, o que permite a formação de representações confiáveis para palavras OOV (fora do vocabulário).
O ELMo pode ser usado para várias tarefas na PNL. Por exemplo, para nossa tarefa, os vetores de mensagens recebidos usando o ELMo podem ser enviados para o classificador clássico de ML ou usar uma rede convolucional ou totalmente conectada.
Os casamentos pré-treinados do ELMo são bastante simples de usar para sua tarefa; um exemplo de uso pode ser encontrado
aqui .
Recursos de implementação
API do balão
A API do protótipo foi escrita no Flask, pois é fácil de usar.
Imagens do Docker
Para a implantação, usamos duas imagens de janela de encaixe: a base, onde todas as dependências foram instaladas, e a principal para iniciar o aplicativo. Isso economiza bastante tempo de montagem, pois a primeira imagem raramente é reconstruída e economiza tempo durante a implantação. É gasto muito tempo na construção e no download de bibliotecas de aprendizado de máquina, o que não é necessário em todas as confirmações.
Teste
A peculiaridade da implementação de um número bastante grande de algoritmos de aprendizado de máquina é que, mesmo com altas métricas no conjunto de dados de validação, a qualidade real do algoritmo na produção pode ser baixa. Portanto, para testar a operação do algoritmo, toda a equipe usou o bot no Slack. Isso é muito conveniente, porque qualquer membro da equipe pode verificar qual resposta os algoritmos dão para uma mensagem específica. Este método de teste permite que você veja imediatamente como os algoritmos funcionarão em dados ativos.
Uma boa alternativa é lançar a solução em sites públicos como Yandex Toloka e AWS Mechanical Turk.
Conclusão
Examinamos várias abordagens para resolver o problema da moderação automática de mensagens e descrevemos os recursos de nossa implementação.
As principais observações obtidas durante o trabalho:
- O algoritmo de pesquisa de dicionário e aprendizado de máquina baseado em TF-IDF e regressão logística permitiu classificar as mensagens rapidamente, mas nem sempre corretamente.
- Os algoritmos de rede neural e os modelos de incorporação pré-treinados lidam melhor com essa tarefa e podem determinar a toxicidade no significado da mensagem.
Obviamente, postamos a
demonstração aberta de
detecção de comentários tóxicos de Poteha no bot do
Facebook . Ajude-nos a melhorar o bot!
Ficarei feliz em responder às perguntas nos comentários.