
1. Introdução
É hora de falar sobre exceções ou, melhor dizendo, sobre situações excepcionais. Antes de começarmos, vejamos a definição. O que é uma situação excepcional?
Essa é uma situação que torna incorreta a execução do código atual ou subsequente. Quero dizer diferente de como foi projetado ou planejado. Tal situação compromete a integridade de um aplicativo ou de sua parte, por exemplo, um objeto. Ele traz o aplicativo para um estado extraordinário ou excepcional.
Mas por que precisamos definir essa terminologia? Porque isso nos manterá em alguns limites. Se não seguirmos a terminologia, podemos nos afastar muito de um conceito projetado que pode resultar em muitas situações ambíguas. Vamos ver alguns exemplos práticos:
struct Number { public static Number Parse(string source) { // ... if(!parsed) { throw new ParsingException(); } // ... } public static bool TryParse(string source, out Number result) { // .. return parsed; } }
Este exemplo parece um pouco estranho, e é por uma razão. Eu criei esse código um pouco artificial para mostrar a importância dos problemas que aparecem nele. Primeiro, vejamos o método Parse . Por que isso deveria lançar uma exceção?
- Como o parâmetro aceito é uma sequência, mas sua saída é um número, que é um tipo de valor. Este número não pode indicar a validade dos cálculos: apenas existe. Em outras palavras, o método não possui meios em sua interface para comunicar um problema em potencial.
- Por outro lado, o método espera uma sequência correta que contenha algum número e nenhum caractere redundante. Se não contiver, há um problema nos pré-requisitos do método: o código que chama nosso método passou dados incorretos.
Portanto, a situação em que esse método obtém uma string com dados incorretos é excepcional, pois o método não pode retornar um valor correto nem nada. Assim, a única maneira é lançar uma exceção.
A segunda variante do método pode sinalizar alguns problemas com os dados de entrada: o valor de retorno aqui é boolean que indica uma execução bem-sucedida do método. Este método não precisa usar exceções para sinalizar problemas: todos eles são cobertos pelo valor de retorno false .
Visão geral
O tratamento de exceções pode parecer tão fácil quanto o ABC: precisamos apenas colocar blocos try-catch e aguardar os eventos correspondentes. No entanto, essa simplicidade se tornou possível devido ao tremendo trabalho das equipes de CLR e CoreCLR que unificaram todos os erros provenientes de todas as direções e fontes no CLR. Para entender sobre o que falaremos a seguir, vejamos um diagrama:
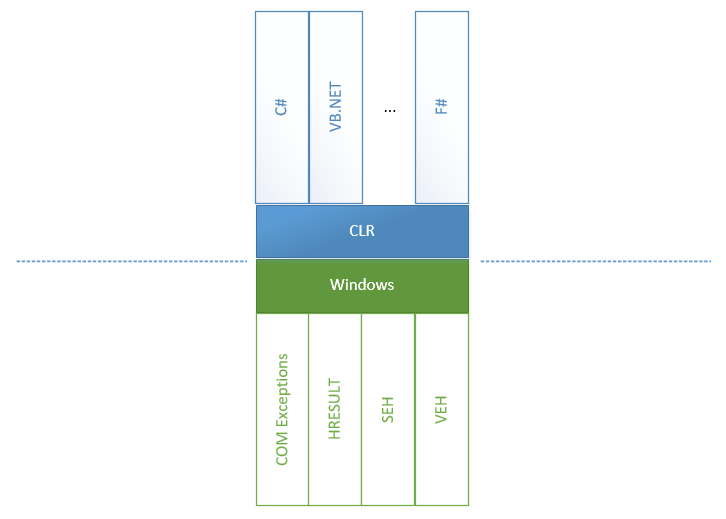
Podemos ver que dentro do grande .NET Framework existem dois mundos: tudo o que pertence ao CLR e tudo o que não pertence, incluindo todos os erros possíveis que aparecem no Windows e em outras partes do mundo inseguro.
- O SEH (Structured Exception Handling) é uma maneira padrão pelo qual o Windows lida com exceções. Quando métodos
unsafe são chamados e exceções são lançadas, ocorre a conversão insegura de exceções <-> CLR nas duas direções: de inseguras para CLR e para trás. Isso ocorre porque o CLR pode chamar um método não seguro, que pode chamar um método CLR por sua vez. - O Vectored Exception Handling (VEH) é uma raiz do SEH e permite que você coloque seus manipuladores em locais onde exceções possam ser lançadas. Em particular, é usado para colocar
FirstChanceException . - As exceções do COM + aparecem quando a fonte de um problema é um componente do COM. Nesse caso, uma camada entre COM e um método .NET deve converter um erro COM em uma exceção .NET.
- E, é claro, invólucros para HRESULT. Eles são introduzidos para converter um modelo WinAPI (um código de erro está contido em um valor de retorno, enquanto os valores de retorno são obtidos usando parâmetros de método) em um modelo de exceções, porque é uma exceção padrão do .NET.
Por outro lado, existem idiomas acima da CLI, cada um dos quais mais ou menos possui funções para lidar com exceções. Por exemplo, recentemente o VB.NET ou o F # tiveram uma funcionalidade de manipulação de exceções mais rica, expressa em vários filtros que não existiam no C #.
Códigos de retorno vs. exceção
Separadamente, devo mencionar um modelo de tratamento de erros de aplicativo usando códigos de retorno. A idéia de simplesmente retornar um erro é clara e clara. Além disso, se tratarmos as exceções como um operador goto , o uso de códigos de retorno se tornará mais razoável: nesse caso, o usuário de um método vê a possibilidade de erros e pode entender quais erros podem ocorrer. No entanto, não vamos adivinhar o que é melhor e para quê, mas discuta o problema da escolha usando uma teoria bem fundamentada.
Vamos supor que todos os métodos tenham interfaces para lidar com erros. Todos os métodos se pareceriam com:
public bool TryParseInteger(string source, out int result); public DialogBoxResult OpenDialogBox(...); public WebServiceResult IWebService.GetClientsList(...); public class DialogBoxResult : ResultBase { ... } public class WebServiceResult : ResultBase { ... }
E seu uso seria semelhante a:
public ShowClientsResult ShowClients(string group) { if(!TryParseInteger(group, out var clientsGroupId)) return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed }; var webResult = _service.GetClientsList(clientsGroupId); if(!webResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult }; } var dialogResult = _dialogsService.OpenDialogBox(webResult.Result); if(!dialogResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult }; } return ShowClientsResult.Success(); }
Você pode pensar que esse código está sobrecarregado com o tratamento de erros. No entanto, gostaria que você reconsiderasse sua posição: tudo aqui é uma emulação de um mecanismo que lança e manipula exceções.
Como um método pode relatar um problema? Isso pode ser feito usando uma interface para relatar erros. Por exemplo, no método TryParseInteger , essa interface é representada por um valor de retorno: se tudo estiver OK, o método retornará true . Se não estiver bom, ele retornará false . No entanto, há uma desvantagem aqui: o valor real é retornado através do parâmetro out int result . A desvantagem é que, por um lado, o valor de retorno é logicamente e, pela percepção, tem mais essência de "valor de retorno" do que out parâmetro out . Por outro lado, nem sempre nos preocupamos com erros. Na verdade, se uma string destinada a a análise vem de um serviço que gerou essa sequência, não precisamos verificar se há erros: a sequência sempre será correta e adequada para a análise. No entanto, suponha que adotemos outra implementação do método:
public int ParseInt(string source);
Depois, há uma pergunta: se uma string tem erros, o que o método deve fazer? Deve retornar zero? Isso não estará correto: não há zero na string. Nesse caso, temos um conflito de interesses: a primeira variante possui muito código, enquanto a segunda variante não tem como relatar erros. No entanto, é realmente fácil decidir quando usar códigos de retorno e quando usar exceções.
Se receber um erro for uma norma, escolha um código de retorno. Por exemplo, é normal quando um algoritmo de análise de texto encontra erros em um texto, mas se outro algoritmo que trabalha com uma sequência analisada obtiver um erro de um analisador, ele poderá ser crítico ou, em outras palavras, excepcional.
Tente pegar finalmente
Um bloco try cobre uma seção em que um programador espera obter uma situação crítica que é tratada como norma por código externo. Em outras palavras, se algum código considerar seu estado interno inconsistente com base em algumas regras e gerar uma exceção, um sistema externo, com uma visão mais ampla da mesma situação, poderá capturar essa exceção usando um bloco catch e normalizar a execução do código do aplicativo . Assim, você legaliza exceções nesta seção do código, capturando-as . Penso que é uma ideia importante que justifica a proibição de capturar todas as try-catch(Exception ex){ ...} por precaução .
Isso não significa que capturar exceções contradiz alguma ideologia. Eu digo que você deve pegar apenas os erros que você espera de uma seção específica do código. Por exemplo, você não pode esperar todos os tipos de exceções herdadas de ArgumentException ou não pode obter NullReferenceException , porque muitas vezes significa que um problema está mais no seu código do que no chamado. Mas é apropriado esperar que você não consiga abrir um arquivo pretendido. Mesmo se você tiver 200% de certeza de que será capaz, não se esqueça de conferir.
O bloco finally também é bem conhecido. É adequado para todos os casos cobertos por blocos try-catch . Exceto por várias situações especiais raras, esse bloco sempre funcionará. Por que essa garantia de desempenho foi introduzida? Limpar os recursos e grupos de objetos que foram alocados ou capturados no bloco try e pelos quais esse bloco é responsável.
Esse bloco geralmente é usado sem o bloco catch quando não nos importamos com o erro que quebrou um algoritmo, mas precisamos limpar todos os recursos alocados para esse algoritmo. Vejamos um exemplo simples: um algoritmo de cópia de arquivo precisa de dois arquivos abertos e um intervalo de memória para um buffer de caixa. Imagine que alocamos memória e abrimos um arquivo, mas não conseguimos abrir outro. Para agrupar tudo em uma "transação" atomicamente, colocamos todas as três operações em um único bloco de try (como uma variante de implementação) com os recursos finally limpos. Pode parecer um exemplo simplificado, mas o mais importante é mostrar a essência.
O que C # realmente falta é um bloco de fault que é ativado sempre que ocorre um erro. É como finally usar esteróides. Se tivéssemos isso, poderíamos, por exemplo, criar um único ponto de entrada para registrar situações excepcionais:
try { //... } fault exception { _logger.Warn(exception); }
Outra coisa que devo mencionar nesta introdução são os filtros de exceção. Não é um novo recurso na plataforma .NET, mas os desenvolvedores de C # podem ser novos: a filtragem de exceções apareceu apenas na v. 6.0 Os filtros devem normalizar uma situação em que há um único tipo de exceção que combina vários tipos de erros. Isso deve nos ajudar quando queremos lidar com um cenário específico, mas precisamos capturar todo o grupo de erros primeiro e filtrá-los mais tarde. Claro, quero dizer o código do seguinte tipo:
try { //... } catch (ParserException exception) { switch(exception.ErrorCode) { case ErrorCode.MissingModifier: // ... break; case ErrorCode.MissingBracket: // ... break; default: throw; } }
Bem, agora podemos reescrever esse código corretamente:
try { //... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier) { // ... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket) { // ... }
A melhoria aqui não está na falta de construção de switch . Eu acredito que essa nova construção é melhor em várias coisas:
- usando
when para filtrar, captamos exatamente o que queremos e é certo em termos de ideologia; - o código se torna mais legível neste novo formulário. Examinando o código, nosso cérebro pode identificar blocos para lidar com erros com mais facilidade, pois inicialmente procura por
catch e não switch-case ; - o último mas não menos importante: uma comparação preliminar é ANTES de entrar no bloco catch. Isso significa que, se fizermos suposições erradas sobre situações em potencial, essa construção funcionará mais rápido do que
switch no caso de lançar uma exceção novamente.
Muitas fontes dizem que a característica peculiar desse código é que a filtragem ocorre antes do desenrolamento da pilha. Você pode ver isso em situações em que não há outras chamadas, exceto a habitual, entre o local em que uma exceção é lançada e o local em que a verificação de filtragem ocorre.
static void Main() { try { Foo(); } catch (Exception ex) when (Check(ex)) { ; } } static void Foo() { Boo(); } static void Boo() { throw new Exception("1"); } static bool Check(Exception ex) { return ex.Message == "1"; }
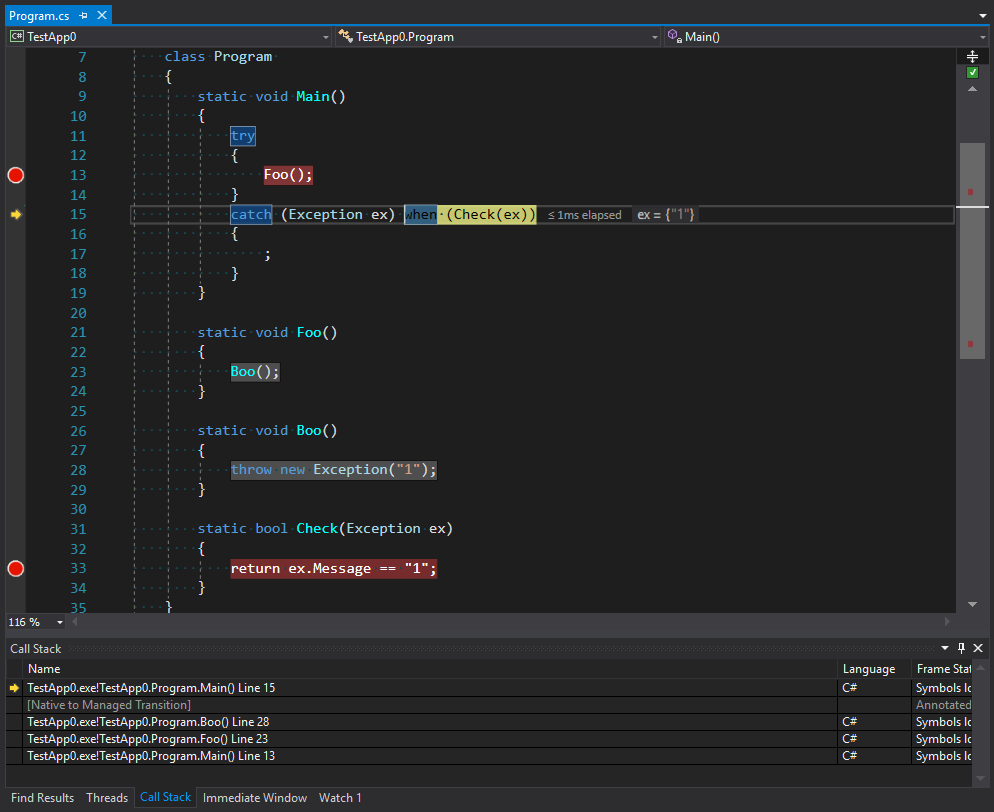
Você pode ver na imagem que o rastreamento de pilha contém não apenas a primeira chamada de Main como o ponto para capturar uma exceção, mas a pilha inteira antes do ponto de lançar uma exceção mais a segunda entrada no Main por código não gerenciado. Podemos supor que esse código seja exatamente o código para lançar exceções que estão no estágio de filtrar e escolher um manipulador final. No entanto, nem todas as chamadas podem ser tratadas sem o desenrolar da pilha . Acredito que a uniformidade excessiva da plataforma gera muita confiança nela. Por exemplo, quando um domínio chama um método de outro domínio, é absolutamente transparente em termos de código. No entanto, a maneira como os métodos chamam trabalho é uma história absolutamente diferente. Nós vamos falar sobre eles na próxima parte.
Serialização
Vamos começar analisando os resultados da execução do código a seguir (adicionei a transferência de uma chamada através do limite entre dois domínios de aplicativo).
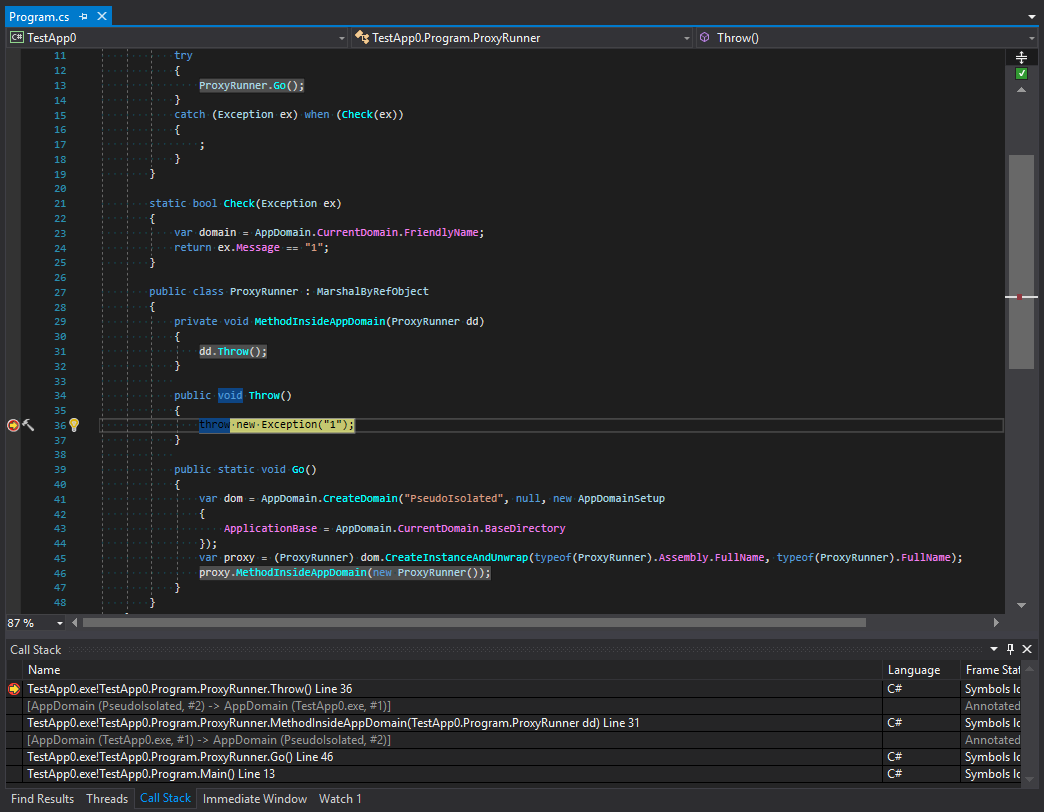
class Program { static void Main() { try { ProxyRunner.Go(); } catch (Exception ex) when (Check(ex)) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { throw new Exception("1"); } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } } }
Podemos ver que o desenrolar da pilha acontece antes de começarmos a filtrar. Vamos ver as capturas de tela. O primeiro é obtido antes da geração de uma exceção:
O segundo é depois:
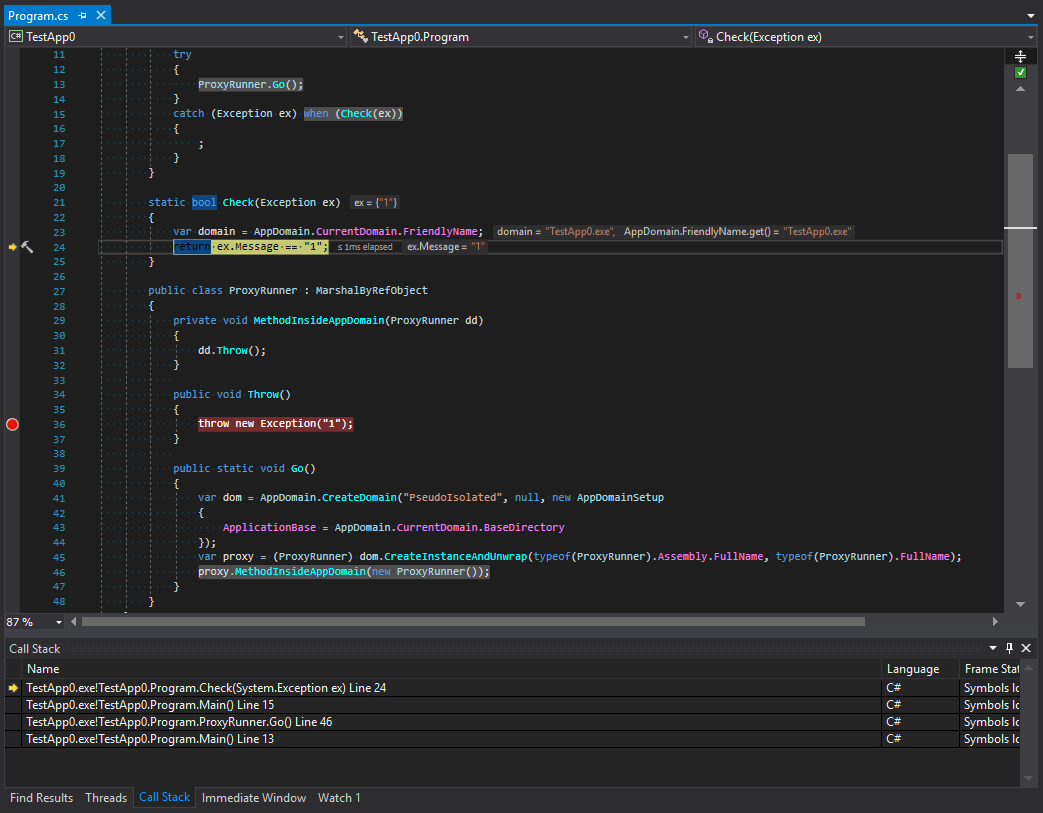
Vamos estudar o rastreamento de chamadas antes e depois das exceções serem filtradas. O que acontece aqui? Podemos ver que os desenvolvedores de plataformas criaram algo que, à primeira vista, parece a proteção de um subdomínio. O rastreamento é cortado após o último método na cadeia de chamadas e, em seguida, há a transferência para outro domínio. Mas acho isso estranho. Para entender por que isso acontece, lembre-se da regra principal para tipos que organizam a interação entre domínios. Esses tipos devem herdar MarshalByRefObject e ser serializáveis. No entanto, apesar do rigor dos tipos de exceção em C #, pode ser de qualquer natureza. O que isso significa? Isso significa que situações podem ocorrer quando uma exceção dentro de um subdomínio pode ser capturada em um domínio pai. Além disso, se um objeto de dados que pode entrar em uma situação excepcional tiver alguns métodos perigosos em termos de segurança, ele poderá ser chamado em um domínio pai. Para evitar isso, a exceção é primeiro serializada e, em seguida, cruza a fronteira entre os domínios do aplicativo e aparece novamente com uma nova pilha. Vamos verificar esta teoria:
[StructLayout(LayoutKind.Explicit)] class Cast { [FieldOffset(0)] public Exception Exception; [FieldOffset(0)] public object obj; } static void Main() { try { ProxyRunner.Go(); Console.ReadKey(); } catch (RuntimeWrappedException ex) when (ex.WrappedException is Program) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { var x = new Cast {obj = new Program()}; throw x.Exception; } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } }
Como o código C # poderia gerar uma exceção de qualquer tipo (não quero torturá-lo com o MSIL), executei um truque neste exemplo, convertendo um tipo para um não comparável, para que pudéssemos lançar uma exceção de qualquer tipo, mas o tradutor pensaria que usamos o tipo de Exception . Criamos uma instância do tipo Program , que não é serializável, com certeza, e lançamos uma exceção usando esse tipo como carga de trabalho. A boa notícia é que você obtém um invólucro para exceções não-Exception de RuntimeWrappedException que armazenará uma instância do nosso objeto de tipo de Program dentro e poderemos capturar essa exceção. No entanto, existem más notícias que apóiam nossa ideia: chamar proxy.MethodInsideAppDomain(); irá gerar SerializationException :
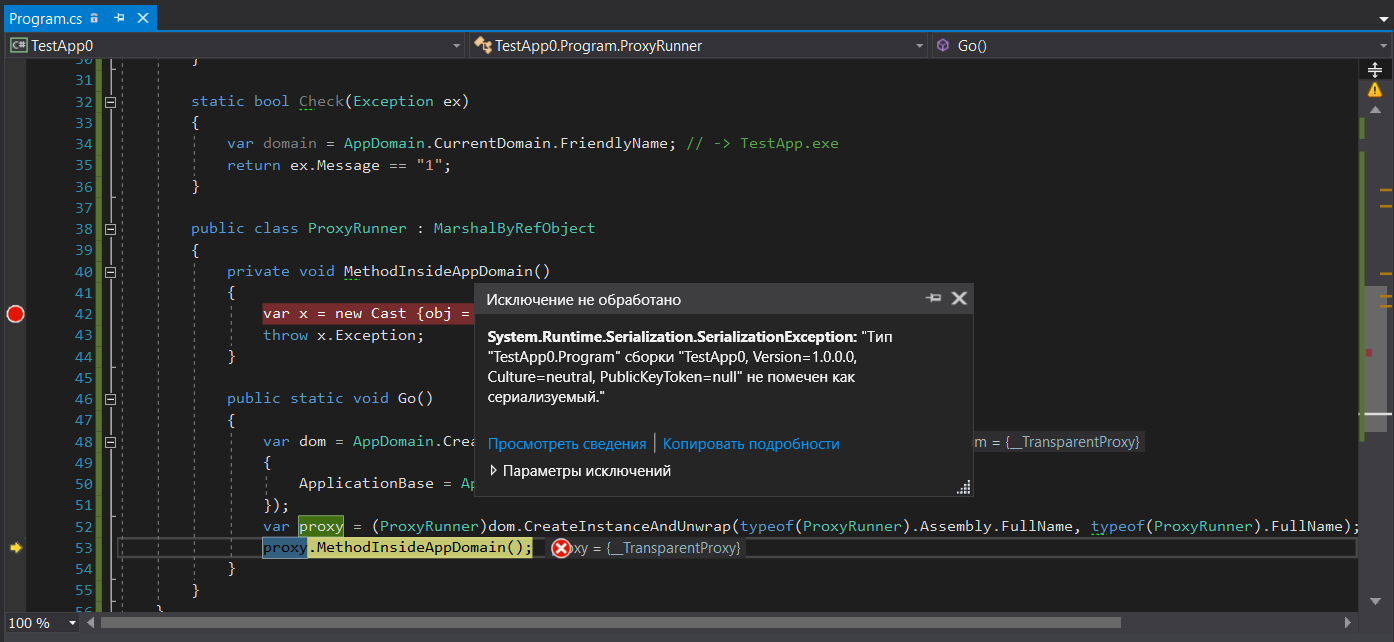
Portanto, você não pode transferir uma exceção entre domínios, pois não é possível serializá-la. Isso, por sua vez, significa que o uso de filtros de exceção para chamadas de métodos de quebra FullTrust em outros domínios levará a desenrolar a pilha, apesar de a serialização parecer desnecessária com FullTrust configurações FullTrust de um subdomínio.
Devemos prestar atenção adicional ao motivo pelo qual a serialização entre domínios é tão necessária. Em nosso exemplo artificial, criamos um subdomínio que não possui configurações. Isso significa que funciona da maneira FullTrust. O CLR confia totalmente em seu conteúdo e não executa verificações adicionais. No entanto, quando você insere pelo menos uma configuração de segurança, a confiança total desaparece e o CLR começa a controlar tudo o que acontece dentro de um subdomínio. Portanto, quando você tem um domínio totalmente confiável, não precisa de uma serialização. Admita, não precisamos nos proteger. Mas a serialização existe não apenas para proteção. Cada domínio carrega todos os assemblies necessários uma segunda vez e cria suas cópias. Assim, ele cria cópias de todos os tipos e todas as VMTs. Obviamente, ao passar um objeto de domínio para domínio, você obterá o mesmo objeto. Mas suas VMTs não serão próprias e esse objeto não poderá ser convertido para outro tipo. Em outras palavras, se criarmos uma instância de um tipo Boo e a colocarmos em outro domínio, a conversão do (Boo)boo não funcionará. Nesse caso, a serialização e a desserialização resolverão o problema, pois o objeto existirá em dois domínios simultaneamente. Ele existirá com todos os seus dados onde foi criado e existirá no domínio de uso como um objeto proxy, garantindo que os métodos de um objeto original sejam chamados.
Ao transferir um objeto serializado entre domínios, você obtém uma cópia completa do objeto de um domínio em outro enquanto mantém alguma delimitação na memória. No entanto, essa delimitação é fictícia. É usado apenas para os tipos que não estão no Shared AppDomain . Portanto, se você lançar algo não serializável como uma exceção, mas no Shared AppDomain , você não receberá um erro de serialização (podemos tentar lançar Action vez de Program ). No entanto, o desenrolar da pilha ocorrerá de qualquer maneira neste caso: as duas variantes devem funcionar de maneira padrão. Para que ninguém fique confuso.
 Este capítulo foi traduzido do russo em conjunto pelo autor e por tradutores profissionais . Você pode nos ajudar com a tradução do russo ou do inglês para qualquer outro idioma, principalmente para chinês ou alemão.
Este capítulo foi traduzido do russo em conjunto pelo autor e por tradutores profissionais . Você pode nos ajudar com a tradução do russo ou do inglês para qualquer outro idioma, principalmente para chinês ou alemão.
Além disso, se você quiser nos agradecer, a melhor maneira de fazer isso é nos dar uma estrela no github ou no fork do repositório  github / sidristij / dotnetbook .
github / sidristij / dotnetbook .