Oi Meu nome é Vadim Madison, lidero o desenvolvimento da System Platform Avito. Sobre como nós, na empresa, estamos mudando de uma arquitetura monolítica para uma arquitetura de microsserviços, já foi dito mais de uma vez. É hora de compartilhar como transformamos nossa infraestrutura para tirar o máximo proveito dos microsserviços e não nos perdermos neles. Como o PaaS nos ajuda aqui, como simplificamos a implantação e reduzimos a criação de um microsserviço para um clique - continue a ler. Nem tudo o que escrevo abaixo é totalmente implementado no Avito, parte é como desenvolvemos nossa plataforma.
(E no final deste artigo, falarei sobre a oportunidade de participar de um seminário de três dias de um especialista em arquitetura de microsserviços, Chris Richardson).

Como chegamos aos microsserviços
Avito é um dos maiores classificados do mundo, publica mais de 15 milhões de novos anúncios por dia. Nosso back-end aceita mais de 20 mil solicitações por segundo. Agora temos várias centenas de microsserviços.
Estamos construindo a arquitetura de microsserviços há vários anos. Como exatamente - nossos colegas falaram em detalhes em nossa seção no RIT ++ 2017. No CodeFest 2017 (veja o vídeo ), Sergey Orlov e Mikhail Prokopchuk explicaram em detalhes por que precisávamos da transição para microsserviços e qual o papel que o Kubernetes desempenha aqui. Bem, agora estamos fazendo tudo para minimizar os custos de dimensionamento inerentes a essa arquitetura.
Inicialmente, não criamos um ecossistema que nos ajudasse de maneira abrangente no desenvolvimento e lançamento de microsserviços. Eles simplesmente coletaram soluções sensatas de código aberto, as lançaram em casa e sugeriram que o desenvolvedor as tratasse. Como resultado, ele foi para uma dúzia de lugares (painéis, serviços internos), após o que se tornou mais forte no desejo de cortar o código da maneira antiga, em um monólito. A cor verde nos diagramas abaixo indica o que o desenvolvedor faz de uma maneira ou de outra com as próprias mãos; a cor amarela indica automação.
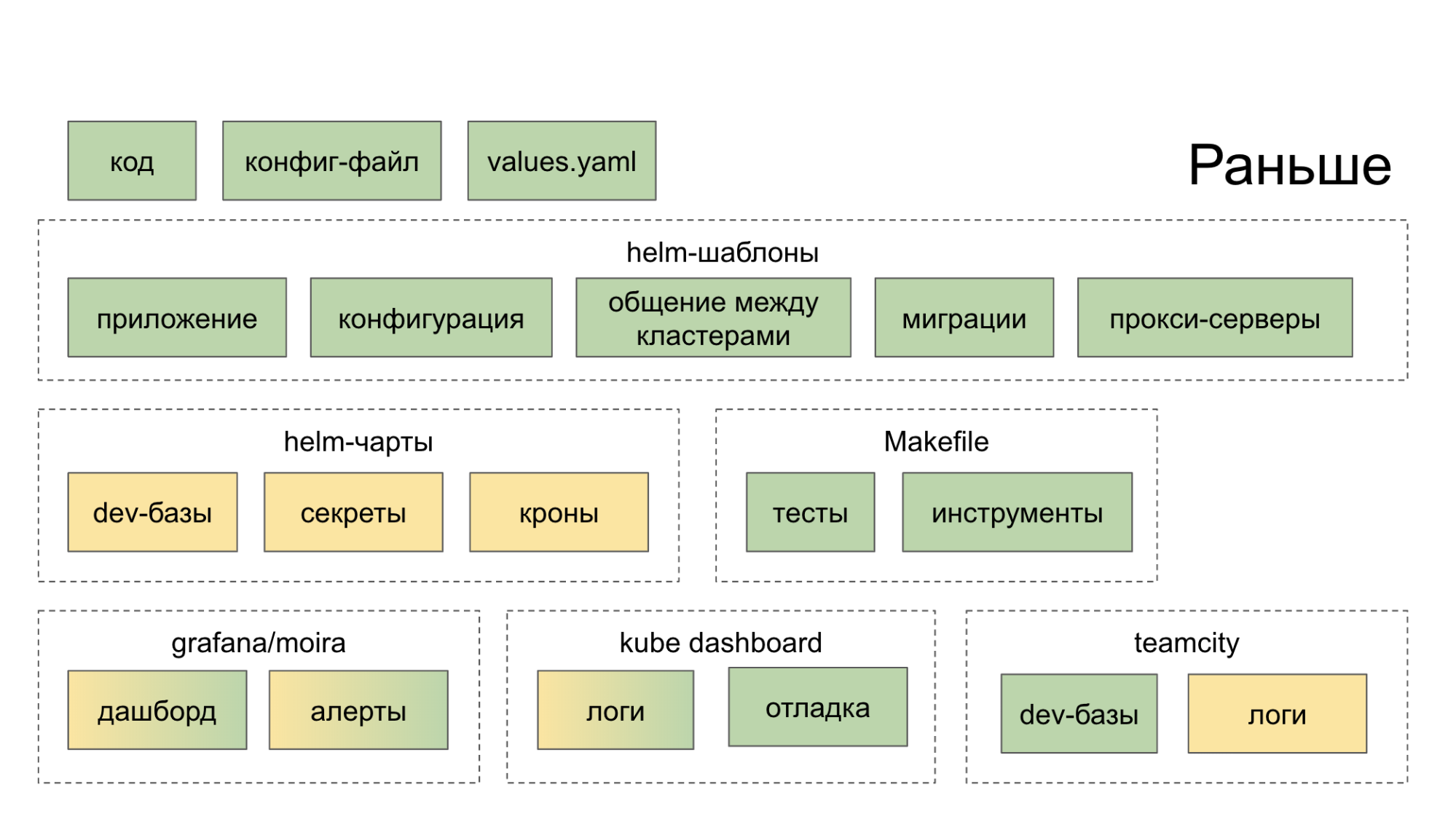
Agora, no utilitário PaaS CLI, uma equipe cria um novo serviço e mais duas adicionam um novo banco de dados e implantam no Stage.
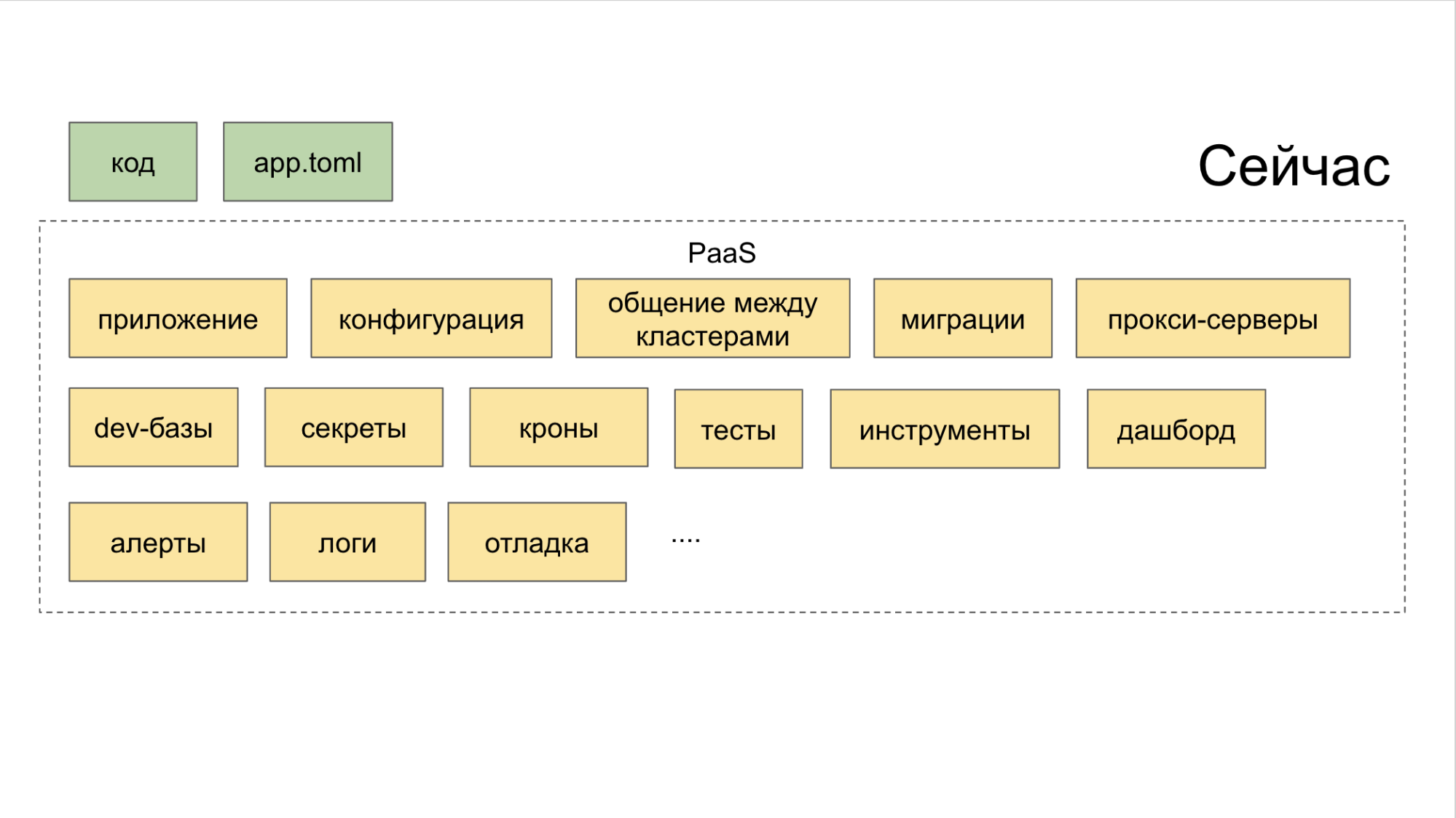
Como superar a era da "fragmentação de microsserviços"
Com uma arquitetura monolítica, para manter a consistência das mudanças no produto, os desenvolvedores foram forçados a descobrir o que estava acontecendo com seus vizinhos. Ao trabalhar na nova arquitetura, os contextos de serviço não dependem mais um do outro.
Além disso, para que a arquitetura de microsserviço seja eficaz, muitos processos precisam ser estabelecidos, a saber:
• registro;
Rastreamento de consultas (Jaeger);
• agregação de erros (Sentinela);
Status, mensagens, eventos do Kubernetes (processamento de fluxo de eventos);
• limite de corrida / disjuntor (você pode usar o Hystrix);
• controle da conectividade do serviço (usamos o Netramesh);
• monitoramento (Grafana);
Montagem (TeamCity);
• comunicação e notificação (Slack, email);
• rastreamento de tarefas; (Jira)
• compilação de documentação.
Para que, à medida que o sistema dimensione, não perca sua integridade e permaneça efetivo, repensamos a organização do trabalho dos microsserviços no Avito.
Como lidamos com microsserviços
A condução de uma "política partidária" unificada entre os muitos microsserviços que a Avito ajuda:
- divisão da infraestrutura em camadas;
- Conceito de plataforma como serviço (PaaS);
- monitoramento de tudo o que acontece com microsserviços.
As camadas de abstração de infraestrutura incluem três camadas. Vamos de cima para baixo.
A. Malha de serviço superior. No começo, tentamos o Istio, mas descobriu-se que ele usa muitos recursos, o que é muito caro em nossos volumes. Portanto, o engenheiro sênior da equipe de arquitetura Alexander Lukyanchenko desenvolveu sua própria solução - Netramesh (disponível em código aberto), que agora usamos em produção e que consome várias vezes menos recursos que o Istio (mas não faz tudo o que o Istio possui).
B. Médio - Kubernetes. Nele, implantamos e operamos microsserviços.
C. Metal inferior. Nós não usamos nuvens e coisas como o OpenStack, mas sentamos inteiramente no metal puro.
Todas as camadas são combinadas pelo PaaS. E essa plataforma, por sua vez, consiste em três partes.
I. Geradores controlados através do utilitário CLI. É ela quem ajuda o desenvolvedor a criar um microsserviço da maneira certa e com o mínimo de esforço.
II Coletor combinado com controle de todas as ferramentas através de um painel comum.
III Repositório . Isso interfere nos planejadores que definem automaticamente gatilhos para ações significativas. Graças a esse sistema, nenhuma tarefa é perdida apenas porque alguém se esqueceu de colocar uma tarefa no Jira. Usamos uma ferramenta interna chamada Atlas para isso.

A implementação de microsserviços no Avito também é realizada de acordo com um único esquema, que simplifica o controle sobre eles em cada estágio de desenvolvimento e lançamento.
Como o pipeline de desenvolvimento de microsserviço padrão funciona
Em termos gerais, a cadeia de criação de microsserviços é a seguinte:
CLI-push → Integração contínua → Assar → Implementar → Testes artificiais → Testes canários → Testes de compressão → Produção → Serviço.
Nós passamos por isso exatamente nesta sequência.
CLI-push
• Criando um microsserviço .
Lutamos por um longo tempo para ensinar cada desenvolvedor a fazer microsserviços. Incluindo escreveu no Confluence instruções detalhadas. Mas os esquemas mudaram e complementaram. Conclusão - um gargalo formado no início da jornada: demorou muito mais tempo para iniciar os microsserviços do que o permitido e, ainda assim, ao criá-los, os problemas geralmente surgiam.
No final, criamos um utilitário CLI simples que automatiza as etapas básicas ao criar um microsserviço. De fato, ele substitui o primeiro push git. É isso que ela faz.
- Cria um serviço de acordo com o modelo - passo a passo, no modo "assistente". Temos modelos para as principais linguagens de programação no servidor Avito: PHP, Golang e Python.
- Em um comando, ele implementa o ambiente para desenvolvimento local em uma máquina específica - o Minikube aumenta, os gráficos Helm são gerados e lançados automaticamente nos kubernetes locais.
- Conecta o banco de dados desejado. O desenvolvedor não precisa saber o IP, o login e a senha para acessar o banco de dados de que precisa - pelo menos localmente, pelo menos no Stage, pelo menos na produção. Além disso, o banco de dados é implantado imediatamente em uma configuração tolerante a falhas e com balanceamento.
- Ele próprio realiza uma montagem ao vivo. Digamos que um desenvolvedor consertou algo em um microsserviço por meio de seu IDE. O utilitário vê as alterações no sistema de arquivos e, com base nelas, remonta o aplicativo (para Golang) e reinicia. Para o PHP, simplesmente encaminhamos o diretório dentro do cubo e o live-reload é obtido "automaticamente".
- Gera autotestes. Sob a forma de discos, mas bastante adequado para uso.
• Implantar microsserviço .
Era um pouco triste implantar um microsserviço antes. Obrigatório obrigatório:
I. Dockerfile.
II Config.
III Um gráfico Helm, que é volumoso e inclui:
- os próprios gráficos;
- modelos;
- valores específicos, tendo em conta diferentes ambientes.
Nós nos livramos da dor de refazer os manifestos do Kubernetes, e agora eles são gerados automaticamente. Mas o mais importante, eles simplificaram a implantação até o limite. A partir de agora, temos um Dockerfile e o desenvolvedor grava toda a configuração em um único arquivo app.toml curto.
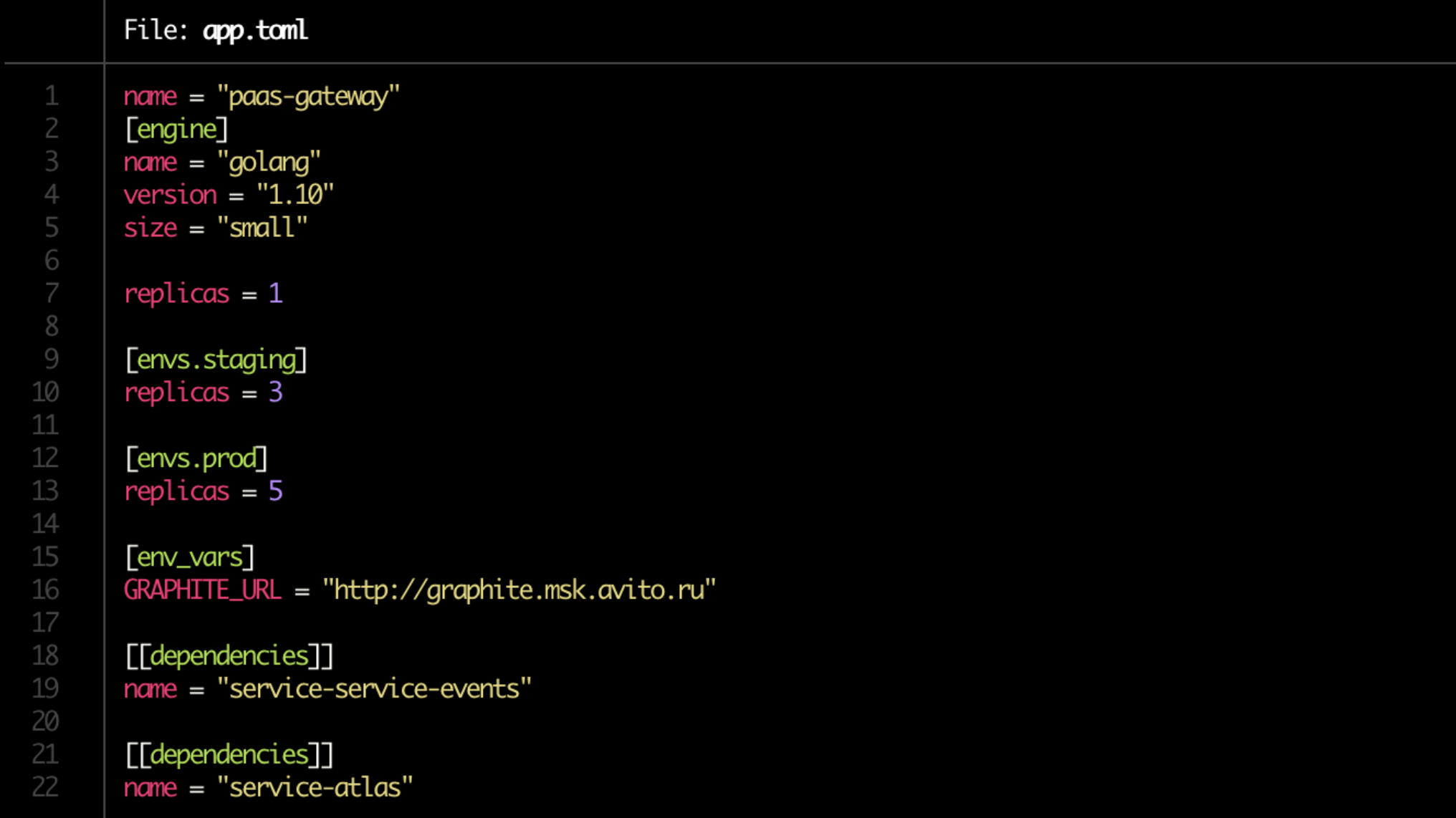
Sim, e no app.toml agora é assunto por um minuto. Anotamos onde quantas cópias do serviço aumentar (no servidor de desenvolvimento, na preparação, na produção), indicam suas dependências. Observe o tamanho da linha = "pequeno" no bloco [mecanismo]. Este é o limite que será alocado para o serviço através do Kubernetes.
Além disso, com base na configuração, todos os gráficos Helm necessários são gerados automaticamente e as conexões com os bancos de dados são criadas.
Validação básica. Tais verificações também são automatizadas.
Precisa acompanhar:
- existe um Dockerfile;
- existe app.toml;
- se existe documentação;
- se as dependências estão em ordem;
- são as regras dos alertas definidos.
Até o último ponto: o próprio proprietário do serviço indica quais métricas do produto monitorar.
• Preparação da documentação.
Ainda é um lugar problemático. Parece ser o mais óbvio, mas ao mesmo tempo um recorde "muitas vezes esquecido" e, portanto, um elo vulnerável na cadeia.
É necessário que a documentação esteja em cada microsserviço. Os seguintes blocos estão incluídos nele.
I. Breve descrição do serviço . Apenas algumas frases sobre o que ele faz e o que é necessário.
II Link para o diagrama da arquitetura . É importante que uma rápida olhada seja fácil de entender, por exemplo, se você usa o Redis para armazenamento em cache ou como o principal armazenamento de dados no modo persistente. No Avito, até agora este é um link para o Confluence.
III Runbook . Um pequeno guia para iniciar o serviço e os meandros do manuseio.
IV FAQ , onde seria bom prever os problemas que seus colegas podem encontrar ao trabalhar com o serviço.
V. Descrição dos terminais para a API . Se de repente você não indicou seu destino, certamente será pago por colegas cujos microsserviços estão relacionados ao seu. Agora usamos o Swagger para isso e nossa solução é chamada breve.
VI Etiquetas Ou marcadores que mostram a qual produto, funcionalidade, unidade estrutural da empresa à qual o serviço pertence. Eles ajudam a entender rapidamente, por exemplo, se você não está vendo a funcionalidade que seus colegas implementaram há uma semana para a mesma unidade de negócios.
VII O proprietário ou proprietários do serviço . Na maioria dos casos, ele - ou eles - pode ser determinado automaticamente usando PaaS, mas para o seguro, exigimos que o desenvolvedor os especifique manualmente.
Por fim, é uma boa prática revisar a documentação, semelhante à revisão de código.
Integração contínua
- Preparando repositórios.
- Criando um pipeline no TeamCity.
- Definir direitos.
- Procure por proprietários de serviços. Existe um esquema híbrido - marcação manual e automação mínima do PaaS. Um esquema totalmente automático falha ao transferir serviços de suporte para outra equipe de desenvolvimento ou, por exemplo, se um desenvolvedor de serviços for encerrado.
- Registro de serviço no Atlas (veja acima). Com todos os seus proprietários e dependências.
- Verifique as migrações. Verificamos se há algum potencialmente perigoso entre eles. Por exemplo, em um deles, uma tabela de alteração é exibida ou outra coisa que pode prejudicar a compatibilidade do esquema de dados entre diferentes versões do serviço. Em seguida, a migração não é executada, mas é feita uma assinatura - o PaaS deve sinalizar ao proprietário do serviço quando for seguro usá-lo.
Assar
O próximo estágio é o empacotamento de serviços antes da implantação.
- Crie o aplicativo. De acordo com os clássicos - na imagem do Docker.
- Geração de gráficos Helm para o próprio serviço e recursos relacionados. Incluindo para bancos de dados e cache. Eles são criados automaticamente de acordo com a configuração app.toml gerada no estágio de envio por CLI.
- Criando tickets para os administradores abrirem portas (quando necessário).
- Execução do teste de unidade e cálculo da cobertura do código . Se a cobertura do código estiver abaixo de um determinado valor limite, provavelmente o serviço falhará ainda mais - ao implantar. Se estiver à beira do permitido, um coeficiente de "pessimização" será atribuído ao serviço: então, na ausência de melhoria do indicador ao longo do tempo, o desenvolvedor receberá uma notificação de que não há progresso por parte dos testes (e algo precisa ser feito com isso).
- Consideração de limitações de memória e CPU . Nós escrevemos principalmente microsserviços em Golang e os executamos em Kubernetes. A partir daqui, há uma sutileza associada à peculiaridade do idioma Golang: por padrão, todos os kernels na máquina são usados na inicialização, se você não definir explicitamente a variável GOMAXPROCS e, quando vários serviços são iniciados na mesma máquina, eles começam a competir por recursos, interferindo entre si. Os gráficos abaixo mostram como o tempo de execução muda se você executar o aplicativo sem concorrência e na corrida por recursos. (A fonte dos gráficos está aqui ).

Prazo de execução, menos é melhor. Máximo: 643ms; Mínimo: 42ms. A foto é clicável.
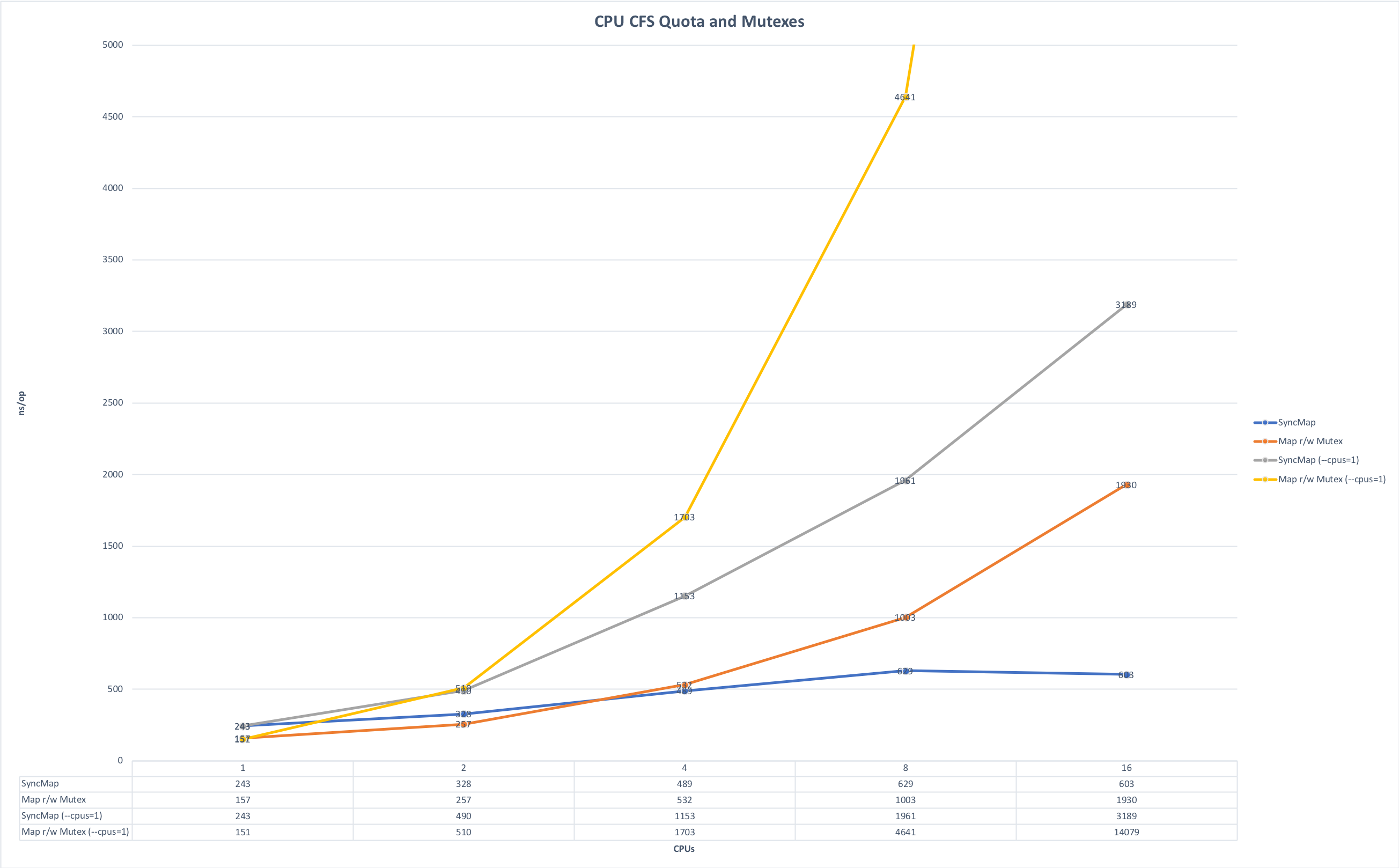
Hora da cirurgia, menos é melhor. Máximo: 14091 ns, Mínimo: 151 ns. A foto é clicável.
Na fase de preparação da montagem, você pode definir essa variável explicitamente ou usar a biblioteca automaxprocs dos funcionários do Uber.
Implantar
• verificação de convenções. Antes de começar a fornecer assemblies de serviço aos ambientes pretendidos, é necessário verificar o seguinte:
- pontos finais da API.
- Conformidade do esquema de pontos finais de respostas da API.
- formato de log.
- Definindo cabeçalhos para solicitações de serviço (o netramesh está fazendo isso agora)
- Configurando o token do proprietário ao enviar mensagens para o barramento (barramento de eventos). Isso é necessário para rastrear a conectividade dos serviços através do barramento. Você pode enviar dados idempotentes para o barramento que não aumenta a conectividade dos serviços (o que é bom), bem como dados comerciais que aprimoram a conectividade dos serviços (o que é muito ruim!). E no momento em que essa conectividade se torna um problema, entender quem escreve e lê o barramento ajuda a dividir corretamente os serviços.
Embora não haja muitas convenções em Avito, a piscina está se expandindo. Quanto mais esses acordos estiverem na forma de um comando compreensível e conveniente, mais fácil será manter a consistência entre os microsserviços.
Ensaios sintéticos
• Teste de malha fechada. Para ele, agora estamos usando o Hoverfly.io de código aberto. Primeiro, ele registra a carga real no serviço e, em seguida, apenas em um circuito fechado, ele emula.
• Teste de carga. Tentamos trazer todos os serviços para o desempenho ideal. E todas as versões de cada serviço devem ser submetidas a testes de estresse - para que possamos entender o desempenho atual do serviço e a diferença com as versões anteriores do mesmo serviço. Se, após uma atualização de serviço, seu desempenho cai uma vez e meia, isso é um sinal claro para seus proprietários: você precisa se aprofundar no código e corrigir a situação.
Criamos os dados coletados, por exemplo, para implementar corretamente o dimensionamento automático e, no final, entender como o serviço é escalável.
Durante o teste de estresse, verificamos se o consumo de recursos atende aos limites estabelecidos. E nos concentramos principalmente em extremos.
a) Observamos a carga total.
- Muito pequeno - provavelmente algo não funcionará se a carga cair repentinamente várias vezes.
- Muito grande - é necessária otimização.
b) Observamos o ponto de corte pelo RPS.
Aqui, examinamos a diferença entre a versão atual e a anterior e o número total. Por exemplo, se um serviço produz 100 rps, é mal escrito ou é a sua especificidade, mas, em qualquer caso, esta é uma ocasião para examinar atentamente o serviço.
Se, pelo contrário, houver muitos RPS, talvez algum bug e alguns dos pontos de extremidade parem de executar a carga, mas algum tipo de return true; acionado return true;
Testes de canário
Após a aprovação dos testes sintéticos, executamos o microsserviço em um pequeno número de usuários. Começamos com cuidado, com uma pequena fração da audiência estimada do serviço - menos de 0,1%. Nesse estágio, é muito importante que as métricas técnicas e de produto corretas sejam estabelecidas no monitoramento, para que mostrem o problema no serviço o mais rápido possível. O tempo mínimo para um teste de canário é de 5 minutos, o principal é de 2 horas. Para serviços complexos, definimos o horário no modo manual.
Analisamos:
- métricas específicas do idioma, em particular os trabalhadores de php-fpm;
- erros no Sentry;
- status das respostas;
- tempo de resposta (tempo de resposta), preciso e médio;
- latência;
- exceções processadas e não processadas;
- métricas de alimentos.
Teste de compressão
O Squeeze Testing também é chamado de teste de extrusão. O nome da técnica foi introduzido no Netflix. Sua essência é que, a princípio, preenchemos uma instância com tráfego real para o estado de falha e, assim, definimos seu limite. Em seguida, adicione outra instância e carregue esse par - novamente ao máximo; vemos o teto e o delta com o primeiro "aperto". E assim, conectamos uma instância por etapa e calculamos o padrão de mudanças.
Os dados de teste por meio de "extrusão" também são agregados ao banco de dados de métricas gerais, onde enriquecemos os resultados do carregamento artificial com eles ou até os substituímos por "sintéticos".
Produção
• escala. Ao implantar o serviço de produção, rastreamos como ele é dimensionado. Nesse caso, monitorar apenas os indicadores da CPU, em nossa experiência, é ineficiente. O dimensionamento automático com o benchmarking de RPS em sua forma pura funciona, mas apenas para determinados serviços, por exemplo, streaming on-line. Portanto, estamos analisando principalmente as métricas de produtos específicas de aplicativos.
Como resultado, ao escalar, analisamos:
- indicadores de CPU e RAM,
- o número de pedidos na fila,
- tempo de resposta
- previsão com base em dados históricos.
Ao dimensionar um serviço, também é importante monitorar suas dependências para que não sejamos o primeiro serviço da cadeia de dimensionamento, e aqueles a quem ele se refere caem sob carga. Para estabelecer uma carga aceitável para todo o pool de serviços, examinamos os dados históricos do serviço dependente "mais próximo" (com base em uma combinação de CPU e RAM e métricas específicas do aplicativo) e os comparamos com os dados históricos do serviço de inicialização e assim por diante ao longo de toda a "cadeia de dependência" ", De cima para baixo.
Serviço
Depois que o microsserviço é colocado em operação, podemos colocar gatilhos nele.
Aqui estão situações típicas nas quais dispara fogo.
- Migrações potencialmente perigosas detectadas.
- Atualizações de segurança foram lançadas.
- O serviço em si não é atualizado há muito tempo.
- A carga no serviço diminuiu significativamente ou qualquer uma de suas métricas de produto está além da faixa normal.
- O serviço deixou de atender aos novos requisitos da plataforma.
Alguns dos gatilhos são responsáveis pela estabilidade do trabalho, outros em função da manutenção do sistema - por exemplo, alguns serviços não são implantados há muito tempo e sua imagem básica deixa de passar nas verificações de segurança.
Dashboard
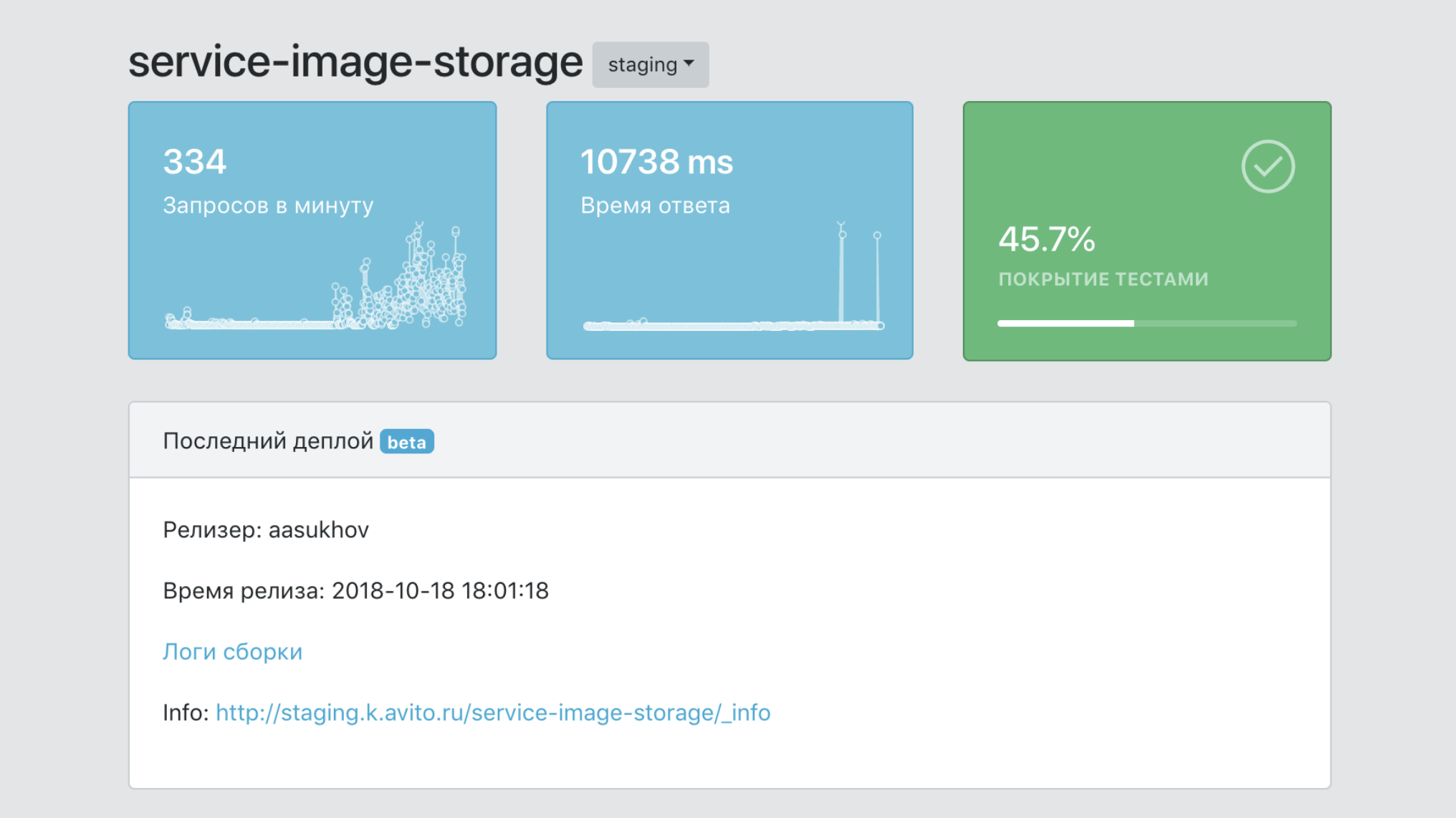
Em resumo, o painel é o painel de controle de todo o nosso PaaS.
- Um único ponto de informação sobre um serviço, com dados sobre sua cobertura com testes, o número de suas imagens, o número de cópias de produção, versões etc.
- Uma ferramenta para filtrar dados por serviços e etiquetas (marcadores de pertencer a unidades de negócios, funcionalidade do produto etc.)
- Meios de integração com ferramentas de infraestrutura para rastreamento, registro em log, monitoramento.
- Uma única documentação de ponto de serviço.
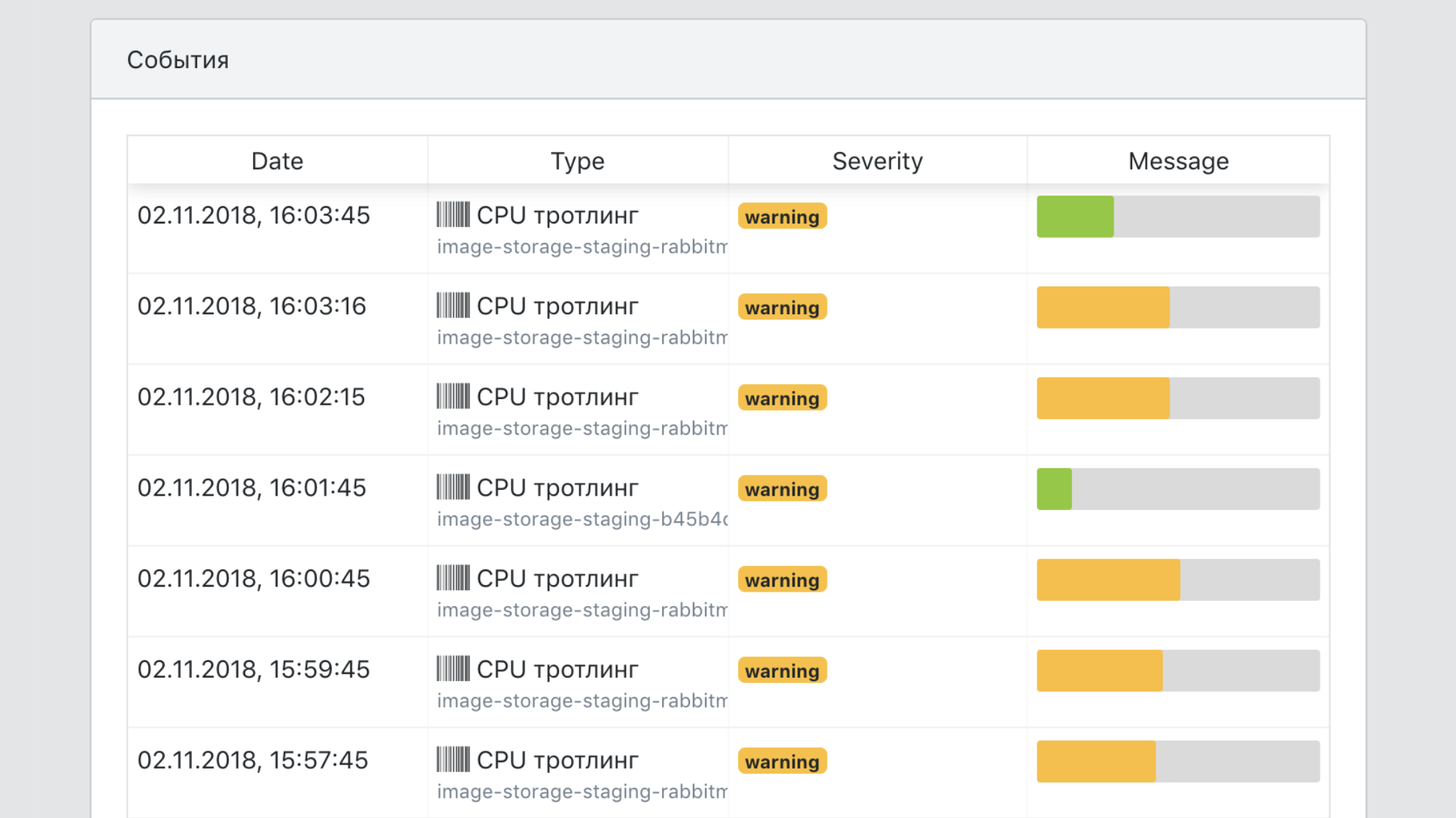
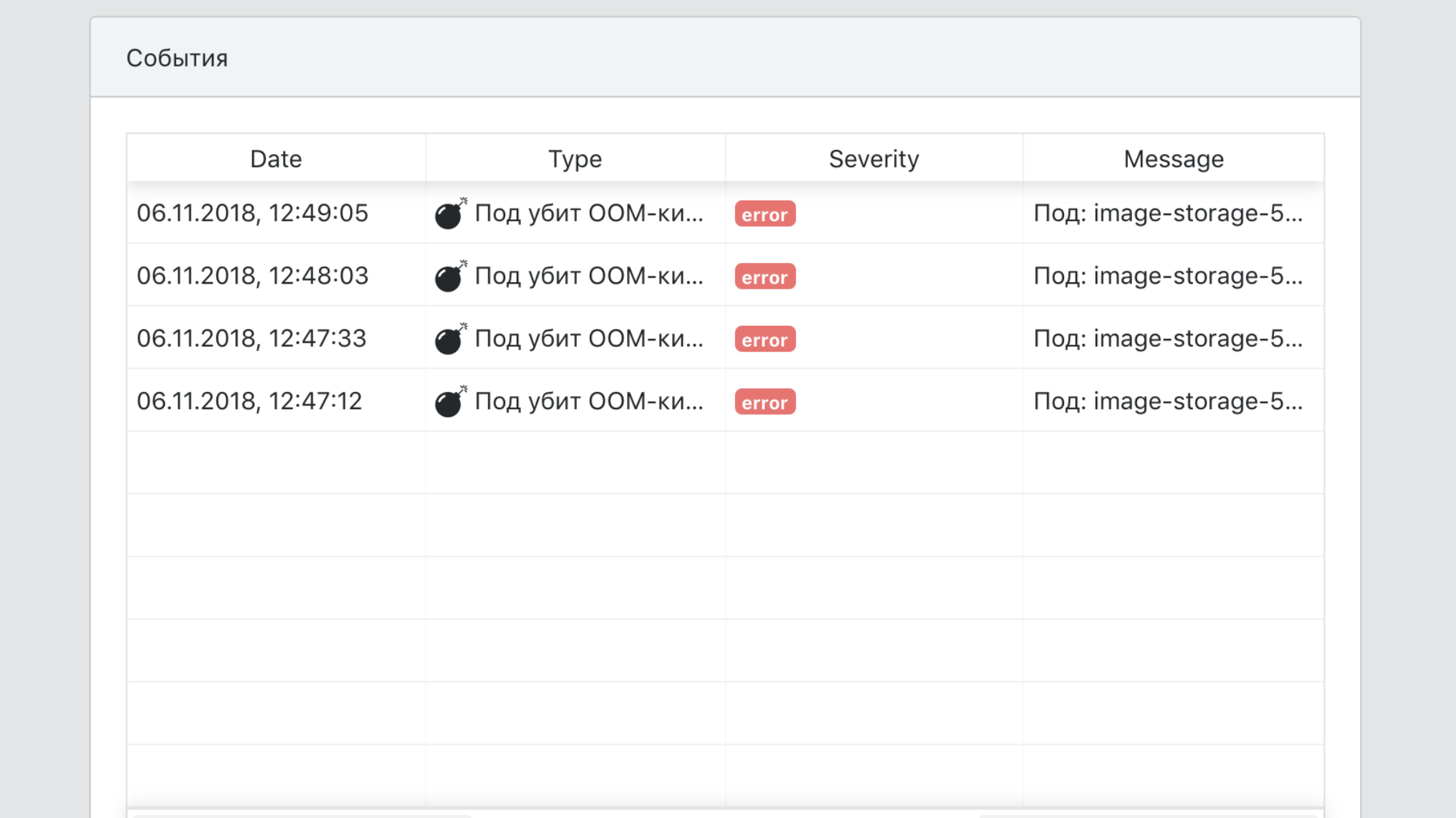
- Um único ponto de vista de todos os eventos de serviço.
Total
Antes da introdução do PaaS, um novo desenvolvedor poderia passar várias semanas classificando todas as ferramentas necessárias para executar um microsserviço na produção: Kubernetes, Helm, nossos recursos internos do TeamCity, configurando a conexão com bancos de dados e caches de forma tolerante a falhas, etc. Agora, leva algumas horas para ler o início rápido e fazer o próprio serviço.
Eu fiz um relatório sobre este tópico para o HighLoad ++ 2018, você pode assistir ao vídeo e apresentação .
Faixa bônus para quem leu até o fim
Em Avito, organizaremos um treinamento interno de três dias para desenvolvedores de Chris Richardson , especialista em arquitetura de microsserviços. Queremos dar a oportunidade de participar dele para um dos leitores deste post. Aqui está um programa de treinamento.
O treinamento será realizado de 5 a 7 de agosto em Moscou. Estes são dias úteis que serão totalmente ocupados. O almoço e o treinamento estarão em nosso escritório, e o participante escolhido paga pela viagem e pela acomodação.
Você pode se inscrever para participar deste formulário do Google . De você - a resposta para a pergunta: por que exatamente você precisa participar do treinamento e informações sobre como entrar em contato com você? Responda em inglês, porque Chris escolherá o participante que participar do treinamento.
Anunciaremos o nome do participante do treinamento como uma atualização para esta postagem nas redes sociais da Avito para desenvolvedores (AvitoTech no Facebook , Vkontakte , Twitter ) até 19 de julho.
UPD, 19/07: recebemos dezenas de solicitações. Chris os examinou e escolheu um participante: juntamente com nossos colegas, Andrei Igumnov irá estudar. Parabéns!