Olá pessoal. Minha equipe na Tinkoff está construindo sistemas de recomendação. Se você está satisfeito com seu reembolso mensal, esse é o nosso negócio. Também construímos um sistema de recomendação de ofertas especiais de parceiros e estamos envolvidos em coleções individuais de histórias no aplicativo Tinkoff. E adoramos participar de competições de aprendizado de máquina para nos manter em boa forma.
Durante dois meses, de 18 de fevereiro a 18 de abril, foi realizada uma competição no Boosters.pro para construir um sistema de recomendação com dados reais de um dos maiores cinemas on-line russos Okko . Os organizadores pretendiam melhorar o sistema de recomendação existente. No momento, a competição está disponível no modo sandbox , no qual você pode testar suas abordagens e aprimorar suas habilidades na criação de sistemas de recomendação.
Descrição dos dados
O acesso ao conteúdo em Okko é realizado através do aplicativo na TV ou smartphone ou através da interface da web. O conteúdo pode ser alugado®, comprado (P) ou visualizado por assinatura (S). O organizador da competição forneceu dados sobre visualizações por N dias (N> 60). Além disso, estavam disponíveis informações sobre as classificações e os indicadores adicionados. Vale lembrar um detalhe importante: se o usuário assistiu a um filme várias vezes ou a vários episódios da série, apenas a data da última transação e o tempo total gasto por unidade de conteúdo serão registrados no tablet.
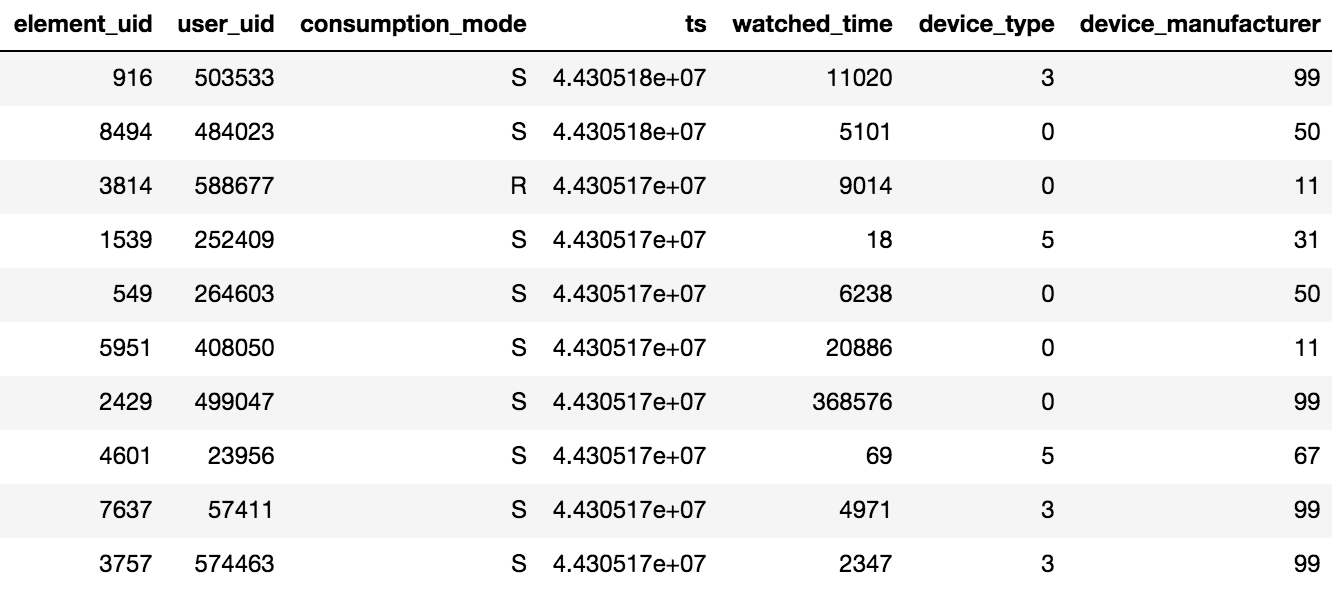
Foram fornecidos cerca de 10 milhões de transações, 450 mil classificações e 950 mil fatos de bookmarking para 500 mil usuários.
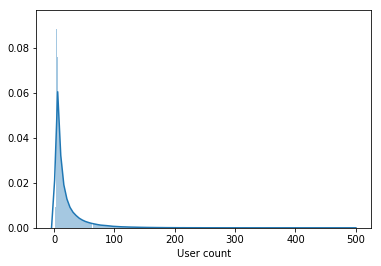
A amostra contém não apenas usuários ativos, mas também usuários que assistiram a alguns filmes durante todo o período.
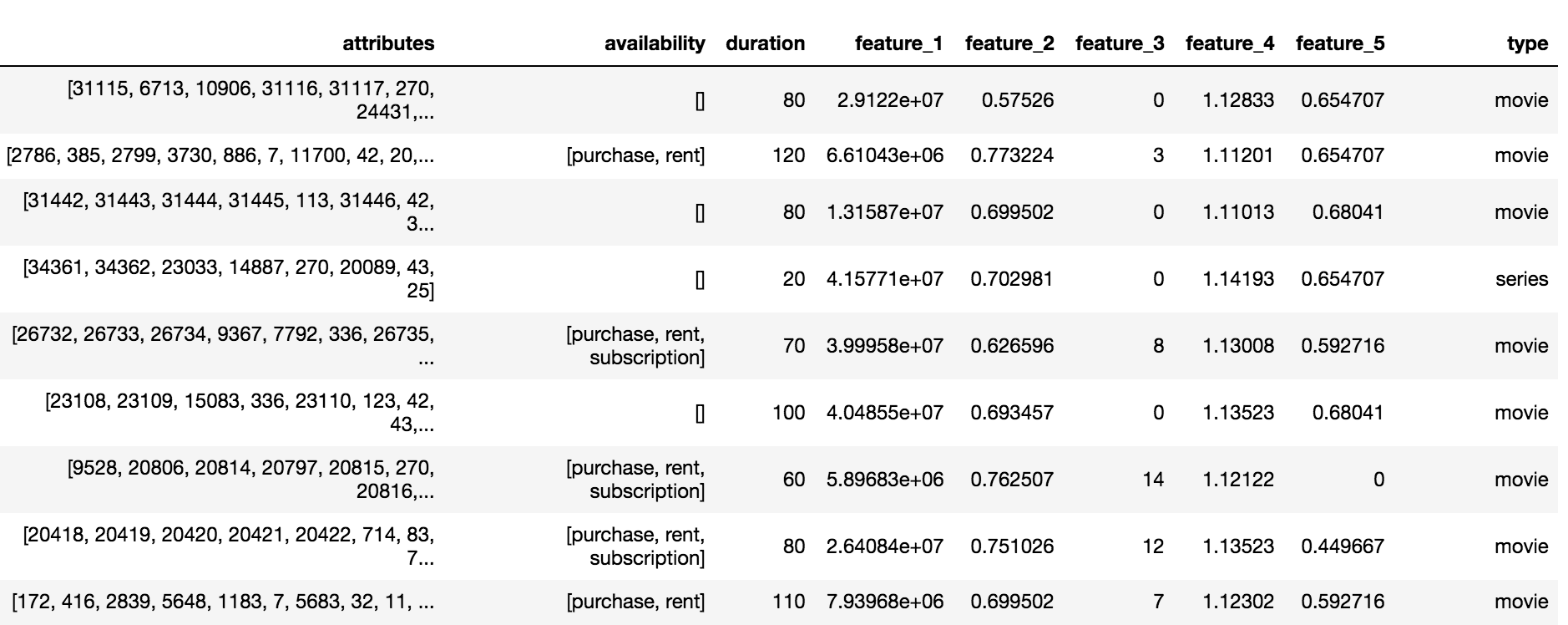
O catálogo Okko contém três tipos de conteúdo: filmes (filme), série (série) e filmes em série (filme multipart), totalizando 10.200 objetos. Para cada objeto, estavam disponíveis um conjunto de atributos e atributos anônimos (recurso_1, ..., recurso_5), disponibilidade, subscrição, aluguel ou compra e duração.
Variável e métrica de destino
A tarefa necessária para prever muito conteúdo que o usuário consumiria nos próximos 60 dias. Acredita-se que um usuário consuma conteúdo se:
- Compre ou alugue
- Assista a mais da metade do filme por assinatura
- Assista a mais de um terço da série por assinatura
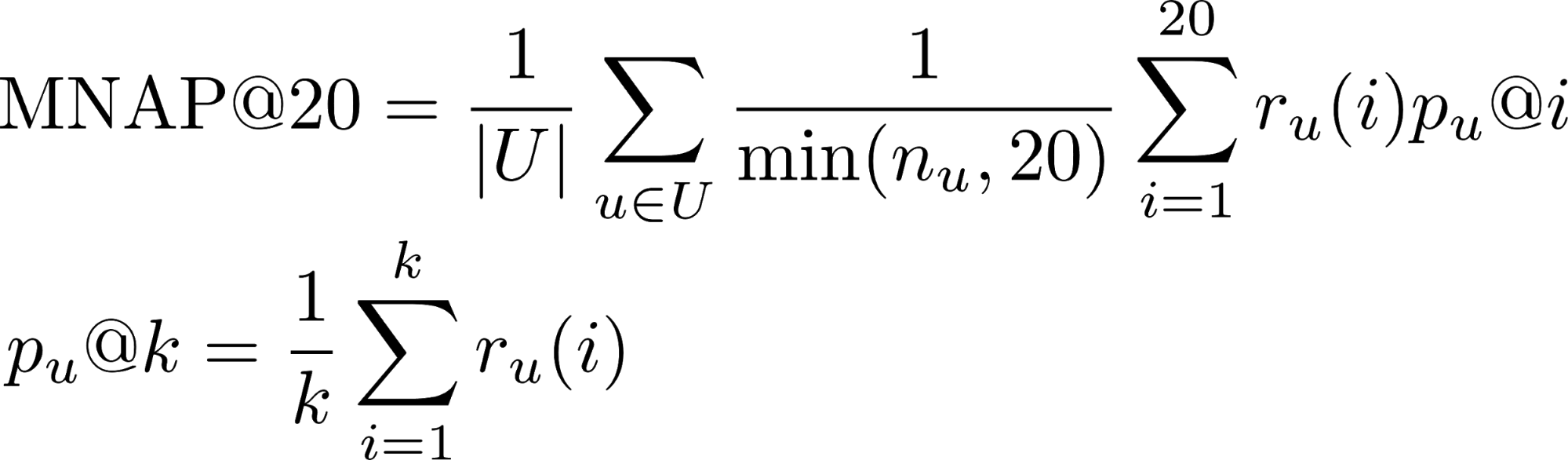
- r_u (i) - se o usuário consumiu o conteúdo previsto para ele no lugar i (1 ou 0)
- n_u - o número de elementos que o usuário consumiu durante o período de teste
- U - muitos usuários de teste
Você pode aprender mais sobre métricas para a tarefa de classificação nesta postagem .
A maioria dos usuários assiste filmes até o fim, então a participação da classe positiva nas transações é de 65%. A qualidade do algoritmo foi avaliada utilizando um subconjunto de 50 mil usuários da amostra apresentada.
Classificação agregada
A decisão da concorrência começou com a agregação de todas as interações do usuário com o conteúdo em uma única escala de classificação. Supunha-se que, se o usuário comprou o conteúdo, isso significa interesse máximo. O filme é mais curto que a série, portanto, para visualizar a série como um todo, você precisa dar mais pontos. Como resultado, o rating agregado foi formado de acordo com as seguintes regras:
- Partilha de filme * 5
- Compartilhamento de programa de TV * 10
- [Marcar o filme como favorito] * 0,5
- [Marcando a série como favorito] * 1,5
- [Compra / aluguel de conteúdo] * 15
- Avaliação + 2
Modelo de primeiro nível
Os organizadores forneceram uma solução básica baseada na filtragem colaborativa com escalas Tf-IDF. A adição de todos os tipos de interações à classificação agregada, aumentando o número de vizinhos mais próximos de 20 para 150 e substituindo o Tf-IDF por pesos BM25, bateu cerca de 0,03 no LB (Quadro de Líderes).
Inspirado no cargo da equipe que ficou em terceiro lugar no RecSys Challenge 2018 , escolhi o modelo LightFM com perda WARP como o segundo modelo base. O LightFM com hiper parâmetros selecionados: learning_rate, no_components, item_alpha, user_alpha, max_sampled deu 0,033 no LB.

A validação do modelo foi realizada no prazo: os primeiros 80% das interações caíram no trem e os 20% restantes na validação. Para uma submissão no LB, um modelo foi treinado em todo o conjunto de dados com parâmetros selecionados para validação.
Model Blending
No estágio anterior, acabou criando duas linhas de base fortes, além disso, suas recomendações se cruzavam em média para 60% do conteúdo recomendado. Se houver dois modelos fortes e ao mesmo tempo fracamente correlacionados, sua mistura é um passo razoável.
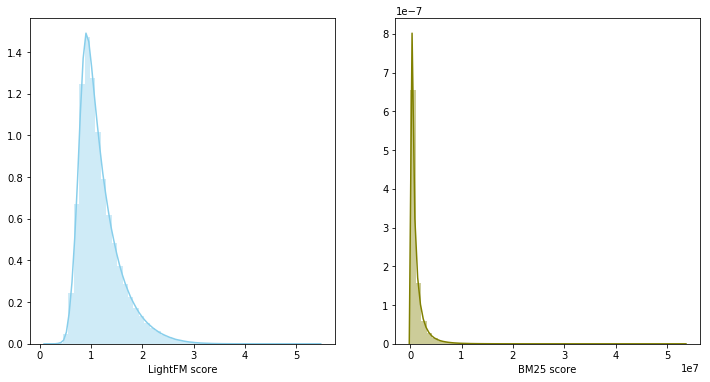
Nesse caso, as pontuações do modelo pertencem a diferentes distribuições e têm escalas diferentes, por isso foi decidido usar a soma das classificações para combinar os dois modelos. A mistura do modelo rendeu 0,0347 em LB.

Modelo de segundo nível
Os sistemas recomendadores costumam usar uma abordagem de dois níveis para a construção de modelos: primeiro, os principais candidatos são selecionados por um modelo simples de primeiro nível; depois, o topo selecionado é re-classificado por um modelo mais complexo, com a adição de um grande número de recursos.

O conjunto de dados foi dividido no tempo nas partes de treinamento e validação. Uma seleção de recomendações foi coletada para a parte de validação de cada usuário, consistindo na combinação das previsões de 200 principais dos modelos de primeiro nível, com exceção dos filmes já assistidos. Além disso, foi necessário ensinar o modelo a reorganizar a parte superior resultante para cada usuário. O problema foi formulado em termos de classificação binária. Um par (usuário, conteúdo) pertencia à classe positiva somente se o usuário consumisse o conteúdo durante o período de validação. Como modelo de segundo nível, foi utilizado o aumento de gradiente, a saber, o pacote LightGBM.
Sinais
Os modelos de primeiro nível para pares (usuário, conteúdo) avaliam a relevância na forma de uma velocidade, classificando em ordem decrescente você pode obter uma classificação. O modelo treinado nos sinais de classificação e velocidade, juntamente com os sinais do catálogo de conteúdo, eliminou 0,0359 no LB.
A partir da forma de distribuição do primeiro dos recursos anonimizados, concluiu-se que é a data em que o filme apareceu no catálogo; portanto, o modelo foi fortemente treinado para esse recurso com o esquema de validação selecionado. A remoção de uma característica da amostra aumentou em LB para 0,0367
O modelo LightFM, além de prever a relevância do conteúdo para o usuário, retorna dois vetores: viés de item e viés de usuário, que se correlacionam com o grau de popularidade do conteúdo e o número de filmes visualizados pelo usuário, respectivamente. A adição de sinais aumentou a velocidade no LB para 0,0388 .
Você pode atribuir uma classificação para um par (usuário, conteúdo) antes ou depois da exclusão de filmes já assistidos. Alterações no método para este último proporcionaram um aumento no LB para 0,0395 .
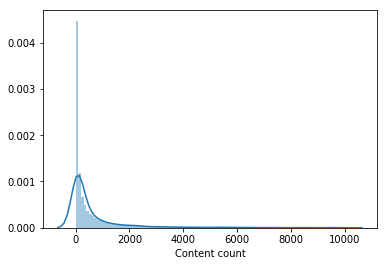
Quase ninguém assistiu uma parte significativa do catálogo de filmes. O conteúdo assistido por menos de 100 usuários foi removido da amostra para treinar um modelo de segundo nível, o que reduziu o catálogo pela metade. A remoção de conteúdo impopular tornou a seleção de modelos de primeiro nível mais relevante e somente depois disso o vetor de usuários do LightFM melhorou a velocidade de validação e aumentou o LB para 0,0429 .
Além disso, um sinal foi adicionado - o usuário adicionou o marcador ao livro, mas não analisou o período do trem, que aumentou a velocidade no LB para 0,0447 . Além disso, sinais sobre a data da primeira e da última transação foram adicionados e aumentaram a velocidade para 0,0457 no LB.

Vamos considerar este modelo final. Os mais significativos foram sinais de modelos de primeiro nível e sinais anonimizados do catálogo de conteúdo.
Os seguintes recursos não aumentaram para o modelo final:
- número de favoritos + compartilhamento de conteúdo visualizado dos favoritos - 0,0453 LB
- o número de filmes comprados 0,0451 LB
Mas ao se misturar com o modelo final, eles nocautearam 0,0465 no LB. Inspirados no resultado da mistura, os seguintes modelos foram treinados separadamente:
- com frações diferentes da amostra de treinamento para o modelo de primeiro nível. A divisão de 90% / 10% deu um aumento, em contraste com a divisão de 95% / 5% e 70% / 30%.
- com um método de agregação de classificação modificado.
- com a adição de filmes impopulares ao conjunto de treinamento para um modelo de segundo nível. Para cada unidade de conteúdo, uma compilação de 1000 usuários foi compilada.
A mistura final de 6 modelos permitiu atingir 0,0469678 no LB, o que correspondeu ao 5º lugar.

Na parte privada, houve um abalo, que levou a solução ao 2º lugar. Penso que a solução acabou por ser sustentável graças à mistura de um grande número de modelos.
Não inserido
No processo de solução da competição, foram gerados muitos sinais que pareciam definitivamente entrar, mas infelizmente. Sinais e abordagens mais confiáveis:
- Atributos de conteúdo anônimo. Não se sabia ao certo o que eles continham, mas todos os participantes da competição acreditavam que continham informações sobre atores, diretores, compositores ... Na minha decisão, tentei adicioná-los em vários formatos: os mais populares como personagens binários, crie uma matriz de conteúdo atributos usando LightFM e BigARTM e, em seguida, retire os vetores e adicione-os ao modelo de segundo nível.
- Vetores de conteúdo do modelo LigthFM no modelo de segundo nível.
- Atributos dos dispositivos dos quais o usuário visualizou o conteúdo.
- Diminuindo o peso do conteúdo popular para um modelo de segundo nível.
- A proporção de filmes / programas de TV em relação ao número total de conteúdo visualizado.
- Métricas de classificação do CatBoost.
Fatos interessantes sobre a competição
- A solução Top1 acabou sendo pior que o modelo de produto okko 0,048 vs 0,062. Deve-se ter em mente que o modelo do produto já foi lançado no momento da amostragem.
- Cerca de uma semana após o início da competição, o conjunto de dados foi alterado. Para aqueles que participaram desde o início, adicionaram 30 envios, que se esgotaram inesperadamente após a fusão das equipes.
- A validação nem sempre se correlacionou com o LB, o que indicava uma possível agitação.
Código de decisão
A solução está disponível no github na forma de dois laptops jupyter: agregação de classificação, modelos de treinamento do primeiro e do segundo níveis.
Uma solução de terceiro lugar também está disponível no github .
A decisão dos organizadores
Em vez de mil palavras, anexo os principais recursos dos organizadores.
Além disso, os caras da Okko publicaram um artigo no qual conversam sobre os estágios de desenvolvimento de seu mecanismo de recomendação.
PS aqui, você pode ver o desempenho no Data Fest 6 sobre esta solução para o problema.