
Se algum de seus projetos usar os dados armazenados no banco de dados Azhurov, é bem possível que você tenha a oportunidade de usar a pesquisa de dados usando a pesquisa do Azure. Você pode pesquisar não apenas por bancos de dados (Azure Cosmos DB, Banco de Dados SQL do Azure, SQL Server hospedado em uma VM do Azure), mas também pelo Blob (Armazenamento de Blob do Azure, Armazenamento de Tabela do Azure).
A pesquisa possui uma tarifa gratuita, que permite criar até três índices com um tamanho total de até 50 Mb. A tarifa gratuita não possui recursos de balanceamento de carga, mas é bastante adequada para uso.
Lidar com a pesquisa me pareceu bastante simples (embora nem sempre seja óbvio). Existem 3 tipos de objetos: fonte de dados, índice e indexador. O objeto principal, talvez, é o índice. É ele quem é responsável por como pesquisar e o que exatamente procurar. A fonte de dados é uma conexão de dados e o indexador é um trabalho que atualiza os dados do índice.
A interface do usuário do portal permite importar dados e criar todos os três objetos. A oportunidade estará de passagem e acrescentará recursos cognitivos à pesquisa. Se o banco de dados SQL estiver na assinatura, você poderá selecioná-lo ao criar a fonte de dados. Embora a senha, por algum motivo, você ainda precise digitar. Se você deseja usar o Cosmos DB, precisará inserir a cadeia de conexão manualmente. Não se esqueça de indicar na linha e no banco de dados, adicionando no final da linha Database = YOUR_BASE_NAME
Depois de escolher uma fonte de dados, você será solicitado a usar os recursos de pesquisa cognitiva. O conjunto de habilidades padrão ainda é muito pequeno: você pode definir o idioma, extrair nomes, nomes de organizações, lugares e frases-chave. Há também uma oportunidade interessante para determinar a natureza do texto para emoções positivas ou negativas usando a detecção de sentimentos. Essa habilidade deve ser conveniente para uso com análises de produtos em lojas online. É possível criar sua própria habilidade usando a descrição da API.
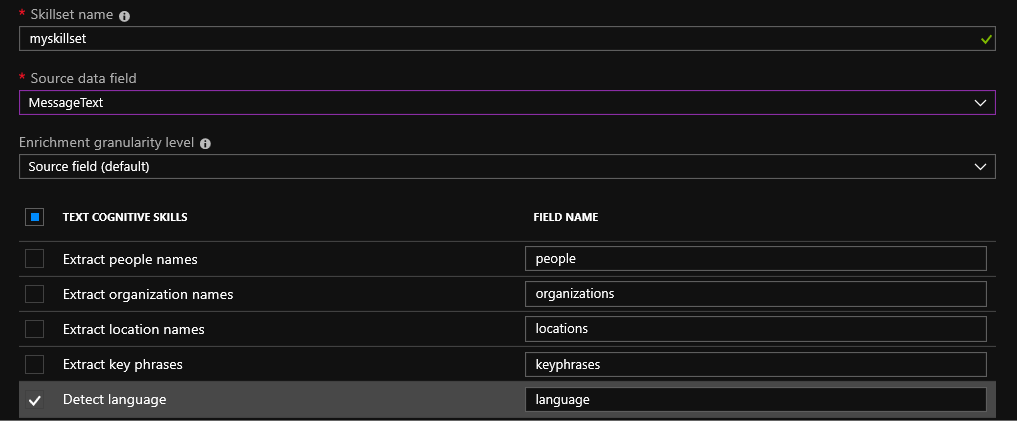
Para arquivos enviados para o blob, o OCR (reconhecimento óptico de caracteres) é possível. É possível o reconhecimento de texto manuscrito (até agora apenas em inglês) e impresso. Usando serviços cognitivos, é possível identificar vários objetos na foto. Por exemplo, lugares famosos ou celebridades.
O próximo passo é criar um índice. A única opção para o modo de pesquisa hoje em dia é "analysisInfixMatching"
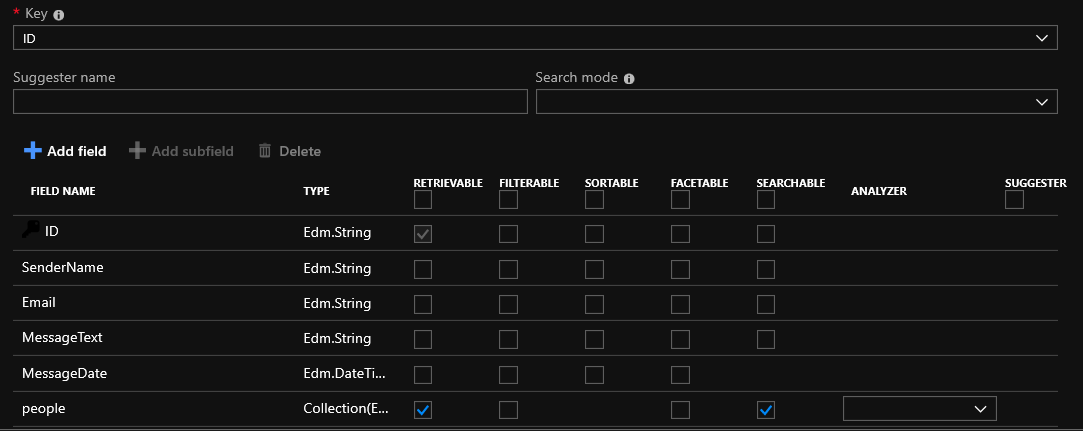
Nesse ponto, você pode marcar as caixas próximas aos campos da sua tabela ou adicionar um novo campo ao índice. Apenas no caso, explicarei as possibilidades dos campos:
Recuperável - o campo estará presente nos resultados da pesquisa
Filtrável - o valor do campo pode ser filtrado
Classificável - você pode classificar o resultado por este campo
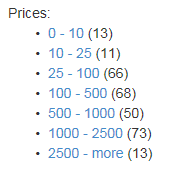
Facetable - um tipo de agrupamento de acordo com certas características. Por exemplo, usando a seguinte expressão facet = listPrice, values: 10 | 25 | 100 | 500 | 1000 | 2500, é possível obter a seguinte divisão dos resultados em grupos
Pesquisável - este campo pesquisará
O campo Analisador sugere a escolha de um analisador para vários idiomas. 2 versões são usadas - Lucene e Microsoft . Para entender qual é a diferença, você precisa entender qual é a diferença entre os dois termos a seguir:
Stamming é o processo de encontrar a base de uma palavra para uma determinada palavra-fonte. Caule (inglês) - caule, caule, origem. Stemming usa algoritmos. Freqüentemente trunca as palavras removendo sufixos e terminações, obtendo a base da palavra.
Lematização é o processo de reduzir uma forma de palavra a um lema - sua forma normal (vocabulário). O lema é a forma básica canônica da palavra. A lematização usa uma pesquisa de dicionário contendo várias formas de palavras.
O analisador Lucene usa o stemming. O analisador da Microsoft usa lematização.
Por padrão, se nada for selecionado, o Lucene será usado. Mas se você estiver procurando dados em um idioma específico, é indiscutivelmente melhor usar um analisador para esse idioma.
Suggester - permite dar dicas com documentos contendo o texto digitado usando as letras iniciais da pesquisa.
Se você estiver usando o testador na Pesquisa do Azure no aplicativo cliente, terá duas opções para usá-lo: o próprio contador ou o preenchimento automático . Em resumo, o prompt sugere completamente toda a linha do campo da tabela e o preenchimento automático oferece apenas a conclusão de uma palavra ou expressão a partir de algumas palavras. O melhor artigo sobre as diferenças entre os modos de prompt e preenchimento automático é descrito no seguinte artigo: Preenchimento automático na Pesquisa do Azure agora em visualização pública Este artigo tem gifs muito visuais.
No estágio de criação do indexador, você deve especificar uma coluna de marca d'água alta . Este é um campo que muda toda vez que um registro é alterado. Geralmente, isso é algo como um campo com a data da última alteração ou um campo _ts no Cosmos DB. Durante a indexação, se o valor do campo for alterado, o índice também será alterado.
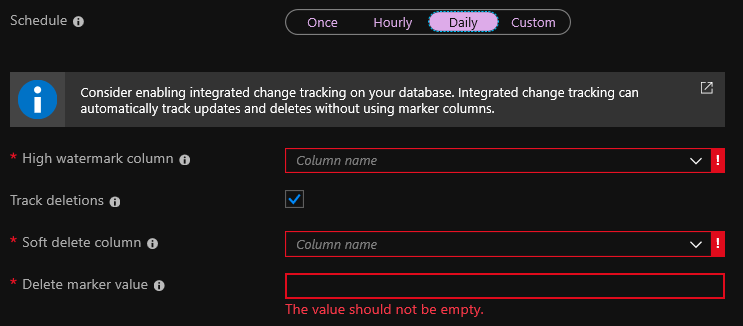
Excluir exclusões de faixas é uma opção para excluir entradas do índice automaticamente. Mas para isso, você deve ter a exclusão virtual configurada no seu banco de dados. Se você usar a exclusão suave, ao excluir um registro, ele não será excluído, mas simplesmente marcado como excluído. A opção padrão é adicionar o campo isDeleted ao banco de dados e configurá-lo como true se o registro for excluído.
Como alternativa, sempre que você excluir uma entrada do banco de dados, poderá enviar uma solicitação de exclusão da pesquisa para a API de Pesquisa do Azure. Nesse caso, a caixa de seleção Exclusões do Trak pode ser omitida. Mas eu realmente não gosto dessa opção, porque se a solicitação de exclusão não funcionar, o registro permanecerá no índice. Quanto a mim, não há oportunidade suficiente para reconstruir o índice uma vez em um determinado período de tempo completamente.
Apesar de toda a conveniência do portal, após a criação, você pode adicionar alguns novos campos ao índice, mas não pode alterar os existentes. O que fazer se você precisar mudar alguma coisa? Você pode recriar o índice. Exclua o existente e crie um novo contendo as alterações necessárias. Usar o portal para fazer isso é uma tarefa bastante sombria. Eu uso a API para esses fins. Usando um aplicativo como o Postman, é possível obter o JSON do índice e usá-lo para gravar uma solicitação de criação de índice. Só é necessário fazer pequenas alterações (por exemplo, remova os campos do sistema "@ odata.context" e "@ odata.etag").
Para trabalhar com a API, você precisa pegar a chave do portal, que deve ser adicionada ao cabeçalho de cada solicitação da API. A chave é retirada aqui:
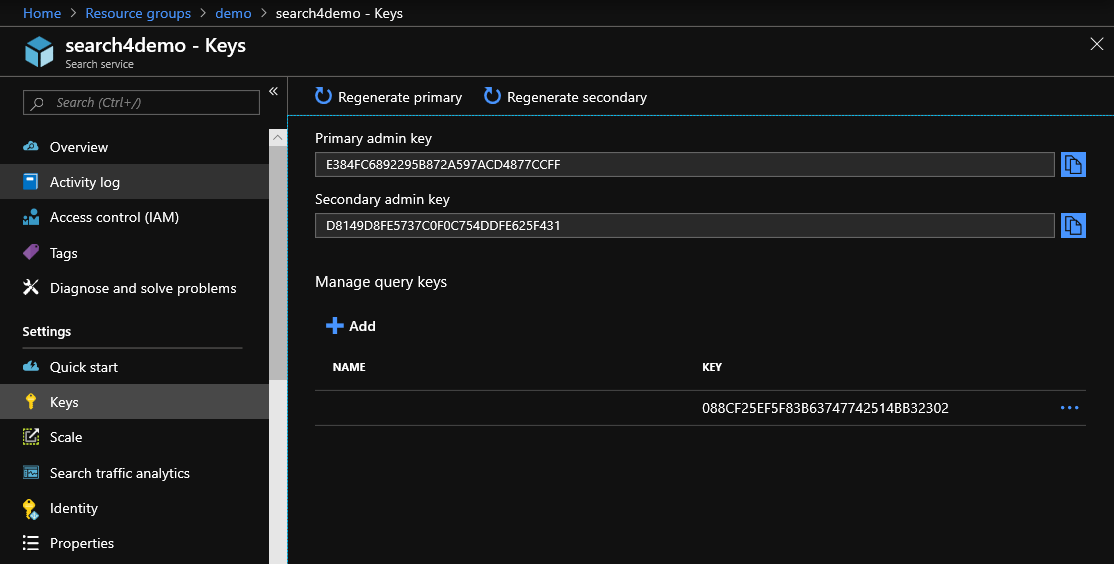
Uma consulta para obter dados do índice é:
GET https://[service name].search.windows.net/indexes/[index name]?api-version=[api-version]
api-key: [admin key] deve ser adicionada ao cabeçalho api-key: [admin key]
É possível criar um índice usando uma das duas consultas a seguir:
POST https://[servicename].search.windows.net/indexes?api-version=[api-version] Content-Type: application/json api-key: [admin key]
ou
PUT https://[servicename].search.windows.net/indexes/[index name]?api-version=[api-version]
No corpo, você deve especificar JSON com o conteúdo do índice. A versão mais recente no momento é 06-05-2019 e antes de ser usada por um longo período de tempo 2017-11-11
Trabalhando com a API, você pode usar alguns recursos de pesquisa que não estão disponíveis no portal.
Para dar prioridade a alguns campos na pesquisa, você pode usar perfis de pontuação .
O seguinte JSON adicionado à solicitação fornece ao campo "title" uma vantagem dupla sobre o campo "info":
"scoringProfiles": [ { "name": "profileForTitle", "document": { "weights": { "title": 2, “info": 1 } } ]
Além da capacidade de priorizar alguns campos usando pesos, é possível usar algumas funções predefinidas: frescura, magnitude, distância e tag.
O frescor é usado apenas nos campos DateTime e permite que você exiba os registros mais recentes na pesquisa. A magnitude é usada com campos int e double. Bem, e adequadamente, essa função é boa para usar com campos que armazenam preços, o número de downloads e outras informações numéricas. A distância é usada apenas em campos como Edm.GeographyPoint e é aumentada em uma pesquisa por distância de um local específico. Se a tag for especificada como o tipo de função, os documentos que contenham tags que aparecem na cadeia de pesquisa serão gerados na pesquisa.
Uma das opções mais populares é pegar os documentos mais recentes em uma pesquisa como esta:
"scoringProfiles": [{ "name":"newDocs", "functions": [ { "type": "freshness", "fieldName": "documentDate", "boost": 10, "interpolation": "quadratic", "freshness": { "boostingDuration": "P7D" } } ] } ]
Os documentos cujo campo documentDate contém a data dos últimos sete dias ("P7D") serão levantados.
Depois de criar um perfil de pontuação, você pode especificar seu nome em solicitações. Somente neste caso, os campos necessários serão gerados na pesquisa.
Leia mais na documentação oficial: Adicionar perfis de pontuação a um índice do Azure Search
Política de detecção de alterações de dados
A API fornece um pouco mais de recursos para a fonte de dados. Como você pode ler acima, ao criar uma fonte de dados, você pode especificar um campo pelo qual determinar se os dados foram alterados. Na forma de JSON, fica assim:
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy", "highWaterMarkColumnName" : "[a rowversion or last_updated column name]" } soft delete policy: "dataDeletionDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" }
Se você usa o SQL Server e seu banco de dados oferece suporte ao acompanhamento de alterações, os registros excluídos podem ser excluídos do índice automaticamente. A especificação de highWaterMarkColumnName nesse caso não é necessária. Basta especificar SqlIntegratedChangeTrackingPolicy em vez de HighWaterMarkChangeDetectionPolicy
"dataChangeDetectionPolicy" : { "@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy" }
É muito conveniente Mas existem nuances que não permitem aproveitar esse recurso completamente.
Primeiro, SqlIntegratedChangeTrackingPolicy não pode ser usado com visualizações. Em segundo lugar, a tabela não deve ter chaves primárias compostas. Escusado será dizer que a versão do SQL Server deve ser mais ou menos nova. E, finalmente, o controle de alterações deve estar ativado para o banco de dados e as tabelas usadas pela pesquisa. Para o banco de dados, ele é ativado assim:
ALTER DATABASE AdventureWorks2012 SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
E para a mesa assim:
ALTER TABLE Person.Contact ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)
Mas isso não é tudo. É altamente recomendável que você ative o isolamento de instantâneo para a base.
ALTER DATABASE AdventureWorks2012 SET ALLOW_SNAPSHOT_ISOLATION ON;
Além de dançar com um pandeiro ao instalar o Change Traking para o banco de dados para mim, a desvantagem é a incapacidade de usar visualizações. Então, eu ainda geralmente tenho que usar o HighWaterMarkChangeDetectionPolicy
Pesquisa de dados
Por padrão, a pesquisa do Azure usa sintaxe de consulta simples . Pode não parecer surpreendente, mas é bastante simples:
wifi + luxo pesquisa pelas palavras wifi e luxo ao mesmo tempo
"hotel de luxo" está procurando a frase
wifi | luxo está procurando a palavra wifi ou a palavra luxo
wifi - luxo procura textos com a palavra wifi, mas sem a palavra luxo
lux procura por palavras que começam com lux
É possível combinar regras de pesquisa usando parênteses. Por exemplo, a regra motel + (wifi | luxo) pesquisa a palavra motel e a palavra wifi ou a palavra luxo
É bom que a Pesquisa do Azure possa usar a sintaxe do Lucene . Para usá-lo, é necessário adicionar queryType = full à consulta de pesquisa
A diferença entre o Azure e a sintaxe clássica do Lucene é apenas na ausência de intervalo.
Portanto, na Pesquisa do Azure, você não pode: mod_date:[20020101 TO 20030101]
Mas na Pesquisa do Azure, você pode usar $ filter com sintaxe ODATA . Aqui está um exemplo de filtro:
{ "name": "Scott", "filter": "(age ge 25 and and lt 50) or surname eq 'Guthrie'" }
Os filtros também podem ser usados com sintaxe de consulta simples.
No Lucene, a lógica “ou” é implementada usando OR ou ||
Ambos os valores podem ser encontrados especificando a instrução "e" com: AND , && ou +
Para "not", você pode usar um dos seguintes: NOT ,! ou -
A instrução "not" possui um recurso comum para sintaxe simples e Lucene. Seu comportamento depende do modo de pesquisa, que pode ser definido em searchMode = all e em searchMode = any (esse valor é usado por padrão). Em qualquer modo, a pesquisa por wifi -luxury encontrará documentos com a palavra wifi ou documentos sem a palavra luxo. No modo todos, pela mesma solicitação, ele encontrará docas com a palavra wifi e simultaneamente sem a palavra luxo.
Vejamos alguns recursos interessantes do Lucene.
A pesquisa difusa permite pesquisar palavras que diferem da pesquisa por uma ou mais letras. Ou seja, ajuda a lidar com erros de digitação. Por exemplo, uma pesquisa por "azul ~" ou "azul ~ 1" retornará você com "azul" e "azul" e até "cola". Mas, ao mesmo tempo, uma pesquisa por "analista de negócios ~" significa negócios ou analista
A proximidade permite procurar palavras próximas. Por exemplo, "hotel aeroporto" ~ 5 encontrará as palavras "hotel" e "aeroporto", que estão localizadas no texto a não mais de 5 palavras uma da outra.
O aumento de termos permite definir a prioridade de uma palavra na pesquisa. Exemplo: "rock ^ 2 electronic" pesquisa as palavras rock e electronic, mas as entradas com a palavra rock na pesquisa serão exibidas acima.
Expressões regulares - usando expressões regulares. Tudo aqui está de acordo com a documentação oficial do Lucene regex. Você pode encontrá-la no seguinte link . Ao pesquisar, expressões regulares devem ser colocadas entre barras "/". Por exemplo, assim: / [mh] otel /
Se sua sequência de caracteres de pesquisa contiver caracteres especiais, eles deverão ser escapados com uma barra invertida. Caracteres de exemplo a serem escapados: + - && ||! () {} [] ^ "~ * ?: \ /
A pesquisa pode ser feita usando uma solicitação GET. O exemplo oficial é este:
GET /indexes/hotels/docs?search=category:budget AND \"recently renovated\"^3&searchMode=all&api-version=2019-05-06&querytype=full
Mas você pode usar uma solicitação POST com o corpo. Novamente, um exemplo oficial:
POST /indexes/hotels/docs/search?api-version=2019-05-06 { "search": "category:budget AND \"recently renovated\"^3", "queryType": "full", "searchMode": "all" }
Se você estiver usando uma solicitação GET ou POST com o tipo de dados application / x-www-form-urlencoded, precisará codificar caracteres não seguros e reservados.
Símbolos /?: @ = & estão reservados
Os caracteres `` <> #% {} | \ ^ ~ [] não são seguros.
Por exemplo, o símbolo # se tornará% 23 e o símbolo? torna-se% 3F
Alguns links para desenvolvedores.
Se o .NET for um desenvolvedor, você poderá usar o pacote Microsoft.Azure.Search NuGet . Além disso, existem exemplos no NodeJS e Java .
Um exemplo de um aplicativo simples no .NET Core, você pode encontrar aqui exemplo de pesquisa do ASP.NET Core Azure