Normalmente, o desempenho é entendido como o número de operações para um determinado intervalo de tempo e, quanto mais delas, melhor. Mas essa definição e a abordagem como um todo têm pouca aplicabilidade ao front-end, porque cada usuário terá seu próprio "front-end". É sobre isso que eu quero falar, o que está acontecendo “lá”, com o usuário, do outro lado, na realidade, e não no seu MacBook de topo.
Além disso, tentarei considerar brevemente as regras gerais para otimizar o código e alguns erros que merecem atenção. Também vou falar sobre uma
ferramenta que ajuda não apenas na criação de perfis, mas também pronta para o uso, que reúne várias métricas básicas sobre o desempenho do seu aplicativo (e espero que você leia esta postagem até o final).
Primeiro, determinaremos o que é desempenho de front-end e depois passaremos a como medi-lo. Portanto, como eu disse, não mediremos algumas operações / segundo, precisamos de dados reais que possam responder à pergunta do que exatamente acontece com o nosso projeto em cada etapa do seu trabalho. Para fazer isso, precisamos do seguinte conjunto de métricas:
- velocidade de download;
- hora da primeira renderização e interatividade (Time To Interactive);
- velocidade de reação às ações do usuário;
- FPS para rolagem e animações;
- inicialização de aplicativo;
- se você tiver um SPA, precisará medir o tempo gasto na alternância entre rotas;
- consumo de memória e tráfego;
- e ... o suficiente por enquanto.
Todas essas são métricas básicas, sem as quais é impossível entender o que exatamente está acontecendo no front-end. E não apenas no front-end, mas na realidade, com o usuário final. Mas, para começar a coletar essas métricas, primeiro você precisa aprender como medi-las, então vamos lembrar quais métodos existem para a análise de desempenho.
A primeira coisa a começar é, obviamente, a API de desempenho. Ou seja,
performance.timing , através do qual você pode descobrir quanto tempo um usuário levou para abrir seu projeto. Mas a API de desempenho cobre apenas parte da métrica, o restante precisará ser medido por nós mesmos e, para isso, temos as seguintes ferramentas:
Naquele momento, percebi que você precisava ver uma ferramenta que combinasse as vantagens das opções acima e, se possível, não tivesse desvantagens. Então havia o
PerfKeeper .
Perfkeeper
- Controle total sobre o começo e o fim.
- Você pode enviar para o servidor.
- É exibido no console.
- Suporta DevTools -> Desempenho -> Tempo do Usuário.
- Existe um agrupamento.
- Existe um código de cores (assim como unidades de medida, ou seja, você pode medir não apenas o tempo).
- Suporta extensões.
Agora não pintarei a API aqui, não escrevi
documentação para isso, e o artigo não é sobre isso, mas continuarei a coletar métricas.
Velocidade de download da página
Como eu já disse, você pode descobrir a velocidade do download em
performance.timing , que permitirá descobrir o ciclo completo desde o início do carregamento da página (hora de resolver o DNS, instalar o HTTP Handshake, processar a solicitação) e até que a página esteja totalmente carregada (DomReady e OnLoad):
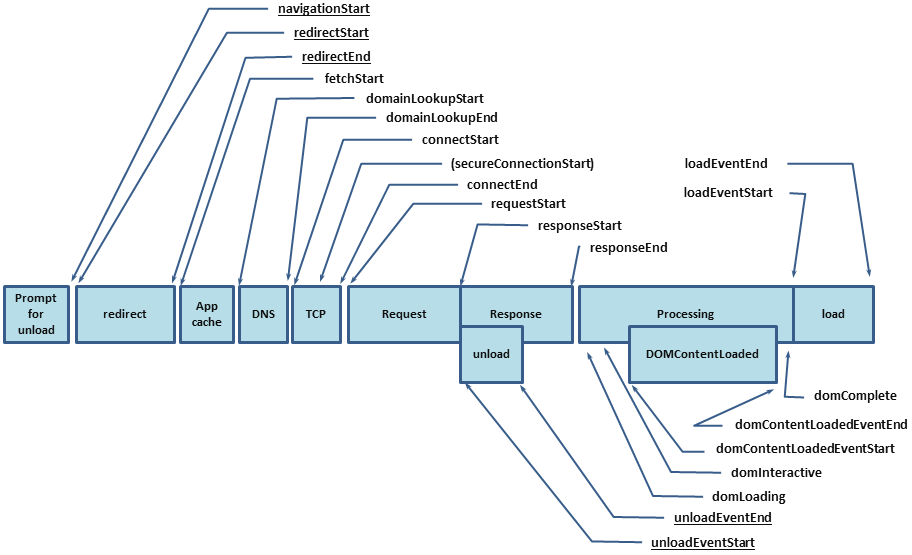
Como resultado, você deve obter o seguinte conjunto de métricas:
Um exemplo da extensão de navegação para @ perf-tools / keeper .Mas isso não basta, obtivemos apenas os valores básicos e ainda não sabemos o que exatamente levou tanto tempo. E para descobrir, você também precisa preencher as métricas HTML.
Como eu já disse, mostrarei exemplos usando o
PerfKeeper , então a primeira coisa a fazer é embutida no próprio
<hed/> PerfKeeper (2,5 Kb) e mais:

Como resultado, você verá tanta beleza no console:
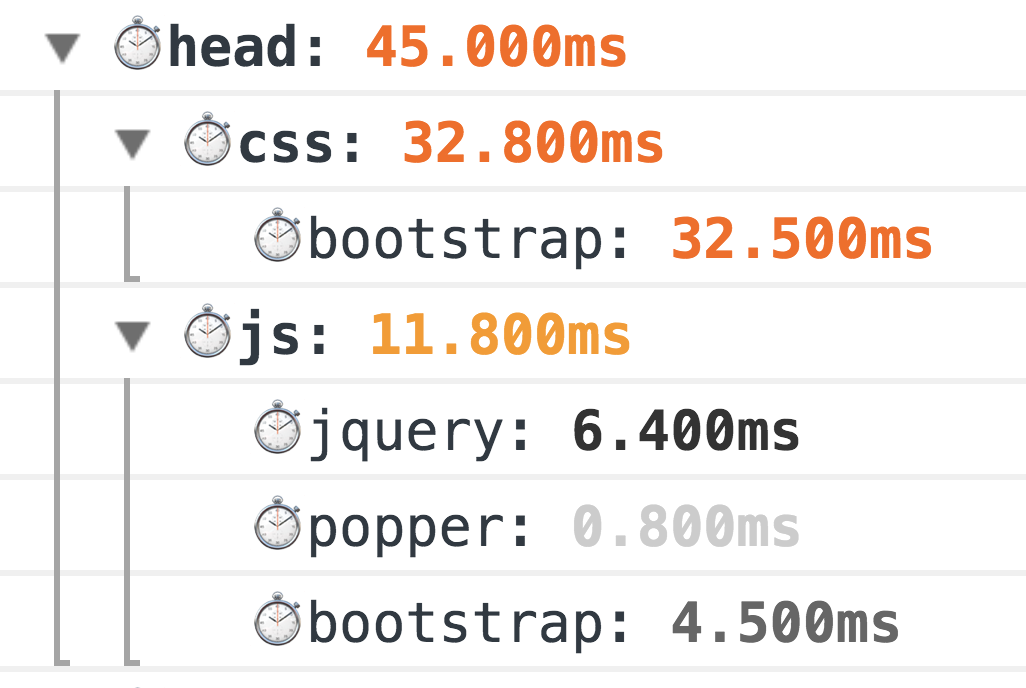
Este é um método clássico de medição do avô, 100% funciona. Mas o mundo não fica parado e, para medições mais precisas, agora temos a
API de Tempo de Recurso (e se os recursos estiverem em um domínio separado de
Tempo de Permissão de Origem para ajudá-lo).
E aqui vale a pena falar sobre erros clássicos durante o carregamento inicial da página, a saber:
- falta de GZip e HTTP / 2 (sim, isso ainda é comum);
- uso irracional de fontes (algumas vezes, uma fonte é conectada apenas por um cabeçalho ou até mesmo um número de telefone no rodapé 0_o);
- Pacotes CSS / JS muito genéricos.
Maneiras de otimizar o carregamento da página:
- use Brotli (ou mesmo SDCH) em vez de GZip, ative HTTP / 2;
- Colete apenas o CSS necessário (crítico) e não se esqueça do CSSO ;
- minimizar o tamanho do pacote JS separando o pacote CORE mínimo e carregar o restante sob demanda, ou seja, assincronamente;
- carregue JS e CSS no modo sem bloqueio, criando dinamicamente
/> <sript src="..."/> , idealmente carregue JS após o conteúdo principal; - use SVG em vez de PNG e, se combinado com JS, ele se livrará de XML redundante (por exemplo, como font-awesome );
- use carregamento lento para imagens e iframes (além disso, o suporte nativo aparecerá em um futuro próximo).
Primeira renderização e interatividade (TTI)
O próximo estágio após o carregamento é o momento em que o usuário viu o resultado e a interface entrou no modo interativo. Para isso, precisamos do
Performance Paint Timing e do
PerformanceObserver .
O primeiro é simples, chamamos
performance.getEntriesByType('paint') e obtemos duas métricas:
- primeira pintura - a primeira renderização;
- primeira pintura com conteúdo - e a primeira renderização completa.
 Um exemplo da extensão de tinta para @ perf-tools / keeper .
Um exemplo da extensão de tinta para @ perf-tools / keeper .Mas com a próxima métrica, Time To Interactive, é um pouco mais interessante. Não há uma maneira exata de determinar quando seu aplicativo se tornou interativo, ou seja, acessível ao usuário, mas isso pode ser indiretamente entendido pela ausência de
longas tarefas :
 Um exemplo da extensão de desempenho para @ perf-tools / keeper .
Um exemplo da extensão de desempenho para @ perf-tools / keeper .Além dessas métricas básicas, também é necessária a métrica de prontidão do aplicativo, ou seja, algures no seu código deve ser assim:
Import { system } from '@perf-tools/keeper'; export function applicationBoot(el, data) { const app = new Application(el, data);
Taxa de resposta às ações do usuário
Há um campo enorme para as métricas e elas são muito individuais, por isso vou falar sobre duas básicas que são adequadas para qualquer projeto, a saber:
primeiro evento - a hora do primeiro evento, por exemplo, o primeiro clique (dividindo onde o usuário cutucou), essa métrica é especialmente relevante para todos os tipos de resultados de pesquisa, uma lista de produtos, feeds de notícias etc. Com ele, você pode controlar como o tempo de reação e o usuário fluem de suas ações (alterações em: design / novos recursos / otimizações, etc.)
 Um exemplo da extensão de desempenho para @ perf-tools / keeper .latência
Um exemplo da extensão de desempenho para @ perf-tools / keeper .latência - atraso no processamento de alguns eventos, por exemplo:
click ,
input ,
submit ,
scroll etc.
Para medir o atraso, basta travar o manipulador de eventos na
window com
capture = true e use
requestAnimationFrame calcular a diferença, este será o atraso:
window.addEventListener(eventType, ({target}) => { const start = now(); requestAnimationFrame(() => { const latency = now() - start; if (latency >= minLatency) {
 Um exemplo da extensão de desempenho para @ perf-tools / keeper trabalhando quando um número de Fibonacci é calculado em um clique.
Um exemplo da extensão de desempenho para @ perf-tools / keeper trabalhando quando um número de Fibonacci é calculado em um clique.FPS ao rolar e animar
Essa é a métrica mais interessante, geralmente é medida por
requestAnimationFrame e, se você precisar fazer medições constantes de FPS, o
FPSMeter clássico fará (embora seja muito otimista). Mas não funciona se você precisar medir a suavidade da rolagem da página, porque ele precisa de um aquecimento. E então me deparei com uma
maneira muito
interessante .
De maneira engenhosa, na verdade, simplesmente criamos uma div transparente (1x1px), adicionamos
transition: left 300ms linear e a executamos de um canto a outro, e enquanto anima, através de
requestAnimationFrame verificamos sua esquerda real e, se o novo comprimento for diferente do anterior, aumente o número de quadros renderizados (caso contrário, temos um rebaixamento de FPS).
E isso não é tudo, se você usa o FF, simplesmente existe o
mozPaintCount , responsável pelo número de quadros renderizados, ou seja, lembramos de "DO" e, no
transitionend da
transitionend , calculamos a diferença.
Total, sem nenhum aquecimento, sabemos com certeza se o navegador redesenha o quadro ou não.
Eles logo prometem uma API normal:
http://wicg.imtqy.com/frame-timing/Um exemplo da extensão fps para @ perf-tools / keeper .Otimização de rolagem:
- o mais simples é não fazer nada na rolagem ou atrasar a execução por meio de
requestAnimationFrame ou mesmo requestIdleCallback ; - use muito cuidadosamente
pointer-events: none , ativá-lo e desativá-lo pode ter o efeito oposto; portanto, é melhor realizar um experimento A / B usando pointer-events e sem; - não se esqueça das listas virtualizadas, quase todos os mecanismos do View agora possuem esses componentes, mas, novamente, tenha cuidado, os elementos dessa lista devem ser o mais simples possível ou use "manequins" que serão substituídos por elementos reais depois que a rolagem for concluída. Se você mesmo escrever uma lista virtualizada, não haverá HTML interno e não se esqueça da reciclagem do DOM (é quando você não cria elementos DOM para cada espirro, mas os reutiliza).
Inicialização de aplicativo
Há apenas uma regra: detalhe para que você possa responder exatamente quanto tempo consumiu desde a inicialização do aplicativo até o lançamento final. Como resultado, você deve obter pelo menos as seguintes métricas:
- quanto tempo levou para resolver cada vício;
- tempo para receber e preparar dados para a aplicação;
- processar aplicativo com detalhamento por blocos.
I.e. na saída, você deve obter essas métricas pelas quais pode rastrear com precisão exatamente em qual fase o seu rebaixamento está ocorrendo.
Exemplo de trabalhoConsole 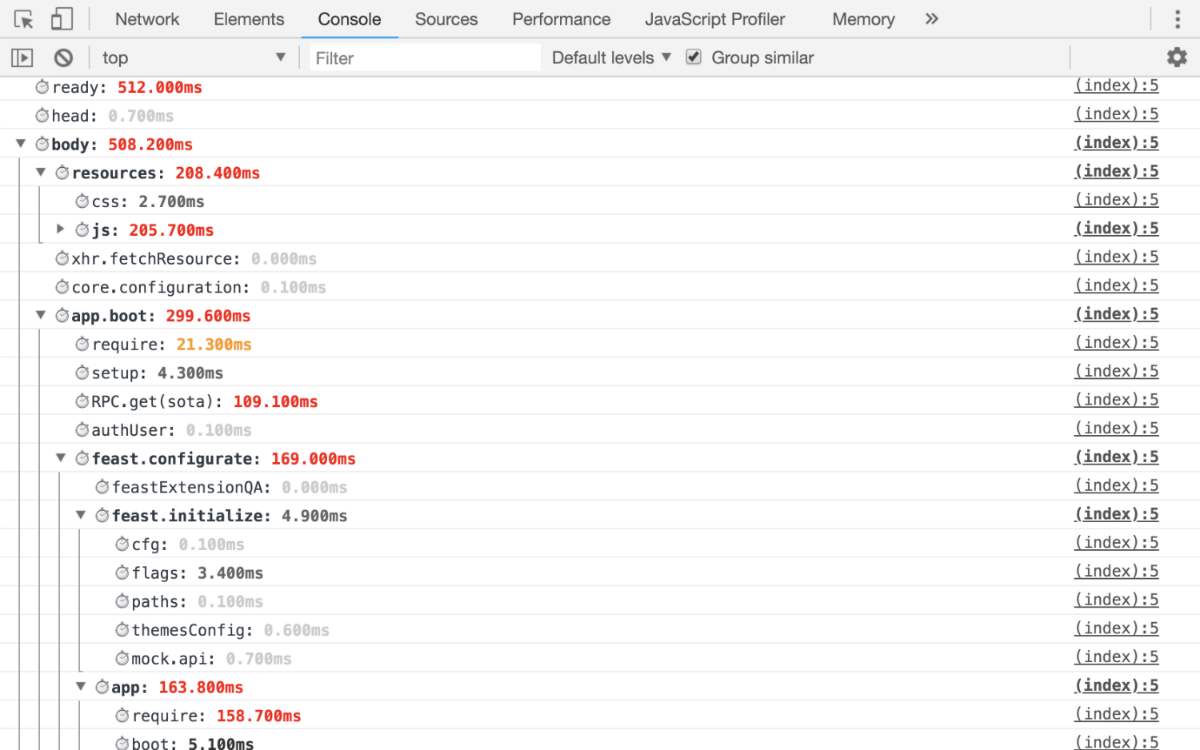 Tempo do usuário
Tempo do usuário 
Se você tem SPA, precisa medir o tempo de roteamento
Primeiro, deve haver uma métrica geral para avaliar o desempenho (tempo de trânsito na rota) como um todo, mas também é necessário ter uma métrica para cada rota (por exemplo, temos uma "Lista de threads", "Lendo um thread", "Pesquisa" etc. d.), a própria métrica deve ser dividida em métricas:
- Recebendo dados (com uma discriminação de quais)
- Render
- Aplicação total
- Blocos (por exemplo, conosco, será: "Coluna esquerda" (também conhecida como "Lista de pastas"), "Barra de pesquisa inteligente", "Lista de letras" e similares)
Sem tudo isso, é impossível entender onde os problemas começam, portanto, temos muitos módulos
endTime para uso com intervalos de tempo (por exemplo, o mesmo módulo para o XHR possui
endTime e
endTime , que são registrados automaticamente).
Mas essas métricas não são suficientes para avaliar adequadamente o que está acontecendo. Eles são muito gerais porque como estamos falando de SPA, você definitivamente tem algum tipo de cache de tempo de execução (para não voltar ao servidor novamente se já estiver lá), para que nossas métricas sejam divididas em roteamento com e sem cache. Ainda assim, especificamente em nosso caso, dividimos a métrica pelo número de entidades nela. Em outras palavras, você não pode adicionar a visualização "Encadeamento" com 1, 5, 10 ou mais de 100 letras em uma métrica. Portanto, se você tiver alguma lista exibida, precisará selecionar pontos de interrupção e separar ainda mais a métrica.
Consumo de memória e tráfego
Vamos começar com a memória . E aqui estamos esperando uma grande decepção. No momento, há apenas performance.memory não padronizada (somente Chrome), o que fornece números ridiculamente baixos. Mas eles ainda precisam ser medidos e observar como o aplicativo "flui" ao longo do tempo:
Um exemplo da extensão de memória para @ perf-tools / keeperTráfego Para contar o tráfego, você precisará do
Timing-Allow-Origin (se os recursos estiverem localizados em um domínio separado) e da
API do
Resource Timing , isso ajudará não apenas a calcular o tráfego, mas também a detalhar:
- qual protocolo é usado (HTTP / 1, HTTP / 2 etc.);
- tipos de recursos carregados;
- quanto tempo levou para baixá-los;
- Além disso, você pode entender se o recurso está carregado na rede ou extraído do cache.
Um exemplo da extensão de recurso para @ perf-tools / keeper .O que dá contagem de tráfego?
- O mais importante é que ele permite que você veja a imagem real, e não como sempre com CSS + JS e além disso, como essa "imagem" muda com o tempo.
- Depois, você pode analisar o que exatamente está carregado, dividir recursos em grupos etc.
- Quão bem o cache funciona para você.
- Existem anomalias, por exemplo, após 15 minutos de operação, por exemplo, o código entrou em recursão e carrega algum recurso sem parar, o monitoramento do tráfego ajudará nisso.
Bem, um relatório de atualização do meu colega
Igor Druzhinin sobre este tópico:
Avaliando a qualidade do aplicativo - monitorando o consumo de tráfegoGoogle Analytics
Montamos as métricas e depois o que? E então eles precisam ser enviados para algum lugar. E aqui você escolhe um pouco de
grafite ou, para começar, pode usar o
Google Analytics ou similar para agregação de dados para ganho pessoal.
E não se esqueça, não basta apenas obter um cronograma; para todas as métricas importantes, deve haver percentis que permitam entender, por exemplo, qual a porcentagem de público que o projeto está carregando para <1s, <2s, <3s, <5s, 5s +, etc.
Escrevendo um código de alto desempenho
No começo, eu queria escrever algo significativo aqui, eles dizem usar WebWorker, não se esqueça de
requestIdleCallback ou algo exótico, por exemplo, através do Runtime Cache, através de guias do navegador usando SharedWorker ou ServiceWorker (que não é apenas sobre cache, se isso). Mas tudo isso é muito abstrato e muitos tópicos são superados pela impossibilidade; basta escrever o seguinte:
- Inicialmente, cubra seu código com métricas que medem seu desempenho.
- Não acredite nos benchmarks com o jsperf. A grande maioria deles é mal escrita e simplesmente retirada de contexto. A melhor referência é a métrica real do projeto, segundo a qual você verá o efeito de suas ações.
- Lembre-se da percepção de produtividade, ou melhor, da Lei de Weber-Fechner. Nomeadamente, se você iniciou a otimização, não execute as alterações até que se tornem melhores pelo menos em 20%, caso contrário os usuários simplesmente não perceberão. A lei também funciona na direção oposta.
- Medo regulares, especialmente aqueles gerados. Eles não apenas podem travar o navegador, mas também obter o XSS, e é por isso que no nosso Mail é proibido analisar o HTML usando-os, apenas através de um desvio do DOM.
- Você não precisa usar matrizes para inserir um valor em um ou outro grupo; para isso, existe um
object ou um Set (por exemplo, successSteps.includes(currentStep) necessário successSteps.hasOwnProperty(currentStep) ), O (1) é tudo. - A expressão "Otimização prematura é a raiz de todos os males" não é sobre escrever o que você quiser. Se você sabe qual a melhor forma, escreva da melhor maneira.
Escreverei alguns parágrafos sobre o código e sua otimizaçãoDOM Muitas vezes ouço “O Problema no DOM” - isso, é claro, é verdade, mas dado que quase todo mundo agora tem uma abstração sobre ele. É ela quem se torna o gargalo, ou melhor, o seu código, responsável pela formação da visão e da lógica de negócios.
Mas se falarmos sobre o DOM, por exemplo, em vez de excluir um fragmento do DOM, é melhor ocultá-lo ou anexá-lo. Se você ainda precisar excluir, faça essa operação em
requestIdleCallback (se possível) ou divida o processo de destruição em duas fases: síncrona e assíncrona.
Farei uma reserva imediatamente, use essa abordagem com sabedoria, caso contrário, você pode dar um tapa no joelho.
Também usamos outra técnica interessante em listas, por exemplo, a "Lista de Tópicos". A essência da técnica é que, em vez de uma "Lista" global e atualização de seus dados, geramos uma "Lista de threads" para cada "Pasta". Como resultado, quando o usuário navega entre as "Pastas", uma lista é removida do DOM (não excluída) e a outra é atualizada parcial ou totalmente. E não todos, como é o caso da "Lista Única".
Tudo isso fornece uma resposta instantânea às ações do usuário.
Matemática Removemos facilmente toda a matemática no Worker ou no WebAssembly, pois isso funciona há muito tempo.
Transpilers . Ah, muitos nem pensam que o código que escrevem passa pelo transpilador. Sim, eles sabem sobre ele, mas é tudo. Mas com o que ele se transforma eles não se importam mais. De fato, no DevTools, eles veem o resultado do mapa de origem.
Portanto, estude as ferramentas que você usa, por exemplo, a mesma babel no
playground tem a oportunidade de ver em que ele gera código, dependendo das predefinições selecionadas, basta olhar para o mesmo campo,
await ou
for of .
As sutilezas da língua . Menos pessoas ainda sabem do monomorfismo do código, ou brega por que o bind é lento e ... você finalmente usa o
handleEvent !
Dados e pré-gravação . Menos pedidos, mais armazenamento em cache. Além disso, muitas vezes usamos a técnica de "previsão", é quando, em segundo plano, carregamos dados. Por exemplo, depois de renderizar a "Lista de threads", começamos a carregar segmentos não lidos na "Pasta" atual, para que, quando você clicar neles, o usuário mude imediatamente para "Leitura" em vez de outro "carregador". Usamos uma técnica semelhante, não apenas para Data, mas também para JS. Por exemplo, “Escrever uma carta” é um pacote enorme (por causa do editor), e nem todas as pessoas escrevem cartas de uma só vez; portanto, carregamos em segundo plano, depois que o aplicativo é inicializado.
Louders Não sei por que, mas não vi artigos que ensinavam como não fazer um carregador, mas fiz uma apresentação do React "futuro", no qual muito tempo foi dedicado a esse problema no Suspense. Mas, afinal, o aplicativo ideal é sem carregadores, tentamos há muito tempo no Mail mostrá-lo apenas em situações de emergência.
Em geral, temos essa política, não há dados, não há visão, não há nada para desenhar uma semi-interface, primeiro carregamos os dados e só depois "desenhamos". É por isso que usamos a “previsão” de onde o usuário está indo e carregamos esses dados para que o usuário não veja o carregador. Além disso, nossa camada de dados, que é persistente, ajuda muito nessa tarefa. se você solicitou "Encadeamento" em algum lugar de um local, da próxima vez que solicitar de outro ou do mesmo local, não haverá solicitação, obteremos dados do Runtime Cache (mais precisamente, um link para os dados). E assim, em tudo, coleções de threads também são apenas links para dados.
Mas se você ainda decidir criar um carregador, não esqueça as regras básicas que tornarão seu carregador menos irritante:
- não há necessidade de mostrar o carregador imediatamente, no momento do envio da solicitação, deve haver um atraso de pelo menos 300-500 ms antes do show;
- Depois de receber os dados, você não precisa remover muito o carregador, aqui novamente deve haver um atraso.
Essas regras simples são necessárias para que o carregador apareça apenas em solicitações pesadas e não pisque após a conclusão. Mas o mais importante, o melhor carregador é um carregador que não apareceu.
Obrigado pela atenção, isso é tudo, meça, analise e use o
PerfKeeper (
exemplo ao vivo ), além do
meu github e
twitter , em caso de dúvidas!