As imagens JPEG são encontradas em todos os lugares da nossa vida digital, mas por trás dessa cobertura de consciência há algoritmos que eliminam detalhes que não são percebidos pelo olho humano. O resultado é a mais alta qualidade visual, com o menor tamanho de arquivo - mas como exatamente tudo isso funciona? Vamos ver o que exatamente nossos olhos não vêem!

É fácil ter, como garantido, a capacidade de enviar uma foto a um amigo, e não se preocupar com qual dispositivo, navegador ou sistema operacional ele usa - no entanto, esse nem sempre foi o caso. No início dos anos 80, os computadores sabiam armazenar e exibir imagens digitais, mas havia muitas idéias concorrentes sobre a melhor maneira de fazer isso. Era impossível simplesmente enviar uma imagem de um computador para outro e esperar que tudo desse certo.
Para resolver esse problema, em 1986, um comitê de especialistas de todo o mundo foi reunido sob o nome “Joint Photographic Experts Group (JPEG), com base na colaboração da Organização Internacional de Padronização (ISO) e da Comissão Eletrotécnica Internacional (IEC) ) - duas organizações internacionais de normalização, com sede em Genebra (Suíça).
Um grupo de pessoas chamado JPEG criou o padrão de compressão de imagem digital JPEG em 1992. Qualquer pessoa que use a Internet provavelmente encontrará imagens codificadas em JPEG. Essa é a maneira mais comum de codificar, enviar e armazenar imagens. De páginas da web a e-mail e redes sociais, o JPEG é usado bilhões de vezes por dia - quase toda vez que assistimos a uma imagem on-line ou a enviamos. Sem JPEG, a Web seria menos vibrante, mais lenta e provavelmente haveria menos fotos de gatos!
Este artigo é sobre como decodificar uma imagem JPEG. Em outras palavras, sobre o que é necessário para converter dados compactados armazenados em um computador em uma imagem que aparece na tela. Vale a pena conhecer isso, não apenas porque é importante para entender a tecnologia que usamos diariamente, mas também porque, ao divulgar os níveis de compressão, entendemos melhor a percepção e a visão, bem como os detalhes aos quais nossos olhos são mais sensíveis.
Além disso, brincar com imagens dessa maneira é muito interessante.
Olhando dentro de um JPEG
Em um computador, tudo é armazenado como uma sequência de números binários. Normalmente, esses bits, zeros e uns, são agrupados em oito, formando bytes. Quando você abre uma imagem JPEG em um computador, algo (navegador, SO, outra coisa) deve decodificar os bytes, restaurando a imagem original na forma de uma lista de cores que podem ser exibidas.
Se você baixar esta
foto fofa de
gato e abri-la em um editor de texto, verá vários caracteres incoerentes.
 Aqui, uso o Notepad ++ para examinar o conteúdo de um arquivo, pois editores de texto comuns, como o Bloco de Notas do Windows, corromperão o binário após o salvamento e não atenderão mais ao formato JPEG.
Aqui, uso o Notepad ++ para examinar o conteúdo de um arquivo, pois editores de texto comuns, como o Bloco de Notas do Windows, corromperão o binário após o salvamento e não atenderão mais ao formato JPEG.Quando você abre uma imagem em um editor de texto, confunde o computador, assim como confunde seu cérebro quando esfrega os olhos e começa a ver manchas coloridas!
Esses pontos que você vê são conhecidos como
fosfenos e não são o resultado da exposição a um estímulo luminoso ou alucinações geradas pela mente. Eles ocorrem porque seu cérebro acredita que quaisquer sinais elétricos nos nervos ópticos transmitem informações sobre a luz. O cérebro precisa fazer essas suposições, porque é impossível saber se o sinal é som, visão ou qualquer outra coisa. Todos os nervos do corpo transmitem exatamente os mesmos impulsos elétricos. Ao pressionar os olhos, você envia sinais que não são visuais, mas ativa os receptores oculares que seu cérebro interpreta - nesse caso, incorretamente - como algo visual. Você é literalmente capaz de ver a pressão!
É engraçado pensar em como os computadores se parecem com um cérebro, mas também é uma analogia útil que ilustra quanto o significado dos dados - transmitidos pelo corpo pelos nervos ou armazenados em um computador - depende de sua interpretação. Todos os dados binários consistem em zeros e uns, componentes básicos que podem transmitir informações de qualquer tipo. Seu computador geralmente adivinha como interpretá-los usando dicas, como extensões de arquivo. E agora estamos forçando-o a interpretá-los como texto, pois é isso que o editor de texto espera.
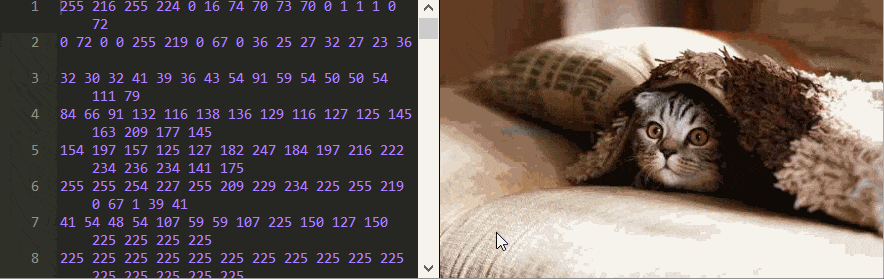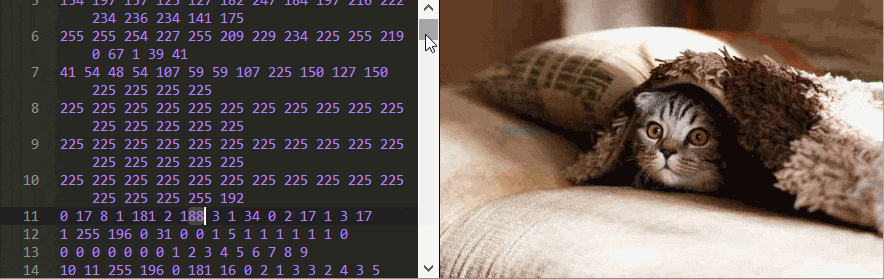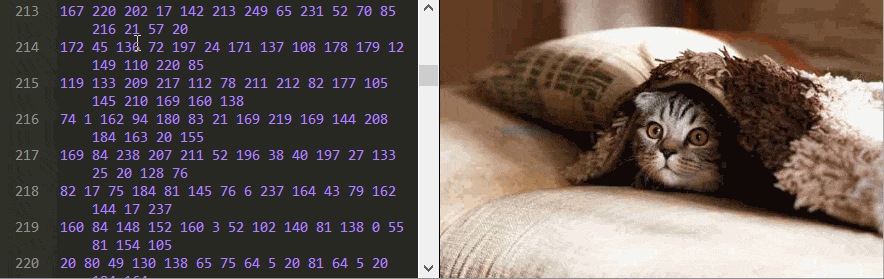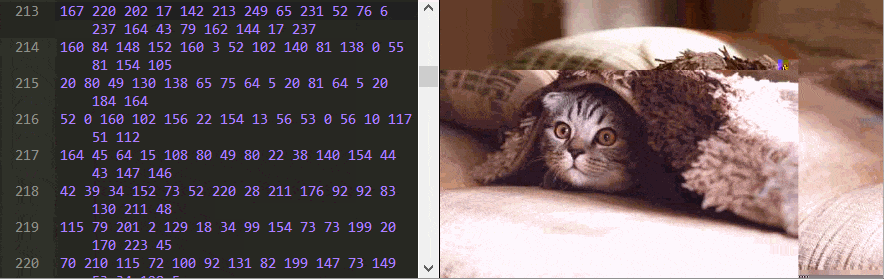
Para entender como decodificar JPEG, precisamos ver os próprios sinais originais - dados binários. Isso pode ser feito usando o editor hexadecimal ou diretamente na
página da web do artigo original ! Há uma imagem, ao lado da qual todos os bytes da caixa de texto (exceto o cabeçalho) são apresentados em forma decimal. Você pode alterá-los e o script recodificará e produzirá uma nova imagem rapidamente.

Você pode aprender muito apenas brincando com este editor. Por exemplo, você pode dizer em que ordem os pixels são armazenados?
Neste exemplo, é estranho que a alteração de alguns números não afete a imagem, mas, por exemplo, se você substituir o número 17 por 0 na primeira linha, a foto ficará completamente ruim!

Outras alterações, por exemplo, substituir 7 na linha 1988 pelo número 254 alteram a cor, mas apenas os pixels subsequentes.

Talvez o mais estranho seja que alguns números mudem não apenas a cor, mas também a forma da imagem. Mude 70 na linha 12 para 2 e olhe para a linha superior da imagem para entender o que quero dizer.

E não importa qual imagem JPEG você use, você sempre encontrará essas seqüências de xadrez enigmáticas ao editar bytes.
Ao jogar com o editor, é difícil entender como a foto é recriada a partir desses bytes, pois a compactação JPEG consiste em três tecnologias diferentes que são aplicadas seqüencialmente nos níveis. Estudaremos cada um deles separadamente para revelar o comportamento misterioso que observamos.
Três níveis de compactação JPEG:- Redução de amostras de cores .
- Transformação discreta e discretização de cosseno .
- Comprimentos de série de codificação , Delta e Huffman
Para que você possa imaginar a escala de compactação, observe que a imagem acima representa 79.819 números, ou seja, cerca de 79 Kb. Se o armazenássemos sem compactação, seriam necessários três números para cada pixel - para o componente vermelho, verde e azul. Seriam 917.700 números, ou aprox. 917 Kb. Como resultado da compactação JPEG, o arquivo resultante diminuiu mais de 10 vezes!
De fato, essa imagem pode ser compactada com muito mais força. Abaixo estão duas imagens lado a lado - a foto à direita foi reduzida para 16 Kb, 57 vezes menor que a versão não compactada!

Se você olhar atentamente, verá que essas imagens não são idênticas. Ambos são imagens com compactação JPEG, mas a correta é muito menor em volume. Também parece um pouco pior (observe os quadrados das cores de fundo). Portanto, o JPEG também é chamado de compactação com perdas; durante a compactação, a imagem muda e perde alguns detalhes.
1. Redução de amostras de cores
Aqui está uma imagem usando apenas o primeiro nível de compactação.
 (Versão interativa - no artigo original ). A remoção de um número destrói todas as cores. No entanto, se você excluir exatamente seis números, isso praticamente não afetará a imagem.
(Versão interativa - no artigo original ). A remoção de um número destrói todas as cores. No entanto, se você excluir exatamente seis números, isso praticamente não afetará a imagem.Agora os números são um pouco mais fáceis de decifrar. Essa é uma lista quase simples de cores, na qual cada byte altera exatamente um pixel, mas ao mesmo tempo já tem a metade do tamanho de uma imagem não compactada (que ocuparia cerca de 300 Kb em tamanho reduzido). Adivinha por que?
Você pode ver que esses números não indicam os componentes vermelho, verde e azul padrão, porque se substituirmos todos os números por zeros, obteremos uma imagem verde (e não branca).

Isso ocorre porque esses bytes indicam Y (brilho),

Cb (azul relativo)

e Cr (vermelhidão relativa).

Por que não usar RGB? De fato, é assim que a maioria das telas modernas funciona. Seu monitor pode mostrar qualquer cor, incluindo vermelho, verde e azul com intensidades diferentes para cada pixel. O branco é obtido ativando os três com brilho total e o preto - desativando-os.
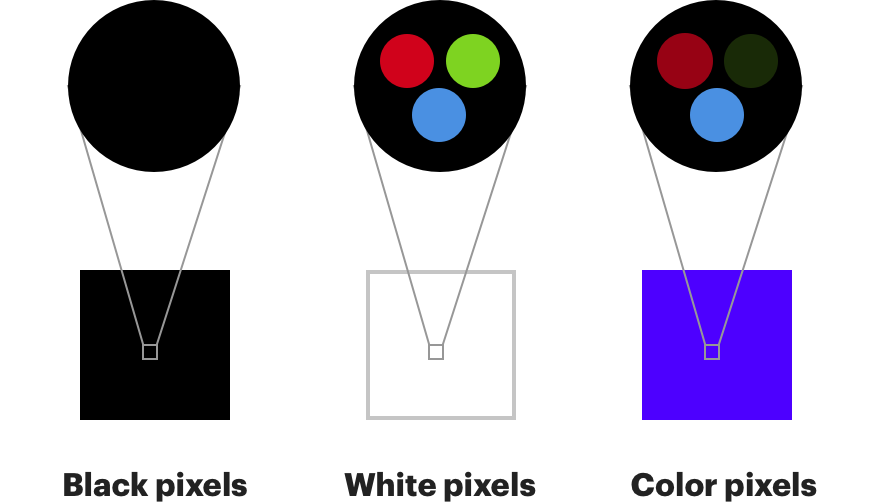
Também é muito parecido com o trabalho do olho humano. Os receptores de cores de nossos olhos são chamados de "
cones " e são divididos em três tipos, cada um dos quais é mais sensível a vermelho, verde ou azul [os cones do tipo S são sensíveis em azul violeta (S de inglês curto - ondas curtas espectro), tipo M - em verde-amarelo (M do inglês. Médio - onda média) e tipo-L - nas partes amarelo-vermelho (L do inglês. Longa - longa onda) do espectro. A presença desses três tipos de cones (e hastes sensíveis na parte verde esmeralda do espectro) proporciona uma visão de cores da pessoa. / aprox. transl.].
As hastes , outro tipo de fotorreceptor em nossos olhos, podem capturar apenas alterações no brilho, mas são muito mais sensíveis. Aos nossos olhos, existem cerca de 120 milhões de varas e apenas 6 milhões de cones.
Portanto, nossos olhos percebem mudanças de brilho muito melhores do que mudanças de cor. Se você separar a cor do brilho, poderá remover um pouco de cor e ninguém perceberá nada. A redução da amostragem de cores é o processo de representar os componentes de cores de uma imagem em uma resolução mais baixa que os componentes de brilho. No exemplo acima, cada pixel possui exatamente um componente Y e cada grupo individual de quatro pixels possui exatamente um componente Cb e um Cr. Portanto, a imagem contém quatro vezes menos informações sobre cores do que o original.
O espaço de cores YCbCr é usado não apenas em JPEG. Foi originalmente inventado em 1938 para programas de televisão. Nem todo mundo tem uma TV em cores; portanto, a separação de cores e brilho permitiu que todos recebessem o mesmo sinal, e as TVs sem cores usavam apenas o componente de brilho.
Portanto, a exclusão de um número do editor destrói completamente todas as cores. Os componentes são armazenados como AAAA Cb Cr (de fato, não necessariamente nessa ordem - a ordem de armazenamento é especificada no cabeçalho do arquivo). A remoção do primeiro número levará ao fato de que o primeiro valor de Cb será percebido como Y, Cr como Cb e, como um todo, ocorrerá um efeito dominó, alternando todas as cores da imagem.
A especificação JPEG não obriga a usar o YCbCr. Porém, na maioria dos arquivos, é usado porque fornece imagens de melhor qualidade após a redução da amostra em comparação com o RGB. Mas você não precisa aceitar minha palavra. Veja na tabela abaixo como a redução de amostra de cada componente individual será semelhante em RGB e em YCbCr.

(Versão interativa - no artigo
original ).
A remoção do azul não é tão perceptível quanto o vermelho ou o verde. Isso ocorre por causa dos seis milhões de cones em seus olhos, cerca de 64% são sensíveis ao vermelho, 32% ao verde e 2% ao azul.
A subamostragem do componente Y (canto inferior esquerdo) é melhor visualizada. Perceptível é mesmo uma ligeira mudança.
A conversão de uma imagem de RGB para YCbCr não reduz o tamanho do arquivo, mas facilita a localização de detalhes menos perceptíveis que podem ser removidos. A compressão com perdas ocorre no segundo estágio. É baseado na ideia de representar dados de uma forma mais compressível.
2. Transformação discreta e discretização de cosseno
Esse nível de compactação determina a maior parte da essência do JPEG. Depois de converter as cores em YCbCr, os componentes são compactados separadamente, para que possamos nos concentrar no componente Y somente mais tarde. E é assim que os bytes do componente Y se aplicam após a aplicação desse nível.
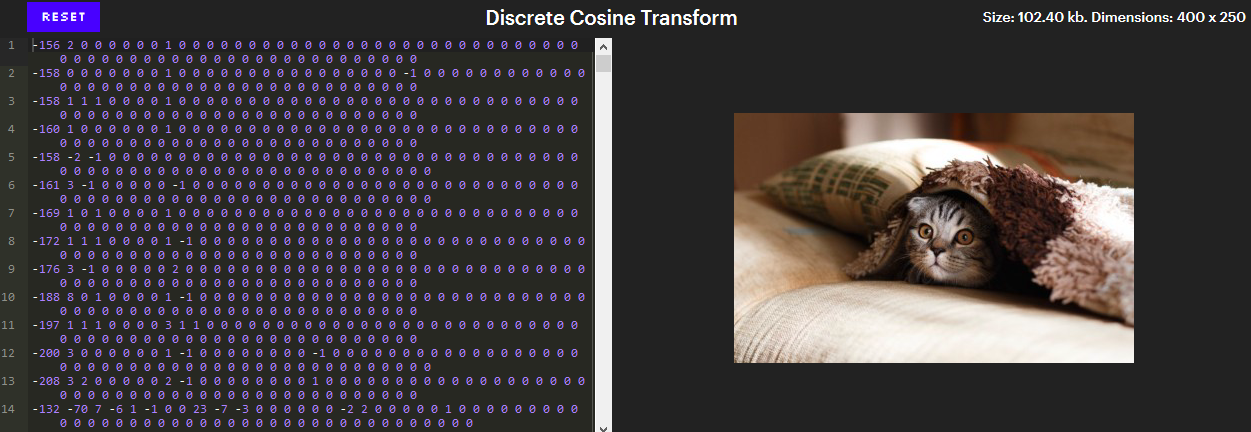 (Versão interativa - no artigo original ).
(Versão interativa - no artigo original ). Na versão interativa, clicar em um pixel rola o editor para a linha que o indica. Tente remover números do final ou adicionar alguns zeros a um número específico.
À primeira vista, parece uma compressão muito ruim. Existem 100.000 pixels na imagem e 102.400 números são necessários para indicar o brilho (componentes Y) - isso é pior do que não compactar nada!
No entanto, observe que a maioria desses números é zero. Além disso, todos esses zeros no final das linhas podem ser excluídos sem alterar a imagem. Restam cerca de 26.000 números, e isso é quase 4 vezes menos!
Nesse nível está o segredo dos padrões de xadrez. Ao contrário de outros efeitos que vimos, a aparência desses padrões não é uma falha. Eles são os blocos de construção de toda a imagem. Cada linha do editor contém exatamente 64 números, coeficientes de transformada discreta de cosseno (DCT) correspondentes a intensidades de 64 padrões únicos.
Esses padrões são formados com base no gráfico de cosseno. Aqui estão alguns deles:
 8 de 64 probabilidades
8 de 64 probabilidadesAbaixo está uma imagem mostrando todos os 64 padrões.
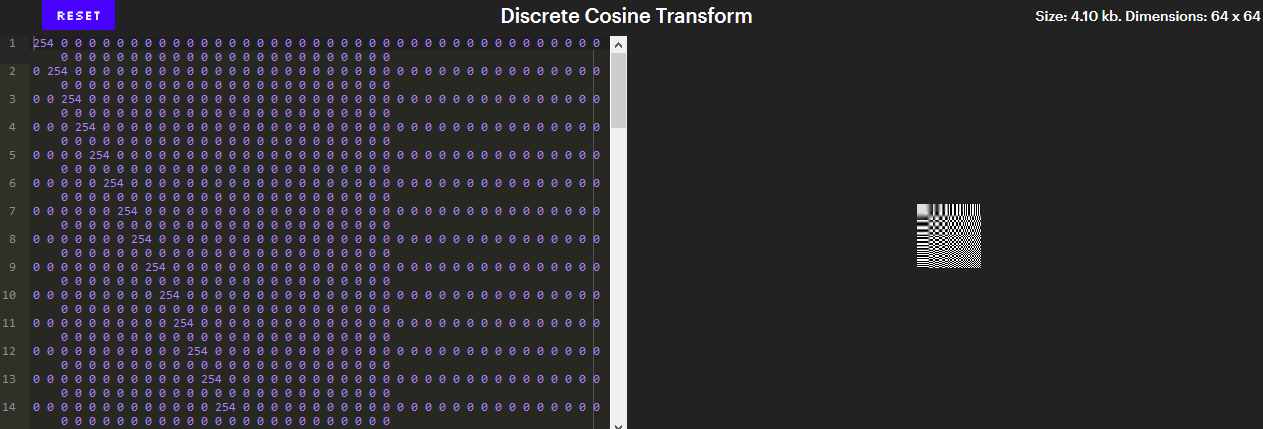 (Versão interativa - no artigo original ).
(Versão interativa - no artigo original ).Esses padrões são de particular importância, pois formam a base das imagens 8x8. Se você não estiver familiarizado com álgebra linear, isso significa que qualquer imagem 8x8 pode ser obtida a partir desses 64 padrões. DCT é o processo de dividir imagens em blocos 8x8 e converter cada bloco em uma combinação desses 64 coeficientes.
O fato de qualquer imagem poder ser composta por 64 padrões específicos parece mágico. No entanto, é o mesmo que dizer que qualquer lugar na Terra pode ser descrito por dois números - latitude e longitude [indicando hemisférios / aprox. transl.]. Costumamos considerar a superfície da Terra bidimensional, por isso precisamos de apenas dois números. Uma imagem 8x8 tem 64 dimensões, por isso precisamos de 64 números.
Ainda não está claro como isso nos ajuda no sentido da compressão. Se precisarmos de 64 números para representar uma imagem 8x8, por que isso seria melhor do que apenas armazenar 64 componentes de luminância? Fazemos isso pela mesma razão pela qual transformamos três números RGB em três números YCbCr: isso nos permite remover detalhes invisíveis.
É difícil ver exatamente quais detalhes foram removidos nesse estágio, porque o JPEG aplica o DCT a blocos 8x8. No entanto, ninguém nos proíbe de aplicá-lo a todo o cenário. Aqui está a aparência do DCT no componente Y quando aplicado a toda a imagem:
No final, você pode excluir mais de 60.000 números praticamente sem alterações visíveis na foto.

No entanto, observe que, se redefinirmos os cinco primeiros números, a diferença será óbvia.

Os números no início indicam mudanças de baixa frequência na imagem, e nossos olhos os captam melhor. Os números próximos ao final indicam alterações nas frequências altas que são mais difíceis de perceber. Para "ver o que não é visível a olho nu", podemos isolar essas partes de alta frequência zerando os primeiros 5000 números.

Vemos todas as áreas da imagem nas quais a maior alteração ocorre de pixel para pixel. Destacam-se os olhos do gato, o bigode, o cobertor felpudo e as sombras no canto inferior esquerdo. Você pode ir além limpando os primeiros 10.000 números:

20.000:

40.000:

60.000:

Essas partes de alta frequência são jpeg e são excluídas durante a fase de compressão. A conversão de cores em coeficientes DCT é sem perdas. As perdas são geradas na etapa de discretização, na qual os valores de alta frequência ou quase zero são removidos. Quando você diminui a qualidade de salvar o JPEG, o programa aumenta o limite para o número de valores excluídos, o que reduz o tamanho do arquivo, mas torna a imagem mais pixelizada. Portanto, a imagem na primeira seção, que era 57 vezes menor, ficava assim. Cada bloco 8x8 parecia ter um número muito menor de coeficientes de DCT em comparação com uma versão melhor.
Você pode criar um efeito interessante, como a transmissão gradual de imagens. Você pode exibir uma imagem borrada, que fica mais detalhada à medida que mais e mais coeficientes são baixados.
Aqui, apenas por diversão, o que acontece ao usar apenas 24.000 números:

Ou apenas 5000:

Muito embaçado, mas como se fosse reconhecível!
3. Codificação dos comprimentos das séries, delta e Huffman
Até agora, todos os estágios de compressão foram perdidos. A última etapa, pelo contrário, fica sem perdas. Ele não exclui informações, mas reduz significativamente o tamanho do arquivo.
Como você pode compactar algo sem descartar informações? Imagine como descreveríamos um simples retângulo preto de 700 x 437.
O JPEG usa 5000 números para isso, mas um resultado muito melhor pode ser alcançado. Você pode imaginar um esquema de codificação que descreva essa imagem com o mínimo de bytes possível?
O esquema mínimo que eu poderia criar usa quatro: três para indicar cores e o quarto - quantos pixels têm essa cor. A idéia de representar valores repetidos de maneira compactada é chamada de codificação de comprimento de série. Não possui perdas, pois podemos restaurar os dados codificados em sua forma original.
O tamanho de um arquivo JPEG com um retângulo preto é muito maior que 4 bytes - lembre-se de que no nível DCT, a compactação é aplicada a blocos de 8x8 pixels. Portanto, pelo menos, precisamos de um coeficiente DCT para cada 64 pixels. Precisamos de um porque, em vez de armazenar um único coeficiente DCT seguido de 63 zeros, a codificação dos comprimentos das séries nos permite armazenar um número e indicar que "todos os outros são zeros".
A codificação delta é uma técnica na qual cada byte contém uma diferença de algum valor, em vez de um valor absoluto. Portanto, editar certos bytes altera a cor de todos os outros pixels. Por exemplo, em vez de armazenar
12 13 14 14 14 13 13 14
Poderíamos começar com 12 e, em seguida, simplesmente indicar quanto precisamos adicionar ou subtrair para obter o próximo número. E essa sequência na codificação delta assume a forma:12 1 1 0 0 -1 0 1 Osdados convertidos não são obtidos menos que o original, mas já é mais fácil compactá-lo. O uso da codificação delta antes da codificação das séries pode ajudar bastante, mantendo a compactação sem perdas.A codificação delta é uma das poucas técnicas usadas fora dos blocos 8x8. Dos 64 coeficientes DCT, um é simplesmente uma função de onda constante (cor sólida). Representa o brilho médio de cada bloco para os componentes de luminância ou o azul médio para os componentes Cb, e assim por diante. O primeiro valor de cada bloco DCT é chamado de valor DC, e cada valor DC passa por uma codificação delta em relação aos anteriores. Portanto, uma alteração no brilho do primeiro bloco afetará todos os blocos.O último mistério permanece: como a mudança singular estraga completamente toda a cena? Até agora, os níveis de compactação não tinham essas propriedades. A resposta está no cabeçalho JPEG. Os primeiros 500 bytes contêm metadados sobre a imagem - largura, altura etc., e até agora não trabalhamos com eles.Sem um cabeçalho, é quase impossível (bem ou muito difícil) decodificar JPEG. Parece que estou tentando descrever a imagem para você e começar a inventar palavras para transmitir minha impressão. A descrição provavelmente será muito concisa, porque posso inventar palavras com exatamente o significado que quero transmitir, mas, para todas as outras, elas não farão sentido.Parece estúpido, mas é exatamente isso que acontece. Cada imagem JPEG é compactada com códigos específicos. Um dicionário de códigos é armazenado no cabeçalho. Essa técnica é chamada de código Huffman e o dicionário é chamado tabela Huffman. No cabeçalho, a tabela é marcada com dois bytes - 255 e 196. Cada componente de cor pode ter sua própria tabela.Alterações nas tabelas afetarão radicalmente qualquer imagem. Um bom exemplo é alterar 1 em 12 na linha 15. Isso ocorre porque as tabelas indicam como ler bits individuais. Até agora, trabalhamos apenas com números binários na forma decimal. Mas isso nos oculta o fato de que, se você deseja armazenar o número 1 em um byte, será 00000001, pois cada byte deve ter exatamente oito bits, mesmo que apenas um deles seja necessário.Isso é potencialmente um grande desperdício de espaço se você tiver muitos números pequenos. O código de Huffman é uma técnica que nos permite relaxar esse requisito, segundo o qual cada número deve ocupar oito bits. Isso significa que se você vir dois bytes:234 115Isso, dependendo da tabela de Huffman, pode ter três números. Para extraí-los, primeiro é necessário dividi-los em bits separados:11101010 01110011Em seguida, passamos à tabela para entender como agrupá-los. Por exemplo, podem ser os primeiros seis bits (111010) ou 58 no sistema decimal, seguidos de cinco bits (10011) ou 19 e, finalmente, os últimos quatro bits (0011) ou 3.Portanto, é muito difícil entender bytes nesta fase de compressão. Bytes não representam o que parece. Não entrarei em detalhes sobre como trabalhar com a tabela neste artigo, mas existem materiais suficientes sobre esse assunto na rede .Um dos truques interessantes que você pode fazer se souber separar o cabeçalho do JPEG e armazená-lo separadamente. De fato, acontece que apenas você pode ler o arquivo. O Facebook está fazendo isso para reduzir ainda mais o tamanho do arquivo.O que mais você pode fazer é modificar bastante a tabela Huffman. Para outros, parecerá uma imagem danificada. E somente você saberá a versão mágica de sua correção.Para resumir: o que é necessário para a decodificação JPEG?
Isso ocorre porque as tabelas indicam como ler bits individuais. Até agora, trabalhamos apenas com números binários na forma decimal. Mas isso nos oculta o fato de que, se você deseja armazenar o número 1 em um byte, será 00000001, pois cada byte deve ter exatamente oito bits, mesmo que apenas um deles seja necessário.Isso é potencialmente um grande desperdício de espaço se você tiver muitos números pequenos. O código de Huffman é uma técnica que nos permite relaxar esse requisito, segundo o qual cada número deve ocupar oito bits. Isso significa que se você vir dois bytes:234 115Isso, dependendo da tabela de Huffman, pode ter três números. Para extraí-los, primeiro é necessário dividi-los em bits separados:11101010 01110011Em seguida, passamos à tabela para entender como agrupá-los. Por exemplo, podem ser os primeiros seis bits (111010) ou 58 no sistema decimal, seguidos de cinco bits (10011) ou 19 e, finalmente, os últimos quatro bits (0011) ou 3.Portanto, é muito difícil entender bytes nesta fase de compressão. Bytes não representam o que parece. Não entrarei em detalhes sobre como trabalhar com a tabela neste artigo, mas existem materiais suficientes sobre esse assunto na rede .Um dos truques interessantes que você pode fazer se souber separar o cabeçalho do JPEG e armazená-lo separadamente. De fato, acontece que apenas você pode ler o arquivo. O Facebook está fazendo isso para reduzir ainda mais o tamanho do arquivo.O que mais você pode fazer é modificar bastante a tabela Huffman. Para outros, parecerá uma imagem danificada. E somente você saberá a versão mágica de sua correção.Para resumir: o que é necessário para a decodificação JPEG? É necessário:
- Extraia as tabelas Huffman do cabeçalho e decodifique os bits.
- Extraia coeficientes discretos de transformação de cosseno para cada componente de cor e brilho de cada bloco 8x8 executando transformações inversas de codificação de comprimentos e deltas de séries.
- , 88.
- , ( ).
- YCbCr RGB.
- !
Trabalho sério para facilitar a visualização de fotos com um gato! No entanto, o que eu mais gosto é que você pode ver como a tecnologia JPEG é centrada no ser humano. É baseado nas características de nossa percepção, o que nos permite obter uma compressão muito melhor do que as tecnologias convencionais. E agora, entendendo como o JPEG funciona, você pode imaginar como essas tecnologias podem ser transferidas para outras áreas. Por exemplo, a codificação delta no vídeo pode reduzir bastante o tamanho do arquivo, pois geralmente existem áreas inteiras que não mudam de quadro para quadro (por exemplo, plano de fundo).O código usado no artigo está aberto e contém instruções para substituir imagens por você.