Até o momento, o serviço Bitrix24 não possui centenas de gigabits de tráfego, não há uma grande frota de servidores (embora existam, é claro, muitos existentes). Mas para muitos clientes, é a principal ferramenta para trabalhar na empresa, é um aplicativo essencial para os negócios. Portanto, caindo - bem, de jeito nenhum. Mas e se a queda acontecesse, mas o serviço "se rebelasse" tão rapidamente que ninguém notasse nada? E como você consegue implementar o failover sem perder a qualidade do trabalho e o número de clientes? Alexander Demidov, diretor de serviços em nuvem Bitrix24, contou ao nosso blog sobre como o sistema de backup evoluiu ao longo dos 7 anos de existência do produto.

“Na forma de SaaS, lançamos o Bitrix24 há 7 anos. A principal dificuldade, provavelmente, foi a seguinte: antes de ser lançado em público na forma de SaaS, este produto existia simplesmente no formato de uma solução in a box. Os clientes compraram de nós, os colocaram em seus servidores, criaram um portal corporativo - uma solução comum para comunicação com funcionários, armazenamento de arquivos, gerenciamento de tarefas, CRM, só isso. E até 2012, decidimos que queríamos lançá-lo como um SaaS, administrando-o nós mesmos, fornecendo tolerância a falhas e confiabilidade. Adquirimos experiência no processo, porque até então simplesmente não possuíamos - éramos apenas fabricantes de software, não fornecedores de serviços.
Ao iniciar o serviço, entendemos que o mais importante é garantir a tolerância a falhas, a confiabilidade e a disponibilidade constante do serviço, porque se você tem um site regular simples, uma loja, por exemplo, e ele caiu de você e fica uma hora - apenas você sofre, você perde pedidos , você perde clientes, mas para o seu cliente - para ele, isso não é muito crítico. Ele ficou chateado, é claro, mas foi comprar em outro site. E se esse é um aplicativo ao qual todos trabalham dentro da empresa, comunicações e decisões, o mais importante é conquistar a confiança dos usuários, ou seja, não decepcioná-los e não cair. Porque todo o trabalho pode melhorar se algo dentro não funcionar.
Bitrix.24 como SaaS
O primeiro protótipo que montamos um ano antes do lançamento público, em 2011. Reunidos em cerca de uma semana, pareciam retorcidos - ele estava mesmo trabalhando. Ou seja, foi possível entrar no formulário, inserir o nome do portal ali, um novo portal se desenrolando, uma base de usuários sendo configurada. Examinamos, avaliamos o produto em princípio, desligamos e finalizamos um ano depois. Como tínhamos uma grande tarefa: não queríamos criar duas bases de código diferentes, não queríamos oferecer suporte a um produto em caixa separado, soluções em nuvem separadamente - queríamos fazer tudo isso dentro do mesmo código.

Uma aplicação web típica da época é um servidor no qual algum código php está sendo executado, a base do mysql, os arquivos estão sendo baixados, os documentos e as fotos são colocados no pai do upload - bem, tudo funciona. Infelizmente, é impossível executar um serviço da Web criticamente sustentável nisso. O cache distribuído não é suportado lá, a replicação de banco de dados não é suportada.
Formulamos os requisitos: essa capacidade de estar localizado em diferentes locais, para suportar a replicação, idealmente para estar localizado em diferentes data centers distribuídos geograficamente. Separe a lógica do produto e, de fato, o armazenamento de dados. Dinamicamente ser capaz de escalar de acordo com a carga, geralmente faz a estática. A partir dessas considerações, de fato, havia requisitos para o produto, que acabamos de desenvolver durante o ano. Durante esse período, em uma plataforma que acabou sendo unificada - para soluções in a box, para nosso próprio serviço - apoiamos o que precisávamos. Suporte para replicação mysql no nível do produto em si: ou seja, o desenvolvedor que escreve o código não pensa em como suas solicitações serão distribuídas, ele usa nossa API e podemos distribuir corretamente solicitações de gravação e leitura entre mestres e escravos.
Fornecemos suporte em nível de produto para vários armazenamentos de objetos na nuvem: armazenamento do google, amazon s3, - plus, suporte para pilha aberta rápida. Portanto, era conveniente tanto para nós como um serviço quanto para desenvolvedores que trabalham com uma solução in a box: se eles apenas usarem nossa API para o trabalho, não pensam onde o arquivo será salvo, localmente no sistema de arquivos ou no armazenamento de arquivo de objeto .
Como resultado, decidimos imediatamente que reservaríamos no nível de um data center inteiro. Em 2012, lançamos completamente o Amazon AWS, porque já tínhamos experiência com essa plataforma - nosso próprio site estava hospedado lá. Ficamos atraídos pelo fato de que em cada região da Amazônia existem várias zonas de acesso - de fato (em sua terminologia) vários datacenters mais ou menos independentes entre si e que nos permitem reservar no nível de um datacenter inteiro: se repentinamente falha, os bancos de dados mestre-mestre são replicados, os servidores de aplicativos da web são reservados e a estática é movida para o armazenamento de objeto s3. A carga é equilibrada - naquele momento, o cotovelo da Amazônia, mas um pouco mais tarde chegamos a nossos próprios balanceadores, porque precisávamos de uma lógica mais complexa.
O que eles queriam, eles conseguiram ...
Todas as coisas básicas que queríamos fornecer - a tolerância a falhas dos próprios servidores, aplicativos da web, bancos de dados - tudo funcionou bem. O cenário mais simples: se alguns aplicativos da Web falharem, tudo será simples - eles serão desligados da balança.

O balanceador de máquinas (na época era um cotovelo da Amazônia) que causou um acidente na própria máquina, marcado como não íntegro, desativou a distribuição de carga neles. O dimensionamento automático da Amazônia funcionou: quando a carga aumentou, novos carros foram adicionados ao grupo de dimensionamento automático, a carga foi distribuída para carros novos - tudo estava bem. Com nossos balanceadores, a lógica é praticamente a mesma: se algo acontecer com o servidor de aplicativos, removeremos solicitações dele, jogaremos essas máquinas fora, iniciaremos novas e continuaremos trabalhando. O esquema para todos esses anos mudou um pouco, mas continua funcionando: é simples, compreensível e não há dificuldades com isso.
Trabalhamos em todo o mundo, o pico de carga dos clientes é completamente diferente e, de uma maneira boa, devemos ser capazes de executar determinados trabalhos de manutenção com qualquer componente do sistema a qualquer momento - invisivelmente para os clientes. Portanto, temos a oportunidade de desligar o banco de dados do trabalho, redistribuindo a carga no segundo data center.
Como tudo isso funciona? - Mudamos o tráfego para um datacenter em funcionamento - se for um acidente no datacenter, então completamente, se é o trabalho planejado com qualquer base, então fazemos parte do tráfego que atende esses clientes, mudamos para o segundo datacenter e para replicação. Se você precisar de novas máquinas para aplicativos da Web, à medida que a carga no segundo data center aumentar, elas serão iniciadas automaticamente. Terminamos o trabalho, a replicação é restaurada e retornamos toda a carga. Se precisarmos espelhar algum trabalho no segundo controlador de domínio, por exemplo, instalar atualizações do sistema ou alterar as configurações no segundo banco de dados, em geral, repetimos a mesma coisa, da outra maneira. E se isso for um acidente, fazemos tudo de maneira trivial: no sistema de monitoramento, usamos o mecanismo de manipuladores de eventos. Se várias verificações funcionarem para nós e o status for crítico, esse manipulador será iniciado, um manipulador que pode executar essa ou aquela lógica. Para cada banco de dados, registramos qual servidor possui failover e onde você precisa trocar o tráfego, se não estiver disponível. Nós - como ele se desenvolveu historicamente - usamos de uma forma ou de outra nagios ou qualquer um de seus garfos. Em princípio, mecanismos semelhantes existem em quase qualquer sistema de monitoramento; ainda não estamos usando algo mais complicado, mas talvez um dia o usemos. Agora, o monitoramento é acionado pela inacessibilidade e tem a capacidade de mudar alguma coisa.
Reservamos tudo?
Temos muitos clientes dos EUA, muitos clientes da Europa, muitos clientes mais próximos do leste - Japão, Cingapura e assim por diante. Claro, uma enorme proporção de clientes na Rússia. Ou seja, o trabalho está longe de estar em uma região. Os usuários desejam uma resposta rápida, há requisitos para a observação de várias leis locais e, em cada região, reservamos dois data centers, além de alguns serviços adicionais que, novamente, são convenientes para serem colocados em uma região - para clientes que estão nessa região. trabalho regional. Manipuladores REST, servidores de autorização, eles são menos críticos para o cliente como um todo. Você pode alternar entre eles com um pequeno atraso aceitável, mas não deseja inventar bicicletas, como monitorá-las e o que fazer com elas. Portanto, ao máximo, estamos tentando usar as soluções existentes, e não desenvolver alguma competência em produtos adicionais. E em algum lugar, usamos trivialmente a comutação no nível de DNS e determinamos a vitalidade do serviço com o mesmo DNS. A Amazon possui um serviço Route 53, mas não é apenas um DNS para o qual você pode gravar tudo, é muito mais flexível e conveniente. Por meio dele, você pode criar serviços de distribuição geográfica com geolocalizações, quando usá-lo para determinar de onde o cliente veio e fornecer a eles certos registros - com ele, você pode construir arquiteturas de failover. As mesmas verificações de saúde são configuradas no próprio Route 53, você especifica pontos de extremidade monitorados, define métricas e especifica quais protocolos determinam a vitalidade do serviço - tcp, http, https; defina a frequência das verificações que determinam se o serviço está ativo ou não. E no próprio DNS você prescreve o que será primário, o que será secundário, para onde mudar se a verificação de saúde dentro da rota 53 for acionada. Tudo isso pode ser feito com outras ferramentas, mas o que é mais conveniente - uma vez configurado e depois não pensamos em como fazemos verificações, como trocamos: tudo funciona por si só.
O primeiro “mas” : como e como reservar a própria rota 53? Isso acontece se algo acontecer com ele? Felizmente, nunca pisamos neste rake, mas novamente, na minha frente, terei uma história de por que pensamos que ainda precisamos reservar. Aqui colocamos a palha com antecedência. Várias vezes ao dia, descarregamos completamente todas as zonas que temos na rota 53. A API da Amazon permite enviá-los com segurança para JSON, e criamos vários servidores redundantes onde os convertemos, carregamos na forma de configurações e, grosso modo, temos uma configuração de backup. Nesse caso, podemos implantá-lo manualmente rapidamente, não perderemos os dados das configurações de DNS.
O segundo “mas” : o que não está reservado nesta figura? O balanceador ele mesmo! Nossa distribuição de clientes por região é muito simples. Temos domínios bitrix24.ru, bitrix24.com, .de - agora existem 13 domínios diferentes que funcionam em zonas muito diferentes. Chegamos ao seguinte: cada região tem seus próprios balanceadores. É mais conveniente distribuir por região, dependendo de onde está o pico de carga na rede. Se houver uma falha no nível de qualquer balanceador, ele será simplesmente desativado e removido do DNS. Se ocorrer um problema com um grupo de balanceadores, eles serão reservados em outros sites, e a alternância entre eles será feita usando a mesma rota53, porque, devido a um ttl curto, a alternância ocorre por no máximo 2, 3, 5 minutos.
O terceiro “mas” : o que ainda não foi reservado? S3, certo. Colocando os arquivos armazenados pelos usuários no s3, acreditamos sinceramente que era uma armadura e não havia necessidade de reservar nada lá. Mas a história mostra o que acontece de maneira diferente. Em geral, a Amazon descreve o S3 como um serviço fundamental, porque o próprio Amazon usa o S3 para armazenar imagens de máquinas, configurações, imagens AMI, instantâneos ... E se o s3 travar, como aconteceu nesses 7 anos, quanto bitrix24 estamos usando, é seguido por um fã puxa um monte de tudo - inacessibilidade ao iniciar máquinas virtuais, mau funcionamento da API e assim por diante.
E o S3 pode cair - aconteceu uma vez. Portanto, chegamos ao seguinte esquema: alguns anos atrás, não havia armazenamento público sério de objetos na Rússia, e estávamos considerando a opção de fazer algo nosso ... Felizmente, não começamos a fazê-lo, porque investigávamos aquele exame que não realizamos. possuir, e provavelmente teria feito isso. Agora o Mail.ru possui armazenamentos compatíveis com s3, o Yandex e vários provedores ainda o possuem. Como resultado, chegamos à conclusão de que queremos ter, primeiro, um backup e, em segundo lugar, a capacidade de trabalhar com cópias locais. Para uma região russa específica, usamos o serviço Mail.ru Hotbox, que é compatível com API s3. Não precisamos de modificações sérias no código dentro do aplicativo e fizemos o seguinte mecanismo: no s3 existem gatilhos que trabalham na criação / exclusão de objetos, a Amazon possui um serviço como o Lambda - este é um código em execução sem servidor que será executado apenas quando certos gatilhos são acionados.
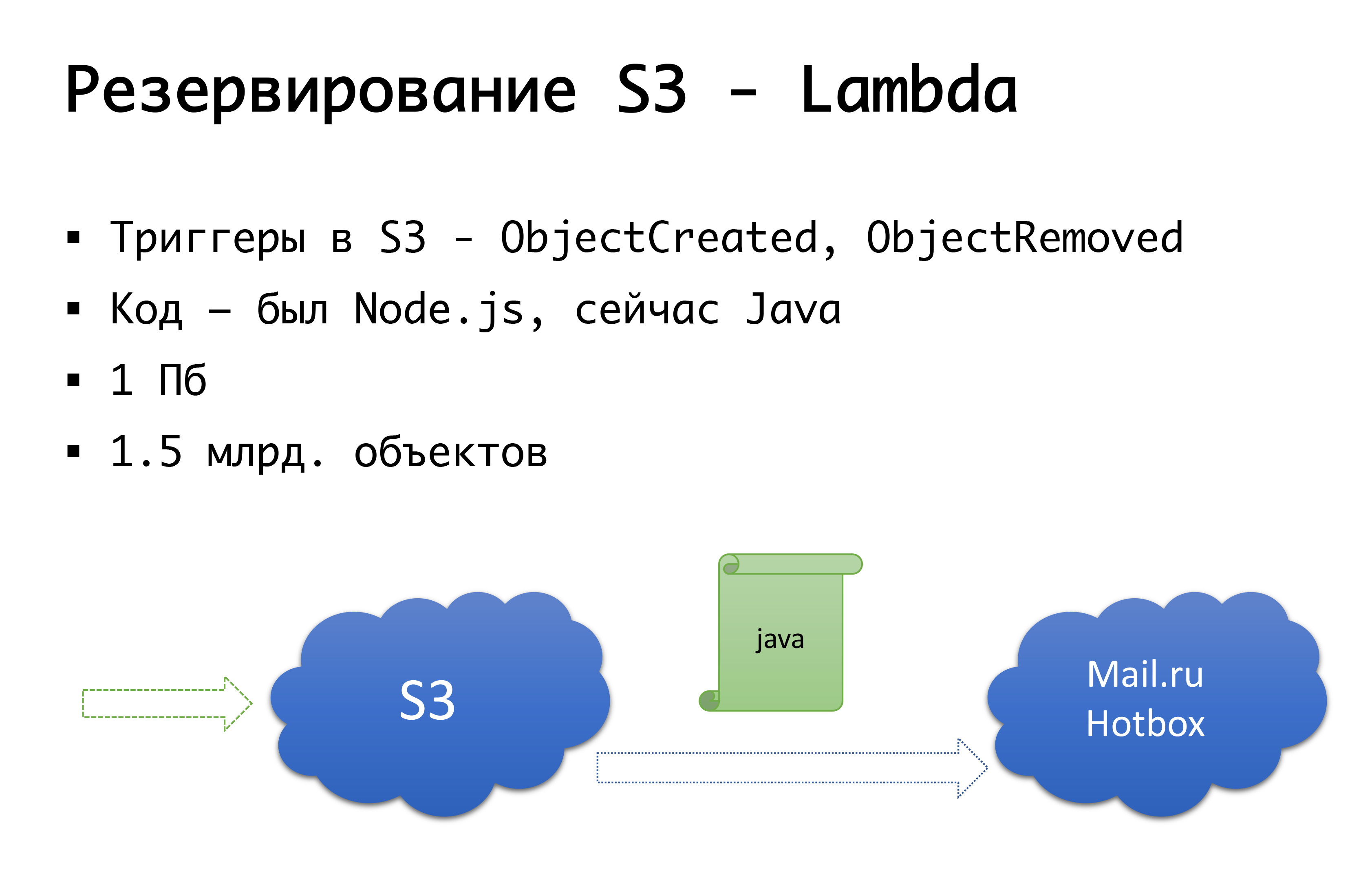
Fizemos isso de maneira muito simples: se o nosso gatilho for acionado, executaremos o código que copiará o objeto no repositório Mail.ru. Para começar a trabalhar totalmente com cópias locais de dados, também precisamos de sincronização reversa, para que os clientes localizados no segmento russo possam trabalhar com o armazenamento mais próximo deles. O Mail está prestes a concluir os gatilhos em seu repositório - será possível executar a sincronização reversa já no nível da infraestrutura, mas por enquanto estamos fazendo isso no nível do nosso próprio código. Se percebermos que o cliente colocou algum tipo de arquivo, no nível do código, colocamos o evento na fila, processamos e fazemos a replicação reversa. Por que isso é ruim: se tivermos algum tipo de trabalho com nossos objetos fora do nosso produto, ou seja, por alguns meios externos, não levaremos isso em consideração. Portanto, esperamos até o final, quando os gatilhos aparecerem no nível de armazenamento, para que, independentemente de onde executemos o código, o objeto que veio até nós seja copiado da outra maneira.
No nível do código, para cada cliente, os dois repositórios são registrados: um é considerado o principal e o outro é o backup. Se tudo estiver bem, trabalhamos com o armazenamento mais próximo de nós: nossos clientes que estão na Amazon, trabalham com o S3 e aqueles que trabalham na Rússia, trabalham com o Hotbox. Se a caixa de seleção funcionar, o failover deve se conectar a nós e trocaremos os clientes para outro armazenamento. Podemos definir esse sinalizador independentemente por região e alterná-los. Na prática, ainda não o usamos, mas imaginamos esse mecanismo e achamos que algum dia precisaremos e usaremos essa mesma opção. Uma vez que já aconteceu.
Ah, e sua Amazônia escapou ...
Este mês de abril é o aniversário do início dos bloqueios do Telegram na Rússia. O provedor mais afetado que veio com isso é a Amazon. E, infelizmente, as empresas russas que trabalharam em todo o mundo sofreram mais.
Se a empresa é global e a Rússia, por ser um segmento muito pequeno, 3-5% - bem, de uma forma ou de outra, você pode doá-las.
Se esta é uma empresa puramente russa - tenho certeza de que você precisa localizá-la localmente - bem, é justo que os próprios usuários sejam convenientes, confortáveis, haverá menos riscos.
E se esta é uma empresa que trabalha globalmente e possui quotas de clientes aproximadamente iguais da Rússia e de algum lugar do mundo? A conectividade dos segmentos é importante e eles devem trabalhar entre si de qualquer maneira.
No final de março de 2018, a Roskomnadzor enviou uma carta aos maiores operadores afirmando que planejava bloquear vários milhões de ip da Amazon para bloquear ... o Zello messenger. Graças a esses mesmos fornecedores, eles vazaram a carta com sucesso para todos, e havia um entendimento de que a conectividade com a Amazon poderia desmoronar. Era sexta-feira, corremos em pânico para os colegas do servers.ru, com as palavras: "Amigos, precisamos de vários servidores que não estarão na Rússia, não na Amazônia, mas, por exemplo, em algum lugar de Amsterdã". para poder, de alguma forma, colocar nosso próprio VPN e proxy lá para alguns pontos de extremidade que não podemos influenciar, por exemplo, pontos finais do mesmo s3 - não podemos tentar aumentar um novo serviço e obter outro IP, você ainda precisa chegar lá. Em alguns dias, configuramos esses servidores, aumentamos e, em geral, preparamos o início dos bloqueios. É curioso que o ILV, olhando para o hype e o pânico elevado, tenha dito: "Não, não vamos bloquear nada agora". (Mas isso é exatamente até o momento em que eles começaram a bloquear os telegramas.) Depois de configurar as opções de desvio e perceber que eles não entraram na fechadura, nós, no entanto, não desmontamos tudo. Então, apenas no caso.

E em 2019, ainda vivemos nas condições de bloqueios. Eu olhei ontem à noite: cerca de um milhão de ip continuam bloqueados. É verdade que a Amazon quase completamente desbloqueada, no pico atingiu 20 milhões de endereços ... Em geral, a realidade é que conectividade, boa conectividade - pode não ser. De repente. Pode não ser por razões técnicas - incêndios, escavadeiras, tudo isso. Ou, como vimos, não totalmente técnico. Portanto, alguém grande e grande, com seu próprio AS-kami, provavelmente pode orientá-lo de outras maneiras - a conexão direta e outras coisas já estão no nível l2. Mas, em uma versão simples, assim como nós ou ainda menor, você pode, no caso de ter, redundância no nível de servidores criados em outro local, configurado com antecedência vpn, proxy, com a capacidade de alternar rapidamente configurações nos segmentos com conectividade crítica . Isso foi útil para nós mais de uma vez, quando os bloqueios da Amazon começaram, deixamos o tráfego do S3 na pior das hipóteses, mas gradualmente tudo deu errado.
E como reservar ... todo o provedor?
Agora não temos cenário em caso de falha de toda a Amazônia. Temos um cenário semelhante para a Rússia. Nós, na Rússia, estávamos hospedados por um provedor, de quem escolhemos ter vários sites. E há um ano, encontramos um problema: mesmo sendo dois data centers, já pode haver problemas no nível da configuração de rede do provedor que afetarão os dois data centers de qualquer maneira. E podemos obter inacessibilidade nos dois sites. Claro, foi isso que aconteceu. Finalmente redefinimos a arquitetura interna. Não mudou muito, mas para a Rússia agora temos dois sites, que não são um provedor, mas dois diferentes. Se um deles falhar, podemos mudar para outro.
Hipoteticamente, estamos considerando que a Amazon se reserve no nível de outro fornecedor; talvez Google, talvez outra pessoa ... Mas até agora observamos na prática que, se a Amazon travar no mesmo nível de zona de disponibilidade, travamentos no nível de uma região inteira são bastante raros. Portanto, teoricamente, temos a ideia de que, talvez, façamos uma reserva “Amazônia não é Amazônia”, mas na prática isso ainda não existe.
Algumas palavras sobre automação
Você sempre precisa de automação? É apropriado recuperar o efeito Dunning-Krueger. No eixo x, nosso conhecimento e experiência, que estamos obtendo, e no eixo y - confiança em nossas ações. A princípio, não sabemos nada e não temos certeza. Então, sabemos um pouco e nos tornamos mega-confiantes - esse é o chamado "pico da estupidez", bem ilustrado pelo quadro "demência e coragem". Além disso, já aprendemos um pouco e estamos prontos para a batalha. Então pisamos em um rake mega sério, caímos em um vale de desespero quando parecemos saber alguma coisa, mas na verdade não sabemos muito. Então, à medida que você ganha experiência, nos tornamos mais confiantes.
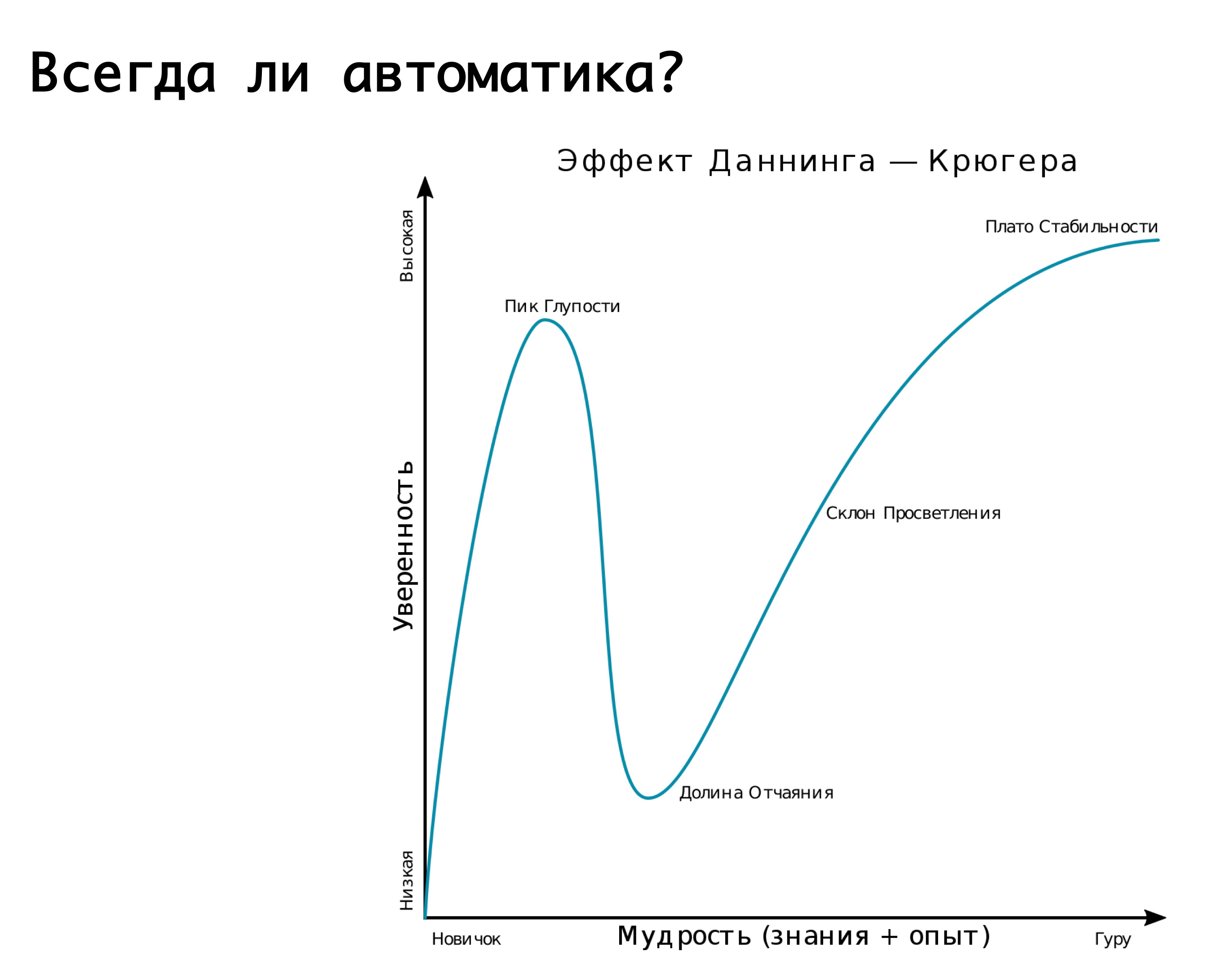
Nossa lógica sobre várias mudanças automaticamente para um ou outro acidente é muito bem descrita por este gráfico. — , . , , , . -: false positive, - , , -, . , - — . , . , . Mas! , , , , , , …
Conclusão
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
Um compromisso razoável entre perfeccionismo e forças reais, tempo, dinheiro que você pode gastar no esquema que acabará tendo.Este texto é uma versão suplementar e ampliada do relatório de Alexander Demidov na conferência Uptime day 4 .