Os aplicativos da Web agora são amplamente utilizados, e o HTTP é a maior parte de todos os protocolos de transporte. Estudando as nuances do desenvolvimento de aplicativos da Web, a maioria deles presta muito pouca atenção ao sistema operacional em que esses aplicativos realmente são executados. A separação entre desenvolvimento (Dev) e operação (Ops) só piorou as coisas. Mas com a disseminação da cultura DevOps, os desenvolvedores começam a assumir a responsabilidade de lançar seus aplicativos na nuvem, por isso é muito útil que eles se familiarizem completamente com o back-end do sistema operacional. Isso é especialmente útil se você estiver tentando implantar um sistema para milhares ou dezenas de milhares de conexões simultâneas.
Limitações nos serviços da web são muito semelhantes às limitações em outros aplicativos. Seja balanceadores de carga ou servidores de banco de dados, todos esses aplicativos têm problemas semelhantes em um ambiente de alto desempenho. Compreender essas limitações fundamentais e como superá-las em geral ajudará a avaliar o desempenho e a escalabilidade de seus aplicativos da web.
Estou escrevendo esta série de artigos em resposta a perguntas de jovens desenvolvedores que desejam se tornar arquitetos de sistemas bem informados. É impossível entender claramente os métodos de otimização de aplicativos Linux sem se aprofundar no básico de como eles funcionam no nível do sistema operacional. Embora existam muitos tipos de aplicativos, nesta série eu quero explorar aplicativos de rede, não os de desktop, como um navegador ou editor de texto. Este material é destinado a desenvolvedores e arquitetos que desejam entender como os programas Linux ou Unix funcionam e como estruturá-los para obter alto desempenho.
O Linux é um sistema operacional de
servidor e, na maioria das vezes, seus aplicativos são executados nesse SO específico. Embora eu diga "Linux", na maioria das vezes você pode assumir com segurança que todos os sistemas operacionais semelhantes ao Unix são geralmente usados. No entanto, não testei o código que o acompanha em outros sistemas. Portanto, se você está interessado no FreeBSD ou OpenBSD, o resultado pode variar. Quando tento algo específico do Linux, aponto.
Embora você possa usar esse conhecimento para criar um aplicativo a partir do zero, e ele será perfeitamente otimizado, é melhor não. Se você escrever um novo servidor Web em C ou C ++ para o aplicativo de negócios da sua organização, este poderá ser seu último dia de trabalho. No entanto, o conhecimento da estrutura desses aplicativos ajudará na seleção dos programas existentes. Você pode comparar sistemas baseados em processos com sistemas baseados em encadeamento e baseados em eventos. Você entenderá e entenderá por que o Nginx funciona melhor que o Apache httpd, por que um aplicativo Python baseado em Tornado pode atender a mais usuários do que um aplicativo Python baseado em Django.
ZeroHTTPd: Ferramenta de Aprendizagem
ZeroHTTPd é um servidor web que escrevi do zero em C como uma ferramenta de treinamento. Não possui dependências externas, incluindo acesso ao Redis. Nós executamos nossas próprias rotinas Redis. Veja abaixo para mais detalhes.
Embora possamos discutir a teoria por um longo tempo, não há nada melhor do que escrever código, executá-lo e comparar todas as arquiteturas de servidor. Este é o método mais óbvio. Portanto, escreveremos um servidor Web ZeroHTTPd simples usando cada modelo: com base em processos, threads e eventos. Vamos verificar cada um desses servidores e ver como eles funcionam em comparação. O ZeroHTTPd é implementado em um único arquivo C. O servidor baseado em eventos inclui
uthash , uma excelente implementação de tabela de hash que é
enviada em um único arquivo de cabeçalho. Em outros casos, não há dependências, para não complicar o projeto.
Existem muitos comentários no código para ajudar a resolvê-lo. Sendo um servidor web simples em algumas linhas de código, o ZeroHTTPd também é uma estrutura mínima de desenvolvimento web. Possui funcionalidade limitada, mas é capaz de produzir arquivos estáticos e páginas "dinâmicas" muito simples. Devo dizer que o ZeroHTTPd é adequado para aprender a criar aplicativos Linux de alto desempenho. Em geral, a maioria dos serviços da Web espera por solicitações, verifica-as e processa-as. É exatamente isso que o ZeroHTTPd fará. Esta é uma ferramenta de aprendizado, não uma ferramenta de produção. Ele não é bom em lidar com erros e é improvável que se orgulhe das melhores práticas de segurança (ah, sim, eu usei o
strcpy ) ou dos truques abstrusos de C. Mas espero que ele faça bem seu trabalho.
 Página inicial do ZeroHTTPd. Pode produzir diferentes tipos de arquivos, incluindo imagens
Página inicial do ZeroHTTPd. Pode produzir diferentes tipos de arquivos, incluindo imagensPedido de Livro de Visitas
Aplicativos web modernos geralmente não se limitam a arquivos estáticos. Eles têm interações complexas com vários bancos de dados, caches, etc. Portanto, criaremos um aplicativo da Web simples chamado “Livro de Visitas”, onde os visitantes deixam entradas com seus nomes. O livro de visitas salva as entradas deixadas anteriormente. Há também um balcão de visitantes na parte inferior da página.
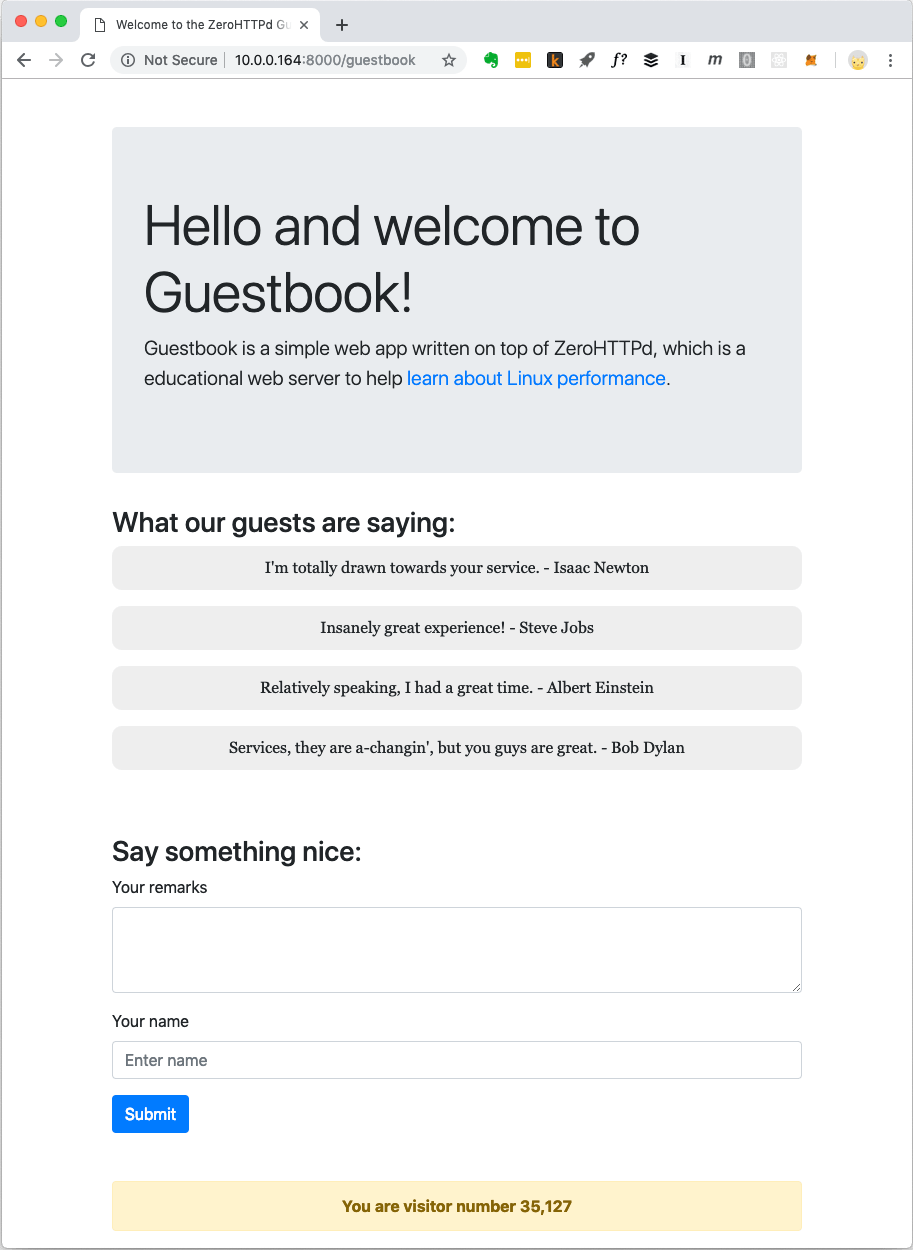 Aplicativo Web de Livro de Visitas ZeroHTTPd
Aplicativo Web de Livro de Visitas ZeroHTTPdAs entradas do contador de visitantes e do livro de visitas são armazenadas no Redis. Para comunicação com o Redis, procedimentos próprios são implementados; eles são independentes de uma biblioteca externa. Eu não sou um grande fã de codificar códigos internos quando existem soluções publicamente disponíveis e bem testadas. Mas o objetivo do ZeroHTTPd é estudar o desempenho do Linux e o acesso a serviços externos, enquanto o atendimento de solicitações HTTP afeta seriamente o desempenho. Devemos controlar totalmente as comunicações com o Redis em cada uma de nossas arquiteturas de servidor. Em uma arquitetura, usamos chamadas de bloqueio, em outras, usamos procedimentos baseados em eventos. O uso de uma biblioteca cliente Redis externa não dará esse controle. Além disso, nosso pequeno cliente Redis executa apenas algumas funções (obter, configurar e aumentar uma chave; obter e adicionar a uma matriz). Além disso, o protocolo Redis é excepcionalmente elegante e simples. Ele nem precisa ser ensinado especialmente. O fato de o protocolo executar todo o trabalho em cerca de cem linhas de código indica o quão bem pensado é.
A figura a seguir mostra o aplicativo quando o cliente (navegador) solicita
/guestbookURL .
 O mecanismo do aplicativo de livro de visitas
O mecanismo do aplicativo de livro de visitasQuando você precisa emitir uma página do livro de visitas, há uma chamada para o sistema de arquivos para ler o modelo na memória e três chamadas de rede para o Redis. O arquivo de modelo contém a maior parte do conteúdo HTML da página na captura de tela acima. Também existem espaços reservados especiais para a parte dinâmica do conteúdo: contador de registros e visitantes. Nós os obtemos do Redis, os inserimos na página e fornecemos ao cliente conteúdo completo. Uma terceira chamada para Redis pode ser evitada porque Redis retorna um novo valor de chave quando incrementado. No entanto, para o nosso servidor com uma arquitetura assíncrona baseada em eventos, muitas chamadas de rede são um bom teste para fins de treinamento. Assim, descartamos o valor de retorno da Redis sobre o número de visitantes e solicitamos em uma chamada separada.
Arquiteturas de servidor ZeroHTTPd
Estamos construindo sete versões do ZeroHTTPd com a mesma funcionalidade, mas com arquiteturas diferentes:
- Iterativo
- Servidor fork (um processo filho por solicitação)
- Servidor pré-fork (processos de pré-bifurcação)
- Servidor com threads (uma thread por solicitação)
- Servidor com pré-threading
- Arquitetura baseada em
poll()
- Arquitetura Epoll
Medimos o desempenho de cada arquitetura carregando o servidor com solicitações HTTP. Porém, ao comparar arquiteturas com um alto grau de paralelismo, o número de solicitações aumenta. Testamos três vezes e consideramos a média.
Metodologia de teste
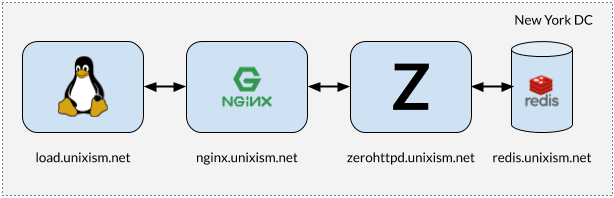 Instalação para teste de estresse ZeroHTTPd
Instalação para teste de estresse ZeroHTTPdÉ importante que, ao executar testes, todos os componentes não funcionem na mesma máquina. Nesse caso, o sistema operacional carrega custos adicionais de planejamento, uma vez que os componentes competem pela CPU. Medir a sobrecarga do sistema operacional de cada uma das arquiteturas de servidor selecionadas é um dos objetivos mais importantes deste exercício. Adicionar mais variáveis será prejudicial ao processo. Portanto, a configuração na figura acima funciona melhor.
O que cada um desses servidores faz
- load.unixism.net: aqui executamos
ab , o utilitário Apache Benchmark. Ele gera a carga necessária para testar nossas arquiteturas de servidor.
- nginx.unixism.net: às vezes queremos executar mais de uma instância de um programa de servidor. Para isso, o servidor Nginx com as configurações apropriadas funciona como um balanceador de carga vindo de ab para os processos do servidor.
- zerohttpd.unixism.net: aqui executamos nossos programas de servidor em sete arquiteturas diferentes, uma de cada vez.
- redis.unixism.net: o daemon Redis está em execução neste servidor, onde as entradas são armazenadas no livro de visitas e no contador de visitantes.
Todos os servidores são executados em um único núcleo do processador. A idéia é avaliar o desempenho máximo de cada arquitetura. Como todos os programas de servidor são testados no mesmo hardware, este é o nível básico para compará-los. Minha configuração de teste consiste em servidores virtuais alugados da Digital Ocean.
O que estamos medindo?
Você pode medir diferentes indicadores. Avaliamos o desempenho de cada arquitetura nessa configuração, carregando servidores com solicitações em diferentes níveis de simultaneidade: a carga cresce de 20 para 15.000 usuários simultâneos.
Resultados do teste
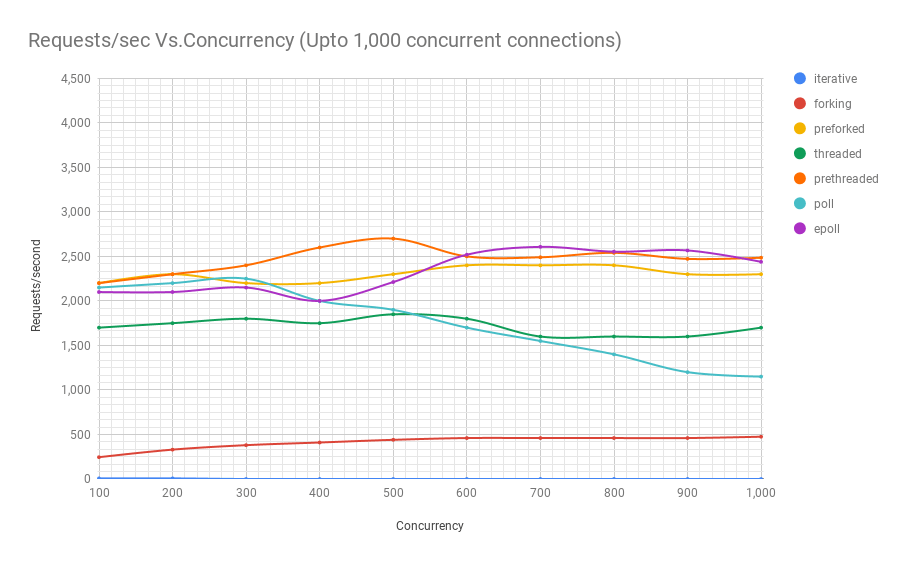
O diagrama a seguir mostra o desempenho de servidores em diferentes arquiteturas em diferentes níveis de simultaneidade. O eixo y é o número de solicitações por segundo, o eixo x são conexões paralelas.
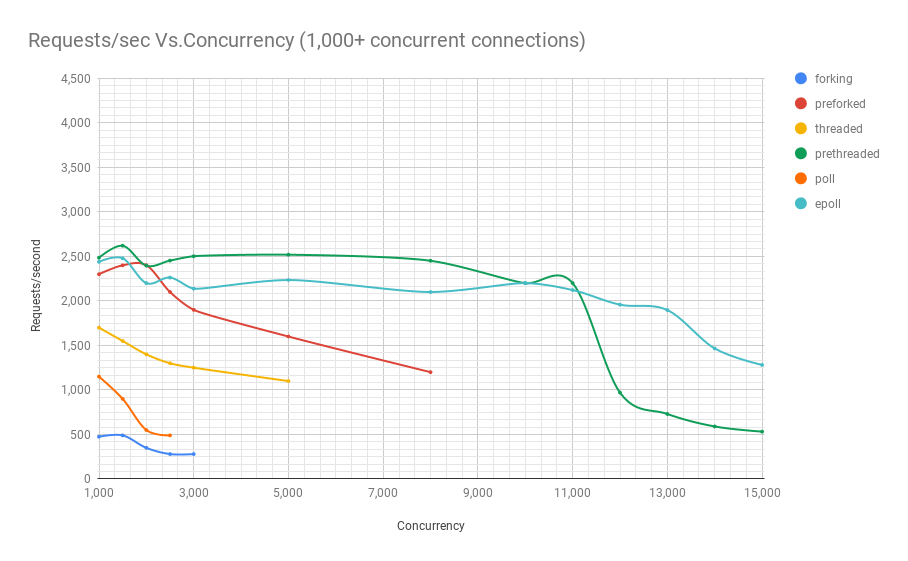
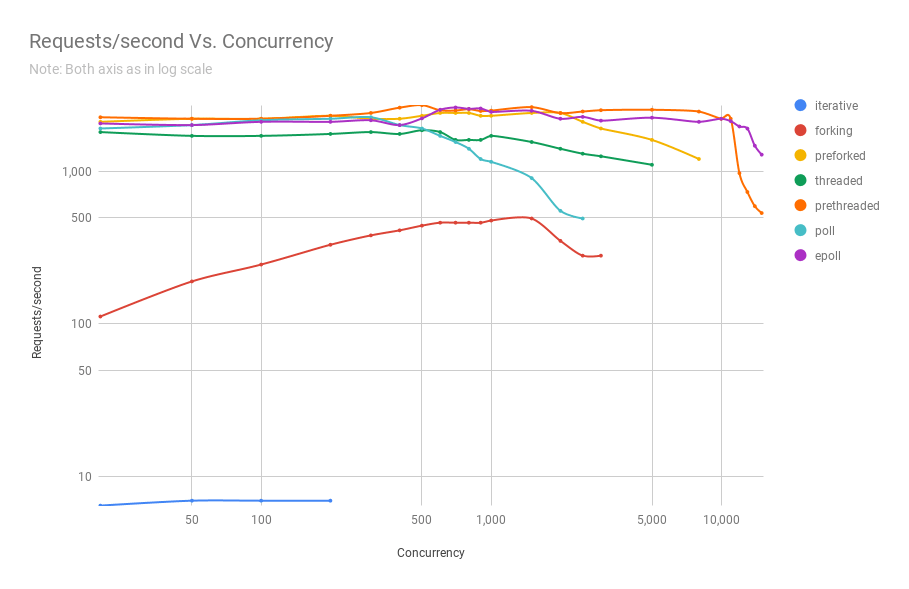
Abaixo está uma tabela com os resultados.
Pode ser visto no gráfico e na tabela que, acima de 8000 solicitações simultâneas, restam apenas dois jogadores: pré-fork e epoll. À medida que a carga aumenta, o servidor baseado em pesquisa executa pior que o servidor de streaming. A arquitetura pré-threading compete com o epoll: isso é uma prova de quão bem o kernel do Linux planeja um grande número de threads.
Código-fonte ZeroHTTPd
O código fonte do ZeroHTTPd está
aqui . Cada arquitetura possui um diretório separado.
ZeroHTTPd
│
01── 01_iterative
│ ├── main.c
├── 02_forking
│ ├── main.c
03── 03_preforking
│ ├── main.c
04── 04_threading
│ ├── main.c
05── 05_prethreading
│ ├── main.c
06── 06_poll
│ ├── main.c
07── 07_epoll
│ └── main.c
Make── Makefile
├── público
Index ├── index.html
T └── tux.png
└── modelos
└── livro de visitas
└── index.html Além de sete diretórios para todas as arquiteturas, há mais dois no diretório de nível superior: público e modelos. O primeiro contém o arquivo index.html e a imagem da primeira captura de tela. Outros arquivos e pastas podem ser colocados lá, e o ZeroHTTPd deve emitir esses arquivos estáticos sem problemas. Se o caminho no navegador corresponder ao da pasta pública, o ZeroHTTPd procurará o arquivo index.html nesse diretório. O conteúdo do livro de visitas é gerado dinamicamente. Ele possui apenas a página principal e seu conteúdo é baseado no arquivo 'templates / guestbook / index.html'. ZeroHTTPd adiciona facilmente páginas dinâmicas para expansão. A idéia é que os usuários possam adicionar modelos a esse diretório e estender o ZeroHTTPd conforme necessário.
Para criar todos os sete servidores, execute
make all do diretório de nível superior - e todas as builds aparecerão nesse diretório. Os executáveis procuram os diretórios público e de modelos no diretório de onde são executados.
API do Linux
Para entender as informações nesta série de artigos, não é necessário conhecer bem a API do Linux. No entanto, eu recomendo ler mais sobre este tópico, existem muitos recursos de referência na Web. Embora abordemos várias categorias de APIs do Linux, nosso foco será principalmente em processos, encadeamentos, eventos e pilha de rede. Além de livros e artigos sobre a API do Linux, também recomendo a leitura de mana para chamadas do sistema e funções de biblioteca usadas.
Desempenho e escalabilidade
Uma observação sobre desempenho e escalabilidade. Teoricamente, não há conexão entre eles. Você pode ter um serviço da web que funcione muito bem, com um tempo de resposta de alguns milissegundos, mas não é escalável. Da mesma forma, pode haver um aplicativo da Web com uma execução insuficiente que leva alguns segundos para responder, mas é escalável para dezenas para lidar com dezenas de milhares de usuários simultâneos. No entanto, a combinação de alto desempenho e escalabilidade é uma combinação muito poderosa. Aplicativos de alto desempenho geralmente usam recursos economicamente e, assim, atendem efetivamente a usuários mais concorrentes no servidor, reduzindo custos.
Tarefas de CPU e E / S
Por fim, sempre existem dois tipos possíveis de tarefas na computação: para E / S e CPU. Receber solicitações via Internet (E / S de rede), manutenção de arquivos (E / S de rede e disco), comunicação com o banco de dados (E / S de rede e disco) são todas ações de E / S. Algumas consultas ao banco de dados podem carregar um pouco a CPU (classificando, calculando a média de um milhão de resultados etc.). A maioria dos aplicativos da web é limitada pelo máximo de E / S possível, e o processador raramente é usado na capacidade total. Quando você vê que algumas CPUs usam muitas CPUs, isso provavelmente é um sinal de arquitetura de aplicativo ruim. Isso pode significar que os recursos da CPU são gastos no controle do processo e na alternância de contexto - e isso não é totalmente útil. Se você estiver executando algo como processamento de imagem, conversão de áudio ou aprendizado de máquina, o aplicativo precisará de recursos poderosos da CPU. Mas para a maioria das aplicações não é assim.
Mais sobre arquiteturas de servidor
- Parte I. Arquitetura Iterativa
- Parte II Servidores de garfo
- Parte III Servidores pré-fork
- Parte IV Servidores com Threads
- Parte V. Servidores com Pré-Criação de Encadeamentos
- Parte VI Arquitetura baseada em pesquisas
- Parte VII Arquitetura Epoll