O HighLoad ++ existe
há muito tempo e falamos sobre trabalhar com o PostgreSQL regularmente. Mas os desenvolvedores ainda têm os mesmos problemas de mês para mês, de ano para ano. Quando em pequenas empresas sem um DBA no estado há erros no trabalho com bancos de dados, isso não é surpreendente. As grandes empresas também precisam de bancos de dados e, mesmo com processos depurados, os erros ainda ocorrem e os bancos de dados caem. Não importa qual o tamanho da empresa - ainda ocorrem erros, os bancos de dados periodicamente travam, travam.

Obviamente, isso nunca acontecerá com você, mas verificar a lista de verificação não é difícil e pode ser muito decente economizar nervos futuros. Abaixo, listamos os principais erros típicos que os desenvolvedores cometem ao trabalhar com o PostgreSQL, ver por que não precisamos fazer isso e descobrir como.
Sobre o palestrante: Alexey Lesovsky começou como administrador de sistemas Linux. Das tarefas de virtualização e monitoramento de sistemas, gradualmente chegou ao PostgreSQL. Agora, o PostgreSQL DBA na
Data Egret , uma empresa de consultoria que trabalha com muitos projetos diferentes e vê muitos exemplos de problemas recorrentes. Este é um
link para a apresentação do relatório no HighLoad ++ 2018.
De onde vêm os problemas
Para aquecer, algumas histórias sobre como os erros ocorrem.
História 1. Recursos
Um dos problemas é quais recursos a empresa usa ao trabalhar com o PostgreSQL. Tudo começa simples: PostgreSQL, conjuntos de dados, consultas simples com JOIN. Pegamos os dados, selecionamos - tudo é simples.
Então começamos a usar a funcionalidade adicional do PostgreSQL, adicionamos novas funções, extensões. O recurso está ficando maior. Nós conectamos replicação de streaming, sharding. Vários utilitários e kits corporais aparecem ao redor - pgbouncer, pgpool, patroni. Algo assim.

Cada palavra-chave é um motivo para o erro aparecer.
Histórico 2. Armazenamento de Dados
A maneira como armazenamos dados também é uma fonte de erros.
Quando o projeto apareceu pela primeira vez, havia muitos dados e tabelas nele. Consultas simples são suficientes para receber e registrar dados. Mas existem mais e mais tabelas. Os dados são selecionados em diferentes lugares, JOINs aparecem. As consultas são complicadas e incluem construções CTE, SUBQUERY, IN, LATERAL. Cometer um erro e escrever uma consulta de curva se torna muito mais fácil.
E esta é apenas a ponta do iceberg - em algum lugar do lado, pode haver outras 400 tabelas, partições, das quais os dados também são ocasionalmente lidos.
História 3. Ciclo de Vida
A história de como o produto é seguido. Os dados sempre precisam ser armazenados em algum lugar, para que haja sempre um banco de dados. Como um banco de dados se desenvolve quando um produto se desenvolve?
Por um lado, há
desenvolvedores que estão ocupados com linguagens de programação. Eles escrevem seus aplicativos e desenvolvem habilidades no campo do desenvolvimento de software, não prestando atenção aos serviços. Frequentemente, eles não estão interessados em como o Kafka ou o PostgreSQL funciona - eles desenvolvem novos recursos em sua aplicação e não se importam com o resto.
 Administradores, por
Administradores, por outro lado. Eles criam novas instâncias da Amazon no Bare-metal e estão ocupados com a automação: eles configuram uma implantação para fazer o layout funcionar bem e configuram-se para que os serviços interajam bem.

Existe uma situação em que não há tempo ou desejo de ajuste fino dos componentes e do banco de dados também. Os bancos de dados funcionam com configurações padrão e depois os esquecem completamente - "funciona, não toque".
Como resultado, os ancinhos estão espalhados em vários lugares, que de vez em quando voam para a testa dos desenvolvedores. Neste artigo, tentaremos coletar todos esses ancinhos em um barracão para que você os conheça e não os pise ao trabalhar com o PostgreSQL.
Planejamento e monitoramento
Primeiro, imagine que temos um novo projeto - é sempre um desenvolvimento ativo, teste de hipóteses e implementação de novos recursos. No momento em que o aplicativo acaba de aparecer e está em desenvolvimento, possui pouco tráfego, usuários e clientes, e todos eles geram pequenas quantidades de dados. O banco de dados possui consultas simples que são processadas rapidamente. Não há necessidade de arrastar grandes quantidades de dados, não há problemas.
Mas há mais usuários, o tráfego chega: novos dados são exibidos, os bancos de dados crescem e as consultas antigas param de funcionar. É necessário concluir índices, reescrever e otimizar consultas. Há problemas de desempenho. Tudo isso leva a alertas às quatro da manhã, estresse para os administradores e descontentamento da gerência.
O que está errado?
Na minha experiência, na maioria das vezes não há discos suficientes.
O primeiro exemplo . Abrimos o gráfico de monitoramento da utilização do disco e vemos que o
espaço livre no disco está acabando .
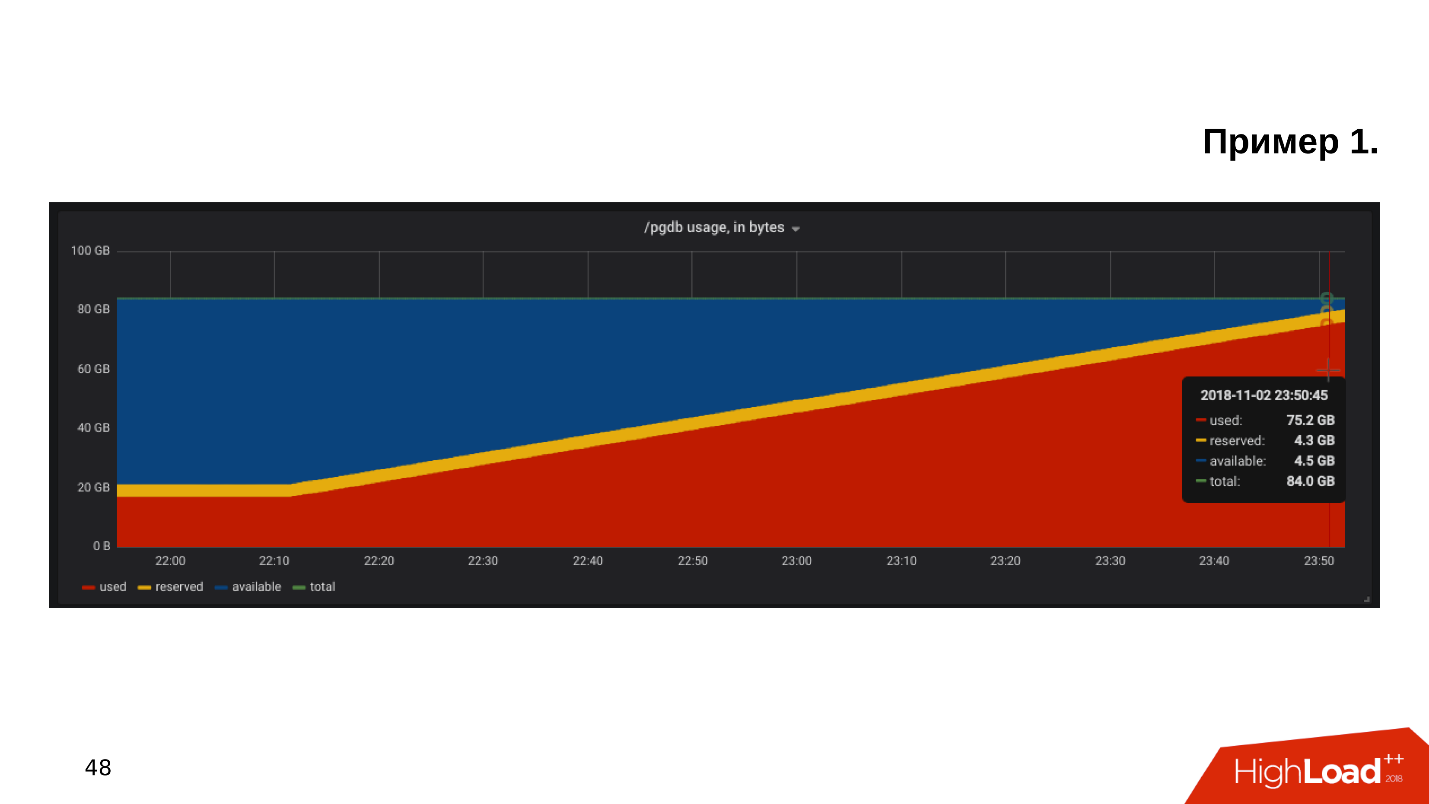
Observamos quanto espaço e o que é consumido - acontece que existe um diretório pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
Os administradores de banco de dados geralmente sabem o que é esse diretório e não o tocam - ele existe e existe. Mas o desenvolvedor, especialmente se ele olha para a encenação, coça a cabeça e pensa:
- Algum tipo de registro ... Vamos excluir o pg_xlog!Exclui o diretório, o banco de dados para de funcionar . Imediatamente, você precisa pesquisar no Google como aumentar o banco de dados após excluir os logs de transações.
 Segundo exemplo
Segundo exemplo . Novamente, abrimos o monitoramento e vemos que não há espaço suficiente. Desta vez, o local é ocupado por algum tipo de base.
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
Estamos procurando qual banco de dados ocupa mais espaço, quais tabelas e índices.

Acontece que esta é uma tabela com logs históricos. Nós nunca precisávamos de registros históricos. Eles são escritos apenas por precaução, e se não fosse pelo problema do local, ninguém os olharia até a segunda vinda:
- Vamos limpar tudo o que mm ... mais antigo que outubro!Faça um pedido de atualização, execute-o, ele funcionará e excluirá algumas das linhas.
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
A consulta é executada por 10 minutos, mas a tabela ainda ocupa a mesma quantidade de espaço.
O PostgreSQL remove as linhas da tabela - tudo está correto, mas não retorna o local ao sistema operacional. Esse comportamento do PostgreSQL é desconhecido para a maioria dos desenvolvedores e pode ser muito surpreendente.
O terceiro exemplo . Por exemplo, o ORM fez uma solicitação interessante. Geralmente, todo mundo culpa o ORM por fazer consultas "ruins" que leem algumas tabelas.
Suponha que haja várias operações JOIN que leem tabelas em paralelo em vários encadeamentos. O PostgreSQL pode paralelizar operações de dados e pode ler tabelas em vários threads. Mas, como temos vários servidores de aplicativos, essa consulta lê todas as tabelas milhares de vezes por segundo. Acontece que o servidor do banco de dados está sobrecarregado, os discos não conseguem lidar e tudo isso leva a um erro
502 Bad Gateway do back-end - o banco de dados está indisponível.
Mas isso não é tudo. Você pode recuperar outros recursos do PostgerSQL.
- Freios nos processos em segundo plano do DBMS - O PostgreSQL possui todos os tipos de pontos de verificação, vazios e replicação.
- Sobrecarga de virtualização . Quando o banco de dados está sendo executado em uma máquina virtual, no mesmo pedaço de ferro também existem máquinas virtuais ao lado e elas podem entrar em conflito com os recursos.
- O armazenamento é do fabricante chinês NoName , cujo desempenho depende da lua em Capricórnio ou da posição de Saturno, e não há como descobrir por que funciona dessa maneira. A base está sofrendo.
- A configuração padrão . Este é o meu tópico favorito: o cliente diz que seu banco de dados está ficando mais lento - veja bem, e ele tem uma configuração padrão. O fato é que a configuração padrão do PostgreSQL foi projetada para ser executada no bule mais fraco . A base é lançada, funciona, mas quando já funciona em hardware de nível médio, essa configuração não é suficiente, precisa ser ajustada.
Na maioria das vezes, o PostgreSQL não possui espaço em disco nem desempenho em disco. Felizmente, com processadores, memória e uma rede, tudo está mais ou menos em ordem.
Como ser Precisa de monitoramento e planejamento! Parece óbvio, mas por alguma razão, na maioria dos casos, ninguém planeja uma base, e o monitoramento não cobre tudo o que precisa ser monitorado durante a operação do PostgreSQL. Há um conjunto de regras claras, com as quais tudo funcionará bem, e não "aleatoriamente".
Planejamento
Hospede o banco de dados em um SSD sem hesitar . Os SSDs se tornaram confiáveis, estáveis e produtivos. Os modelos de SSD corporativo existem há anos.
Sempre planeje um esquema de dados . Não escreva no banco de dados que você duvida do que é necessário - garantido que não é necessário. Um exemplo simples é uma tabela ligeiramente modificada de um de nossos clientes.

Esta é uma tabela de log na qual há uma coluna de dados do tipo json. Relativamente falando, você pode escrever qualquer coisa nesta coluna. No último registro desta tabela, é possível observar que os logs ocupam 8 MB. O PostgreSQL não tem nenhum problema em armazenar registros desse tamanho. O PostgreSQL possui um armazenamento muito bom que mastiga esses registros.
Mas o problema é que, quando os servidores de aplicativos leem os dados desta tabela, eles entupem facilmente toda a largura de banda da rede e outras solicitações sofrem. Esse é o problema de planejar um esquema de dados.
Use o particionamento para qualquer dica de uma história que precise ser armazenada por mais de dois anos . O particionamento às vezes parece complicado - você precisa se preocupar com gatilhos, com funções que criarão partições. Nas novas versões do PostgreSQL, a situação é melhor e agora a configuração do particionamento é muito mais simples - uma vez feito e funciona.
No exemplo considerado de exclusão de dados em 10 minutos,
DELETE pode ser substituído por
DROP TABLE - uma operação semelhante em circunstâncias semelhantes levará apenas alguns milissegundos.
Quando os dados são classificados por partição, a partição é excluída literalmente em alguns milissegundos e o sistema operacional assume o controle imediatamente. Gerenciar dados históricos é mais fácil, mais fácil e mais seguro.
Monitoramento
O monitoramento é um grande tópico separado, mas do ponto de vista do banco de dados, existem recomendações que podem caber em uma seção do artigo.
Por padrão, muitos sistemas de monitoramento fornecem monitoramento de processadores, memória, rede, espaço em disco, mas, como regra,
não há descarte de dispositivos de disco . Informações sobre a carga dos discos, qual largura de banda está atualmente nos discos e o valor da latência sempre deve ser adicionado ao monitoramento. Isso o ajudará a avaliar rapidamente como as unidades são carregadas.
Existem muitas opções de monitoramento do PostgreSQL, existem para todos os gostos. Aqui estão alguns pontos que devem estar presentes.
- Clientes conectados . É necessário monitorar com quais status eles trabalham, encontrar rapidamente os clientes "nocivos" que prejudicam o banco de dados e desativá-los.
- Erros É necessário monitorar os erros para rastrear como o banco de dados funciona: nenhum erro - ótimo, erros apareceram - uma razão para examinar os logs e começar a entender o que está errado.
- Pedidos (declarações) . Monitoramos as características quantitativas e qualitativas das solicitações para avaliar aproximadamente se temos solicitações lentas, longas ou com uso intenso de recursos.
Para obter mais informações, consulte o relatório
“Noções básicas de monitoramento do PostgreSQL” com o HighLoad ++ Siberia e a página
Monitoramento no Wiki do PostgreSQL.
Quando planejamos tudo e "nos cobrimos" com o monitoramento, ainda podemos encontrar alguns problemas.
Dimensionamento
Normalmente, o desenvolvedor vê a linha do banco de dados na configuração. Ele não está particularmente interessado em como isso é organizado internamente - como o ponto de verificação, a replicação e o agendador funcionam. O desenvolvedor já tem algo a fazer - no todo, há muitas coisas interessantes que ele deseja experimentar.
"Dê-me o endereço da base, então eu mesmo." © desenvolvedor anônimo.
A ignorância do assunto leva a consequências bastante interessantes quando o desenvolvedor começa a escrever consultas que funcionam nesse banco de dados. Às vezes, fantasias ao escrever consultas oferecem efeitos impressionantes.
Existem dois tipos de transações.
As transações OLTP são rápidas, curtas e leves, que levam frações de um milissegundo. Eles se exercitam muito rapidamente, e existem muitos deles.
OLAP - consultas analíticas - lentas, longas, pesadas, leem grandes matrizes de tabelas e leem estatísticas.
Nos últimos 2
a 3 anos, a abreviatura
HTAP geralmente soa - Transação híbrida / processamento analítico ou processamento
transacional-analítico híbrido . Se você não tiver tempo para pensar sobre o dimensionamento e a diversidade de solicitações OLAP e OLTP, poderá dizer: "Temos o HTAP!" Mas a experiência e a dificuldade dos erros mostram que, afinal, diferentes tipos de solicitações devem viver separadamente uma da outra, porque solicitações OLAP longas bloqueiam solicitações OLTP leves.
Então chegamos à questão de como escalar o PostgreSQL para espalhar a carga, e todos ficaram satisfeitos.
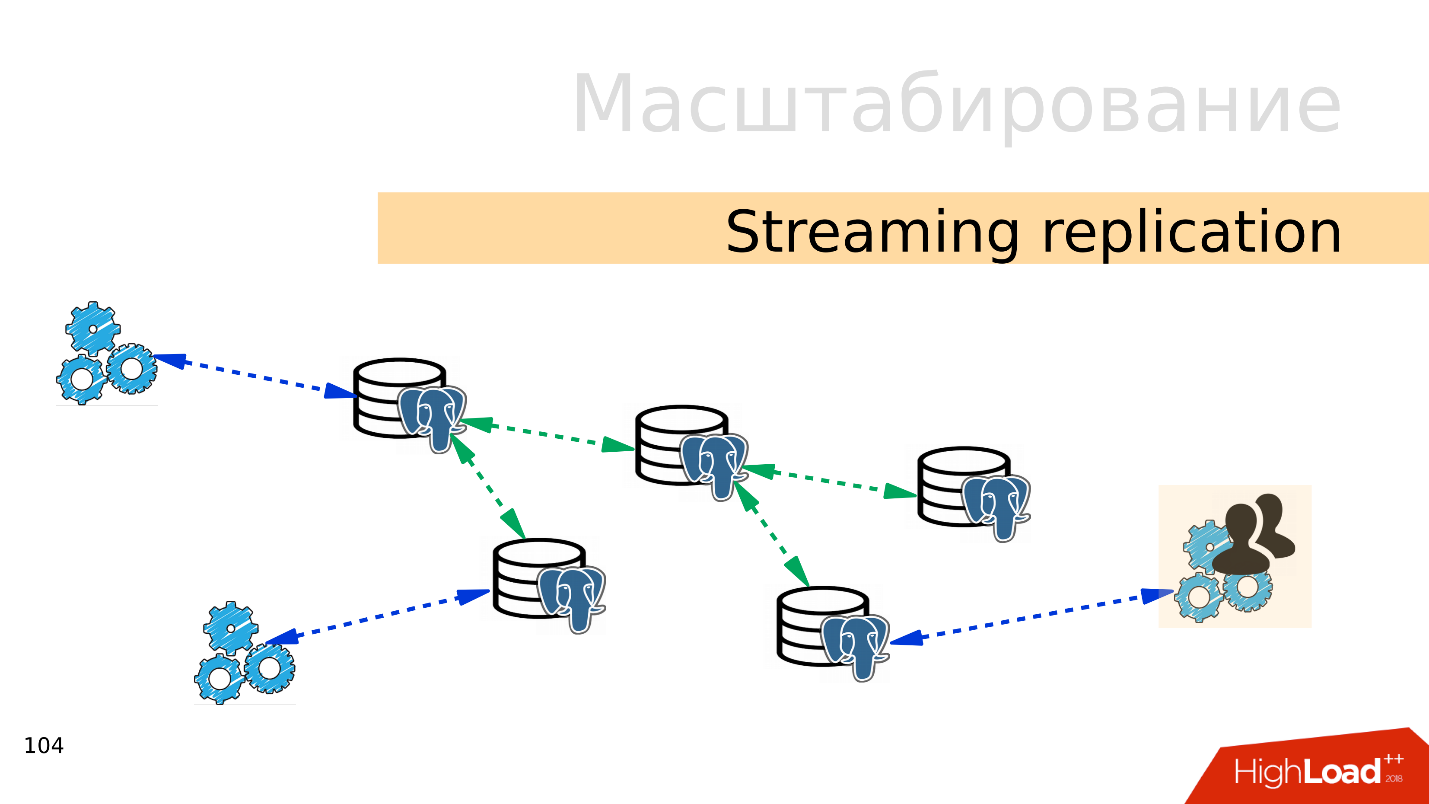
Replicação de streaming . A opção mais fácil é
a replicação de streaming . Quando o aplicativo trabalha com o banco de dados, conectamos várias réplicas a esse banco de dados e distribuímos a carga. A gravação ainda vai para a base principal e a leitura para réplicas. Este método permite que você dimensione muito amplamente.
Além disso, você pode conectar mais réplicas a réplicas individuais e obter
replicação em cascata . Grupos de usuários ou aplicativos separados que, por exemplo, leem análises, podem ser movidos para uma réplica separada.
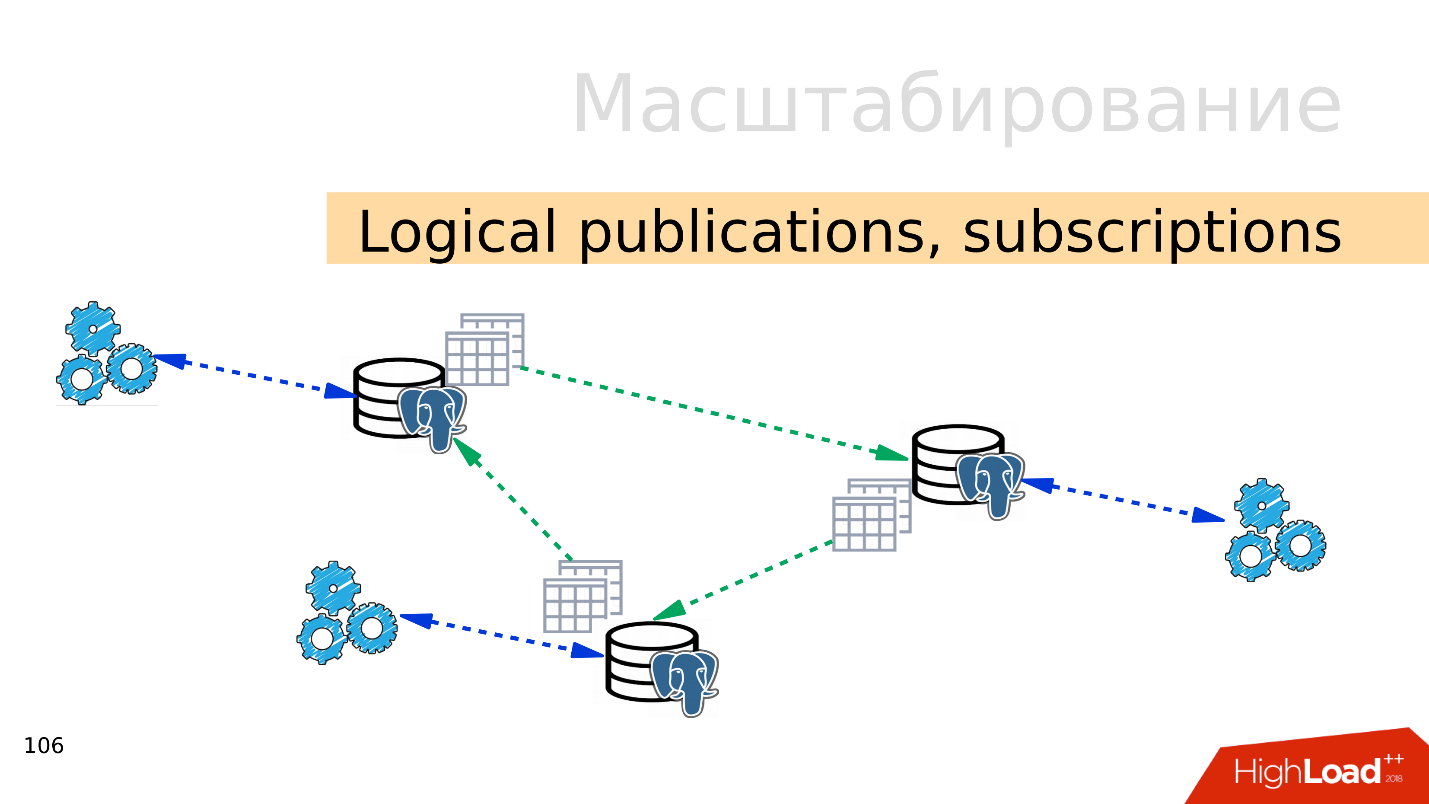
 Publicações lógicas, assinaturas
Publicações lógicas, assinaturas - o mecanismo de publicações e assinaturas lógicas implica a presença de vários servidores PostgreSQL independentes, com bancos de dados e conjuntos de tabelas separados. Esses conjuntos de tabelas podem ser conectados a bancos de dados vizinhos; eles estarão visíveis para aplicativos que podem usá-los normalmente. Ou seja, todas as alterações que ocorrem na origem são replicadas para a base de destino e são visíveis lá. Funciona muito bem com o PostgreSQL 10.
 Tabelas estrangeiras, particionamento declarativo - particionamento declarativo e tabelas externas
Tabelas estrangeiras, particionamento declarativo - particionamento declarativo e tabelas externas . Você pode pegar vários PostgreSQL e criar vários conjuntos de tabelas para armazenar os intervalos de dados desejados. Podem ser dados para um ano específico ou dados coletados em qualquer intervalo.
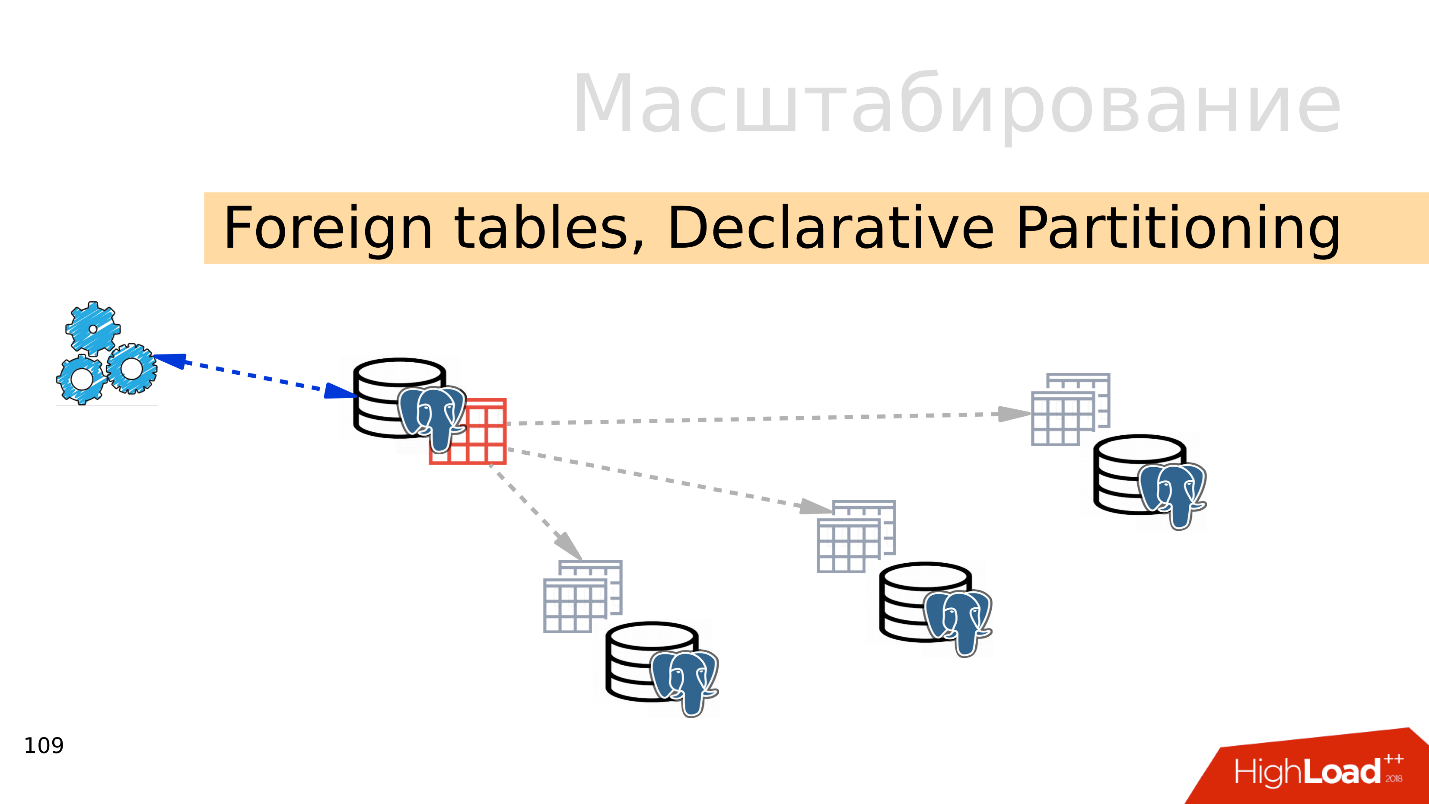
Usando o mecanismo de tabelas externas, você pode combinar todos esses bancos de dados na forma de uma tabela particionada em um PostgreSQL separado. Um aplicativo já pode funcionar com essa tabela particionada, mas na verdade ele lerá dados de partições remotas. Quando os volumes de dados são mais do que os recursos de um único servidor, isso é fragmentação.

Tudo isso pode ser combinado com configurações espalhadas, para criar diferentes topologias de replicação do PostgreSQL, mas como tudo funciona e como gerenciá-lo é o tópico de um relatório separado.
Por onde começar?
A opção mais fácil é
com replicação . O primeiro passo é espalhar a carga na leitura e na escrita. Ou seja, escreva para o mestre e leia as réplicas. Então, escalamos a carga e realizamos a leitura do assistente. Além disso, não se esqueça dos analistas. As consultas analíticas funcionam por um longo período de tempo, elas precisam de uma réplica separada com configurações separadas para que consultas analíticas longas não possam interferir no restante.
O próximo passo é
equilibrar . Ainda temos a mesma linha na configuração em que o desenvolvedor opera. Ele precisa de um lugar onde ele escreva e leia. Existem várias opções aqui.
O ideal é implementar o balanceamento
no nível do aplicativo , quando o próprio aplicativo souber de onde ler os dados e souber escolher uma réplica. Suponha que um saldo da conta seja sempre atualizado e precise ser lido pelo mestre, e a imagem ou informações sobre o produto possam ser lidas com algum atraso e feitas a partir de uma réplica.
- O DNS Round Robin , na minha opinião, não é uma implementação muito conveniente, porque às vezes funciona por um longo período de tempo e não fornece o tempo necessário ao alternar funções de assistente entre servidores em casos de failover.
- Uma opção mais interessante é usar o Keepalived e o HAProxy . Endereços virtuais para o mestre e o conjunto de réplicas são lançados entre servidores HAProxy, e o HAProxy já está equilibrando o tráfego.
- Patroni, DCS em conjunto com algo como ZooKeeper, etcd, Consul - a opção mais interessante, na minha opinião. Ou seja, a descoberta de serviço é responsável pelas informações sobre quem é o mestre agora e quem é a réplica. Patroni gerencia um cluster do PostgreSQL'ov, realiza a alternância - se a topologia mudou, essas informações aparecerão na descoberta de serviços e os aplicativos poderão descobrir rapidamente a topologia atual.
E há nuances na replicação, a mais comum delas é o
atraso na
replicação . Você pode fazer isso como o GitLab e, quando o atraso se acumular, basta soltar a base. Mas temos um monitoramento abrangente - analisamos e vemos transações longas.
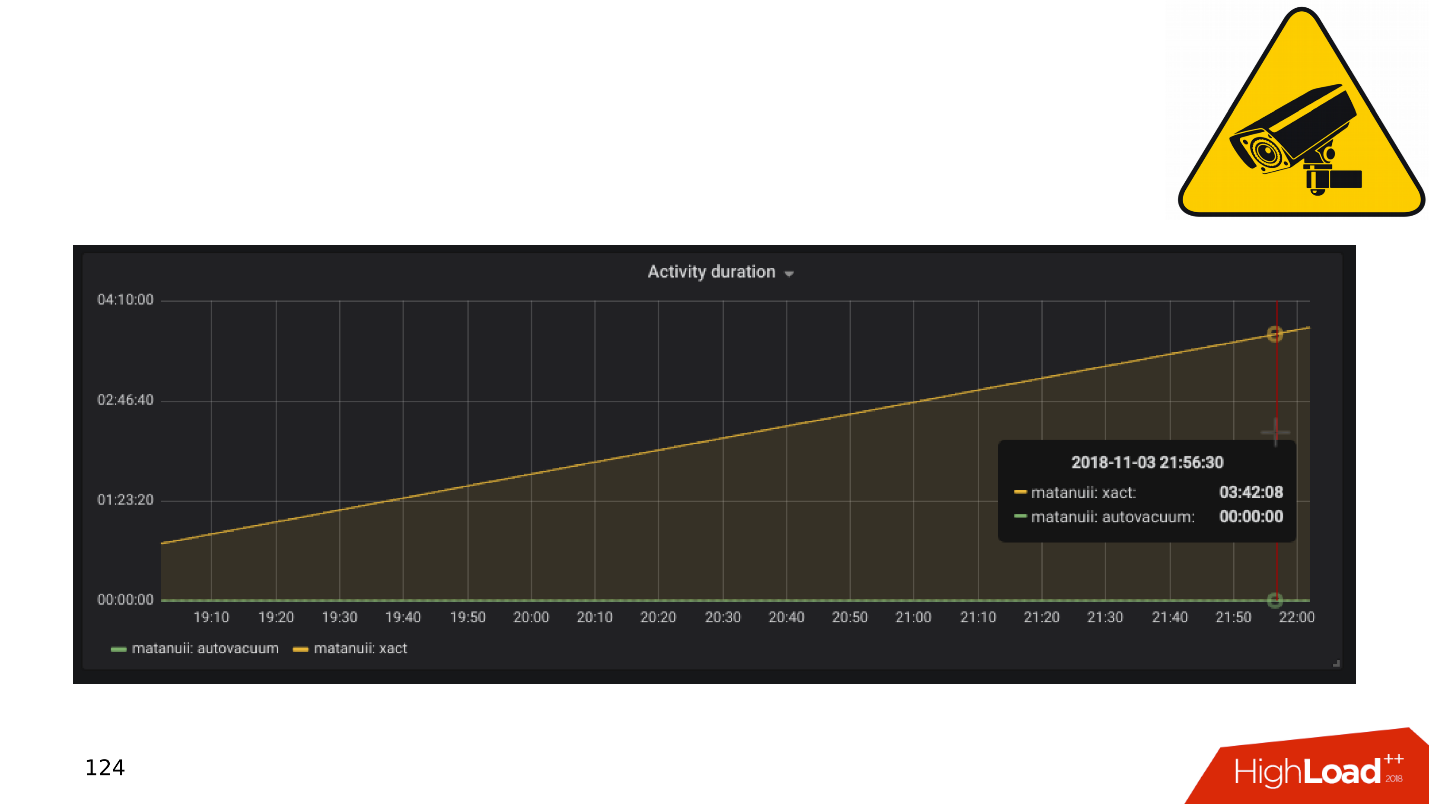
Aplicativos e transações de DBMS
Em geral, transações lentas e ociosas resultam em:
- diminuição da produtividade - não para um espasmódico acentuado, mas suave;
- bloqueios e deadlocks , porque transações longas mantêm bloqueios em linhas e impedem que outras transações funcionem;
- 50 * Erros de HTTP no back-end , erros de interface ou outro local.
Vamos examinar uma pequena teoria sobre como esses problemas surgem e por que o mecanismo de transações longas e ociosas é prejudicial.
O PostgreSQL possui MVCC - relativamente falando, um mecanismo de banco de dados. Ele permite que os clientes trabalhem competitivamente com os dados sem interferir entre si: os leitores não interferem nos leitores e os escritores não interferem nos escritores. Obviamente, existem algumas exceções, mas neste caso elas não são importantes.
Acontece que no banco de dados de uma linha pode haver várias versões para transações diferentes. Os clientes se conectam, o banco de dados fornece a eles instantâneos de dados e, dentro desses instantâneos, podem existir diferentes versões da mesma linha. Assim, no ciclo de vida do banco de dados, as transações são alteradas, substituem-se e as versões das linhas parecem desnecessárias.
Portanto, é
necessário um coletor de lixo - o aspirador automático . Existem transações longas e impedem que o vácuo automático limpe as versões de linhas desnecessárias. Esses dados indesejados começam a vagar da memória para o disco, do disco para a memória. Para armazenar esse lixo, os recursos da CPU e da memória são desperdiçados.
Quanto mais longa a transação, mais lixo e menor desempenho.
Do ponto de vista de "Quem é o culpado?", O aplicativo é o responsável pelo aparecimento de transações longas. Se o banco de dados existir por si só, transações longas e sem nada serão tomadas de qualquer lugar. Na prática, existem as seguintes opções para a aparência de transações inativas.
"Vamos para uma fonte externa .
" O aplicativo abre uma transação, faz algo no banco de dados e decide recorrer a uma fonte externa, por exemplo, Memcached ou Redis, na esperança de retornar ao banco de dados, continuar trabalhando e fechar a transação. Mas se ocorrer um erro na fonte externa, o aplicativo trava e a transação permanece fechada até que alguém perceba e o mate.
Sem manipulação de erros . Por outro lado, pode haver um problema ao lidar com erros. Quando, novamente, o aplicativo abriu uma transação, resolveu algum problema no banco de dados, retornou à execução do código, executou algumas funções e cálculos, a fim de continuar trabalhando na transação e fechá-la. Quando nesses cálculos a operação do aplicativo foi interrompida com um erro, o código retornou ao início do ciclo e a transação permaneceu novamente fechada.
O fator humano . Por exemplo, um administrador, desenvolvedor, analista, trabalha em algum pgAdmin ou no DBeaver - abriu uma transação, faz algo nela. Então a pessoa se distraiu, mudou para outra tarefa e depois para a terceira, esqueceu a transação, deixou para o fim de semana e a transação continua paralisada. O desempenho básico sofre.
Vamos ver o que fazer nesses casos.
- Temos monitoramento; portanto, precisamos de alertas no monitoramento . Qualquer transação que trava por mais de uma hora e não faz nada é uma ocasião para ver de onde veio e entender o que está errado.
- O próximo passo é filmar essas transações através da tarefa na coroa (pg_terminate_backend (pid)) ou configurar na configuração do PostgreSQL. São necessários limites de 10 a 30 minutos, após os quais as transações são concluídas automaticamente.
- Refatoração de aplicativo . Obviamente, você precisa descobrir de onde vêm as transações inativas, por que elas ocorrem e eliminar esses locais.
Evite transações longas a todo custo, pois elas afetam bastante o desempenho do banco de dados.
Tudo se torna ainda mais interessante quando tarefas pendentes aparecem, por exemplo, você precisa calcular cuidadosamente as unidades. E chegamos à questão da construção de bicicletas.
Construção de bicicletas
Tópico dolorido. Os negócios no lado do aplicativo precisam executar o processamento de eventos em segundo plano. Por exemplo, para calcular agregados: valor mínimo, máximo e médio, enviar notificações aos usuários, cobrar clientes, configurar a conta de um usuário após o registro ou o registro em serviços vizinhos - faça o processamento atrasado.
A essência dessas tarefas é a mesma - elas são adiadas para mais tarde. As tabelas aparecem no banco de dados que apenas executam as filas.

Aqui está o identificador da tarefa, o horário em que a tarefa foi criada, quando atualizada, o manipulador que a executou, o número de tentativas para concluir. Se você tiver uma tabela que se assemelhe remotamente a esta, terá
filas auto-escritas .
Tudo isso funciona bem até que transações longas apareçam. Depois disso, as
tabelas que funcionam com filas aumentam de tamanho . Novos trabalhos são adicionados o tempo todo, antigos são excluídos, atualizações acontecem - uma tabela com gravação intensiva é obtida. Ele deve ser limpo regularmente de versões desatualizadas de seqüências de caracteres para que o desempenho não sofra.
O tempo de processamento está aumentando - uma transação longa mantém um bloqueio em versões desatualizadas de linhas ou impede que o vácuo a limpe. Quando a tabela aumenta de tamanho, o tempo de processamento também aumenta, pois você precisa ler muitas páginas com lixo. O tempo aumenta e,
em algum momento , a
fila deixa de funcionar .
Abaixo está um exemplo da parte superior de um de nossos clientes que tinha uma fila. Todas as solicitações estão relacionadas apenas à fila.

Preste atenção no tempo de execução dessas solicitações - todas, exceto uma, funcionam por mais de vinte segundos.
Para resolver esses problemas, o
Skytools PgQ , um gerenciador de filas do PostgreSQL, foi inventado há muito tempo. Não reinvente sua bicicleta - pegue o PgQ, configure-o uma vez e esqueça as linhas.
É verdade que ele também tem recursos. O Skytools PgQ possui
pouca documentação . Depois de ler a página oficial, sente-se que ele não entendeu nada. O sentimento cresce quando você tenta fazer algo. Tudo funciona, mas
como funciona não está claro . Algum tipo de magia Jedi. Mas muita informação pode ser encontrada nas
listas de discussão . Este não é um formato muito conveniente, mas existem muitas coisas interessantes, e você terá que ler estas folhas.
Apesar dos contras, o Skytools PgQ trabalha com o princípio de "configurar e esquecer". , , , . PgQ , . PgQ , .
, - — , . .
PgQ. , PostgreSQL, , , PgQ . , .
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
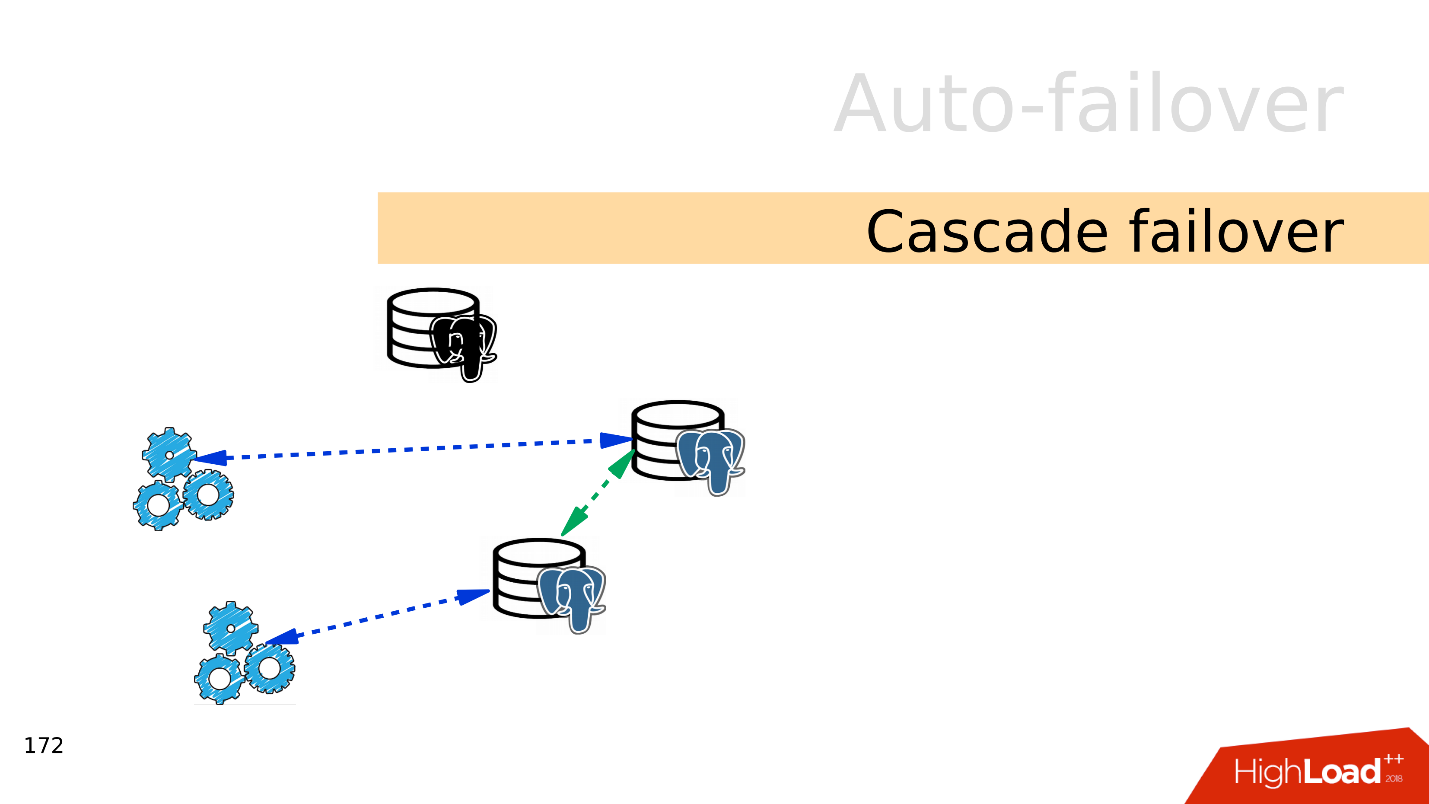
, . , .
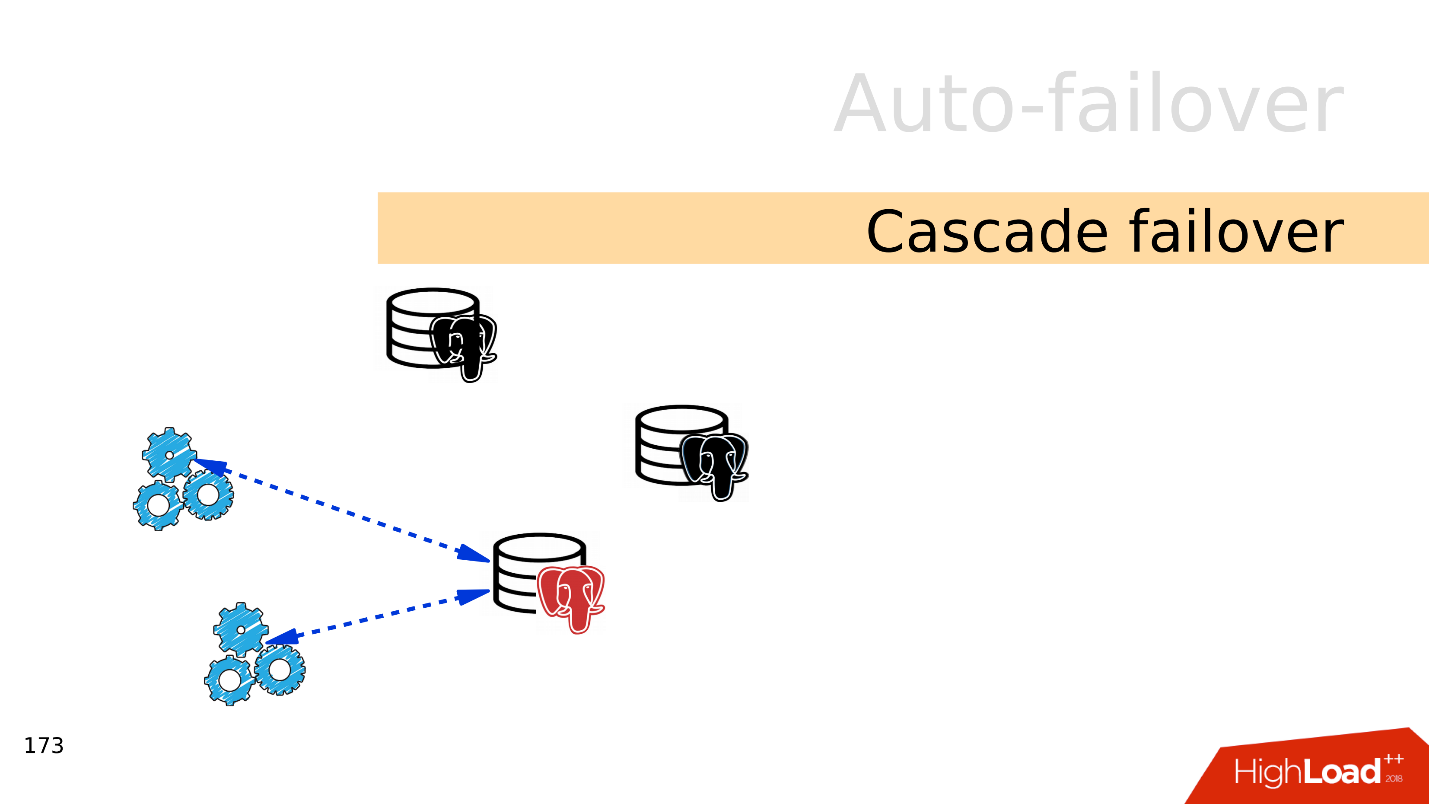
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
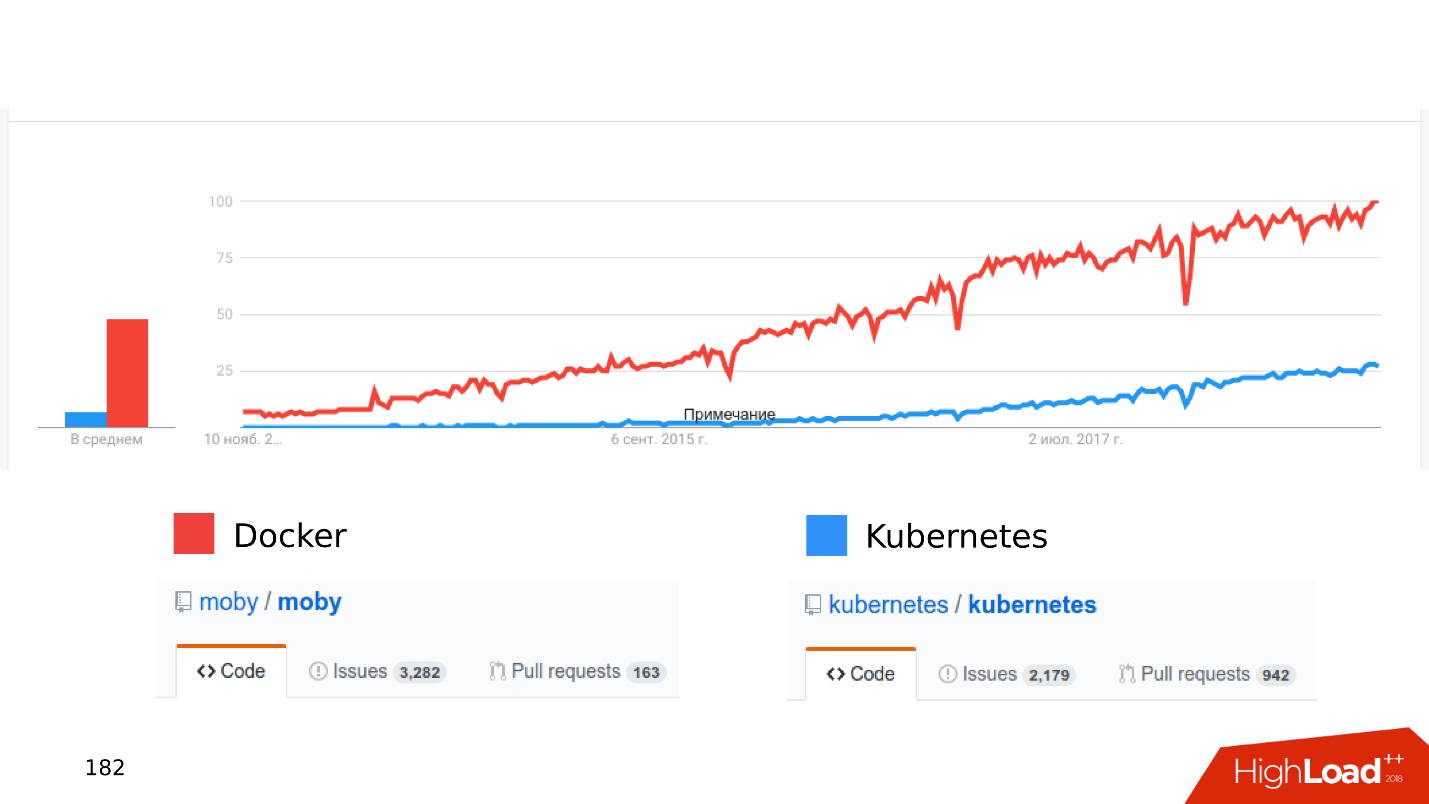
, .
« Kubernetes...» .
— stateful , - . Onde . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
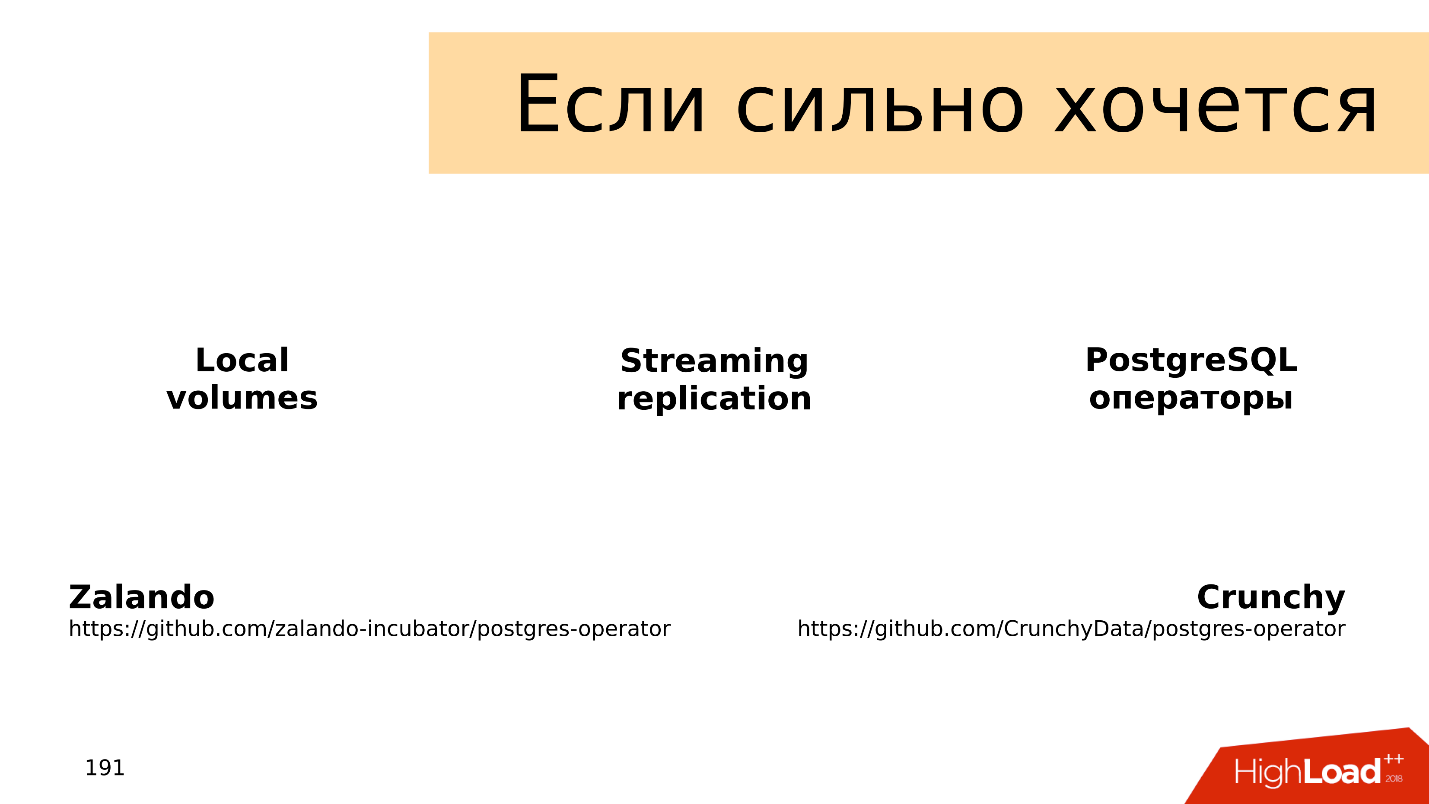
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
Sumário
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !