Olá pessoal! Descoberto recentemente a linguagem Rust. Ele compartilhou suas primeiras impressões em um artigo anterior . Agora eu decidi ir um pouco mais fundo, para isso você precisa de algo mais sério do que a lista. Minha escolha caiu na árvore Merkle. Neste artigo eu quero:
- falar sobre essa estrutura de dados
- veja o que Rust já tem
- ofereça sua implementação
- comparar desempenho
Árvore Merkle
Essa é uma estrutura de dados relativamente simples e já existe muita informação na Internet, mas acho que meu artigo ficará incompleto sem uma descrição da árvore.
Qual é o problema
A árvore Merkle foi inventada em 1979, mas ganhou popularidade graças ao blockchain. A cadeia de blocos na rede é muito grande (para bitcoin é mais do que 200 GB), e nem todos os nós podem usá-lo. Por exemplo, telefones ou caixas registradoras. No entanto, eles precisam saber sobre o fato de incluir essa ou aquela transação no bloco. Para isso, foi inventado o protocolo SPV - Verificação Simplificada de Pagamento .
Como uma árvore funciona
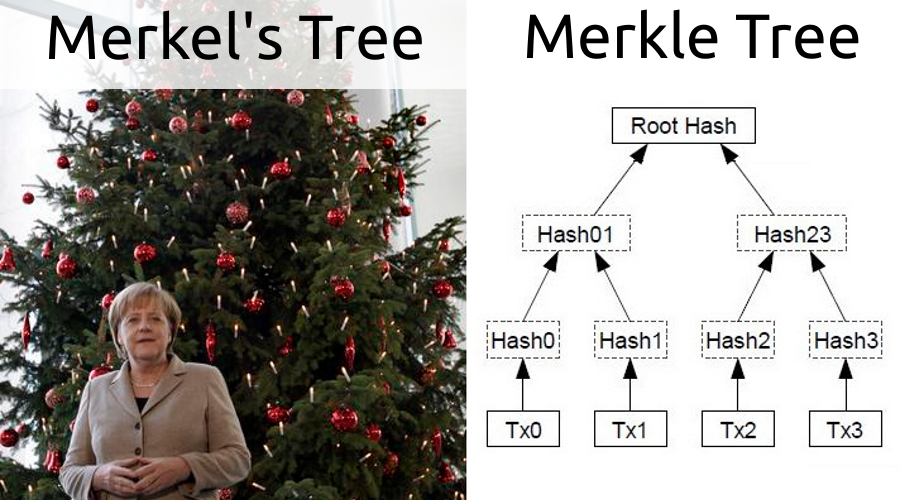
Esta é uma árvore binária cujas folhas são hashes de qualquer objeto. Para construir o próximo nível, os hashes das folhas vizinhas são coletados em pares, concatenados e o hash do resultado da concatenação é calculado, o que é ilustrado na figura no cabeçalho. Assim, a raiz da árvore é um hash de todas as folhas. Se você remover ou adicionar um elemento, a raiz mudará.
Como funciona uma árvore?
Tendo uma árvore Merkle, é possível construir evidências da inclusão de uma transação em um bloco como um caminho de um hash de transação para a raiz. Por exemplo, estamos interessados na transação Tx2, pois a prova será (Hash3, Hash01). Esse mecanismo também é usado no SPV. O cliente baixa apenas o cabeçalho do bloco com seu hash. Tendo uma transação de interesse, ele solicita prova de um nó que contém toda a cadeia. Então ele faz uma verificação, para Tx2 será:
hash(Hash01, hash(Hash2, Hash3)) = Root Hash
O resultado é comparado com a raiz do cabeçalho do bloco. Essa abordagem torna impossível falsificar evidências, pois nesse caso o resultado do teste não converge para o conteúdo do cabeçalho.
Quais implementações já existem
A ferrugem é uma linguagem jovem, mas muitas realizações da árvore Merkle já estão escritas nela. A julgar pelo Github, no momento 56, isso é mais do que em C e C ++ combinados. Embora o Go os faça stand-up com 80 implementações.
Para minha comparação, escolhi essa implementação pelo número de estrelas no repositório.
Essa árvore é construída da maneira mais óbvia, ou seja, é um gráfico de objetos. Como já observei, essa abordagem não é totalmente compatível com Rust. Por exemplo, não é possível fazer comunicação bidirecional dos filhos para os pais.
A construção da evidência ocorre através de uma pesquisa em profundidade. Se uma folha com o hash correto for encontrada, o caminho para ela será o resultado.
O que pode ser melhorado
Não foi interessante para mim fazer uma implementação simples (n + 1) -ésima, então pensei em otimização. O código para minha árvore de merkle de vetor está no Github .
Armazenamento de dados
A primeira coisa que vem à mente é mudar a árvore para uma matriz. Essa solução será muito melhor em termos de localidade dos dados: mais ocorrências de cache e melhor pré-carregamento. Andar por objetos espalhados da memória leva mais tempo. Um fato conveniente é que todos os hashes têm o mesmo comprimento, porque calculado por um algoritmo. A árvore Merkle na matriz ficará assim:

Prova
Ao inicializar a árvore, você pode criar um HashMap com todos os índices de folhas. Assim, quando não há folha, não é necessário contornar a árvore inteira e, se houver, você pode ir imediatamente para ela e subir à raiz, construindo uma prova. Na minha implementação, fiz o HashMap opcional.
Concatenação e hash
Parece que aqui pode ser melhorado? Afinal, tudo está claro - pegue dois hashes, cole-os e calcule um novo hash. Mas o fato é que essa função não é comutativa, ou seja, hash (H0, H1) ≠ hash (H1, H0). Por isso, ao construir a prova, é necessário lembrar de que lado o nó vizinho está. Isso dificulta a implementação do algoritmo e adiciona a necessidade de armazenar dados redundantes. Tudo é muito fácil de corrigir, basta classificar os dois nós antes do hash. Por exemplo, citei Tx2, levando em consideração a comutatividade, a verificação será assim:
hash(hash(Hash2, Hash3), Hash01) = Root Hash
Quando você não precisa se preocupar com o pedido, o algoritmo de verificação se parece com uma convolução simples de uma matriz:
pub fn validate(&self, proof: &Vec<&[u8]>) -> bool { proof[2..].iter() .fold( get_pair_hash(proof[0], proof[1], self.algo), |a, b| get_pair_hash(a.as_ref(), b, self.algo) ).as_ref() == self.get_root() }
O elemento zero é o hash do objeto desejado, o primeiro é seu vizinho.
Vamos lá!
A história ficaria incompleta sem uma comparação de desempenho, o que me levou várias vezes mais que a implementação da árvore em si. Para esses propósitos, usei a estrutura de critérios . As fontes dos próprios testes estão aqui . Todos os testes são realizados através da interface TreeWrapper , que foi implementada para os dois assuntos:
pub trait TreeWrapper<V> { fn create(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn find(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); fn validate(&self, c: &mut Criterion, counts: Vec<usize>, data: Vec<Vec<V>>, title: String); }
Ambas as árvores trabalham com a mesma criptografia em anel . Aqui não vou comparar bibliotecas diferentes. Eu peguei o mais comum.
Como objetos hash, seqüências geradas aleatoriamente são usadas. As árvores são comparadas em matrizes de vários comprimentos: (500, 1000, 1500, 2000, 2500 3000). 2500 - 3000 é o número aproximado de transações no bloco de bitcoin no momento.
Em todos os gráficos, o eixo X indica o número de elementos da matriz (ou o número de transações no bloco) e o eixo Y representa o tempo médio para concluir a operação em microssegundos. Ou seja, quanto mais, pior.
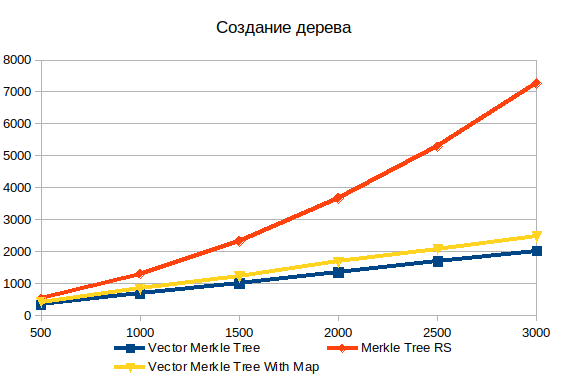
Fabricação de árvores
O armazenamento de todos os dados da árvore em uma matriz excede muito o gráfico de desempenho dos objetos. Para uma matriz com 500 elementos, 1,5 vezes, e para 3000 elementos já 3,6 vezes. A natureza não linear da dependência da complexidade do volume de dados de entrada na implementação padrão é claramente visível.
Além disso, em comparação, adicionei duas variantes da árvore de vetores: com e sem HashMap . O preenchimento de uma estrutura de dados adicional adiciona cerca de 20%, mas permite pesquisar objetos muito mais rapidamente ao criar evidências.
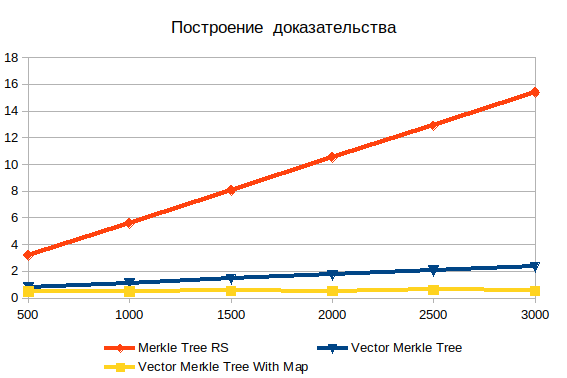
Construindo evidências
Aqui você pode ver a óbvia ineficiência da pesquisa em profundidade. Com um aumento na entrada, isso só piora. É importante entender que os objetos que você está procurando são folhas, para que não haja complexidade de log (n) . Se os dados forem pré-hash, o tempo de operação é praticamente independente do número de elementos. Sem hash, a complexidade cresce linearmente e consiste em busca de força bruta.
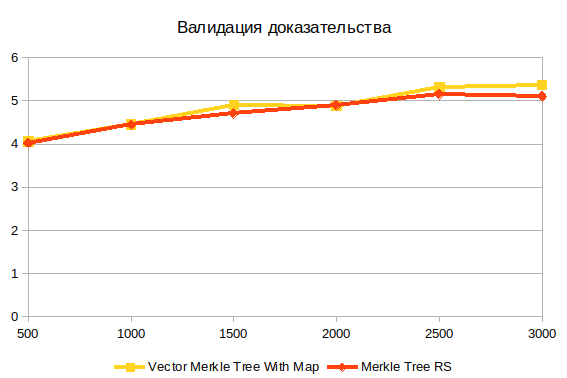
Validação de evidência
Esta é a última operação. Não depende da estrutura da árvore, porque trabalha com o resultado da construção de evidências. Acredito que a principal dificuldade aqui é o cálculo de hash.
Sumário
- A maneira como os dados são armazenados afeta muito o desempenho. Quando tudo em uma matriz é muito mais rápido. E serializar essa estrutura será muito simples. A quantidade total de código também é reduzida.
- Concatenar nós com a classificação simplifica bastante o código, mas não o torna mais rápido.
Um pouco sobre Rust
- Gostei da estrutura de critérios . Dá resultados claros com valores médios e desvios equipados com gráficos. Capaz de comparar diferentes implementações do mesmo código.
- A falta de herança não interfere muito na vida.
- Macros são um mecanismo poderoso. Eu os usei em meus testes em árvore para parametrização. Eu acho que se eles forem mal utilizados, você poderá fazer algo que não será feliz mais tarde.
- Em alguns lugares, o compilador se entedia com suas verificações de memória. Minha suposição inicial de que começar a escrever em Rust simplesmente não funcionava estava correta.
Referências