Sentimento de morte, solidão, ao mesmo tempo, uma sede louca de vida ... Você pode pensar que decidimos dar uma palestra sobre expressionismo e mergulhá-lo no trabalho de Munch. Mas não. Você passa por todas essas etapas no momento em que vê que sua dívida técnica em breve empurrará sua empresa para o abismo da crise.

Por 8 anos, a equipe de TI da Dodo Pizza cresceu de 2 desenvolvedores que atendem a um país para 80 pessoas atendendo a 12 países. Três anos atrás, ingressei na Dodo Pizza como Chief Agile Officer e comecei a ajudar as equipes a criar processos e implementar práticas de engenharia. Muitas vezes, essas implementações eram muito lentas. Além disso, verificou-se que, quando várias equipes trabalham no mesmo produto, é difícil conseguir que elas mantenham um código de alta qualidade.
Buscamos o desenvolvimento de funções de negócios, adiando a perfeição técnica do código para mais tarde. Então, ficamos presos. Uma enorme dívida técnica nos atingiu, mas não a esmagou, mas apenas com um estalar de dedos lançou nossa empresa no abismo da crise. Em 2018, a equipe de marketing lançou uma campanha publicitária massiva, não conseguimos suportar a carga e caímos. Vergonha, vergonha e vergonha. Mas durante a crise, percebemos que podemos trabalhar muitas vezes com mais eficiência. A crise nos forçou a implementar rapidamente as práticas de engenharia mais famosas e a revolucionar processos.
Antecedentes
Dodo Pizza é uma empresa de cyborg que vende pizza . Nosso negócio é baseado na plataforma Dodo IS, que gerencia todos os processos de negócios: recebimento de pedidos, fabricação de pizza, gerenciamento de estoque, gerenciamento de pessoas (gerenciamento) e muito, muito mais. Em apenas 8 anos, passamos de 2 desenvolvedores que servem uma pizzaria para mais de 80 desenvolvedores que servem 498 pizzarias em 12 países.
Três anos atrás, o Dodo IS era um monólito contendo 1 milhão de linhas de código. Houve pouca cobertura com testes de unidade, não houve testes de API / UI. A qualidade do código em si foi decepcionante. Todo mundo sabia disso, ou pelo menos adivinhou. Em sonhos de um futuro melhor, dividimos o monólito em uma dúzia de serviços e reescrevemos as partes mais repugnantes do sistema. Até fizemos um diagrama da arquitetura "futura", mas, francamente, não fizemos nada para nos aproximar dela.
Quanto mais a equipe crescia, mais sofríamos com a falta de um processo claro e de práticas de engenharia. Os lançamentos se tornaram cada vez mais, porque todas as seis equipes de desenvolvimento fizeram alterações simultaneamente em diferentes ramos. Quando as equipes mesclavam suas alterações em uma ramificação, às vezes perdíamos até 4 horas tentando resolver conflitos de mesclagem. Não houve testes de regressão automática e, a cada versão, passávamos cada vez mais tempo na regressão manual.
Merda acontece
Em 2018, a equipe de marketing lançou nossa primeira campanha publicitária de TV federal com um orçamento de 100 milhões de rublos. Foi um grande evento para Dodo Pizza. A equipe de TI também estava bem preparada para a campanha. Automatizamos e simplificamos nossa implantação - agora, com um único botão no TeamCity, podemos implantar um monólito em 12 países. Usando testes de desempenho, realizamos uma análise de vulnerabilidade. Nós fizemos o nosso melhor, mas estragamos tudo de qualquer maneira.
A campanha publicitária foi incrível. Recebemos de 100 a 300 pedidos por minuto. Essa foi uma boa notícia. A má notícia: o Dodo IS não suportou tal carga e morreu. Atingimos o limite de escala vertical e não conseguimos mais processar pedidos. O sistema é reiniciado a cada 3 horas. Cada minuto de inatividade nos custa dezenas de milhares de rublos, sem contar a perda de respeito de clientes irritados.
Quando cheguei à Dodo Pizza há três anos, comecei imediatamente a implementar práticas de engenharia. A maioria das equipes adotou a programação em pares, testes de unidade e DDD rapidamente. Mas nem tudo era tão simples. Eu tive que superar a resistência dos desenvolvedores, produtos e equipe de suporte.
Ao contrário das idéias das práticas de engenharia, a princípio, nem todos apoiaram a ideia das equipes de recursos. Os desenvolvedores estão acostumados a pensar que uma equipe focada em um componente escreve o melhor código. Não ficou claro como combinar o rápido desenvolvimento de funções de negócios com a refatoração maciça há muito esperada de um sistema complexo. Além disso, esse fluxo interminável de bugs exigia atenção constantemente ... Lançamos o produto não mais de uma vez por semana, e cada lançamento demorava muito tempo, exigia uma enorme quantidade de regressão manual e suporte para testes de interface do usuário. Tentei consertá-lo, mas a alteração do processo foi muito lenta e fragmentada.
A história do outono e ascensão
Estado inicial: arquitetura monolítica
Na busca pela velocidade do desenvolvimento das funções de negócios, nem sempre pensamos bem em soluções técnicas. Afetado por uma falta de experiência. Tínhamos um aplicativo monolítico com um único banco de dados contendo todos os dados de todos os componentes em um único local. Rastreador, contabilidade, site, API para páginas de destino - todos os componentes do sistema funcionavam com um banco de dados, o que era um gargalo.
História verdadeira
A arquitetura monolítica é boa para começar, porque é simples. Mas não suporta uma carga alta, sendo o único ponto de falha. Uma vez que todos os nossos restaurantes na Rússia pararam de aceitar pedidos devido a uma postagem no blog. Como isso pôde acontecer?
Nosso CEO, Fedor, postou uma postagem em seu blog. Este post rapidamente ganhou popularidade. O blog do Fedor possui um contador que mostra o número de pizzarias em nossa rede e a receita total de todas as pizzarias. Sempre que alguém lê o blog de Fedor, o servidor da Web envia uma solicitação ao banco de dados mestre para calcular a receita. Esses pedidos sobrecarregaram tanto o banco de dados que pararam de atender aos pedidos do caixa do restaurante. Corrigimos rapidamente o problema, mas esse era um dos muitos sinais de que nossa arquitetura não era capaz de atender às necessidades dos negócios e deveria ser redesenhada. No entanto, continuamos a ignorar esses sinais.
Falha no início de 2017
14 de fevereiro. Para os amantes de parabéns, em 14 de fevereiro, fazemos uma pizza especial - Pepperoni em forma de coração. Sempre me lembrarei de 14 de fevereiro de 2017, porque neste dia, quando todas as pizzarias estavam trabalhando a plena carga, o Dodo IS começou a cair. Cada pizzaria possui de 4 a 5 comprimidos para o gerenciamento da produção: por que ordem o pizzaiolo rola a massa, coloca os ingredientes, assa ou envia para entrega. Naquele momento, o número de pizzarias atingiu mais de 150, cada comprimido foi atualizado várias vezes por minuto. Todas essas consultas criaram uma carga tão grande no banco de dados que ele parou de suportar e começou a falhar. Dodo IS morreu durante o pico de vendas. Mas havia uma temporada de férias movimentada pela frente: 23 de fevereiro, 8 de março, 1 e 9 de maio. Durante esses feriados, esperávamos um crescimento ainda maior de pedidos.
O dia em que você morre . Conhecendo nossos planos de crescimento e o limite de carga que podemos suportar, descobrimos quanto tempo podemos permanecer vivos. A data estimada do Armagedom era esperada em cerca de seis meses: de agosto a setembro de 2017. Como é viver, sabendo a data da sua morte?
Pare o desenvolvimento de funções por um ano. Juntamente com o CEO Fedor, tivemos que tomar uma decisão difícil. Talvez uma das decisões mais difíceis da história da empresa. No próximo ano, fizemos apenas um recurso de negócios. O resto do tempo as equipes pagaram dívidas técnicas. Essa dívida nos custou caro - mais de 100 milhões de rublos apenas para os salários dos desenvolvedores.
Algumas melhorias após um ano
Ao longo do ano, crescemos acentuadamente:
- Automatizamos e aceleramos o processo de implantação para 4-5 horas
- Finalmente, começamos a ver o monólito: as placas do rastreador e da TV foram movidas para um serviço separado com seu próprio banco de dados
- Começamos a separar o caixa de entrega - o segundo componente que criou uma carga alta
- Reescrever o sistema de autenticação de usuário e dispositivo
Parece que poderíamos ter orgulho de nós mesmos. Mas à nossa frente havia uma enorme decepção.
Falha durante a campanha publicitária federal. Segunda crise de confiança
A dívida técnica é fácil de acumular, mas muito difícil de pagar. É improvável que você seja capaz de entender com antecedência quanto isso lhe custará.
Apesar de termos lutado com um backlog técnico por um ano inteiro, não estávamos prontos para uma campanha de marketing em massa e estragamos tudo diante dos nossos negócios. A confiança que conquistamos gota a gota desapareceu.
Sob o peso da Campanha Federal de Marketing, nos deitamos novamente. O sistema travou novamente e reiniciou a cada 3 horas. Nosso negócio estava perdendo dezenas de milhões de rublos.

Graças à crise, aprendemos que em condições extremas podemos trabalhar muitas vezes com mais eficiência. Somos liberados 20 vezes por dia. Todos trabalharam como uma equipe, concentrando-se em um objetivo. Durante as duas semanas de crise, fizemos o que tínhamos medo de começar a fazer mais cedo, acreditando que levaria meses de trabalho. Recepção assíncrona de pedidos, pedidos desativados, testes de estresse, logs limpos - isso é apenas uma pequena parte do que fizemos. Queríamos continuar a trabalhar com a mesma eficiência, mas sem horas extras e estresse.
Lições aprendidas
Após a retrospectiva, reorganizamos completamente nossos processos. Tomamos o LeSS como base e o complementamos com práticas de engenharia. Nos meses seguintes, fizemos um avanço na introdução de práticas de engenharia. Com base no LeSS, implementamos e continuamos a usar:
- Backlog de produto único
- Comandos totalmente funcionais e de componentes cruzados
- Programação em pares e mob
- True Continuous Integration (CI) - Integração de código com 12 equipes em uma filial
- Trabalho simplificado com ramificações (desenvolvimento baseado em tronco)
- Versões frequentes: implantação contínua para microsserviços, liberação diária para monólito
- Recusa de uma equipe de controle de qualidade separada, especialistas em controle de qualidade fazem parte da equipe de desenvolvimento
6 práticas que escolhemos após a crise:
1. O poder do foco. Antes da crise, cada equipe trabalhava com sua própria dívida e se especializou em seu campo. Durante a crise, as equipes não tiveram tarefas específicas, pois tinham um grande objetivo difícil. Por exemplo, um aplicativo móvel e uma API devem processar 300 pedidos por minuto, não importa o quê. A equipe aceita o objetivo e pensa de maneira independente como alcançá-lo. A própria equipe formula as hipóteses e as testa rapidamente no prod. As equipes não querem ser simples codificadores, querem resolver problemas.
O poder do foco se manifesta em tarefas complexas. Por exemplo, durante a crise, criamos testes de estresse, apesar de não termos experiência. Também criamos a lógica para receber o pedido de forma assíncrona. Nós pensamos sobre isso por um longo tempo e conversamos, e parecia-nos que essa é uma tarefa muito difícil, que pode levar muito tempo. Mas a equipe é capaz de fazer isso em duas semanas, se não estiver distraída e se concentrar totalmente no problema.
2. Hackathons internos. Realizamos o Hackathon dos 500 erros. Todas as equipes juntas limparam os logs e removeram as causas de 500 erros no site e na API. O objetivo era manter os logs limpos. Quando os logs estão limpos, novos erros são claramente visíveis, você pode definir facilmente limites para alertas.
Outro exemplo de hackathon são os bugs. Anteriormente, tínhamos uma lista completa de bugs, alguns deles por muitos anos. Eles nunca pareciam terminar. E todos os dias novos apareciam. Combinamos o trabalho em bugs e os elementos habituais da lista de pendências.
#Zerobugspolicy policy.- Se o bug estiver no backlog há mais de 3 meses, exclua-o. Ele ficou ali por muito tempo e ninguém morreu.
- Avalie a dor que os erros restantes causam aos clientes. Deixe apenas os bugs que dificultam a vida de um grande grupo de usuários.
- Organize um hackathon interno para erros. Fizemos isso em alguns sprints. Cada sprint, cada equipe, cometeu vários erros e os corrigiu. Após 2-3 sprints, tivemos uma lista de pendências limpa. Agora você pode inserir #zerobugspolicy.
- #zerobugspolicy. Se o bug entrar no backlog, ele será definitivamente corrigido. Qualquer bug no backlog tem uma prioridade mais alta do que qualquer outro elemento do backlog. Mas, para entrar no backlog, o bug deve ser sério. Ou causa danos irreparáveis ou afeta um grande número de usuários.
3. Das equipes de projeto a uma equipe estável. Havia uma história engraçada com as equipes de projeto. Durante a crise, formamos equipes especializadas de pessoas mais qualificadas para a tarefa. Após o término da crise, as equipes decidiram continuar essa prática. Apesar de não gostar dessa idéia, tentamos. Em apenas 2 semanas (uma corrida), na próxima retrospectiva, as equipes abandonaram essa prática (essa decisão me deixou feliz). Se uma equipe não possui algumas habilidades, elas podem aprender gradualmente. Mas espírito de equipe, suporte e assistência mútua levam muito tempo para serem concluídos, leva meses. As equipes de projeto de curto prazo estão constantemente no estágio de formação e assalto. Você pode tolerar isso por várias semanas, mas não poderá trabalhar dessa maneira o tempo todo.
4. Sem regressão manual. Estabelecemos uma meta para nos livrar das regressões manuais. Levamos 1,5 anos para alcançá-lo. Mas ter um objetivo ambicioso a longo prazo faz você pensar nas etapas que levam ao objetivo.
Fizemos isso em 3 etapas.- Automação de caminho crítico.
Em junho de 2017, formamos uma equipe de controle de qualidade. A tarefa da equipe era automatizar a regressão da funcionalidade mais crítica do Dodo IS - receber e produzir pedidos. Nos seis meses seguintes, uma nova equipe de controle de qualidade para quatro pessoas cobriu todas as funcionalidades críticas do sistema com testes automáticos. Os desenvolvedores da equipe de recursos ajudaram ativamente a equipe de controle de qualidade. Juntos, criamos uma linguagem de domínio bonita e compreensível (DSL), que foi entendida até pelos clientes. Paralelamente aos testes de ponta a ponta, os desenvolvedores ponderaram o código com testes de unidade. Alguns novos componentes foram redesenhados usando TDD. Depois disso, dissolvemos a equipe de controle de qualidade. Ex-membros da equipe de controle de qualidade se uniram às equipes que trabalham em recursos de negócios para transferir a experiência de desenvolvimento e suporte de autoteste para as equipes. - Modo de sombra.
Em autotestes, durante 5 lançamentos, fizemos regressão manual no modo de sombra. As equipes confiaram apenas no teste automático, mas quando a equipe decidiu que estava pronta para o lançamento, lançamos uma regressão manual para verificar se nossos autotestes haviam perdido algum erro. Nós rastreamos quantos erros foram detectados manualmente e não detectados pelos testes automáticos. Após 5 lançamentos, analisamos os dados e decidimos confiar em nossos testes automáticos. Nenhum erro grave foi perdido. - Recusa de regressão manual.
Quando tivemos testes suficientes para começar a confiar neles, abandonamos completamente os testes manuais. Quanto mais testes escrevemos, mais confiamos neles. Mas isso aconteceu apenas 1,5 anos depois que começamos a automatizar os testes de regressão.
5. Os testes de estresse fazem parte da regressão. Durante a crise, escrevemos testes de estresse. Esta foi uma experiência completamente nova para nós. No entanto, em apenas duas semanas, conseguimos criar algo usando as ferramentas do Visual Studio. Nós os usamos, inclusive para gerar carga artificial no servidor, a fim de encontrar limites de desempenho. Por exemplo, se a carga orgânica no produto for 100 pedidos / min, adicionamos outros 50 pedidos / min usando nossos testes para verificar se o sistema é capaz de lidar com o aumento da carga.
No ano seguinte, reescrevemos os testes de estresse com uma equipe experiente do PerformanceLab. Hoje, esses testes são executados semanalmente e fornecem feedback rápido para as equipes de desenvolvimento.
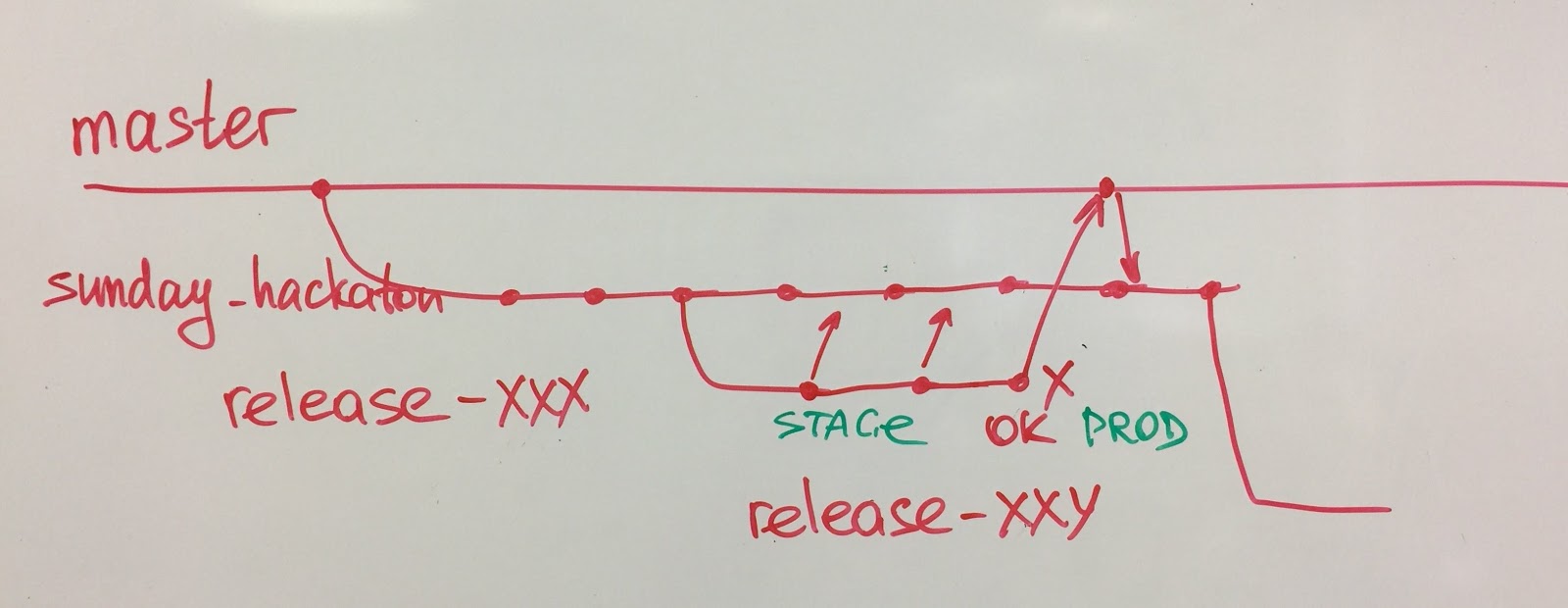 6. Práticas de engenharia.
6. Práticas de engenharia. Todas as nossas equipes usam programação em pares. Considero a programação em pares uma das práticas mais simples, porém mais poderosas. Se você não sabe com qual prática de engenharia começar, recomendo a programação em pares.
Resultados
O principal resultado para nós foi um abalo. Nós acordamos e começamos a atuar. A crise nos ajudou a ver nosso potencial máximo. Vimos que podemos trabalhar muitas vezes com mais eficiência e rapidez para atingir nossos objetivos. Mas, para isso, é necessário mudar a maneira usual de trabalhar. Não temos mais medo de experiências ousadas.
Como resultado dessas experiências ao longo do ano passado, melhoramos significativamente a qualidade e a estabilidade do Dodo IS. Se durante as férias de primavera de 2018 nossas pizzarias não funcionarem por causa do Dodo IS, então em 2019, com um aumento de 300 para 498 pizzarias, o Dodo IS funcionará perfeitamente. Sobrevivemos com calma ao pico de vendas no ano novo, durante a Segunda campanha de marketing e férias de primavera.
Pela primeira vez em muito tempo, estamos confiantes na qualidade do sistema e podemos dar ao luxo de dormir profundamente à noite. Este é o resultado do uso contínuo de métodos de engenharia e o foco na excelência técnica.
Resultados de Negócios
As práticas de engenharia não são necessárias por si próprias, se não beneficiam seus negócios. Como resultado do foco na excelência técnica, melhoramos a qualidade do código e desenvolvemos funções de negócios com velocidade previsível. Os lançamentos se tornaram um evento comum para nós.
Resultados para Equipes
Hoje usamos uma ampla gama de métodos de engenharia:
- Comandos totalmente funcionais e de componentes cruzados
- Programação Pair / Mob
- Integração Contínua - integração contínua de 12 comandos em uma ramificação
- Especialista no assunto em equipe
- Não há equipe de controle de qualidade separada, especialistas em controle de qualidade fazem parte das equipes de desenvolvimento
- Substituindo a regressão manual por autotestes
- Política sem bugs (#Zerobugspolicy)
- Interrompa a linha como um driver para acelerar a implantação
O que aprendemos
Eu gostaria que a crise não acontecesse. Como desenvolvedor, me senti pessoalmente responsável por acumular muita dívida técnica e por não poder prever as conseqüências.
- As práticas de engenharia protegem os negócios da crise
- Não acumule dívidas técnicas. Pode ficar tarde demais e custar muito
- As mudanças evolutivas demoram várias vezes mais que as revolucionárias
- Uma crise nem sempre é uma coisa ruim. Use crise para revolucionar processos
- No entanto, é necessário um treinamento evolutivo prolongado.
- Não aplique cegamente todos os métodos que você gosta. Alguns métodos estão esperando nos bastidores e, quando ele chegar, as equipes os usarão sem resistência. Aguarde o momento certo
- Com o tempo, as próprias equipes começam a tomar decisões importantes e implementá-las. Dê a eles um ambiente propício para tentar, deixe que falhem e aprenda com os erros
A dívida técnica nos levou a uma crise terrível. Estou muito feliz que nossa equipe tenha encontrado forças para usar esse impasse como ponto de crescimento. Em nossa própria pele, percebemos que o tempo de crise pode e deve ser usado para grandes mudanças organizacionais e de processo. Portanto, nunca desista, porque mesmo nas situações mais difíceis há espaço para um feito.
Agradecimentos
Gostaria de agradecer a todas as pessoas que me ajudaram na minha jornada da crise à transformação do LeSS. Eu constantemente sinto seu apoio.Muito obrigado ao nosso CEO Fedor Ovchinnikov por sua confiança. Você é um verdadeiro líder em uma empresa com uma cultura verdadeira e flexível.Muito obrigado a Dmitry Pavlov, nosso Product Owner, meu velho amigo e co-treinador.Obrigado a Alexander Andronov e Andrey Morevsky pelo apoio.Muito obrigado a Dasha Bayanova, nosso primeiro mestre em Scrum em tempo integral, que sempre me ajuda e me apoia com toda a nossa iniciativa. É difícil superestimar sua ajuda.Um agradecimento especial a Joanna Rothman, que me ajudou a escrever este relatório em qualquer condição: de férias, me recuperando de uma doença. Joanna, foi um prazer trabalhar com você. Seus conselhos, atenção aos detalhes e trabalho duro me ajudaram bastante.