
Os engenheiros do DevOps e do SRE provavelmente já ouviram falar de Prometheus mais de uma vez.
O Prometheus foi criado no SoundCloud em 2012 e desde então se tornou o padrão para sistemas de monitoramento . Possui código-fonte completamente aberto, fornece dezenas de diferentes exportadores com os quais você pode configurar o monitoramento de toda a infraestrutura em minutos .
O Prometheus tem um valor óbvio e já está sendo usado por inovadores da indústria como DigitalOcean ou Docker como parte de um sistema completo de monitoramento.
O que é Prometeu?
Por que é necessário?
Como é diferente de outros sistemas?
Se você não sabe nada sobre o Prometheus ou deseja entendê-lo melhor, seu ecossistema e todas as interações, este artigo é apenas para você .
Dividimos este guia em 3 partes, como fizemos com o InfluxDB .
- Primeiro, vem uma visão completa do Prometheus , seu ecossistema e os principais aspectos da tecnologia em ritmo acelerado.
- Em seguida, são fornecidas explicações sobre os termos técnicos do Prometheus . Se você não sabe o que são métricas, rótulos, instâncias ou exportadores, aqui está você.
- Por fim, descrevemos vários cenários do mundo real para o uso do Prometheus . Aqui você será inspirado por exemplos de empresas de sucesso.
Parte I. O que é Prometeu?
Prometheus é um banco de dados de séries temporais. Se você não souber o que é um banco de dados de séries temporais, leia a primeira parte do manual do InfluxDB .
Mas Prometheus não é apenas um banco de dados de séries temporais.
Você pode anexar um ecossistema inteiro de ferramentas para expandir a funcionalidade.
O Prometheus monitora uma ampla variedade de sistemas : servidores, bancos de dados, máquinas virtuais individuais e quase tudo.
Para fazer isso, Prometheus periodicamente raspa seus alvos .
O que é raspagem?
O Prometheus recupera métricas por meio de chamadas HTTP para pontos de extremidade específicos especificados na configuração do Prometheus.
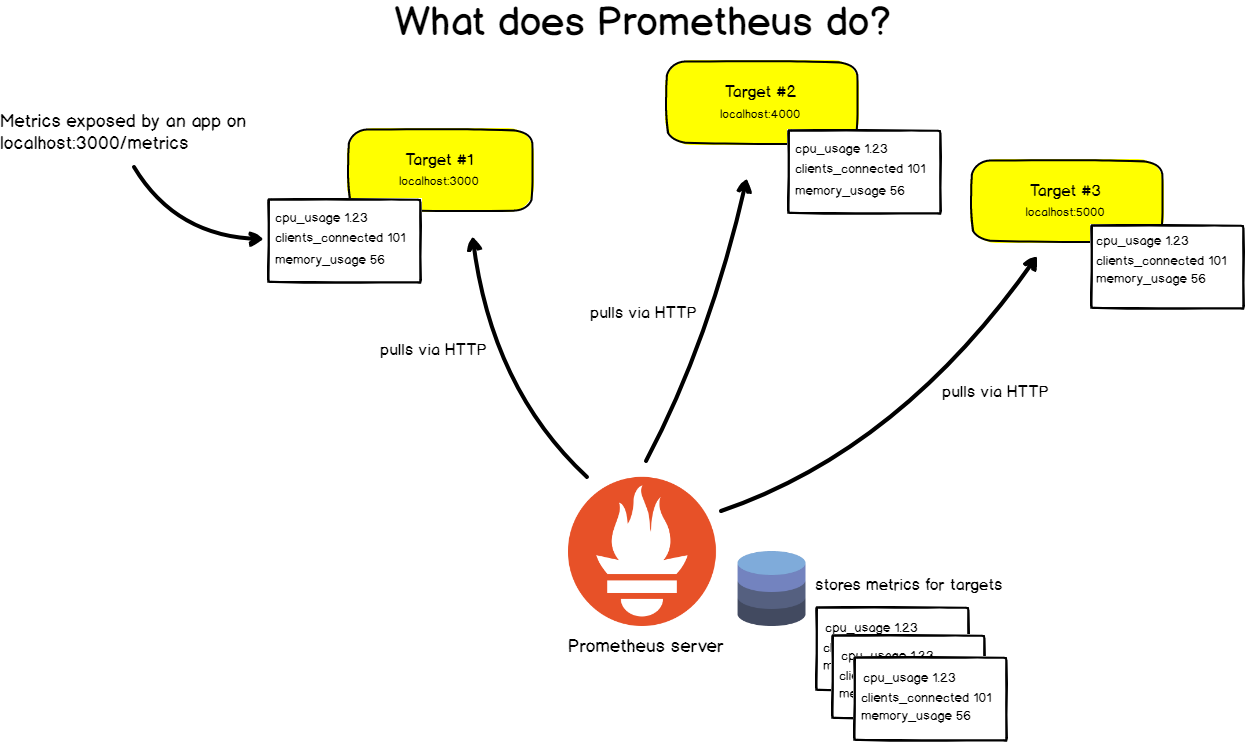
Pegue, por exemplo, o aplicativo Web localizado em http: // localhost: 3000 . O aplicativo transmite métricas em formato de texto para algum URL. Vamos dizer http: // localhost: 3000 / metrics .
Nesse endereço, o Prometheus recupera dados do destino em intervalos específicos.
1. Como o Prometheus funciona?
Como dissemos, o Prometheus consiste em uma ampla variedade de componentes.
Primeiro, você precisa extrair métricas de seus sistemas. Existem diferentes maneiras:
- Instrumentação do aplicativo, ou seja, seu aplicativo fornecerá métricas compatíveis com o Prometheus no URL especificado. O Prometheus o identificará como o destino e o descartará no intervalo especificado.
- Uso de exportadores prontos . Prometheus tem uma coleção de exportadores de tecnologias existentes. Por exemplo, exportadores prontos para monitorar máquinas Linux ( Node Exporter ), bancos de dados comuns ( SQL Exporter ou MongoDB Exporter ) e até mesmo para balanceadores de carga HTTP (por exemplo, HAProxy Exporter ).
- Usando o Pushgateway . Às vezes, aplicativos ou tarefas não fornecem métricas diretamente. Eles podem não ter sido projetados para isso (por exemplo, tarefas em lote) ou você mesmo decidiu não fornecer métricas diretamente por meio do aplicativo.
Como você já entendeu, o Prometheus coleta os próprios dados (exceto os casos raros em que usamos o Pushgateway).
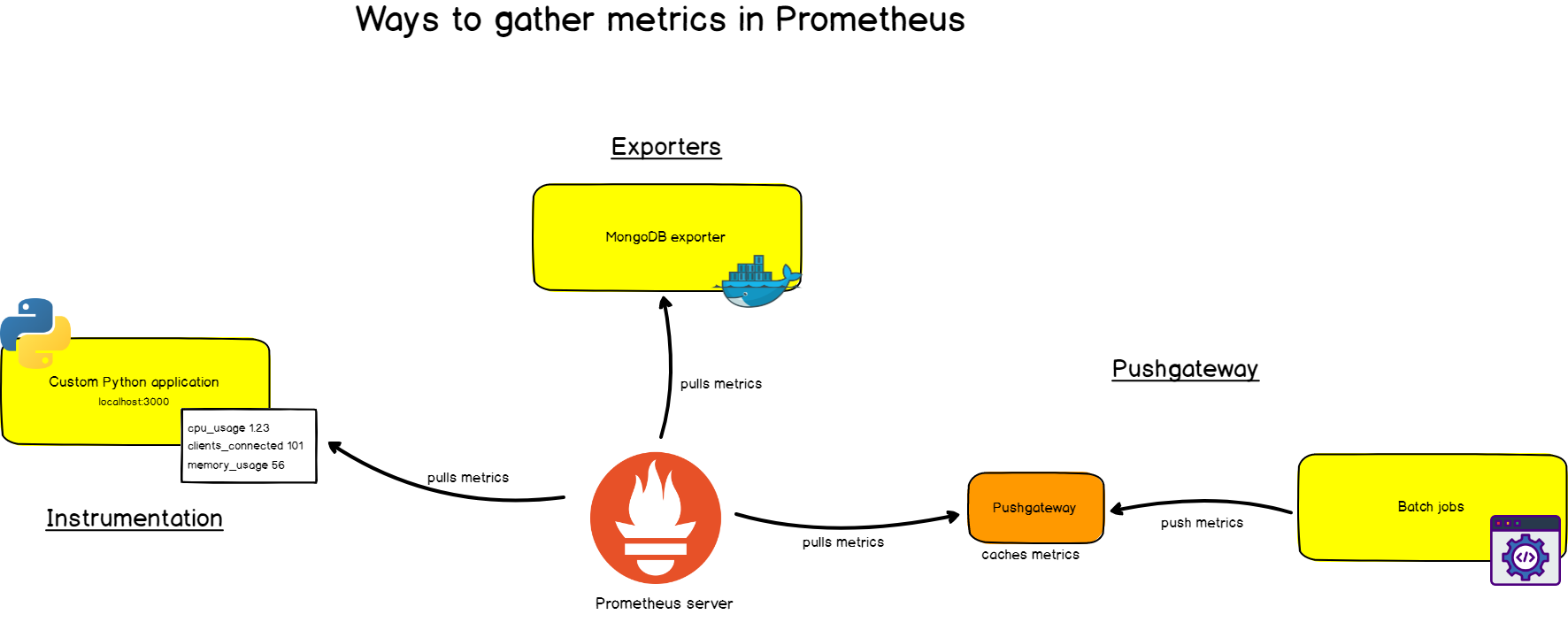
O que isso significa?
Por que isso é necessário?
2. Coleção vs. enviando
O Prometheus tem uma diferença notável em relação a outros bancos de dados de séries temporais: ele verifica ativamente os destinos para obter métricas deles .
O InfluxDB, por exemplo, funciona de maneira diferente: você envia dados diretamente para você mesmo.
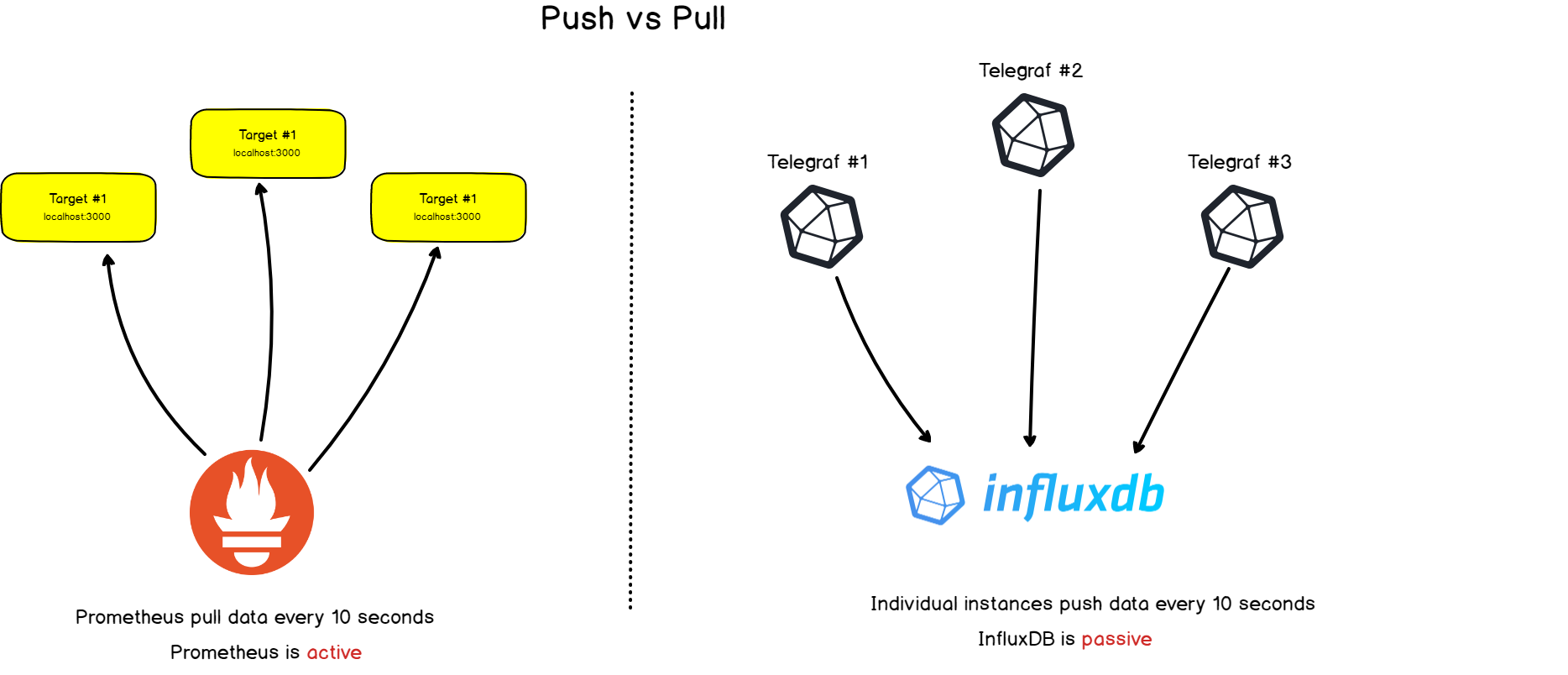
Ambas as abordagens têm seus prós e contras. Com base na documentação disponível, compilamos uma lista de razões pelas quais os criadores do Prometheus escolheram essa arquitetura:
- Controle centralizado . Se o Prometheus enviar solicitações para destinos, realizaremos toda a configuração no lado do Prometheus, não nos sistemas individuais.
Prometeu decide onde e com que frequência raspar.
Se os próprios objetos enviarem dados, existe o risco de haver muitos desses dados e o servidor travar. Quando o sistema coleta dados, você pode controlar a frequência da coleta e criar várias configurações de raspagem para selecionar uma frequência diferente para diferentes objetos .
- Prometheus armazena métricas agregadas .
Esta é uma adição à primeira parte em que discutimos o papel de Prometeu.
O Prometheus não é baseado em eventos e é muito diferente de outros bancos de dados de séries temporais. Ele não intercepta eventos individuais com limite de tempo (por exemplo, interrupções de serviço), mas coleta métricas pré-agregadas sobre seus serviços .
Especificamente, o serviço da web não envia uma mensagem de erro 404 e uma mensagem com a causa do erro. É enviada uma mensagem informando que o serviço recebeu uma mensagem de erro 404 nos últimos cinco minutos.
Essa é a principal diferença entre os bancos de dados de séries temporais que coletam métricas agregadas e os que coletam métricas brutas.
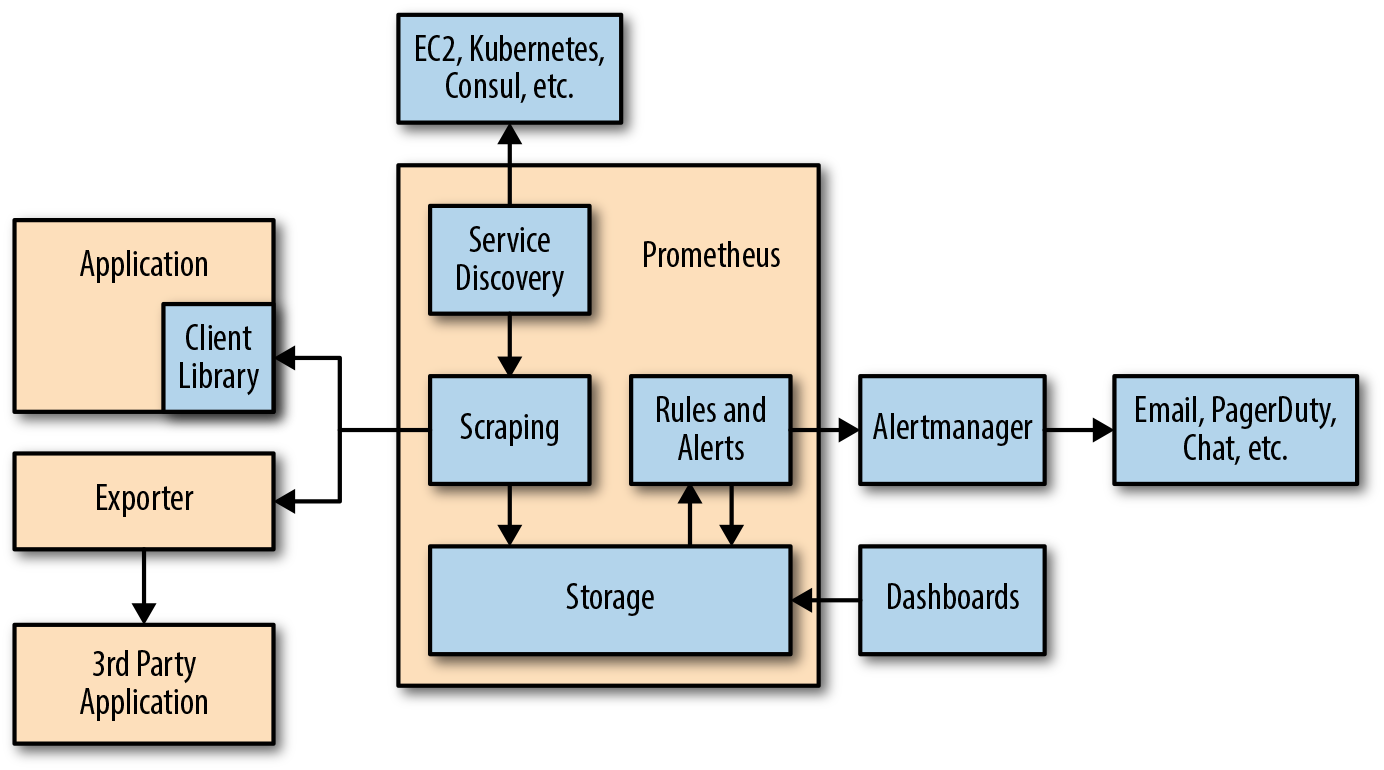
3. Desenvolvido o ecossistema de Prometheus
Essencialmente, o Prometheus é um banco de dados de séries temporais.
Porém, ao trabalhar com esses bancos de dados, você geralmente precisa visualizar os dados, analisá- los e configurar alertas para eles.
O Prometheus suporta as seguintes ferramentas que expandem sua funcionalidade:
- Alertmanager . O Prometheus envia alertas para o Alertmanager com base nas regras personalizadas definidas nos arquivos de configuração. A partir daí, eles podem ser exportados para diferentes pontos de extremidade (por exemplo, Pagerduty ou Slack).
- Visualização de dados . Como o Grafana, você pode visualizar séries temporais diretamente na interface do usuário da web do Prometheus. Você pode filtrar os dados e criar revisões específicas do que está acontecendo em diferentes destinos.
- Descoberta de serviço . O Prometheus detecta dinamicamente os alvos e raspa automaticamente novos alvos, mediante solicitação. Isso é especialmente conveniente se você trabalha com contêineres que alteram dinamicamente endereços com base na demanda.

Parte II Conceitos de Prometeu
Como no manual do InfluxDB, explicaremos em detalhes os termos técnicos relacionados ao Prometheus.
1. Modelo de dados de valor-chave
Antes de passar para as ferramentas do Prometheus, é importante entender completamente esse modelo de dados.
Prometheus trabalha com pares de valores-chave . A chave descreve o que estamos medindo e o valor armazena o valor real como um número.
Lembre-se: O Prometheus não foi projetado para armazenar informações brutas, como texto sem formatação. Ele armazena métricas agregadas ao longo de um período de tempo.
A chave neste caso é chamada de métrica . Por exemplo, velocidade do processador ou uso de memória.
Mas e se você precisar de mais detalhes sobre a métrica?
Por exemplo, o processador possui 4 núcleos e precisamos de 4 métricas separadas?
E aqui atalhos vêm para o resgate. Os atalhos fornecem mais informações sobre métricas adicionando campos adicionais. Por exemplo, você descreve não apenas a velocidade do processador, mas a velocidade de um núcleo em um IP específico.
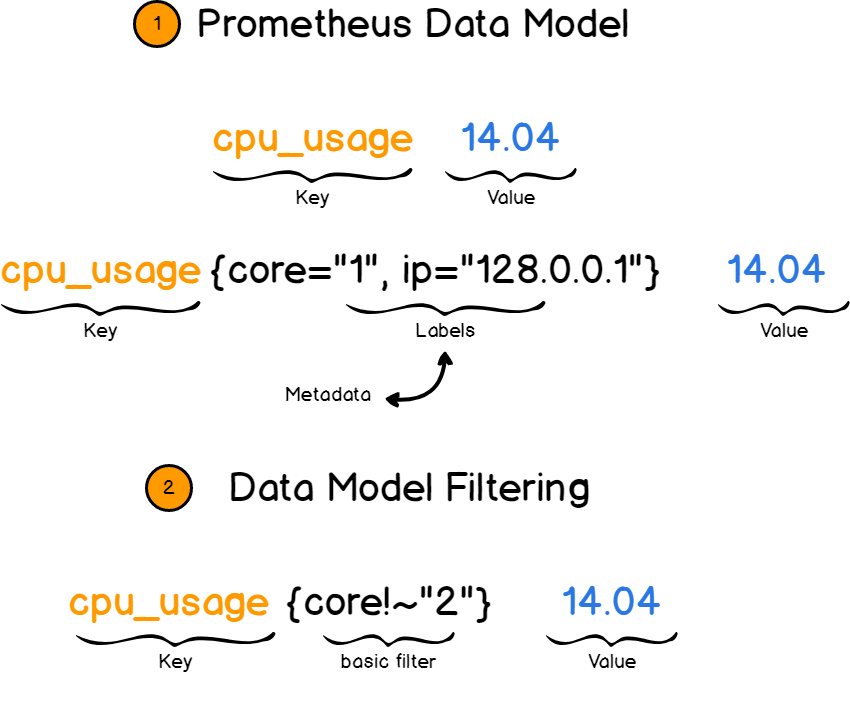
Em seguida, você pode filtrar as métricas por rótulos e visualizar apenas as informações necessárias.
2. Tipos de métricas
Ao monitorar com o Prometheus, as métricas podem ser descritas de quatro maneiras. É melhor ler até o fim, porque existem armadilhas aqui.
Contador
Este é provavelmente o tipo mais simples de métrica. O contador, como o nome indica, conta os elementos por um período de tempo .
Se você quiser contar, por exemplo, erros de HTTP em servidores ou visitar um site, use um contador .
E logicamente, é claro, o contador só pode aumentar ou zerar o número , portanto, não é adequado para valores que podem diminuir ou valores negativos.
Com sua ajuda, é especialmente conveniente considerar o número de ocorrências de um determinado evento durante um período de tempo, ou seja, a taxa de alteração da métrica ao longo do tempo.
E se você precisar medir, digamos, a memória usada por um determinado período?
Este valor pode diminuir. Como contar com Prometheus?
Metros
Conheça os medidores!
Os medidores lidam com valores que podem diminuir com o tempo . Eles podem ser comparados com termômetros - se você olhar para o termômetro, veremos a temperatura atual.
Mas se os medidores podem aumentar e diminuir e assumir valores positivos e negativos, então eles são melhores do que contadores?
Então os contadores são inúteis?
No começo, eu pensei que sim. Como eles podem fazer tudo, vamos usá-los em qualquer lugar. Isso é lógico?
Mas não.
Os medidores são ideais para medir o valor atual da métrica, que pode diminuir com o tempo.
É aqui que estão as mesmas armadilhas: o medidor não mostra o desenvolvimento da métrica por um período de tempo. Usando medidores, você pode perder alterações irregulares de métrica ao longo do tempo .
Porque Aqui está o que / u / justinDavidow diz :
“O medidor mostra o valor médio do contador delta para uma unidade durante um período de tempo.
O contador leva em consideração cada unidade usada (se for um processador, operações, ciclos ou ticks) e, em seguida, você pode escolher quais indicadores para qual período precisa.
Se você estiver usando um medidor, a taxa de amostragem deve ser precisa. Se a frequência diferir em pelo menos alguns microssegundos, o valor não será confiável. "Isso é ainda mais visível sob carga pesada, onde o tempo entre as medições aumenta exponencialmente, porque o planejador do sistema não tem tempo para prestar atenção ao aplicativo de monitoramento".
Se o sistema enviar métricas a cada 5 segundos e o Prometheus raspar o alvo a cada 15, algumas métricas poderão ser perdidas no processo. Se você realizar cálculos adicionais com essas métricas, a precisão dos resultados será ainda menor.
No balcão, cada valor é agregado. Quando Prometeu o coleta, ele percebe que o valor foi enviado em um determinado intervalo.
Agora não fique confuso.
Gráfico de barras
Um histograma é um tipo de métrica mais complexo. Fornece informações adicionais. Por exemplo, a soma das medições e seu número.
Os valores são coletados em uma área com um limite superior personalizado. Portanto, um histograma pode:
- Calcular valores médios , ou seja, a soma dos valores divididos pelo número de valores.
- Calcule medidas relativas de valores , e isso é muito conveniente se você precisar descobrir quantos valores em uma determinada área correspondem aos critérios especificados. Isso é especialmente útil se você precisar rastrear proporções ou definir indicadores de qualidade.
No mundo real, eu gostaria de ser notificado se 20% dos meus servidores tiverem uma resposta de mais de 300 ms ou uma resposta de servidor de mais de 300 ms em mais de 20% do tempo.
Se você está lidando com proporções, precisa de histogramas .
Sumário
Os painéis são histogramas avançados . Eles também mostram a soma e o número de medições, e também quantis para o período móvel .
Quantiles, se houver, estão dividindo a densidade de probabilidade em segmentos de igual probabilidade.
Então: gráficos de barra ou resumos?
Tudo depende da intenção .
Os histogramas combinam valores ao longo de um período de tempo, fornecendo a quantidade e a quantidade pela qual você pode acompanhar o desenvolvimento de uma determinada métrica.
Os resumos, por outro lado, mostram quantis durante um período de movimento (isto é, desenvolvimento contínuo ao longo do tempo).
Isso é especialmente conveniente se você precisar conhecer um valor que represente 95% dos valores registrados durante um período.
3. Tarefas e instâncias
Dados os recentes avanços nas arquiteturas distribuídas e a popularidade das soluções baseadas na nuvem, é improvável que você use um único servidor executando por conta própria.
Os servidores são replicados e distribuídos pelo mundo.
Para ilustrar isso, vejamos a arquitetura clássica de dois servidores HAProxy que redistribuem a carga em nove servidores Web de back-end ( não, não, não há pilhas Stackoverflow ) .
Neste exemplo da vida real, rastrearemos o número de erros HTTP retornados pelos servidores da web .
No Prometheus, um servidor web é chamado de instância . A tarefa será o fato de você medir o número de erros de HTTP em todas as instâncias.
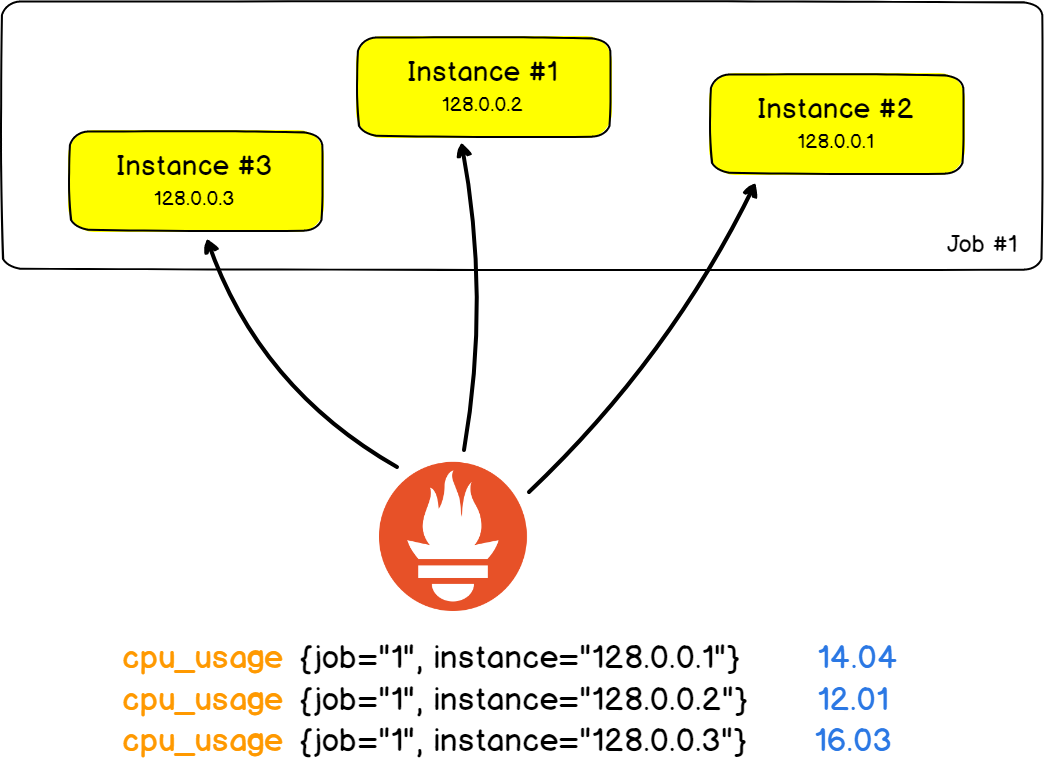
O bom é que tarefas e instâncias são campos em rótulos, e você pode filtrar os resultados por uma instância ou tarefa específica.
É conveniente?
4. PromQL
Se você usa bancos de dados baseados no InfluxDB, provavelmente já está familiarizado com o InfluxQL . Ou use SQL no TimescaleDB .
O Prometheus também possui sua própria linguagem para consultar e recuperar dados de servidores: PromQL .
Como já sabemos, os dados são apresentados na forma de pares de valores-chave. O PromQL usa a mesma sintaxe e retorna resultados como vetores.
Que tipo de vetores?
Existem dois tipos de vetores no Prometheus e no PromQL:
- Vetores instantâneos que representam todas as métricas pelo último registro de data e hora.
- Vetores com um intervalo de tempo : se você precisar analisar o desenvolvimento de uma métrica ao longo do tempo, poderá especificar um intervalo de tempo em uma solicitação ao Prometheus. Como resultado, você obterá um vetor que combina todos os valores registrados para o período selecionado.
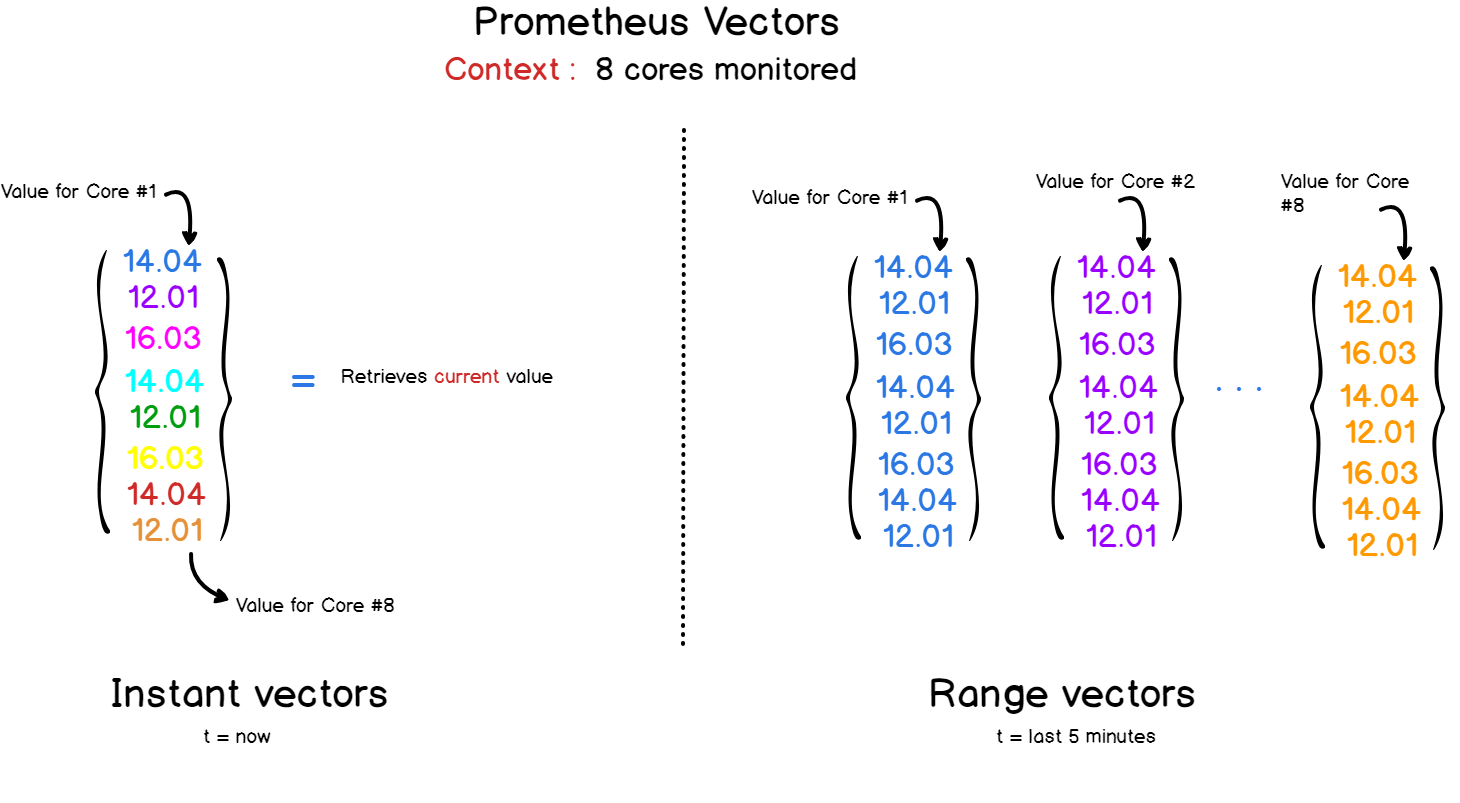
A API PromQL fornece um conjunto de funções para operações com dados em consultas.
Você pode classificar valores, aplicar funções matemáticas a eles (por exemplo, calcular derivadas ou expoentes) e até fazer previsões (por exemplo, usando o modelo Holt-Winters).
5. Instrumentação
A instrumentação é outra parte importante de Prometeu. Você instrumenta aplicativos antes de extrair dados deles.
No Prometheus, instrumentação significa adicionar bibliotecas de clientes ao aplicativo para fornecer métricas do Prometheus.
A instrumentação está disponível para as linguagens de programação mais comuns: por exemplo, Python, Java, Ruby, Go e até Node ou C # .
Em essência, você cria objetos de memória (por exemplo, medidores ou contadores) que aumentam ou diminuem dinamicamente o valor.
Então você escolhe onde fornecer as métricas. Prometheus irá buscá-los a partir daí e salvá-los em seu banco de dados de séries temporais.
6. Exportadores
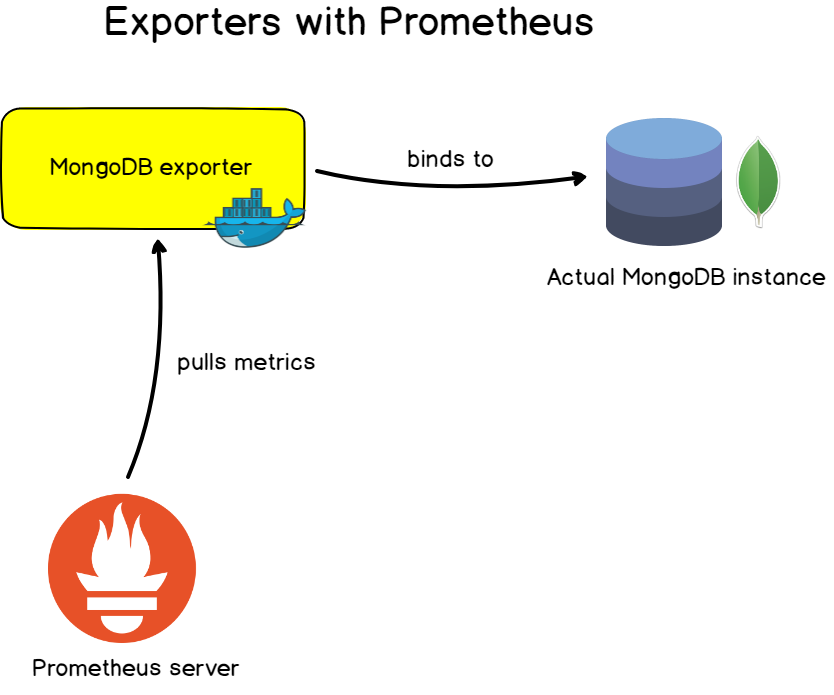
Nos aplicativos que você escreveu, é muito conveniente personalizar as métricas fornecidas e alterá-las ao longo do tempo usando instrumentação.
Para aplicativos, servidores e bancos de dados conhecidos, o Prometheus oferece aos exportadores com os quais você pode monitorar os destinos .
Esses exportadores geralmente são representados como imagens do Docker e são fáceis de personalizar. Eles fornecem um conjunto pronto de métricas e painéis frequentemente prontos com os quais você pode configurar o monitoramento em minutos.
Exemplos de exportadores:
- Exportadores de banco de dados: para bancos de dados MongoDB, servidores SQL e MySQL.
- Exportadores HTTP : para servidores HAProxy, Apache ou NGINX.
- Exportadores Unix : o desempenho do sistema pode ser monitorado usando os exportadores de nó integrados, que fornecem todas as métricas do sistema sem configuração adicional.
Algumas palavras sobre compatibilidade mútua
A maioria dos bancos de dados de séries temporais oferece suporte à interoperabilidade para seus sistemas.
Prometheus não é o único sistema de monitoramento com seus requisitos métricos. Por exemplo, InfluxDB (via Telegraf), CollectD , StatsD e Nagios também têm seus próprios padrões.
Portanto, para a interação de diferentes sistemas, são criados exportadores. Mesmo que o Telegraf não envie as métricas no formato aceito pelo Prometheus, o Telegraf pode enviar essas métricas ao exportador do InfluxDB, de onde o Prometheus as buscará.
7. Alertas
Ao trabalhar com bancos de dados de séries temporais, você precisa de feedback dos dados, e os gerentes de alerta são responsáveis por isso.
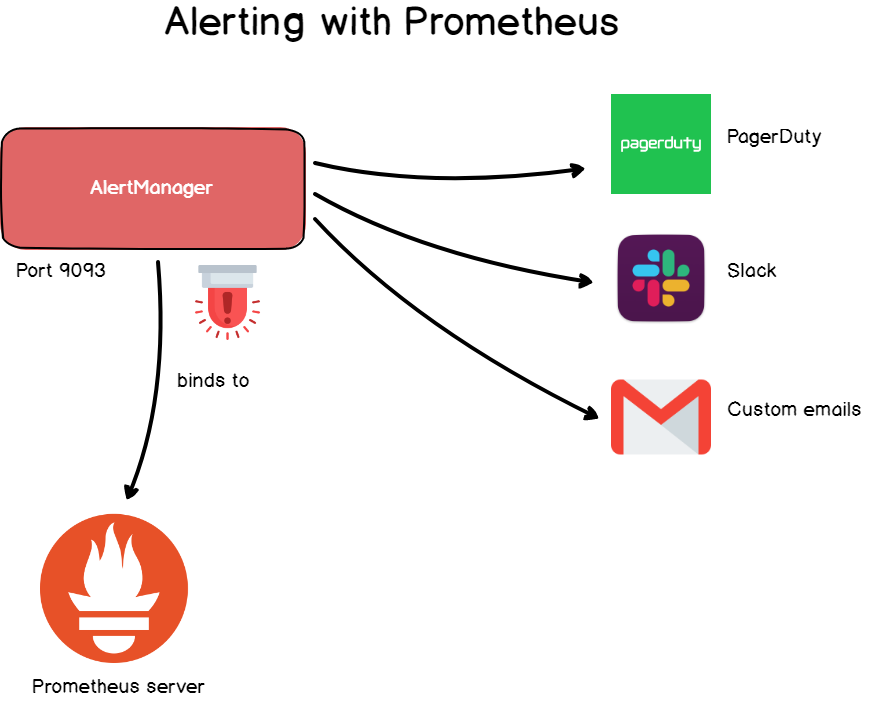
No Grafana, os alertas são comuns, mas também estão disponíveis no Prometheus por meio do gerenciador de alertas.
O Alert Manager é uma ferramenta separada que se une ao Prometheus e lança sirenes personalizadas .
Os alertas são definidos no arquivo de configuração e definem um conjunto de regras para métricas. Se a conformidade com a regra ocorrer na série temporal, um alerta será acionado e enviado aos destinatários especificados.
Como no Grafana, você pode especificar o endereço de email, Slack webhook, PagerDuty e objetos HTTP personalizados como destinatário.
Parte III Exemplos de Prometeu

E, é claro, todo guia deve ter exemplos práticos . Como eu gostaria de dizer, a tecnologia não é um fim em si mesma e deve cumprir uma tarefa específica.
Nós vamos falar sobre isso.
1. DevOps
Com todos esses exportadores para diferentes sistemas, bancos de dados e servidores, é óbvio que o Prometheus se destina principalmente ao setor de DevOps .
Sabemos que existem muitos fornecedores concorrentes e soluções personalizadas nessa área.
Prometheus é perfeito para DevOps.
Não é preciso quase nenhum esforço para instalar e executar instâncias, e você pode ativar e configurar facilmente qualquer ferramenta auxiliar.
Detectando destinos - por exemplo, através de um exportador de arquivos -, é uma ótima solução para pilhas em que os contêineres e arquiteturas distribuídas são amplamente utilizados.
Em um ambiente em que as instâncias são constantemente criadas e excluídas, nenhuma pilha do DevOps pode ficar sem a descoberta de serviço .
2. Saúde
Hoje, as soluções de monitoramento são necessárias não apenas em TI. Eles também são usados em grandes indústrias que fornecem arquiteturas de assistência médica flexíveis e escaláveis.
A demanda está crescendo e as arquiteturas de TI devem cumpri-la. Se você não possui uma ferramenta confiável para monitorar toda a infraestrutura, corre o risco de interrupções sérias no serviço . Já no setor da saúde, esse perigo deve ser definitivamente minimizado.
Este exemplo foi discutido no opensource.com no seguinte artigo .
3. Serviços financeiros
O exemplo mais recente foi dado na conferência da InfoQ, que discutiu o uso do Prometheus em instituições financeiras.
Jamie Christian e Alan Strader mostram como eles usam o Prometheus para monitorar sua infraestrutura no Northern Trust. Muito informativo, eu aconselho você a procurar.
Parte X. O que vem a seguir?

É hora de passar da teoria para a prática .
Hoje você se familiarizou com o básico do Prometheus, aprendeu quais funções ele executa, quais ferramentas e sistemas ele trabalha e quais termos ele usa.
Agora você tem tudo o que precisa para criar sua solução de monitoramento .
Para começar com o Prometheus, estude todos os exportadores disponíveis .
Em seguida, instale as ferramentas necessárias, crie seu primeiro painel - e pronto!
Se você precisar de inspiração, leia meu artigo sobre como monitorar uma máquina Linux com Prometheus e Grafana . Existem instruções para configurar ferramentas e o primeiro painel.
Espero que você tenha aprendido algo novo.
Se você tem um tópico para o meu próximo artigo, compartilhe-o.
Felizmente fique!