Um trabalho científico significativo a partir de 2012 transformou o campo do software de reconhecimento de imagem

Hoje eu posso, por exemplo, abrir o Google Fotos, escrever “praia” e ver várias fotos de várias praias que visitei na última década. E nunca assinei minhas fotos: o Google reconhece as praias com base no conteúdo. Esse recurso aparentemente chato é baseado em uma tecnologia chamada "rede neural convolucional profunda", que permite que os programas compreendam imagens usando um método complexo, inacessível às tecnologias das gerações anteriores.
Nos últimos anos, os pesquisadores descobriram que a precisão do software se torna melhor à medida que constroem redes neurais mais profundas (NS) e as treinam em conjuntos de dados cada vez maiores. Isso criou uma necessidade insaciável de poder de computação e enriqueceu fabricantes de GPU, como Nvidia e AMD. Há alguns anos, o Google desenvolveu seus próprios chips especiais para a Assembléia Nacional, enquanto outras empresas estão tentando acompanhá-lo.
Na Tesla, por exemplo, Andrei Karpati, especialista em aprendizado profundo, foi nomeado chefe do projeto Piloto Automático. Agora, a montadora está desenvolvendo seu próprio chip para acelerar o trabalho do NS em versões futuras do piloto automático. Ou então, pegue a Apple: os chips A11 e A12, centrais para os iPhones mais recentes, têm um “
processador neural ” do Neural Engine que acelera o NS e permite que aplicativos de reconhecimento de imagem e voz funcionem melhor.
Os especialistas que entrevistei para este artigo acompanham o início do boom do aprendizado profundo em um trabalho específico: AlexNet, em homenagem ao autor principal, Alex Krizhevsky. "Acredito que 2012 foi um ano marcante quando o trabalho da AlexNet foi lançado", disse Sean Gerrish, especialista em defesa e autor do livro "
Como os carros inteligentes pensam ".
Até 2012, as redes neurais profundas (GNS) eram uma espécie de remanso no mundo da região de Moscou. Mas então Krizhevsky e seus colegas da Universidade de Toronto participaram da prestigiada competição pelo reconhecimento de imagens, e seu programa superou dramaticamente em precisão tudo o que foi desenvolvido antes dele. Quase instantaneamente, o STS se tornou a tecnologia líder em reconhecimento de imagem. Outros pesquisadores que usam essa tecnologia logo demonstraram novas melhorias na precisão do reconhecimento.
Neste artigo, vamos nos aprofundar no aprendizado profundo. Vou explicar o que é o NS, como eles são treinados e por que eles exigem esses recursos de computação. E então explicarei por que um certo tipo de NS - redes de convolução profunda - entende as imagens tão bem. Não se preocupe, haverá muitas fotos.
Um exemplo simples com um neurônio
O conceito de uma "rede neural" pode parecer vago para você, então vamos começar com um exemplo simples. Suponha que você queira que a Assembléia Nacional decida se deve dirigir um carro com base nos sinais de trânsito verde, amarelo e vermelho. O NS pode resolver esse problema com um único neurônio.

Um neurônio recebe dados de entrada (1 - ligado, 0 - desligado), multiplica pelo peso apropriado e soma todos os valores dos pesos. Em seguida, o neurônio adiciona um deslocamento que define o valor limite para a "ativação" do neurônio. Nesse caso, se o resultado for positivo, acreditamos que o neurônio foi ativado - e vice-versa. O neurônio é equivalente à desigualdade "verde - vermelho - 0,5> 0". Se for verdade - ou seja, o verde está aceso e o vermelho não está aceso -, o carro deve partir.
Na NS real, os neurônios artificiais dão outro passo. Ao adicionar uma entrada ponderada e adicionar um deslocamento, o neurônio usa uma função de ativação não linear. Freqüentemente usado é um sigmóide, uma função em forma de S, sempre produzindo um valor de 0 a 1.
O uso da função de ativação não altera o resultado do nosso modelo simples de semáforo (basta usar um valor limite de 0,5, e não 0). Mas a não linearidade das funções de ativação é necessária para que os NSs modelem funções mais complexas. Sem a função de ativação, cada NS arbitrariamente complexo é reduzido a uma combinação linear de dados de entrada. Uma função linear não pode simular fenômenos complexos no mundo real. A função de ativação não linear permite ao NS aproximar
qualquer função matemática .
Exemplo de rede
Obviamente, existem muitas maneiras de aproximar uma função. Os NS se destacam pelo fato de sabermos “treiná-los” usando um pouco de álgebra, um monte de dados e um mar de poder computacional. Em vez de instruir o programador a desenvolver o NS para uma tarefa específica, podemos criar um software que comece com um NS bastante geral, estude vários exemplos marcados e depois altere o NS para fornecer o rótulo correto para o maior número possível de exemplos. A expectativa é que o NS final resuma os dados e produza os rótulos corretos para exemplos que não estavam anteriormente no banco de dados.
O processo que levou a esse objetivo começou muito antes da AlexNet. Em 1986, um trio de pesquisadores publicou um
trabalho histórico sobre retropropagação, uma tecnologia que ajudou a tornar realidade o aprendizado matemático de NSs complexos.
Para imaginar como funciona a retropropagação, vejamos um simples NS descrito por Michael Nielsen em seu excelente
livro online GO . O objetivo da rede é processar a imagem de um número escrito à mão em uma resolução de 28x28 pixels e determinar corretamente se o número 0, 1, 2 etc. é gravado.
Cada imagem tem 28 * 28 = 784 quantidades de entrada, cada uma com um número real de 0 a 1, indicando quanto o pixel é claro ou escuro. Nielsen criou o NA desse tipo:
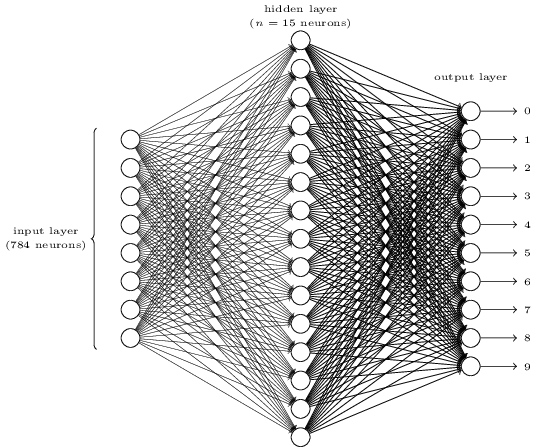
Cada círculo no centro e na coluna da direita é um neurônio semelhante ao que examinamos na seção anterior. Cada neurônio obtém uma média ponderada da entrada, adiciona um deslocamento e aplica uma função de ativação. Os círculos à esquerda não são neurônios, eles representam os dados de entrada da rede. E embora a imagem mostre apenas 8 círculos de entrada, na verdade existem 784 deles - um para cada pixel.
Cada um dos 10 neurônios à direita deve "acionar" seu próprio número: o superior deve ativar quando um 0 manuscrito é inserido (e somente nesse caso), o segundo quando a rede vê um 1 manuscrito (e somente ele) e assim por diante.
Cada neurônio percebe a entrada de cada neurônio da camada anterior. Portanto, cada um dos 15 neurônios no meio recebe 784 valores de entrada. Cada um desses 15 neurônios possui um parâmetro de peso para cada um dos 784 valores de entrada. Isso significa que apenas essa camada possui 15 * 784 = 11.760 parâmetros de peso. Da mesma forma, a camada de saída contém 10 neurônios, cada um dos quais recebe entrada de todos os 15 neurônios da camada do meio, o que adiciona outros 15 * 10 = 150 parâmetros de peso. Além disso, a rede possui 25 variáveis de deslocamento - uma para cada um dos 25 neurônios.
Treinamento em redes neurais
O objetivo do treinamento é ajustar esses 11.935 parâmetros para maximizar a probabilidade de que o neurônio de saída desejado - e somente ele - seja ativado quando as redes fornecerem uma imagem de um dígito manuscrito. Podemos fazer isso com o conhecido conjunto de imagens MNIST, onde existem 60.000 imagens marcadas com uma resolução de 28x28 pixels.
 160 de 60.000 imagens do conjunto MNIST
160 de 60.000 imagens do conjunto MNISTA Nielsen demonstra como treinar uma rede usando 74 linhas de código python comum - sem nenhuma biblioteca para MO. O aprendizado começa escolhendo valores aleatórios para cada um desses 11.935 parâmetros, pesos e compensações. Em seguida, o programa passa por exemplos de imagens, passando por duas etapas com cada uma delas:
- A etapa de propagação direta calcula a saída da rede com base na imagem de entrada e nos parâmetros atuais.
- A etapa de retropropagação calcula o desvio do resultado dos dados de saída corretos e altera os parâmetros da rede para melhorar levemente sua eficiência nesta imagem.
Um exemplo Digamos que a rede tenha recebido a seguinte imagem:
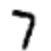
Se estiver bem calibrado, o pino "7" deve ir para 1 e as outras nove conclusões devem ir para 0. Mas, digamos que, em vez disso, a rede na saída "0" dê um valor de 0,8. Isso é demais! O algoritmo de treinamento altera os pesos de entrada do neurônio responsável por "0" para que fique mais próximo de 0 na próxima vez que esta imagem for processada.
Para isso, o algoritmo de retropropagação calcula um gradiente de erro para cada peso de entrada. Esta é uma medida de como o erro de saída será alterado para uma determinada alteração no peso de entrada. Em seguida, o algoritmo usa o gradiente para decidir quanto alterar cada peso de entrada - quanto maior o gradiente, mais forte a alteração.
Em outras palavras, o processo de treinamento "treina" os neurônios da camada de saída para prestar menos atenção às entradas (neurônios na camada do meio) que as levam à resposta errada, e mais às entradas que pressionam na direção certa.
O algoritmo repete esta etapa para todos os outros neurônios de saída. Reduz os pesos de entrada dos neurônios "1", "2", "3", "4", "5", "6", "8" e "9" (mas não "7"), a fim de diminuir o valor desses neurônios de saída. Quanto maior o valor de saída, maior o gradiente do erro de saída em relação ao peso de entrada - e mais seu peso diminuirá.
E vice-versa, o algoritmo aumenta o peso dos dados de entrada para a saída "7", o que faz com que o neurônio produza um valor mais alto na próxima vez que receber essa imagem. Novamente, entradas com valores maiores aumentarão mais os pesos, o que fará com que o neurônio de saída “7” preste mais atenção a essas entradas na próxima vez.
Então, o algoritmo deve executar os mesmos cálculos para a camada intermediária: altere cada peso de entrada em uma direção que reduza os erros de rede - novamente, aproximando a saída "7" de 1 e o restante a 0. Mas cada neurônio médio tem uma conexão com todos os 10 dias de folga, o que complica as coisas em dois aspectos.
Em primeiro lugar, o gradiente de erro para cada neurônio médio depende não apenas do valor de entrada, mas também dos gradientes de erro na próxima camada. O algoritmo é chamado de retropropagação porque os gradientes de erro das camadas posteriores da rede se propagam na direção oposta e são usados para calcular os gradientes nas camadas anteriores.
Além disso, cada neurônio do meio é uma entrada para todos os dez dias de folga. Portanto, o algoritmo de treinamento deve calcular o gradiente de erro, o que reflete como uma alteração em um determinado peso de entrada afeta o erro médio de todas as saídas.
A retropropagação é um algoritmo de escalar uma colina: cada passagem aproxima os valores de saída dos valores corretos para uma determinada imagem, mas apenas um pouco. Quanto mais exemplos o algoritmo examina, mais alto ele sobe a colina em direção ao conjunto ideal de parâmetros que classificam corretamente o número máximo de exemplos de treinamento. Para obter alta precisão, milhares de exemplos são necessários e o algoritmo pode precisar percorrer cada imagem neste conjunto dezenas de vezes antes que sua eficácia pare de crescer.
Nielsen mostra como implementar essas 74 linhas em python. Surpreendentemente, uma rede treinada com um programa tão simples pode reconhecer mais de 95% dos números manuscritos do banco de dados MNIST. Com melhorias adicionais, uma rede simples de duas camadas pode reconhecer mais de 98% dos números.
Inovação AlexNet
Você pode pensar que o desenvolvimento do tema da retropropagação deveria ocorrer na década de 1980 e dar origem a um rápido progresso no MO baseado na Assembléia Nacional - mas isso não aconteceu. Nos anos 90 e início dos anos 2000, algumas pessoas trabalharam nessa tecnologia, mas o interesse na Assembléia Nacional não ganhou impulso até o início dos anos 2010.
Isso pode ser rastreado até
a competição ImageNet , uma competição anual de MO organizada por Stanford Fay Fay Lee, especialista em TI. A cada ano, os rivais recebem o mesmo conjunto de mais de um milhão de imagens para treinamento, cada qual rotulado manualmente em categorias de mais de 1000 - de "caminhão de bombeiros" e "cogumelo" a "chita". O software dos participantes é julgado pela possibilidade de classificar outras imagens que não estavam no conjunto. Um programa pode dar alguns palpites e seu trabalho é considerado bem-sucedido se pelo menos um dos cinco primeiros palpites corresponder à marca estabelecida por uma pessoa.
A competição começou em 2010 e os NSs profundos não tiveram um grande papel nos primeiros dois anos. As melhores equipes usaram diferentes técnicas de MO e alcançaram resultados razoavelmente médios. Em 2010, a equipe venceu com uma porcentagem de erros igual a 28. Em 2011 - com um erro de 25%.
E então veio 2012. Uma equipe da Universidade de Toronto fez uma
oferta - mais tarde apelidada de AlexNet em homenagem ao autor principal, Alex Krizhevsky - e deixou os rivais para trás. Usando o NS profundo, a equipe alcançou uma taxa de erro de 16%. Para o concorrente mais próximo, esse número era 26.
O NS descrito no artigo para reconhecimento de manuscrito possui duas camadas, 25 neurônios e quase 12.000 parâmetros. O AlexNet era muito maior e mais complexo: oito camadas treinadas, 650.000 neurônios e 60 milhões de parâmetros.
É necessário um enorme poder de processamento para treinar NSs desse tamanho, e o AlexNet foi projetado para tirar proveito da paralelização massiva disponível nas GPUs modernas. Os pesquisadores descobriram como dividir o trabalho de treinar a rede em duas GPUs, o que dobrou o poder. E, apesar da otimização rigorosa, o treinamento em rede levou de 5 a 6 dias para o hardware que estava disponível em 2012 (em um par de Nvidia GTX 580 com 3 Gb de memória).
É útil estudar exemplos dos resultados da AlexNet para entender o quão sério esse avanço foi. Aqui está uma foto de um artigo científico que mostra exemplos de imagens e os cinco primeiros palpites da rede por sua classificação:

A AlexNet conseguiu reconhecer o tique na primeira foto, embora exista apenas um pequeno formulário no canto. O software não apenas identificou corretamente o leopardo, mas também deu outras opções próximas - um jaguar, chita, leopardo das neves, o Mau egípcio. AlexNet adicionou aos itens a foto hornbeam como "agaric". Apenas "cogumelo" foi a segunda versão da rede.
"Erros" AlexNet também são impressionantes. Ela marcou a foto com um dálmata em pé atrás de um monte de cerejas como "dálmata", embora o rótulo oficial fosse "cereja". A AlexNet reconheceu que havia algum tipo de fruta na foto - entre as cinco primeiras opções eram "uvas" e "sabugueiro" - ela simplesmente não reconheceu a cereja. Em uma foto de um lêmure de Madagascar sentado em uma árvore, AlexNet deu uma lista de pequenos mamíferos que vivem em árvores. Eu acho que muitas pessoas (inclusive eu) teriam colocado a assinatura errada aqui.
A qualidade do trabalho foi impressionante e demonstrou que o software é capaz de reconhecer objetos comuns em uma ampla gama de orientações e ambientes. O GNS rapidamente se tornou a técnica mais popular para reconhecimento de imagens e, desde então, o mundo do MO não o abandonou.
“Após o sucesso do método baseado em GO em 2012, a maioria dos participantes da competição de 2013 mudou para redes neurais convolucionais profundas”, escreveram os patrocinadores do ImageNet. Nos anos seguintes, essa tendência continuou e, posteriormente, os vencedores trabalharam com base em tecnologias básicas, aplicadas pela primeira vez pela equipe AlexNet. Em 2017, os rivais, usando NSs mais profundos, reduziram seriamente a taxa de erro para menos de três. Dada a complexidade da tarefa, os computadores aprenderam até certo ponto a resolvê-la melhor do que muitas pessoas.
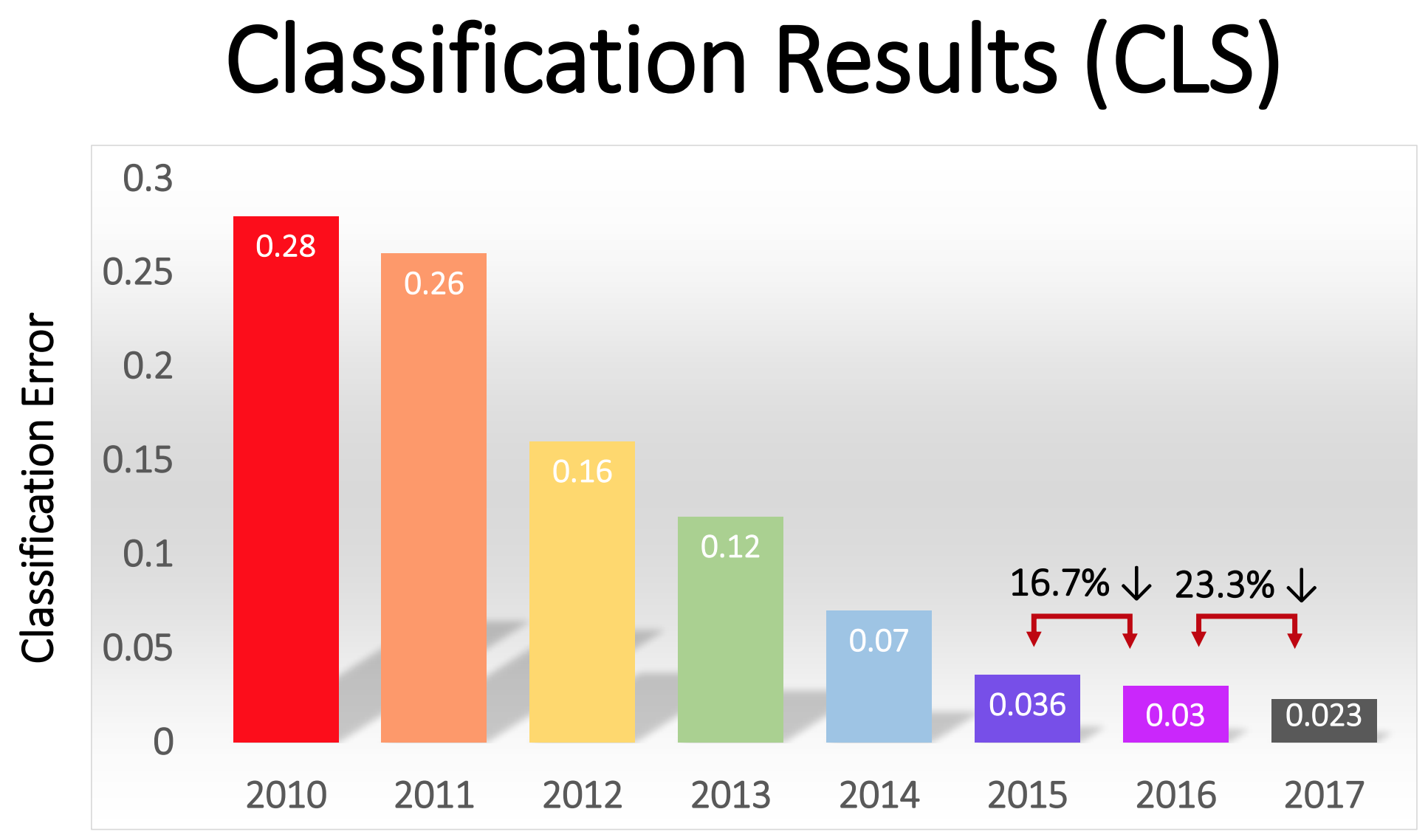 A porcentagem de erros na classificação de imagens em diferentes anos
A porcentagem de erros na classificação de imagens em diferentes anosRedes de convolução: um conceito
Tecnicamente, AlexNet era um NS convolucional. Nesta seção, explicarei o que a rede neural convolucional (SNA) faz e por que essa tecnologia se tornou criticamente importante para os algoritmos modernos de reconhecimento de padrões.
A rede simples discutida anteriormente para reconhecimento de manuscrito estava completamente conectada: cada neurônio da primeira camada era uma entrada para cada neurônio da segunda camada. Essa estrutura funciona muito bem em tarefas simples com reconhecimento de números em imagens de 28x28 pixels. Mas não escala bem.
No banco de dados de dígitos manuscritos MNIST, todos os caracteres são centralizados. Isso simplifica muito o aprendizado, porque, digamos, os sete sempre terão vários pixels escuros na parte superior e direita e o canto inferior esquerdo é sempre branco. Zero quase sempre terá uma mancha branca nos pixels médios e escuros nas bordas. Uma rede simples e totalmente conectada pode reconhecer esses padrões facilmente.
Mas digamos que você queira criar um NS capaz de reconhecer números que podem ser localizados em qualquer lugar em uma imagem maior. Uma rede totalmente conectada não funcionará tão bem com essa tarefa, porque não possui uma maneira eficaz de reconhecer recursos semelhantes em formulários localizados em diferentes partes da imagem. Se no conjunto de dados de treinamento a maioria dos setes estiver localizada no canto superior esquerdo, sua rede será melhor em reconhecer os setes no canto superior esquerdo do que em qualquer outra parte da imagem.
Teoricamente, esse problema pode ser resolvido garantindo que o seu conjunto tenha muitos exemplos de cada dígito em cada uma das posições possíveis. Mas, na prática, isso será um enorme desperdício de recursos. Com o aumento do tamanho da imagem e da profundidade da rede, o número de links - e o número de parâmetros de peso - aumentará de forma explosiva. Você precisará de muito mais imagens de treinamento (e poder de computação) para obter uma precisão adequada.
, , . .
« , , — . – , , – ? , . . , . . , ».
, , 2828 . , , . «7», , . .
AlexNet
«» , , – . , 28 . AlexNet 1111 . 3-5 .
: , , . , . AlexNet 96 , 96 .

, , 96 AlexNet . , , , .
: , . AlexNet , 96 . «» 96 , .
96 , - :

, - :

, - :

93 AlexNet. , – 96 ( , 4 ).
AlexNet. , .
, , , . . , , , . , . .
2014
, , , ImageNet.
, , , , . , . – . – , . , , , , .
 –
– –
– , ,
, , ,
,
, , . , . . - (, , - ).
11, – . , , , «» . , . , , .
, . , , , :

. , , . !
, , , , «», . AlexNet , , . , , 1000 .
, . , , . . , .
:
, , , .
() . , , . .
, , . . , , .
AlexNet . 1111 , 1111 . 121 , – , . 363 . , 363 , . , 363, 363.
. 1111 , . 7 , , . 363 , 1111, , .
, 363 , , . , . ; 4 .
, : 5555 3025 . 363 , . , «» , .
, AlexNet 96 . 3025 96 . 95- – 3025 . 3025 363 – , 95 .
, , .
« – », — . , , .
. .
O trabalho de AlexNet se tornou uma sensação na comunidade acadêmica da região de Moscou, mas sua importância foi rapidamente entendida no setor de TI. O Google estava especialmente interessado nela.
Em 2013, o Google adquiriu uma startup fundada pelos autores AlexNet. A empresa usou essa tecnologia para adicionar um novo recurso de pesquisa de fotos ao Google Fotos. "Pegamos a pesquisa avançada e a colocamos em operação pouco mais de seis meses depois", escreveu Chuck Rosenberg, do Google.
Enquanto isso, em 2013, foi descrito como o Google usa o GSS para reconhecer endereços de fotos do Google Street View. "Nosso sistema nos ajudou a extrair quase 100 milhões de endereços físicos dessas imagens", escreveram os autores.
Os pesquisadores descobriram que a eficácia do NS cresce com o aumento da profundidade. "Descobrimos que a eficácia dessa abordagem aumenta com a profundidade do SNA, e a arquitetura mais profunda que treinamos mostra os melhores resultados", escreveu a equipe do Google Street View. "Nossos experimentos sugerem que arquiteturas mais profundas podem produzir maior precisão, mas com uma desaceleração da eficiência".
Então, depois da AlexNet, as redes começaram a ficar mais profundas. A equipe do Google fez uma oferta na competição em 2014 - apenas dois anos após a vitória da AlexNet em 2012. Também foi baseado em um SNA profundo, mas Goolge usou uma rede muito mais profunda de 22 camadas para obter uma taxa de erro de 6,7% - essa foi uma grande melhoria em comparação aos 16% da AlexNet.
Mas, ao mesmo tempo, redes mais profundas funcionavam melhor apenas com conjuntos maiores de dados de treinamento. Portanto, Gerrish diz que o conjunto de dados e a concorrência do ImageNet tiveram um papel importante no sucesso do SNA. Lembre-se de que, no concurso ImageNet, os participantes recebem um milhão de imagens e são solicitados a classificá-las em 1.000 categorias.
"Se você tem um milhão de imagens para treinamento, cada classe inclui 1.000 imagens", disse Gerrish. Sem um conjunto de dados tão grande, ele disse: "você teria muitas opções para treinar a rede".
Nos últimos anos, os especialistas estão se concentrando cada vez mais na coleta de uma enorme quantidade de dados para treinar redes mais profundas e precisas. É por isso que as empresas que desenvolvem carros-robô se concentram em rodar em vias públicas - imagens e vídeos dessas viagens são enviados para a sede e usados para treinar NS corporativos.
Crescimento de aprendizado profundo de computação
A descoberta do fato de que redes mais profundas e conjuntos de dados maiores podem melhorar o desempenho do NS criou uma sede insaciável de poder de computação cada vez maior. Um dos principais componentes do sucesso da AlexNet foi a idéia de que o treinamento em matriz é usado no treinamento NS, que pode ser executado com eficiência em GPUs bem paralelizáveis.
"Os NSs são bem paralelos", disse Jai Ten, pesquisador do MO. As placas gráficas - fornecendo uma enorme capacidade de processamento paralelo para videogames - provaram ser úteis para os NSs.
"A parte central do trabalho da GPU, a multiplicação muito rápida da matriz, acabou sendo a parte central do trabalho da Assembléia Nacional", disse Ten.
Tudo isso foi bem-sucedido para os principais fabricantes de GPU, Nvidia e AMD. Ambas as empresas desenvolveram novos chips especificamente adaptados às necessidades do aplicativo MO, e agora os aplicativos de IA são responsáveis por uma parte significativa das vendas de GPU dessas empresas.
Em 2016, o Google anunciou a criação de um chip especial, a Tensor Processing Unit (TPU), projetada para operar na Assembléia Nacional. "Embora o Google estivesse considerando a possibilidade de criar circuitos integrados para fins especiais (ASICs) em 2006, essa situação tornou-se urgente em 2013",
escreveu um representante da empresa no ano passado. "Foi então que percebemos que os requisitos de rápido crescimento da Assembléia Nacional para poder de computação podem exigir que dobremos o número de data centers que temos".
Inicialmente, apenas os serviços do Google tinham acesso a TPUs, mas depois a empresa permitiu que todos usassem essa tecnologia por meio de uma plataforma de computação em nuvem.
Obviamente, o Google não é a única empresa que trabalha com chips de IA. Apenas alguns exemplos: nas versões mais recentes dos chips para iPhone,
existe um "núcleo neural" otimizado para operações com o NS. A Intel está
desenvolvendo sua própria linha de chips otimizados para GO. A Tesla
anunciou recentemente a rejeição de chips da Nvidia em favor de seus próprios chips NS. Há rumores de que a Amazon esteja
trabalhando em seus chips de IA.
Por que redes neurais profundas são difíceis de entender
Expliquei como as redes neurais funcionam, mas não expliquei por que elas funcionam tão bem. Não está claro como exatamente a imensa quantidade de cálculos matriciais permite que um sistema de computador diferencie uma onça-pintada de um guepardo e sabugueiro de groselha.
Talvez a qualidade mais notável da Assembléia Nacional seja que não. A convolução permite que o NS entenda a hifenização - eles podem dizer se a imagem no canto superior direito da imagem é semelhante à imagem no canto superior esquerdo de outra imagem.
Mas, ao mesmo tempo, o SNA não tem idéia sobre geometria. Eles não podem reconhecer a semelhança das duas imagens se forem giradas 45 graus ou dobradas. O SNA não tenta entender a estrutura tridimensional dos objetos e não pode levar em consideração as diferentes condições de iluminação.
Mas, ao mesmo tempo, os NSs podem reconhecer fotos de cães tirados de frente e de lado, e não importa se o cão ocupa uma pequena parte da imagem ou uma grande. Como eles fazem isso? Acontece que, se houver dados suficientes, uma abordagem estatística com enumeração direta pode lidar com a tarefa. O SNA não foi projetado para "imaginar" como uma imagem em particular ficaria de um ângulo diferente ou em condições diferentes, mas com um número suficiente de exemplos rotulados, ela pode aprender todas as variações possíveis da imagem por simples repetição.
Há evidências de que o sistema visual das pessoas funciona de maneira semelhante. Veja algumas fotos - primeiro estude cuidadosamente a primeira e depois abra a segunda.
 Primeira foto
Primeira fotoO criador da imagem tirou a fotografia de alguém e virou os olhos e a boca de cabeça para baixo. A imagem parece relativamente normal quando você a olha de cabeça para baixo, porque o sistema visual humano está acostumado a ver olhos e bocas nessa posição. Mas se você olhar a foto na orientação correta, poderá ver imediatamente que o rosto está estranhamente distorcido.
Isso sugere que o sistema visual humano é baseado nas mesmas técnicas de reconhecimento de padrões brutos que o NS. Se olharmos para algo que quase sempre é visível em uma orientação - o olho humano -, podemos reconhecê-lo muito melhor em sua orientação normal.
Os NSs reconhecem bem as imagens usando todo o contexto disponível nelas. Por exemplo, carros geralmente dirigem nas estradas. Os vestidos geralmente são usados no corpo de uma mulher ou pendurados em um armário. As aeronaves geralmente são atiradas contra o céu ou dominam a pista. Ninguém ensina especificamente ao NS essas correlações, mas com um número suficiente de exemplos rotulados, a própria rede pode aprendê-los.
Em 2015, pesquisadores do Google tentaram entender melhor o NS, "executando-os ao contrário". Em vez de usar imagens para o treinamento de NS, eles usavam NS treinado para alterar as imagens. Por exemplo, eles começaram com uma imagem contendo ruído aleatório e, gradualmente, a mudaram para que ativasse fortemente um dos neurônios de saída do SN - na verdade, pediram ao NS para "desenhar" uma das categorias que foi ensinado a reconhecer. Em um caso interessante, eles forçaram o NS a gerar imagens que ativam o NS, treinadas para reconhecer halteres.

"É claro que existem halteres aqui, mas nenhuma imagem dos halteres parece completa sem a presença de um rolo muscular muscular levantando-os", escreveram pesquisadores do Google.
À primeira vista, parece estranho, mas, na realidade, não é tão diferente do que as pessoas fazem. Se vemos um objeto pequeno ou embaçado na imagem, procuramos uma pista ao seu redor para entender o que pode acontecer lá. As pessoas, obviamente, falam sobre as fotos de maneira diferente, usando uma compreensão conceitual complexa do mundo ao seu redor. Mas, no final, o STS reconhece bem as imagens, porque elas tiram o máximo proveito de todo o contexto descrito nelas, e isso não é muito diferente de como as pessoas fazem isso.