
Em 14 de maio, quando Trump estava se preparando para lançar todos os cães na Huawei, sentei-me pacificamente em Shenzhen no Huawei STW 2019 - uma grande conferência para 1000 participantes - que incluía relatórios de
Philip Wong , vice-presidente de pesquisa da TSMC sobre as perspectivas da computação não-von Neumann arquiteturas, e Heng Liao, Huawei Fellow, Cientista Chefe Huawei 2012 Lab, no desenvolvimento de uma nova arquitetura de processadores tensoriais e neuroprocessadores. O TSMC, se você sabe, produz aceleradores neurais para Apple e Huawei usando a tecnologia de 7 nm (que
poucas pessoas possuem ), e a Huawei está pronta para competir com o Google e a NVIDIA por neuroprocessadores.
O Google na China está proibido, eu não me preocupei em colocar uma VPN no tablet, então usei o Yandex de forma
patriótica para ver qual é a situação com outros fabricantes de ferro semelhante e o que geralmente acontece. Em geral, observei a situação, mas somente depois desses relatórios percebi o quão em grande escala a revolução estava sendo preparada nas entranhas das empresas e no silêncio das salas científicas.
Somente no ano passado, foram investidos mais de US $ 3 bilhões no tópico. O Google há muito tempo declara as redes neurais uma área estratégica, está construindo ativamente seu suporte de hardware e software. A NVIDIA, sentindo que o trono é impressionante, está fazendo esforços fantásticos nas bibliotecas de aceleração de redes neurais e no novo hardware. Em 2016, a Intel gastou 0,8 bilhões para comprar duas empresas envolvidas na aceleração de hardware de redes neurais. E isso apesar do fato de que as principais compras ainda não começaram e o número de jogadores excedeu cinquenta e está crescendo rapidamente.
TPU, VPU, IPU, DPU, NPU, RPU, NNP - o que tudo isso significa e quem vencerá? Vamos tentar descobrir. Quem se importa - Bem-vindo ao gato!
Isenção de responsabilidade: o autor teve que reescrever completamente os algoritmos de processamento de vídeo para uma implementação efetiva no ASIC, e os clientes fizeram protótipos no FPGA, para que haja uma idéia da profundidade da diferença nas arquiteturas. No entanto, o autor não trabalhou diretamente com ferro recentemente. Mas ele antecipa que terá que se aprofundar nisso.
Antecedentes dos problemas
O número de cálculos necessários está crescendo rapidamente, as pessoas gostariam de ter mais camadas, mais opções de arquitetura, jogar mais ativamente com hiperparâmetros, mas ... depende do desempenho. Ao mesmo tempo, por exemplo, com o crescimento da produtividade dos bons e antigos processadores - grandes problemas. Todas as coisas boas chegam ao fim: a lei de Moore, como você sabe, está se esgotando e a taxa de crescimento do desempenho do processador cai:
Cálculos do desempenho real de operações inteiras no SPECint em comparação com o VAX11-780 , daqui em diante frequentemente uma escala logarítmicaSe de meados da década de 80 a meados da década de 2000 - nos anos abençoados do auge dos computadores - o crescimento foi a uma taxa média de 52% ao ano, nos últimos anos diminuiu para 3% ao ano. E isso é um problema (uma tradução de um artigo recente do patriarca John Hennessey sobre os problemas e as perspectivas da arquitetura moderna
estava em Habré ).
Há muitas razões, por exemplo, a frequência dos processadores parou de crescer:
Tornou-se mais difícil reduzir o tamanho dos transistores. O último infortúnio que reduz drasticamente a produtividade (incluindo o desempenho das CPUs já lançadas) é (rolo de tambor) ... certo, segurança.
Fusão ,
Spectre e
outras vulnerabilidades causam enormes danos à taxa de crescimento da potência de processamento da CPU (
um exemplo de desativação do hyperthreading (!)). O tópico se tornou popular e novas vulnerabilidades desse tipo são encontradas
quase que mensalmente . E isso é algum tipo de pesadelo, porque dói em termos de desempenho.
Ao mesmo tempo, o desenvolvimento de muitos algoritmos está firmemente ligado ao crescimento familiar da potência do processador. Por exemplo, hoje muitos pesquisadores não estão preocupados com a velocidade dos algoritmos - eles terão alguma coisa. E seria bom aprender - as redes se tornam grandes e "difíceis" de usar. Isso é especialmente evidente no vídeo, para o qual a maioria das abordagens, em princípio, não é aplicável em alta velocidade. E eles costumam fazer sentido apenas em tempo real. Isso também é um problema.
Da mesma forma, novos padrões de compressão estão sendo desenvolvidos, o que implica um aumento na potência do decodificador. E se a energia do processador não aumentar? A geração mais velha lembra como, nos anos 2000, houve problemas na reprodução de vídeo em alta definição no
H.264 então fresco em computadores mais antigos. Sim, a qualidade foi melhor com um tamanho menor, mas em cenas rápidas a imagem foi interrompida ou o som foi rasgado. Eu tenho que me comunicar com os desenvolvedores do novo
VVC / H.266 (um lançamento está planejado para o próximo ano). Você não os invejará.
Então, o que o próximo século nos prepara à luz da diminuição da taxa de crescimento do desempenho do processador aplicado às redes neurais?
CPU
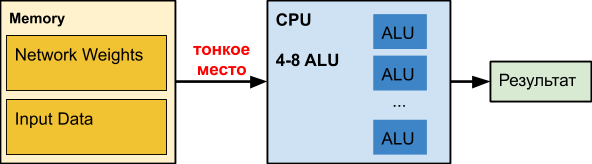
Uma
CPU comum é um grande número de britadores aperfeiçoados há décadas. Infelizmente, para outras tarefas.
Quando trabalhamos com redes neurais, especialmente as profundas, nossa própria rede pode ocupar centenas de megabytes. Por exemplo, os requisitos de memória das redes de
detecção de
objetos são os seguintes:
Em nossa experiência, os coeficientes de uma rede neural profunda para processar
bordas translúcidas podem ocupar 150-200 MB. Os colegas da rede neural determinam a idade e o sexo do tamanho dos coeficientes da ordem de 50 MB. E durante a otimização para a versão móvel de precisão reduzida - cerca de 25 MB (float32⇒float16).
Ao mesmo tempo, o gráfico de atraso ao acessar a memória, dependendo do tamanho dos dados, é distribuído
aproximadamente assim (a escala horizontal é logarítmica):
I.e. com um aumento no volume de dados de mais de 16 MB, o atraso aumenta 50 vezes ou mais, o que afeta fatalmente o desempenho. De fato, na maioria das vezes a CPU, ao trabalhar com redes neurais profundas, espera
estupidamente por dados.
Os dados da Intel sobre aceleração de várias redes são interessantes, onde, de fato, a aceleração ocorre apenas quando a rede se torna pequena (por exemplo, como resultado da quantização de pesos), para começar a entrar pelo menos parcialmente no cache juntamente com os dados processados. Observe que o cache de uma CPU moderna consome até metade da energia do processador. No caso de redes neurais pesadas, é ineficaz e funciona aquecedor excessivamente caro.
Para adeptos de redes neurais na CPUDe acordo com nossos testes internos, até o
Intel OpenVINO perde a implementação da estrutura de multiplicação de matrizes + NNPACK em muitas arquiteturas de rede (especialmente em arquiteturas simples onde a largura de banda é importante para o processamento de dados em tempo real no modo de thread único). Esse cenário é relevante para vários classificadores de objetos na imagem (onde a rede neural precisa ser executada um grande número de vezes - 50–100 em termos do número de objetos na imagem) e a sobrecarga de iniciar o OpenVINO se torna excessivamente alta.
Prós:- "Todo mundo tem", e geralmente fica ocioso, ou seja, preço de entrada relativamente baixo para cobrança e implementação.
- Existem redes não CV separadas que se encaixam bem na CPU, os colegas chamam, por exemplo, Wide & Deep e GNMT.
Menos:- A CPU é ineficiente ao trabalhar com redes neurais profundas (quando o número de camadas de rede e o tamanho dos dados de entrada são grandes), tudo funciona dolorosamente devagar.
GPU

Como o tópico é bem conhecido, descrevemos brevemente o principal. No caso de redes neurais, a
GPU possui uma vantagem significativa de desempenho em tarefas massivamente paralelas:
Preste atenção em como o
Xeon Phi 7290 de 72 núcleos
é recozido, enquanto o "azul" também é o servidor Xeon, ou seja, A Intel não desiste tão facilmente, o que será discutido abaixo. Mais importante, porém, a memória das placas de vídeo foi originalmente projetada para um desempenho cerca de 5 vezes maior. Nas redes neurais, a computação com dados é extremamente simples. Algumas ações elementares e precisamos de novos dados. Como resultado, a velocidade de acesso aos dados é crítica para a operação eficiente de uma rede neural. Uma memória de alta velocidade "integrada" na GPU e um sistema de gerenciamento de cache mais flexível do que na CPU podem resolver este problema:
Por vários anos, Tim Detmers apoia a interessante revisão de
"Quais GPU (s) obter (s) para o Deep Learning: minha experiência e conselhos para usar GPUs no Deep Learning" ("Qual GPU é melhor para o aprendizado profundo ..."). É claro que Tesla e Titans governam o treinamento, embora a diferença nas arquiteturas possa causar explosões interessantes, por exemplo, no caso de redes neurais recorrentes (e o líder em geral é o TPU, observe para o futuro):
No entanto, existe um gráfico de desempenho extremamente útil para o dólar, no cavalo
RTX (provavelmente devido aos
seus núcleos tensores ), se você tiver memória suficiente para isso, é claro:
Obviamente, o custo da computação é importante. O segundo lugar da primeira classificação e o último da segunda - o
Tesla V100 é vendido por 700 mil rublos, como 10 computadores "comuns" (+ o caro switch Infiniband, se você deseja treinar em vários nós). V100 verdadeiro e trabalha para dez. As pessoas estão dispostas a pagar em excesso pela aceleração tangível do aprendizado.
Total, resumir!
Prós:- Cardinal - 10-100 vezes - aceleração em comparação com a CPU.
- Extremamente eficaz para treinamento (e um pouco menos eficaz para uso).
Menos:- O custo das placas de vídeo topo de linha (que têm memória suficiente para treinar redes grandes) excede o custo do restante do computador ...
FPGA
 FPGA
FPGA já é mais interessante. Esta é uma rede de vários milhões de blocos programáveis, os quais também podemos interconectar programaticamente. A rede e os blocos
são mais ou menos assim (o gargalo é o gargalo, preste atenção, novamente na frente da memória do chip, mas é mais fácil, que será descrito abaixo):
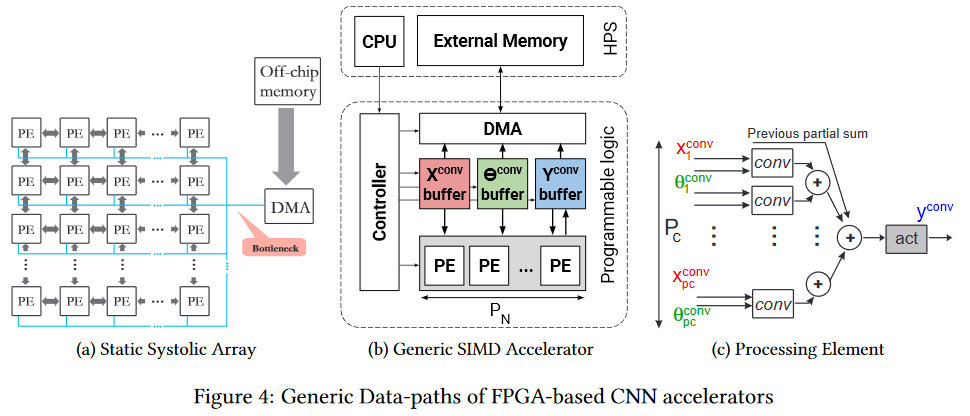
Naturalmente, faz sentido usar o FPGA já no estágio de uso de uma rede neural (na maioria dos casos, não há memória suficiente para o treinamento). Além disso, o tópico de execução no FPGA começou a se desenvolver ativamente. Por exemplo, aqui está a
estrutura fpgaConvNet , que pode acelerar significativamente o uso da CNN em FPGAs e reduzir o consumo de energia.
A principal vantagem do FPGA é que podemos armazenar a rede diretamente nas células, ou seja, um ponto fino na forma de centenas de megabytes dos mesmos dados sendo transferidos 25 vezes por segundo (para vídeo) na mesma direção desaparece magicamente. Isso permite uma velocidade de clock mais baixa e a ausência de caches, em vez de um desempenho menor, para obter um aumento perceptível. Sim, e reduza drasticamente
o consumo de energia do
aquecimento global por unidade de cálculo.
A Intel ingressou ativamente no processo, lançando o
OpenVINO Toolkit em código aberto no ano passado, que inclui o
Deep Learning Deployment Toolkit (parte do
OpenCV ). Além disso, o desempenho em FPGAs em diferentes redes parece bastante interessante, e a vantagem dos FPGAs em comparação com as GPUs (embora as GPUs integradas da Intel) sejam bastante significativas:
O que especialmente aquece a alma do autor - FPS são comparados, ou seja, quadros por segundo é a métrica mais prática para vídeo. Dado que a Intel comprou a
Altera , o segundo maior player do mercado de FPGA, em 2015, o gráfico fornece bons pensamentos.
E, obviamente, a barreira de entrada para essas arquiteturas é mais alta; portanto, é necessário algum tempo para que apareçam ferramentas convenientes que efetivamente levem em conta a arquitetura FPGA fundamentalmente diferente. Mas subestimar o potencial da tecnologia não vale a pena. Dolorosamente muitos lugares magros que ela rodeia.
Finalmente, enfatizamos que a
programação de FPGAs é uma arte separada. Como tal, o programa não é executado lá e todos os cálculos são feitos em termos de fluxos de dados, atrasos no fluxo (que afetam o desempenho) e portas usadas (que sempre faltam). Portanto, para iniciar a programação eficaz, você precisa
alterar completamente
seu próprio firmware (na rede neural que fica entre seus ouvidos). Com boa eficiência, isso não é obtido. No entanto, os novos quadros em breve esconderão a diferença externa dos pesquisadores.
Prós:- Execução de rede potencialmente mais rápida.
- Consumo de energia significativamente mais baixo comparado ao CPU e GPU (isso é especialmente importante para soluções móveis).
Contras:- Principalmente, eles ajudam a acelerar a execução; o treinamento neles, ao contrário da GPU, é visivelmente menos conveniente.
- Programação mais complexa em comparação com as opções anteriores.
- Notavelmente menos especialistas.
ASIC

Em seguida, é o
ASIC , que é a abreviação de Circuito Integrado Específico à Aplicação, circuito integrado para a nossa tarefa. Por exemplo, realizando uma rede neural colocada em ferro. No entanto, a maioria dos nós de computação pode trabalhar em paralelo. De fato, apenas dependências de dados e computação desigual em diferentes níveis da rede podem impedir que usemos constantemente todas as ALUs em funcionamento.
Talvez a mineração de criptomoedas tenha feito o maior anúncio do ASIC entre o público em geral nos últimos anos. No começo, a mineração na CPU era bastante lucrativa, depois tive que comprar uma GPU, depois FPGA e depois ASICs especializadas, pois as pessoas (leia - o mercado) amadureceram para pedidos nos quais sua produção se tornou lucrativa.
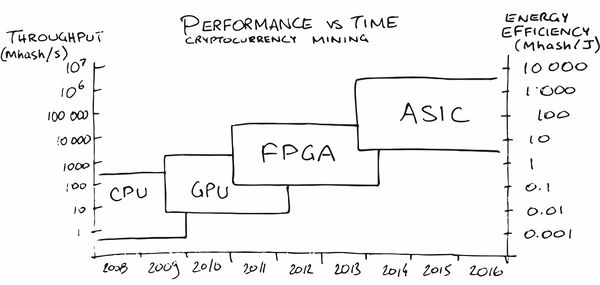
Em nossa área, os
serviços também já apareceram (naturalmente!),
Que ajudam a colocar uma rede neural no ferro com as características necessárias para o consumo de energia, FPS e preço. Magicamente, concordo!
MAS! Estamos perdendo a personalização da rede. E, claro, as pessoas também pensam nisso. Por exemplo, aqui está um artigo com o ditado, “
Uma arquitetura reconfigurável pode vencer o ASIC como um acelerador da CNN? ” (“Uma arquitetura configurável pode vencer o ASIC como um acelerador da CNN?”). Há trabalho suficiente sobre esse tópico, porque a pergunta não está ociosa. A principal desvantagem do ASIC é que, depois de direcionar a rede para o hardware, fica difícil alterá-la. Eles são mais benéficos para os casos em que já precisamos de uma rede que funcione bem, com milhões de chips com baixo consumo de energia e alto desempenho. E essa situação está se desenvolvendo gradualmente no mercado de carros de piloto automático, por exemplo. Ou em câmeras de vigilância. Ou nas câmaras dos aspiradores de pó robóticos. Ou nas câmaras de uma geladeira doméstica. Ou em uma câmara de cafeteira.
Ou na câmara de ferro. Bem, você entende a ideia, em
suma !
É importante que, na produção em massa, o chip seja barato, funcione rapidamente e consuma um mínimo de energia.
Prós:- O menor custo de chip comparado a todas as soluções anteriores.
- Menor consumo de energia por unidade de operação.
- Alta velocidade (incluindo, se desejado, um registro).
Contras:- Capacidade muito limitada de atualizar a rede e a lógica.
- Maior custo de desenvolvimento em comparação com todas as soluções anteriores.
- O uso do ASIC é econômico, principalmente para grandes tiragens.
TPU
Lembre-se de que, ao trabalhar com redes, há duas tarefas - treinamento e execução (inferência). Se os FPGA / ASICs estiverem focados principalmente em acelerar a execução (incluindo algum tipo de rede fixa), o TPU (Tensor Processing Unit ou processadores de tensores) é uma aceleração de aprendizado baseada em hardware ou uma aceleração relativamente universal de uma rede arbitrária. O nome é bonito, concordo, embora, de fato, ainda estejam sendo usados
tensores de classificação 2 com uma Unidade Multiplicada Mista (MXU) conectada à Memória de Alta Largura de Banda (HBM). Abaixo está o diagrama da arquitetura da versão 2 e 3 do TPU Google:
TPU Google
Em geral, o Google fez um anúncio para o nome TPU, revelando desenvolvimentos internos em 2017:
Eles começaram o trabalho preliminar em processadores especializados para redes neurais com suas palavras em 2006, em 2013 eles criaram um projeto com um bom financiamento e em 2015 começaram a trabalhar com os primeiros chips que ajudavam muito em redes neurais para o serviço em nuvem do Google Translate e muito mais. E isso foi, enfatizamos, a aceleração da rede. Uma vantagem importante para os datacenters é a eficiência energética de TPU de duas ordens de magnitude mais alta em comparação com as CPUs (gráfico para TPU v1):
Além disso, como regra geral, em comparação com a GPU, o
desempenho da rede é 10 a 30 vezes melhor para melhor:
A diferença é 10 vezes significativa. É claro que a diferença com a GPU em 20 a 30 vezes determina o desenvolvimento dessa direção.
E, felizmente, o Google não está sozinho.
TPU Huawei
Hoje, a sofredora Huawei também começou a desenvolver TPU há vários anos sob o nome Huawei Ascend, e em duas versões ao mesmo tempo - para data centers (como o Google) e para dispositivos móveis (que o Google também começou a fazer recentemente). Se você acredita nos materiais da Huawei, eles substituíram o novo Google TPU v3 por FP16 2,5 vezes e NVIDIA V100 2 vezes:

Como sempre, uma boa pergunta: como esse chip se comportará em tarefas reais. Pois no gráfico, como você pode ver, o desempenho máximo. Além disso, o Google TPU v3 é bom de várias maneiras, pois pode funcionar efetivamente em clusters de 1024 processadores. A Huawei também anunciou clusters de servidores para o Ascend 910, mas não há detalhes. Em geral, os engenheiros da Huawei mostraram-se extremamente competentes nos últimos 10 anos, e há todas as chances de que o desempenho de pico 2,8 vezes maior comparado ao Google TPU v3, juntamente com a mais recente tecnologia de processo de 7 nm, seja usado no caso.
A memória e o barramento de dados são críticos para o desempenho, e o slide mostra que uma atenção considerável foi dada a esses componentes (incluindo a velocidade de comunicação com a memória muito mais rapidamente que a da GPU):
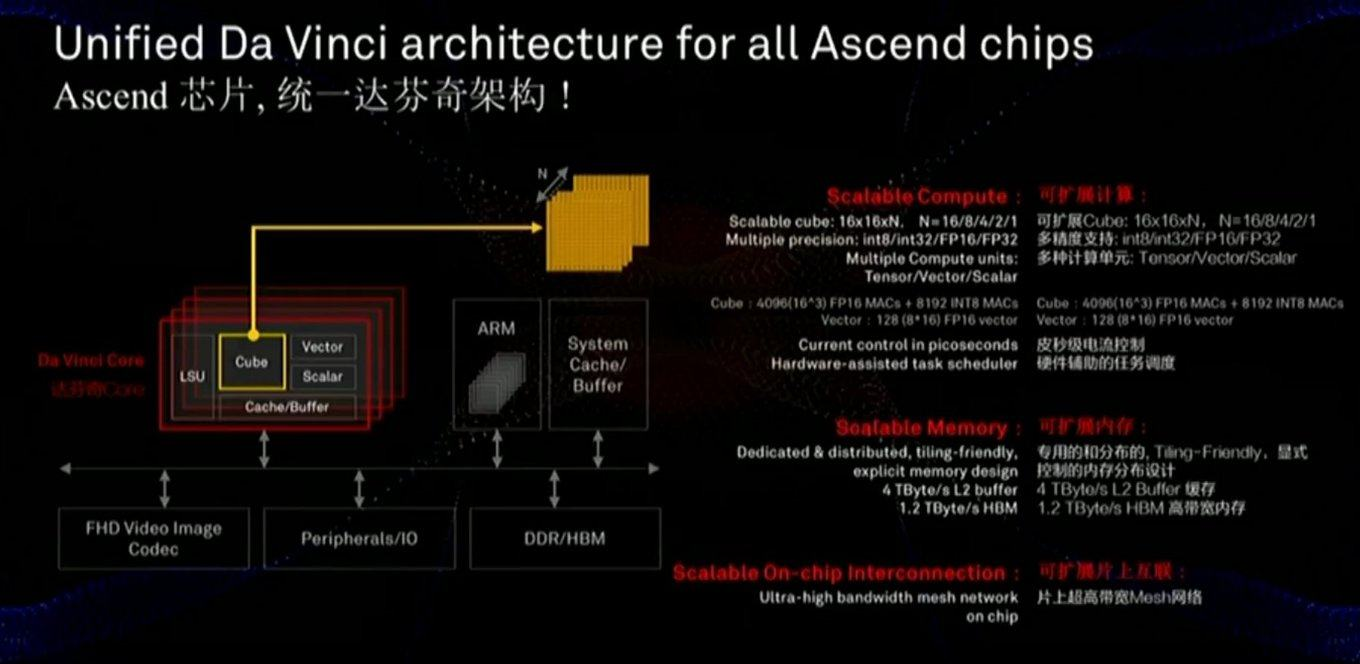
O chip também usa uma abordagem ligeiramente diferente - não as escalas bidimensionais do MXU 128x128, mas os cálculos em um cubo tridimensional de tamanho menor 16x16xN, onde N = {16.8,4,2,1}. Portanto, a questão principal é quão bem ela estará na aceleração real de redes específicas (por exemplo, cálculos em um cubo são convenientes para imagens). Além disso, um estudo cuidadoso do slide mostra que, diferentemente do Google, o chip incorpora imediatamente o trabalho com vídeo FullHD compactado. Para o autor, isso parece
muito encorajador!
Como mencionado acima, na mesma linha, os processadores são desenvolvidos para dispositivos móveis para os quais a eficiência energética é essencial e nos quais a rede será executada principalmente (ou seja, separadamente - processadores para aprendizado na nuvem e separadamente - para execução): E com esse parâmetro, tudo Parece bom em comparação com a NVIDIA, pelo menos (observe que eles não trouxeram uma comparação com o Google, no entanto, o Google não oferece TPUs na nuvem em mãos). E seus chips móveis competirão com processadores da Apple, Google e outras empresas, mas é muito cedo para fazer um balanço aqui.É claramente visto que os novos chips Nano, Tiny e Lite devem ser ainda melhores. Torna-se claro
E com esse parâmetro, tudo Parece bom em comparação com a NVIDIA, pelo menos (observe que eles não trouxeram uma comparação com o Google, no entanto, o Google não oferece TPUs na nuvem em mãos). E seus chips móveis competirão com processadores da Apple, Google e outras empresas, mas é muito cedo para fazer um balanço aqui.É claramente visto que os novos chips Nano, Tiny e Lite devem ser ainda melhores. Torna-se claro por que Trump estava com medo por que muitos fabricantes estão examinando cuidadosamente os sucessos da Huawei (que superaram todas as empresas de ferro dos EUA em receita, incluindo a Intel em 2018).Redes analógicas profundas
Como você sabe, a tecnologia geralmente se desenvolve em espiral, quando abordagens antigas e esquecidas se tornam relevantes em uma nova rodada.Algo semelhante poderia muito bem acontecer com redes neurais. Você deve ter ouvido falar que, uma vez que as operações de multiplicação e adição foram realizadas por tubos e transistores de elétrons (por exemplo, a conversão de espaços de cores - uma multiplicação típica de matrizes - ocorreu em todas as TVs coloridas até meados dos anos 90)? Uma boa pergunta surgiu: se nossa rede neural é relativamente resistente a cálculos imprecisos, e se convertermos esses cálculos em forma analógica? Temos imediatamente uma aceleração notável dos cálculos e uma redução potencialmente dramática no consumo de energia para uma operação:Com essa abordagem, o DNN (Deep Neural Network) é calculado rapidamente e com eficiência de energia. Mas há um problema - esses são conversores DAC / ADCs (DAC / ADC) - de digital para analógico e vice-versa, que reduzem a eficiência energética e a precisão do processo.No entanto, em 2017, a IBM Research propôs CMOS analógico para RPUs ( Unidades de Processamento Resistivo ), que permitem armazenar dados processados também na forma analógica e aumentar significativamente a eficiência geral da abordagem:, — RPU, , . IBM , 2- ( ), 100 (!) GPU:
, :
No entanto, a direção potencial da computação analógica parece
extremamente interessante.
A única coisa que confunde é que é a IBM,
que já registrou dezenas de patentes sobre o assunto . Segundo a experiência, devido às peculiaridades da cultura corporativa, elas cooperam relativamente fracamente com outras empresas e, possuindo alguma tecnologia, têm mais probabilidade de desacelerar seu desenvolvimento entre outras do que compartilhá-lo efetivamente. Por exemplo, a IBM se recusou a licenciar a compressão aritmética para JPEG ao comitê
ISO , apesar do fato de o rascunho do padrão ser uma opção com compressão aritmética. Como resultado, o JPEG ganhou vida com a compressão de Huffman e ficou 10 a 15% pior do que poderia. A mesma situação ocorreu com os padrões de compactação de vídeo. E a indústria mudou massivamente para a compressão aritmética nos codecs somente quando cinco patentes da IBM expiraram 12 anos depois ... Esperamos que a IBM esteja mais inclinada a cooperar dessa vez e, consequentemente,
desejamos o máximo sucesso no campo para todos que não estiverem associados à IBM , o benefício de
tais pessoas e empresas é muito .
Se funcionar,
será uma revolução no uso de redes neurais e uma revolução em muitas áreas da ciência da computação.Outras letras diversas
Em geral, o tópico de acelerar redes neurais se tornou moda, todas as principais empresas e dezenas de startups estão envolvidas nele, e
pelo menos cinco delas atraíram mais de US $ 100 milhões em investimentos até o início de 2018. No total, em 2017, US $ 1,5 bilhão foram investidos em startups relacionadas ao desenvolvimento de chips. Apesar do fato de os investidores não perceberem os fabricantes de chips há 15 anos (porque não havia nada para pegar lá no contexto de gigantes). Em geral - agora há uma chance real de uma pequena revolução do ferro. Além disso, é extremamente difícil prever qual arquitetura vencerá, a necessidade de revolução amadureceu e as possibilidades de aumentar a produtividade são grandes. A situação revolucionária clássica amadureceu:
Moore não pode mais e
Dean ainda não está pronto.
Bem, como a lei de mercado mais importante - seja diferente, há muitas novas cartas, por exemplo:
- Unidade de processamento neural ( NPU ) - Um neuroprocessador, às vezes lindamente - um chip neuromórfico - em geral, o nome geral de um acelerador de redes neurais, chamadas chips Samsung , Huawei e mais adiante na lista ...
A seguir, nesta seção, serão apresentados principalmente slides de apresentações corporativas como exemplos de nomes próprios de tecnologia
É claro que uma comparação direta é problemática, mas aqui estão alguns dados interessantes que comparam chips com neuroprocessadores da Apple e Huawei, produzidos pela TSMC mencionados no início. Pode-se observar que a concorrência é dura, a nova geração mostra um aumento de produtividade de 2 a 8 vezes e a complexidade dos processos tecnológicos:
- Processador de rede neural (NNP) - processador de rede neural.
Esse é o nome de sua família de chips, por exemplo, Intel (originalmente era a empresa Nervana Systems , que a Intel comprou em 2016 por US $ 400 milhões). No entanto, em artigos e livros, o nome NNP também é bastante comum.
- Unidade de Processamento de Inteligência (IPU) - um processador inteligente - o nome dos chips promovidos pela Graphcore (a propósito, que já recebeu um investimento de US $ 310 milhões).
Produz placas especiais para computadores, mas voltadas para o treinamento de redes neurais, com um desempenho de treinamento da RNN 180 a 240 vezes maior do que o da NVIDIA P100.
- Unidade de Processamento de Fluxo de Dados (DPU) - processador de processamento de dados - o nome é promovido pela WAVE Computing , que já recebeu um investimento de US $ 203 milhões. Produz os mesmos aceleradores do Graphcore:
Como eles receberam 100 milhões a menos, eles declaram o treinamento apenas 25 vezes mais rápido que na GPU (embora prometam que serão 1000 vezes em breve). Vamos ver ...
- Unidade de Processamento de Visão ( VPU ) - Computer Vision Processor:
O termo é usado em produtos de várias empresas, por exemplo, Myriad X VPU da Movidius (também comprado pela Intel em 2016).
- Um dos concorrentes da IBM (que, lembramos, usa o termo RPU ) - Mythic - está movendo o DNN analógico , que também armazena a rede no chip e uma execução relativamente rápida. Até agora, eles têm apenas promessas, embora sérias :
E isso lista apenas as maiores áreas no desenvolvimento das quais centenas de milhões foram investidas (isso é importante no desenvolvimento do ferro).
Em geral, como vemos, todas as flores florescem rapidamente. Gradualmente, as empresas digerem bilhões de dólares em investimentos (geralmente leva de 1,5 a 3 anos para produzir chips), a poeira se acalma, o líder fica claro, os vencedores, como sempre, escrevem uma história e o nome da tecnologia de maior sucesso no mercado será geralmente aceito. Isso já aconteceu mais de uma vez ("IBM PC", "Smartphone", "Xerox" etc.).
Algumas palavras sobre a comparação correta
Como já mencionado acima, comparar corretamente o desempenho de redes neurais não é fácil. É exatamente por isso que o Google publica um gráfico no qual o TPU v1 produz a NVIDIA V100. A NVIDIA, vendo essa desgraça, publica uma programação em que o Google TPU v1 perde o V100. (Então!) O Google publica o gráfico a seguir, onde o V100 perde no Google TPU v2 e v3. E, finalmente, a Huawei é o cronograma em que todos perdem no Huawei Ascend, mas o V100 é melhor que o TPU v3. Circo, em suma. O que é característico -
cada gráfico
tem sua própria verdade!
As causas da situação são claras:
- Você pode medir a velocidade de aprendizado ou a velocidade de execução (o que for mais conveniente).
- É possível medir diferentes redes neurais, porque a velocidade de execução / treinamento de diferentes redes neurais em arquiteturas específicas pode diferir significativamente devido à arquitetura da rede e à quantidade de dados necessários.
- E você pode medir o desempenho máximo do acelerador (talvez o mais abstrato de todos os itens acima).
Como uma tentativa de colocar as coisas em ordem neste zoológico,
apareceu o teste
MLPerf , que agora tem a versão 0.5 disponível, ou seja, ele está no processo de desenvolver uma metodologia de comparação, que está prevista para ser lançada no primeiro lançamento no
terceiro trimestre deste ano :
Como os autores são um dos principais contribuidores do TensorFlow, há todas as chances de descobrir qual é a melhor maneira de treinar e possivelmente usá-lo (porque a versão móvel do TF provavelmente também será incluída neste teste ao longo do tempo).
Recentemente, a organização internacional
IEEE , que publica a terceira parte da literatura técnica mundial em rádio eletrônica, computadores e engenharia elétrica,
baniu a Huawei do rosto de uma criança e logo, no entanto,
cancelou a proibição. A Huawei ainda não está no ranking
atual da MLPerf, enquanto a Huawei TPU é uma concorrente séria dos cartões Google TPUs e NVIDIA (ou seja, além dos políticos, há razões econômicas para ignorar a Huawei, francamente). Com interesse indiscutível, acompanharemos o desenvolvimento de eventos!
Tudo para o céu! Mais perto das nuvens!
E, como se tratava de treinamento, vale a pena dizer algumas palavras sobre seus detalhes:
- Com a partida generalizada da pesquisa em redes neurais profundas (com dezenas e centenas de camadas que realmente impressionam a todos), foi necessário moer centenas de megabytes de coeficientes, o que imediatamente tornou ineficazes todos os caches de processadores das gerações anteriores. Ao mesmo tempo, o ImageNet clássico discute uma correlação estrita entre o tamanho da rede e sua precisão (quanto maior, melhor, direita, maior a rede, o eixo horizontal é logarítmico):
- O processo de cálculo dentro da rede neural segue um esquema fixo, ou seja, onde todas as “ramificações” e “transições” (em termos do século passado) ocorrerão na grande maioria dos casos, é precisamente conhecido com antecedência, o que deixa a execução especulativa das instruções sem trabalho, o que anteriormente aumenta significativamente a produtividade:
Isso torna ineficazes os mecanismos de previsão superescalares para ramificações e pré-cálculos das décadas anteriores de aprimoramento do processador (essa parte do chip, infelizmente, também contribui para o aquecimento global, como o DNN no cache do DNN).
- Além disso, o treinamento da rede neural é relativamente pouco dimensionado horizontalmente . I.e. não podemos pegar 1000 computadores poderosos e aprender a acelerar a aceleração 1000 vezes. E mesmo com 100, não podemos (pelo menos até que o problema teórico da deterioração da qualidade do treinamento em um grande tamanho do lote seja resolvido). Em geral, é bastante difícil para nós distribuir algo em vários computadores, porque assim que a velocidade de acesso à memória unificada na qual a rede se encontra diminui, a velocidade de seu aprendizado cai catastroficamente. Portanto, se um pesquisador tiver acesso a 1000 computadores poderosos
de graça , ele certamente os pegará em breve, mas provavelmente (se não houver infinita de banda + RDMA), haverá muitas redes neurais com diferentes hiperparâmetros. I.e. o tempo total de treinamento será apenas várias vezes menor do que com 1 computador. Lá é possível brincar com os tamanhos do lote, a educação continuada e outras novas tecnologias da moda, mas a principal conclusão é sim, com um aumento no número de computadores, a eficiência do trabalho e a probabilidade de alcançar um resultado aumentarão, mas não linearmente. Hoje, o tempo de um pesquisador de ciência de dados é caro e, muitas vezes, se você pode gastar muitos carros (embora não razoável), mas obtém aceleração - isso é feito (veja o exemplo com 1, 2 e 4 V100s caros nas nuvens logo abaixo).
Exatamente esses pontos explicam por que tantas pessoas correram para o desenvolvimento de ferro especializado para redes neurais profundas. E por que eles conseguiram bilhões? Realmente há luz visível no fim do túnel e não apenas o Graphcore (que, lembre-se, 240 vezes o treinamento da RNN acelerou).
Por exemplo, os senhores da IBM Research
estão otimistas quanto ao desenvolvimento de chips especiais que aumentarão a eficiência dos cálculos em uma ordem de grandeza após 5 anos (e após 10 anos em 2 ordens de grandeza, atingindo um aumento de 1000 vezes em comparação com o nível de 2016 neste gráfico, embora , em eficiência por watt, mas a potência principal também aumentará):
Tudo isso significa a aparência de pedaços de ferro, cujo treinamento será relativamente rápido, mas caro, o que naturalmente leva à idéia de compartilhar o tempo de uso desse caro pedaço de ferro entre os pesquisadores. E essa idéia hoje não menos naturalmente nos leva à computação em nuvem. E a transição do aprendizado para as nuvens tem sido ativamente ativa.
Observe que agora o treinamento dos mesmos modelos pode diferir no tempo por uma ordem de magnitude de diferentes serviços em nuvem. A Amazon lidera e o Colab gratuito do Google vem por último. Observe como o resultado do número de V100 muda entre os líderes - um aumento no número de cartões em 4 vezes (!) Aumenta a produtividade em menos de um terço (!!!) de azul para roxo, e o Google tem ainda menos:
Parece que nos próximos anos a diferença crescerá para duas ordens de magnitude. Senhor! Cozinhando dinheiro! Devolveremos amigavelmente investimentos de bilhões de dólares aos investidores mais bem-sucedidos ...
Em suma
Vamos tentar resumir os pontos principais do tablet:
Algumas palavras sobre aceleração de software
Para ser justo, mencionamos que hoje o grande tópico é a aceleração por software da execução e treinamento de redes neurais profundas. A execução pode ser significativamente acelerada principalmente devido à chamada quantização da rede. Talvez isso seja, primeiro, uma vez que o intervalo de pesos usado não é tão grande e geralmente é possível aumentar pesos de um valor de ponto flutuante de 4 bytes para um número inteiro de 1 byte (e, lembrando os sucessos da IBM, ainda mais fortes). Em segundo lugar, a rede treinada como um todo é bastante resistente ao ruído computacional e a precisão da transição para o
int8 cai um pouco. Ao mesmo tempo, apesar do número de operações poder aumentar (devido ao dimensionamento no cálculo), o fato de a rede ter um tamanho reduzido em 4 vezes e poder ser considerado operações vetoriais rápidas aumenta significativamente a velocidade geral de execução. Isso é especialmente importante para aplicativos móveis, mas também funciona nas nuvens (um exemplo de execução acelerada nas nuvens da Amazon):
Existem outras maneiras de
acelerar algoritmicamente
a execução da rede e ainda mais maneiras de
acelerar o aprendizado . No entanto, esses são grandes tópicos separados sobre os quais não desta vez.
Em vez de uma conclusão
Em suas palestras, o investidor e autor
Tony Ceba dá um exemplo magnífico: em 2000, o supercomputador nº 1, com capacidade de 1 teraflops, ocupou 150 metros quadrados, custou US $ 46 milhões e consumiu 850 kW:
15 anos depois, a GPU NVIDIA com um desempenho de 2,3 teraflops (2 vezes mais) cabia em uma mão, custava US $ 59 (uma melhoria de cerca de um milhão de vezes) e consumia 15 watts (uma melhoria de 56 mil vezes):
Em março deste ano, o
Google lançou os TPU Pods , que na verdade são supercomputadores de refrigeração líquida baseados no TPU v3, cuja principal característica é que eles podem trabalhar juntos em sistemas de 1024 TPU. Eles parecem bastante impressionantes:
Os dados exatos não são fornecidos, mas diz-se que o sistema é comparável aos 5 maiores supercomputadores do mundo. O TPU Pod pode aumentar drasticamente a velocidade de aprendizado de redes neurais. Para aumentar a velocidade de interação, as TPUs são conectadas por linhas de alta velocidade a uma estrutura toroidal:

Parece que, após 15 anos, esse neuroprocessador duas vezes mais poderoso também poderá caber na sua mão, como o
processador Skynet (você
deve admitir, é algo semelhante):
Filmado a partir da versão diretorial do filme "Terminator 2"Dada a atual taxa de aprimoramento dos aceleradores de hardware de redes neurais profundas e o exemplo acima, isso é completamente real. Em alguns anos, há uma chance de adquirir um chip com um desempenho como o TPU Pod de hoje.
A propósito, é engraçado que, no filme, os fabricantes de chips (aparentemente imaginando para onde a rede de auto-treinamento levaria) desativassem a reciclagem por padrão. Caracteristicamente, o próprio
T-800 não pôde ativar o modo de treinamento e trabalhou no modo de inferência (consulte a
versão mais longa do
diretório ). Além disso, seu
processador de rede neural era avançado e, ao ativar a reciclagem, poderia usar os dados acumulados anteriormente para atualizar o modelo. Nada mal para 1991.
Este texto foi iniciado no quente 13 milhões de Shenzhen. Sentei-me em um dos 27.000 táxis elétricos da cidade e olhei para as quatro telas de cristal líquido do carro com grande interesse. Um pequeno - entre os dispositivos na frente do motorista, dois - no centro do painel e o último - translúcido - no espelho retrovisor, combinado com um DVR, uma câmera de vigilância por vídeo e um androide a bordo (a julgar pela linha superior com o nível de carga e comunicação com a rede). Ele exibia dados do motorista (a quem reclamar, se isso), uma nova previsão do tempo e parecia haver uma conexão com a frota de táxis. O motorista não sabia inglês e não conseguiu perguntar sobre suas impressões sobre a máquina elétrica. Portanto, ele preguiçosamente pressionou o pedal, movendo levemente o carro em um engarrafamento. E eu observei a janela com um olhar futurista com interesse - os chineses em suas jaquetas estavam dirigindo do trabalho em scooters elétricos e monowheels ... e me perguntei como ficaria em 15 anos ...
Atualmente, atualmente, o espelho retrovisor, usando os dados da câmera do DVR e a
aceleração de hardware das redes neurais , é capaz de controlar o carro no trânsito e traçar o caminho. À tarde, pelo menos). Após 15 anos, o sistema claramente não apenas poderá dirigir um carro, mas também terá o prazer de me fornecer as características dos veículos elétricos chineses frescos. Em russo, naturalmente (como uma opção: inglês, chinês ... albanês, finalmente). O motorista aqui é supérfluo, mal treinado, um link.
Senhor!
EXTREMAMENTE INTERESSANTE 15 anos estão esperando por nós!
Fique atento!
Eu voltarei! )))
 UPD:
UPD: Os comentários mais interessantes:
Sobre quantização e aceleração de cálculos no FPGA
Comentários @Mirn
No FPGA, não apenas a aritmética de precisão arbitrária está disponível, mas também uma importante capacidade de salvar e processar dados de bits arbitrários. Por exemplo, há muitos coeficientes nos irritantes MobileNetV2 W e B e você pode quantificá-los sem muita perda de precisão para apenas 16 bits ou terá que treinar novamente. Mas se você olhar para dentro e coletar estatísticas sobre canais e camadas, poderá ver que todos os 16 bits são usados apenas na entrada dos primeiros coeficientes de 1000 W, o restante possui 8-11 bits, dos quais apenas 2-3 e sinais mais significativos são realmente importantes, e estatísticas sobre o uso de canais, de modo que existam muitos canais em que geralmente zeros ou valores pequenos ou canais em que quase todos os valores são de 8 a 11 bits, ou seja, é possível pregar o expositor nas unhas em tempo de compilação e não armazenar, ou seja, na verdade, é possível armazenar na memória ROM valores não de 16 bits, mas de 4 bits, e você pode até armazenar toda a rede neural em FPGAs baratos sem muita perda de precisão (menos de 1%) e também processar em velocidades de até dezenas de milhares de FPS com latência, para obter uma resposta de rede neural imediatamente Como termina a recepção do quadro.
Sobre quantização: minha ideia é que, em vários estágios da computação W, os coeficientes do canal n ° 0 mudam apenas de +50 para -50, faz sentido comprimir a bit para 7, e se de -123 para +124, por exemplo, para 8 (incluindo o sinal ) FPGA , 7, 8 ROM . , .
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! porque dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
GPU, FPGA, ASIC
@BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
FPGA, FPGA Microsoft
@Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . I.e. - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
FPGA ASIC
@Mirn
Eu acho que o FPGA é uma medida necessária:
eles combinam com sucesso o baixo custo relativo, a velocidade computacional e a velocidade de prototipagem e modificação em comparação com os ASICs.
Por exemplo:
FPGA
É necessário organizar a aceleração do cálculo (mas não o treinamento), vários trabalhos são necessários (um conjunto de uma licença de quartus, licença de modelo, licenças principais de IP e cascas de terceiros custam de 30 a 50 mil dólares há cerca de 5 anos quando eu as comprei).
você precisa comprar cartões, pelo menos intermediários como Arriya10 em termos de número de empregos mais um (se queimarem e não esperarem), isso é 5kbaks * * (N + 1)
Bem, salários, escritório, contabilidade e outras despesas - aproximadamente 10 mil dólares por mês para um desenvolvedor, eles obviamente não funcionarão por alguns meses, mas alguns anos, isso é 120 mil * N
Durante esse período, você pode fazer uma dúzia de versões (fazer o primeiro sucesso em um ano e depois fazer correções todo mês e meio)
Total para o ano: (120 + 50 + 5) * N, para 5 pessoas, são 880 t de dólares
muito, mas você pode encontrar quem quiser pagar tente sem garantias
ASIC
Aqui eu não sou especialista, mas parece-me que o software custará muito mais (otimista assumirei que 2 vezes)
O pedido de chips custará na faixa de um milhão de dólares por iteração
uma iteração do verílogo para o ferro levará várias vezes mais (3-4 meses)
no ASIC, você não pode lançar uma rede altamente especializada com bits e arquitetura "acertados", não faz sentido fazê-lo - significa que a estrutura se tornará mais complicada: deve ser moderadamente universal, é muitas vezes mais complicada
precisamos de negociadores, grande capital financeiro e um nome (antes de tudo, a fábrica entrará na carteira e, se você ignorar tudo), gerentes e outros engenheiros também são necessários - um chip é necessário para o chip e, de preferência, um caso de refrigeração, esse é um nível muito trivial de circuitos e tecnologia.
observe aqui: que na mesma mineração, as placas são especialmente primitivas - elas tentaram empurrar todos dentro do chip, incluindo comutadores de reguladores de tensão, drivers de corrente para interfaces, etc., etc.
E, novamente, não são necessários desenvolvedores simples de verílogos, mas com conhecimento do analógico e conhecimento da física de semicondutores e tecnologias (eu o estudei superficialmente no MiT - é MUITO COMPLEXO, é apenas o espaço e a vanguarda de uma liga de ciência e tecnologia, tão dura sem smoothies, unicórnios e pregadores marketing de inicialização, engenharia limpa e ciência)
É difícil calcular o total para o ASIC, mas são claramente dezenas de milhões de dólares, a equipe é 10 vezes mais para as pessoas e o momento da primeira versão de um buggy, mas de alguma forma trabalhando por 3-5 anos, com um risco muito alto de falha (e social - faça a equipe trabalhar, manter e trazer para a linha de chegada, e técnico não é um fato que a arquitetura planejada irá disparar e os negócios não são um fato que todos os contratados não irão falhar) e as chances de fazer várias tentativas diferentes com arquitetura diferente são pequenas, mais precisamente uma tentativa: ninguém vai refazer do zero.
Este é um caso de mega corporação! já! desenvolvimentos e pessoas disponíveis. por exemplo, NEC e SONY (trabalhei com eles e as Olimpíadas em biônica, conheço os termos reais de 10 a 15 anos para uma primeira iteração do zero, não é segredo)
Resumidamente: FPGA é uma maneira de acelerar e reduzir o custo de desenvolvimento em dezenas e centenas de vezes em relação ao ASIC.
AgradecimentosGostaria de agradecer cordialmente:
- Laboratório de Computação Gráfica VMK Moscow State University MV Lomonosov por sua contribuição ao desenvolvimento de computação gráfica na Rússia e não apenas
- nossos colegas Mikhail Erofeev e Nikita Bagrov, cujos exemplos são usados acima,
- pessoalmente Konstantin Kozhemyakov, que fez muito para tornar este artigo melhor e mais visual,
- e, finalmente, muito obrigado a Alexander Bokov, Mikhail Erofeev, Vitaly Ludvichenko, Roman Kazantsev, Nikita Bagrov, Ivan Molodetsky, Yegor Sklyarov, Alexei Solovyov, Evgeny Lyapustin, Sergey Lavrushkin e Nikolai Oplachko por muitos comentários e correções úteis que fizeram este texto melhor!