Lembre-se de que o Elastic Stack é baseado no banco de dados não relacional do Elasticsearch, na interface da web do Kibana e nos coletores de dados (o mais famoso Logstash, vários Beats, APM e outros). Uma das boas adições a toda a pilha de produtos listados é a análise de dados usando algoritmos de aprendizado de máquina. No artigo, entendemos quais são esses algoritmos. Pedimos gato.
O aprendizado de máquina é um recurso pago do shareware Elastic Stack e faz parte do X-Pack. Para começar a usá-lo, é suficiente após a ativação para ativar a avaliação de 30 dias. Após o término do período de avaliação, você pode solicitar suporte para sua extensão ou comprar uma assinatura. O custo da assinatura é calculado não a partir da quantidade de dados, mas a partir do número de nós usados. Não, a quantidade de dados afeta, é claro, o número de nós necessários, mas ainda assim essa abordagem de licenciamento é mais humana em relação ao orçamento da empresa. Se não houver necessidade de alto desempenho - você pode salvar.
O ML no Elastic Stack é escrito em C ++ e funciona fora da JVM, que executa o próprio Elasticsearch. Ou seja, o processo (que, a propósito, é chamado de detecção automática) consome tudo o que a JVM não engole. No estande de demonstração, isso não é tão crítico, mas em um ambiente produtivo, é importante destacar nós separados para tarefas de ML.
Os algoritmos de aprendizado de máquina são divididos em duas categorias -
com e
sem professor . No Elastic Stack, o algoritmo é da categoria "sem professor".
Este link permite ver o aparato matemático dos algoritmos de aprendizado de máquina.
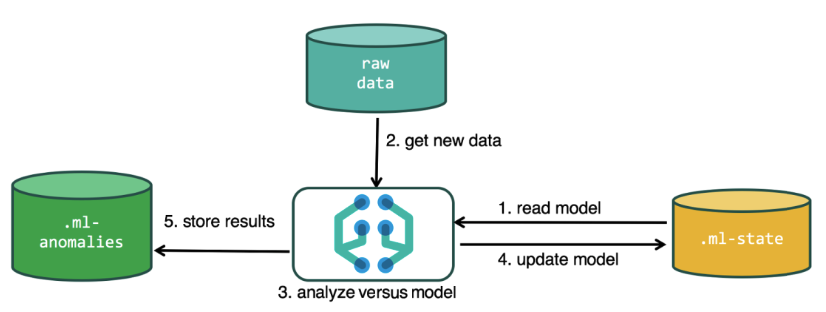
Para executar a análise, o algoritmo de aprendizado de máquina usa os dados armazenados nos índices do Elasticsearch. Você pode criar tarefas para análise na interface do Kibana e através da API. Se você fizer isso através do Kibana, algumas coisas não serão necessárias. Por exemplo, índices adicionais que o algoritmo usa no processo.
Índices adicionais usados no processo de análise.ml-state - informações sobre modelos estatísticos (configurações de análise);
.ml-anomalies- * - resultados do trabalho de algoritmos de ML;
.ml-Notifications - configurações de notificação com base nos resultados da análise.
A estrutura de dados no banco de dados Elasticsearch consiste em índices e documentos armazenados neles. Se comparado com um banco de dados relacional, o índice poderá ser comparado com o esquema do banco de dados e com um documento com uma entrada na tabela. Essa comparação é condicional e é fornecida para simplificar o entendimento de mais material para aqueles que ouviram apenas sobre o Elasticsearch.
A mesma funcionalidade está disponível através da API e através da interface da Web; portanto, para maior clareza e entendimento dos conceitos, mostraremos como configurar através do Kibana. Há uma seção de aprendizado de máquina no menu à esquerda, onde você pode criar um novo trabalho. Na interface do Kibana, ela se parece com a imagem abaixo. Agora, analisaremos cada tipo de tarefa e mostraremos os tipos de análise que podem ser construídos aqui.
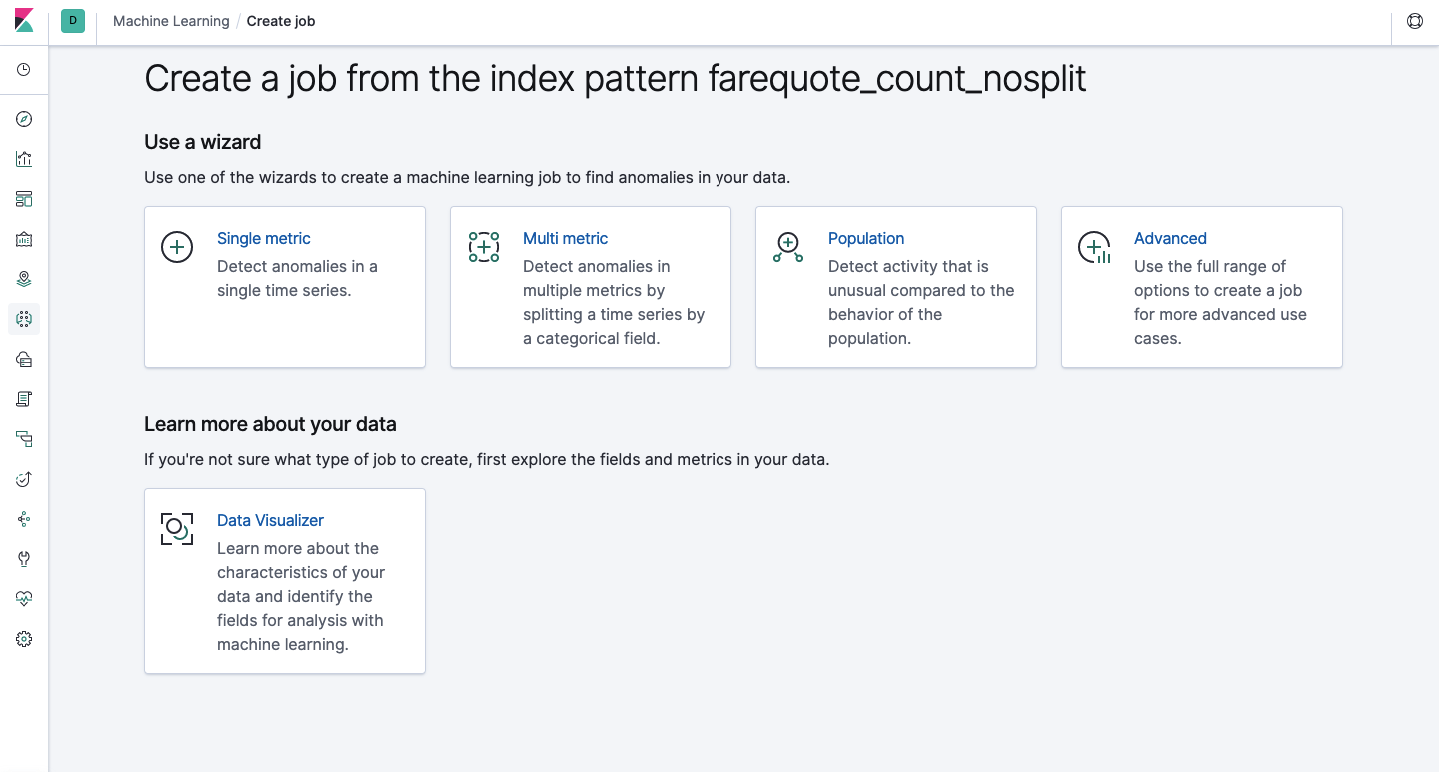
Métrica única - análise de uma métrica; Métrica múltipla - análise de duas ou mais métricas. Em ambos os casos, cada métrica é analisada em um ambiente isolado, ou seja, o algoritmo não leva em consideração o comportamento das métricas analisadas em paralelo, como pode parecer no caso da Multi Metric. Para realizar o cálculo levando em consideração a correlação de várias métricas, você pode aplicar a análise de população. E Advanced é um ajuste fino de algoritmos com opções adicionais para determinadas tarefas.
Métrica única
A análise de alterações em uma única métrica é a coisa mais simples que você pode fazer aqui. Depois de clicar em Criar trabalho, o algoritmo procurará anomalias.
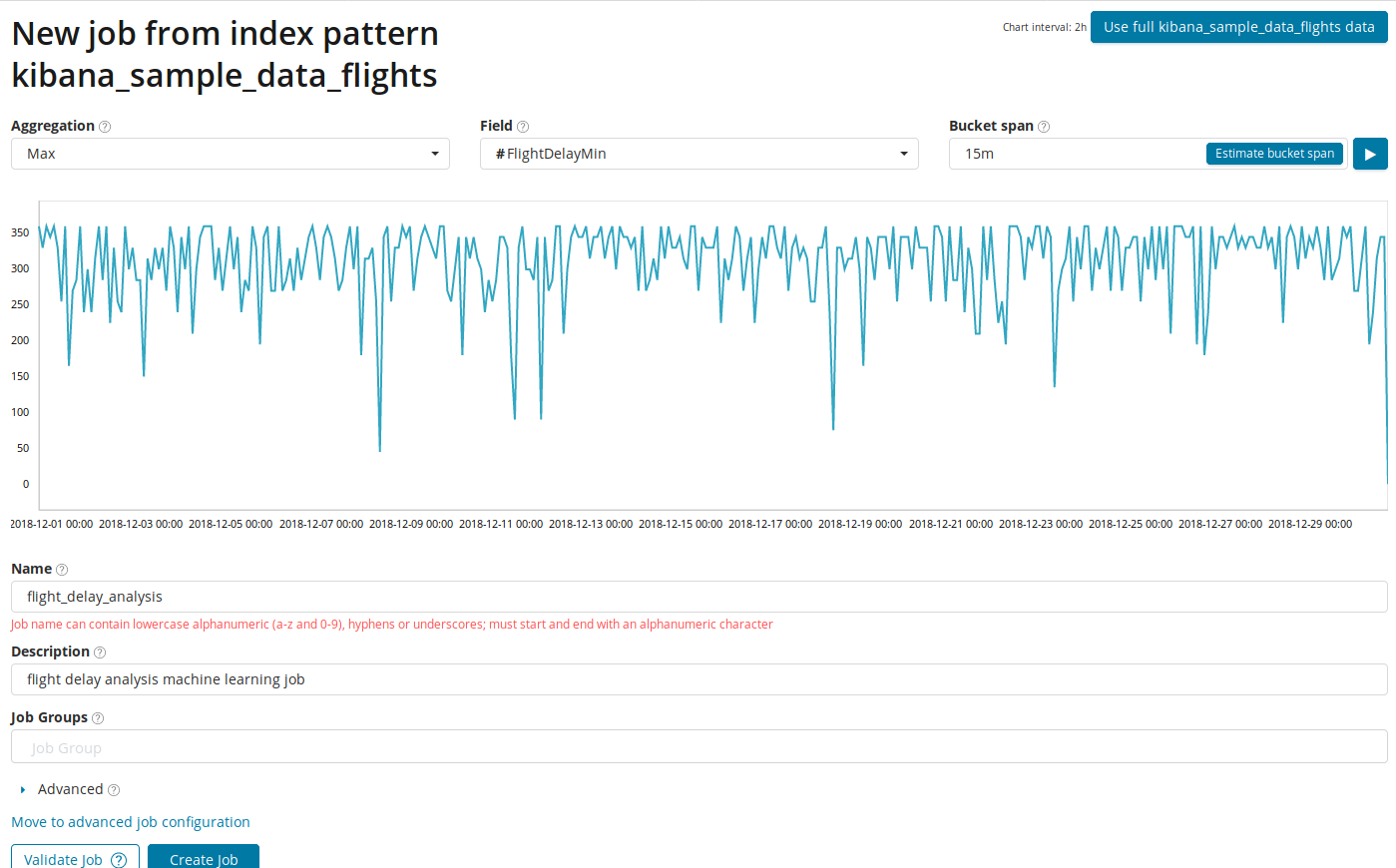
No campo
Agregação , você pode escolher uma abordagem para procurar anomalias. Por exemplo, com
Min, os valores anormais serão considerados mais baixos que o típico. Existem
Max, Hign Mean, Low, Mean, Distinct e outros. A descrição de todas as funções pode ser encontrada
aqui .
O campo Campo indica o campo numérico no documento pelo qual iremos analisar.
No campo Intervalo de intervalo, a granularidade dos intervalos na linha do tempo sobre a qual a análise será realizada. Você pode confiar na automação ou escolher manualmente. A imagem abaixo mostra um exemplo de granularidade muito baixo - você pode pular a anomalia. Usando essa configuração, você pode alterar a sensibilidade do algoritmo para anomalias.

A duração dos dados coletados é uma coisa importante que afeta a eficácia da análise. Na análise, o algoritmo determina os intervalos de repetição, calcula o intervalo de confiança (linhas de base) e identifica anomalias - desvios atípicos do comportamento usual da métrica. Apenas por exemplo:
Linhas de base com um pequeno período de dados:
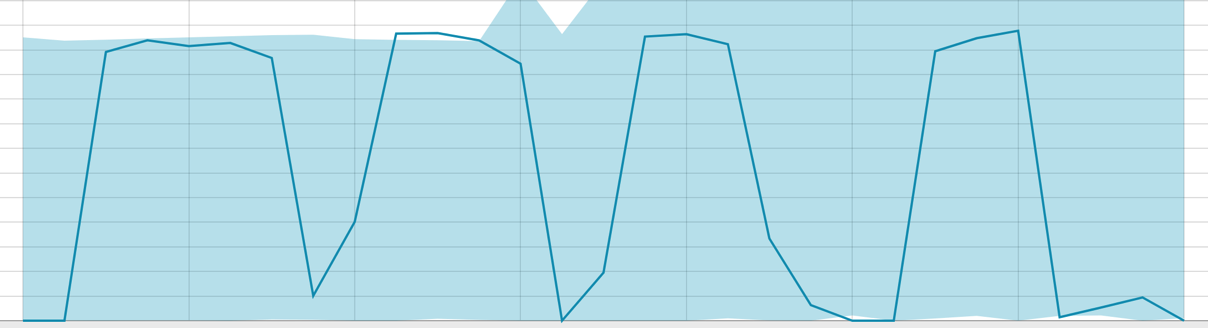
Quando o algoritmo tem algo a aprender, a linha de base fica assim:
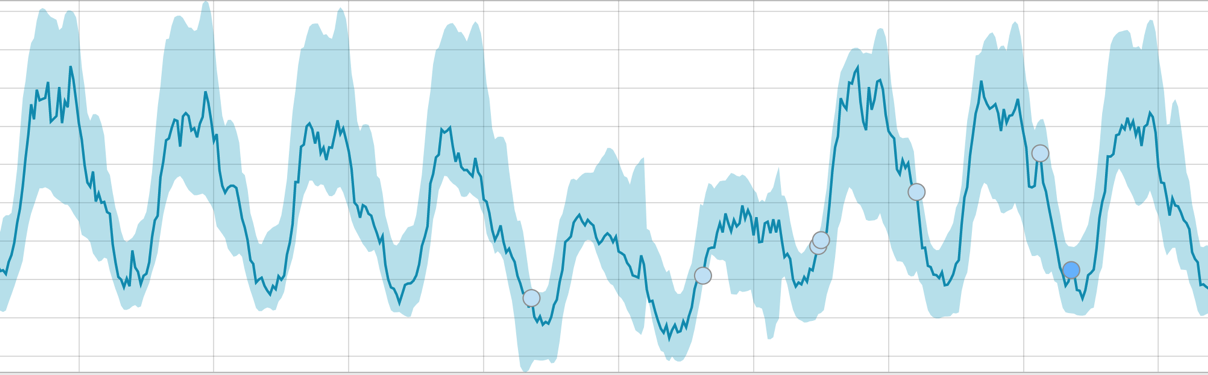
Após o início da tarefa, o algoritmo determina os desvios anômalos da norma e os classifica pela probabilidade da anomalia (a cor do rótulo correspondente é indicada entre colchetes):
Aviso (ciano): menos de 25
Menor (amarelo): 25-50
Principal (laranja): 50-75
Crítico (vermelho): 75-100
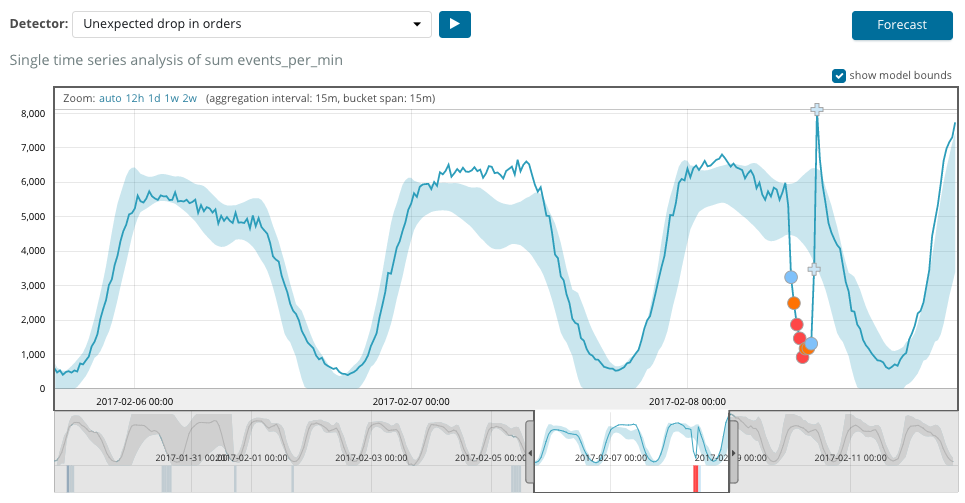
O gráfico abaixo mostra um exemplo de anomalia encontrada.
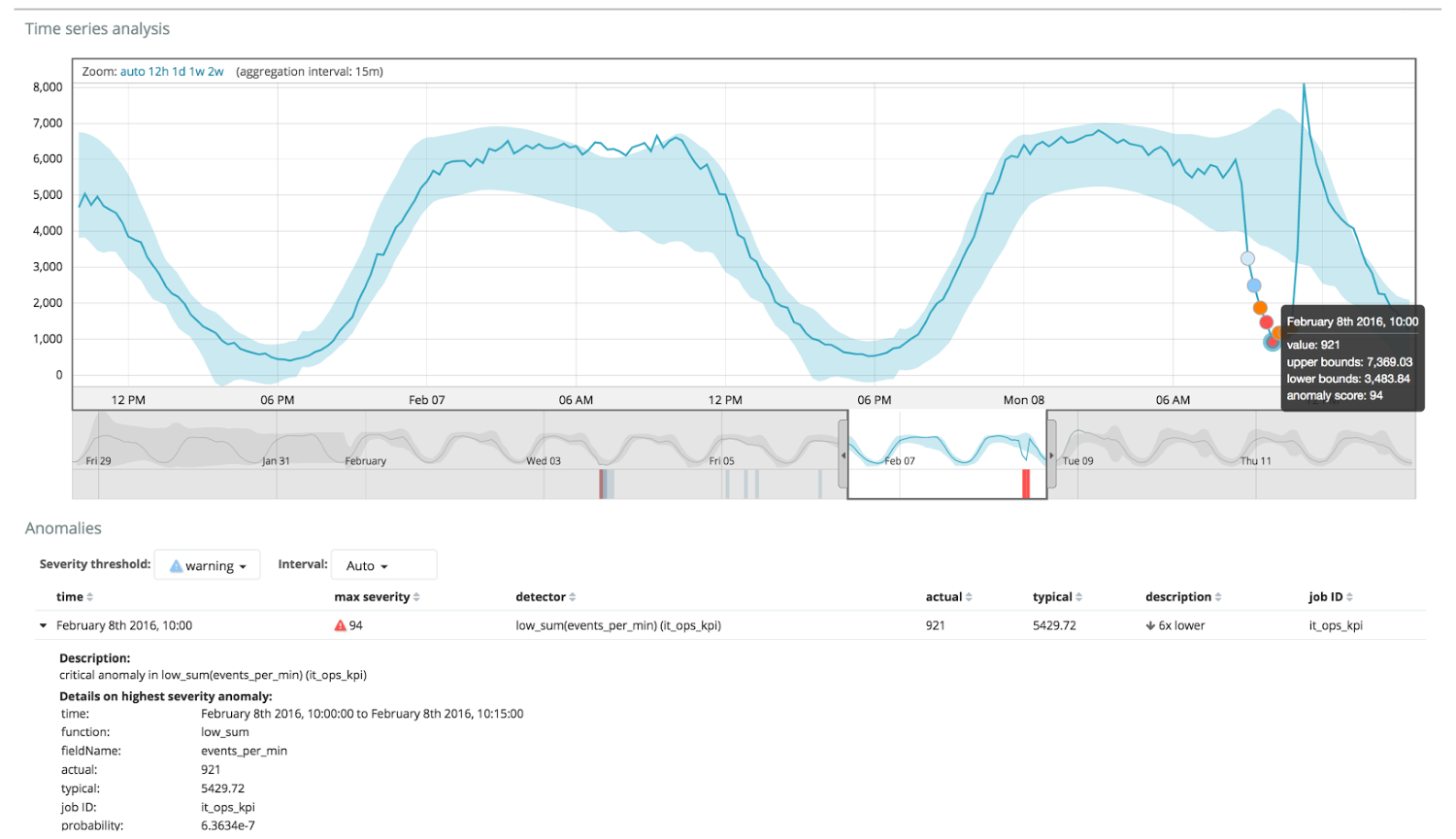
Aqui você pode ver o número 94, que indica a probabilidade de uma anomalia. É claro que, como o valor está próximo de 100, isso significa uma anomalia. A coluna abaixo do gráfico mostra uma probabilidade depreciativa de 0,000063634% da aparência do valor da métrica.
Além de procurar anomalias no Kibana, você pode executar a previsão. Isso é feito de maneira elementar e da mesma visualização com anomalias - o botão
Previsão no canto superior direito.

A previsão é baseada em um máximo de 8 semanas de antecedência. Mesmo se você realmente quiser, não poderá mais por design.
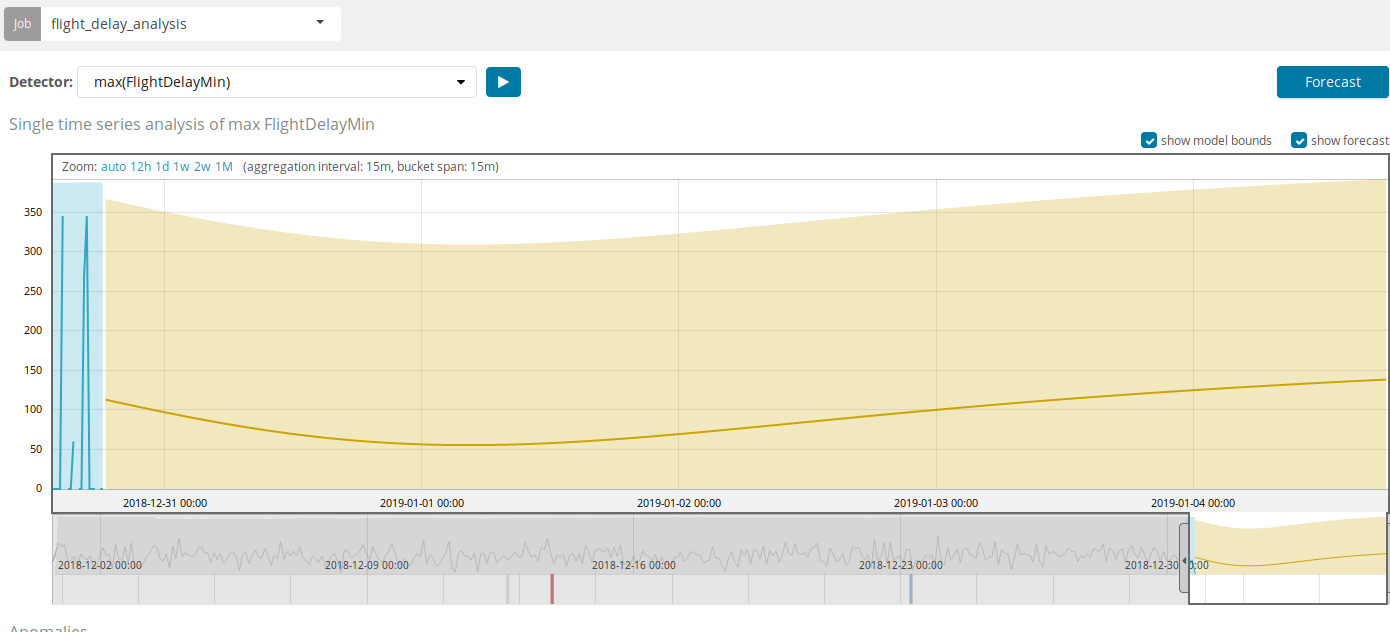
Em algumas situações, a previsão será muito útil, por exemplo, quando o carregamento do usuário na infraestrutura for monitorado.
Métrica múltipla
Passamos para o próximo recurso de ML no Elastic Stack - análise de várias métricas em um único pacote. Mas isso não significa que a dependência de uma métrica em outra será analisada. É o mesmo que Métrica Única, com apenas muitas métricas em uma tela para facilitar a comparação dos efeitos de uma na outra. Falaremos sobre a análise da dependência de uma métrica em relação a outra na parte População.
Depois de clicar no quadrado com o Multi Metric, uma janela de configurações será exibida. Vamos nos debruçar sobre eles com mais detalhes.
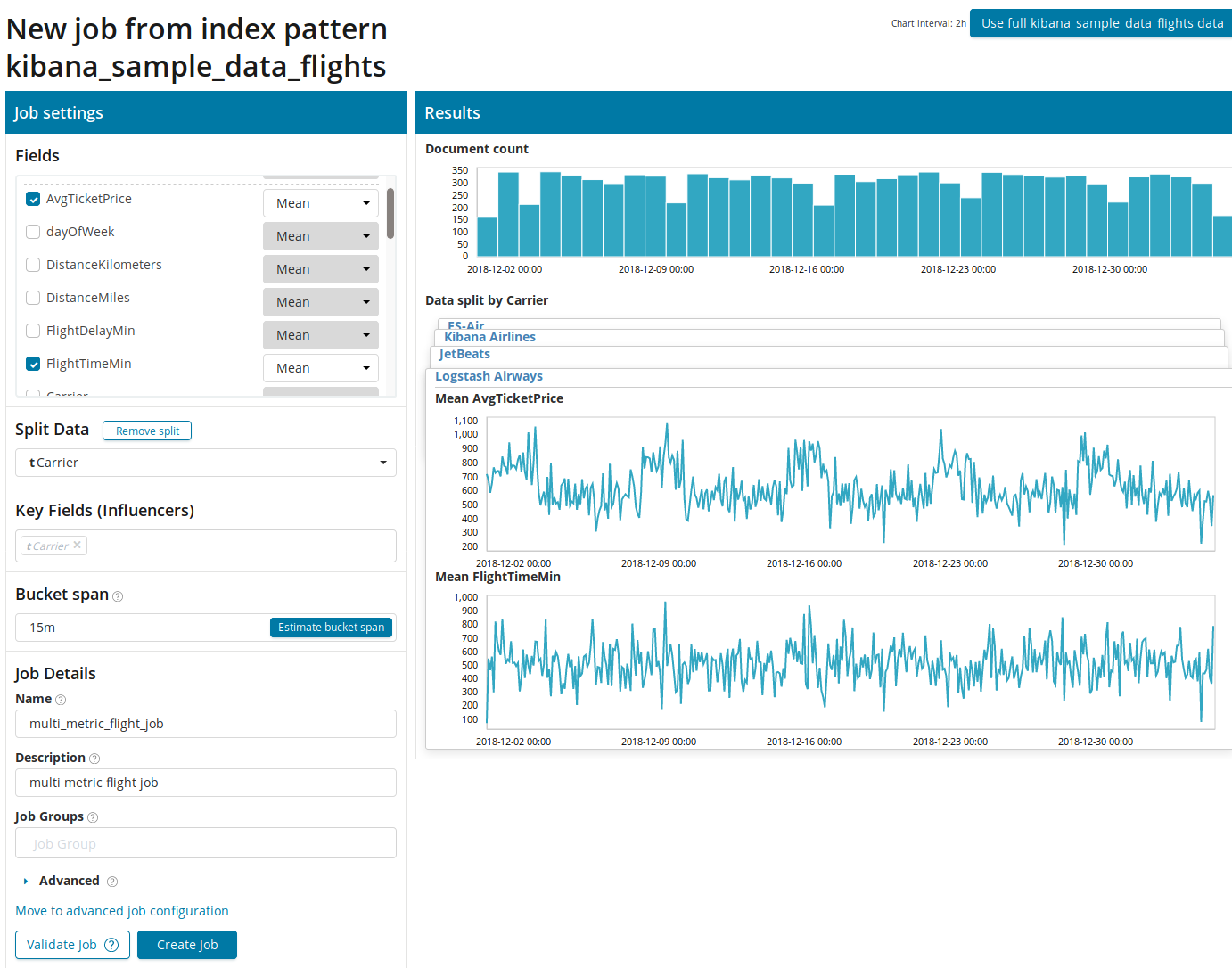
Primeiro, você precisa selecionar os campos para análise e agregação de dados neles. As opções de agregação aqui são as mesmas que para Métrica Única (
Máx, Média Hign, Baixa, Média, Distinta e outras). Além disso, os dados são opcionalmente divididos em um dos campos (campo
Dados divididos ). No exemplo, fizemos isso usando o campo
OriginAirportID . Observe que o gráfico de métricas à direita agora é apresentado como vários gráficos.
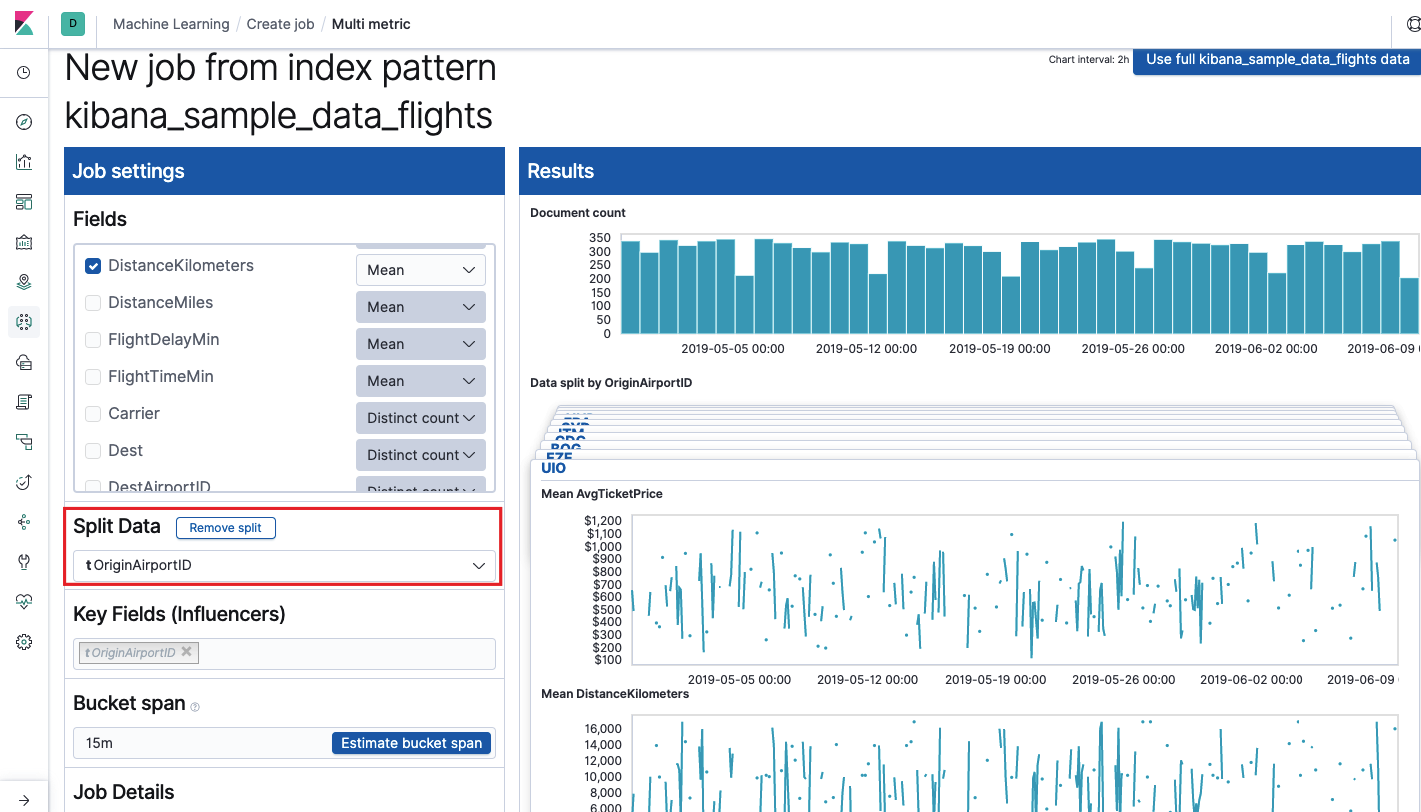
O campo
Key Fields (Influencers) afeta diretamente as anomalias encontradas. Por padrão, sempre haverá pelo menos um valor e você pode adicionar outros. O algoritmo levará em consideração a influência desses campos na análise e mostrará os valores mais "influentes".
Após o lançamento, a seguinte imagem aparecerá na interface do Kibana.
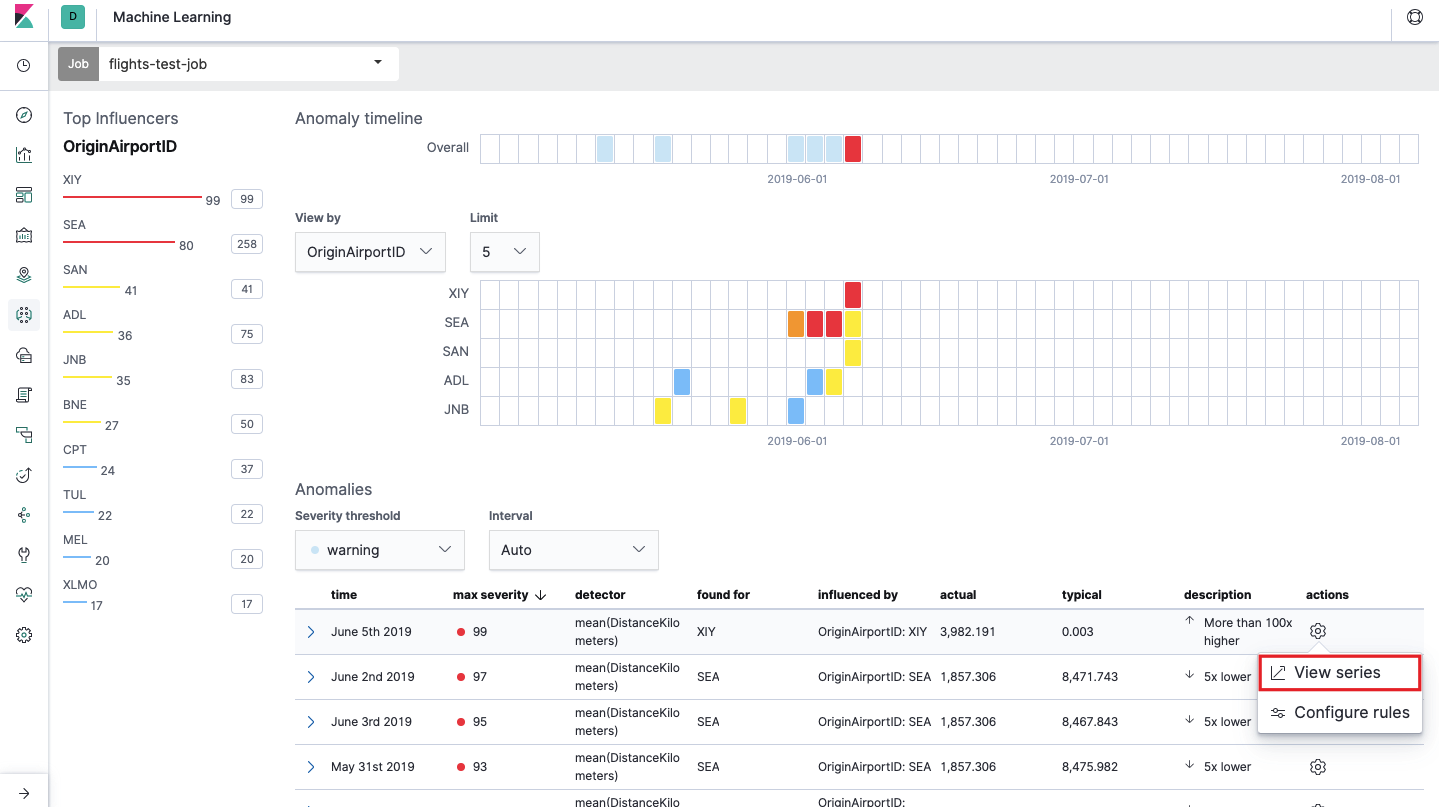
Este é o chamado mapa de calor de anomalias para cada valor do campo
OriginAirportID que especificamos nos
dados divididos . Como na Métrica Única, a cor indica o nível de desvio anormal. É conveniente fazer uma análise semelhante, por exemplo, em estações de trabalho para rastrear aquelas onde há suspeitas de muitas autorizações etc. Já escrevemos
sobre eventos suspeitos no EventLog Windows , que também podem ser coletados e analisados aqui.
Abaixo do mapa de calor, há uma lista de anomalias, de cada uma delas você pode acessar a visualização Métrica Única para análise detalhada.
População
Para procurar anomalias entre as correlações entre diferentes métricas, o Elastic Stack possui uma análise populacional especializada. É com a ajuda dele que você pode procurar valores anômalos no desempenho de um servidor em comparação com outros com, por exemplo, um aumento no número de solicitações ao sistema de destino.
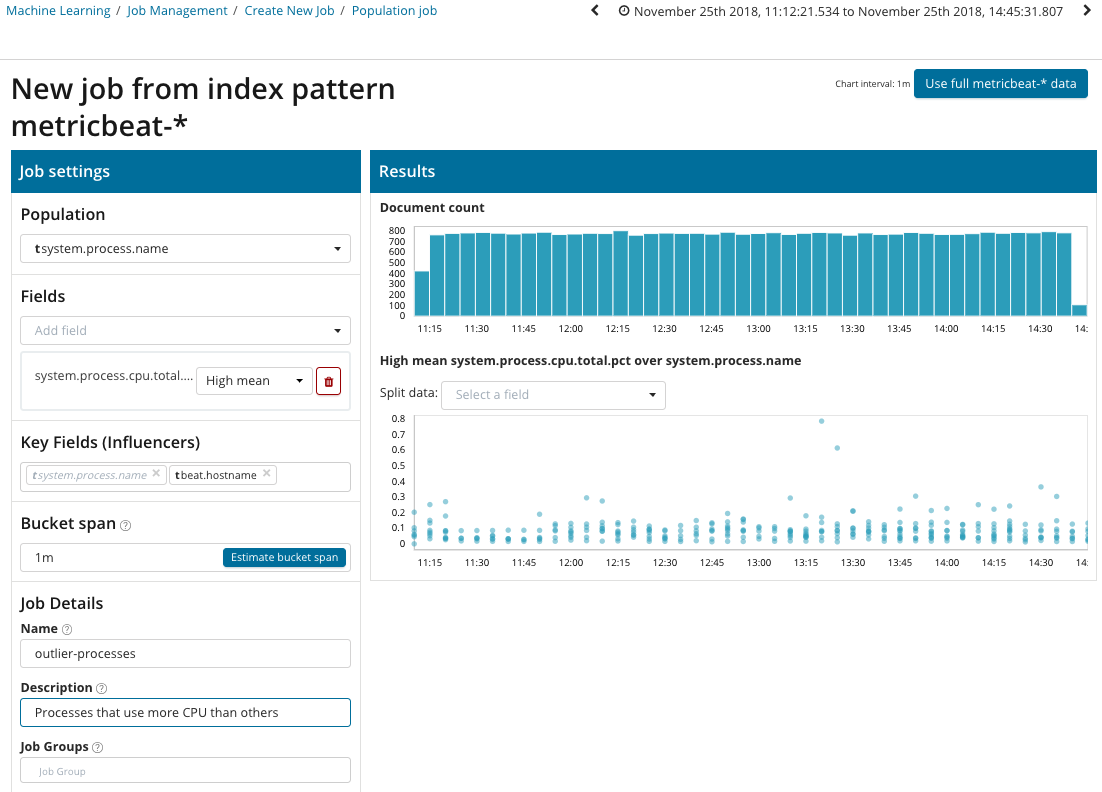
Nesta ilustração, o campo Population indica o valor ao qual as métricas analisadas se relacionarão. Este é o nome do processo. Como resultado, veremos como o carregamento do processador por cada um dos processos se influenciou.
Observe que o gráfico dos dados analisados é diferente dos casos com Métrica Única e Métrica Métrica. Isso é feito em Kibana por design para uma percepção aprimorada da distribuição de valores dos dados analisados.

O gráfico mostra que o processo de
estresse (a propósito, gerado por um utilitário especial) no servidor
poipu se comportou de maneira anormal , o que influenciou (ou acabou sendo um influenciador) a ocorrência dessa anomalia.
Avançado
Análise refinada. Com a Análise avançada, configurações adicionais aparecem no Kibana. Depois de clicar no menu criar no bloco Avançado, uma janela com guias é exibida. A guia
Detalhes da tarefa foi deliberadamente ignorada. As configurações básicas não estão diretamente relacionadas às configurações da análise.
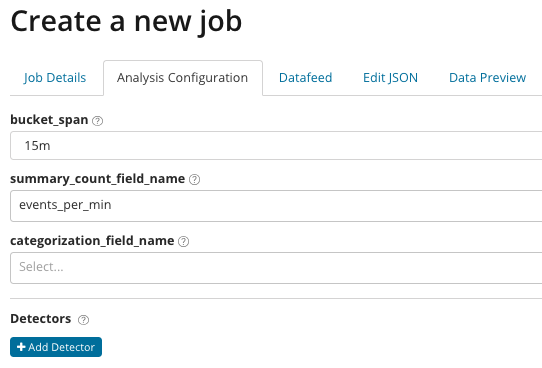
Em
summary_count_field_name, você pode opcionalmente especificar o nome do campo nos documentos que contêm valores agregados. Neste exemplo, o número de eventos por minuto. O
categorization_field_name indica o nome do valor do campo do documento, que contém algum tipo de valor da variável. Por máscara neste campo, você pode dividir os dados analisados em subconjuntos. Preste atenção ao botão
Adicionar detector na ilustração anterior. Abaixo está o resultado de clicar neste botão.

Aqui está um bloco de configurações adicionais para configurar o detector de anomalia para uma tarefa específica. Planejamos analisar casos de uso específicos (especialmente para segurança) nos seguintes artigos. Por exemplo,
veja um dos casos desmontados. Está associado à busca de valores que raramente aparecem e é implementado
pela função rara .
No campo de
função , você pode selecionar uma função específica para procurar anomalias. Além de
raro , existem algumas funções interessantes -
time_of_day e time_of_week . Eles identificam anomalias no comportamento das métricas ao longo do dia ou semana, respectivamente. O restante das funções de análise
está na documentação .
O nome do campo indica o campo do documento que será analisado.
By_field_name pode ser usado para separar os resultados da análise para cada valor individual do campo do documento especificado aqui. Se você preencher
over_field_name, obterá a análise da população, que examinamos acima. Se você especificar um valor em
partition_field_name , nesse campo de documento serão calculadas linhas de base individuais para cada valor (por exemplo, o nome do servidor ou o processo no servidor pode atuar como o valor). Em
exclude_frequent, você pode selecionar
todos ou
nenhum , o que significa a exclusão (ou inclusão) dos valores dos campos de documentos encontrados com frequência.
No artigo, tentamos dar uma idéia mais concisa sobre as possibilidades de aprendizado de máquina no Elastic Stack, ainda há muitos detalhes nos bastidores. Diga-nos nos comentários quais casos você conseguiu resolver com a ajuda do Elastic Stack e para quais tarefas você o utiliza. Para entrar em contato conosco, você pode usar mensagens pessoais no Habré ou o
formulário de comentários no site .