Trago a sua atenção uma tradução do relatório de Alexander Kuzmenko (desde abril deste ano ele trabalha oficialmente como desenvolvedor do compilador Haxe) sobre mudanças na linguagem Haxe ocorridas desde o lançamento do Haxe 3.4.

Mais de dois anos e meio se passaram desde o lançamento do Haxe 3.4. Durante esse período, foram lançadas 7 versões de patches, 5 versões de pré-visualização do Haxe 4 e 2 candidatos a versões do Haxe 4. Era um longo caminho até a nova versão e está quase pronta ( cerca de 20 problemas ainda precisam ser resolvidos).

Alexander agradeceu à comunidade Haxe por reportar bugs, por seu desejo de participar do desenvolvimento do idioma. Graças ao projeto haxe-evolution , coisas como a seguir aparecerão no Haxe 4:
- marcação embutida
- funções embutidas no local da chamada
- funções de seta

Além disso, dentro da estrutura deste projeto, estão sendo realizadas discussões sobre possíveis inovações como: Promessas , isso polimórfico e tipos padrão (parâmetros de tipo padrão).
Em seguida, Alexander falou sobre as mudanças na sintaxe do idioma .

A primeira é a nova sintaxe para descrever os tipos de função. A sintaxe antiga era um pouco estranha.
O Haxe é uma linguagem de programação com vários paradigmas, sempre com suporte para funções de primeira classe, mas a sintaxe para descrever os tipos de funções foi herdada de uma linguagem funcional (e difere da adotada em outros paradigmas). E os programadores familiarizados com a programação funcional esperam que as funções dessa sintaxe sejam compatíveis com o curry automático. Mas em Haxe não é assim.
A principal desvantagem da sintaxe antiga, de acordo com Alexander, é a incapacidade de determinar os nomes dos argumentos, e é por isso que você precisa escrever comentários de anotação longos com uma descrição dos argumentos.
Mas agora temos uma nova sintaxe para descrever os tipos de função (que, a propósito, foram adicionados ao idioma como parte da iniciativa haxe-evolution), onde existe uma oportunidade (embora isso seja opcional, mas recomendado). A nova sintaxe é mais fácil de ler e pode até ser considerada parte da documentação do código.
Outra desvantagem da sintaxe antiga para descrever os tipos de função era sua Void->Void - a necessidade de especificar o tipo de argumento da função, mesmo quando a função não aceita argumentos: Void->Void (essa função não aceita argumentos e não retorna nada).
Na nova sintaxe, isso é implementado de forma mais elegante: ()->Void

O segundo são funções de seta ou expressões lambda - uma forma curta de descrever funções anônimas. A comunidade pede há muito tempo para adicioná-los ao idioma e, finalmente, aconteceu!
Nessas funções, em vez da palavra-chave de return , a sequência de caracteres -> (portanto, o nome da sintaxe é "função da seta").
Na nova sintaxe, ainda é possível definir os tipos de argumentos (como o sistema de inferência automática de tipos nem sempre pode fazer isso da maneira que o programador deseja, por exemplo, o compilador pode decidir usar Float vez de Int ).
A única limitação da nova sintaxe é a incapacidade de definir explicitamente o tipo de retorno. Se necessário, você pode optar por usar a sintaxe antiga ou a sintaxe do tipo de verificação no corpo da função, que informará ao compilador o tipo de retorno.

As funções de seta não têm uma representação especial na árvore de sintaxe, são processadas da mesma maneira que as funções anônimas regulares. A sequência -> é substituída pela palavra-chave return .

A terceira alteração - final agora se tornou uma palavra-chave (na final Haxe 3, uma das meta tags incorporadas no compilador).
Se você aplicá-lo a uma classe, ele proibirá a herança, o mesmo se aplica às interfaces. A aplicação do qualificador final a um método de classe impedirá que ele seja substituído em classes filho.
No entanto, no Haxe, havia uma maneira de contornar as restrições impostas pela palavra-chave final - você pode usar a metatag @:hack para isso (mas ainda assim, isso deve ser feito apenas se for absolutamente necessário).
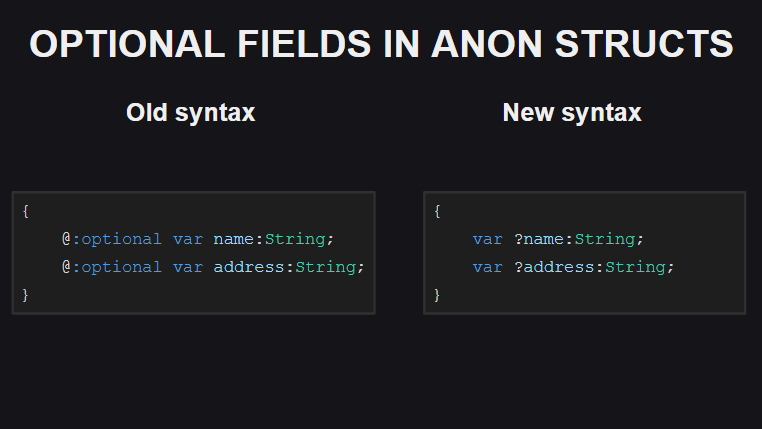
A quarta alteração é uma maneira de declarar campos opcionais em estruturas anônimas. Anteriormente, a meta tag @:optional era usada para isso, agora basta adicionar um ponto de interrogação na frente do nome do campo.

Em quinto lugar, as enumerações abstratas se tornaram um membro completo da família de tipos Haxe e, em vez da metatag @:enum palavra-chave @:enum agora é usada para declará-las.
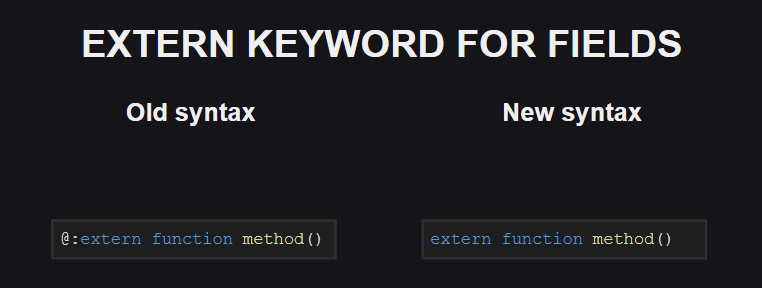
Uma mudança semelhante afetou a meta tag @:extern .

Sétimo é um novo tipo de sintaxe de interseção que reflete melhor a essência das estruturas em expansão.
A mesma nova sintaxe é usada para limitar as restrições dos parâmetros de tipo; ela transmite com mais precisão as restrições impostas a um tipo. Para uma pessoa não familiarizada com o Haxe, a sintaxe antiga MyClass<T:(Type1, Type2)> pode ser percebida como um requisito para o tipo do parâmetro T ser Type1 ou Type2 . A nova sintaxe nos diz explicitamente que T deve ser do tipo 1 e do tipo 2 ao mesmo tempo.
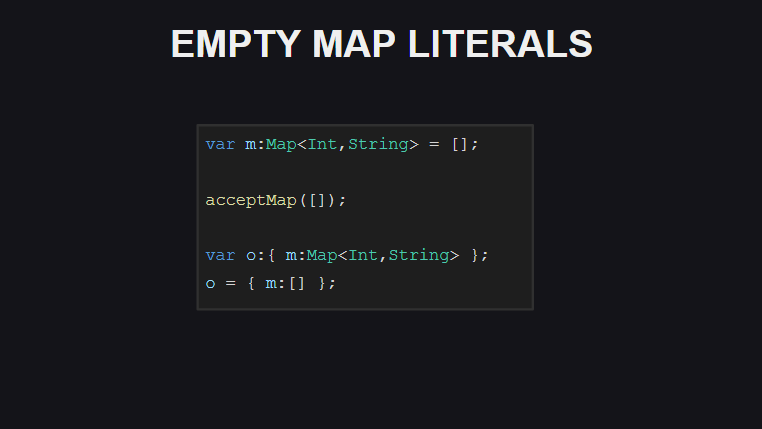
A oitava é a capacidade de usar [] para declarar um contêiner de Map vazio (no entanto, se você não especificar explicitamente o tipo da variável, o compilador emitirá o tipo como uma matriz para este caso).
Depois de falar sobre as mudanças na sintaxe, vamos para a descrição de novas funções no idioma .
Vamos começar com os novos iteradores de valor-chave
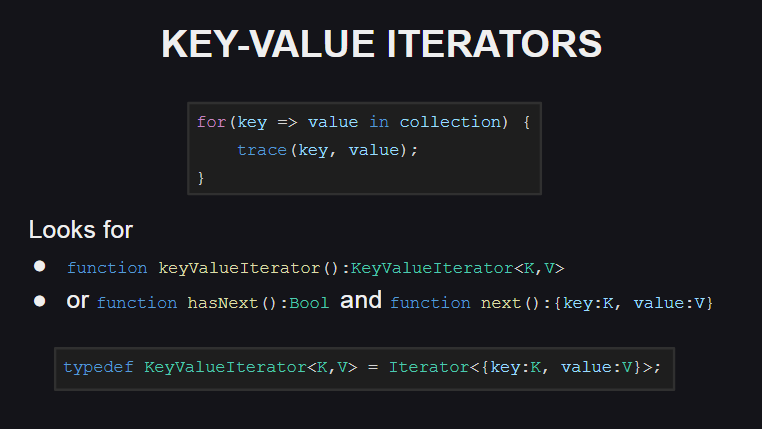
Uma nova sintaxe foi adicionada para uso.
Para oferecer suporte a esses iteradores, o tipo deve implementar o método keyValueIterator():KeyValueIterator<K, V> ou os métodos hasNext():Bool e next():{key:K, value:V} . Ao mesmo tempo, o tipo KeyValueIterator<K, V> é sinônimo de um iterador regular na estrutura anônima Iterator<{key:K, value:V}> .
Os iteradores de valores-chave são implementados para alguns tipos da biblioteca padrão Haxe ( String , Map , DynamicAccess ), e também está em andamento o trabalho para implementá-los para matrizes.
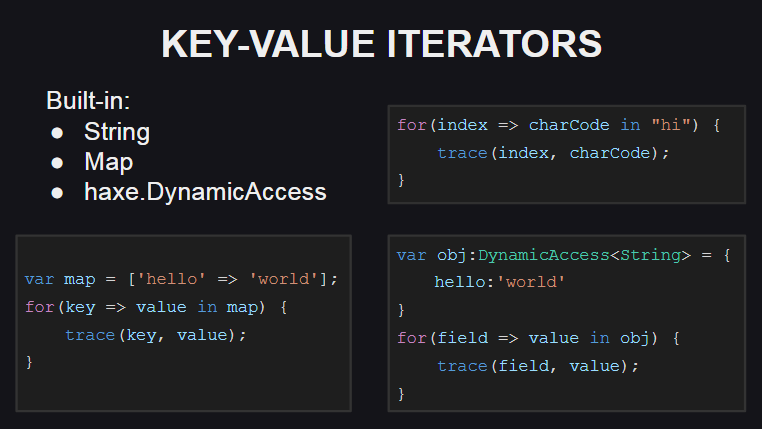
Para cadeias, o índice de caracteres na cadeia é usado como chave e o código de caracteres no índice especificado é usado como valor (se o próprio caractere for necessário, o método String.fromCharCode() poderá ser usado).
Para o contêiner de Map , o novo iterador funciona da mesma forma que o antigo método de iteração, ou seja, recebe uma matriz de chaves no contêiner e passa por ele, solicitando valores para cada uma das chaves.
Para DynamicAccess (um invólucro para objetos anônimos), o iterador trabalha usando reflexão (para obter uma lista dos campos de um objeto usando o método Reflect.fields() e obter valores de campo por seus nomes usando o método Reflect.field() ).

O Haxe 4 usa um intérprete de macro completamente novo, "eval". Simon Krajewski, autor do intérprete, o descreveu com alguns detalhes no blog oficial do Haxe , bem como em seu relatório de progresso do ano passado .
As principais mudanças no trabalho do intérprete:
- é várias vezes mais rápido que o antigo intérprete de macros (4 vezes em média)
- suporta depuração interativa (anteriormente, para macros, somente a saída do console podia ser usada)
- é usado para executar o compilador no modo de intérprete (anteriormente o neko foi usado para isso. A propósito, eval também supera o neko na velocidade).

O suporte a Unicode para todas as plataformas (com exceção da neko) é uma das maiores mudanças no Haxe 4. Simon falou sobre isso em detalhes no ano passado . Mas aqui está uma breve visão geral do estado atual do suporte a strings Unicode no Haxe:
- para Lua, PHP, Python e eval (interpretador de macro), é implementado suporte unicode completo (codificação UTF8)
- para outras plataformas (JavaScript, C #, Java, Flash, HashLink e C ++), a codificação UTF16 é usada.
Portanto, as linhas no Haxe funcionam da mesma maneira para caracteres incluídos no plano multilíngue principal , mas para caracteres fora deste plano (por exemplo, para emoji), o código para trabalhar com linhas pode produzir resultados diferentes dependendo da plataforma (mas isso é ainda melhor, do que a situação que temos no Haxe 3, quando cada plataforma tinha seu próprio comportamento).

Para cadeias codificadas em Unicode (tanto em UTF8 quanto em UTF16), iteradores especiais foram adicionados à biblioteca padrão do Haxe que funcionam igualmente em TODAS as plataformas para todos os caracteres (no plano multilíngue principal e além):
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

Como a implementação de strings varia de plataforma para plataforma, é necessário ter em mente algumas das nuances de seu trabalho. No UTF16, cada caractere ocupa 2 bytes, portanto, o acesso a um caractere em uma sequência de caracteres por índice é rápido, mas apenas dentro do plano multilíngue principal. Por outro lado, em UTF8 todos os caracteres são suportados, mas isso é conseguido ao custo de uma pesquisa lenta por um caractere em uma sequência de caracteres (como os caracteres podem ocupar diferentes números de bytes na memória, acessar um caractere por índice requer iteração na linha todas as vezes desde o início). Portanto, ao trabalhar com grandes seqüências de caracteres em Lua e PHP, você deve ter em mente que o acesso a um caractere arbitrário funciona muito lentamente (também nessas plataformas, o comprimento da string é calculado novamente a cada vez).
No entanto, embora o suporte completo a Unicode seja declarado para Python, essa restrição não se aplica a ele porque as linhas nele são implementadas de uma maneira ligeiramente diferente: para caracteres no plano multilíngue principal, ele usa a codificação UTF16 e para caracteres mais amplos (3 e mais bytes) O Python usa UTF32.
Otimizações adicionais são implementadas para o interpretador de macro eval: a sequência "sabe" se contém caracteres Unicode. No caso de não conter esses caracteres, a sequência é interpretada como consistindo em caracteres ASCII (em que cada caractere ocupa 1 byte). O acesso seqüencial por índice em eval também é otimizado: a posição do último caractere acessado é armazenada em cache na linha. Portanto, se você girar primeiro para o 10º caractere na sequência, quando você voltar para o 20º caractere, eval o procurará não desde o início da linha, mas a partir do 10º. Além disso, o comprimento da sequência em eval é armazenado em cache, ou seja, é calculado apenas na primeira solicitação.
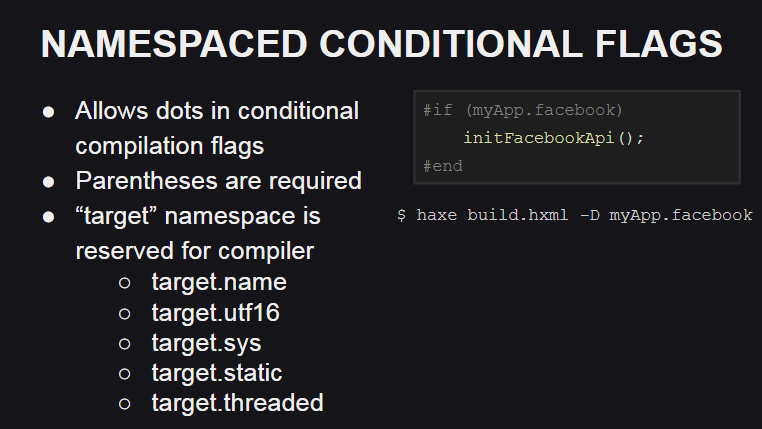
O Haxe 4 apresenta suporte para namespaces para sinalizadores de compilação, que podem ser úteis, por exemplo, para organizar código ao escrever bibliotecas personalizadas.
Além disso, um namespace reservado para sinalizadores de compilação apareceu - target , que é usado pelo compilador para descrever a plataforma de destino e seu comportamento:
target.name - nome da plataforma (js, cpp, php, etc.)target.utf16 - diz que o suporte a Unicode é implementado usando UTF16target.sys - indica se as classes do pacote sys estão disponíveis (por exemplo, para trabalhar com o sistema de arquivos)target.static - indica se a plataforma é estática (em plataformas estáticas, os tipos base Int , Float e Bool não podem ter null como valor)target.threaded - indica se a plataforma suporta multithreading
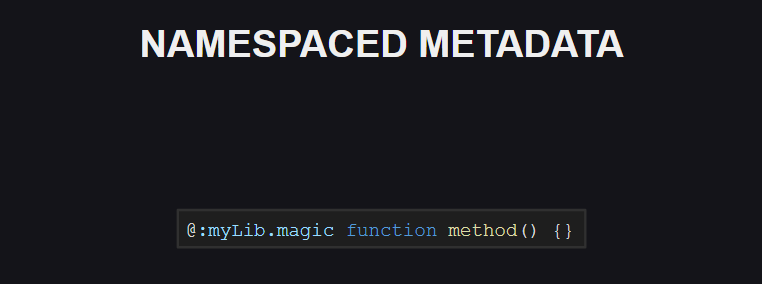
Da mesma forma, o suporte ao namespace para metatags apareceu. Até o momento, não há namespaces reservados para metatags no idioma, mas a situação pode mudar no futuro.

O tipo ReadOnlyArray adicionado à biblioteca padrão do Haxe - uma abstração em uma matriz regular, na qual os métodos estão disponíveis apenas para a leitura de dados da matriz.

Outra inovação no idioma são os campos finais e as variáveis locais.
Se final usado no lugar da palavra-chave var ao declarar um campo de classe ou variável local, isso significa que o campo ou variável especificado não pode ser reatribuído (se o compilador tentar fazer isso, ocorrerá um erro). Mas, ao mesmo tempo, seu estado pode ser alterado, portanto o campo ou variável final não é uma constante.
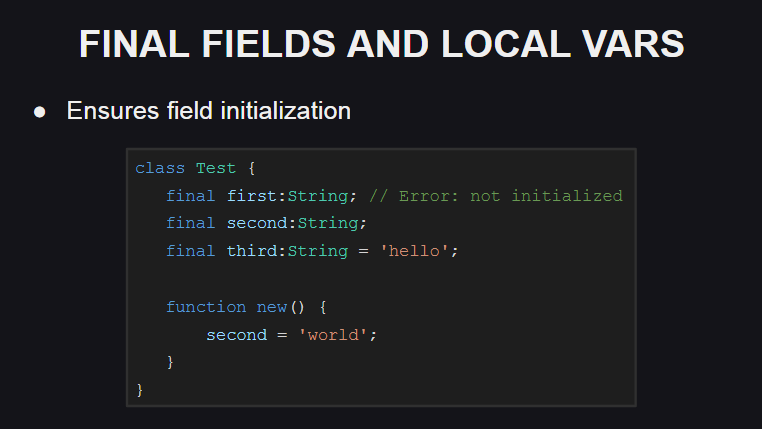
Os valores dos campos finais devem ser inicializados quando eles são declarados ou no construtor, caso contrário, o compilador lançará um erro.

O HashLink é uma nova plataforma com sua própria máquina virtual, criada especificamente para a Haxe. O HashLink suporta a chamada “compilação dupla” - o código pode ser compilado no bytecode (que é muito rápido, acelera o processo de depuração de aplicativos desenvolvidos) ou no código C (que é caracterizado pelo desempenho aprimorado). Nicholas dedicou o HashLink a várias postagens do blog Haxe e também falou sobre ele na conferência de Seattle do ano passado . A tecnologia HashLink é usada em jogos populares como Dead Cells e Northgard.

Outro novo recurso interessante do Haxe 4 é a segurança nula, que ainda está em fase experimental (devido a falsos positivos e verificações de segurança de código insuficientes).
O que é segurança nula? Se sua função não declarar explicitamente que pode aceitar null como valores de parâmetro, quando você tenta passar null para ela, o compilador lançará o erro correspondente. Além disso, para parâmetros de função que podem assumir null como valor, o compilador exigirá que você escreva código adicional para verificar e manipular esses casos.
Essa funcionalidade é desativada por padrão, mas não afeta a velocidade de execução do código (se você ativá-la, no entanto), pois as verificações descritas são realizadas apenas no estágio de compilação. Ele pode ser ativado para todo o código, bem como gradualmente ativado para campos, classes e pacotes individuais (fornecendo uma transição gradual para um código mais seguro). Você pode usar meta tags e macros especiais para isso.
Os modos nos quais a segurança nula pode funcionar são: Strict (o mais rigoroso), Loose (o modo padrão) e Off (usado para desativar as verificações de pacotes e tipos individuais).

Para a função mostrada no slide, a verificação de segurança nula está ativada. Vemos que esta função possui um parâmetro opcional s , ou seja, podemos passar null para ela como um valor de parâmetro. Ao tentar compilar código com essa função, o compilador produzirá vários erros:
- ao tentar acessar algum campo do objeto
s (pois pode ser null ) - ao tentar atribuir uma variável str, que, como vemos, não deve ser
null (caso contrário, deveríamos tê-la declarado não como String , mas como Null<String> ) - ao tentar retornar um objeto
s de uma função (já que a função não deve retornar null )
Como corrigir esses erros?
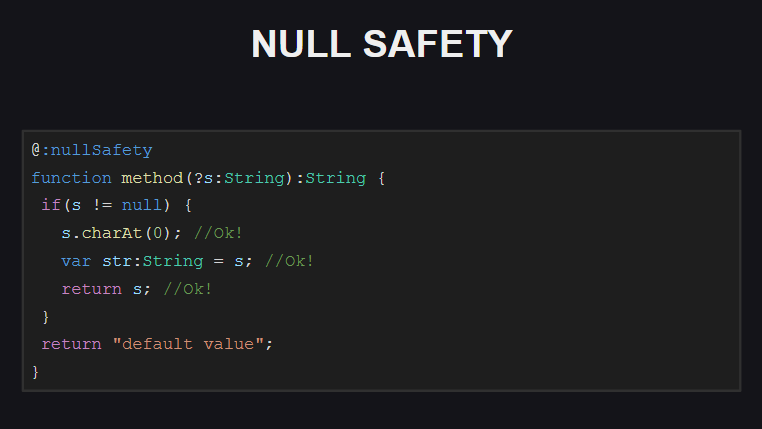
Nós apenas precisamos adicionar verificação null ao código (dentro do bloco com verificação null , o compilador “sabe” que s não pode ser null e pode ser usado com segurança), além de garantir que a função não retorne null !

Além disso, ao executar verificações de segurança nula, o compilador leva em consideração a ordem na qual os programas são executados. Por exemplo, se depois de verificar o valor do parâmetro s para nulo para finalizar a função (ou lançar uma exceção), o compilador “saberá” que após essa verificação, o parâmetro s não poderá mais ser null e poderá ser usado com segurança.

Se o compilador habilitar o modo Rigoroso de verificações para segurança Nula, ele exigirá verificações adicionais para null nos casos em que entre a verificação inicial do valor null e uma tentativa de acessar o campo do objeto em que qualquer código foi executado, podendo defini-lo como null .
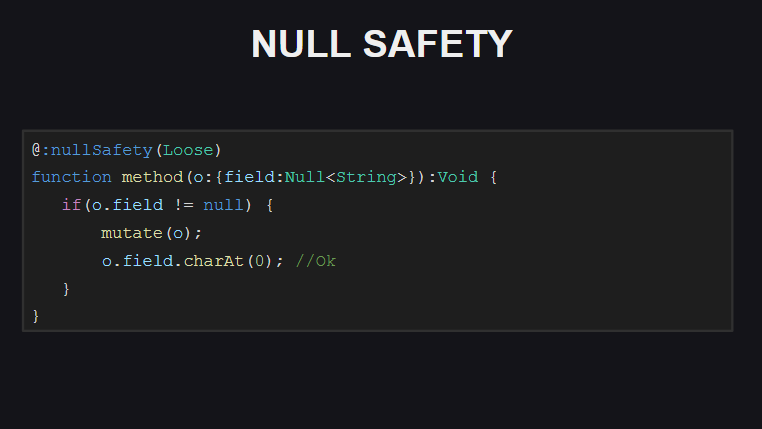
No modo Loose (usado por padrão), o compilador não exigirá essas verificações (a propósito, esse comportamento também é usado por padrão no TypeScript).

Além disso, quando as verificações de segurança nula estão ativadas, o compilador verifica se os campos nas classes são inicializados (diretamente quando são declarados ou no construtor). Caso contrário, o compilador lançará erros ao tentar passar um objeto dessa classe, bem como ao tentar chamar métodos nesses objetos, até que todos os campos do objeto sejam inicializados. Essas verificações podem ser desativadas para campos individuais da classe, marcando-as com a metatag @:nullSafety(Off)
Alexander falou mais sobre segurança nula em Haxe em outubro passado .

O Haxe 4 introduziu a capacidade de gerar classes ES6 para JavaScript; é ativado usando o sinalizador de compilação js-es=6 .
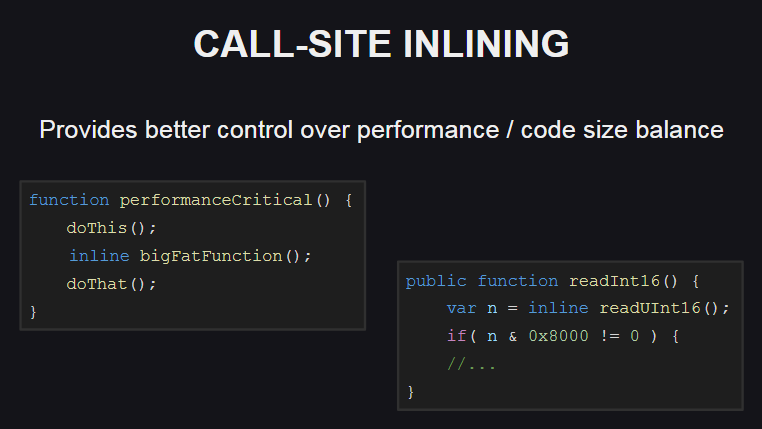
A incorporação de funções no local de uma chamada (inlining do site da chamada) oferece mais opções para controlar o equilíbrio entre o desempenho e o tamanho do código. Essa funcionalidade também é usada na biblioteca padrão Haxe.
Como ela é? Ele permite incorporar o corpo da função (usando a inline ) apenas nos locais em que é necessário garantir alto desempenho (por exemplo, se necessário, chamar um método suficientemente volumoso no loop), enquanto em outros locais o corpo da função não é incorporado. Como resultado, o tamanho do código gerado será ligeiramente aumentado.
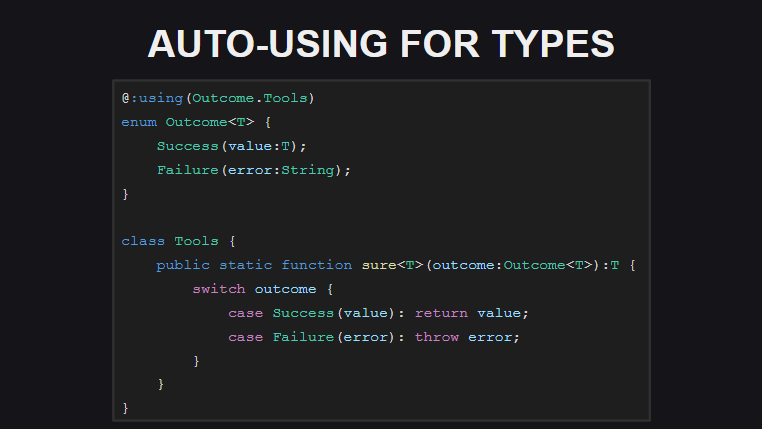
O uso automático (extensões automáticas para tipos) significa que agora para tipos você pode declarar extensões estáticas no local da declaração de tipo. Isso elimina a necessidade de usar a construção de using type; cada vez using type; em cada módulo em que os métodos de tipo e extensão são usados. No momento, esse tipo de extensão é implementado apenas para transferências, mas na versão final (e nas compilações noturnas) pode ser usado não apenas para transferências.

No Haxe 4, será possível redefinir o operador para acessar os campos de um objeto para tipos abstratos (apenas para campos que não existem no tipo). Para fazer isso, use métodos marcados com a meta tag @:op(ab) .

A marcação interna é outro recurso experimental do Haxe. O código de marcação interno não é processado pelo compilador como um documento xml - o compilador o vê como uma sequência envolvida na metatag @:markup . .
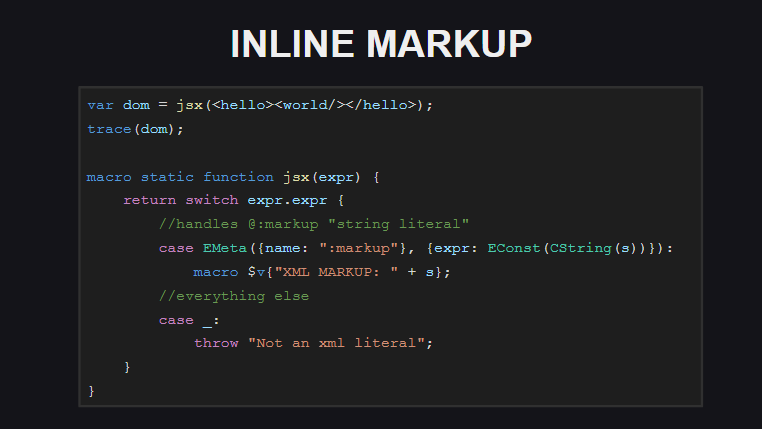
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
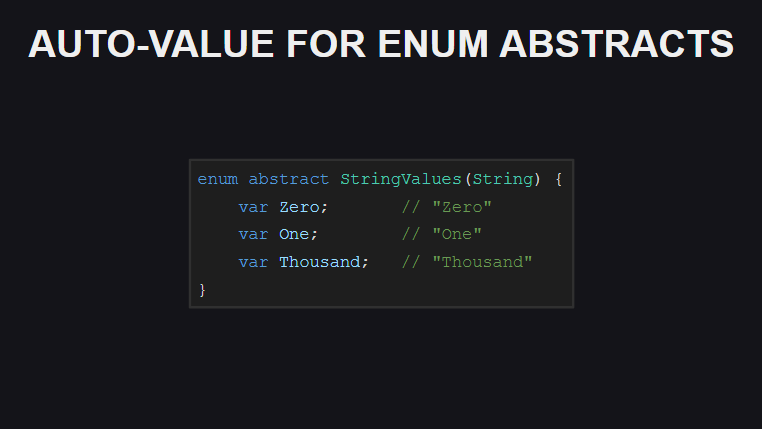
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !