
Hoje vou falar sobre como surgiu a idéia de criar uma nova rede interna para nossa empresa. Cargo de gerência - você precisa criar o mesmo projeto completo que o do cliente. Se fizermos isso bem por nós mesmos, poderemos convidar o cliente e mostrar o quão bem organizado e funciona o que oferecemos a ele. Portanto, abordamos o desenvolvimento do conceito de uma nova rede para o escritório de Moscou com muito cuidado, usando todo o ciclo de produção: análise das necessidades dos departamentos → escolha da solução técnica → design → implementação → teste. Então aqui vamos nós.
Escolha da solução técnica: reserva de mutantes
Até agora, o procedimento para trabalhar em um sistema automatizado complexo é melhor descrito em GOST 34.601-90 “Sistemas automatizados. Os estágios da criação ”, então trabalhamos nisso. E já nas etapas de formação de requisitos e desenvolvimento de um conceito, encontramos as primeiras dificuldades. Organizações de vários perfis - bancos, seguradoras, desenvolvedores de software etc. - para suas tarefas e padrões, são necessários certos tipos de redes, cujas especificidades são claras e padronizadas. No entanto, isso não funcionará conosco.
Porque
A Jet Infosystems é uma grande empresa de TI multidisciplinar. Ao mesmo tempo, nosso departamento de suporte interno é pequeno (mas orgulhoso), garante a disponibilidade de serviços e sistemas básicos. A empresa contém muitas divisões que desempenham funções diferentes: inclui várias equipes poderosas de terceirização, seus próprios desenvolvedores de sistemas de negócios e segurança da informação e arquitetos de complexos de computadores - em geral, quem não é. Consequentemente, suas tarefas, sistemas e políticas de segurança também são diferentes. O que era esperado criava dificuldades no processo de análise de necessidades e sua padronização.
Por exemplo, o departamento de desenvolvimento: seus funcionários escrevem e testam código para um grande número de clientes. Freqüentemente, é necessário organizar rapidamente os ambientes de teste e, francamente, nem sempre é possível para cada projeto formar requisitos, solicitar recursos e criar um ambiente de teste separado, de acordo com todos os regulamentos internos. Isso cria situações curiosas: uma vez que seu humilde servidor olhou para a sala de desenvolvedores e encontrou um cluster Hadoop que funcionava bem, com 20 áreas de trabalho embaixo da mesa, inexplicavelmente conectado a uma rede comum. Acho que não vale a pena especificar que o departamento de TI da empresa não sabia de sua existência. Essa circunstância, como muitas outras, tornou-se a culpada pelo fato de que, durante o desenvolvimento do projeto, nasceu o termo “reserva mutante”, descrevendo o estado da infra-estrutura de escritórios que sofria.
Ou aqui está outro exemplo. Periodicamente, uma bancada de testes é montada dentro de uma unidade. Esse foi o caso de Jira e Confluence, que foram usados de forma limitada pelo Centro de Desenvolvimento de Software em alguns projetos. Após algum tempo, esses recursos úteis foram descobertos em outras divisões, avaliados e, no final de 2018, Jira e Confluence passaram do status de "programadores locais de brinquedos" para o status de "recursos da empresa". Agora, o proprietário deve ser atribuído a esses sistemas, SLAs, políticas de acesso / segurança, políticas de backup, políticas de monitoramento, regras de roteamento para aplicativos de solução de problemas - em geral, todos os atributos de um sistema de informações completo devem estar presentes.
Cada uma de nossas unidades também é uma incubadora que cultiva seus próprios produtos. Alguns deles morrem no estágio de desenvolvimento, alguns dos quais usamos durante o período de trabalho em projetos, enquanto outros criam raízes e se tornam soluções replicadas que começamos a aplicar a nós mesmos e a vender para os clientes. Para cada um desses sistemas, é desejável ter seu próprio ambiente de rede, onde ele se desenvolverá sem interferir com outros sistemas e, em algum momento, poderá ser integrado à infraestrutura da empresa.
Além do desenvolvimento, temos um
Centro de Serviços muito grande
, com mais de 500 funcionários, formados em equipes para cada cliente. Eles estão envolvidos na manutenção de redes e outros sistemas, monitoramento remoto, liquidação de aplicativos e assim por diante. Ou seja, a infraestrutura do
SC é, de fato, a infraestrutura do cliente com quem eles estão trabalhando atualmente. A peculiaridade de trabalhar com essa parte da rede é que suas estações de trabalho para nossa empresa são parcialmente externas e parcialmente internas. Portanto, para a SC, implementamos a seguinte abordagem - a empresa fornece à unidade correspondente rede e outros recursos, considerando as estações de trabalho dessas unidades como conexões externas (semelhantes a filiais e usuários remotos).
Projeto da rodovia: somos o operador (surpresa)
Depois de avaliar todas as armadilhas, percebemos que estávamos recebendo a rede de uma operadora de telecomunicações em um escritório e começamos a agir de acordo.
Criamos uma rede de backbone, com a qual qualquer consumidor interno e, a longo prazo, é fornecido com o serviço necessário: VPN L2, VPN L3 VPN ou roteamento L3 convencional. Alguns departamentos precisam de acesso seguro à Internet, enquanto outros precisam de acesso limpo, sem firewalls, mas com a proteção de nossos recursos corporativos e da rede principal contra o tráfego.
Com cada divisão, informalmente "concluímos um SLA". De acordo com ele, todos os incidentes que surgirem devem ser eliminados em um determinado período de tempo previamente acordado. Os requisitos da empresa para sua rede acabaram sendo difíceis. O tempo máximo de resposta a incidentes para falhas de telefone e e-mail foi de 5 minutos. O tempo de recuperação da rede durante falhas típicas não passa de um minuto.
Como temos uma rede de classe de operadora, você pode se conectar a ela somente em estrita conformidade com as regras. Os departamentos de serviço estabelecem políticas e prestam serviços. Eles nem precisam de informações sobre as conexões de servidores, máquinas virtuais e estações de trabalho específicas. Mas, ao mesmo tempo, são necessários mecanismos de proteção, porque nenhuma conexão deve desativar a rede. Ao criar acidentalmente um loop, outros usuários não devem perceber isso, ou seja, é necessária uma resposta de rede adequada. Qualquer operadora de telecomunicações resolve constantemente tarefas aparentemente complexas em sua rede principal. Ele fornece serviços para muitos clientes com diferentes necessidades e tráfego. Ao mesmo tempo, diferentes assinantes não devem sofrer transtornos com o tráfego de outras pessoas.
Em casa, resolvemos esse problema da seguinte maneira: construímos uma rede L3 básica com redundância total usando o
protocolo IS-IS . Uma rede de sobreposição baseada na tecnologia
EVPN /
VXLAN foi construída sobre o backbone, usando o
protocolo de roteamento
MP-BGP . Para acelerar a convergência de protocolos de roteamento, foi utilizada a tecnologia
BFD .
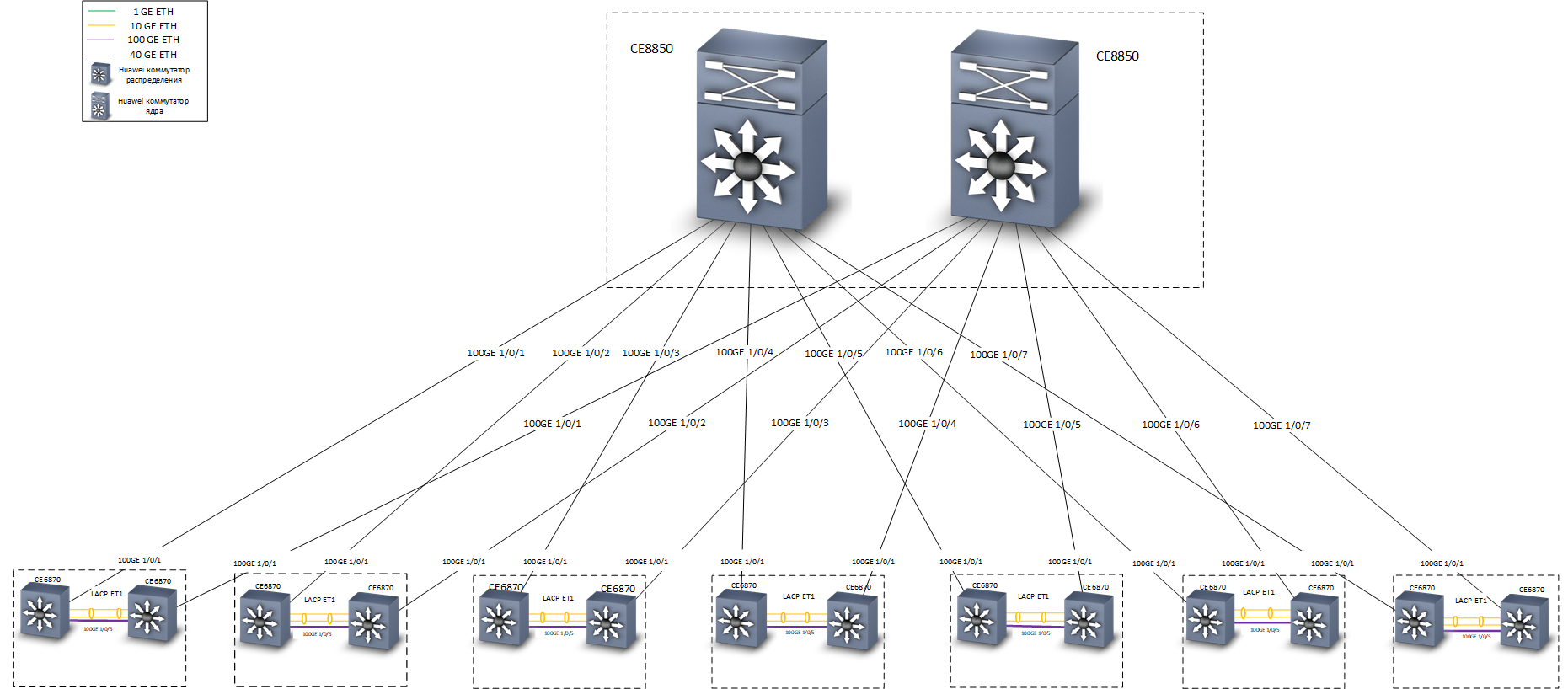 Estrutura de rede
Estrutura de redeNos testes, esse esquema provou ser excelente - quando qualquer canal ou comutador era desligado, o tempo de convergência não era superior a 0,1-0,2 s, um mínimo de pacotes (geralmente - não era um único pacote) era perdido, as sessões TCP não eram interrompidas, as conversas telefônicas não eram interrompidas.
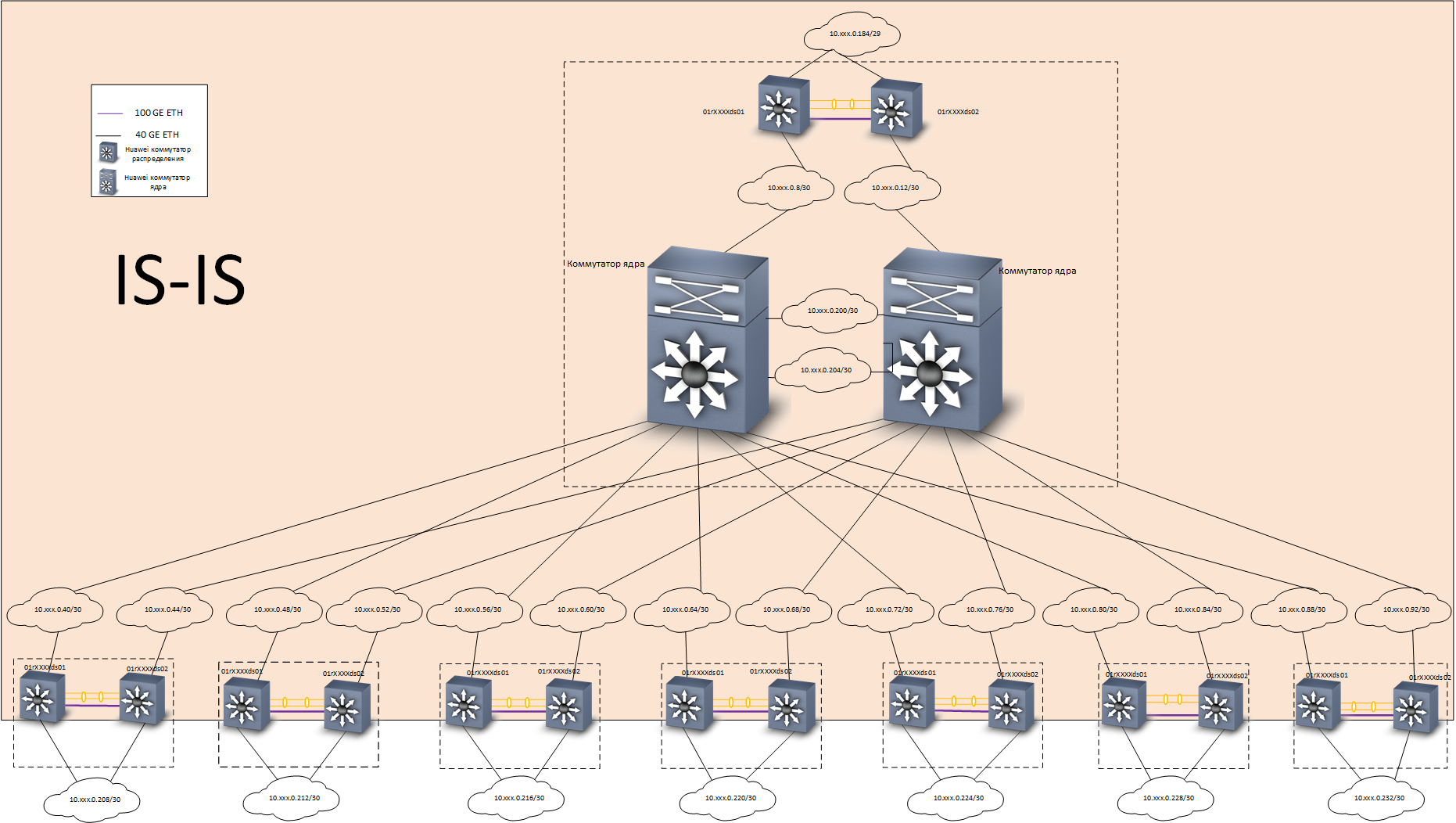 Nível de subjacência - roteiro
Nível de subjacência - roteiro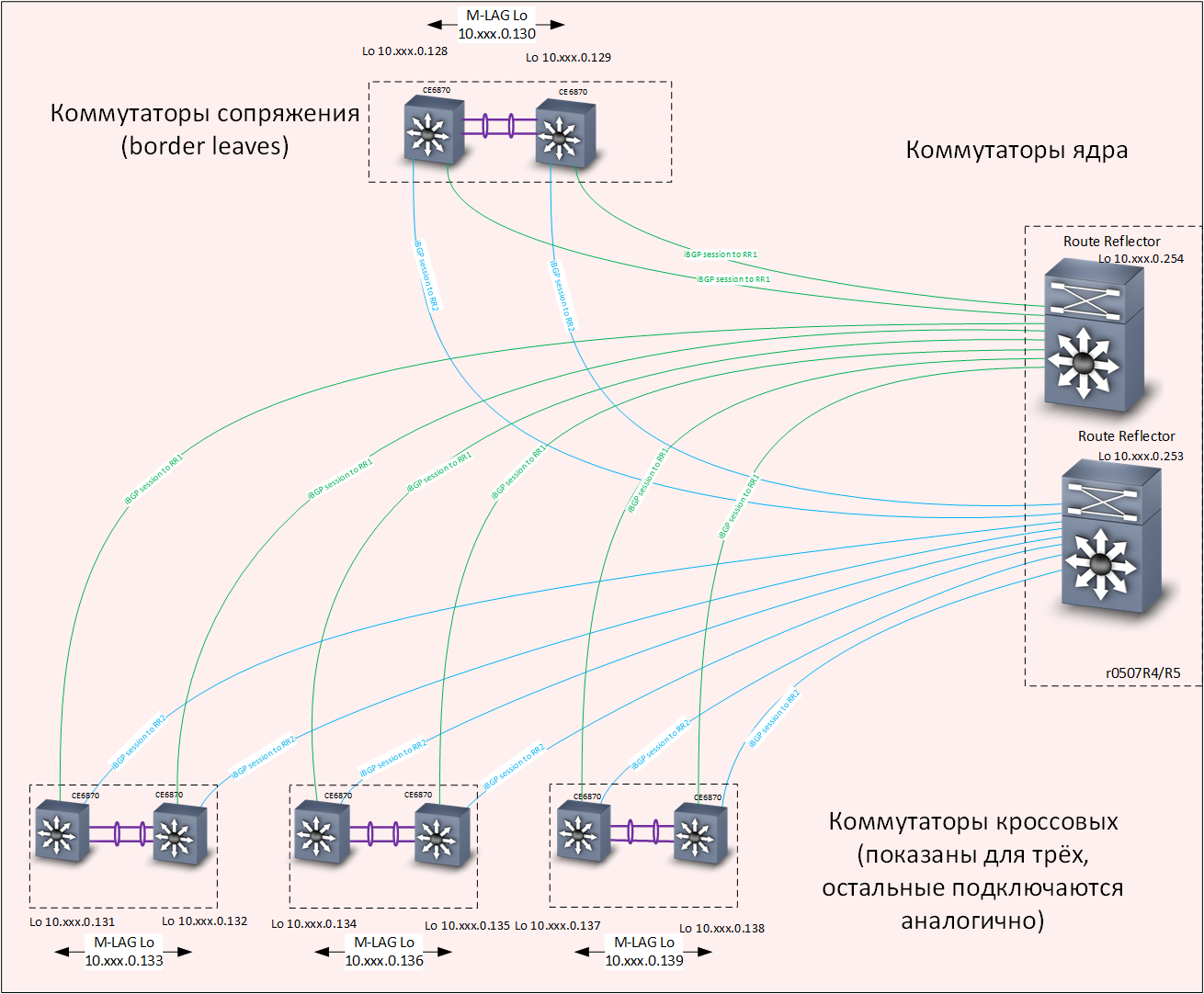 Sobreposição de nível - Roteamento
Sobreposição de nível - RoteamentoComo switches de distribuição, foram utilizados switches Huawei CE6870 com licenças VXLAN. Este dispositivo possui uma combinação ideal de preço / qualidade, permite conectar assinantes a uma velocidade de 10 Gbit / se conectar ao tronco a velocidades de 40 a 100 Gbit / s, dependendo dos transceptores usados.
 Huawei CE6870 Switches
Huawei CE6870 SwitchesComo switches principais, foram utilizados os switches Huawei CE8850. Da tarefa - para transmitir tráfego de maneira rápida e confiável. Nenhum dispositivo está conectado a eles, exceto os switches de distribuição, eles não sabem nada sobre VXLAN; portanto, foi escolhido um modelo com 32 portas de 40/100 Gbit / s, com uma licença básica que fornece roteamento L3 e suporte aos protocolos IS-IS e MP-BGP .
 O mais baixo é o comutador central Huawei CE8850
O mais baixo é o comutador central Huawei CE8850No estágio de design, surgiu uma discussão na equipe sobre tecnologias com as quais você pode implementar uma conexão à prova de falhas aos nós da rede principal. Nosso escritório em Moscou está localizado em três prédios, temos 7 salas transversais, em cada uma das quais dois switches de distribuição Huawei CE6870 foram instalados (apenas alguns switches de acesso foram instalados em várias salas transversais). Ao desenvolver o conceito de rede, duas opções de backup foram consideradas:
- A combinação de comutadores de distribuição em uma pilha à prova de falhas em cada sala transversal. Prós: simplicidade e facilidade de configuração. Contras: existe uma maior probabilidade de falha de toda a pilha ao manifestar erros no firmware dos dispositivos de rede (“vazamentos de memória” e similares).
- Aplique as tecnologias de gateway M-LAG e Anycast para conectar dispositivos a comutadores de distribuição.
Como resultado, decidimos pela segunda opção. É um pouco mais difícil de configurar, mas na prática mostrou seu desempenho e alta confiabilidade.
Considere primeiro conectar os dispositivos terminais aos comutadores de distribuição:
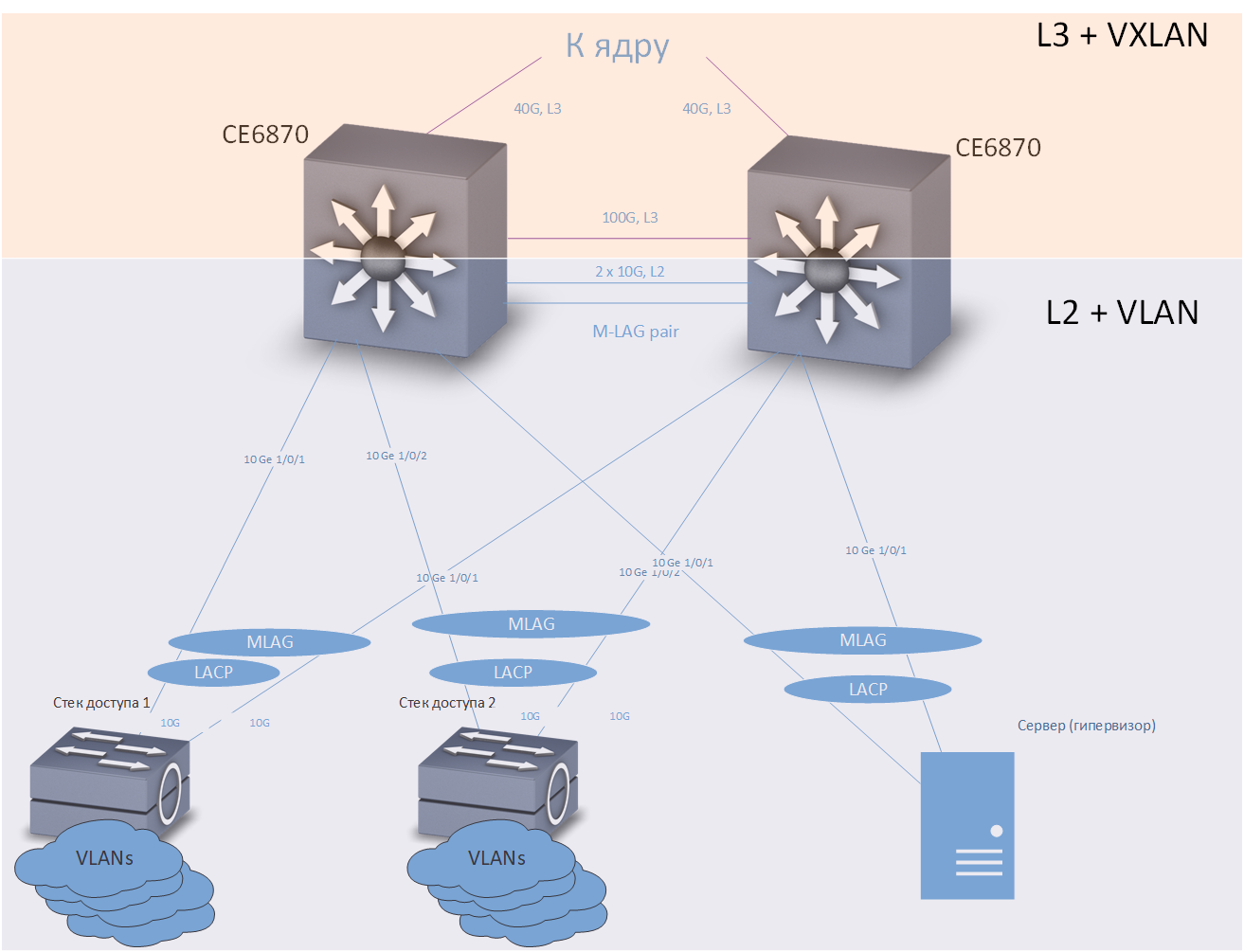 Cross
CrossUm comutador de acesso, servidor ou qualquer outro dispositivo que exija uma conexão de failover está incluído em dois comutadores de distribuição. A tecnologia M-LAG fornece redundância de link. Supõe-se que dois comutadores de distribuição se pareçam com um dispositivo para o equipamento conectado. Redundância e balanceamento de carga são realizados usando o protocolo LACP.
A tecnologia de gateway Anycast fornece redundância no nível da rede. Cada switch de distribuição é configurado com um número suficientemente grande de VRFs (cada VRF é projetado para seus próprios fins - separadamente para usuários "comuns", separadamente para telefonia, separadamente para diferentes ambientes de teste e desenvolvimento, etc.) e em cada O VRF configurou várias VLANs. Em nossa rede, os switches de distribuição são os gateways padrão para todos os dispositivos conectados a eles. Os endereços IP correspondentes às VLANs são os mesmos para os dois comutadores de distribuição. O tráfego é roteado através do switch mais próximo.
Agora considere conectar os comutadores de distribuição ao kernel:
A tolerância a falhas é fornecida no nível da rede, de acordo com o protocolo IS-IS. Observe - entre os comutadores, é fornecida uma linha de comunicação L3 separada, a uma velocidade de 100G. Fisicamente, esta linha de comunicação é um cabo de acesso direto, pode ser visto à direita na foto dos switches Huawei CE6870.
Uma alternativa seria organizar uma topologia de estrela dupla "honesta" e totalmente conectada, mas, como mencionado acima, temos 7 salas transversais em três edifícios. Portanto, se escolhermos a topologia de "estrela dupla", precisaremos exatamente o dobro do número de transceptores 40G de "longo alcance". As economias aqui são muito substanciais.
Preciso dizer algumas palavras sobre como as tecnologias de gateway VXLAN e Anycast funcionam juntas. O VXLAN, se não entrar em detalhes, é um túnel para o transporte de quadros Ethernet dentro de pacotes UDP. As interfaces de loopback dos comutadores de distribuição são usadas como o endereço IP de destino do túnel VXLAN. Cada switch possui dois switches com os mesmos endereços de interface de loopback, respectivamente, um pacote pode chegar a qualquer um deles e um quadro Ethernet pode ser extraído dele.
Se o switch souber sobre o endereço MAC de destino do quadro extraído, o quadro será entregue corretamente ao seu destino. O mecanismo M-LAG, que fornece a sincronização de tabelas de endereços MAC (bem como tabelas ARP) em ambos, é responsável por garantir que os dois comutadores de distribuição instalados em uma cruz tenham informações atualizadas sobre todos os endereços MAC "chegando" dos comutadores de acesso Comutadores de par M-LAG.
O balanceamento de tráfego é alcançado devido à presença na rede subjacente de várias rotas para as interfaces de loopback dos comutadores de distribuição.
Em vez de uma conclusão
Como mencionado acima, durante os testes e em operação, a rede mostrou alta confiabilidade (tempo de recuperação com falhas típicas de não mais do que centenas de milissegundos) e bom desempenho - cada um interconectado com o núcleo com dois canais de 40 Gbit / s. Os switches de acesso em nossa rede são empilhados e conectados aos switches de distribuição via LACP / M-LAG com dois canais de 10 Gb / s. A pilha geralmente possui 5 comutadores com 48 portas cada, até 10 pilhas de acesso são conectadas à distribuição em cada cruzamento. Assim, o backbone fornece cerca de 30 Mbit / s por usuário, mesmo com carga teórica máxima, que no momento da redação é suficiente para todas as nossas aplicações práticas.
A rede permite que você organize com facilidade o emparelhamento de qualquer dispositivo conectado arbitrário via L2 e L3, fornecendo isolamento completo do tráfego (que é apreciado pelo serviço de segurança da informação) e domínios de falha (que é apreciado pelo serviço de operação).
Na
próxima parte , descreveremos como migramos para uma nova rede. Fique atento!
Maxim Klochkov
Consultor Sênior, Auditoria de Rede e Projetos Integrados
Centro de Soluções de Rede
Jet Infosystems