
Os mecanismos de pesquisa não têm muita lógica, isso é um fato. Mas eles estão tentando. E especialistas em SEO estão tentando responder - eles estão tentando alcançar a máxima relevância das páginas, com base em suposições e experimentações.
O Google recentemente gostou de um novo fator de classificação - a correspondência neural. Lemos que os especialistas escrevem sobre isso e coletamos alguns truques que ajudarão você a escrever textos mais relevantes para solicitações.
E, a propósito, NM não é LSI para você, é um pouco mais complicado.
Em setembro de 2018, Danny Sullivan twittou que, nos últimos meses, o Google usou o método de IA Neural Matching para associar melhor as palavras aos conceitos. Esse algoritmo influenciou os resultados de 30% das solicitações em todo o mundo.

Não tínhamos pressa de escrever sobre o novo algoritmo, aguardávamos esclarecimentos do Google e pesquisas nessa área. Mas as coisas ainda estão lá - a maioria dos comentaristas mostra as mesmas capturas de tela e fala sobre a transição da busca por palavras para a busca por intenção. Eles também se referem ao Deep Relevance Matching Model (DRMM) .
Vamos tentar descobrir que tipo de animal esse Neural Matching é e como adaptar o conteúdo do site para ele.
Exemplos de correspondência neural
Danny Sullivan descreve o que é a correspondência neural. Ele deu um exemplo de emissão da consulta "por que minha TV parece estranha"? O usuário entra nessa consulta quando ainda não sabe qual é o efeito da novela. Mas o Google, graças ao novo algoritmo, sabe exatamente o que você precisa:

Em russo, uma história semelhante:

Outro exemplo Você conheceu um inseto "bonito" no apartamento e não faz ideia do nome:

Vamos ao Google, inserimos um conjunto de recursos e, na primeira posição, obtemos a resposta relevante:

A implementação da Correspondência Neural se deve ao fato de os usuários nem sempre saberem o que estão procurando e nem sempre formulam corretamente as solicitações. Danny Sullivan mostrou várias dessas consultas "erradas":

A tarefa da correspondência neural é determinar a verdadeira intenção (pesquisa) e produzir os resultados corretos.

Para determinar a intenção, não são usadas palavras separadas, mas essências e relações entre elas. Veja como funciona - no exemplo das consultas "ficou bêbado o que fazer" e "ficou bêbado durante a noite".
Cada solicitação contém a mesma entidade - "ficou bêbado". Mas combiná-lo com a essência de "overnight" indica ao mecanismo de busca que o usuário quer comer demais. E a essência do "o que fazer" está provavelmente associada à intoxicação.

Como o Google define a intenção - a semântica é semelhante? O mecanismo de pesquisa compara a frequência com que as entidades combinadas na solicitação são encontradas lado a lado nas páginas. Além disso, as estatísticas das solicitações são levadas em consideração (os usuários que entram na solicitação "ficam bêbados à noite" geralmente clicam nos artigos especificamente sobre comer demais).
Outro exemplo O usuário digita a frase "colocar janelas". Este é apenas o pedido "errado" de que Danny Sullivan está falando. O Google entende que uma pessoa por "colocar" significa algo diferente de uma simples instalação do Windows e exibe no TOP os resultados corretos do ponto de vista dele:
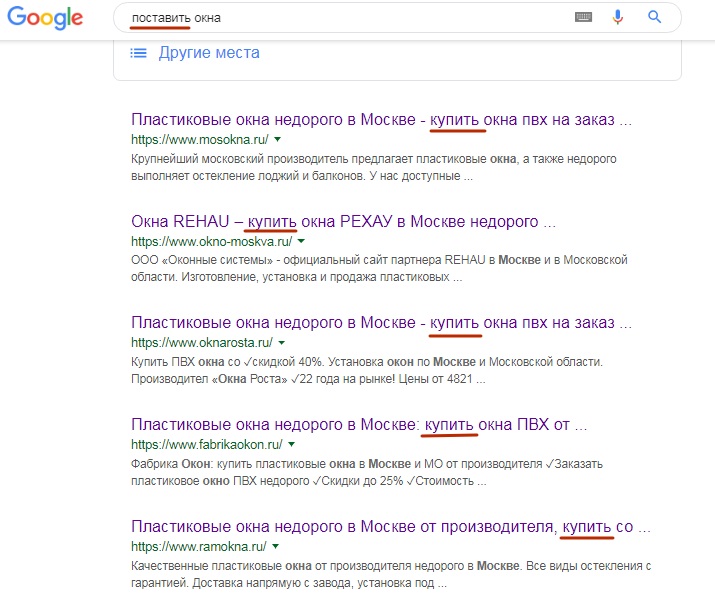
Nesse caso, apenas uma página do TOP-6 contém a palavra "entregar" (no significado de "provedor de janelas" e não "instalar o Windows você mesmo"). Nas páginas restantes do TOP-6, não há uma palavra "colocar", nem mesmo palavras raiz. Embora resultados como "Como instalar o Windows você mesmo", etc., já estejam misturados abaixo.
Isso leva a uma conclusão aparentemente paradoxal: para ocupar posições altas em muitas palavras, não é necessário saturar textos com semântica semelhante a uma consulta de pesquisa. A relevância do conteúdo é avaliada por um conjunto de entidades (frases), com grande probabilidade de satisfazer a intenção de pesquisa.
Isso muda a abordagem para escrever textos de SEO: antes as chaves eram o ponto de referência, agora o público precisa.
Classificação da relevância dos documentos e correspondência neural - como isso afetará o SEO?
Roger Montti sugeriu em um artigo do Search Engine Journal que o algoritmo de correspondência neural poderia funcionar com base no método de classificação de relevância de documentos (DRR). O método é descrito no artigo " Classificação de relevância profunda usando interações aprimoradas de consulta a documentos ", publicado no Google AI.
A essência do método DRR é que, ao determinar a relevância de um documento, seu texto é usado exclusivamente. Outros fatores - links, âncoras, menções, SEO na página - não importam.
O que, os links não são mais necessários? Não é bem assim. A classificação de acordo com o método DRR descrito faz parte do algoritmo geral de classificação. Na primeira etapa, a emissão é formada levando em consideração todos os fatores de classificação (links, chaves, “mobilidade”, geolocalização, etc.). Portanto, o mecanismo de pesquisa elimina o conteúdo base e identifica sites respeitáveis. Na segunda etapa, a RRD entra no trabalho - entre os melhores resultados, ele seleciona os mais relevantes (mas leva em conta apenas o texto).
Na prática, pode ser assim. Existem dois sites: um muito respeitável e jovem. O site jovem contém super conteúdo que não possui análogos no nicho, cheio de detalhes e especificidades. Porém, como existem mais links para um site oficial, sua página ocupa a primeira posição e a página de um site jovem ocupa a décima. E aqui a DRR entra em operação - o mecanismo de pesquisa verifica os textos e percebe que o conteúdo do site jovem é mais significativo do que o conteúdo de um site oficial. A conseqüência é a mudança do site jovem para uma posição mais alta.
Como criar conteúdo em Correspondência Neural
Se a correspondência neural funciona com base na RRD ou não, isso não é importante. É importante que a intenção de pesquisa "dirija" aqui. Não são longos "calçados", nem a densidade das palavras-chave, nem os sinônimos.

Antes de criar conteúdo, decida:
- para quem ele é (é melhor realizar pesquisas, fazer retratos de usuários e escrever para eles);
- por que é necessário (que tarefa é encerrada);
- o que há nele que os concorrentes não têm (que valor isso traz).
Para aumentar a relevância dos textos, além de consultas básicas, use entidades estreitamente relacionadas. Se o texto for escrito por um especialista, essas entidades provavelmente estarão no texto. Outra questão é quando o redator recebe TK - nesse caso, é necessário determinar as entidades e indicá-las na tarefa.
Vamos considerar os métodos de coleta de entidades usando o exemplo de uma categoria da loja online "Geradores de gasolina".
1. Procure por perguntas / respostas
Você pode identificar as necessidades do usuário usando fóruns, comentários em artigos de blog e discussões em redes sociais. Tudo funciona. Mas é mais fácil ir para Answers@Mail.ru (ou a contraparte ocidental - Quora ), inserir uma consulta de pesquisa, fazer perguntas e destacar as entidades associadas às principais chaves.
A pedido de "geradores a gasolina" mail.ru emite 1624 perguntas. Percorremos a lista e selecionamos as entidades que caracterizam as necessidades do público-alvo.


Depois de selecionar as entidades, pensamos que conteúdo é adequado para elas. Por exemplo, o consumo de gasolina por 1 hora e os métodos de uso do gerador (para soldagem, caldeira, iluminação etc.) devem ser indicados na descrição de mercadorias específicas. Na descrição da rubrica “Geradores a gasolina”, você pode descrever brevemente como os geradores a gasolina diferem de gás, inversor, etc. Um problema com a operação de geradores é descrito no artigo do blog.
O processamento de perguntas nos serviços de controle de qualidade é meticuloso, mas permite destacar as reais necessidades do público, das quais você talvez não tenha adivinhado.
Você pode tentar simplificar o trabalho usando o serviço Responder ao público . Ele coleta perguntas, comparações e várias formulações que ocorrem na rede com a ocorrência de uma determinada frase.

A única desvantagem é o serviço em inglês. A tradução da frase desejada resolve parcialmente o problema. Mas no segmento comercial, vale lembrar as peculiaridades dos mercados (o que preocupa os índios pode ser inútil para os russos).
2. Análise de frases de associação
Sob os resultados da pesquisa, o bloco "Juntamente com ... frequentemente pesquisado" é exibido - frases que o próprio mecanismo de pesquisa associa à frase original ("geradores a gasolina") são coletadas aqui.

A análise de frases de associação permite identificar entidades relacionadas: 5 kW, 3 kW, 10 kW, inversor, 1 kW.
Resta pensar em como incluí-los no conteúdo. Por exemplo, na descrição da coluna “geradores movidos a gasolina”, vale dizer com que finalidade geradores de diferentes potências (1, 3, 5, 10 kW) e tipo (inversor convencional etc.) são adequados.
Se você tiver muitas solicitações iniciais, colete associações manualmente por um longo tempo - use o analisador .
3. Analisando dicas de pesquisa
As dicas são outra fonte para correspondência de entidades relacionadas.

Reabastecemos a lista de entidades coletadas de associações: com execução automática, diesel, 380 volts, silenciosa. Estas são palavras que caracterizam bem os problemas do usuário.
Há também um analisador para coletar dicas.
Em princípio, os métodos discutidos são suficientes para se ter uma idéia das necessidades do público. Mas se você quiser estudar a semântica ainda mais profundamente, aqui estão duas maneiras opcionais.
4. Seleção de quase-sinônimos
Quase-sinônimos (associações semânticas) são palavras que têm significado próximo, mas não são intercambiáveis em diferentes contextos. Por exemplo, as palavras "gerador" e "gerador automático" são sinônimos no texto de peças de reposição para automóveis, mas não serão iguais no texto em tipos de geradores.
Os quase-sinônimos são determinados com base na frequência de sua ocorrência nos textos. Para resolver esse problema, existe um serviço da RusVect (seção “Palavras semelhantes”). Digite a palavra de interesse, marque todos os modelos e partes do discurso disponíveis e inicie a pesquisa.

Como resultado, você obterá os 10 associados mais significativos para cada modelo de pesquisa. Cegamente usá-los na formação de TK não vale a pena - haverá muito "lixo" aqui (ainda é preferível analisar associações com base em dados dos mecanismos de pesquisa). No entanto, você pode identificar palavras interessantes. Por exemplo, vemos que as palavras "gerador de gás", "inversor", "gerador de gás", "contator" etc. estão associadas à palavra "gerador".
5. Analisando textos de concorrentes
Para identificar as necessidades do público, esse método não é o melhor. Em primeiro lugar, não se sabe quando o conteúdo foi criado nos sites dos concorrentes (durante esse período, as preferências de pesquisa podem mudar). Em segundo lugar, não há garantia de que os concorrentes analisaram cuidadosamente os problemas do público e criaram textos com base neles.
Por outro lado, se você usar esse método como auxiliar, haverá uma chance de identificar entidades que você pode perder.
Assim, inserimos a consulta principal "geradores a gasolina" na pesquisa, copiamos os textos relevantes dos sites para o TOP-10 e selecionamos a semântica usando o Advego :

Complementamos a lista de entidades relevantes: 4 tempos, emergência, autônoma, ininterrupta, para chalé de verão, para a natureza etc.
Juntando tudo e otimizando o TK para a correspondência neural.
TK para letra: faça correspondência neural, não LSI
Após a coleta das entidades relevantes, você deve escrever o texto. Mas não basta apenas especificar as chaves e uma lista de sinônimos e palavras relacionadas no TOR, como geralmente é feito ao solicitar textos LSI .

Exemplo de TK para texto LSI
Com base em tal TK - simplesmente com uma lista de palavras - às vezes são obtidos textos bastante estranhos.
Uma prática comum entre redatores é escrever um texto e só então inserir as palavras fornecidas. Isso é mais fácil, pois você não precisa interromper a seleção e a inserção de palavras no processo de composição do texto. Mas essas inserções retroativamente podem quebrar - e freqüentemente quebram - a lógica e o estilo do texto.
O texto em Correspondência neural é sobre usuários e suas necessidades, não sobre chaves e mais palavras. Portanto, recursos puramente de marketing aparecem no TK: descrições do consumidor e seus motivos. As teclas e as palavras mais aparecem no fundo - elas são usadas como marcadores, e não como elementos obrigatórios. Seu lugar é ocupado pelas necessidades de informação do público.

Exemplo TK em Correspondência Neural
Esse TK permite que o autor entenda claramente para quem é o texto, por que e em que circunstâncias ele será lido. Esse TK não apenas indica as palavras a serem usadas, mas fornece instruções - sobre o que escrever para usá-las.
A correspondência neural, ao otimizar as páginas de pesquisa, muda a ênfase da mecânica puramente de SEO para o marketing. De fato, essa tendência é observada há vários anos. A correspondência neural é apenas mais um passo em direção à otimização de mecanismos de pesquisa com um rosto humano.
A otimização do conteúdo para a correspondência neural exige tempo e trabalho. É muito mais fácil soltar as chaves do AX no TK, analisar mais palavras e dizer ao redator: "Escreva para as pessoas". Mas com o desenvolvimento da pesquisa por IA, essa abordagem será cada vez menos eficaz.