Gerenciamento de cluster eficiente e confiável em qualquer escala com o Tupperware

Hoje, na conferência Systems @Scale, apresentamos o Tupperware, nosso sistema de gerenciamento de cluster que orquestra contêineres em milhões de servidores, onde quase todos os nossos serviços funcionam. Lançamos o Tupperware pela primeira vez em 2011 e, desde então, nossa infraestrutura cresceu de 1 data center para 15 data centers distribuídos geograficamente . Todo esse tempo a Tupperware não parou e se desenvolveu conosco. Informaremos em que situações a Tupperware fornece gerenciamento de cluster de primeira classe, incluindo suporte conveniente para serviços com estado, um painel de controle único para todos os data centers e a capacidade de distribuir energia entre serviços em tempo real. E compartilharemos as lições que aprendemos à medida que nossa infraestrutura se desenvolveu.
Tupperware executa várias tarefas. Os desenvolvedores de aplicativos o utilizam para fornecer e gerenciar aplicativos. Ele compacta as dependências de código e aplicativo em uma imagem e as entrega aos servidores na forma de contêineres. Os contêineres fornecem isolamento entre aplicativos no mesmo servidor, para que os desenvolvedores estejam ocupados com a lógica do aplicativo e não pensem em como encontrar servidores ou controlar atualizações. A Tupperware também monitora o desempenho do servidor e, se encontrar uma falha, transfere contêineres do servidor com problema.
Os engenheiros de planejamento de capacidade usam o Tupperware para distribuir as capacidades do servidor em equipes de acordo com o orçamento e as restrições. Eles também o usam para melhorar a utilização do servidor. Os operadores de data center recorrem à Tupperware para distribuir adequadamente os contêineres entre os data centers e parar ou mover contêineres durante a manutenção. Devido a isso, a manutenção de servidores, redes e equipamentos requer um envolvimento humano mínimo.
Arquitetura Tupperware
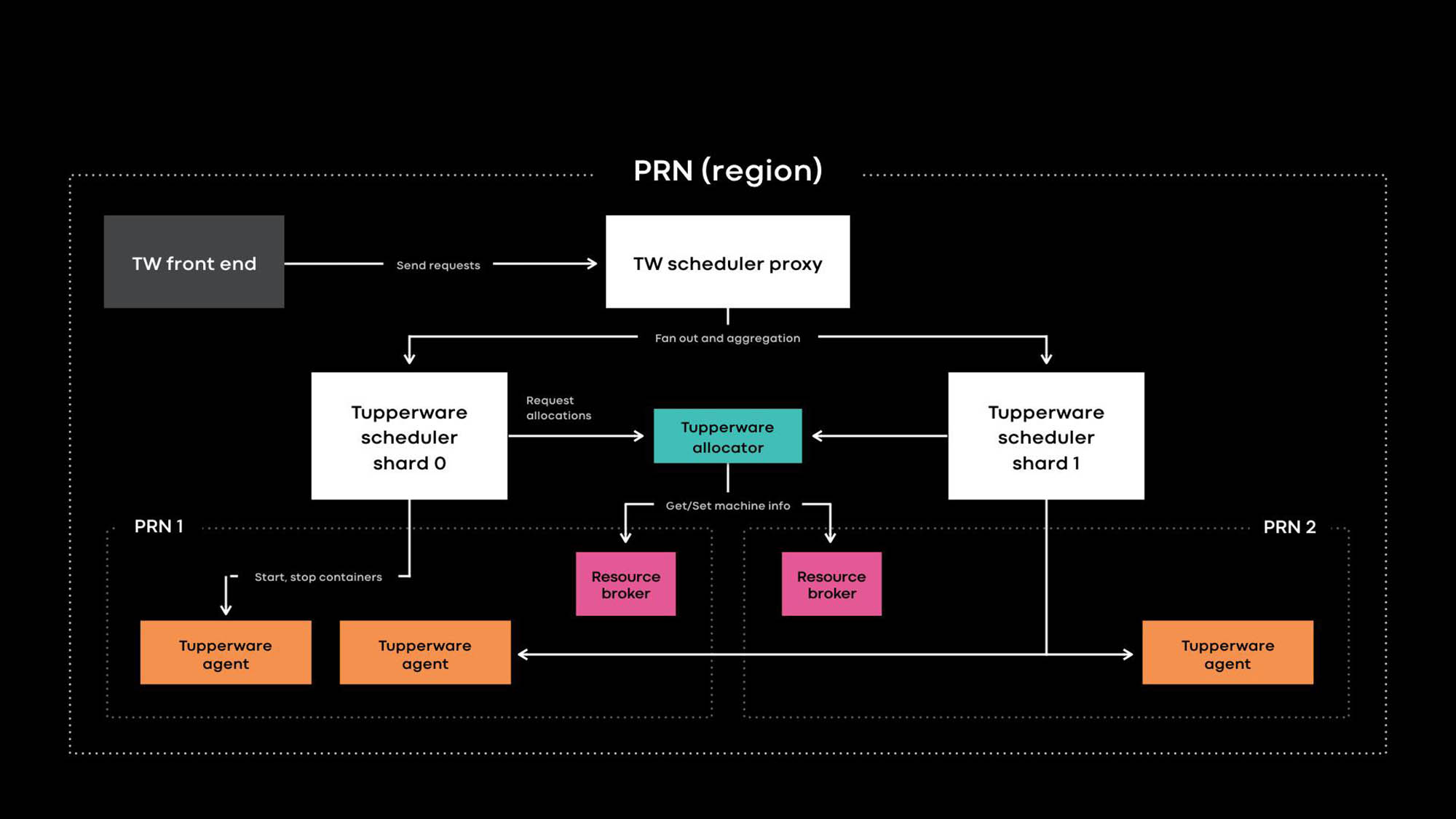
Arquitetura O Tupperware PRN é uma das regiões de nossos data centers. A região consiste em vários edifícios de data center (PRN1 e PRN2) localizados nas proximidades. Planejamos criar um painel de controle que gerencie todos os servidores em uma região.
Os desenvolvedores de aplicativos fornecem serviços na forma de trabalhos da Tupperware. Uma tarefa consiste em vários contêineres, e todos eles geralmente executam o mesmo código de aplicativo.
A Tupperware é responsável pelo provisionamento de contêineres e pelo gerenciamento do ciclo de vida. Consiste em vários componentes:
- O Tupperware Frontend fornece uma API para a interface do usuário, a CLI e outras ferramentas de automação por meio das quais você pode interagir com o Tupperware. Eles ocultam toda a estrutura interna dos proprietários de tarefas da Tupperware.
- O Tupperware Scheduler é o painel de controle responsável pelo gerenciamento do ciclo de vida do contêiner e do trabalho. Ele é implantado nos níveis regional e global, onde um agendador regional gerencia servidores em uma região e um agendador global gerencia servidores de diferentes regiões. O planejador é dividido em shards, e cada shard controla um conjunto de tarefas.
- O proxy do planejador no Tupperware oculta o sharding interno e fornece um painel de controle unificado conveniente para os usuários do Tupperware.
- O distribuidor Tupperware atribui contêineres aos servidores. O planejador é responsável por interromper, iniciar, atualizar e falhar contêineres. Atualmente, um único distribuidor pode gerenciar uma região inteira sem se dividir em shards. (Observe a diferença na terminologia. Por exemplo, o planejador no Tupperware corresponde ao painel de controle no Kubernetes , e o distribuidor do Tupperware é chamado de planejador no Kubernetes.)
- O intermediário de recursos armazena a fonte da verdade para os eventos do servidor e de serviço. Executamos um intermediário de recursos para cada data center e ele armazena todas as informações do servidor nesse data center. Um intermediário de recursos e um sistema de gerenciamento de capacidade, ou sistema de alocação de recursos, decidem dinamicamente qual fornecimento de planejador controla qual servidor. O serviço de verificação de integridade monitora servidores e armazena dados sobre sua saúde no intermediário de recursos. Se o servidor tiver problemas ou precisar de manutenção, o intermediário de recursos solicitará ao distribuidor e ao planejador que parem os contêineres ou os transfiram para outros servidores.
- O Tupperware Agent é um daemon em execução em cada servidor que prepara e remove contêineres. Os aplicativos funcionam dentro do contêiner, o que lhes confere mais isolamento e reprodutibilidade. Na conferência Systems @Scale do ano passado, já descrevemos como os contêineres Tupperware individuais são criados usando imagens, btrfs, cgroupv2 e systemd.
Recursos distintos do Tupperware
O Tupperware é muito semelhante a outros sistemas de gerenciamento de cluster, como Kubernetes e Mesos , mas existem algumas diferenças:
- Suporte nativo para serviços com estado.
- Um único painel de controle para servidores em diferentes data centers para automatizar a entrega de contêineres com base em intenção, desclassificação de clusters e manutenção.
- Separação clara do painel de controle para zoom.
- Cálculos flexíveis permitem distribuir energia entre serviços em tempo real.
Projetamos esses recursos interessantes para oferecer suporte a uma variedade de aplicativos sem estado e sem estado em um enorme parque de servidores compartilhados globalmente.
Suporte nativo para serviços com estado.
A Tupperware gerencia muitos serviços stateful críticos que armazenam dados persistentes de produtos para Facebook, Instagram, Messenger e WhatsApp. Podem ser grandes pares de valores-chave (por exemplo, ZippyDB ) e armazenamento de dados de monitoramento (por exemplo, ODS Gorilla e Scuba ). Manter serviços com estado não é fácil, porque o sistema deve garantir que as entregas de contêineres possam suportar falhas em grande escala, incluindo uma queda de energia ou uma queda de energia. Embora os métodos convencionais, como a distribuição de contêineres pelos domínios de falha, sejam adequados para serviços sem estado, os serviços com estado precisam de suporte adicional.
Por exemplo, se, como resultado de uma falha no servidor, uma réplica do banco de dados se tornar indisponível, é necessário permitir a manutenção automática que atualizará os kernels em 50 servidores a partir de um pool de 10 milésimos? Depende da situação. Se em um desses 50 servidores houver outra réplica do mesmo banco de dados, é melhor aguardar e não perder duas réplicas de uma só vez. Para tomar decisões dinamicamente sobre a manutenção e a integridade do sistema, você precisa de informações sobre a replicação de dados internos e a lógica de localização de cada serviço com estado.
A interface TaskControl permite que serviços com estado influenciem decisões que afetam a disponibilidade de dados. Usando essa interface, o planejador notifica aplicativos externos sobre operações de contêiner (reinicialização, atualização, migração, manutenção). O serviço Stateful implementa um controlador que informa ao Tupperware quando cada operação pode ser executada com segurança e essas operações podem ser trocadas ou atrasadas temporariamente. No exemplo acima, o controlador do banco de dados pode instruir a Tupperware a atualizar 49 dos 50 servidores, mas não tocar em um servidor específico (X) até o momento. Como resultado, se o período de atualização do kernel passar e o banco de dados ainda não conseguir restaurar a réplica do problema, o Tupperware ainda atualizará o servidor X.

Muitos serviços com estado no Tupperware não usam o TaskControl diretamente, mas através do ShardManager, uma plataforma comum para a criação de serviços com estado no Facebook. Com a Tupperware, os desenvolvedores podem indicar sua intenção de como os contêineres devem ser distribuídos pelos datacenters. Com o ShardManager, os desenvolvedores indicam sua intenção de como os shards de dados devem ser distribuídos pelos contêineres. O ShardManager está ciente da hospedagem e replicação de dados de seus aplicativos e interage com o Tupperware por meio da interface TaskControl para planejar operações de contêiner sem o envolvimento direto do aplicativo. Essa integração simplifica bastante o gerenciamento de serviços com estado, mas o TaskControl é capaz de mais. Por exemplo, nossa extensa camada da web é sem estado e usa o TaskControl para ajustar dinamicamente a velocidade das atualizações em contêineres. Como resultado, a camada da Web pode concluir rapidamente várias versões de software por dia, sem comprometer a disponibilidade.
Gerenciamento de servidor em data centers
Quando a Tupperware apareceu pela primeira vez em 2011, um agendador separado controlava cada cluster de servidores. Em seguida, o cluster do Facebook era um grupo de racks de servidores conectados a um comutador de rede, e o datacenter continha vários clusters. O planejador pode gerenciar servidores em apenas um cluster, ou seja, a tarefa não pode se estender a vários clusters. Nossa infraestrutura estava crescendo, estávamos cada vez mais cancelando clusters. Como o Tupperware não pôde transferir a tarefa do cluster descomissionado para outros clusters sem alterações, foi necessário muito esforço e coordenação cuidadosa entre os desenvolvedores de aplicativos e os operadores de data center. Esse processo levou a um desperdício de recursos quando os servidores ficaram ociosos por meses devido ao procedimento de descomissionamento.
Criamos um intermediário de recursos para resolver o problema de desclassificação de clusters e coordenar outros tipos de tarefas de manutenção. O intermediário de recursos monitora todas as informações físicas associadas ao servidor e decide dinamicamente qual planejador gerencia cada servidor. A ligação dinâmica de servidores a agendadores permite que o agendador gerencie servidores em diferentes datacenters. Como o trabalho da Tupperware não se limita mais a um cluster, os usuários da Tupperware podem especificar como os contêineres devem ser distribuídos pelos domínios de falha. Por exemplo, um desenvolvedor pode declarar sua intenção (por exemplo: "executar minha tarefa em 2 domínios de falha na região PRN") sem especificar zonas de disponibilidade específicas. A própria Tupperware encontrará os servidores certos para incorporar essa intenção, mesmo no caso de descomissionamento de um cluster ou serviço.
Escalonamento para suportar todo o sistema global
Historicamente, nossa infraestrutura foi dividida em centenas de pools de servidores dedicados para equipes individuais. Devido à fragmentação e à falta de padrões, tínhamos altos custos de transação e servidores inativos eram mais difíceis de usar novamente. Na conferência Systems @Scale do ano passado, introduzimos a infraestrutura como serviço (IaaS) , que deve integrar nossa infraestrutura a uma grande frota de servidores unificada. Mas uma única frota de servidores tem suas próprias dificuldades. Ele deve atender a certos requisitos:
- Escalabilidade. Nossa infraestrutura cresceu com a adição de data centers em cada região. Os servidores tornaram-se menores e mais eficientes em termos de energia; portanto, em cada região há muito mais. Como resultado, um único planejador para uma região não pode lidar com o número de contêineres que podem ser executados em centenas de milhares de servidores em cada região.
- Confiabilidade Mesmo que a escala do planejador possa ser aumentada, devido ao grande escopo do planejador, o risco de erros será maior e toda a região de contêineres poderá se tornar incontrolável.
- Tolerância a falhas. No caso de uma grande falha na infraestrutura (por exemplo, devido a uma falha na rede ou falta de energia, os servidores em que o agendador está executando falharão), apenas uma parte dos servidores da região terá consequências negativas.
- Facilidade de uso. Pode parecer que você precise executar vários agendadores independentes em uma região. Mas em termos de conveniência, um único ponto de entrada em um pool comum na região simplifica o gerenciamento de capacidade e trabalho.
Dividimos o planejador em shards para resolver problemas de suporte a um grande pool compartilhado. Cada fragmento do planejador gerencia seu conjunto de tarefas na região, e isso reduz o risco associado ao planejador. À medida que o pool total cresce, podemos adicionar mais shards do agendador. Para usuários da Tupperware, os shards e os agendadores de proxy se parecem com um painel de controle. Eles não precisam trabalhar com muitos fragmentos que orquestram tarefas. Os shards do agendador são fundamentalmente diferentes dos agendadores de cluster que usamos anteriormente, quando o painel de controle foi dividido sem separação estática do pool de servidores comum, de acordo com a topologia de rede.
Melhorando a utilização com computação elástica
Quanto maior a nossa infraestrutura, mais importante é usar nossos servidores com eficiência para otimizar os custos da infraestrutura e reduzir a carga. Existem duas maneiras de melhorar a utilização do servidor:
- Computação flexível - reduza a escala de serviços online durante horas tranquilas e use os servidores liberados para cargas offline, por exemplo, para aprendizado de máquina e tarefas MapReduce.
- Carga excessiva - hospede serviços online e cargas de trabalho em lote nos mesmos servidores para que as cargas em lote sejam executadas com baixa prioridade.
O gargalo em nossos data centers é o consumo de energia . Portanto, preferimos servidores pequenos e com baixo consumo de energia, que juntos fornecem mais poder de processamento. Infelizmente, em pequenos servidores com uma pequena quantidade de recursos e memória do processador, o carregamento excessivo é menos eficiente. Obviamente, podemos colocar vários contêineres de pequenos serviços em um pequeno servidor com baixo consumo de energia que consome poucos recursos e memória do processador, mas os serviços grandes terão baixo desempenho nessa situação. Portanto, aconselhamos os desenvolvedores de nossos grandes serviços a otimizá-los para que usem o servidor inteiro.
Basicamente, aprimoramos a utilização com computação elástica. A intensidade do uso de muitos de nossos grandes serviços, por exemplo, feeds de notícias, recursos de mensagens e nível da web de front-end, depende da hora do dia. Intencionalmente reduzimos a escala de serviços online durante horas tranquilas e usamos os servidores liberados para cargas offline, por exemplo, para tarefas de aprendizado de máquina e MapReduce.
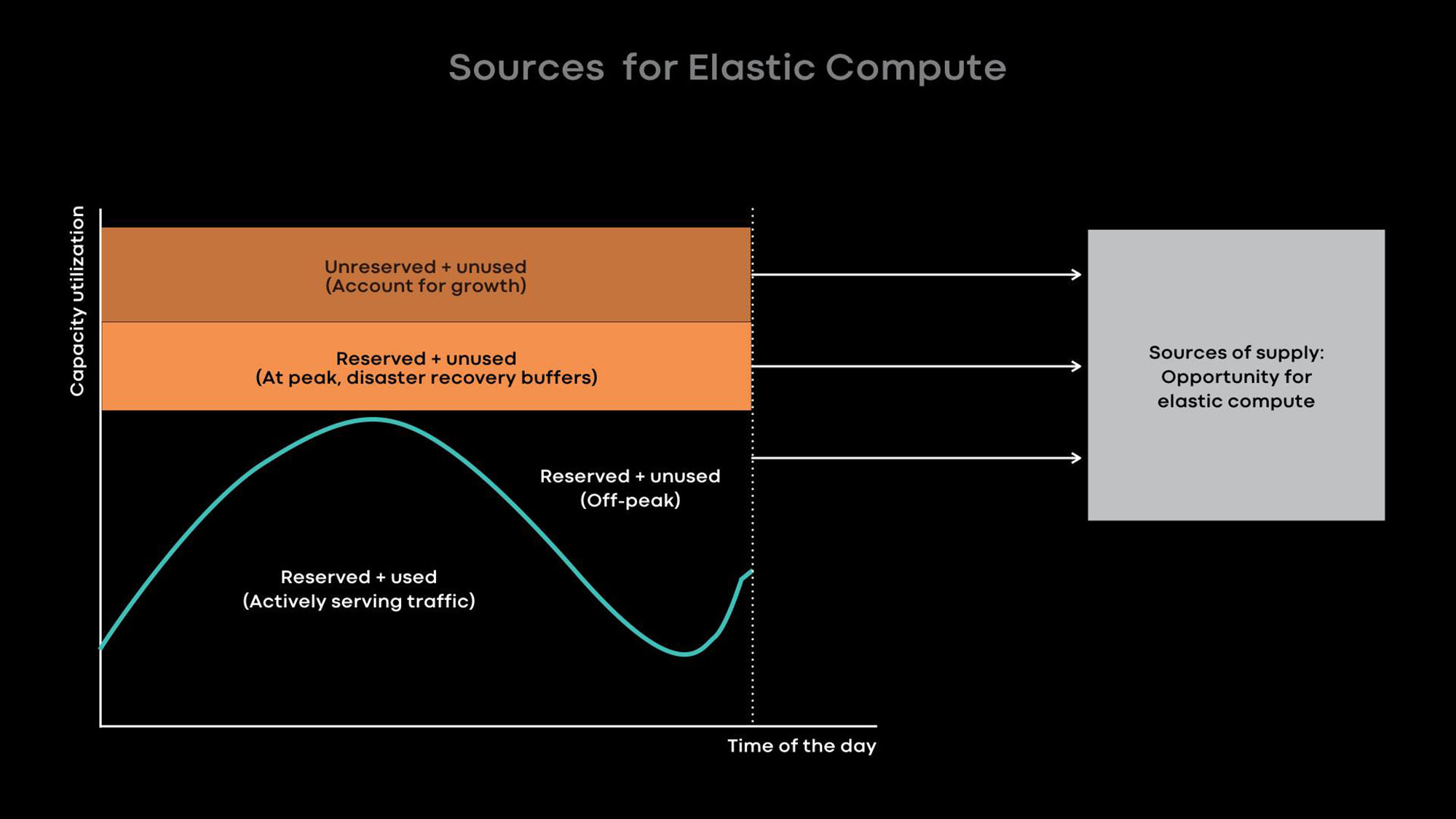
Por experiência, sabemos que é melhor fornecer servidores inteiros como unidades de energia elástica, porque os grandes serviços são os principais doadores e os principais consumidores de energia elástica e são otimizados para o uso de servidores inteiros. Quando o servidor é liberado do serviço online nas horas tranquilas, o intermediário de recursos entrega o servidor ao planejador para uso temporário, para que ele execute carregamentos offline. Se ocorrer um pico de carga em um serviço online, o intermediário de recursos recupera rapidamente o servidor emprestado e, juntamente com o planejador, o retorna ao serviço online.
Lições aprendidas e planos futuros
Nos últimos 8 anos, desenvolvemos a Tupperware para acompanhar o rápido desenvolvimento do Facebook. Falamos sobre o que aprendemos e esperamos que ajude outras pessoas a gerenciar infraestruturas em rápido crescimento:
- Configure comunicações flexíveis entre o painel de controle e os servidores que gerencia. Essa flexibilidade permite ao painel de controle gerenciar servidores em diferentes datacenters, ajuda a automatizar o descomissionamento e manutenção de clusters e fornece distribuição dinâmica de energia usando computação flexível.
- Com um único painel de controle na região, fica mais conveniente trabalhar com tarefas e mais fácil gerenciar uma grande frota comum de servidores. Observe que o painel de controle suporta um único ponto de entrada, mesmo que sua estrutura interna seja dividida por razões de escala ou tolerância a falhas.
- Usando o modelo de plug-in, o painel de controle pode notificar aplicativos externos sobre as próximas operações de contêiner. Além disso, os serviços com estado podem usar a interface do plug-in para configurar o gerenciamento de contêiner. Usando esse modelo de plug-in, o painel de controle fornece simplicidade e serve efetivamente a muitos serviços com estado diferentes.
- Acreditamos que a computação elástica, na qual contratamos servidores inteiros para trabalhos em lotes, aprendizado de máquina e outros serviços não urgentes dos serviços de doadores, é a melhor maneira de aumentar a eficiência do uso de servidores pequenos e com baixo consumo de energia.
Estamos apenas começando a implementar um único parque de servidores comum global . Agora, cerca de 20% dos nossos servidores estão no pool comum. Para atingir 100%, você precisa resolver muitos problemas, incluindo o suporte a um pool comum para sistemas de armazenamento, automatizando a manutenção, gerenciando os requisitos de diferentes clientes, melhorando a utilização do servidor e melhorando o suporte para cargas de trabalho de aprendizado de máquina. Mal podemos esperar para realizar essas tarefas e compartilhar nossos sucessos.