Meu nome é Marko e eu conversei na
Gophercon Russia este ano sobre um tipo muito interessante de índices chamado "índices de bitmap". Eu queria compartilhá-lo com a comunidade, não apenas no formato de vídeo, mas também como um artigo. É uma versão em inglês e você pode ler russo
aqui . Por favor, aproveite!

Materiais adicionais, slides e todo o código-fonte podem ser encontrados aqui:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Gravação de vídeo original:
Vamos começar!
1. Introdução

Hoje eu vou falar sobre
- O que são índices.
- O que é um índice de bitmap;
- Onde é usado. Por que não é usado onde não é usado.
- Vamos ver uma implementação simples no Go e depois tentar no compilador.
- Em seguida, veremos uma implementação um pouco menos simples, mas visivelmente mais rápida, no assembly Go.
- E depois disso, vou abordar os "problemas" dos índices de bitmap, um por um.
- E, finalmente, veremos quais são as soluções existentes.
Então, o que são índices?
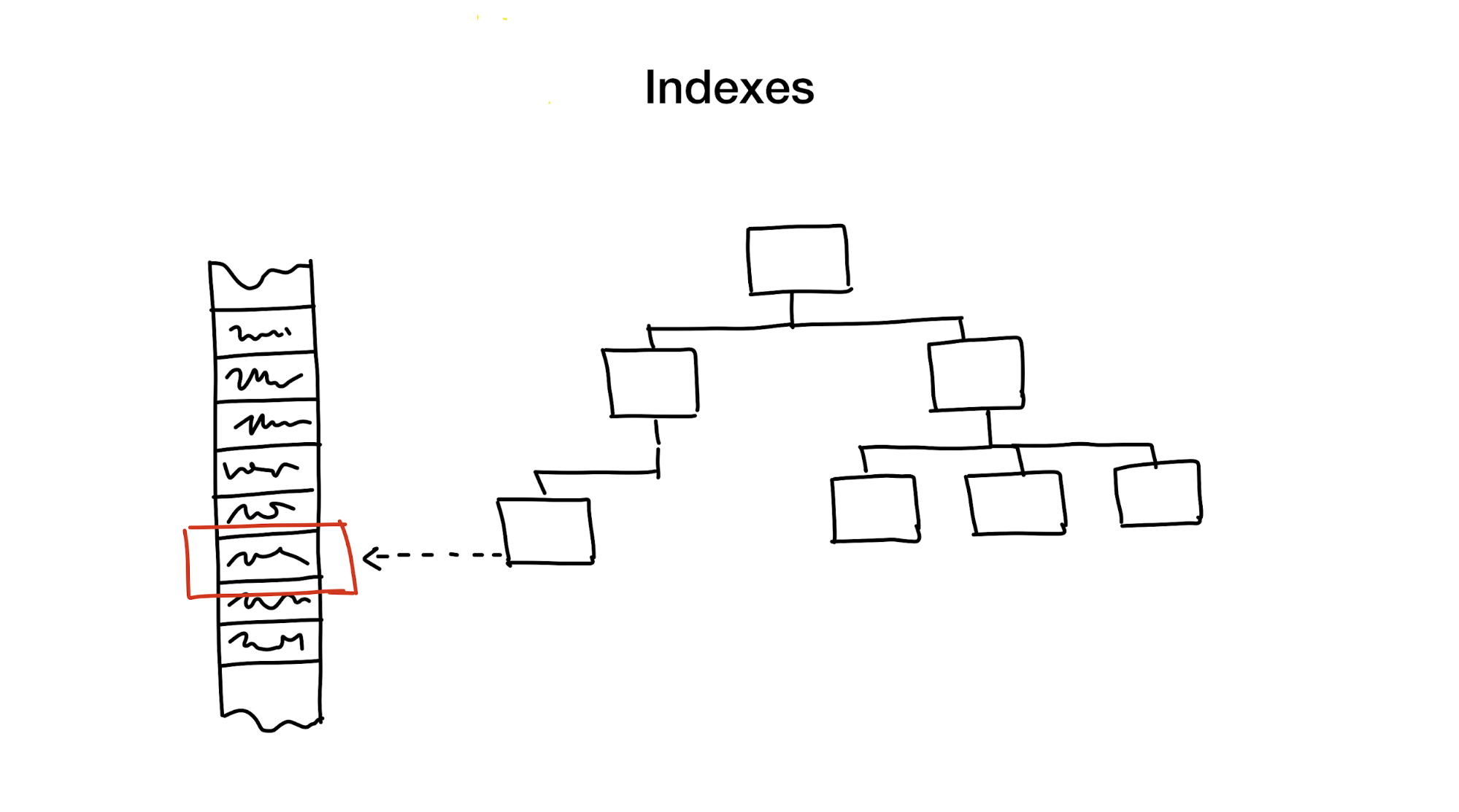
Um índice é uma estrutura de dados distinta que é mantida atualizada além dos dados principais, usada para acelerar solicitações de pesquisa. Sem índices, a pesquisa envolveria passar por todos os dados (em um processo também conhecido como "verificação completa") e esse processo possui complexidade algorítmica linear. Mas os bancos de dados geralmente contêm grandes quantidades de dados, portanto a complexidade linear é muito lenta. Idealmente, gostaríamos de atingir velocidades de complexidade logarítmica ou mesmo constante.
Esse é um tópico enorme e complexo que envolve muitas trocas, mas olhando para trás ao longo de décadas de implementações e pesquisas de banco de dados, eu argumentaria que existem apenas algumas abordagens que são comumente usadas:

Primeiro, é reduzir a área de pesquisa cortando toda a área em partes menores, hierarquicamente.
Geralmente, isso é conseguido usando árvores. É semelhante a ter caixas de caixas em seu guarda-roupa. Cada caixa contém materiais que são posteriormente classificados em caixas menores, cada uma para um uso específico. Se precisarmos de materiais, é melhor procurar a caixa "material" em vez de uma caixa "cookies".
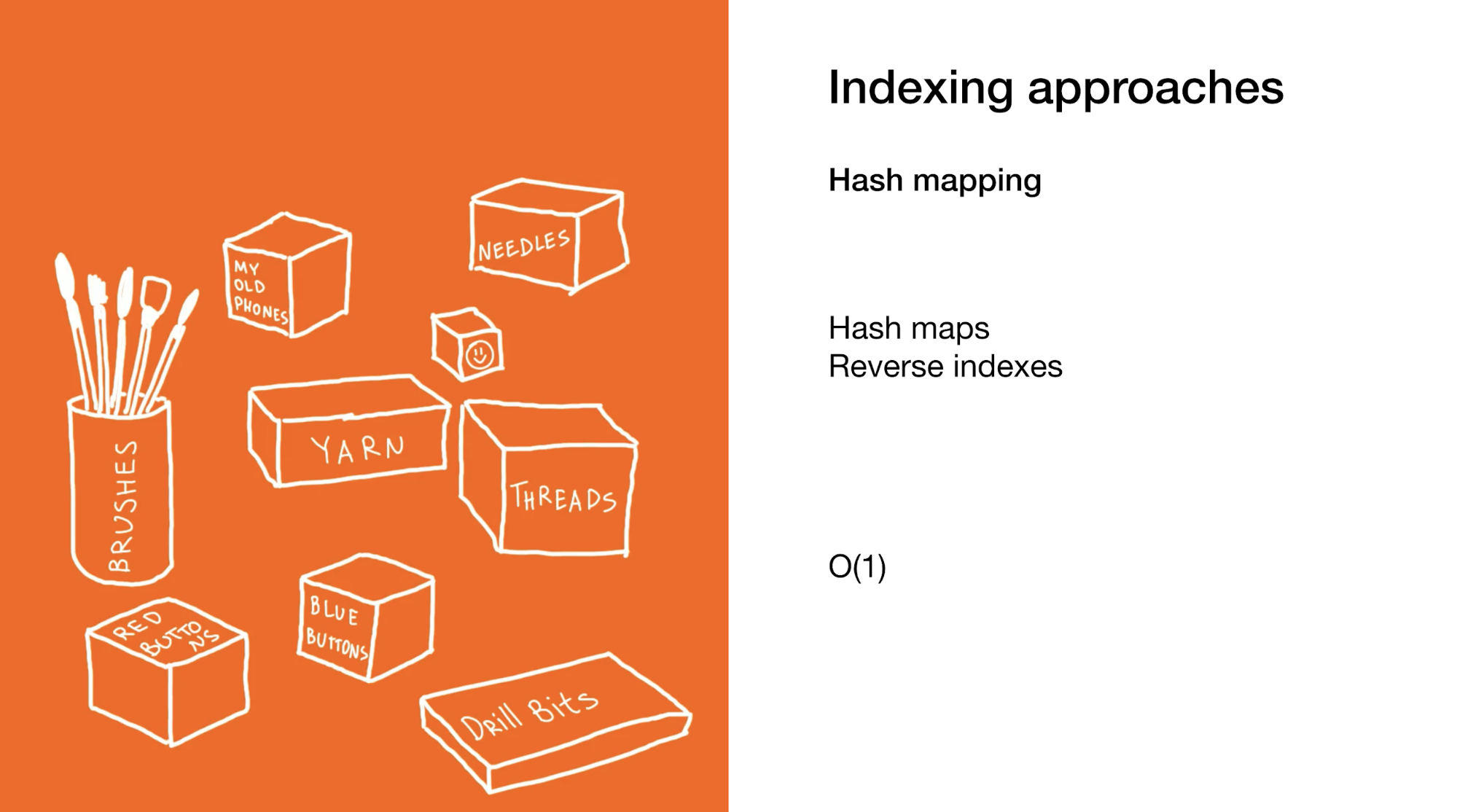
O segundo é identificar instantaneamente um elemento ou grupo específico de elementos, como em mapas de hash ou índices reversos. O uso de mapas de hash é semelhante ao exemplo anterior, mas você usa muitas caixas menores que não contêm caixas, mas itens finais.

A terceira abordagem é remover a necessidade de pesquisar, como nos filtros bloom ou cuco. Os filtros Bloom podem fornecer uma resposta imediata e economizar o tempo gasto na pesquisa.
O último está acelerando a pesquisa, utilizando melhor nossos recursos de hardware, como nos índices de bitmap. Às vezes, os índices de bitmap envolvem passar por todo o índice, sim, mas isso é feito de uma maneira muito eficiente.
Como eu já disse, a pesquisa tem muitas vantagens e desvantagens, e muitas vezes usamos várias abordagens para melhorar ainda mais a velocidade ou para cobrir todos os nossos possíveis tipos de pesquisa.
Hoje eu gostaria de falar sobre uma dessas abordagens menos conhecidas: índices de bitmap.
Mas quem sou eu para falar sobre esse assunto?
Sou líder de equipe no Badoo (talvez você conheça outra de nossas marcas: Bumble). Temos mais de 400 milhões de usuários em todo o mundo e muitos dos recursos que envolvemos na busca da melhor correspondência para você! Para essas tarefas, usamos serviços personalizados que usam índices de bitmap, entre outros.
Agora, o que é um índice de bitmap?
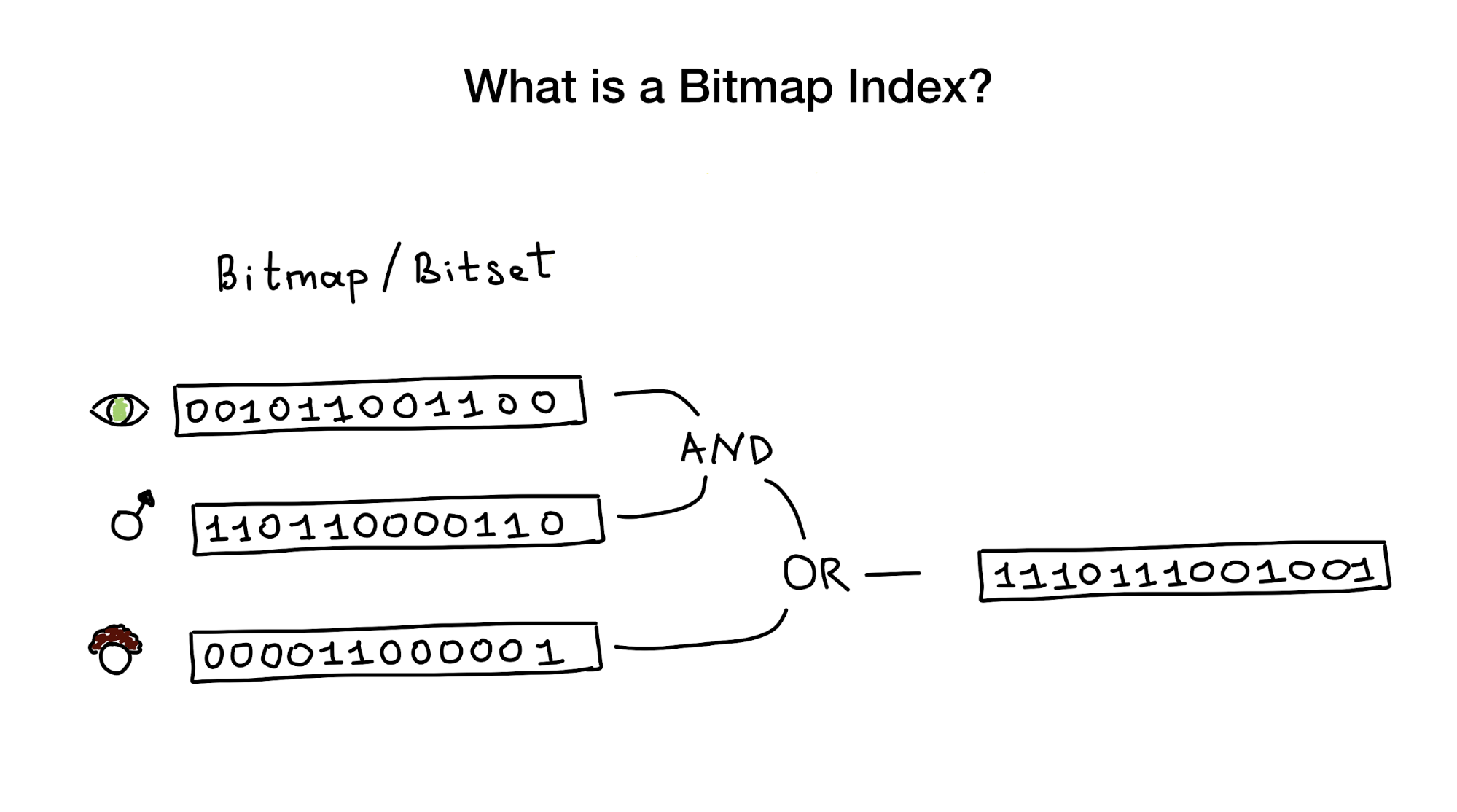
Como o nome sugere, os índices de bitmap usam bitmaps, também conhecidos como bitsets, para implementar o índice de pesquisa. Do ponto de vista de um pássaro, esse índice consiste em um ou vários bitmaps que representam entidades (por exemplo, pessoas) e seus parâmetros (por exemplo, idade ou cor dos olhos) e um algoritmo para responder a consultas de pesquisa usando operações bit a bit como AND, OR, NOT, etc. .

Os índices de bitmap são considerados muito úteis e de alto desempenho se você tiver uma pesquisa que precise combinar consultas de várias colunas com baixa cardinalidade (talvez cor dos olhos ou estado civil) versus algo como a distância do centro da cidade que possui cardinalidade infinita.
Porém, mais adiante neste artigo, mostrarei que os índices de bitmap funcionam mesmo com colunas de alta cardinalidade.
Vejamos o exemplo mais simples de um índice de bitmap ...

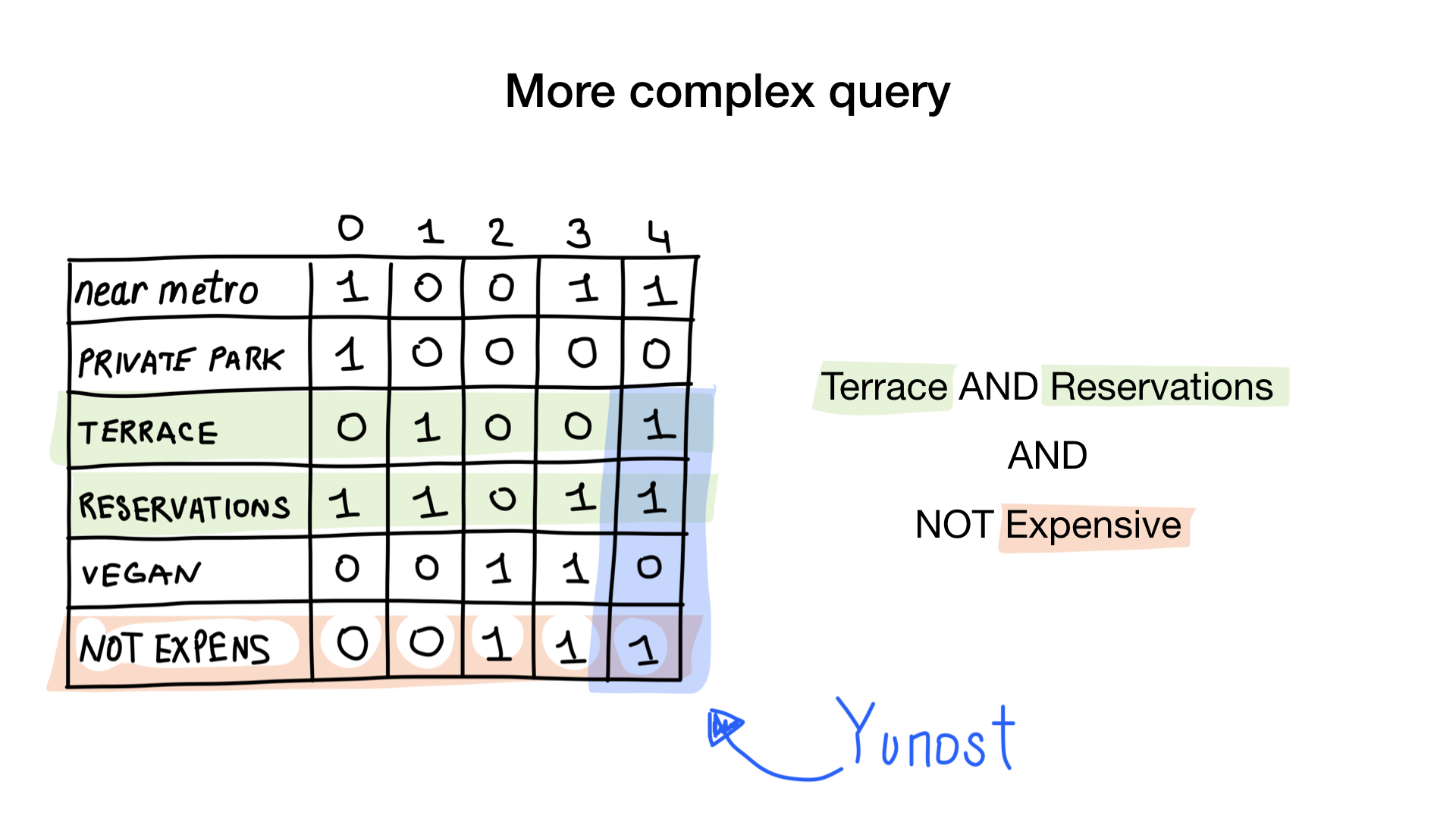
Imagine que temos uma lista de restaurantes em Moscou com características binárias:
- perto do metro
- tem estacionamento privado
- tem terraço
- aceita reservas
- vegan-friendly
- caro
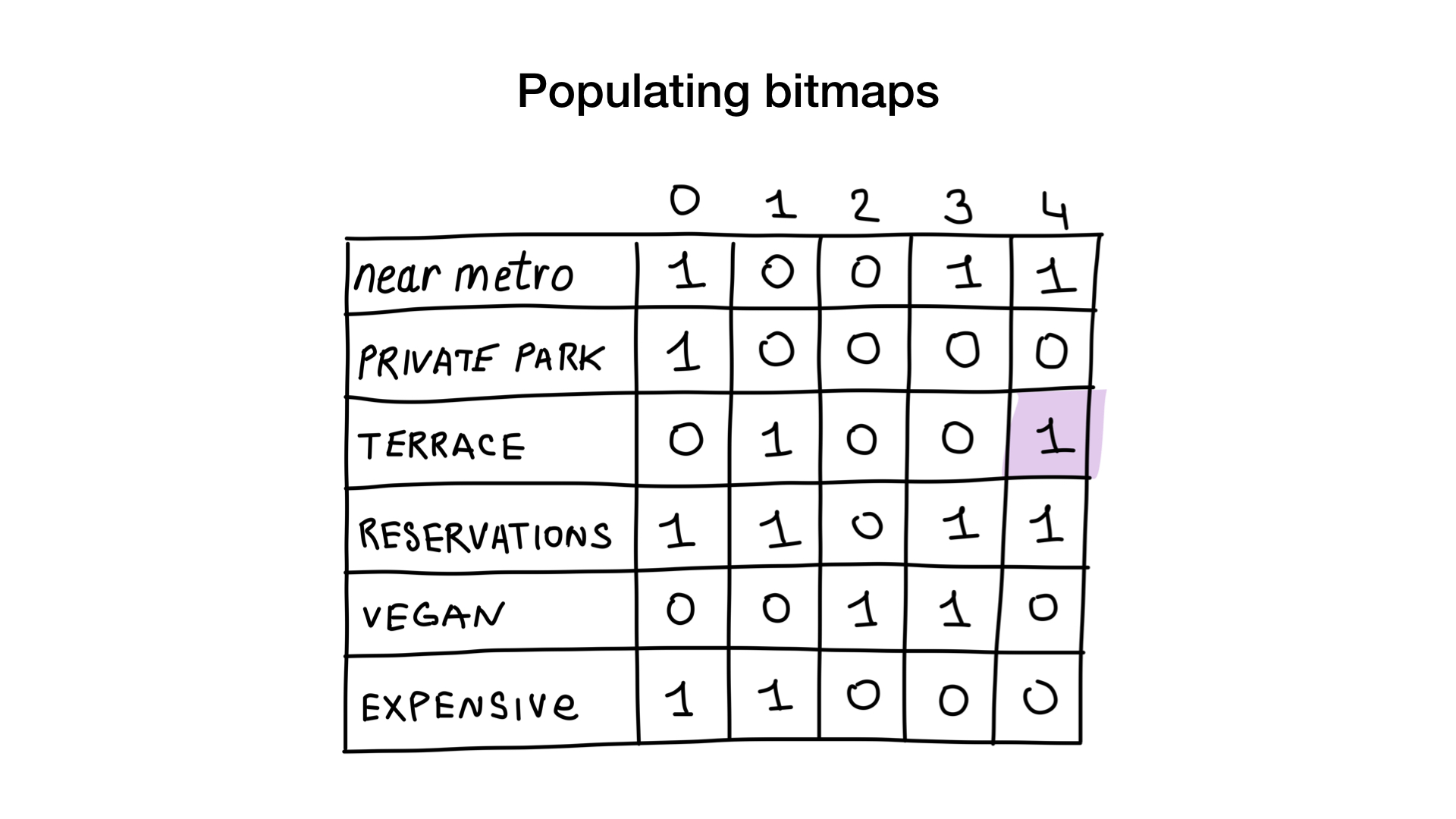
Vamos atribuir a cada restaurante um índice a partir de 0 e alocar 6 bitmaps (um para cada característica). Em seguida, preencheríamos esses bitmaps de acordo com o fato de o restaurante ter uma característica específica ou não. Se o número do restaurante 4 tiver o terraço, o bit número 4 no bitmap "terraço" será definido como 1 (0 se não houver).

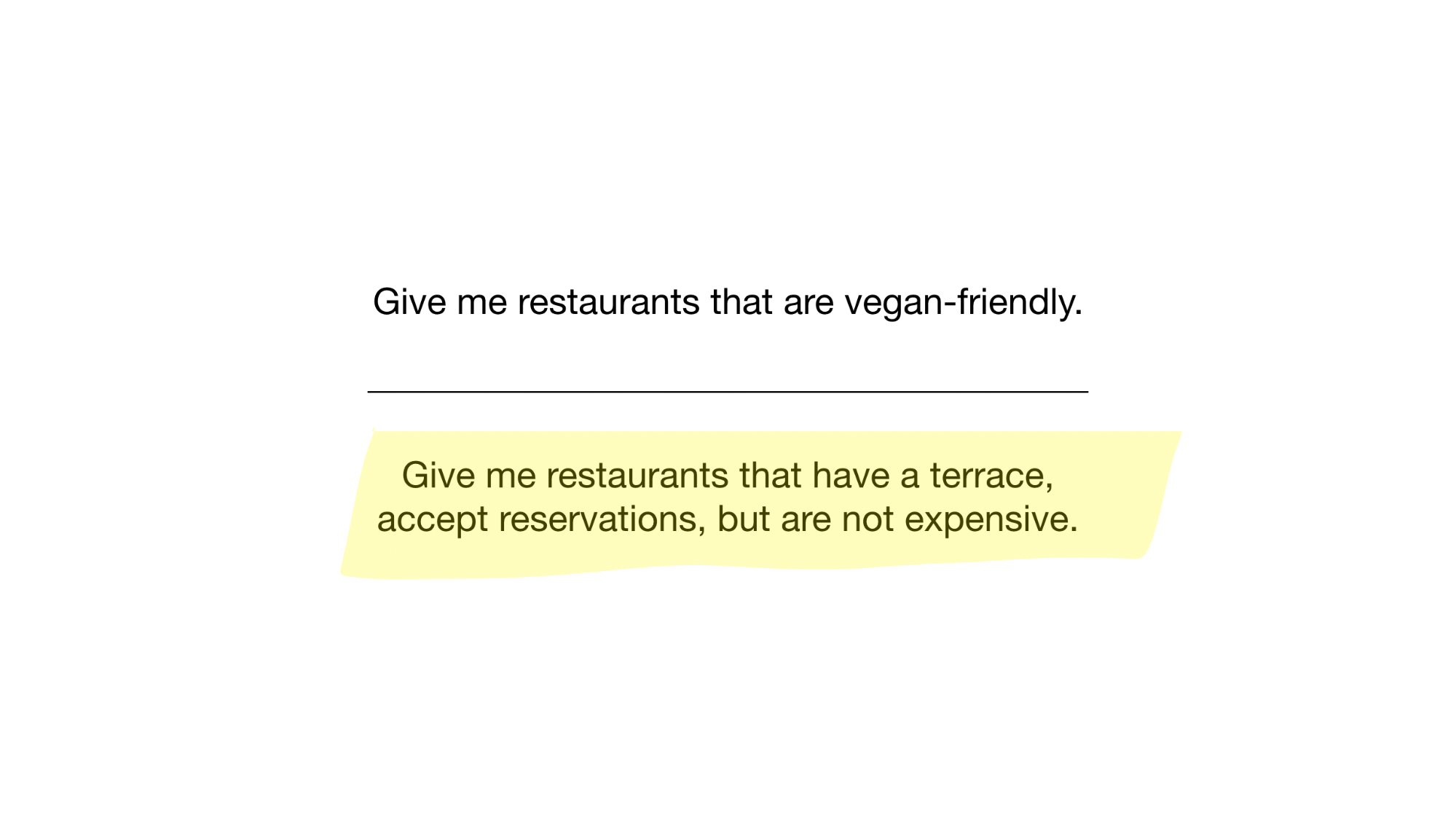
Agora temos o índice de bitmap mais simples possível que podemos usar para responder perguntas como
- Dê-me restaurantes que são veganos
- Dê-me restaurantes com terraço que aceitam reservas, mas não são caros


Como Vamos ver A primeira pergunta é simples. Nós apenas pegamos o bitmap "amigável ao vegano" e retornamos todos os índices que definiram o bit.

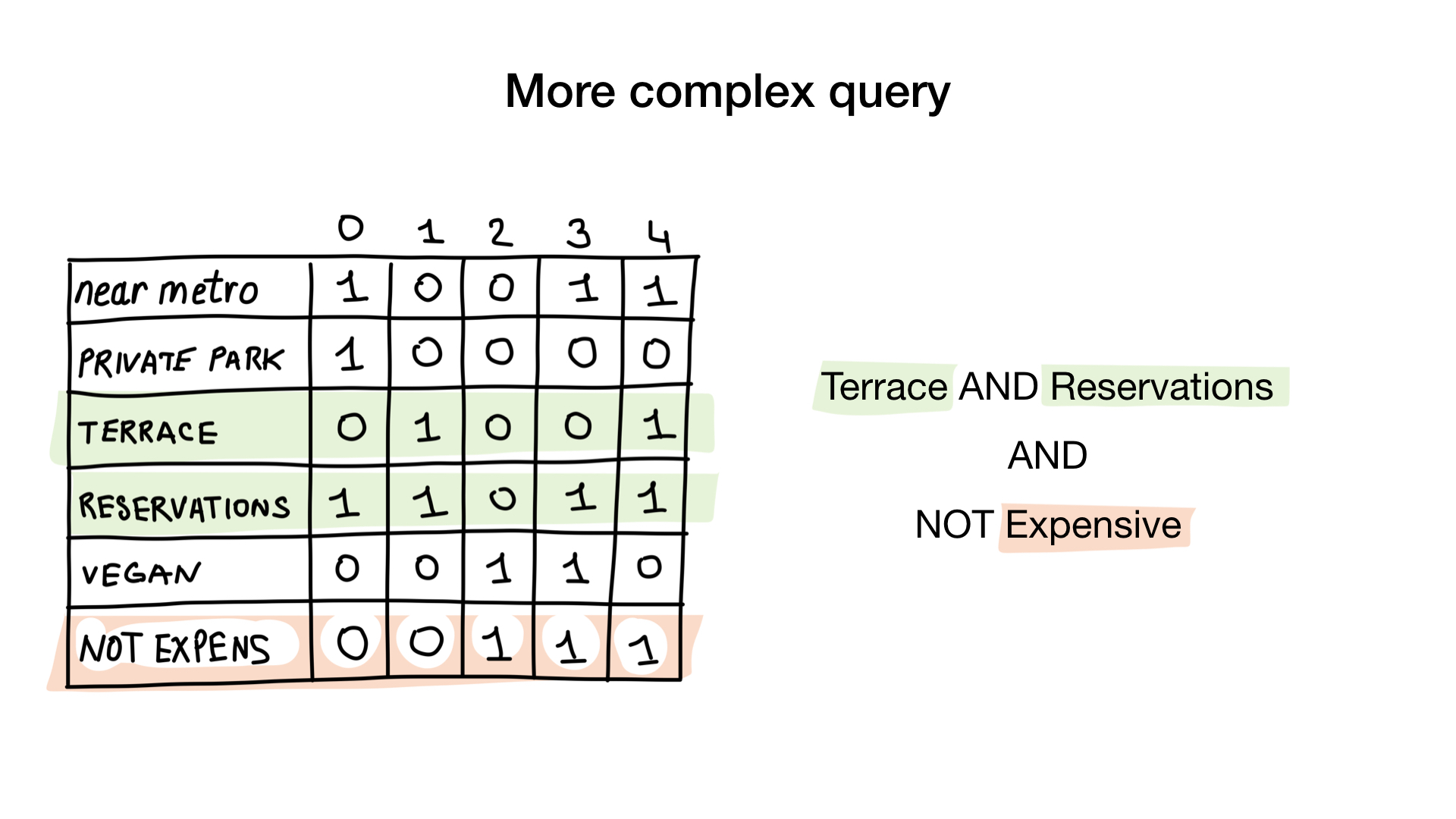
A segunda pergunta é um pouco mais complicada. Usaremos a operação bit a bit, NÃO no bitmap "caro" para obter restaurantes não caros, E com o bitmap "aceitar reserva" e "com bitmap no terraço". O bitmap resultante será composto por restaurantes com todas essas características que desejávamos. Aqui vemos que apenas Yunost tem todas essas características.
Isso pode parecer um pouco teórico, mas não se preocupe, chegaremos ao código em breve.
Onde os índices de bitmap são usados

Se você pesquisar no “índice de bitmap”, 90% dos resultados apontarão para o Oracle DB, que possui índices básicos de bitmap. Mas, certamente, outros DBMS também usam índices de bitmap, não é? Não, na verdade eles não. Vamos examinar os suspeitos do costume, um por um.


- Mas há um novo garoto no quarteirão: Pilosa. Pilosa é um novo DBMS escrito em Go (observe que não há R, não é relacional) que baseia tudo em índices de bitmap. E falaremos sobre Pilosa mais tarde.
Implementação em movimento
Mas porque? Por que os índices de bitmap são tão raramente usados? Antes de responder a essa pergunta, gostaria de orientá-lo na implementação básica do índice de bitmap no Go.

O bitmap é representado como um pedaço de memória. No Go, vamos usar uma fatia de bytes para isso.
Temos um bitmap por característica do restaurante. Cada bit em um bitmap representa se um restaurante específico tem essa característica ou não.

Nós precisaríamos de duas funções auxiliares. Um é usado para preencher o bitmap aleatoriamente, mas com uma probabilidade especificada de ter a característica. Por exemplo, acho que existem muito poucos restaurantes que não aceitam reservas e aproximadamente 20% são veganos.
Outra função nos dará a lista de restaurantes de um bitmap.


Para responder à pergunta "dê-me restaurantes com um terraço que aceita reservas, mas não é caro", precisaríamos de duas operações: NOT e AND.
Podemos simplificar levemente o código introduzindo operações complexas AND NOT.
Temos as funções para cada um deles. Ambas as funções passam por nossas fatias, pegando os elementos correspondentes de cada uma, executando a operação e gravando o resultado na fatia resultante.
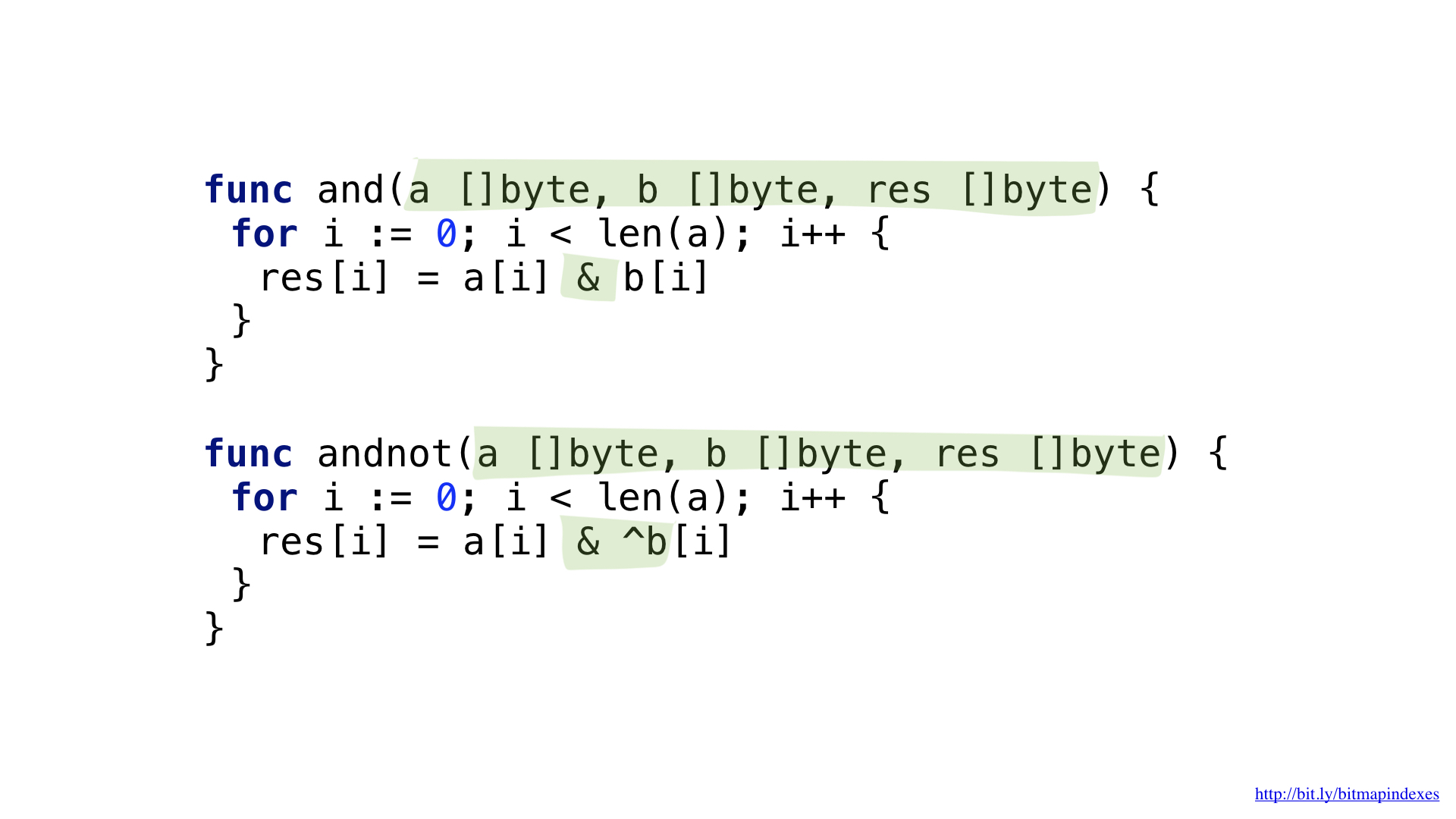
E agora podemos usar nossos bitmaps e nossas funções para obter a resposta.

O desempenho não é tão bom aqui, embora nossas funções sejam realmente simples e economizamos muito em alocações ao não retornar uma nova fatia em cada chamada de função.
Após alguns perfis com o pprof, notei que o compilador go perdeu uma das otimizações básicas: a função inlining.
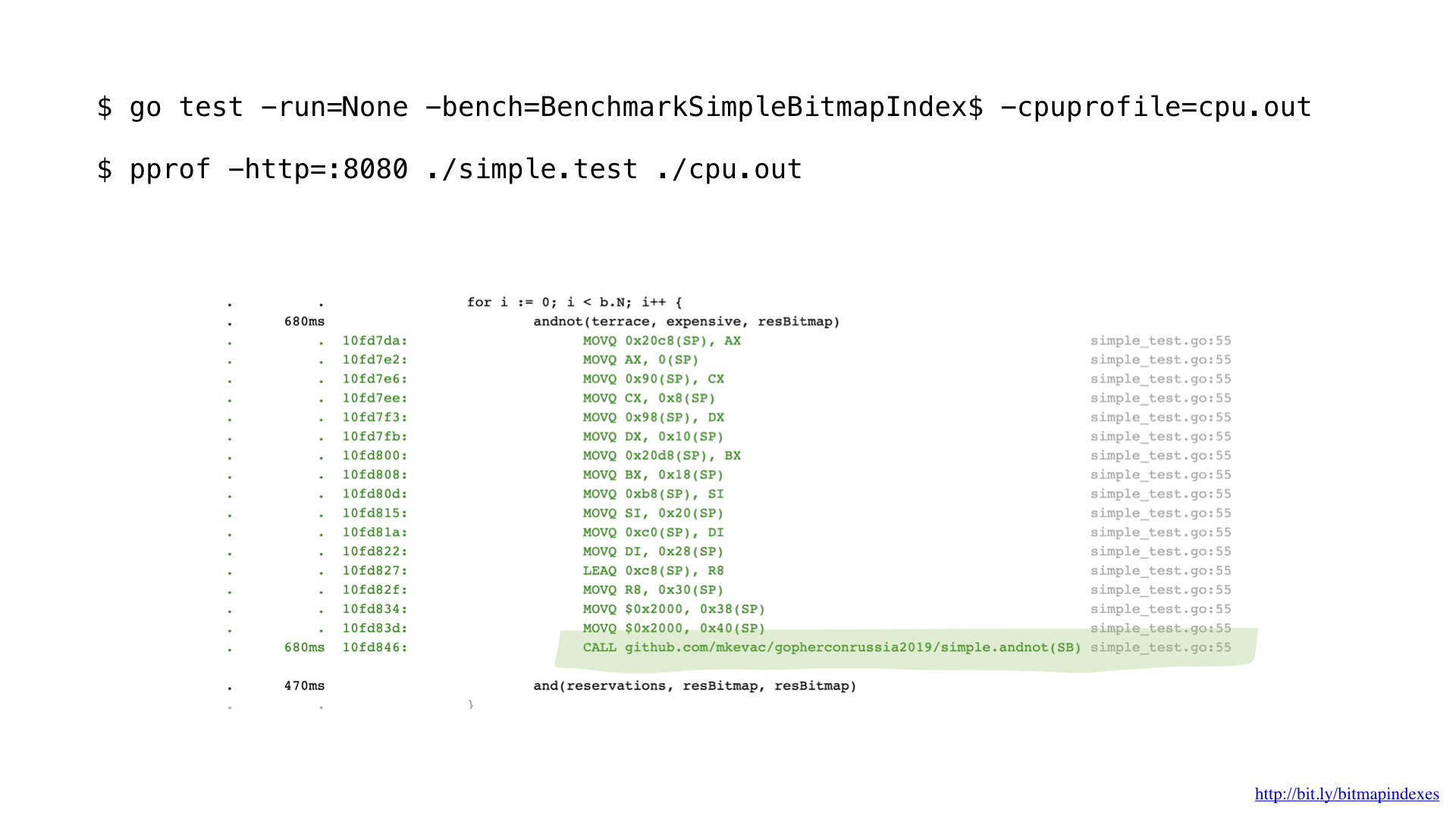
Veja bem, o compilador Go tem medo patológico de loops através de fatias e se recusa a alinhar qualquer função que as possua.
Mas não tenho medo deles e posso enganar o compilador usando goto para o meu loop.


Como você pode ver, o inlining nos salvou em cerca de 2 microssegundos. Nada mal!

Outro gargalo é fácil de detectar quando você olha mais de perto a saída da montagem. O compilador Go inclui verificações de faixa em nosso loop. Go é uma linguagem segura e o compilador tem medo de que meus três bitmaps possam ter comprimentos diferentes e que haja um estouro de buffer.
Vamos acalmar o compilador e mostrar que todos os meus bitmaps têm o mesmo comprimento. Para fazer isso, podemos adicionar uma verificação simples no início da função.
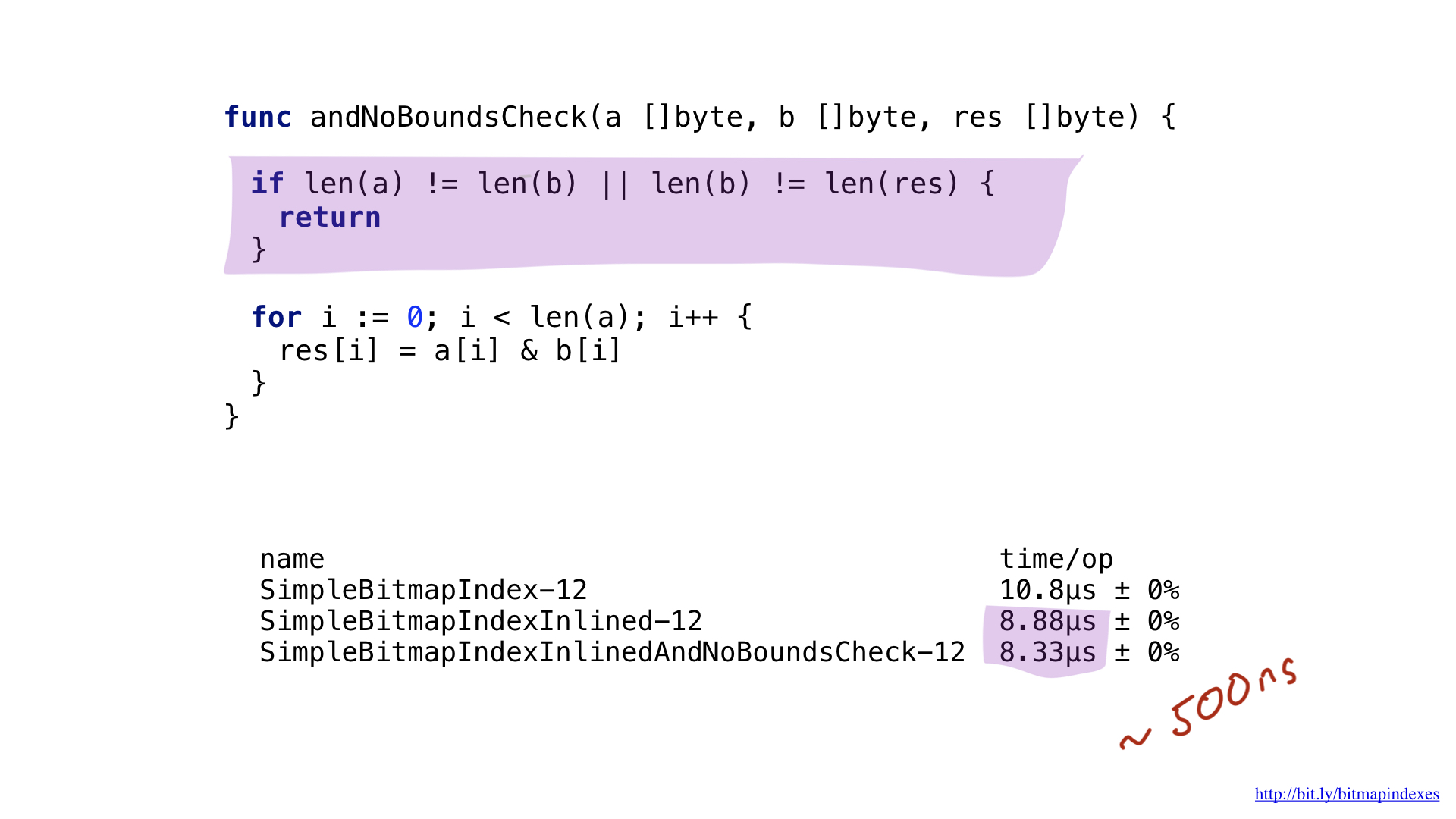
Com esta verificação, o compilador go ignora as verificações de alcance e economizaremos alguns nanossegundos.
Implementação em montagem
Tudo bem, então conseguimos reduzir um pouco mais o desempenho com nossa implementação simples, mas esse resultado é muito pior do que é possível com o hardware atual.
Veja bem, o que estamos fazendo são operações bit a bit muito básicas e nossas CPUs são muito eficazes com elas.
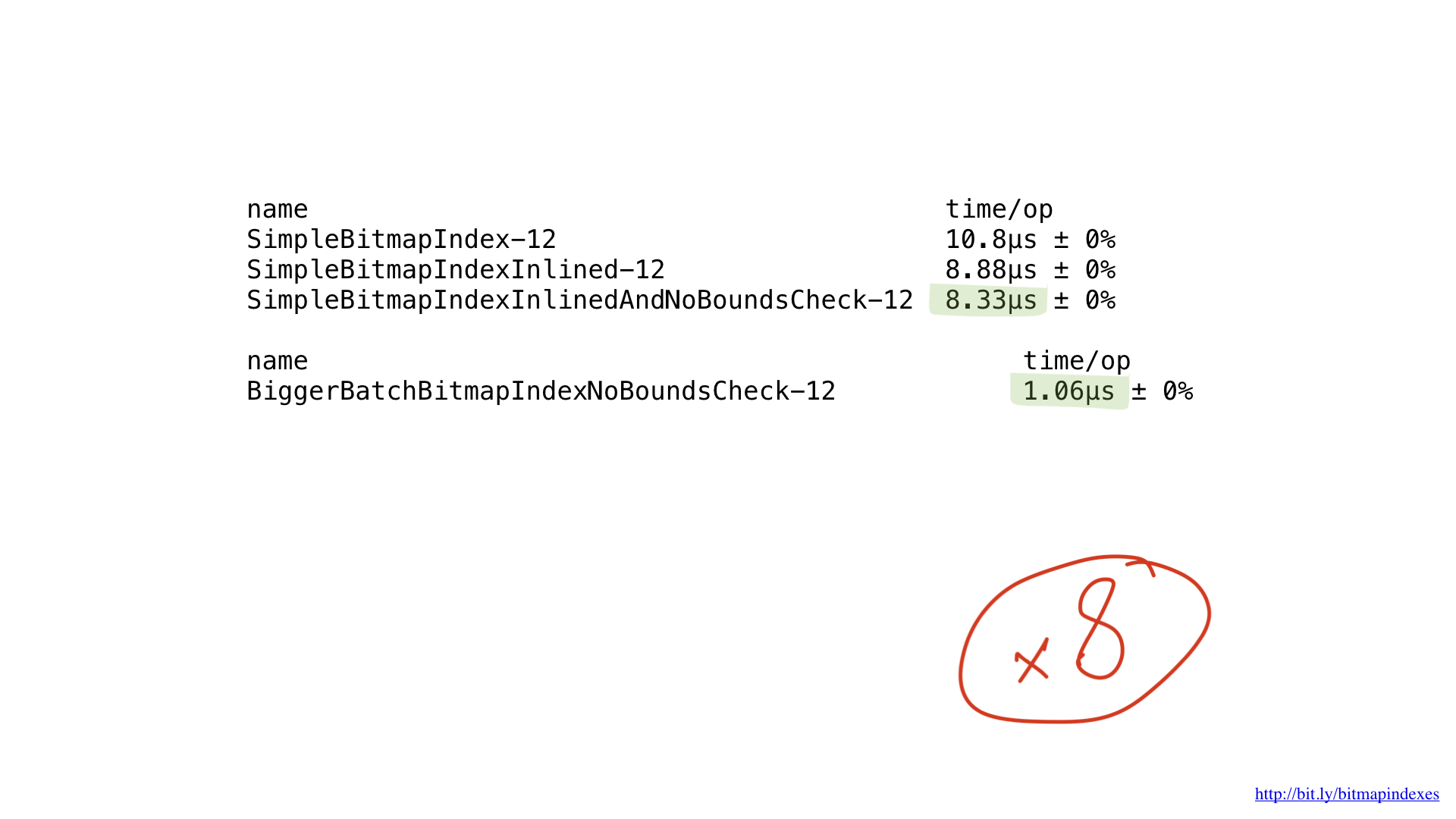
Infelizmente, estamos alimentando nossa CPU com muito pequenos pedaços de trabalho. Nossa função realiza operações byte a byte. Podemos facilmente ajustar nossa implementação para trabalhar com blocos de 8 bytes usando fatias de uint64.

Como você pode ver aqui, ganhamos cerca de 8x de desempenho para o tamanho de lote de 8x, portanto os ganhos de desempenho são praticamente lineares.

Mas este não é o fim do caminho. Nossas CPUs têm a capacidade de trabalhar com pedaços de 16 bytes, 32 bytes e até mesmo com pedaços de 64 bytes. Essas operações são chamadas SIMD (dados múltiplos de instrução única) e o processo de uso dessas operações da CPU é chamado de vetorização.
Infelizmente, o compilador Go não é muito bom com a vetorização. E a única coisa que podemos fazer hoje para vetorizar nosso código é usar o assembly Go e adicionar essas instruções SIMD.

Ir montagem é uma besta estranha. Você pensaria que o assembly é algo ligado à arquitetura para a qual está escrevendo, mas o assembly do Go é mais parecido com o IRL (linguagem de representação intermediária): é independente da plataforma. Rob Pike deu uma palestra incrível sobre isso há alguns anos atrás.
Além disso, o Go usa um formato incomum plan9, diferente dos formatos AT&T e Intel.

É seguro dizer que escrever código de montagem Go não é divertido.
Felizmente para nós, já existem duas ferramentas de nível superior para ajudar na escrita da montagem Go: PeachPy e avo. Ambos geram o assembly go a partir de um código de nível superior escrito em Python e Go, respectivamente.

Essas ferramentas simplificam coisas como alocação e loops de registro e, no fim das contas, reduzem a complexidade de entrar no domínio da programação de montagem do Go.
Usaremos evitar esse post para que nossos programas se pareçam quase com o código Go comum.

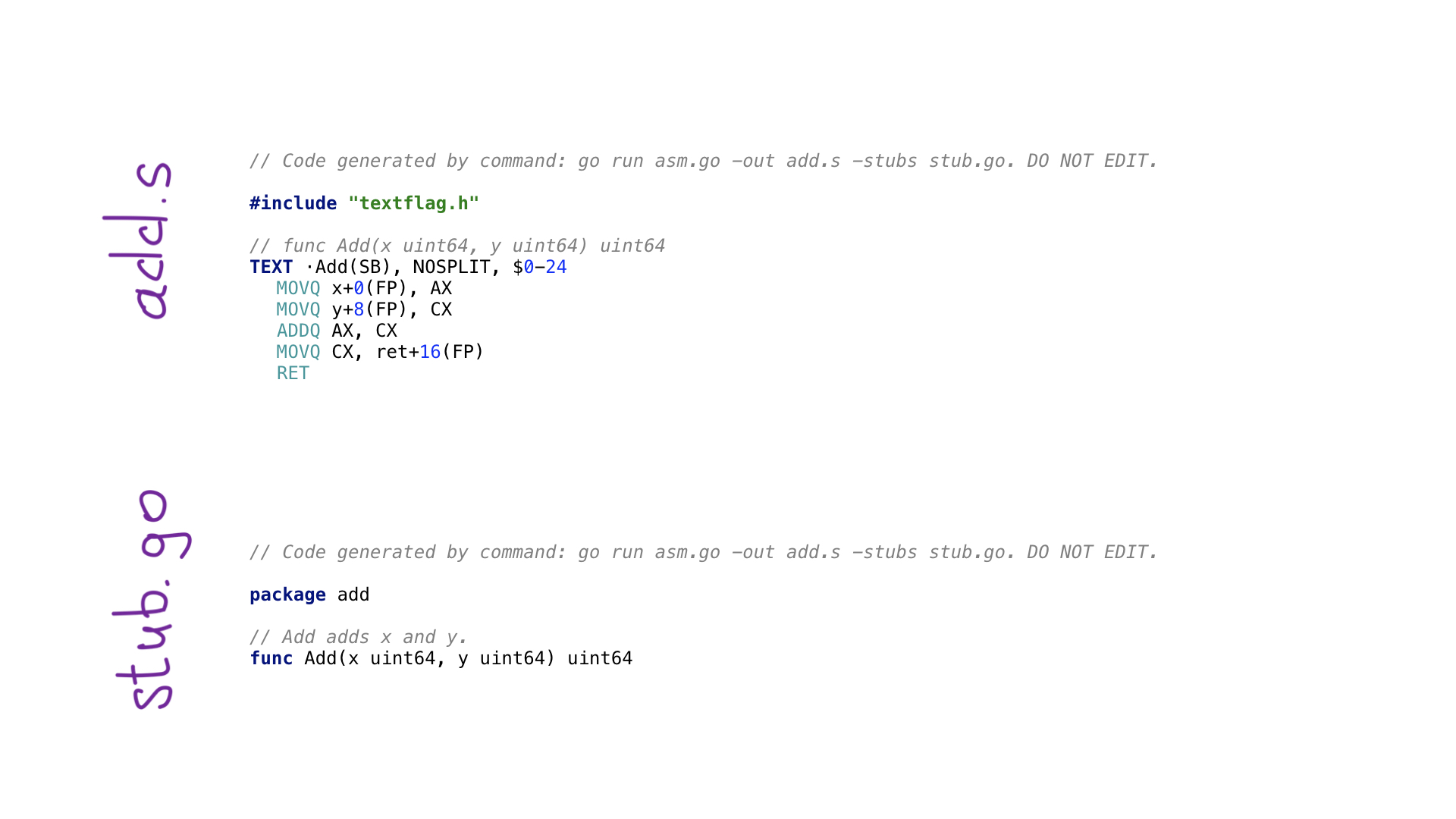
Este é o exemplo mais simples de um programa avo. Temos uma função main () que define uma função chamada Add () que adiciona dois números. Existem funções auxiliares para obter parâmetros por nome e obter um dos registros gerais disponíveis. Existem funções para cada operação de montagem como ADDQ aqui e existem funções auxiliares para salvar o resultado de um registro no valor resultante.

A chamada go generate irá executar este programa avo e dois arquivos serão criados
- add.s com código de montagem gerado
- stub.go com cabeçalhos de função necessários para conectar nosso código go e assembly
Agora que vimos o que o avo faz, vejamos nossas funções. Implementei as versões escalar e SIMD (vetor) de nossas funções.
Vamos ver como é a versão escalar primeiro.

Como no exemplo anterior, podemos solicitar um registro geral e evitar fornecer o correto. Não precisamos rastrear compensações em bytes para nossos argumentos, evitando isso para nós.

Anteriormente, passamos de loops para usar goto por razões de desempenho e para enganar o compilador. Aqui, estamos usando goto (saltos) e rótulos desde o início, porque os loops são construções de nível superior. Na montagem, só temos saltos.

Outro código deve ser bem claro. Emulamos o loop com saltos e etiquetas, pegamos uma pequena parte de nossos dados de nossos dois bitmaps, combinamos usando uma das operações bit a bit e inserimos o resultado no bitmap resultante.

Este é um código ASM resultante que obtemos. Não tivemos que calcular deslocamentos e tamanhos (em verde), não tivemos que lidar com registros específicos (em vermelho).
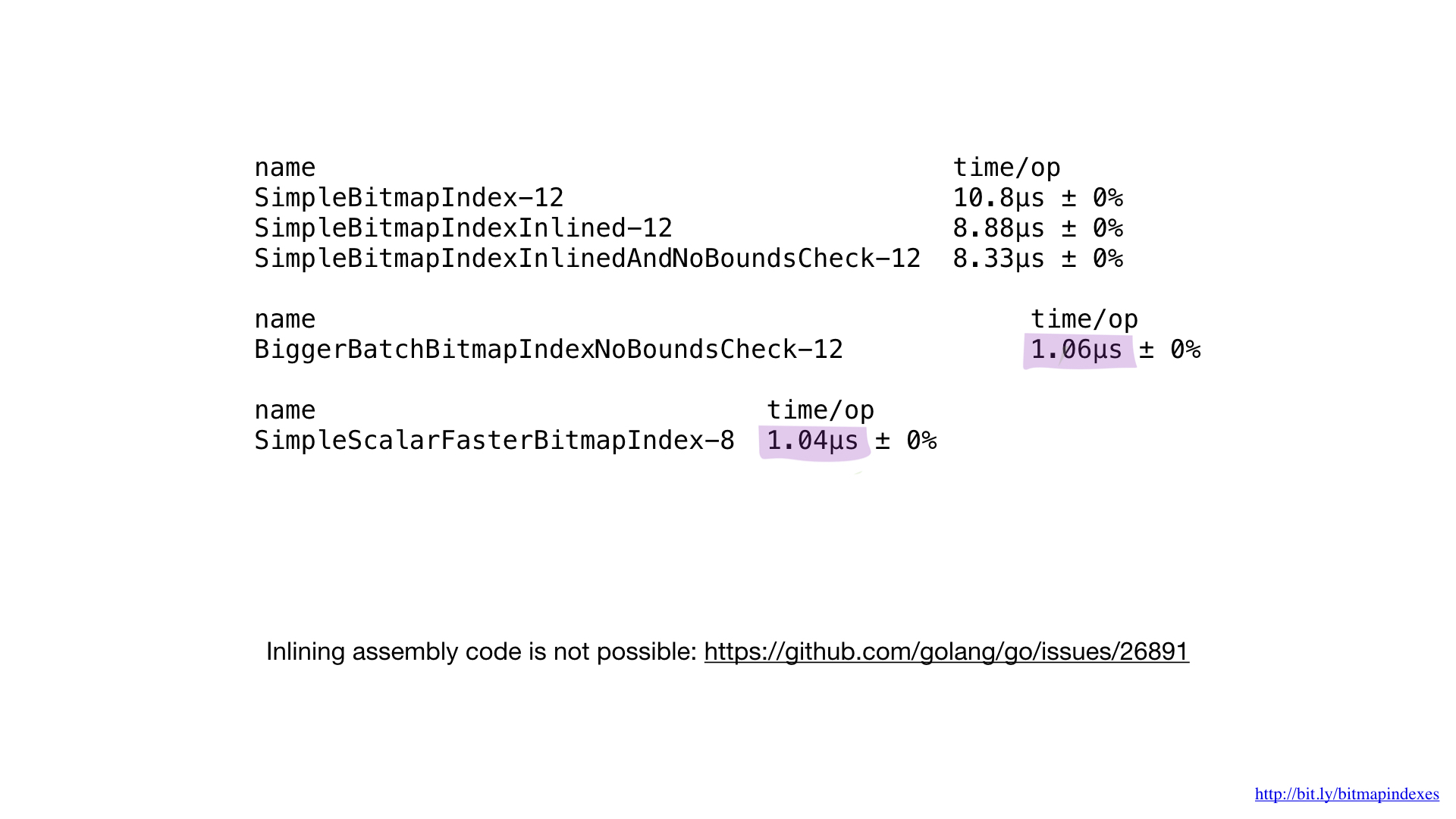
Se compararmos essa implementação em assembly com a melhor anterior escrita em go, veremos que o desempenho é o mesmo que o esperado. Não fizemos nada de diferente.
Infelizmente, não podemos forçar o compilador Go a incorporar nossas funções escritas em asm. Falta completamente suporte e a solicitação para esse recurso já existe há algum tempo. É por isso que as pequenas funções asm não dão nenhum benefício. Você precisa escrever funções maiores, usar o novo pacote math / bits ou ignorar asm completamente.
Vamos escrever a versão vetorial de nossas funções agora.

Eu escolhi usar o AVX2, então vamos usar pedaços de 32 bytes. É muito semelhante ao escalar na estrutura. Carregamos parâmetros, solicitamos registros gerais, etc.
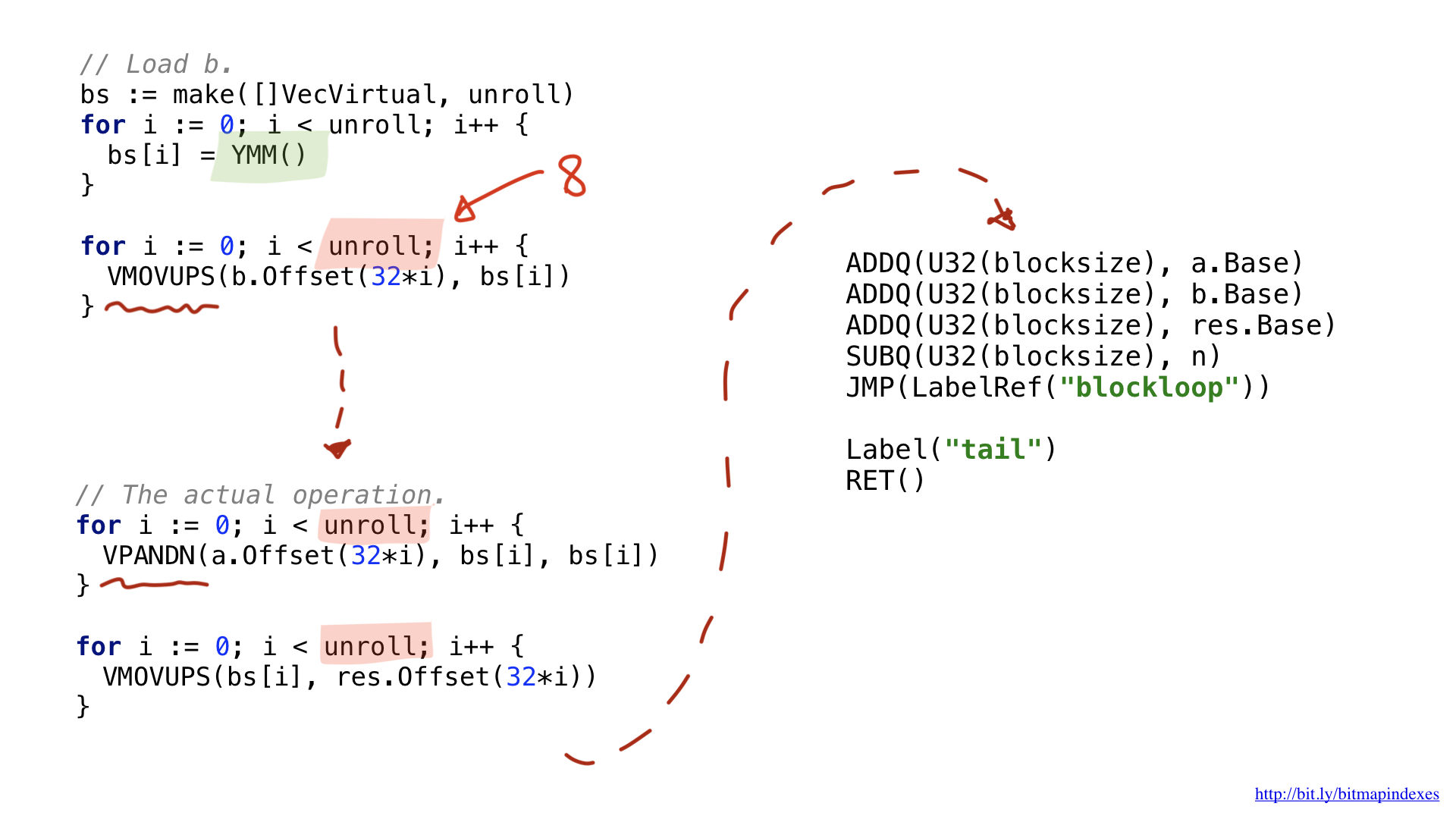
Uma das mudanças tem a ver com o fato de que as operações vetoriais usam registros amplos específicos. Para 32 bytes eles têm o prefixo Y, é por isso que você vê YMM () lá. Para 64 bytes, eles teriam o prefixo Z.
Outra diferença tem a ver com a otimização que realizei chamada desenrolamento ou desenrolamento de loop. Eu escolhi desenrolar parcialmente nosso loop e executar 8 operações de loop em sequência antes de retornar. Essa técnica acelera o código reduzindo as ramificações que temos e é praticamente limitada pelo número de registros que temos disponíveis.
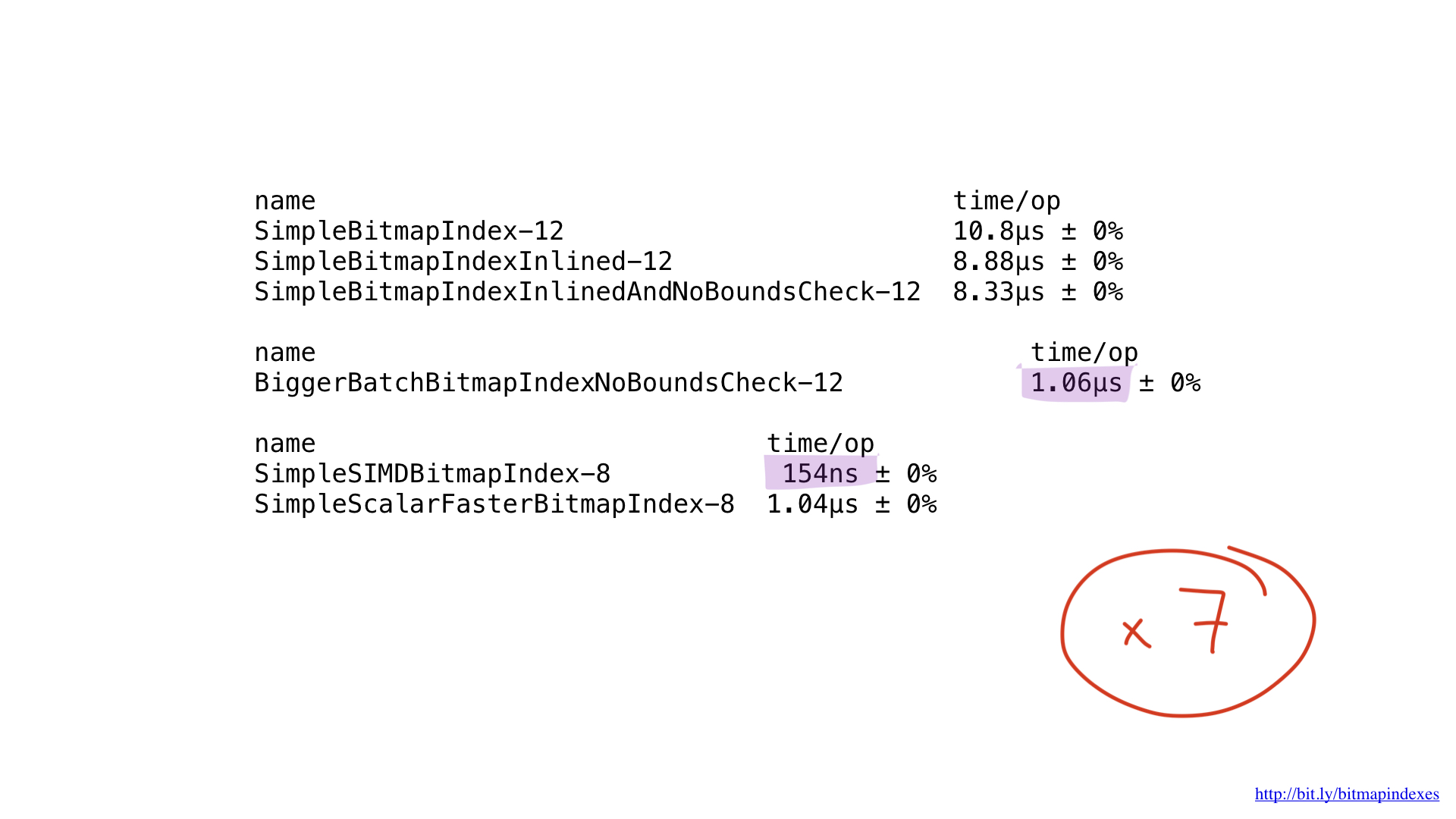
Quanto ao desempenho ... é incrível. Obtivemos cerca de 7x de melhoria em comparação com o melhor anterior. Muito impressionante, certo?
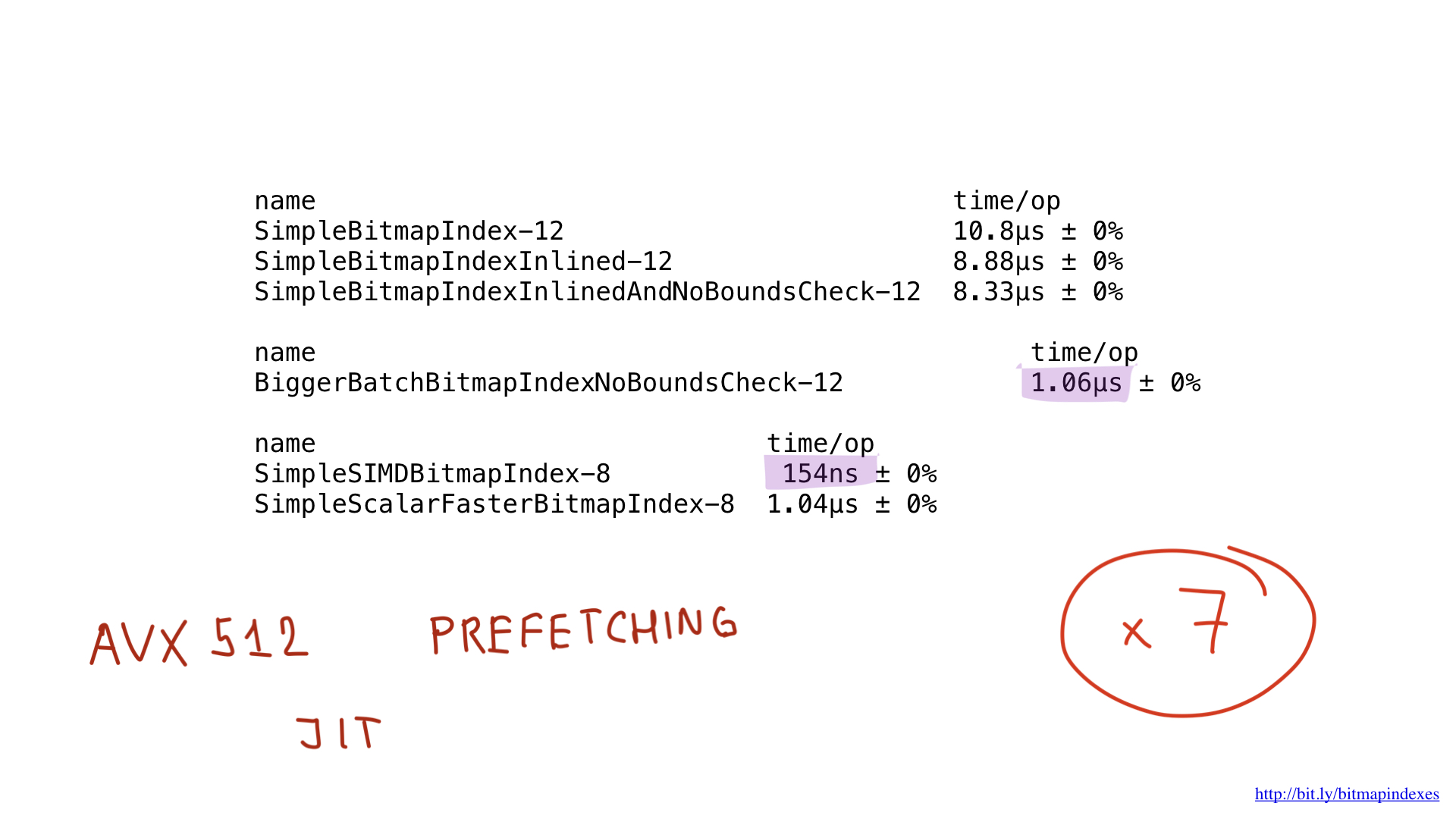
Deve ser possível melhorar ainda mais esses resultados usando o AVX512, pré-busca e talvez até usando a compilação JIT (just in time) em vez do construtor "manual" do plano de consulta, mas isso seria assunto para uma postagem totalmente diferente.
Problemas no índice de bitmap
Agora que vimos a implementação básica e a velocidade impressionante da implementação do asm, vamos falar sobre o fato de que os índices de bitmap não são muito amplamente utilizados. Por que isso?

Publicações mais antigas nos dão essas três razões. Mas os mais recentes e eu argumentamos que estes foram "consertados" ou tratados até agora. Não vou entrar em muitos detalhes aqui porque não temos muito tempo, mas certamente vale a pena dar uma olhada rápida.
Problema de alta cardinalidade
Assim, nos disseram que os índices de bitmap são viáveis apenas para campos de baixa cardinalidade. ou seja, campos com poucos valores distintos, como sexo ou cor dos olhos. O motivo é que a representação comum (um bit por valor distinto) pode ficar muito grande para valores de alta cardinalidade. E, como resultado, o bitmap pode se tornar enorme, mesmo que seja escassamente preenchido.
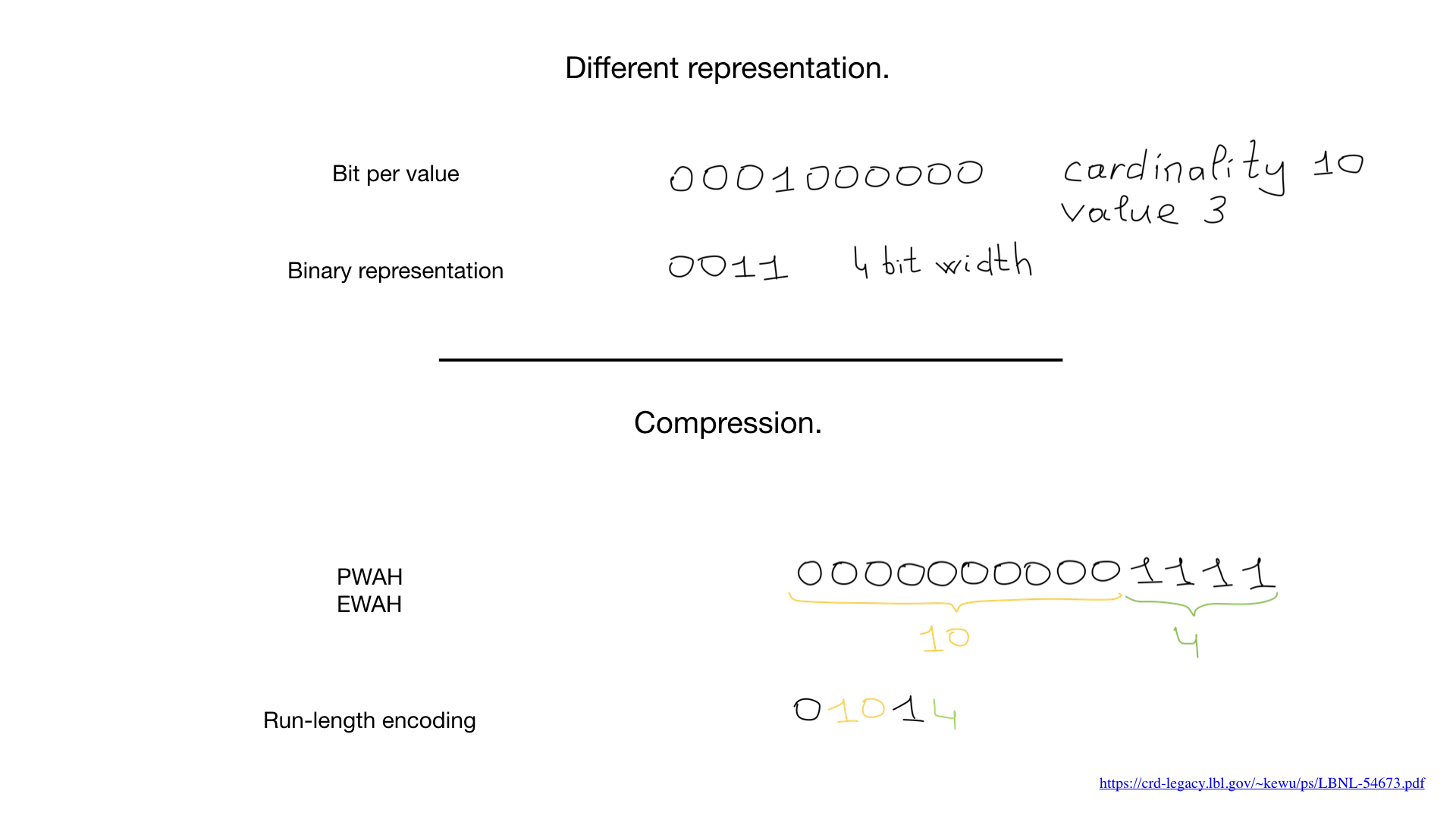
Às vezes, uma representação diferente pode ser usada para esses campos, como uma representação de número binário, como mostrado aqui, mas a maior mudança de jogo é uma compactação. Os cientistas criaram algoritmos de compressão surpreendentes. Quase todos são baseados em algoritmos de duração de execução generalizados, mas o mais surpreendente é que não precisamos descomprimir bitmaps para realizar operações bit a bit neles. As operações bit a bit normais funcionam em bitmaps compactados.

Recentemente, vimos abordagens híbridas aparecerem como "rugidos bitmaps". Os bitmaps ruidosos usam três representações separadas para bitmaps: bitmaps, matrizes e "bit runs" e equilibram o uso dessas três representações para maximizar a velocidade e minimizar o uso de memória.
Os bitmaps ruidosos podem ser encontrados em alguns dos aplicativos mais usados por aí e existem implementações para muitos idiomas, incluindo várias implementações do Go.
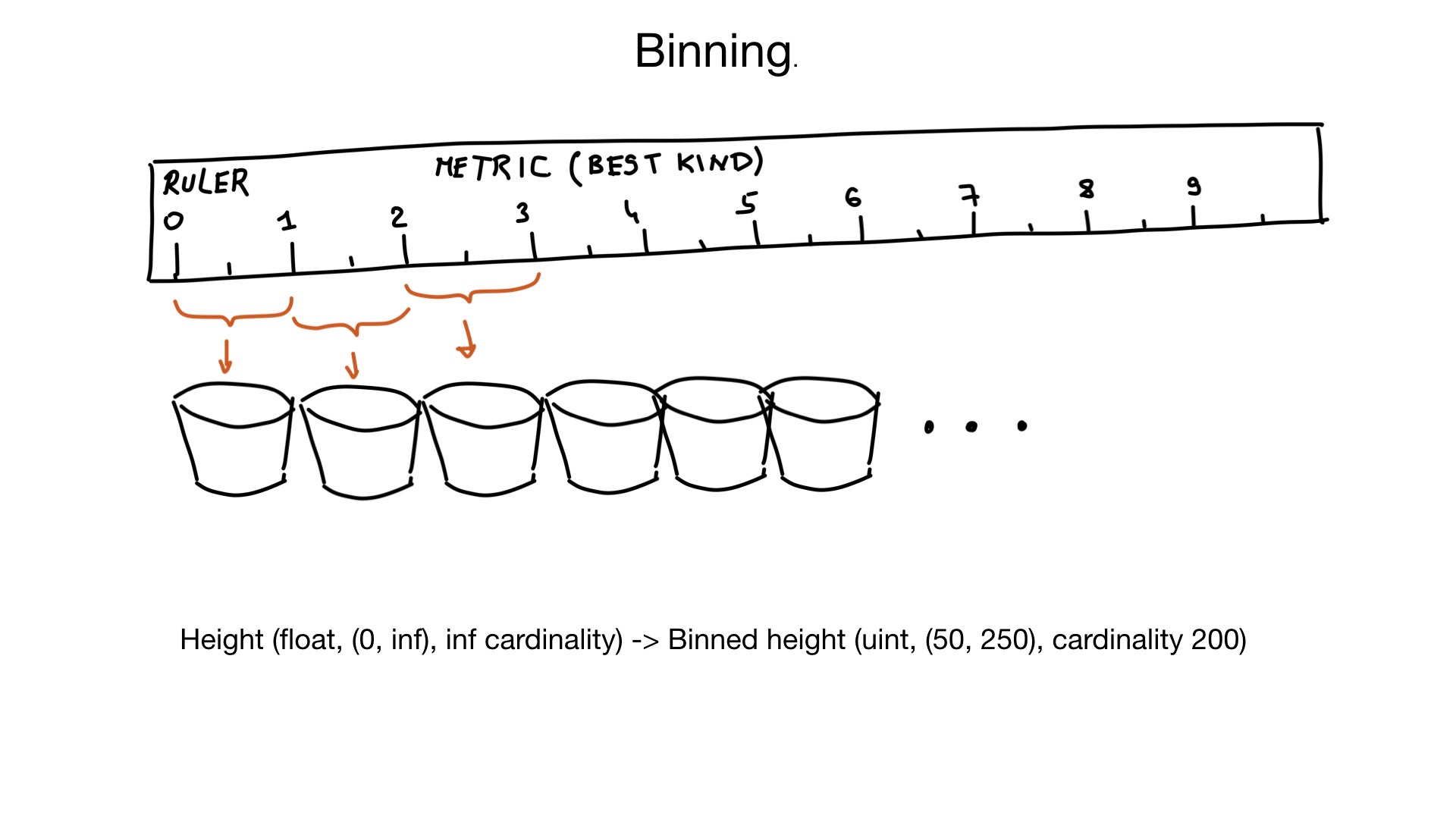
Outra abordagem que pode ajudar com campos de alta cardinalidade é chamada binning. Imagine que temos um campo que representa a altura de uma pessoa. A altura é uma bóia, mas não pensamos dessa maneira. Ninguém se importa se a sua altura é 185,2 ou 185,3 cm. Portanto, podemos usar "caixas virtuais" para espremer alturas semelhantes na mesma bandeja: a bandeja de 1 cm, neste caso. E se você assumir que existem muito poucas pessoas com uma altura inferior a 50 cm ou superior a 250 cm, podemos converter nossa altura no campo com aproximadamente cardinalidade de 200 elementos, em vez de uma cardinalidade quase infinita. Se necessário, poderíamos fazer uma filtragem adicional nos resultados posteriormente.
Problema de alto rendimento
Outra razão pela qual os índices de bitmap são ruins é que pode ser caro atualizar bitmaps.
Os bancos de dados fazem atualizações e pesquisas em paralelo, portanto, você deve poder atualizar os dados enquanto houver centenas de threads passando por bitmaps fazendo uma pesquisa. Bloqueios seriam necessários bloqueios para evitar corridas de dados ou problemas de consistência de dados. E onde há uma grande trava, há contenção de trava.
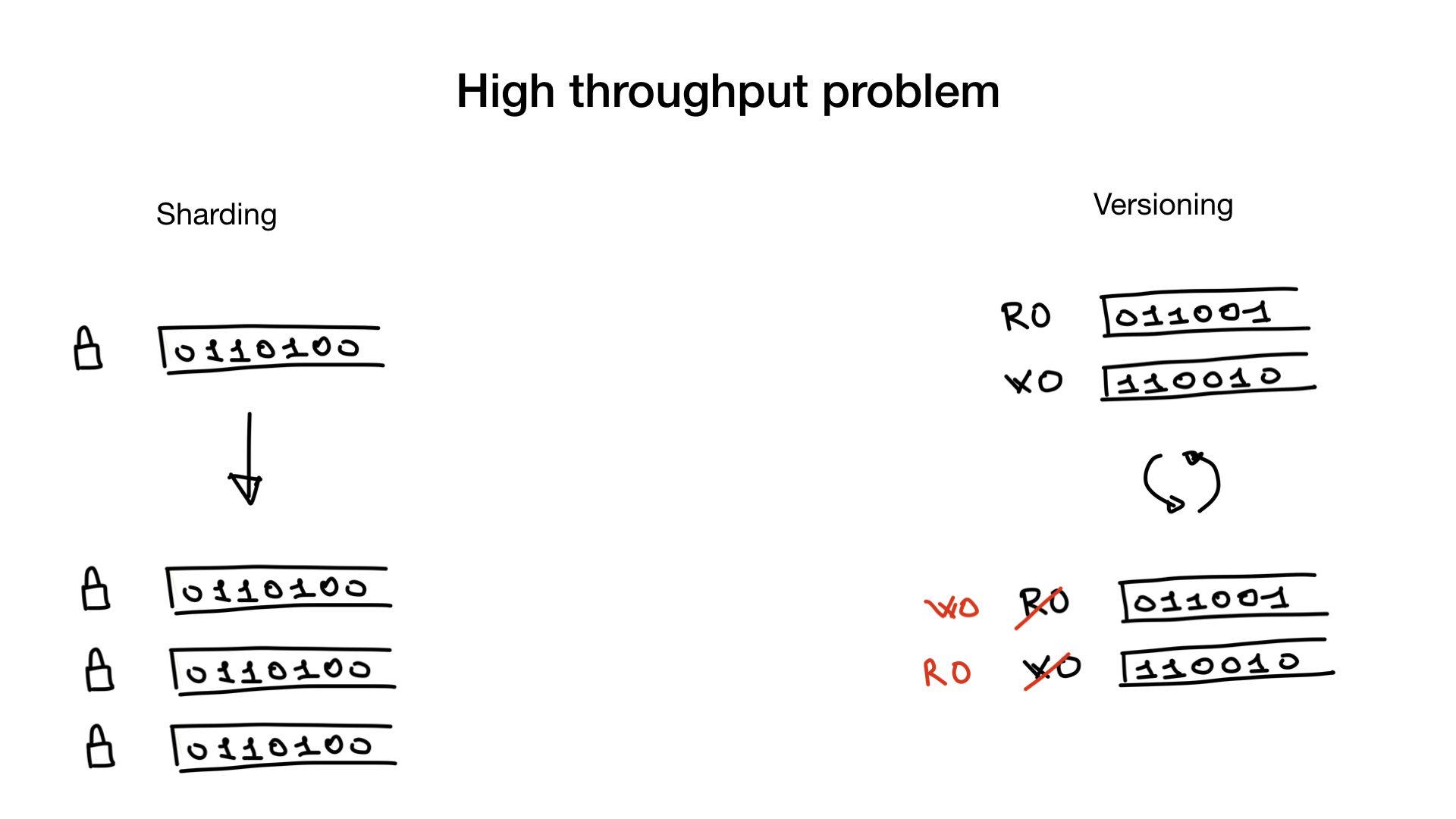
Esse problema, se você o tiver, pode ser corrigido compartilhando seus índices ou tendo versões de índice, se apropriado.
O sharding é direto. Você os fragmenta como faria com os usuários em um banco de dados e agora, em vez de um bloqueio, você tem vários bloqueios, o que reduz bastante sua contenção de bloqueios.
Outra abordagem que às vezes é possível é ter índices com versão. Você tem o índice usado para pesquisa e um índice usado para gravações, atualizações. E você copia e troca com baixa frequência, por exemplo, 100 ou 500 ms.
Mas essa abordagem só é viável se seu aplicativo puder tolerar índices de pesquisa obsoletos um pouco obsoletos.
Obviamente, essas duas abordagens também podem ser usadas juntas. Você pode ter índices versionados divididos.
Consultas não triviais
Outro problema do índice de bitmap tem a ver com o uso de índices de bitmap com consultas de intervalo. E, à primeira vista, operações bit a bit como AND e OR não parecem ser muito úteis para consultas de intervalo como "me dê quartos de hotel que custam de 200 a 300 dólares por noite".

Uma solução ingênua e muito ineficiente seria obter resultados para cada ponto de preço de 200 a 300 e OU os resultados.

Uma abordagem um pouco melhor seria usar binning e colocar nossos hotéis em faixas de preço com larguras de faixa de, digamos, 50 dólares. Essa abordagem reduziria nossas despesas de pesquisa em aproximadamente 50x.
Mas esse problema também pode ser resolvido com muita facilidade usando uma codificação especial que torna as consultas de intervalo possíveis e rápidas. Na literatura, esses bitmaps são chamados de bitmaps codificados por intervalo.

Nos bitmaps codificados por intervalo, não definimos apenas um bit específico, digamos, para o valor 200, mas definimos todos os bits em 200 ou mais. O mesmo para 300.
Portanto, usando essa consulta de intervalo de representação de bitmap codificada por intervalo, a resposta pode ser respondida com apenas duas passagens pelo bitmap. Obtemos todos os hotéis que custam menos que ou igual a 300 dólares e removemos do resultado todos os hotéis que custam menos que ou iguais a 199 dólares. Concluído

Você ficaria surpreso, mas mesmo as consultas geográficas são possíveis usando bitmaps. O truque é usar uma representação como o Google S2 ou similar que inclua uma coordenada em uma figura geométrica que possa ser representada como três ou mais linhas indexadas. Se você usar essa representação, poderá representar a consulta geográfica como várias consultas de intervalo nesses índices de linha.
Soluções prontas
Bem, espero ter despertado um pouco o seu interesse. Agora você tem mais uma ferramenta e se precisar implementar algo assim em seu serviço, saberá onde procurar.
Tudo bem, mas nem todo mundo tem tempo, paciência e recursos para implementar o índice de bitmap, especialmente quando se trata de coisas mais avançadas, como instruções SIMD.
Não tema, existem dois produtos de código aberto que podem ajudá-lo em seu esforço.

Rugindo
Primeiro, há uma biblioteca que eu já mencionei chamada "bitmaps rujir". Esta biblioteca implementa o "contêiner" rujir e todas as operações bit a bit que você precisaria para implementar um índice de bitmap completo.
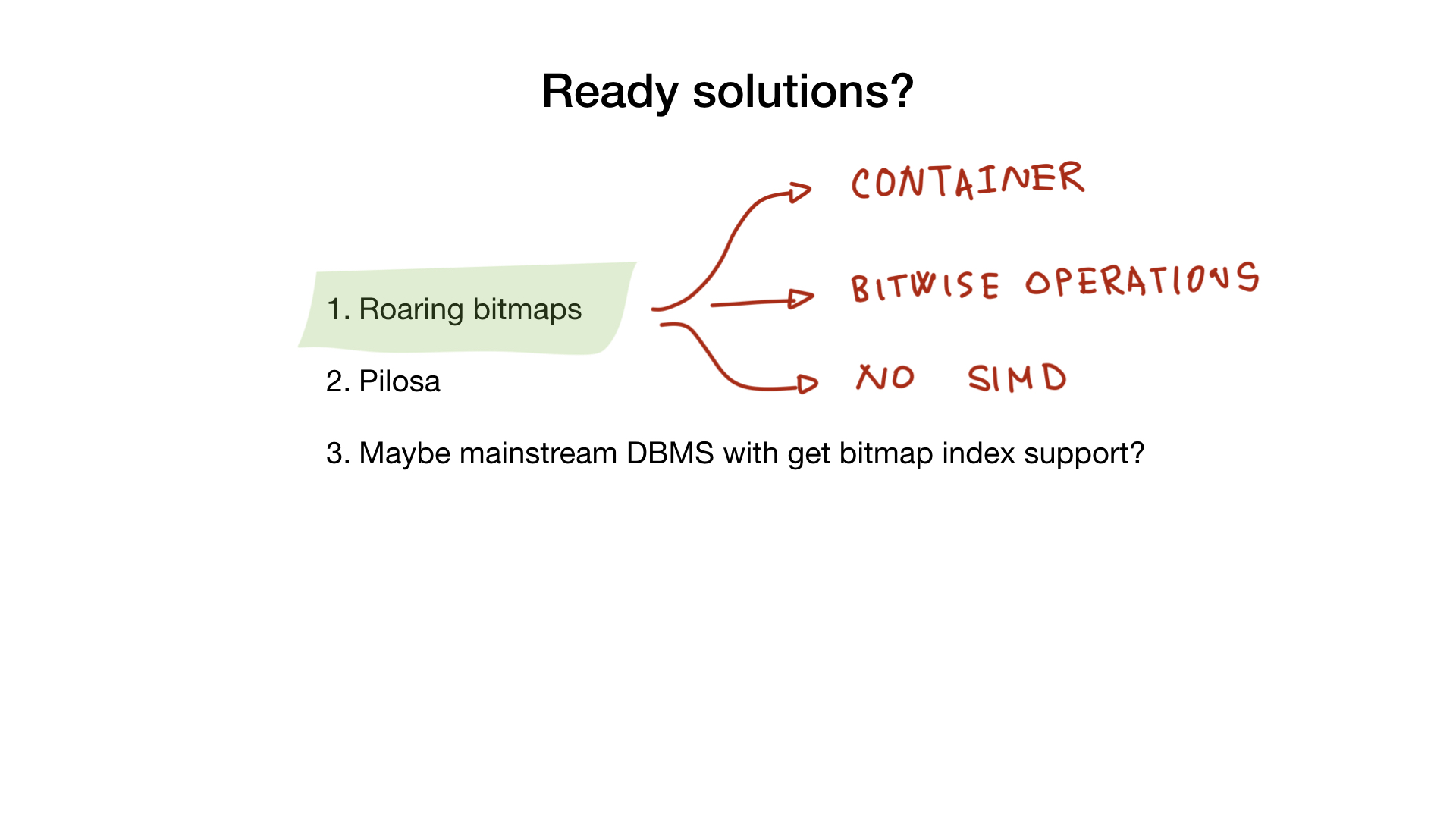
Infelizmente, as implementações go não usam SIMD, portanto, elas apresentam um desempenho um pouco menor do que, digamos, a implementação C.
Pilosa
Outro produto é um DBMS chamado Pilosa que possui apenas índices de bitmap. É um projeto recente, mas ganhou muita força ultimamente.
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0 ">
A Pilosa usa bitmaps ruidosos por baixo e fornece, simplifica ou explica quase tudo o que eu tenho falado hoje: binning, bitmaps codificados por intervalo, a noção de campos etc.
Vamos ver brevemente um exemplo de Pilosa em uso ...

O exemplo que você vê é muito parecido com o que vimos anteriormente. Criamos um cliente para o servidor pilosa, criamos um índice e campos para nossas características. Preenchemos os campos com dados aleatórios com algumas probabilidades, como fizemos anteriormente e, em seguida, executamos nossa consulta de pesquisa.
Você vê o mesmo padrão básico aqui. NÃO é caro cruzado ou com ed com terraço e cruzado com reservas.
O resultado é o esperado.

E, finalmente, espero que em algum momento no futuro, bancos de dados como mysql e postgresql obtenham um novo tipo de índice: índice de bitmap.

Palavras finais

E se você ainda está acordado, agradeço por isso. A falta de tempo significou que eu tive que examinar muitas coisas neste post, mas espero que tenha sido útil e talvez até inspirador.
Os índices de bitmap são úteis para conhecer e entender, mesmo que você não precise deles no momento. Mantenha-os como mais uma ferramenta em seu portfólio.
Durante minha palestra, vimos vários truques de desempenho que podemos usar e coisas com as quais o Go luta no momento. Definitivamente, essas são coisas que todo programador Go precisa saber.
E isso é tudo que tenho para você por enquanto. Muito obrigado!