Parte 1 >>
Parte 2 >>
Parte 3
Um dos processadores mais populares da década passada foi o Intel Core i7-2600K. O design foi revolucionário, pois ofereceu um salto significativo no desempenho e na eficiência de um processador de núcleo único, e o processador também respondeu bem ao overclock. As próximas gerações de processadores Intel não pareciam mais tão interessantes e, muitas vezes, não davam aos usuários uma razão para atualizar; portanto, a frase "ficarei com meus 2600K" tornou-se onipresente nos fóruns e nos sons até hoje. Nesta revisão, tiramos a poeira da caixa com os processadores antigos e conduzimos o veterano através de um conjunto de benchmarks em 2019, tanto nos parâmetros de fábrica quanto no overclock, para garantir que ele ainda seja o campeão.
 Foto de família Core i7
Foto de família Core i7Por que o 2600K se tornou crucial para a geração
Sente-se em uma cadeira, sente-se e imagine-se em 2010. Este foi o ano em que você analisou seu sistema legado Core 2 Duo ou Athlon II e percebeu que estava na hora de fazer uma atualização. Você já está familiarizado com a arquitetura do Nehalem e sabe que o Core i7-920 acelera bem e faz concorrentes. Foi um bom momento, mas de repente a Intel reequilibrou o setor e criou um produto verdadeiramente revolucionário. Os ecos de nostalgia pelos quais ainda são ouvidos.
 Core i7-2600K: a Sandy Bridge mais rápida (até 2700K)
Core i7-2600K: a Sandy Bridge mais rápida (até 2700K)Este novo produto foi o Sandy Bridge. A AnandTech lançou uma revisão exclusiva, e os resultados eram quase impossíveis de acreditar, por muitas razões. De acordo com nossos testes da época, o processador era incomparavelmente mais alto do que tudo o que vimos antes, especialmente considerando os monstros térmicos Pentium 4 lançados alguns anos antes. Uma atualização principal baseada no processo de 32nm da Intel foi o maior ponto de virada no desempenho do x86 e, desde então, não vimos tais descobertas. A AMD precisará de mais 8 anos para obter seu momento de fama com a série Ryzen. A Intel conseguiu tirar proveito do sucesso de seu melhor produto e conquistar um lugar de campeão.
Nesse projeto básico, a Intel não economizou em inovação. Um dos elementos principais foi o cache de microoperação. Isso significava que as instruções recém-decodificadas, necessárias novamente, já foram decodificadas, em vez de desperdiçar energia com a decodificação. Para a Intel com Sandy Bridge e muito mais tarde para a AMD com Ryzen, habilitar o cache micro-operacional foi um milagre para o desempenho de thread único. A Intel também começou a melhorar o multithreading simultâneo (que por várias gerações foi chamado HyperThreading), trabalhando gradualmente na alocação dinâmica de threads de computação.
O design quad-core do melhor processador no lançamento, o Core i7-2600K, tornou-se a base de produtos nas próximas cinco gerações da arquitetura Intel, incluindo Ivy Bridge, Haswell, Broadwell, Skylake e Kaby Lake. Desde Sandy Bridge, embora a Intel tenha mudado para um processo menor e aproveitado o menor consumo de energia, a corporação não conseguiu recriar esse salto excepcional na largura de banda líquida das equipes. Posteriormente, o crescimento no ano foi de 1 a 7%, principalmente devido ao aumento de buffers operacionais, portas de execução e suporte a comandos.
Como a Intel não conseguiu replicar a inovação do Sandy Bridge, e a microarquitetura principal foi a chave para o desempenho do x86, os usuários que compraram o Core i7-2600K (eu comprei dois) permaneceram nele por um longo tempo. Em grande parte devido à expectativa de outro grande salto no desempenho. E ao longo dos anos, sua frustração está crescendo: por que investir em um Kaby Lake Core i7-7700K de quatro núcleos com clock de 4,7 GHz quando seu Sandy Bridge Core i7-2600K de quatro núcleos ainda está com overclock de 5,0 GHz?
(As respostas da Intel geralmente se referem ao consumo de energia e novos recursos, como GPUs e unidades via PCIe 3.0. Mas alguns usuários não estão satisfeitos com essas explicações.)
É por isso que o Core i7-2600K definiu uma geração. Permaneceu válido, a princípio para a alegria da Intel e depois para a decepção quando os usuários não quiseram atualizar. Agora, em 2019, entendemos que a Intel já foi além dos quatro núcleos em seus principais processadores e, se o usuário for muito caro para DDR4, ele poderá mudar para o novo sistema Intel ou escolher o caminho da AMD. Mas aqui está a questão de como o Core i7-2600K lida com as cargas de trabalho e jogos de 2019; ou, mais precisamente, como o Core i7-2600K com overclock suporta?
Encontre as diferenças: Sandy Bridge, Kaby Lake, Coffee Lake
Na verdade, o Core i7-2600K não era o processador Sandy Bridge convencional mais rápido. Alguns meses depois, a Intel lançou um 2700K de "alta frequência" um pouco mais no mercado. Funcionou quase da mesma forma e acelerou de maneira semelhante a 2600K, mas custou um pouco mais. A essa altura, os usuários que viram um salto no desempenho e fizeram o upgrade já estavam em 2600K e continuaram com ele.
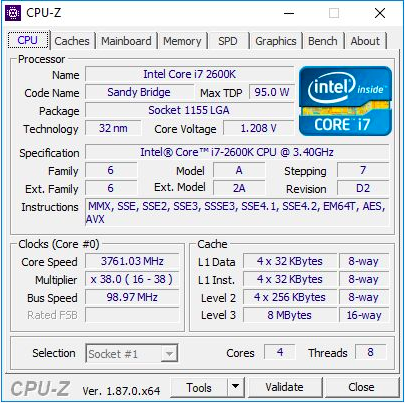
O Core i7-2600K era um processador quad-core de 32 nm com tecnologia HyperThreading, com uma frequência base de 3,4 GHz, uma frequência turbo de 3,8 GHz e um TDP nominal de 95 watts. Então, o TDP da Intel ainda não estava divorciado da realidade: em nossos testes para este artigo, vimos um pico de consumo de energia de 88 W em uma CPU sem clock. O processador veio com gráficos integrados Intel HD 3000 e suportou memória DDR3-1333 por padrão. A Intel estabeleceu um preço de US $ 317 ao lançar o chip.
Para este artigo, usei o segundo i7-2600K, que comprei quando eles apareceram pela primeira vez. Foi testado na freqüência padrão e com overclock para 4,7 GHz em todos os núcleos. Isso é um overclock médio - o melhor desses chips opera na frequência de 5,0 GHz - 5,1 GHz no modo diário. Na verdade, eu me lembro bem como meu primeiro Core i7-2600K funcionou a 5,1 GHz em todos os núcleos e até 5,3 GHz (também em todos os núcleos), durante competições de overclock no meio do inverno, em temperatura ambiente a uma temperatura de cerca de 2 ° C, usei um poderoso resfriador de líquido e radiadores de 720 mm. Infelizmente, com o tempo, danifiquei esse chip e agora ele não carrega nem na frequência e tensão nominais. Portanto, devemos usar meu segundo chip, que não foi tão bom, mas ainda é capaz de dar uma idéia do processador com overclock. Durante o overclock, também usamos a memória com overclock, DDR3-2400 C11.
Vale ressaltar que, desde o lançamento do Core i7-2600K, passamos do Windows 7 para o Windows 10. O Core i7-2600K não suporta as instruções do AVX2 e não foi criado para o Windows 10; portanto, será especialmente interessante ver como isso é exibido nos resultados.

 Core i7-7700K: o mais recente processador quad core Intel Core i7 com tecnologia HyperThreading
Core i7-7700K: o mais recente processador quad core Intel Core i7 com tecnologia HyperThreadingO mais rápido e mais novo (e mais recente?) Processador Quad-core com HyperThreading, lançado pela Intel, foi o Core i7-7700K, um membro da família Kaby Lake. Este processador é construído com a tecnologia de processo aprimorada de 14nm da Intel, funciona com uma frequência base de 4,2 GHz e uma frequência turbo de 4,5 GHz. Seu TDP com uma potência nominal de 91 watts em nosso teste mostrou um consumo de energia de 95 watts. Ele vem com gráficos Intel Gen9 HD 630 e suporta memória DDR4-2400 padrão. A Intel lançou um chip com um preço declarado de 339 dólares.
Juntamente com o 7700K, a Intel também lançou seu primeiro processador dual-core com overclock com hipertreading - Core i3-7350K. No decorrer desta análise, fizemos um overclock em um Core i3 e o comparamos com o Core i7-2600K nas configurações de fábrica, tentando responder à pergunta se a Intel conseguiu obter um desempenho de processador de núcleo duplo semelhante ao antigo carro-chefe de quatro núcleos. Como resultado, enquanto o i3 prevalecia no desempenho de thread único e trabalhava com memória, a falta de alguns núcleos na conta tornava a maioria das tarefas muito trabalhosas para o Core i3.

 Core i7-9700K: o topo mais recente do Intel Core i7 (agora com 8 núcleos)
Core i7-9700K: o topo mais recente do Intel Core i7 (agora com 8 núcleos)Nosso processador mais recente para testes é o Core i7-9700K. Na geração atual, não é mais o carro-chefe do Lago do Café (agora é o i9-9900K), mas possui oito núcleos sem hipertraining. A comparação com a 9900K, que tem o dobro de núcleos e threads, parece inútil, especialmente quando o preço do i9 é de US $ 488. Por outro lado, o Core i7-9700K é vendido a granel por "apenas" US $ 374, com uma frequência base de 3,6 GHz e uma frequência turbo de 4,9 GHz. Seu TDP é definido pela Intel em 95 watts, mas na placa-mãe do consumidor, o chip consome ~ 125 watts em carga máxima. A memória DDR4-2666 é suportada como padrão.
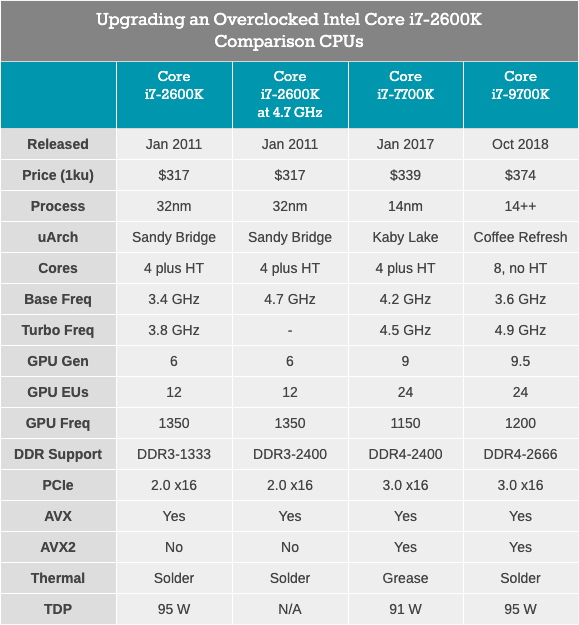
O Core i7-2600K é forçado a trabalhar com DDR3, suporta PCIe 2.0, não PCIe 3.0 e não foi projetado para funcionar com unidades NVMe (que não estão envolvidas neste teste). Será interessante ver a proximidade do veterano com overclock do Core i7-7700K e que tipo de crescimento veremos quando mudarmos para algo como o Core i7-9700K.
Sandy Bridge: arquitetura principal
Em 2019, estamos falando de chips de 100-200 mm2 com até oito núcleos de alto desempenho e criados com a mais recente tecnologia de processo Intel ou AMD GlobalFoundries / TSMC. Mas a Sandy Bridge de 32 nm era uma fera completamente diferente. O processo de produção ainda era "plano", sem transistores FinFET. Na nova CPU, a segunda geração de High-K foi implementada e a escala de 0,7x foi alcançada em comparação com a anterior, maior tecnologia de processo de 45 nm. O Core i7-2600K era o maior chip quad-core e continha 1,16 bilhão de transistores por 216 mm2. Para comparação, o mais recente processador Coffee Lake a 14 nm possui oito núcleos e mais de 2 bilhões de transistores em uma área de ~ 170 mm2.
O segredo do enorme salto de desempenho está na microarquitetura do processador. Sandy Bridge prometeu (e garantiu) desempenho significativo em velocidades iguais, em comparação com os processadores Westmere da geração anterior, e também formou o circuito base dos chips Intel para a próxima década. Muitas inovações importantes apareceram pela primeira vez no varejo com o advento do Sandy Bridge e, em seguida, muitas iterações foram repetidas e aprimoradas, atingindo gradualmente o alto desempenho que usamos hoje.
Na revisão atual, contei bastante com o relatório inicial de microarquitetura 2600K da Anandtech, lançado em 2010. Obviamente, com algumas adições baseadas em uma aparência moderna neste processador.
Breve análise: núcleo da CPU com execução extraordinária de instruções
Para os novatos no design de processadores, aqui está uma rápida visão geral de como um processador de processador extra funciona. Em resumo, o kernel é dividido em interfaces externas e internas (front-end e back-end), e os dados primeiro vão para a interface externa.
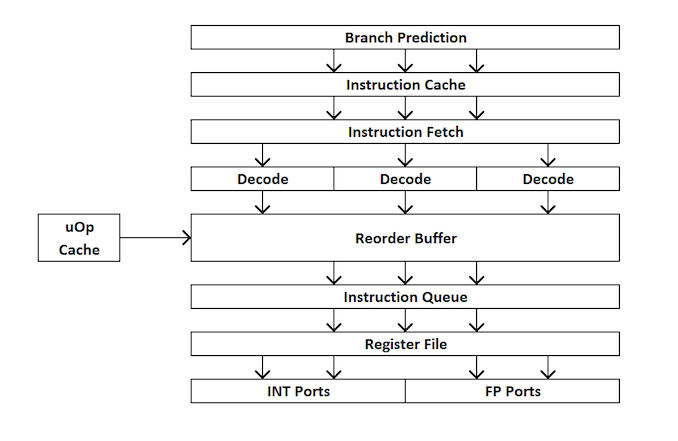
Na interface externa, temos pré-buscadores e preditores de ramificação que preverão e recuperarão instruções da memória principal. A idéia é que, se você puder prever quais dados e instruções serão necessários no futuro próximo (antes que eles sejam necessários), economize tempo colocando esses dados perto do kernel. Em seguida, as instruções são colocadas em um decodificador, que converte a instrução de bytecode em uma série de "microoperações" que o kernel pode processar.
Existem diferentes tipos de decodificadores para instruções simples e complexas - instruções simples do x86 são facilmente mapeadas para uma única micro-operação, enquanto instruções mais complexas podem ser decodificadas para mais operações. A situação ideal é o coeficiente de decodificação o mais baixo possível, embora algumas vezes as instruções possam ser divididas em um número maior de microoperações se essas operações puderem ser executadas em paralelo (paralelismo no nível de comando ou ILP).
Se o kernel possui um cache de microoperação, ele também é um cache uOp, e os resultados de cada instrução decodificada são armazenados nele. Antes que a instrução seja decodificada, o kernel verifica se essa instrução específica foi decodificada recentemente e, se for bem-sucedida, usa o resultado do cache em vez de recodificar, o que consome energia.
Agora, as micro-operações colocam “filas para alocação” - fila de alocação. O núcleo moderno pode determinar se as instruções fazem parte de um ciclo simples ou se as uOps (micro-operações) podem ser combinadas para acelerar todo o processo. Em seguida, os uOps são alimentados no buffer de reordenação, que forma o “back-end” do kernel.
No back-end, começando com o buffer de reordenação, os uOps podem ser reorganizados dependendo de onde os dados necessários para cada microoperação estão localizados. Esse buffer pode renomear e distribuir micro-operações, dependendo de onde elas devem ir (operações inteiras ou FP) e, dependendo do kernel, também pode atuar como um mecanismo para excluir instruções completas. Após o pedido novamente, os buffers de uOps são enviados ao agendador na ordem necessária para garantir que os dados estejam prontos e maximizar a taxa de transferência do uOp.
O planejador envia uOps para as portas de execução (para executar cálculos) conforme necessário. Alguns kernels têm um único planejador para todas as portas, mas em alguns casos ele é dividido em um planejador para operações de número inteiro / vetor. A maioria dos kernels com execução extraordinária possui de 4 a 10 portas (mais algumas), e essas portas executam os cálculos necessários para que a instrução "passe" pelo kernel. As portas de execução podem assumir a forma de um módulo de carregamento (carregamento de um cache), um módulo de armazenamento (armazenamento em cache), um módulo de operações matemáticas inteiras, um módulo de operações matemáticas com ponto flutuante, além de operações matemáticas vetoriais, módulos de divisão especiais e alguns outros para operações especiais . Após o funcionamento da porta de execução, os dados podem ser armazenados em um cache para reutilização, colocado na memória principal; neste momento, a instrução é enviada para a fila de exclusão e, finalmente, excluída.
Esta visão geral não cobre alguns dos mecanismos que os kernels modernos usam para facilitar o armazenamento em cache e a recuperação de dados, como buffers de transação, buffers de fluxo, marcação etc. Alguns mecanismos melhoram iterativamente a cada geração, mas geralmente quando falamos sobre "instruções" por relógio "como um indicador de desempenho, nós nos esforçamos para" pular "o máximo de instruções possível através do kernel (através do front-end e back-end). Esse indicador depende da velocidade de decodificação no front-end do processador, das instruções de pré-busca, do buffer de reordenação e do uso máximo das portas de execução, além da remoção do número máximo de instruções executadas para cada ciclo de clock.
Com base no exposto, esperamos que o leitor seja capaz de entender melhor os resultados dos testes da Anandtech obtidos durante o lançamento do Sandy Bridge.
Sandy Bridge: Front-End
A arquitetura de CPU do Sandy Bridge parece evolutiva rapidamente, mas é revolucionária em termos do número de transistores que foram alterados desde Nehalem / Westmere. A mudança mais importante para o Sandy Bridge (e todas as microarquiteturas depois dele) é o cache microoperacional (uOp cache).

Um cache micro-operacional apareceu no Sandy Bridge, que armazena em cache as instruções após decodificá-las. Não existe um algoritmo complicado; as instruções decodificadas são simplesmente salvas. Quando o Sandy Bridge do prefetter recebe uma nova instrução, a instrução é pesquisada primeiro no cache de microoperação e, se for encontrada, o restante do pipeline trabalha com o cache e o frontend é desativado. A decodificação de hardware é uma parte muito complexa do pipeline x86 e desativá-lo economiza uma quantidade significativa de energia.
Esse é um cache de mapeamento direto e pode armazenar aproximadamente 1,5 KB de micro-operações, o que é realmente equivalente a um cache de instruções de 6 KB. O cache de microoperação está incluído no cache de instruções L1 e sua taxa de acertos para a maioria dos aplicativos atinge 80%. O cache de microoperação possui uma largura de banda um pouco mais alta e mais estável em comparação com o cache de instruções. As instruções L1 e os caches de dados reais não foram alterados; eles ainda têm 32 KB cada (um total de 64 KB L1).
Todas as instruções provenientes do decodificador podem ser armazenadas em cache por esse mecanismo e, como eu já disse, existem alguns algoritmos especiais - simplesmente todas as instruções são armazenadas em cache. Os dados não utilizados por muito tempo são excluídos quando o local acaba. O cache micro-operacional pode parecer semelhante ao cache de rastreamento no Pentium 4, mas com uma diferença significativa: ele não armazena em cache os rastreamentos. Este é simplesmente um cache de instruções que armazena micro-operações em vez de macro-operações (instruções x86).
Juntamente com o novo cache micro-operacional, a Intel também introduziu um módulo de previsão de ramificação completamente redesenhado. A nova BPU é quase a mesma do seu antecessor, mas muito mais precisa. Maior precisão é o resultado de três grandes inovações.
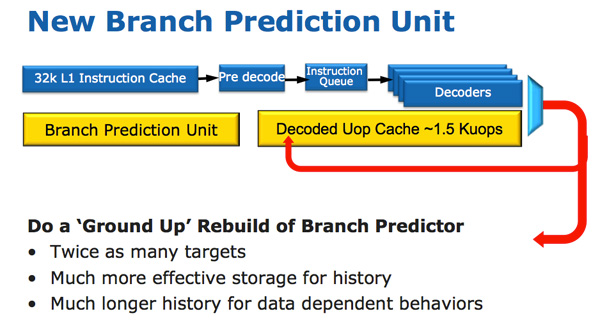
O preditor de ramificação padrão é um preditor de 2 bits. Cada ramificação é marcada na tabela como aceita / não aceita com confiabilidade apropriada (forte / fraca). A Intel descobriu que quase todos os ramos previstos por esse preditor bimodal têm confiança "alta". Portanto, no Sandy Bridge, um preditor bimodal de ramificação usa um bit de confiança para várias ramificações, em vez de um bit de confiança para cada ramificação. Como resultado, sua tabela de histórico de ramificações terá o mesmo número de bits, representando muito mais ramificações, o que levará a previsões mais precisas no futuro.
Sandy Bridge: perto do núcleo
Com o crescimento dos processadores com vários núcleos, o gerenciamento do fluxo de dados entre núcleos e memória tornou-se um tópico importante. Vimos várias maneiras diferentes de mover dados pela CPU, como barra transversal, anel, malha e, posteriormente, chips de E / S completamente separados. A batalha da próxima década (2020+), como mencionado anteriormente pela AnandTech, será uma batalha de conexões internucleares, e agora já está começando.
Uma característica do Sandy Bridge é justamente o fato de ter sido o primeiro CPU de consumo da Intel, que usou um barramento em anel conectando todos os núcleos, memória, cache de último nível e gráficos integrados. Esse ainda é o mesmo design que vemos nos modernos processadores Coffee Lake.
Anel de pneu
O Nehalem / Westmery Bridge adiciona um processador gráfico e um mecanismo de transcodificação de vídeo ao chip que compartilha o cache L3. E, em vez de colocar mais fios no L3, a Intel introduziu o barramento em anel.
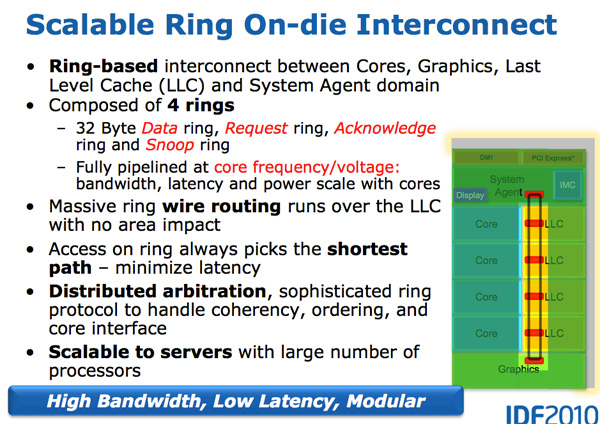
Arquitetonicamente, esse é o mesmo barramento em anel usado no Nehalem EX e no Westmere EX. Cada núcleo, cada fragmento do cache L3 (LLC), processador gráfico integrado, mecanismo de mídia e agente do sistema (um nome engraçado para a ponte norte) são conectados ao barramento em anel. : , , . 32 . .
L3, Westmere — 96 /. Sandy Bridge 4 , Westmere, , 384 /.
, L3 36 Westmere 26 — 31 Sandy Bridge ( , , ). , Westmere, - L3 — un-Core , Intel « », - L3. ( «un-Core» .)
- L3, , . , L3 , . L3, , L3 , . .
L3 , . Sandy Bridge L3, . , . Westmere , , Sandy Bridge . , . , , . , «», .
- Intel un-core SB, Sandy Bridge « ». (-, un-core , - ). . 16 PCIe 2.0, x8. DDR3, , , Lynnfield (Clarkdale ).
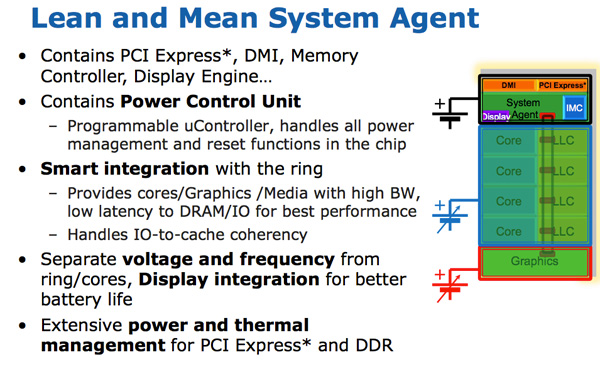
DMI, PCU ( ). SA , , .
Sandy Bridge
Sandy Bridge Westmere . 10-30%, Sandy Bridge , Intel Westmere (Clarkdale / Arrandale). 45 32 , IPC.
Sandy Bridge 32- , . . GPU . , .
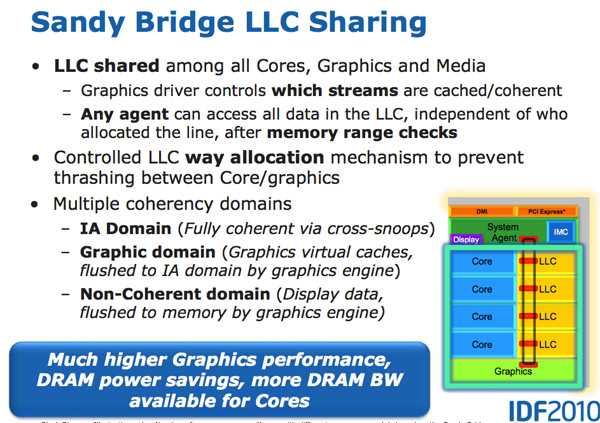
GPU Sandy Bridge, - L3. , L3, , . , , , . .
SNB ( Gen 6) . : , , . – , , .
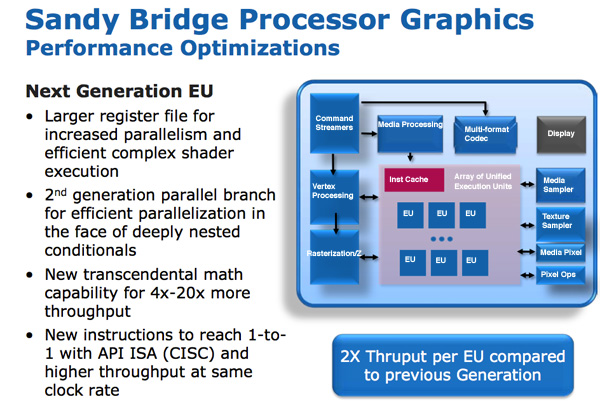
/ / (execution units), Intel EU. EU . ISA -- API DirectX 10, CISC- . - API IPC EU.
EU . EU, . Intel , , Westmere.
Intel « ». , . , , . , . Intel 64 80, , , 120 Sandy Bridge. - .

, EU.
GPU Sandy Bridge: 6 EU 12 EU. ( ) 12 EU, SKU 6 12 . Sandy Bridge Intel, , Intel , GPU. (2019 .) 24 EU (Gen 9.5), 10- ~ 64 EU (Gen11).
Sandy Bridge Media Engine
GPU Sandy Bridge -. SNB : .
: . Intel SNB, EU. Intel , SNB HD-.
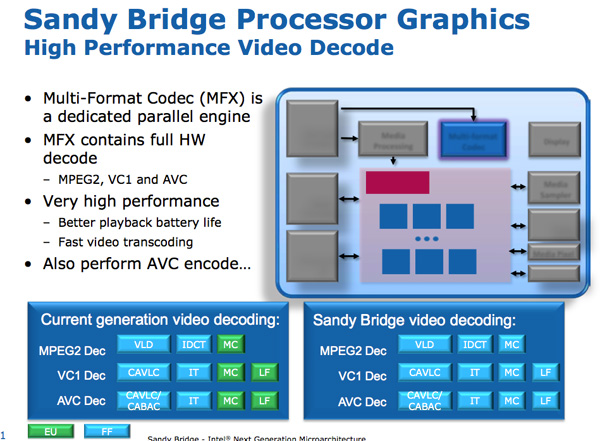
Sandy Bridge. Intel ~ 3- 1080p 30 / iPhone 640 x 360. 14 400 .
/ . Sandy Bridge 3 2 / .
,
Lynnfield Intel, . , TDP 95 , , , -.
, - . , , — , .
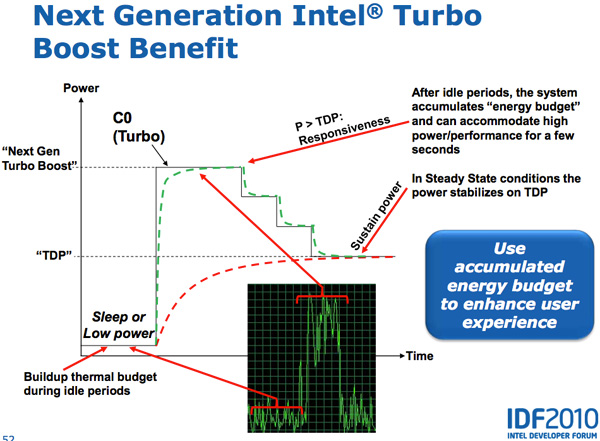
Sandy Bridge , PCU TDP ( 25 ). PCU , . , , TDP. , , TDP, , , TDP. SNB TDP, PCU .

CPU, GPU Turbo . , GPU, SNB, CPU, GPU. , CPU, GPU CPU. Sandy Bridge , , .
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?