Em uma implementação real de ML, o próprio aprendizado leva um quarto do esforço. Os três quartos restantes são a preparação de dados por meio de problemas e burocracia, uma implantação complexa frequentemente em circuito fechado sem acesso à Internet, configuração da infraestrutura, teste e monitoramento. Documentos em centenas de folhas, modo manual, conflitos de versão de modelo, código aberto e empresa agressiva - tudo isso aguarda um cientista de dados. Mas ele não está interessado em questões operacionais "chatas"; ele deseja desenvolver um algoritmo, obter alta qualidade, retribuir e não se lembrar mais.
Talvez, em algum lugar, o ML seja implementado mais fácil, mais simples, mais rápido e com um botão, mas não vimos esses exemplos. Tudo o que está acima é a experiência da Front Tier em fintech e telecomunicações. Sergey Vinogradov, especialista em arquitetura de sistemas altamente carregados, em grandes armazenamentos e em análise de dados pesados, falou sobre ele no
HighLoad ++ .

Ciclo de vida do modelo
Normalmente, o ciclo de vida em nossa área de assunto consiste em três partes. No primeiro
, uma tarefa vem do negócio . No segundo, um
engenheiro de dados e / ou cientista de dados prepara dados , constrói um modelo. Na terceira parte, o
caos começa. Nos últimos dois, diferentes situações interessantes acontecem.
Jack de todos os comércios
A primeira situação frequente é que um cientista ou engenheiro de dados tem acesso aos produtos, então eles dizem a ele: "Você fez tudo isso, pode apostar".
Uma pessoa pega um
Notebook Jupyter ou um pacote de notebooks, os considera exclusivamente como um artefato de implantação e começa a replicar com alegria em alguns servidores.
Tudo parece estar bem, mas nem sempre. Eu vou te dizer mais tarde porque.
Exploração impiedosa
A segunda história é mais complexa e geralmente acontece em empresas onde a exploração atingiu um estado de insanidade leve. O cientista de dados coloca sua solução em operação. Eles abrem essa caixa preta e vêem algo terrível:
- cadernos
- picles de diferentes versões;
- monte de scripts: não está claro onde e quando executá-los, onde salvar os dados que eles geram.
Nesse quebra-cabeça, a exploração encontra incompatibilidade de versão. Por exemplo, um cientista de dados não especificou uma versão específica da biblioteca e a operação foi a mais recente. Depois de um tempo, o cientista de dados recorre:
- Você configurou o scikit-learn para a versão errada, agora todas as métricas se foram! Precisa reverter para a versão anterior.Isso quebra completamente o estímulo e a exploração sofre.
Burocracia
Nas empresas com logotipos verdes, quando o cientista de dados entra em operação e traz o modelo, geralmente recebe um documento de 800 folhas em resposta: “Siga estas instruções, caso contrário, seu produto nunca verá a luz do dia”.
O triste cientista de dados sai, joga tudo pela metade e depois sai - ele não está interessado em fazer isso.
Implantar
Suponha que um cientista de dados tenha passado por todos os círculos e, no final, tudo tenha sido implantado. Mas ele não será capaz de entender que tudo está funcionando como deveria. Na minha experiência, nos mesmos bancos abençoados, não há monitoramento de produtos de ciência de dados.
É bom que o especialista escreva os resultados de seu trabalho no banco de dados. Depois de um tempo, ele os receberá e verá o que acontece lá dentro. Mas isso nem sempre acontece. Quando uma empresa e um cientista de dados simplesmente acreditam que tudo está funcionando bem e maravilhoso, isso se traduz em casos sem êxito.
IMF
De alguma forma, desenvolvemos um mecanismo de pontuação para uma grande organização de microfinanças. Eles não os deixaram ir ao produto, mas simplesmente pegaram uma cascata de modelos, instalaram e lançaram. Os resultados dos testes dos modelos os satisfizeram. Mas depois de 6 meses eles voltaram:
Está tudo ruim. Os negócios não vão, estamos cada vez pior. Parece que os modelos são excelentes, mas os resultados estão caindo, fraude e inadimplência cada vez mais e menos dinheiro. Pelo que lhe pagamos? Vamos acertar.Ao mesmo tempo, o acesso ao modelo novamente não é fornecido. Além disso, os logs foram descarregados por um mês, seis meses atrás. Estudamos a descarga por mais um mês e chegamos à conclusão de que em algum momento o departamento de TI da IMF alterou os dados de entrada e, em vez de documentos em json, eles começaram a enviar documentos em xml. O modelo esperava json, mas recebeu xml, ficou triste e achou que não havia dados na entrada.
Se não houver dados, a avaliação do que está acontecendo é diferente. Sem monitoramento, isso não pode ser detectado.
Nova versão, cascata e testes
Muitas vezes nos deparamos com o fato de que o modelo funciona bem, mas por algum motivo uma
nova versão foi desenvolvida. O modelo novamente precisa ser trazido de alguma forma, e novamente para passar por todos os círculos do inferno. É bom que as versões da biblioteca sejam as mesmas do modelo anterior e, se não, a implantação começa novamente ...
Às vezes, antes de colocar uma nova versão em batalha, queremos
testá-la - coloque-a no prod, observe o mesmo fluxo de tráfego, verifique se está boa. Essa é novamente a cadeia de implantação completa. Além disso, configuramos os sistemas para que, de acordo com esse modelo, não ocorram resultados reais, se estamos falando de pontuação, mas houve apenas monitoramento e análise dos resultados para análise posterior.
Há situações em que uma
cascata de modelos é usada. Quando os resultados dos seguintes modelos dependem dos anteriores, de alguma forma você precisa estabelecer uma interação entre eles e em algum lugar novamente tudo isso deve ser salvo.
Como resolver esses problemas?
Muitas vezes, uma pessoa resolve problemas
manualmente , especialmente em pequenas empresas. Ele sabe como tudo funciona, lembra todas as versões de modelos e bibliotecas, sabe onde e quais scripts funcionam, quais fachadas de loja são construídas. Tudo isso é maravilhoso. Particularmente bonitas são as histórias que o modo manual deixa para trás.
A história da herança . Um homem bom trabalhava em um pequeno banco. Uma vez ele foi para um país do sul e não voltou. Depois disso, obtivemos uma herança: um monte de código que gera frentes de loja nas quais os modelos de modelos trabalham. O código é bonito, funciona, mas não sabemos a versão exata do script que gera essa ou aquela loja. Na batalha, todas as vitrines estão presentes e todas são lançadas. Passamos dois meses tentando entender esse intrincado emaranhado e de alguma forma estruturá-lo.
Em uma empresa dura, as pessoas não querem se preocupar com todos os tipos de Python, Jupiters, etc. Eles dizem:
- Vamos comprar o IBM SPSS, instalar e tudo ficará ótimo. Problemas com o controle de versão, com fontes de dados, com a implantação de alguma maneira resolvida.Essa abordagem tem o direito de existir, mas nem todos podem pagar. De qualquer forma, esta é uma agulha serrilhada de alta qualidade. Eles ficam sentados, mas não dá certo: entalhes. E geralmente custa muito.
Código aberto é o oposto da abordagem anterior. Os desenvolvedores navegaram na Internet, encontraram muitas soluções de código aberto que resolvem suas tarefas em vários graus. Essa é uma ótima maneira, mas para nós mesmos não encontramos soluções que atendam 100% aos nossos requisitos.
Portanto, escolhemos a opção clássica -
nossa decisão . Suas muletas, bicicletas, todas próprias, nativas.
O que queremos de nossa decisão?
Não escreva tudo sozinho . Queremos levar componentes, especialmente os de infraestrutura, que tenham se mostrado bem e estejam familiarizados com a operação nas instituições com as quais trabalhamos. Acabamos de escrever um ambiente que isolará facilmente o trabalho do cientista de dados do trabalho do DevOps.
Processe dados em dois modos: ambos no modo de lote - Lote e em tempo real . Nossas tarefas incluem os dois modos de operação.
Facilite a implantação e em um perímetro fechado . Ao trabalhar com dados particulares confidenciais, não há conexão com a Internet. Nesse momento, tudo deve chegar com rapidez e precisão à produção. Portanto, começamos a olhar para o Gitlab, o pipeline de CI / CD dentro dele e para o Docker.
Um modelo não é um fim em si mesmo. Não resolvemos o problema de construir um modelo, resolvemos um problema de negócios.
Dentro do pipeline, deve haver regras e um conglomerado de modelos com suporte para a
versão de todos os componentes do pipeline.
O que se entende por pipeline? Na Rússia, a Lei Federal 115 sobre o combate à lavagem de dinheiro e ao financiamento do terrorismo está em vigor. Somente o índice das recomendações do Banco Central ocupa 16 telas. Essas são regras simples que um banco pode cumprir se tiver esses dados ou não, se não tiver dados.
A avaliação de um mutuário, transação financeira ou outro processo de negócios é um fluxo de dados que processamos. Um fluxo deve passar por esse tipo de regra. Essas regras são descritas de maneira fácil pelo analista. Ele não é um cientista de dados, mas conhece bem a lei ou outras instruções. O analista se senta e, em linguagem simples, descreve as verificações dos dados.
Crie cascatas de modelos . Freqüentemente surge uma situação quando o próximo modelo usa para o seu trabalho os valores obtidos nos modelos anteriores.
Teste hipóteses rapidamente. Repito a tese anterior: um cientista de dados fez algum tipo de modelo, ele gira em batalha e funciona bem. Por alguma razão, o especialista encontrou uma solução melhor, mas não quer arruinar o fluxo de trabalho estabelecido. O cientista de dados está suspendendo um novo modelo no mesmo tráfego de combate no sistema de combate. Ela não participa diretamente da tomada de decisões, mas serve o mesmo tráfego, considera algumas conclusões e essas conclusões são armazenadas em algum lugar.
Recurso de reutilização fácil. Muitas tarefas têm o mesmo tipo de componentes, especialmente aqueles relacionados à extração de recursos ou regras. Queremos arrastar esses componentes para outros pipelines.
O que você decidiu fazer?
Primeiro queremos monitoramento. E dois desse tipo.
Monitoramento
Monitoramento técnico. Se algum componente do pipeline for implantado, em operação, eles deverão ver o que acontece com o componente: como ele consome memória, CPU, disco.
Monitoramento de negócios. Esta é uma ferramenta de cientista de dados que permite abstrair das nuances técnicas da implementação. No nível do projeto, a construção ajuda a determinar quais métricas de modelo devem estar disponíveis no monitoramento, por exemplo, na distribuição de recursos ou nos resultados do serviço de pontuação.
Um cientista de dados define métricas e não deve se preocupar com a forma como elas entram no sistema de monitoramento. A única coisa importante é que ele definiu essas métricas e a aparência do painel no qual as métricas serão exibidas. Em seguida, o especialista lançou tudo sobre a produção, implantou e, depois de um tempo, as métricas se concentraram no monitoramento. Assim, um cientista de dados sem acesso ao produto pode ver o que está acontecendo dentro do modelo.
Teste
Teste o
pipeline para obter consistência . Dadas as especificidades do pipeline, esse é um tipo de gráfico de computação. Queremos entender que estamos implementando um gráfico, podemos ignorá-lo e encontrar uma maneira de sair dele.
O gráfico possui componentes - módulos. Todos os módulos devem passar no teste de unidade e integração. O processo deve ser transparente e fácil para um cientista de dados.
O desenvolvedor descreve o modelo e testa sozinho ou com a ajuda de outra pessoa. Coloca tudo no Gitlab, o pipeline configurado pela Integração Contínua aumenta, testa, vê resultados. Se tudo estiver bem - vai além, não - começa de novo.
O cientista de dados está focado no modelo e não sabe o que está por trás. Para isso, ele recebe várias coisas.
- Uma API para integração com o núcleo do próprio sistema via barramento de dados - barramento de mensagens. Nesse caso, o especialista precisa descrever o que está entrando e o que está saindo do modelo, o ponto de entrada e a junção com diferentes componentes dentro do pipeline.
- Após o treinamento do modelo, um artefato é exibido - um arquivo XGBoost ou pickle . O cientista de dados tem um executor para trabalhar com artefatos - ele deve integrar os componentes do pipeline dentro.
- API fácil e transparente para o cientista de dados monitorar a operação dos componentes do pipeline - monitoramento técnico e comercial.
- Uma infraestrutura simples e transparente para integração com fontes de dados e preservação dos resultados do trabalho.
Muitas vezes, os modelos funcionam para nós e, depois de um tempo, chega uma auditoria que deseja elevar toda a história do serviço. A auditoria deseja verificar a exatidão do trabalho, a ausência de fraude da nossa parte. São necessárias ferramentas simples para que qualquer auditor que conheça SQL possa entrar em um repositório especial e ver como tudo funcionou, quais decisões foram tomadas e por quê.
Estabelecemos as bases de duas histórias importantes para nós.
Jornada do Cliente. Esta é uma oportunidade de usar os mecanismos para preservar todo o histórico do cliente - o que aconteceu com o cliente como parte dos processos de negócios implementados neste sistema.
Podemos ter fontes de dados externas, por exemplo, plataformas DMP. Nelas, obtemos informações sobre o comportamento humano na rede e em dispositivos móveis. Isso pode afetar o LTV e os modelos de pontuação de seu modelo. Se o mutuário estiver atrasado no pagamento, podemos prever que essa não é uma intenção maliciosa - há simplesmente problemas. Nesse caso, aplicamos métodos suaves de exposição ao mutuário. Quando os problemas são resolvidos, o cliente fecha o empréstimo. Quando ele vier na próxima vez, conheceremos toda a sua história. O cientista de dados obterá uma história visual do modelo e realizará a pontuação no modo leve.
Identificação de anomalias . Estamos constantemente diante de um mundo muito complexo. Por exemplo, pontos fracos na avaliação acelerada das IMFs podem ser uma fonte de fraude automática.
Customer Journey é um conceito de acesso rápido e fácil ao fluxo de dados que passa pelo modelo. O modelo facilita a detecção de anomalias características de fraude no momento de sua ocorrência em massa.
Como está tudo organizado?
Sem hesitar, tomamos
Kafka como um patch de barramento de mensagens. Esta é uma boa solução usada por muitos de nossos clientes. A operação é capaz de trabalhar com ela.
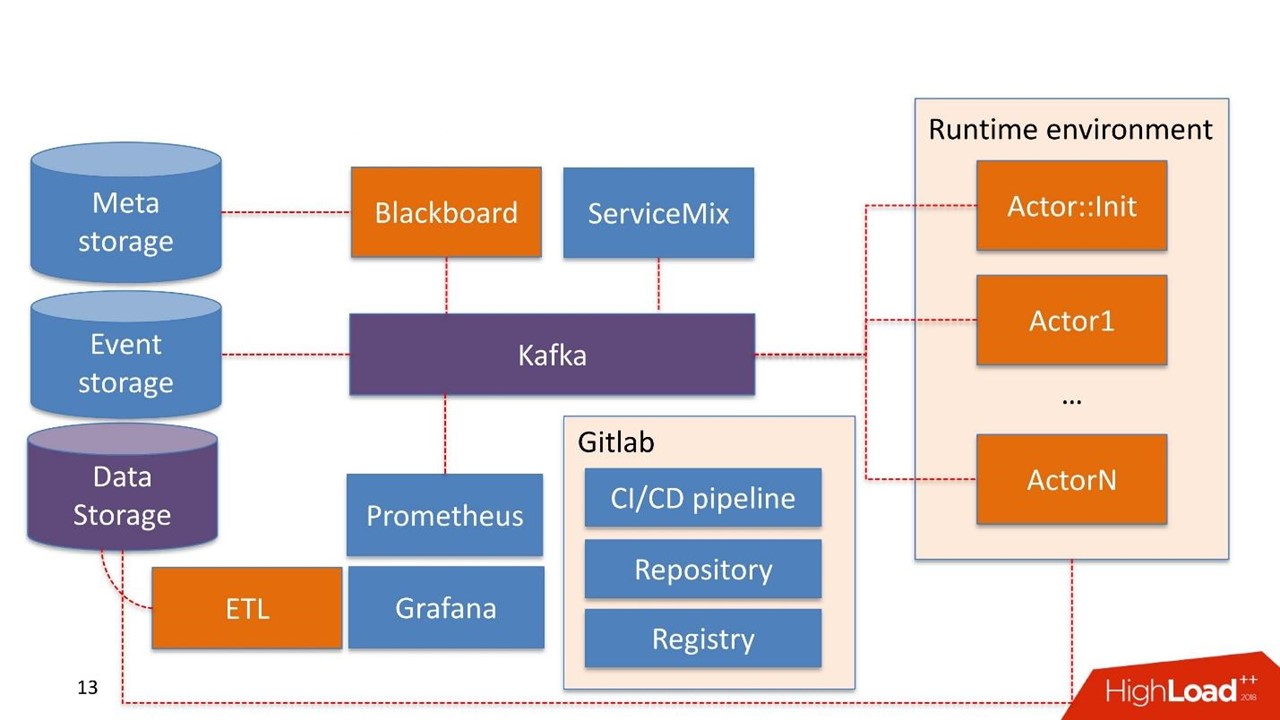
Alguns componentes do sistema já podem ser usados na própria empresa. Não estamos construindo o sistema novamente, mas reutilizando o que eles já possuem.
Armazenamento de dados , neste caso, é o armazenamento que o cliente geralmente já possui. Podem ser bancos de dados Hadoop, relacionais e não relacionais. Podemos trabalhar de forma nativa com HDFS, Hive, Impala, Greenplum e PostgreSQL. Consideramos esses armazenamentos como uma fonte de montras.
Os dados chegam ao armazém, passam pelo nosso ETL ou ETL do cliente, se ele tiver um. Estamos construindo vitrines que são mais usadas dentro dos modelos. O armazenamento de dados é usado no modo somente leitura.
Nossos desenvolvimentos
Quadro-negro O nome é retirado de uma prática bastante estranha de matemáticos dos anos 30-40. Este é o gerente de pipelines que vivem no sistema de administração. O Blackboard possui algum tipo de Meta Storage. Ele armazena os pipelines em si e as configurações necessárias para inicializar todos os componentes.
Todo o trabalho do sistema começa com o Blackboard. Por algum milagre, o pipeline acabou no Meta Storage, Blackboard depois de um tempo entendeu isso, retira a versão atual do pipeline, inicializa-o e envia um sinal dentro de Kafka.
Existe um
ambiente de tempo de execução . Ele é construído no Dockers e pode ser replicado para servidores, inclusive na nuvem privada do cliente.
Fora da caixa vem o
ator principal
:: Init - este é o inicializador. Este é um gênio que pode fazer apenas duas coisas:
construir e
destruir componentes . Ele recebe um comando da Blackboard: "Aqui está o pipeline, ele precisa ser lançado em tais e tais servidores com esses e esses recursos em quantidades e quantidades - trabalhe!" Então o ator começa tudo.
Matematicamente, um ator é uma função que recebe um ou mais objetos como entrada; dentro dele, altera o estado dos objetos de acordo com algum algoritmo; na saída, cria um novo objeto ou altera o estado de um existente.
Tecnicamente, um ator é um programa Python. É executado em um contêiner Docker com seu ambiente.
O ator não sabe sobre a existência de outros atores. A única entidade que sabe que, além do ator, existe todo o pipeline como um todo - esse é o Blackboard. Ele monitora o status de execução de todos os atores no sistema e mantém o estado atual, que é expresso no monitoramento como uma imagem de todo o processo de negócios como um todo.
Ator :: Init gera muitos contêineres do Docker. Além disso, os atores podem trabalhar com armazenamento de dados.
O próprio sistema possui um componente de
armazenamento de eventos . Como armazenamento de eventos, usamos o
ClickHouse . Sua tarefa é simples: todas as informações trocadas entre o ator através do Kafka são armazenadas no ClickHouse. Isso é feito
para auditoria adicional . Este é o log de operações do pipeline.
Os atores também podem ser desenvolvidos para o
Customer Journey . Eles vêem alterações no log do pipeline e podem reconstruir rapidamente as janelas necessárias para os modelos ou componentes funcionarem com as regras, já dentro do pipeline. Este é um processo contínuo de alteração de dados.
O monitoramento é construído primitivamente no
Prometheus . O ator recebe uma API básica e, no modo fechado, mas transparente o suficiente para o desenvolvedor, ele envia mensagens com métricas para Kafka. O Prometheus lê as métricas do Kafka e as salva em seu repositório.
Para visualização, usamos o
Grafana .
Dois pontos de integração
O primeiro é o ponto de integração com fontes de dados que passam por ETLs para o data warehouse. O segundo ponto de integração quando um serviço já é usado por um consumidor de dados, por exemplo, um serviço de pontuação.
Pegamos o
Apache ServiceMix. Por experiência, esses pontos de integração são do mesmo tipo com o mesmo tipo de protocolo: filas SOAP, RESTful e com menos frequência. Toda vez que não queremos desenvolver nosso próprio construtor ou serviço para gerar o próximo serviço SOAP. Portanto, usamos o ServiceMix, descrevemos no SDL, no qual os modelos de dados desse serviço e os métodos existentes nele são construídos. Em seguida, passamos pelo roteador dentro do ServiceMix e ele gera o próprio serviço.
Adicionamos a nós mesmos uma conversão síncrona-assíncrona complicada. Todas as solicitações que vivem dentro do sistema são assíncronas e passam pelo barramento de mensagens.
A maioria dos serviços de pontuação é síncrona. As solicitações do ServiceMix são enviadas por REST ou SOAP. Nesse ponto, ele passa pelo nosso Gateway, que mantém o conhecimento da sessão HTTP. Em seguida, ele envia uma mensagem para Kafka, ela passa por algum pipeline e uma solução é gerada.
No entanto, ainda pode não haver solução. Por exemplo, algo caiu, ou há um SLA difícil de tomar uma decisão, e o Gateway monitora: "OK, recebi uma solicitação, ele veio a mim em outro tópico Kafka, ou nada veio a mim, mas meu gatilho de tempo limite funcionou". Então, novamente, a conversão de síncrono para assíncrono ocorre e, na mesma sessão HTTP, há uma resposta para o consumidor com o resultado do trabalho. Isso pode ser um erro ou uma previsão normal.
Nesse lugar, aliás, comemos um cachorro sem gosto, graças ao grande e poderoso Open Source. Usamos o ServiceMix de uma das versões mais recentes e o Kafka das versões anteriores e tudo funcionou perfeitamente. Escrevemos neste Gateway, com base nos cubos que já estavam no ServiceMix. Quando a nova versão do Kafka foi lançada, felizmente a agarramos, mas o suporte para os cabeçalhos dentro da mensagem em Kafka que existia anteriormente havia mudado. O gateway no ServiceMix não pode mais trabalhar com eles. Para entender isso, passamos muito tempo. Como resultado, criamos nosso Gateway, que pode funcionar com novas versões do Kafka. Escrevemos sobre o problema aos desenvolvedores do ServiceMix e recebemos a resposta: "Obrigado, nós definitivamente o ajudaremos nas próximas versões!"
Portanto, somos forçados a monitorar atualizações e alterar regularmente alguma coisa.
A infraestrutura é o Gitlab. Usamos quase tudo o que há nele.
- Repositório de código.
- Pipeline de integração contínua / entrega contínua.
- Registro para manter um registro de contêineres do Docker.
Componentes
Nós desenvolvemos 5 componentes:
- Quadro - negro - gerenciamento do ciclo de vida do pipeline. Onde, o que e com quais parâmetros executar a partir do pipeline.
- O extrator de recursos funciona de maneira simples - informamos ao extrator de recursos que obtemos esse e tal modelo de dados na entrada, selecionamos os campos necessários a partir dos dados, mapeia-os para determinados valores. Por exemplo, obtemos a data de nascimento do cliente, convertemos para idade, usamos como um recurso em nosso modelo. O extrator de recursos é responsável pelo enriquecimento dos dados.
- Mecanismo baseado em regras - verificação de dados de acordo com as regras. Essa é uma linguagem simples de descrição que permite que uma pessoa familiarizada com a construção de <code> if, caso contrário, <code /> bloqueie a descrição das regras para verificação no sistema.
- Mecanismo de aprendizado de máquina - permite executar o executor, inicializar o modelo treinado e enviá-lo aos dados de entrada. Na saída, o modelo pega dados.
- Mecanismo de decisão - mecanismo de decisão, saia do gráfico. Tendo uma cascata de modelos, por exemplo, diferentes ramos da avaliação do mutuário, você precisa decidir sobre a questão do dinheiro em algum lugar. O conjunto de regras para a solução deve ser simples. , LTV- — , , .
. — , . — , .
pipeline .
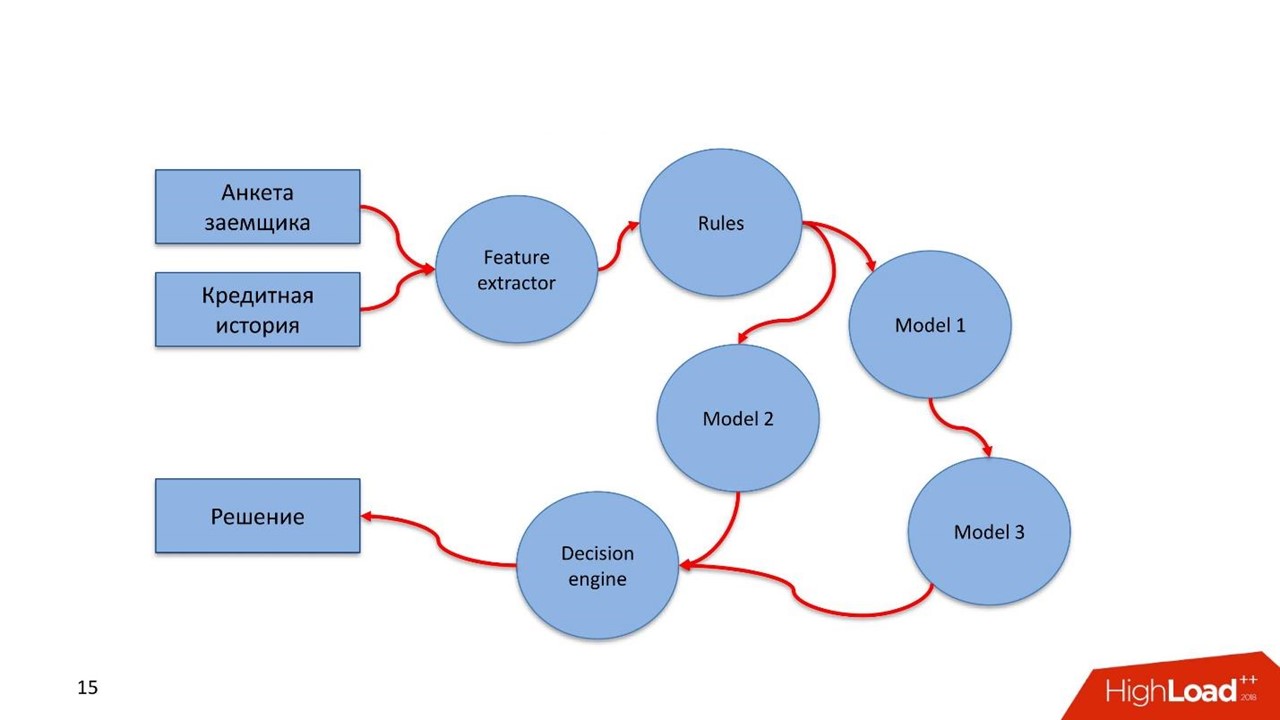
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
Pipeline
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
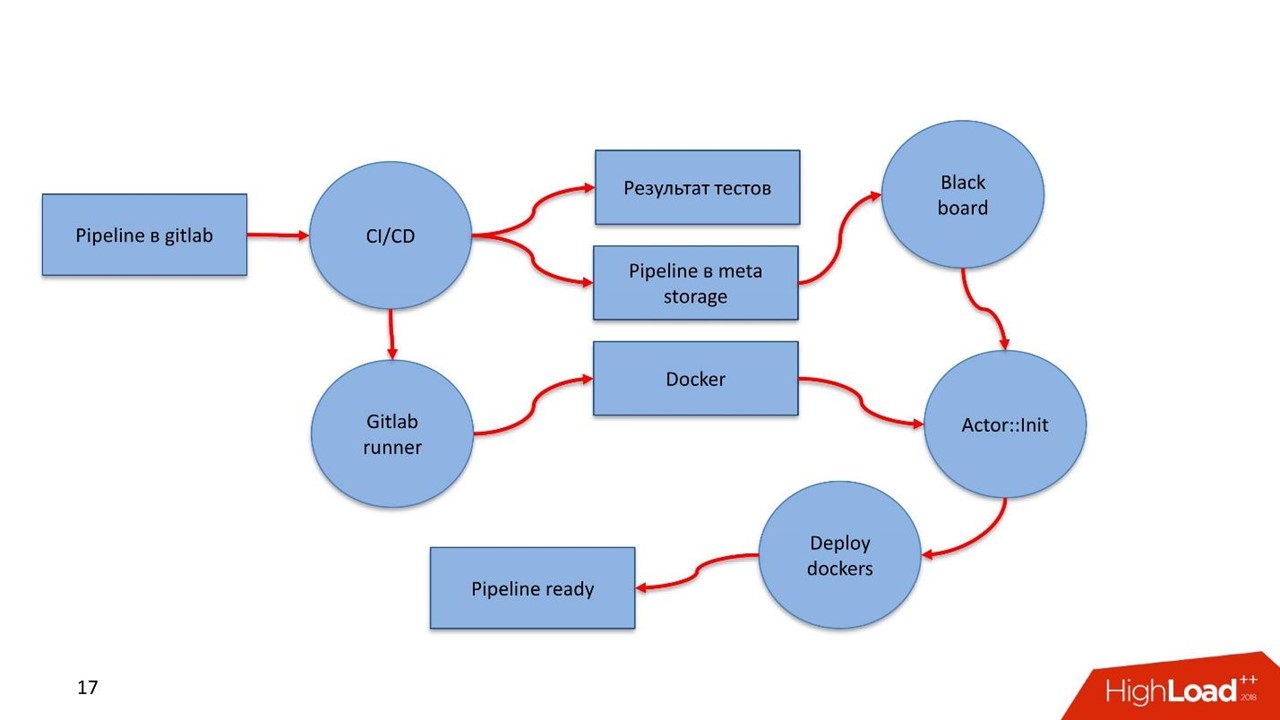
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
Qual é o resultado?
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .