Quanto mais usuários do seu serviço, maior a probabilidade de que eles precisem de ajuda. O chat do suporte técnico é uma solução óbvia, mas bastante cara. Mas se você usar a tecnologia de aprendizado de máquina, poderá economizar algum dinheiro.
O bot agora pode responder a perguntas simples. Além disso, o chatbot pode ser ensinado a determinar as intenções do usuário e capturar o contexto para que ele possa resolver a maioria dos problemas dos usuários sem intervenção humana. Como fazer isso, Vladislav Blinov e Valery Baranova, desenvolvedores do popular assistente Oleg, ajudarão a descobrir.
Passando de métodos simples para métodos mais complicados na tarefa de desenvolver um bot de bate-papo, analisaremos questões práticas de implementação e veremos qual ganho de qualidade pode ser obtido e quanto custará.
Vladislav Blinov é desenvolvedor sênior de sistemas de diálogo em
Tinkoff , geralmente lança abreviações: ML, PNL, DL, etc. Além disso, a escola de pós-graduação examina a modelagem do humor por meio de aprendizado de máquina e redes neurais.
Valeria Baranova escreve coisas legais no campo da PNL em Python há mais de 5 anos. Agora, na equipe de sistemas interativos, Tinkoff faz bots de bate-papo e ministra um curso de Machine Learning para os alunos. Ele também está envolvido em pesquisas no campo do humor computacional, ou seja, ele ensina a IA a entender piadas e a criar novas - Valeria e Vladislav
falarão sobre isso na UseData Conf.
Os serviços do Tinkoff Bank são utilizados por milhões de pessoas. Para fornecer suporte 24 horas para um número tão grande de usuários, é necessária uma grande equipe, o que leva a um alto custo de serviço. Parece lógico que as perguntas populares dos usuários possam ser respondidas automaticamente usando o bot de bate-papo.
Intenção ou intenção do usuário
A primeira coisa que um chatbot precisa é entender o
que o usuário deseja . Essa tarefa é chamada de classificação de intenções ou intenções. Além disso, todos os modelos e abordagens serão considerados na estrutura desta tarefa.
Vejamos um exemplo de classificação de intenções. Se você escrever: “Transferir uma centena de Lera”, o bot de bate-papo Oleg entenderá que essa é a intenção de uma transferência de dinheiro, ou seja, a intenção do usuário de transferir dinheiro. Ou melhor, que Lera precisa transferir a quantidade de 100 rublos.
Iremos comparar métodos e testar a qualidade de seu trabalho em uma amostra de teste, que consiste em diálogos reais com os usuários. Nossa amostra contém mais de 30.000 exemplos marcados e 170 intenções, por exemplo: ir ao cinema, procurar restaurantes, abrir ou fechar um depósito, etc. Oleg também tem muito a sua opinião e pode apenas conversar com você.
Classificação do dicionário
A coisa mais simples que pode ser feita na tarefa de classificar intenções é
usar um dicionário . Por exemplo, se a palavra "traduzir" aparecer na frase de um usuário, considere que uma transferência de dinheiro deve ser feita.
Vejamos a qualidade de uma abordagem tão simples.
Se o classificador simplesmente definir a intenção do usuário como "transferência de dinheiro" pela palavra "traduzir", a qualidade já será bastante alta. Precisão - 88%, enquanto a integridade é baixa, igual a apenas 23%. Isso é compreensível: a palavra "traduzir" não descreve todas as possibilidades de dizer "transferir dinheiro para alguém".
No entanto, essa abordagem tem vantagens:
- Nenhuma amostragem rotulada é necessária (se você não estuda o modelo, a amostragem não é necessária).
- Você pode obter alta precisão se compilar bem os dicionários (mas isso levará tempo e recursos).
No entanto, é provável que a completude de uma solução seja baixa, pois todas as variações de qualquer classe são difíceis de descrever.
Considere um contra-exemplo. Se, além da intenção de transferência de dinheiro, "transferência" também pode incluir a segunda intenção - "transferência para o operador". Quando adicionamos uma nova intenção de tradução ao operador, obtemos resultados diferentes.
A precisão cai 18 pontos, enquanto, é claro, a integridade não cresce. Isso mostra que é necessária uma abordagem mais avançada.
Análise de texto
Antes de usar o aprendizado de máquina, você precisa entender como apresentar o texto como um vetor. Uma das abordagens mais fáceis é
usar um vetor tf-idf .
O vetor tf-idf leva em consideração a ocorrência de cada palavra na frase do usuário e leva em consideração a ocorrência total de palavras na coleção. Palavras frequentemente encontradas em textos diferentes têm menos peso nessa representação vetorial.
Vejamos a qualidade do modelo linear nas representações tf-idf (no nosso caso, regressão logística).
Como resultado,
a completude aumentou acentuadamente e a precisão permaneceu proporcional ao uso do dicionário, a medida f1 (a média harmônica ponderada entre precisão e completude) também aumentou. Ou seja, o próprio modelo já entende quais palavras são importantes para qual intenção - você não precisa inventar nada.
Visualização de dados
A visualização de dados ajuda a entender como as intenções parecem, o quão bem elas são agrupadas no espaço. Porém, como não podemos visualizar diretamente as representações tf-idf devido à grande dimensão, usaremos
o método de compressão de dimensão - t-SNE .
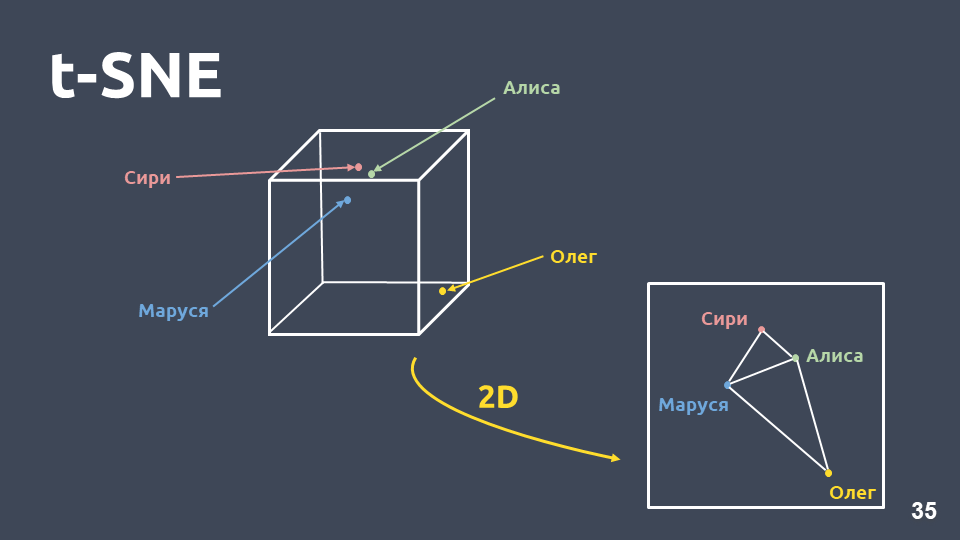
A principal diferença entre esse método e o PCA é que, quando transferida para o espaço bidimensional, a
distância relativa entre os objetos é preservada .
t-SNE no tf-idf (10 principais intenções), pontuação F1 0,92As 10 principais intenções por ocorrência em nossa coleção são apresentadas acima. Existem pontos verdes que não pertencem a nenhuma intenção e 10 clusters marcados com cores diferentes são intenções diferentes. Pode-se ver que alguns deles estão muito bem agrupados. A
medida f1 ponderada
é de 0,92 - isso é bastante, você já pode trabalhar com ela.
Portanto, com um classificador linear sobre tf-idf:
- completude muito maior do que usar um dicionário, com precisão comparável;
- não há necessidade de pensar quais palavras correspondem a qual intenção.
Mas também há desvantagens:
- vocabulário limitado, você pode obter peso apenas para as palavras presentes na amostra de treinamento;
- a reformulação não é levada em consideração;
- a ordem na qual as palavras ocorrem no texto não é levada em consideração.
Reformulação
Vamos considerar o problema de reformulação em mais detalhes.
Os vetores tf-idf podem ser próximos apenas para textos que se cruzam em palavras. A proximidade entre os vetores pode ser calculada através do cosseno do ângulo entre eles. A proximidade do cosseno na representação vetorial tf-idf é calculada para exemplos específicos.
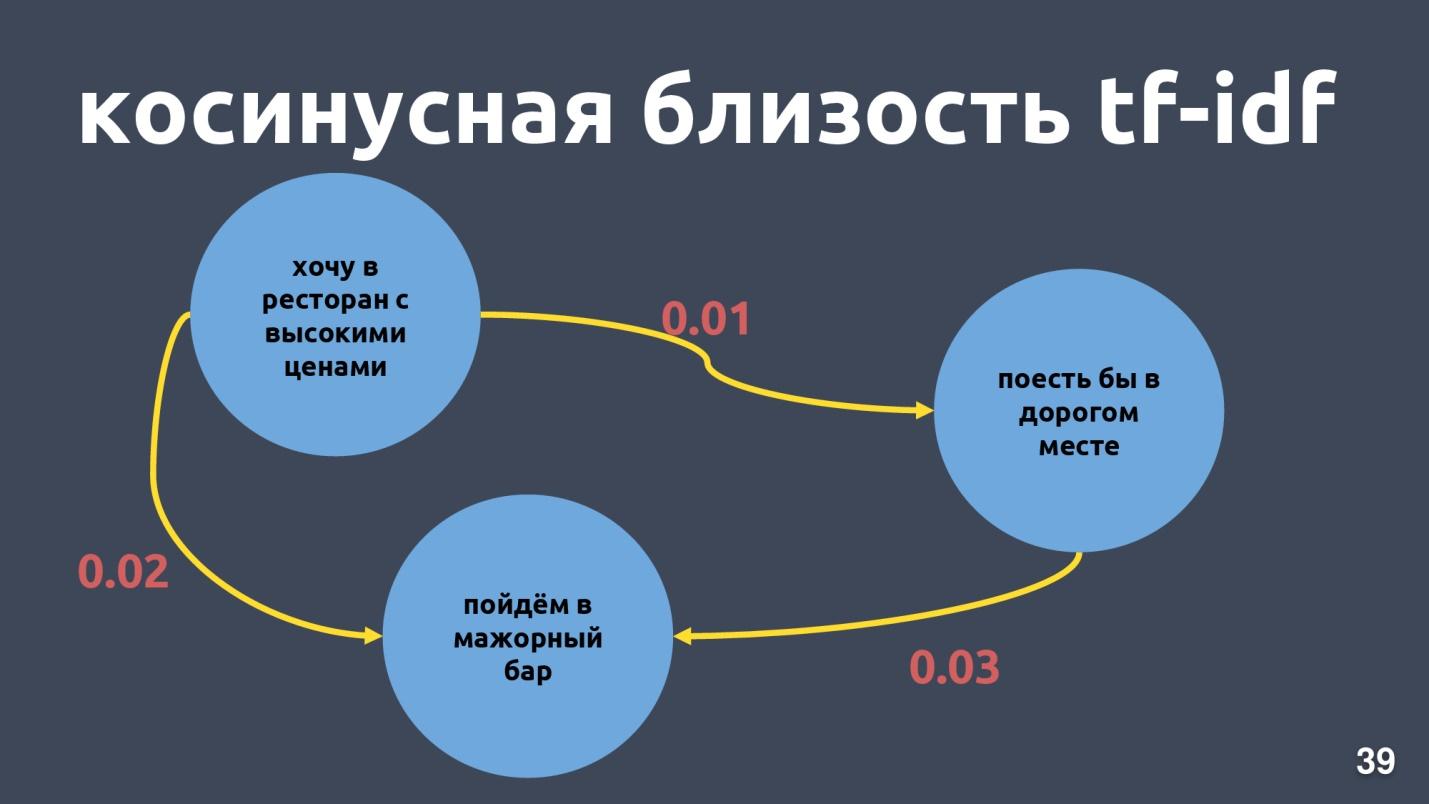
Essas não são frases muito próximas para a representação vetorial tf-idf, embora para nós seja a mesma intenção e a mesma classe.
O que pode ser feito sobre isso? Por exemplo, em vez de um número, você pode representar uma palavra como um vetor inteiro - isso é chamado de "incorporação de palavras".
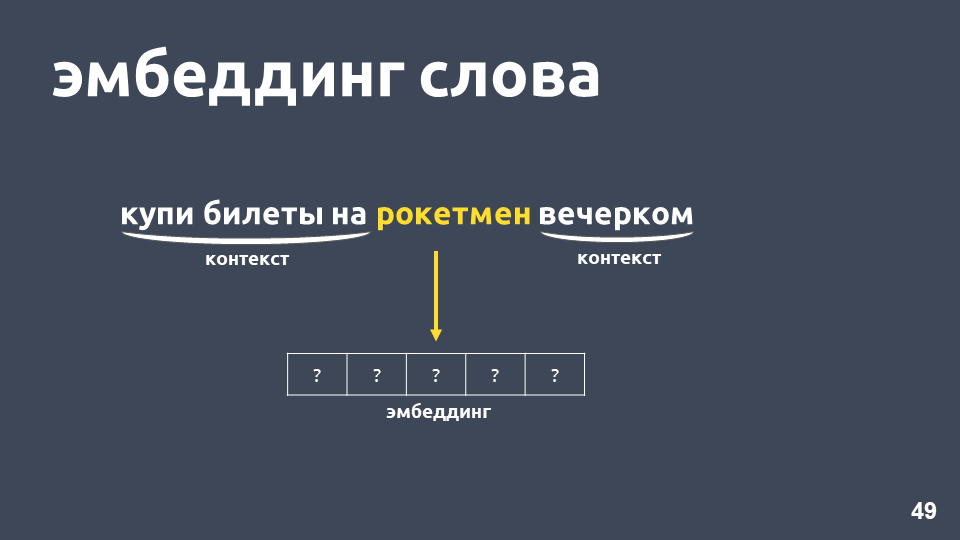
Um dos modelos mais populares para resolver esse problema foi proposto em 2013. É chamado
word2vec e tem sido amplamente utilizado desde então.
Uma das maneiras de aprender o Word2vec funciona aproximadamente da seguinte maneira: pegamos o texto, pegamos alguma palavra do contexto e a jogamos fora, depois pegamos outra palavra aleatória do contexto e apresentamos as duas palavras como vetores quentes. Um vetor quente é um vetor de acordo com a dimensão do dicionário, onde apenas a coordenada correspondente ao índice da palavra no dicionário tem o valor 1, o restante 0.
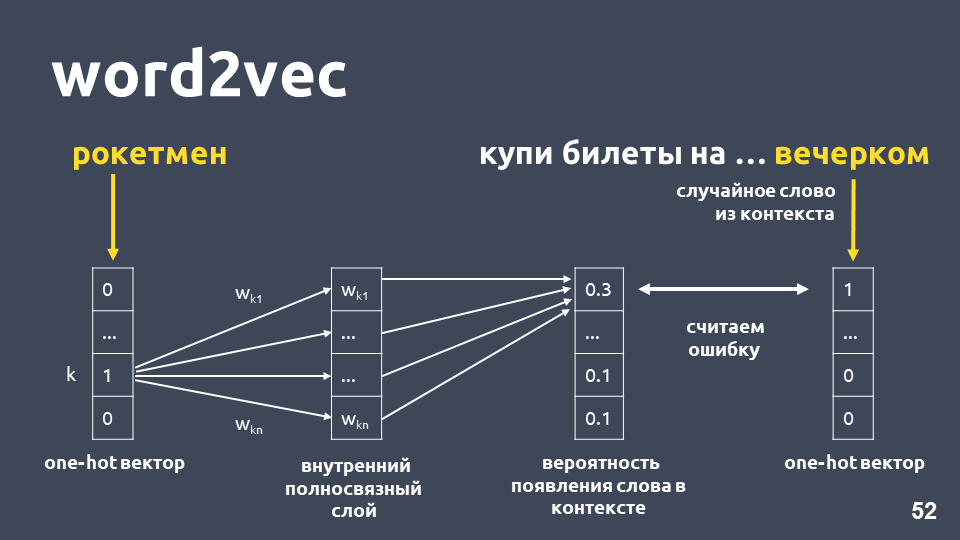
Em seguida, treinamos uma rede neural simples de camada única sem ativação na camada interna para prever a próxima palavra no contexto, ou seja, para prever a palavra "à noite" usando a palavra "homem-foguete". Na saída, obtemos a distribuição de probabilidade para todas as palavras do dicionário como segue. Como sabemos qual era realmente a palavra, podemos calcular o erro, atualizar os pesos etc.

Os pesos atualizados obtidos como resultado do treinamento em nossa amostra são a palavra incorporação.
A vantagem de usar incorporação em vez de número é, primeiro,
que o contexto é levado em consideração . Um exemplo popular: Trump e Putin estão próximos no word2vec porque ambos são presidentes e geralmente são usados juntos em textos.
Para as palavras encontradas na amostra de treinamento, basta pegar a matriz de incorporação, pegar seu vetor pelo índice da palavra e obter incorporação.
Parece que está tudo bem, exceto que algumas palavras em sua matriz podem não estar, porque o modelo não as viu durante o treinamento. Para lidar com o problema de palavras desconhecidas (fora do vocabulário), em 2014, eles apresentaram uma modificação do word2vec -
fasttext .
O texto rápido funciona da seguinte maneira: se a palavra não estiver no dicionário, ela será dividida em n-gramas simbólicos, pois cada incorporação de n-grama é obtida da matriz de incorporações de n-gramas (que são treinadas como word2vec), as médias são incorporadas e um vetor é obtido.
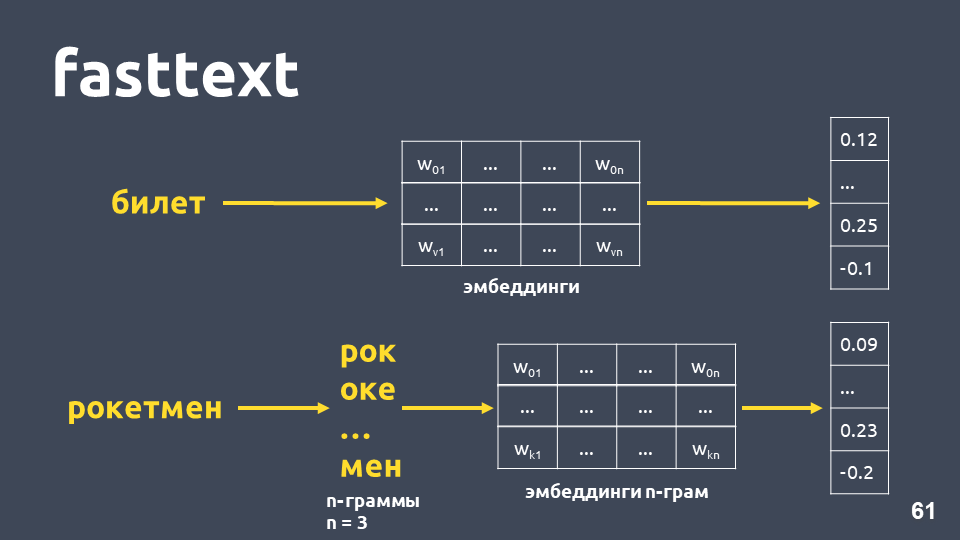
No total, obtemos vetores para palavras que não estão no nosso dicionário. Agora podemos
calcular a semelhança mesmo para palavras desconhecidas . E, o que é mais importante, existem modelos treinados para russo, inglês e chinês, por exemplo, o Facebook e o projeto
DeepPavlov , para que você possa incluí-lo rapidamente em seu pipeline.
Mas as desvantagens permanecem:- O modelo não é usado para todo o vetor de texto. Para obter um vetor de texto comum, é necessário pensar em algo: média ou média com multiplicação por pesos idf, e em tarefas diferentes isso pode funcionar de maneiras diferentes.
- O vetor para uma palavra ainda é um, independentemente do contexto. O Word2vec treina um vetor de palavra para qualquer contexto em que a palavra ocorre. Para palavras com vários valores (como, por exemplo, idioma), haverá um mesmo vetor.
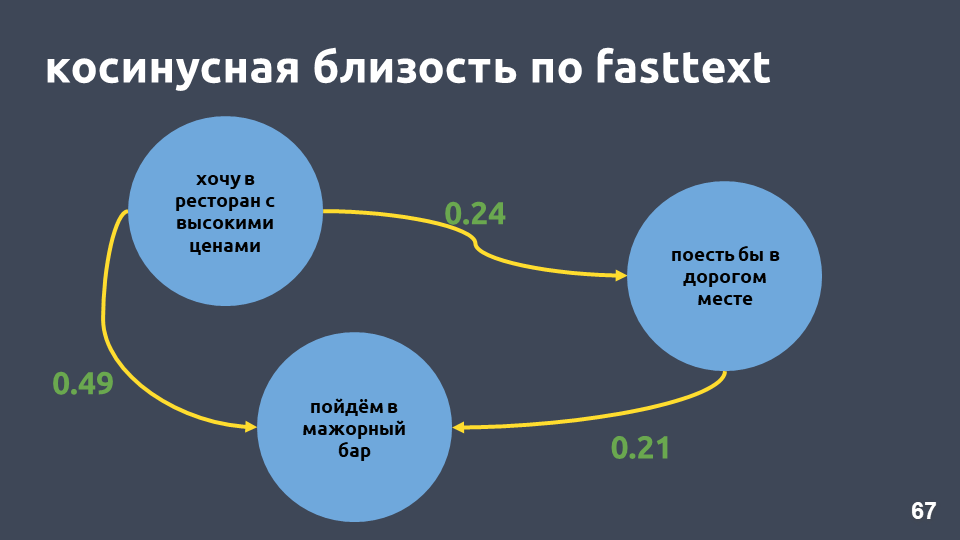
De fato, a proximidade do cosseno em nosso exemplo em texto rápido é maior que a proximidade do cosseno em tf-idf, mesmo que essas frases tenham apenas "em" em comum.
t-SNE em texto rápido (10 principais intenções), pontuação F1: 0,86No entanto, ao visualizar resultados de texto rápido na decomposição de t-SNE, os clusters de intenção se destacam muito piores do que para tf-idf. A medida F1 aqui é 0,86 em vez de 0,92.
Realizamos um experimento: combinados vetores tf-idf e fasttext. A qualidade é absolutamente a mesma que quando se usa apenas tf-idf. Isso não é verdade para todas as tarefas, há problemas em que o tf-idf e o fasttext combinados funcionam melhor do que apenas o tf-idf, ou onde o fasttext funciona melhor que o tf-idf. Você precisa experimentar e tentar.
Vamos tentar aumentar o número de intenções (lembre-se de que temos 170). Abaixo estão os clusters para as 30 principais intenções nos vetores tf-idf.
t-SNE em tf-idf (30 principais intenções), pontuação F1 0, 85 (em 10 era 0,92)A qualidade cai em 7 pontos e agora não vemos uma estrutura de cluster pronunciada.
Vejamos exemplos de textos que começaram a ficar confusos, porque foram adicionadas mais intenções que se cruzam semanticamente e em palavras.
Por exemplo: "E se você abrir um depósito, quais são os juros sobre ele?" e "E eu quero abrir uma contribuição em 7%". Frases muito semelhantes, mas essas são intenções diferentes. No primeiro caso, uma pessoa deseja conhecer as condições dos depósitos e, no segundo caso, para abrir um depósito. Para separar esses textos em diferentes classes, precisamos de algo mais complexo -
aprendizado profundo .
Modelo de linguagem
Queremos obter um vetor de texto e, em particular, um vetor de uma palavra, que dependerá do contexto de uso. A maneira padrão de obter esse vetor é
usar incorporações do modelo de linguagem .
O modelo de linguagem resolve o problema de modelagem de linguagem. E qual é essa tarefa? Que haja uma sequência de palavras, por exemplo: “Eu só falarei na presença de minha própria ...”, e estamos tentando prever a próxima palavra na sequência. O modelo de linguagem fornece contexto para incorporação. Tendo obtido incorporações e vetores contextuais para cada palavra, é possível prever a probabilidade da próxima palavra.
Há um vetor de dimensão de dicionário e cada palavra recebe a probabilidade de ser a próxima. Mais uma vez sabemos o que era realmente a palavra, consideramos um erro e treinamos o modelo.
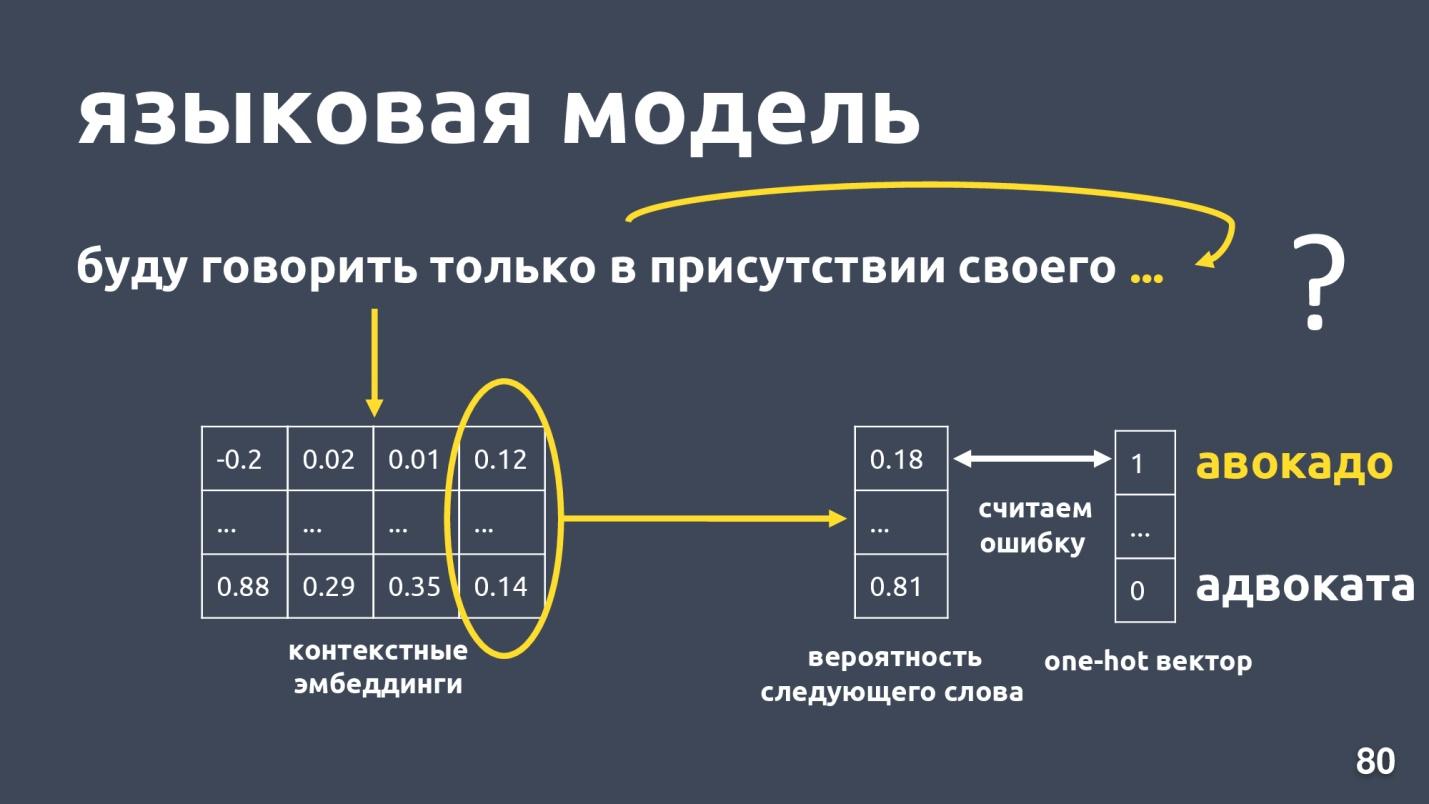
Existem alguns modelos de linguagem, houve um boom no ano passado? e muitas arquiteturas diferentes foram propostas. Um deles é o
ELMo .
ELMo
A idéia do modelo ELMo é criar primeiro uma palavra simbólica incorporada para cada palavra no texto e, em seguida, aplicar uma
rede LSTM para elas, de modo que sejam incorporados os incorporamentos que levem em conta o contexto em que a palavra ocorre.
Vamos examinar como a incorporação simbólica é obtida: dividimos a palavra em símbolos, aplicamos uma camada de incorporação para cada símbolo e obtemos uma matriz de incorporação. Quando se trata apenas de símbolos, a dimensão dessa matriz é pequena. Em seguida, convolução unidimensional é aplicada à matriz de incorporação, como geralmente é feita na PNL, com o agrupamento máximo no final, um vetor é obtido. Uma
rede de rodovias de duas camadas é aplicada a esse vetor, que calcula o
vetor geral de uma palavra .
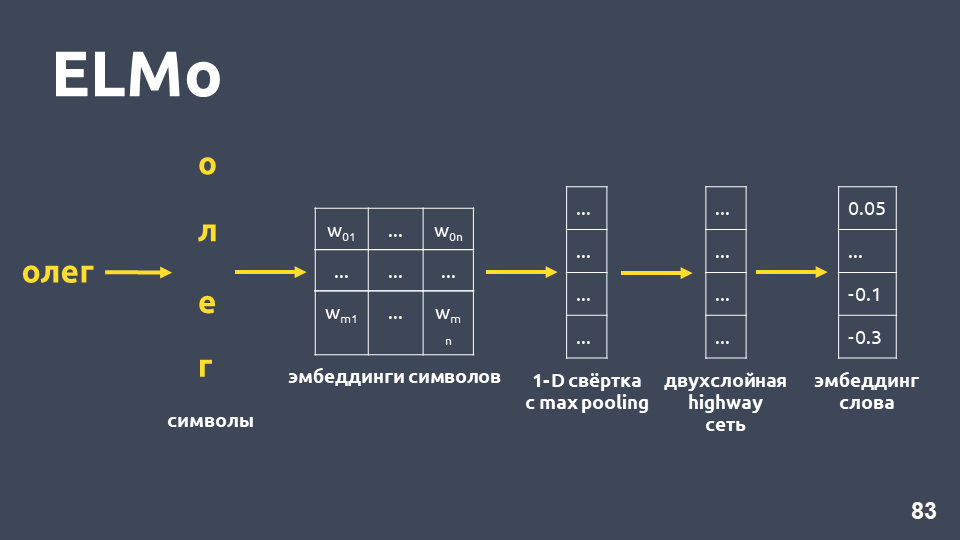
Além disso, o modelo criará algum tipo de hipótese de incorporação, mesmo para uma palavra que não foi encontrada no conjunto de treinamento.
Depois de recebermos combinações simbólicas para cada palavra, aplicamos uma rede BiLSTM de duas camadas a elas.
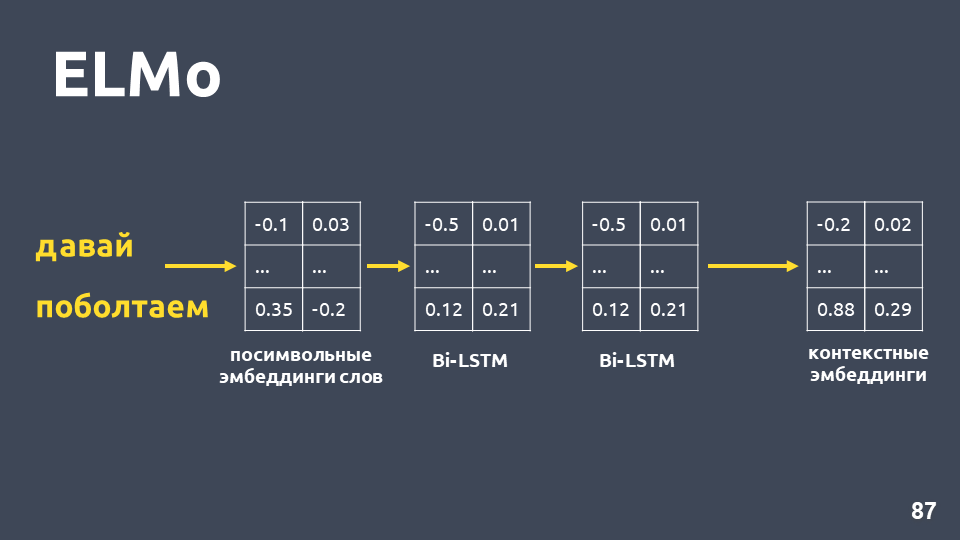
Depois de aplicar uma rede BiLSTM de duas camadas, geralmente os estados ocultos da última camada são normalmente obtidos, e acredita-se que isso seja incorporação contextual. Mas o ELMo tem dois recursos:
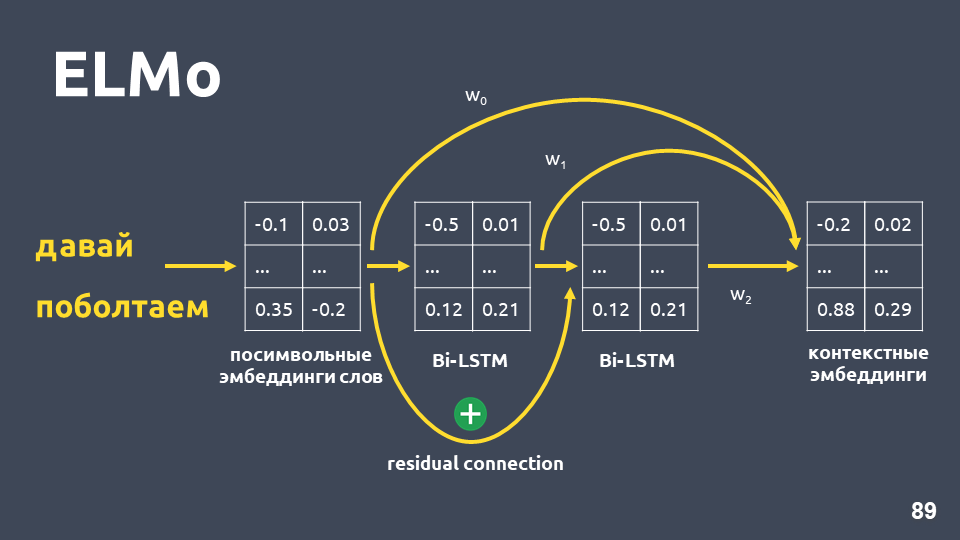
- Conexão residual entre a entrada da primeira camada LSTM e sua saída. A entrada LSTM é adicionada à saída para evitar o problema de gradientes desbotados.
- Os autores do ELMo propõem a combinação de incorporação simbólica para cada palavra, a saída da primeira camada LSTM e a saída da segunda camada LSTM com alguns pesos selecionados para cada tarefa. Isso é necessário para levar em consideração os recursos de baixo nível e os de nível superior que fornecem a primeira e a segunda camadas do LSTM.
Em nosso problema, usamos uma média simples dessas três incorporações e, assim, obtivemos incorporação contextual para cada palavra.
O modelo de linguagem fornece os seguintes benefícios:
- O vetor de uma palavra depende do contexto em que a palavra é usada. Isto é, por exemplo, para a palavra "linguagem" no significado da parte do corpo e do termo linguístico, obtemos vetores diferentes.
- Como no caso do word2vec e fasttext, existem muitos modelos treinados, por exemplo, do projeto DeepPavlov . Você pode pegar o modelo final e tentar aplicar em sua tarefa.
- Você não precisa mais pensar em como calcular a média dos vetores de palavras. O modelo ELMo produz imediatamente um vetor de todo o texto.
- Você pode treinar novamente o modelo de idioma para sua tarefa; existem várias maneiras para isso, por exemplo, ULMFiT.
O único sinal de menos permanece - o
modelo de linguagem não garante que os textos que pertencem à mesma classe, ou seja, com uma intenção, estejam próximos no espaço vetorial.
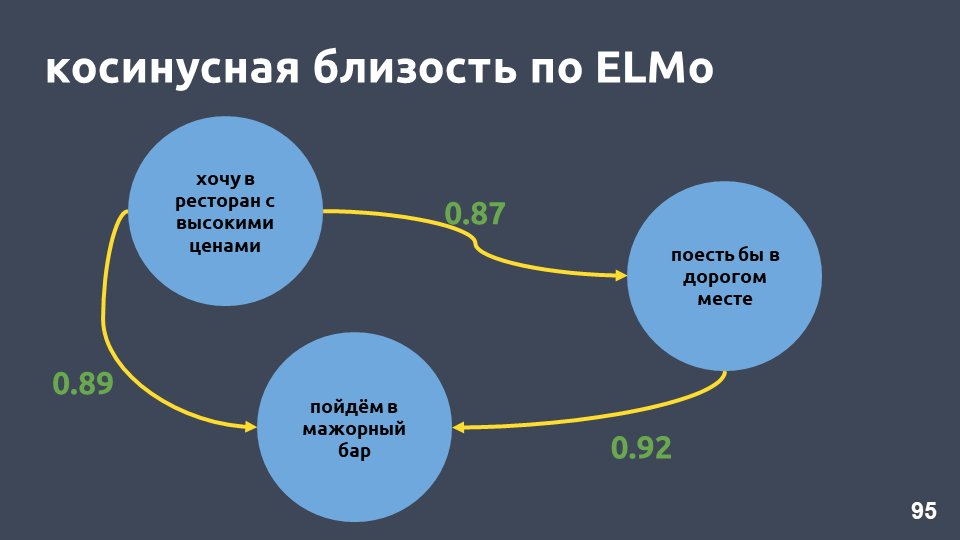
No nosso exemplo de restaurante, os valores de cosseno de acordo com o modelo ELMo realmente se tornaram mais altos.
t-SNE no ELMo (10 principais intenções), pontuação de F1 0,93 (0,92 por tf-idf)Clusters com as 10 principais intenções também são mais pronunciados. Na figura acima, todos os 10 clusters são claramente visíveis, enquanto a precisão aumentou um pouco.
t-SNE no ELMo (30 principais intenções) F1 score 0.86 (0.85 by tf-idf)Para as 30 principais intenções, a estrutura do cluster ainda é preservada e também há um aumento na qualidade em um ponto.
Mas, nesse modelo, não há garantia de que as propostas "E se você abrir um depósito, quais são os juros sobre elas?" e "E eu quero abrir uma contribuição a 7%" estará longe um do outro, embora eles se encontrem em classes diferentes. Com o ELMo, simplesmente aprendemos o modelo de linguagem e, se os textos semanticamente semelhantes, eles estarão próximos.
O ELMo não sabe nada sobre nossas classes , mas você pode reunir vetores de texto com a mesma intenção no espaço usando rótulos de classe.
Rede siamesa
Leve sua arquitetura de rede neural favorita para vetorização de texto e dois exemplos de intenções. Para cada um dos exemplos, recebemos casamentos e depois calculamos a distância do cosseno entre eles.
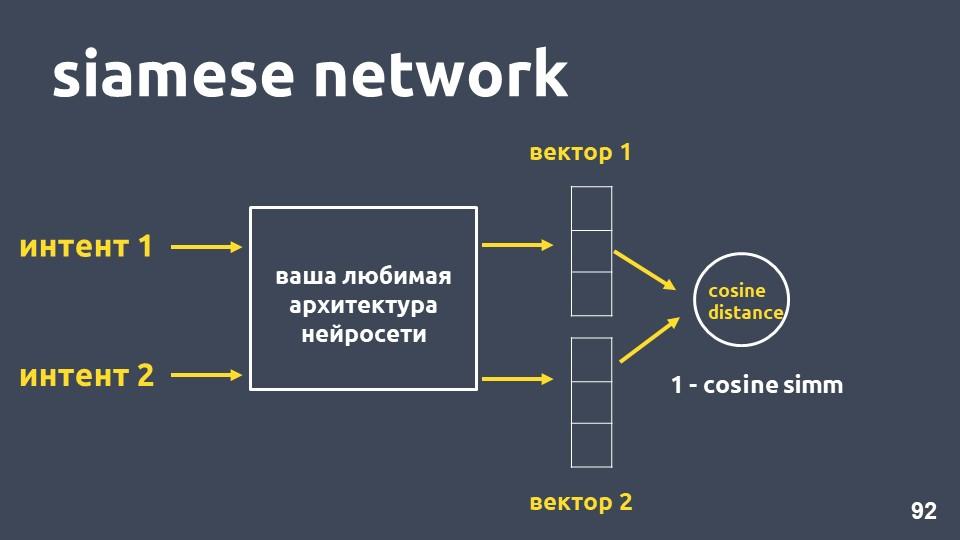
A distância do cosseno é igual a um menos a proximidade do cosseno que encontramos anteriormente.
Essa abordagem é chamada de
rede siamesa .
Queremos textos da mesma classe, por exemplo, "faça uma transferência" e "jogue dinheiro", próximos do espaço. Ou seja, a distância do cosseno entre seus vetores deve ser a menor possível, idealmente zero. E textos relacionados a diferentes intenções devem estar o mais afastados possível.
Mas, na prática, esse método de treinamento não funciona tão bem, porque objetos de classes diferentes não ficam suficientemente distantes um do outro. A função de perda chamada
"perda de trigêmeos" funciona muito melhor. Ele usa triplos objetos chamados trigêmeos.
A ilustração mostra um trio: um objeto âncora em um círculo azul, um objeto positivo em verde e um objeto negativo em um círculo vermelho. O objeto negativo e a âncora estão em classes diferentes, e o positivo e a âncora estão em uma.

Queremos garantir que, após o treinamento, o objeto positivo esteja mais próximo da âncora do que o negativo. Para isso, consideramos a distância do cosseno entre os pares de objetos e inserimos o hiperparâmetro - "margem" - a distância que esperamos estar entre os objetos positivos e negativos.

A função de perda é assim:
Em outras palavras, durante o treinamento, conseguimos que o objeto positivo esteja mais próximo da âncora do que o negativo, pelo menos margem. Se a função de perda for zero, ela funcionará e terminaremos o treinamento, caso contrário, continuamos a minimizar a função objetivo.
Depois de treinarmos o modelo, ainda não obtivemos um classificador, é apenas um método para obter esses embeddings que objetos que estão em uma intenção provavelmente têm vetores próximos.
Quando obtivemos o modelo, podemos usar um método de classificação diferente sobre os casamentos.
O KNN é um bom ajuste, pois já conseguimos que os embeddings tenham uma estrutura de cluster distinta.
Lembre-se de como o kNN funciona para textos: pegue um elemento do texto, incorpore-o, traduza-o em espaço vetorial e veja quem é seu vizinho. Entre os vizinhos, consideramos a classe mais frequente e concluímos que o novo objeto pertence a essa classe.
A dimensão dos casamentos que usamos é 300 e, na amostra de treinamento, existem cerca de 500.000 objetos. Os métodos padrão para encontrar os vizinhos mais próximos não nos servem em termos de desempenho. Utilizamos o método
HNSW -
Mundo Pequeno Navegável Hierárquico .
Navegável Small World é um gráfico conectado no qual existem poucas arestas entre vértices que estão a uma grande distância e muitas arestas entre vértices próximos. No nosso caso, o comprimento da aresta será determinado pela distância do cosseno, ou seja, , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
Sumário
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .