Recentemente, fabricantes de FPGA e empresas terceirizadas têm desenvolvido ativamente métodos de desenvolvimento para FPGAs que diferem das abordagens convencionais usando ferramentas de desenvolvimento de alto nível.
Como desenvolvedor de FPGA, utilizo a linguagem de descrição de hardware (
HDL ) da Verilog como ferramenta principal, mas a crescente popularidade de novos métodos despertou meu grande interesse. Portanto, neste artigo, decidi entender o que estava acontecendo.
Este artigo não é um guia ou instrução de uso, esta é minha revisão e conclusões sobre o que várias ferramentas de desenvolvimento de alto nível podem oferecer a um desenvolvedor ou programador de FPGA que deseja mergulhar no mundo do FPGA. Para comparar as ferramentas de desenvolvimento mais interessantes na minha opinião, escrevi vários testes e analisei os resultados. Sob o corte - o que veio disso.
Por que você precisa de ferramentas de desenvolvimento de alto nível para FPGA?
- Acelerar o desenvolvimento do projeto
- devido à reutilização de código já escrito em linguagens de alto nível;
- através do uso de todas as vantagens de linguagens de alto nível, ao escrever código do zero;
- reduzindo o tempo de compilação e a verificação do código.
- Capacidade de criar código universal que funcione em qualquer família FPGA.
- Reduza o limite de desenvolvimento para FPGAs, por exemplo, evitando os conceitos de "velocidade do relógio" e outras entidades de baixo nível. Capacidade de escrever código para FPGA para um desenvolvedor que não esteja familiarizado com HDL.
De onde vêm as ferramentas de desenvolvimento de alto nível?
Agora muitos são atraídos pela idéia de desenvolvimento de alto nível. Tanto entusiastas como, por exemplo,
Quokka e
o gerador de código Python , quanto empresas como
Mathworks e fabricantes de FPGA
Intel e
Xilinx estão envolvidos nisso.
Todo mundo usa seus métodos e ferramentas para alcançar seu objetivo. Os entusiastas na luta por um mundo perfeito e bonito usam suas linguagens de desenvolvimento favoritas, como Python ou C #. As empresas, tentando agradar o cliente, oferecem suas próprias ou adaptam as ferramentas existentes. O Mathworks oferece sua própria ferramenta de codificador HDL para gerar código HDL a partir de m-scripts e modelos Simulink, enquanto a Intel e o Xilinx oferecem compiladores para o C / C ++ comum.
No momento, empresas com recursos financeiros e humanos significativos obtiveram maior sucesso, enquanto os entusiastas estão um pouco atrasados. Este artigo será dedicado à consideração do codificador HDL do produto da Mathworks e HLS Compiler da Intel.
E o XilinxNeste artigo, não considero o HIL do Xilinx, devido às diferentes arquiteturas e sistemas CAD da Intel e do Xilinx, o que torna impossível fazer uma comparação inequívoca dos resultados. Mas quero observar que o Xilinx HLS, como o Intel HLS, fornece um compilador C / C ++ e eles são conceitualmente semelhantes.
Vamos começar a comparar o codificador HDL do Mathworks e do Intel HLS Compiler, tendo resolvido vários problemas usando abordagens diferentes.
Comparação de ferramentas de desenvolvimento de alto nível
Teste um. "Dois multiplicadores e um somador"
A solução para esse problema não tem valor prático, mas é adequada como primeiro teste. A função pega 4 parâmetros, multiplica o primeiro pelo segundo, o terceiro pelo quarto e adiciona os resultados da multiplicação. Nada complicado, mas vamos ver como nossos assuntos lidam com isso.
Codificador HDL da Mathworks
Para resolver esse problema, o script m é o seguinte:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
Vamos ver o que o Mathworks nos oferece para converter o código em HDL.
Não considerarei o trabalho com o codificador HDL em detalhes, vou me concentrar apenas nas configurações que alterarei no futuro para obter resultados diferentes no FPGA, e cujas alterações deverão ser consideradas pelo programador do MATLAB que precisa executar seu código no FPGA.
Portanto, a primeira coisa a fazer é definir o tipo e o intervalo dos valores de entrada. Não há char familiar, int, float, duplo no FPGA. A profundidade de bits do número pode ser qualquer uma, é lógico escolhê-lo, com base no intervalo de valores de entrada que você planeja usar.
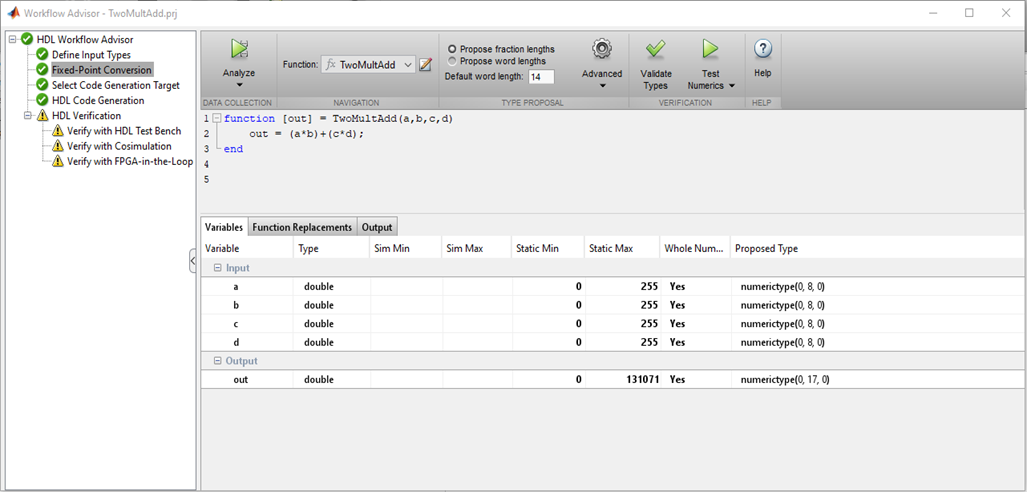 Figura 1
Figura 1O MATLAB verifica os tipos de variáveis, seus valores e seleciona os tamanhos de bits corretos para barramentos e registradores, o que é realmente conveniente. Se não houver problemas com a profundidade de bits e a digitação, prossiga para os seguintes pontos.
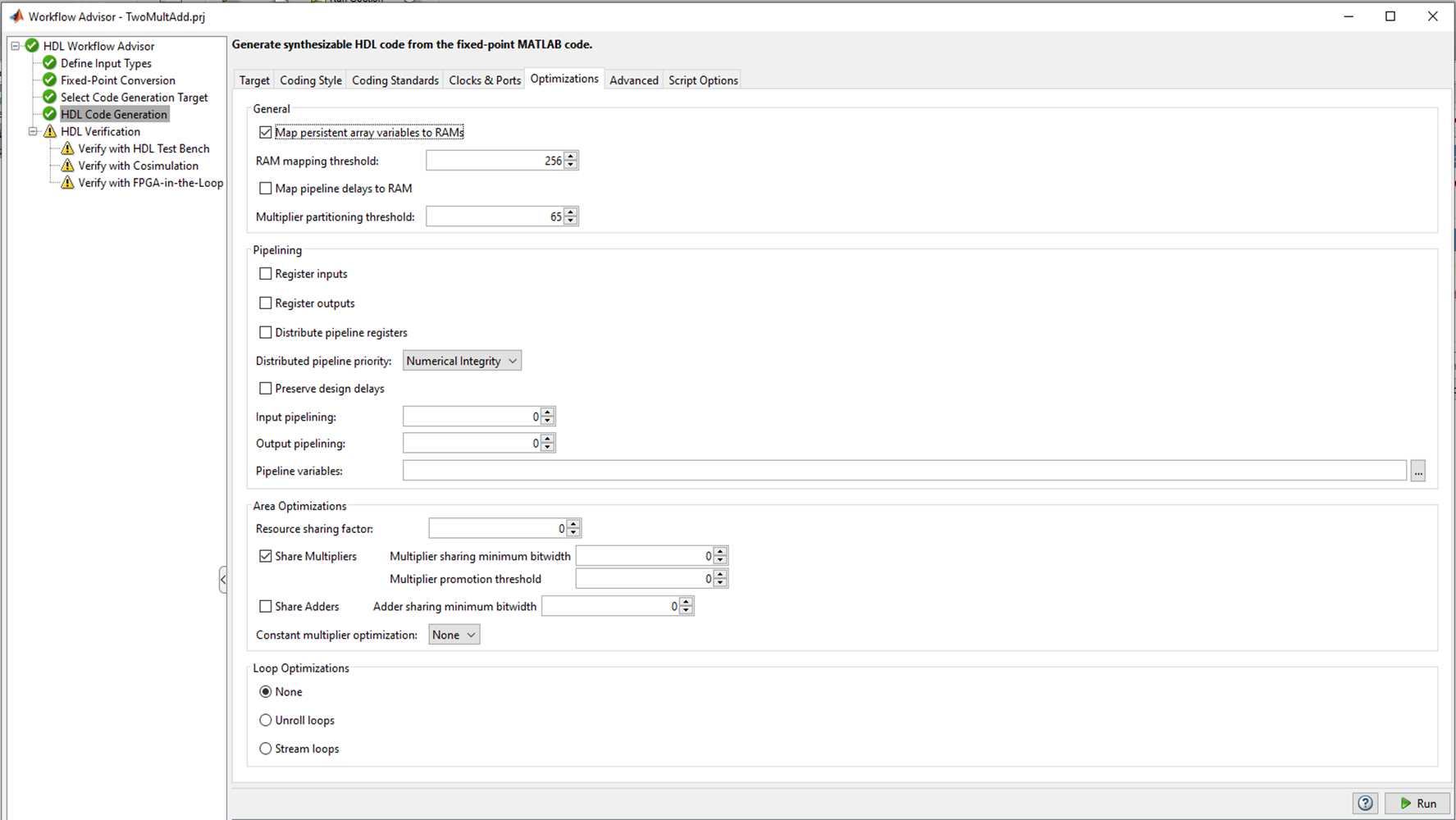 Figura 2
Figura 2Existem várias guias na geração de código HDL, nas quais você pode escolher o idioma para o qual converter (Verilog ou VHDL); estilo de código nomes de sinais. A guia mais interessante, na minha opinião, é a Otimização, e eu vou experimentar, mas mais tarde, por enquanto, vamos deixar todos os padrões e ver o que acontece com o codificador HDL "fora da caixa".
Pressione o botão Executar e obtenha o seguinte código:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
O código parece bom. O MATLAB entende que escrever a expressão inteira em uma única linha no Verilog é uma prática ruim. Cria
fios separados para o multiplicador e o somador, não há do que reclamar.
É alarmante que a descrição dos registros esteja ausente. Isso aconteceu porque não perguntamos sobre o HDL-coder e deixamos todos os campos nas configurações com seus valores padrão.
Aqui está o que Quartus sintetiza a partir desse código.
 Figura 3
Figura 3Sem problemas, tudo foi como planejado.
No FPGA, implementamos circuitos síncronos, e ainda gostaria de ver os registros. O codificador HDL oferece um mecanismo para a colocação de registros, mas a localização dos mesmos depende do desenvolvedor. Podemos colocar os registradores na entrada dos multiplicadores, na saída dos multiplicadores na frente do somador ou na saída do somador.
Para sintetizar os exemplos, escolhi a família FPGA Cyclone V, onde blocos DSP especiais com somadores e multiplicadores embutidos são usados para implementar operações aritméticas. O bloco DSP fica assim:
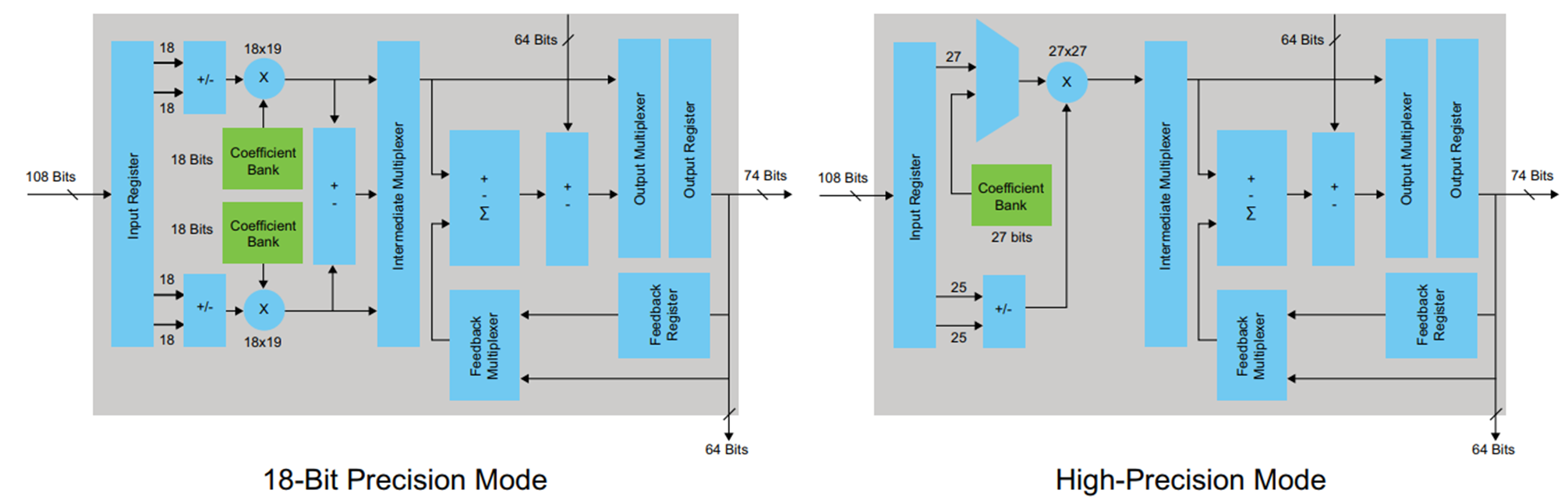 Figura 4
Figura 4O bloco DSP possui registros de entrada e saída. Não há necessidade de tentar tirar os resultados da multiplicação no registro antes da adição, isso violará apenas a arquitetura (em certos casos, essa opção é possível e até necessária). Cabe ao desenvolvedor decidir como lidar com o registro de entrada e saída com base nos requisitos de latência e na frequência máxima necessária. Eu decidi usar apenas o registro de saída. Para que esse registro seja descrito no código gerado pelo codificador HDL, na guia Opções do codificador HDL, marque a caixa de seleção Registrar saída e reinicie a conversão.
Acontece o seguinte código:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
Como você pode ver, o código tem diferenças fundamentais em comparação com a versão anterior. Um bloco sempre apareceu, que é uma descrição do registro (exatamente o que queríamos). Para a operação sempre em bloco, também apareceram as entradas do módulo clk (frequência do relógio) e reset (reset). Pode-se ver que a saída do somador está travada no gatilho descrito em sempre. Há também alguns sinais de permissão ena, mas eles não são muito interessantes para nós.
Vejamos o diagrama que o Quartus agora sintetiza.
 Figura 5
Figura 5E, novamente, os resultados são bons e esperados.
A tabela abaixo mostra a tabela de recursos usados - nós mantemos isso em mente.
 Figura 6
Figura 6Para esta primeira missão, o Mathworks recebe um crédito. Tudo não é complicado, previsível e com o resultado desejado.
Descrevi em detalhes um exemplo simples, forneci um diagrama de um bloco DSP e descrevi as possibilidades de usar as configurações de uso de registro no codificador HDL, que são diferentes das configurações "padrão". Isso é feito por uma razão. Com isso, gostaria de enfatizar que, mesmo em um exemplo tão simples, ao usar o codificador HDL, é necessário o conhecimento da arquitetura FPGA e dos fundamentos dos circuitos digitais, e as configurações devem ser alteradas conscientemente.
Compilador Intel HLS
Vamos tentar compilar código com a mesma funcionalidade escrita em C ++ e ver o que é finalmente sintetizado no FPGA usando o compilador HLS.
Código C ++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
Eu escolhi tipos de dados para evitar o transbordamento de variáveis.
Existem métodos avançados para definir a profundidade de bits, mas nosso objetivo é testar a capacidade de montar funções escritas no estilo C / C ++ no FPGA sem fazer nenhuma alteração, tudo pronto para uso.
Como o compilador HLS é uma ferramenta nativa da Intel, coletamos o código com um compilador especial e verificamos o resultado imediatamente no Quartus.
Vejamos o circuito que Quartus sintetiza.
 Figura 7
Figura 7O compilador criado registra na entrada e na saída, mas a essência está oculta no módulo wrapper. Começamos a implantar o wrapper e ... ver mais, mais e mais módulos aninhados.
A estrutura do projeto é assim.
 Figura 8
Figura 8Uma dica óbvia da Intel é "não coloque as mãos nela!". Mas vamos tentar, especialmente a funcionalidade não é complicada.
Nas entranhas da árvore do projeto | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 é o módulo que você está procurando.
Podemos observar o diagrama do módulo desejado sintetizado pelo Quartus.
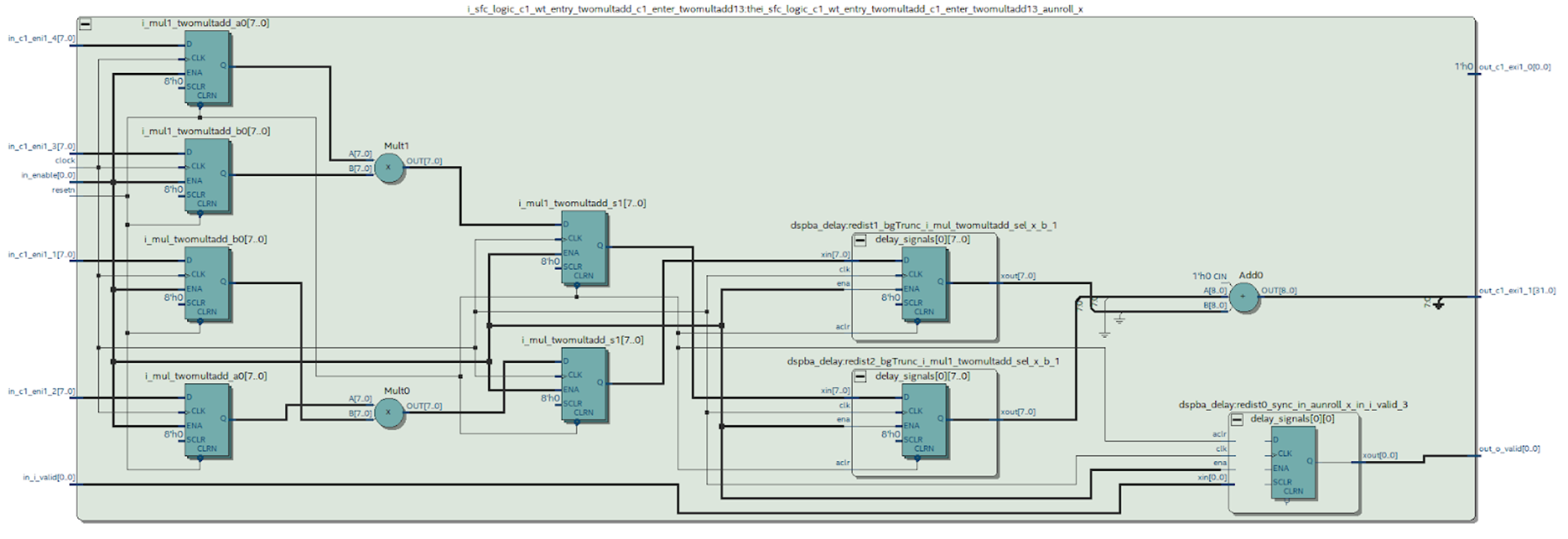 Figura 9
Figura 9Que conclusões podem ser tiradas desse esquema.
É evidente que algo aconteceu que tentamos evitar ao trabalhar no MATLAB: o caso na saída do multiplicador foi sintetizado - isso não é muito bom. Pode ser visto no diagrama de blocos DSP (Figura 4) que existe apenas um registro em sua saída, o que significa que cada multiplicação deverá ser feita em um bloco separado.
A tabela de recursos usados mostra o que isso leva.
 Figura 10
Figura 10Compare os resultados com a tabela do codificador HDL (Figura 6).
Se você usar um número maior de registros, pode gastar muito preciosos blocos DSP em uma funcionalidade tão simples.
Mas há uma enorme vantagem no Intel HLS em comparação com o codificador HDL. Com as configurações padrão, o compilador HLS desenvolveu um design síncrono no FPGA, embora gastasse mais recursos. Essa arquitetura é possível, é claro que o Intel HLS está configurado para atingir o desempenho máximo e não para economizar recursos.
Vamos ver como nossos assuntos se comportam em projetos mais complexos.
O segundo teste. “Multiplicação de matrizes por elementos com soma dos resultados”
Esta função é amplamente utilizada no processamento de imagens: o chamado
"filtro de matriz" . Nós o vendemos usando ferramentas de alto nível.
Codificador HDL da Mathwork
O trabalho começa imediatamente com uma limitação. O codificador HDL não pode aceitar funções da matriz 2-D como entradas. Dado que o MATLAB é uma ferramenta para trabalhar com matrizes, esse é um duro golpe para todo o código herdado, que pode se tornar um problema sério. Se o código foi escrito do zero, esse é um recurso desagradável que deve ser considerado. Portanto, você deve implantar todas as matrizes em um vetor e implementar as funções levando em consideração os vetores de entrada.
O código para a função no MATLAB é o seguinte
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
O código HDL gerado acabou por estar muito inchado e contém centenas de linhas, portanto não o darei aqui. Vamos ver qual esquema o Quartus sintetiza a partir desse código.
 Figura 11
Figura 11Esse esquema parece malsucedido. Formalmente, está funcionando, mas presumo que funcione com uma frequência muito baixa e dificilmente pode ser usado em hardware real. Mas qualquer suposição deve ser verificada. Para fazer isso, colocaremos os registros na entrada e saída deste circuito e, com a ajuda do Timing Analyzer, avaliaremos a situação real. Para conduzir a análise, você deve especificar a frequência operacional desejada do circuito para que o Quartus saiba o que buscar ao fazer a fiação e, em caso de falha, fornecer relatórios de violações.
Definimos a frequência para 100 MHz, vamos ver o que o Quartus pode extrair do circuito proposto.
 Figura 12
Figura 12Pode-se ver que ficou um pouco: 33 MHz parecem frívolos. O atraso na cadeia de multiplicadores e somadores é de cerca de 30 ns. Para se livrar desse “gargalo”, é necessário usar o transportador: insira registradores após operações aritméticas, reduzindo assim o caminho crítico.
O codificador HDL nos dá essa oportunidade. Na guia Opções, você pode definir variáveis de Pipeline. Como o código em questão é escrito no estilo MATLAB, não há como pipeline variáveis (exceto variáveis mult e summ), o que não nos convém. É necessário inserir os registradores nos circuitos intermediários ocultos em nosso código HDL.
Além disso, a situação com otimização poderia ser pior. Por exemplo, nada nos impede de escrever código
out = (sum(target.*kernel))/len;
é bastante adequado para o MATLAB, mas nos priva completamente da possibilidade de otimizar o HDL.
A próxima saída é editar o código manualmente. Este é um ponto muito importante, pois nos recusamos a herdar e começar a reescrever o script m, e NÃO no estilo MATLAB.
O novo código é o seguinte
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
No Quartus, coletamos o código gerado pelo codificador HDL. Pode-se observar que o número de camadas com primitivas diminuiu e o esquema parece muito melhor.
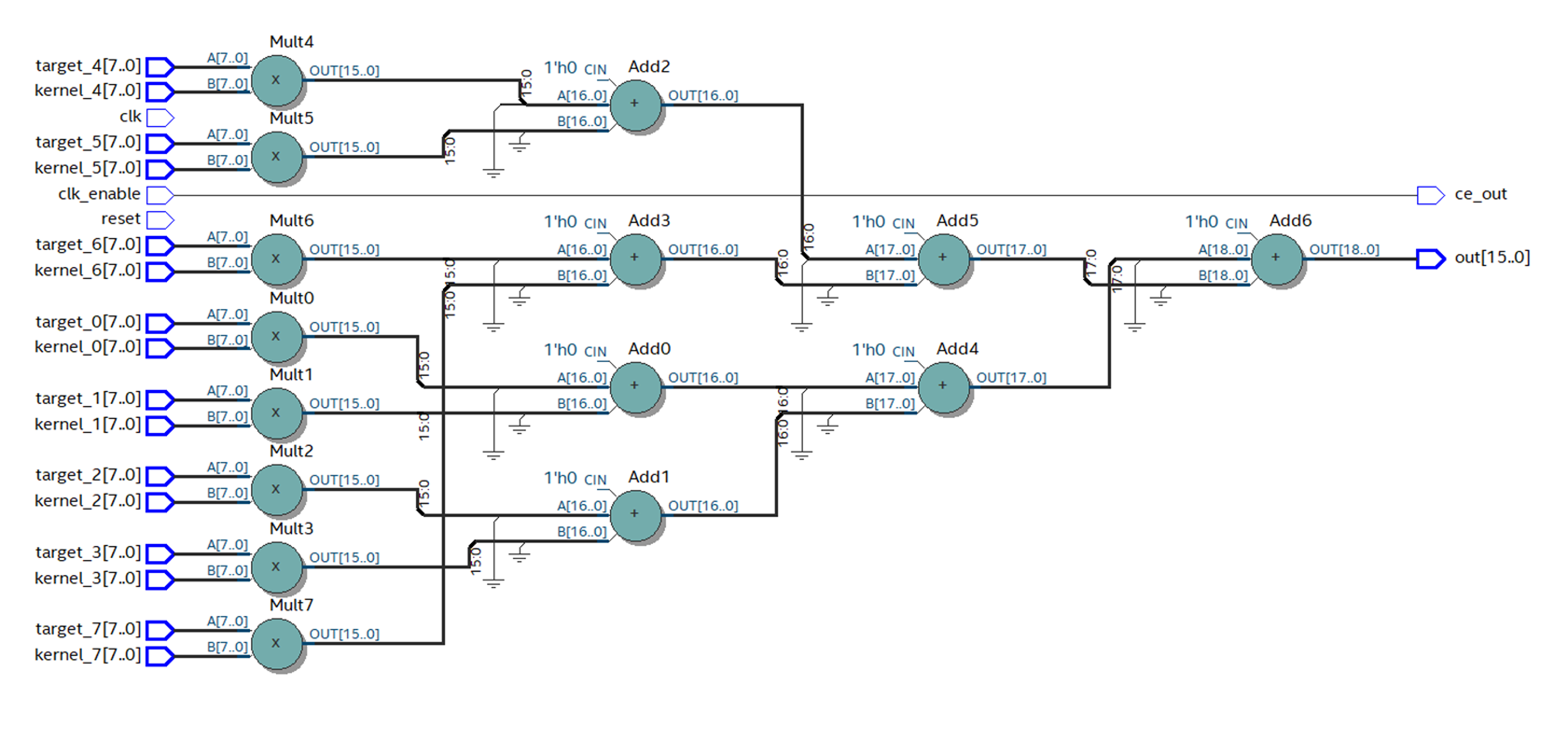 Figura 12
Figura 12Com o layout correto das primitivas, a frequência cresce quase 3 vezes, até 88 MHz.
 Figura 13
Figura 13Agora, o toque final: nas configurações de otimização, especifique summ_1, summ_2 e summ_3 como elementos do pipeline. Coletamos o código resultante no Quartus. O esquema muda da seguinte maneira:
 Figura 14
Figura 14A frequência máxima aumenta novamente e agora seu valor é de cerca de 195 MHz.
 Figura 15
Figura 15Quantos recursos no chip serão necessários para esse projeto? A Figura 16 mostra a tabela de recursos usados para o caso descrito.
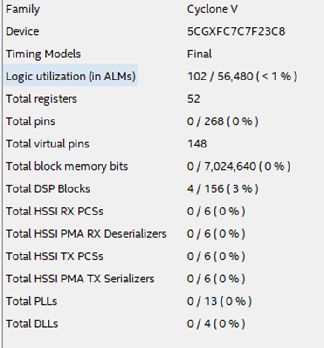 Figura 16
Figura 16Que conclusões podem ser tiradas depois de considerar este exemplo?
A principal desvantagem do codificador HDL é que é improvável que você use o código MATLAB em sua forma pura.
Não há suporte para matrizes como entradas de função, o layout do código no estilo MATLAB é medíocre.
O principal perigo é a falta de registros no código gerado sem configurações adicionais. Sem esses registros, mesmo tendo recebido código HDL formalmente funcionando sem erros de sintaxe, o uso desse código em realidades e desenvolvimentos modernos é indesejável.
É aconselhável escrever imediatamente um código afiado para conversão em HDL. Nesse caso, você pode obter resultados bastante aceitáveis em termos de velocidade e intensidade de recursos.
Se você é um desenvolvedor do MATLAB, não se apresse em clicar no botão Executar e compilar seu código em FPGA, lembre-se de que seu código será sintetizado em um circuito real. =)
Compilador Intel HLS
Para a mesma funcionalidade, escrevi o seguinte código C / C ++
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
A primeira coisa que chama sua atenção é a quantidade de recursos utilizados.
 Figura 17
Figura 17Pode ser visto na tabela que apenas 1 bloco DSP foi usado; portanto, algo deu errado e as multiplicações não são realizadas em paralelo. O número de registradores usados também é surpreendente, e até a memória está envolvida, mas deixaremos isso para a consciência do compilador HLS.
Vale a pena notar que o compilador HLS desenvolveu um subótimo, usando uma enorme quantidade de recursos extras, mas ainda um circuito de trabalho que, de acordo com os relatórios da Quartus, funcionará em uma frequência aceitável e uma falha que o codificador HDL não fará.
 Figura 18
Figura 18Vamos tentar melhorar a situação. O que é necessário para isso? É isso mesmo, feche os olhos para a herança e entre no código, mas até agora não é muito.
O HLS possui diretrizes especiais para otimizar o código do FPGA. Nós inserimos a diretiva unroll, que deve expandir nosso loop em paralelo:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
Vamos ver como o Quartus reagiu a ele
 Figura 19
Figura 19Antes de tudo, preste atenção ao número de blocos DSP - existem 16 deles, o que significa que as multiplicações são realizadas em paralelo.
Viva! desenrolar funciona! Mas já é difícil suportar o quanto a utilização de outros recursos aumentou. O circuito tornou-se completamente ilegível.
 Figura 20
Figura 20Acredito que isso se deve ao fato de ninguém apontar para o compilador que os cálculos em números de ponto fixo são bastante adequados para nós, e ele honestamente implementou toda a matemática de ponto flutuante na lógica e nos registros. Precisamos explicar ao compilador o que é necessário e, para isso, mergulhamos novamente no código.
Com o objetivo de usar ponto fixo, as classes de modelo são implementadas.
 Figura 21
Figura 21Falando com nossas próprias palavras, podemos usar variáveis cuja profundidade de bits é configurada manualmente até um pouco. Para aqueles que escrevem em HDL, você não pode se acostumar, mas os programadores de C / C ++ provavelmente irão se agarrar. Profundidades de bits, como no MATLAB, neste caso, ninguém dirá, e o próprio desenvolvedor deve contar o número de bits.
Vamos ver como fica na prática.
Editamos o código da seguinte maneira:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
E, em vez da massa assustadora da Figura 20, temos essa beleza:
 Figura 22
Figura 22Infelizmente, algo estranho continua a acontecer com os recursos utilizados.
 Figura 23
Figura 23Mas uma análise detalhada dos relatórios mostra que o módulo que nos interessa diretamente parece mais do que adequado:
 Figura 24
Figura 24O enorme consumo de registros e memória de bloco está associado a um grande número de módulos periféricos. Ainda não compreendo completamente o profundo significado de sua existência, e isso precisará ser resolvido, mas o problema está resolvido. Em um caso extremo, você pode cortar cuidadosamente um módulo de interesse da estrutura geral do projeto, o que nos salvará dos módulos periféricos que consomem recursos.
O terceiro teste. "Transição de RGB para HSV"
Começando a escrever este artigo, não esperava que fosse tão volumoso. Mas não posso recusar o terceiro e o último na estrutura deste artigo, um exemplo.
Primeiro, este é um exemplo real da minha prática e foi por isso que comecei a procurar ferramentas de desenvolvimento de alto nível.
Em segundo lugar, a partir dos dois primeiros exemplos, poderíamos assumir que, quanto mais complexo o design, piores as ferramentas de alto nível lidam com a tarefa.
Quero demonstrar que esse julgamento é errôneo e, de fato, quanto mais complexa a tarefa, mais as vantagens das ferramentas de desenvolvimento de alto nível são manifestadas.
No ano passado, ao trabalhar em um dos projetos, não gostei da câmera comprada no Aliexpress, ou seja, as cores não estavam suficientemente saturadas. Uma das maneiras populares de variar a saturação da cor é alternar do espaço de cores RGB para o espaço HSV, onde um dos parâmetros é a saturação. Lembro-me de como abri a fórmula de transição e respirei fundo ... Implementar esses cálculos no FPGA não é algo extraordinário, mas é claro que levará tempo para escrever o código. Portanto, a fórmula para alternar de RGB para HSV é a seguinte:
 Figura 25
Figura 25A implementação de um algoritmo desse tipo no FPGA não levará dias, mas horas, e tudo isso deve ser feito com muito cuidado devido às especificidades do HDL, e a implementação em C ++ ou no MATLAB levará, eu acho, minutos.
No C ++, você pode escrever código diretamente na testa e ainda obter um resultado funcional.
Eu escrevi a seguinte opção em C ++
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
E a Quartus implementou o resultado com sucesso, como pode ser visto na tabela de recursos usados.
 Figura 26
Figura 26A frequência é muito boa.
 Figura 27
Figura 27Com o codificador HDL, as coisas são um pouco mais complicadas.
Para não inflar o artigo, não fornecerei um script m para esta tarefa, não deve causar dificuldades. Um script m escrito na testa dificilmente pode ser usado com êxito, mas se você editar o código e especificar corretamente os locais para o pipelining, obteremos um resultado útil. Isso, é claro, levará várias dezenas de minutos, mas não horas.
C++ , .
, , , , — , FPGA , HDL.
Conclusão
.
, , , .
, , . , , HDL, .
, FPGA FPGA . .
, — FPGA.
HLS compiler : , , , “best practices” .. MATLAB, , GUI , , , , , .
? — Intel HLS compiler. . HDL coder . , HDL coder , , . HLS, , , FPGA , .
Xilinx , — FPGA. , , Verilog/VHDL , . ( ), .
? , , , HDL .
, , , , .