Recentemente, foi lançado
um artigo que mostra uma boa tendência no aprendizado de máquina nos últimos anos. Em resumo: o número de startups no campo de aprendizado de máquina caiu acentuadamente nos últimos dois anos.
Bem o que. Vamos analisar "se a bolha estourou", "como continuar a viver" e falar sobre de onde vem esse rabisco.
Primeiro, vamos falar sobre o que foi o impulsionador dessa curva. De onde ela veio. Provavelmente todos se lembrarão da
vitória do aprendizado
de máquina em 2012 no concurso ImageNet. Afinal, este é o primeiro evento global! Mas, na realidade, não é assim. E o crescimento da curva começa um pouco antes. Eu dividiria em vários pontos.
- 2008 é o surgimento do termo "big data". Produtos reais começaram a aparecer em 2010. O big data está diretamente relacionado ao aprendizado de máquina. Sem big data, a operação estável dos algoritmos que existiam na época é impossível. E essas não são redes neurais. Até 2012, as redes neurais são uma minoria marginal. Mas então começaram a funcionar algoritmos completamente diferentes, que existiam há anos e até décadas: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... As startups desses anos estão principalmente associadas ao processamento automático de dados estruturados : bilheteiras, usuários, publicidade e muito mais.
A derivada dessa primeira onda é um conjunto de estruturas como XGBoost, CatBoost, LightGBM, etc.
- Em 2011-2012, as redes neurais convolucionais venceram uma série de concursos de reconhecimento de imagens. Seu uso real foi um pouco atrasado. Eu diria que startups e soluções massivamente significativas começaram a aparecer em 2014. Foram necessários dois anos para digerir que os neurônios ainda funcionam, para criar estruturas convenientes que pudessem ser instaladas e executadas em um período de tempo razoável, para desenvolver métodos que estabilizassem e acelerassem o tempo de convergência.
As redes convolucionais possibilitaram solucionar problemas de visão de máquina: classificação de imagens e objetos em uma imagem, detecção de objetos, reconhecimento de objetos e pessoas, aprimoramento de imagens, etc., etc. - 2015-2017 anos. O boom de algoritmos e projetos vinculados a redes de recorrência ou seus análogos (LSTM, GRU, TransformerNet, etc.). Surgiram algoritmos de conversão de texto em texto e sistemas de tradução automática. Em parte, eles são baseados em redes convolucionais para destacar os recursos básicos. Parcialmente pelo fato de terem aprendido a coletar conjuntos de dados realmente grandes e bons.
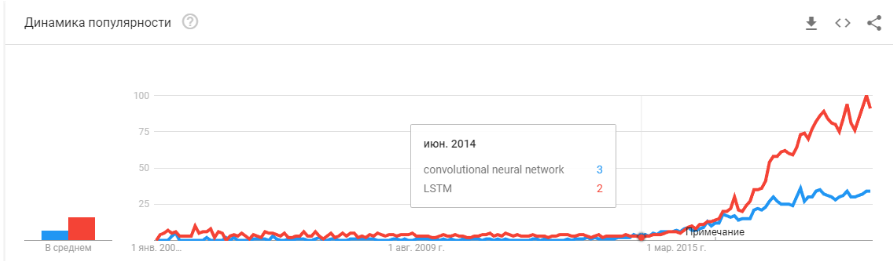
"A bolha estourou?" O Hype está superaquecendo? Eles morreram como uma blockchain? ”
Bem então! Amanhã, a Siri deixará de funcionar no seu telefone e, depois de amanhã, Tesla não distinguirá uma curva de um canguru.
As redes neurais já estão funcionando. Eles estão em dezenas de dispositivos. Eles realmente permitem que você ganhe, mude o mercado e o mundo ao seu redor. Hype parece um pouco diferente:
As redes neurais deixaram de ser algo novo. Sim, muitas pessoas têm grandes expectativas. Mas um grande número de empresas aprendeu a usar seus neurônios e a fabricar produtos baseados neles. Os neurônios fornecem novas funcionalidades, podem reduzir empregos, reduzir o preço dos serviços:
- As empresas de manufatura integram algoritmos para a análise de rejeitos no transportador.
- As fazendas de gado estão comprando sistemas para controlar vacas.
- Colheitadeiras automáticas.
- Centros de atendimento automatizados.
- Filtros no Snapchat. (
bem, pelo menos algo sensato! )
Mas o principal, e não o mais óbvio: "Não há mais idéias novas, ou elas não trarão capital instantâneo". As redes neurais resolveram dezenas de problemas. E eles vão decidir ainda mais. Todas as idéias óbvias que surgiram - geraram muitas startups. Mas tudo o que estava na superfície já foi coletado. Nos últimos dois anos, não conheci uma única idéia nova para o uso de redes neurais. Nem uma única abordagem nova (bem, ok, existem alguns problemas com os GANs).
E toda próxima inicialização é cada vez mais complicada. Não são mais necessários dois indivíduos que treinam um neurônio em dados abertos. Exige programadores, um servidor, uma equipe de escritores, suporte complexo, etc.
Como resultado, há menos startups. Mas a produção é mais. Precisa anexar o reconhecimento de placas? Existem centenas de profissionais com experiência relevante no mercado. Você pode contratar e em alguns meses seu funcionário criará um sistema. Ou compre um acabado. Mas fazer uma nova startup? .. Loucura!
Precisamos criar um sistema para rastrear visitantes - por que pagar por várias licenças, quando você pode fazer suas próprias por 3-4 meses, aprimorá-las para seus negócios.
Agora, as redes neurais seguem o mesmo caminho que dezenas de outras tecnologias.
Lembra como o conceito de "desenvolvedor de sites" mudou desde 1995? Enquanto o mercado não está saturado com especialistas. Existem muito poucos profissionais. Mas posso apostar que em 5 a 10 anos não haverá muita diferença entre um programador Java e um desenvolvedor de rede neural. E esses e esses especialistas serão suficientes no mercado.
Simplesmente haverá uma classe de tarefas para as quais os neurônios são resolvidos. Houve uma tarefa - contratar um especialista.
E então o que? Onde está a inteligência artificial prometida?E aqui há um neponyatchka pequeno, mas interessante :)
A pilha de tecnologia que existe hoje, aparentemente, ainda não nos levará à inteligência artificial. As idéias, sua novidade, esgotaram-se em grande parte. Vamos falar sobre o que mantém o nível atual de desenvolvimento.
Limitações
Vamos começar com auto-drones. Parece ser entendido que é possível fabricar carros totalmente autônomos com as tecnologias atuais. Mas depois de quantos anos isso vai acontecer não está claro. Tesla acredita que isso acontecerá em alguns anos -
Existem muitos outros
especialistas que avaliam isso entre 5 e 10 anos.
Muito provavelmente, em minha opinião, depois de 15 anos, a infraestrutura das cidades mudará para que o surgimento de carros autônomos se torne inevitável, seja sua continuação. Mas isso não pode ser considerado inteligência. O Tesla moderno é um pipeline muito complexo para filtrar dados, pesquisá-los e reciclar. Estas são regras, regras, regras, coleta de dados e filtros acima deles (
aqui escrevi um pouco mais sobre isso, ou veja a partir
deste ponto).
Primeiro problema
E é aqui que vemos o
primeiro problema fundamental . Big data. Foi exatamente isso que gerou a atual onda de redes neurais e aprendizado de máquina. Agora, para fazer algo complexo e automático, você precisa de muitos dados. Não apenas muito, mas muito, muito mesmo. Precisamos de algoritmos automatizados para coleta, marcação e uso. Queremos fazer o carro ver caminhões contra o sol - precisamos primeiro coletar um número suficiente deles. Queremos que o carro não fique louco com uma bicicleta presa ao porta-malas - mais amostras.
Além disso, um exemplo não é suficiente. Centenas? Milhares?

Segundo problema
O segundo problema é a visualização do que nossa rede neural entendeu. Esta é uma tarefa muito não trivial. Até agora, poucas pessoas entendem como visualizar isso. Esses artigos são muito recentes, são apenas alguns exemplos, mesmo remotos:
Visualização de fixação em texturas. Ele mostra bem o que o neurônio tende a percorrer em ciclos + o que ele percebe como informação inicial.
 Visualização de
Visualização de atenuação durante
traduções . Realmente, a atenuação geralmente pode ser usada com precisão para mostrar o que causou uma reação dessa rede. Eu conheci essas coisas para depuração e soluções de produtos. Existem muitos artigos sobre esse tópico. Porém, quanto mais complexos os dados, mais difícil é entender como obter uma visualização sustentável.

Bem, sim, o bom e velho conjunto de "veja qual é a grade interna nos
filtros ". Essas fotos eram populares há cerca de 3-4 anos atrás, mas todos rapidamente perceberam que as fotos são lindas, mas não há muito sentido nelas.

Não citei dezenas de outras loções, métodos, hacks, estudos sobre como exibir o interior da rede. Essas ferramentas funcionam? Eles ajudam você a entender rapidamente qual é o problema e depurar a rede? .. Retire o último percentual? Bem, algo como isto:

Você pode assistir a qualquer concurso no Kaggle. E uma descrição de como as pessoas tomam decisões finais. Chegamos ao modelo 100-500-800 mulenov e funcionou!
Claro, eu exagerei. Mas essas abordagens não dão respostas rápidas e diretas.
Com experiência suficiente e opções diferentes, é possível emitir um veredicto sobre o motivo pelo qual o sistema tomou essa decisão. Mas corrigir o comportamento do sistema será difícil. Coloque uma muleta, mova o limite, adicione um conjunto de dados, pegue outra rede de back-end.
Terceiro problema
O terceiro problema fundamental é que as grades não ensinam lógica, mas estatística. Estatisticamente esta
pessoa :

Logicamente - não é muito parecido. As redes neurais não aprendem algo complicado se não forem forçadas. Eles sempre aprendem os sintomas mais simples. Tem olhos, nariz, cabeça? Então essa cara! Ou dê um exemplo em que os olhos não signifiquem o rosto. E, novamente, milhões de exemplos.
Há muito espaço na parte inferior
Eu diria que são esses três problemas globais que hoje limitam o desenvolvimento de redes neurais e aprendizado de máquina. E onde esses problemas não estavam limitados já é usado ativamente.
Esse é o fim? Redes neurais se levantaram?Desconhecido Mas, é claro, todo mundo espera que não.
Existem muitas abordagens e orientações para solucionar os problemas fundamentais que abordamos acima. Mas até agora, nenhuma dessas abordagens nos permitiu fazer algo fundamentalmente novo, resolver algo que ainda não foi resolvido. Até o momento, todos os projetos fundamentais são realizados com base em abordagens estáveis (Tesla) ou permanecem projetos de teste de institutos ou empresas (Google Brain, OpenAI).
Grosso modo, a direção principal é a criação de alguma representação de alto nível dos dados de entrada. Em certo sentido, "memória". O exemplo mais simples de memória são as várias representações de incorporação de imagens. Bem, por exemplo, todos os sistemas de reconhecimento de rosto. A rede aprende a tirar do rosto uma certa idéia estável que não depende de rotação, iluminação, resolução. De fato, a rede minimiza a métrica de "faces diferentes - distantes" e "idênticas - próximas".

Esse treinamento requer dezenas e centenas de milhares de exemplos. Mas o resultado traz alguns rudimentos do "One-shot Learning". Agora não precisamos de centenas de rostos para lembrar de uma pessoa. Apenas um rosto, e é isso - vamos
descobrir !
Só aqui está o problema ... A grade pode aprender apenas objetos bastante simples. Ao tentar distinguir não rostos, mas, por exemplo, “pessoas de roupas” (a
tarefa de re-identificação ), a qualidade falha em muitas ordens de magnitude. E a rede não pode mais aprender mudanças de ângulo óbvias o suficiente.
E aprender com milhões de exemplos também é, de alguma forma, algo tão divertido.
Há trabalho para reduzir significativamente a eleição. Por exemplo, você pode recordar imediatamente um dos primeiros trabalhos do
Google OneShot Learning :
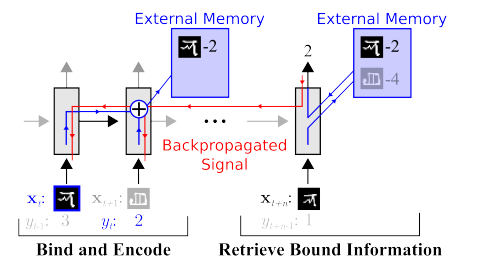
Existem muitos desses trabalhos, por exemplo
1 ou
2 ou
3 .
Há um ponto negativo - geralmente o treinamento funciona bem em alguns exemplos simples de "MNIST'ovskie". E na transição para tarefas complexas - você precisa de uma grande base, um modelo de objetos ou algum tipo de mágica.
Em geral, o trabalho no treinamento One-Shot é um tópico muito interessante. Você encontra muitas idéias. Mas, na maioria das vezes, os dois problemas que listei (pré-treinamento em um enorme conjunto de dados / instabilidade em dados complexos) são muito prejudiciais ao aprendizado.
Por outro lado, a GAN - redes genericamente competitivas - aborda a incorporação. Você provavelmente leu vários artigos sobre esse tópico no Habré. (
1 ,
2 ,
3 )
Um recurso do GAN é a formação de algum espaço de estado interno (essencialmente a mesma incorporação), que permite desenhar uma imagem. Pode ser
pessoas , pode haver
ações .
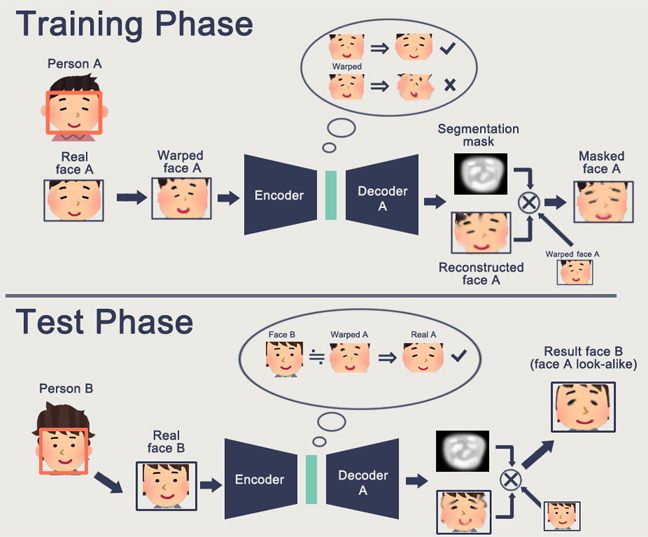
O problema da GAN é que, quanto mais complexo é o objeto gerado, mais difícil é descrevê-lo na lógica "discriminador de gerador". Como resultado, das aplicações reais do GAN, que são ouvidas apenas pelo DeepFake, que novamente manipula as representações dos indivíduos (para os quais existe uma base enorme).
Encontrei muito poucas outras aplicações úteis. Geralmente algum tipo de apito falso com desenhos.
E de novo Ninguém entende como isso nos permitirá avançar em direção a um futuro melhor. Representar a lógica / espaço em uma rede neural é bom. Mas precisamos de um grande número de exemplos, não entendemos como esse neurônio representa em si, não entendemos como fazer com que o neurônio se lembre de uma ideia realmente complicada.
O aprendizado por reforço é uma abordagem completamente diferente. Você certamente se lembra de como o Google venceu todo mundo no Go. Vitórias recentes em Starcraft e Dota. Mas aqui tudo está longe de ser tão otimista e promissor. A melhor coisa sobre RL e sua complexidade é
este artigo .
Para resumir brevemente o que o autor escreveu:
- Modelos prontos para uso não se encaixam / funcionam mal na maioria dos casos
- Tarefas práticas são mais fáceis de resolver de outras maneiras. O Boston Dynamics não usa RL devido à sua complexidade / imprevisibilidade / complexidade computacional
- Para o RL funcionar, você precisa de uma função complexa. Muitas vezes é difícil criar / escrever.
- É difícil treinar modelos. Temos que gastar muito tempo para balançar e sair das ótimas localidades
- Como resultado, é difícil repetir o modelo, a instabilidade do modelo com a menor mudança
- Muitas vezes, é preenchido demais em alguns padrões à esquerda, até o gerador de números aleatórios
O ponto principal é que a RL ainda não funciona na produção. O Google tem algum tipo de experimento (
1 ,
2 ). Mas eu não vi um único sistema de compras.
Memória A desvantagem de tudo o que é descrito acima não é estruturada. Uma abordagem para tentar arrumar tudo isso é fornecer à rede neural acesso a uma memória separada. Para que ela possa gravar e reescrever os resultados de suas etapas lá. Então a rede neural pode ser determinada pelo estado atual da memória. Isso é muito semelhante aos processadores e computadores clássicos.
O artigo mais famoso e popular é do DeepMind:
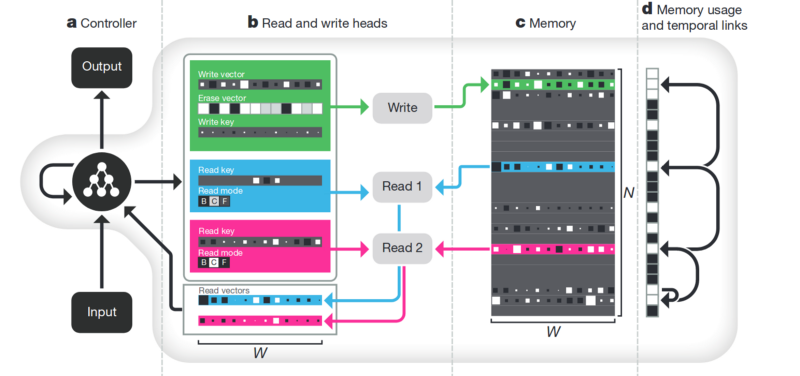
Parece que aqui está a chave para entender a inteligência? Mas sim, não. O sistema ainda precisa de uma enorme quantidade de dados para treinamento. E funciona principalmente com dados tabulares estruturados. Ao mesmo tempo, quando o Facebook
resolveu um problema semelhante, eles seguiram o caminho “veem a memória, apenas complicamos o neurônio, mas há mais exemplos - e ele aprenderá a si próprio”.
Desembaraço . Outra maneira de criar memória significativa é realizar as mesmas incorporações, mas ao aprender a introduzir critérios adicionais que lhes permitam destacar "significados" neles. Por exemplo, queremos treinar uma rede neural para distinguir entre o comportamento de uma pessoa em uma loja. Se seguíssemos o caminho padrão, teríamos que fazer uma dúzia de redes. Um está procurando uma pessoa, o segundo determina o que está fazendo, o terceiro é a idade, o quarto é o sexo. A lógica separada examina a parte da loja onde ele faz / aprende. O terceiro determina sua trajetória, etc.
Ou, se houvesse infinitos dados, seria possível treinar uma rede para todos os tipos de resultados (é óbvio que esse conjunto de dados não pode ser digitado).
A abordagem de desdentamento nos diz - e vamos treinar a rede para que ela mesma possa distinguir entre conceitos. Para que ela forme uma incorporação no vídeo, onde uma área determinaria a ação, uma - a posição no chão no tempo, uma - a altura da pessoa e outra - seu gênero. Ao mesmo tempo, durante o treinamento, quase nunca gostaria de sugerir conceitos-chave para a rede, mas para que ela própria identifique e agrupe áreas. Existem poucos artigos (alguns são
1 ,
2 ,
3 ) e, em geral, são bastante teóricos.
Mas essa direção, pelo menos teoricamente, deve cobrir os problemas listados no começo.
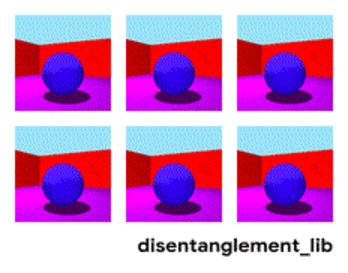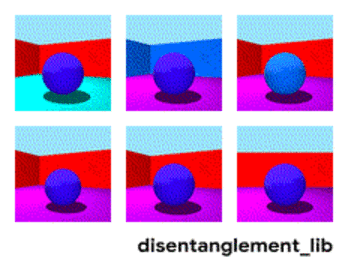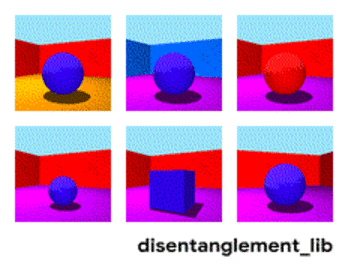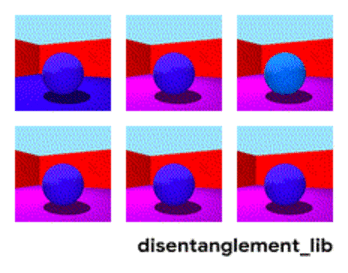
Decomposição da imagem de acordo com os parâmetros “cor da parede / cor do piso / forma do objeto / cor do objeto / etc.”

Decomposição da face de acordo com os parâmetros “tamanho, sobrancelhas, orientação, cor da pele, etc.”
Outros
Existem muitas outras direções não tão globais que nos permitem reduzir a base, trabalhar com dados mais heterogêneos etc.
Atenção . Provavelmente não faz sentido isolar isso como um método separado. Apenas uma abordagem que reforça os outros. Muitos artigos foram dedicados a ele (
1 ,
2 ,
3 ). O significado de Atenção é fortalecer a resposta da rede a objetos significativos durante o treinamento. Geralmente, por alguma designação de destino externo ou por uma pequena rede externa.
Simulação 3D . Se você cria um bom mecanismo 3D, geralmente pode fechar 90% dos dados de treinamento (até vi um exemplo em que quase 99% dos dados foram fechados com um bom mecanismo). Existem muitas idéias e truques sobre como fazer uma rede treinada em um mecanismo 3D funcionar com dados reais (ajuste fino, transferência de estilo etc.). Mas muitas vezes criar um bom mecanismo é várias ordens de magnitude mais difíceis do que coletar dados. Exemplos ao fabricar motores:
Treinamento de robôs (
google ,
braingarden )
Aprendendo a
reconhecer mercadorias em uma loja (mas em dois projetos que realizamos, dispensamos isso com calma).
Treinamento na Tesla (novamente, o vídeo acima).
Conclusões
O artigo inteiro é, em certo sentido, conclusões. Provavelmente a principal mensagem que eu queria fazer era "o brinde acabou, os neurônios não dão soluções mais simples". Agora temos que trabalhar duro para criar soluções complexas. Ou trabalhe duro fazendo relatórios científicos complexos.
Em geral, o tópico é discutível. Talvez os leitores tenham exemplos mais interessantes?