Em vez de se juntar
No início de nosso blog, escrevemos o
que o IPONWEB está
fazendo - automatizamos a exibição de anúncios na Internet. Nossos sistemas tomam decisões não apenas com base em dados históricos, mas também usam ativamente as informações obtidas em tempo real. No caso do DSP (Demand Side Platform - uma plataforma de publicidade para anunciantes), o anunciante (ou seu representante) deve criar e fazer upload de um banner de publicidade (criativo) em um dos formatos (foto, vídeo, banner interativo, foto + texto etc.) , selecione o público de usuários para quem esse banner será exibido, determine quantas vezes é possível exibir publicidade para um usuário, em quais países, em quais sites, em quais dispositivos e reflita isso (e muito mais) nas configurações de segmentação da campanha publicitária, além de distribuir publicidade o orçamento s. Para o SSP (Supply Side Platform - uma plataforma de publicidade para proprietários de plataformas de publicidade), o proprietário do site (aplicativo móvel, quadro de avisos, canal de televisão) deve determinar os pontos de publicidade em seu site e indicar, por exemplo, quais categorias de publicidade ele está pronto para exibir neles. Todas essas configurações são feitas manualmente com antecedência (não no momento da exibição de anúncios) usando a interface do usuário. Neste artigo, falarei sobre nossa abordagem para criar essas interfaces, desde que existam muitas, elas são semelhantes umas às outras e, ao mesmo tempo, têm características individuais.
Como tudo começou
Começamos os negócios de publicidade em 2007, mas não fizemos interfaces imediatamente, mas apenas em 2014. Tradicionalmente, estamos engajados no desenvolvimento de plataformas personalizadas, completamente projetadas de acordo com as especificidades dos negócios de cada cliente - entre as dezenas de plataformas que construímos, não há duas idênticas. E como nossas plataformas de publicidade foram projetadas sem restrições sobre as possibilidades de personalização, a interface do usuário precisava atender aos mesmos requisitos.
Quando recebemos o primeiro pedido de uma interface de publicidade para o DSP, cinco anos atrás, nossa escolha caiu na pilha de tecnologia popular e conveniente: JavaScript e AngularJS no front-end e o back-end no Python, Django e Django Rest Framework (DRF). A partir disso, o projeto mais comum foi realizado, cuja principal tarefa era fornecer a funcionalidade CRUD. O resultado de seu trabalho foi um arquivo de configurações para o sistema de publicidade no formato XML. Agora, esse protocolo de interação pode parecer estranho, mas, como já discutimos, os primeiros sistemas de publicidade (mesmo sem uma interface do usuário) que começamos a construir nos "zero", e esse formato foi preservado até hoje.
Após o lançamento bem-sucedido do primeiro projeto, o seguinte não levou muito tempo. Essa também era a interface do usuário para o DSP e os requisitos para eles eram os mesmos do primeiro projeto. Quase. Apesar de tudo ser muito parecido, o diabo estava oculto nos detalhes - há uma hierarquia de objetos um pouco diferente, alguns campos são adicionados lá ... A maneira mais óbvia de obter o segundo projeto, muito semelhante ao primeiro, mas com melhorias, foi o método de replicação que usamos . E isso implicava problemas familiares para muitos - junto com o código "bom", os bugs também eram copiados, cujos patches tinham que ser distribuídos manualmente. O mesmo aconteceu com todos os novos recursos lançados em todos os projetos ativos.
Nesse modo, era possível trabalhar enquanto havia poucos projetos, mas quando seu número excedia 20, a abordagem familiar deixou de crescer. Portanto, decidimos transferir as partes comuns dos projetos para a biblioteca, da qual o projeto conectará os componentes necessários. Se um bug for detectado, ele é reparado uma vez na biblioteca e é automaticamente distribuído aos projetos quando a versão da biblioteca é atualizada, e o mesmo ocorre com a reutilização de novos recursos.
Configuração e terminologia
Tivemos várias iterações na implementação dessa abordagem, e todas elas evoluíram uma para a outra de forma evolutiva, começando com nosso projeto usual sobre DRF puro. Na implementação mais recente, nosso projeto é descrito usando DSL baseado em JSON (veja a figura). Este JSON descreve a estrutura dos componentes do projeto e suas interconexões, e o front-end e o back-end podem lê-lo.
Após inicializar o aplicativo Angular, o front-end solicita uma configuração JSON do back-end. O back-end não apenas fornece um arquivo de configuração estático, mas também o processa, complementando-o com vários metadados ou excluindo partes da configuração responsáveis por partes do sistema inacessíveis ao usuário. Isso permite que você mostre a diferentes usuários a interface de diferentes maneiras, incluindo formulários interativos, estilos CSS de todo o aplicativo e elementos de design específicos. O último é especialmente verdadeiro para interfaces de usuário de plataformas que são usadas por diferentes tipos de clientes com diferentes funções e níveis de acesso.

O back-end, ao contrário do front-end, lê a configuração uma vez no estágio de inicialização do aplicativo Django. Assim, a quantidade total de funcionalidades é registrada no back-end e o acesso a várias partes do sistema é verificado em tempo real.
Antes de passar para a parte mais interessante - estrutura do banco de dados -, quero introduzir vários conceitos que usamos quando falamos sobre a estrutura de nossos projetos, a fim de manter o mesmo comprimento de onda que o leitor.
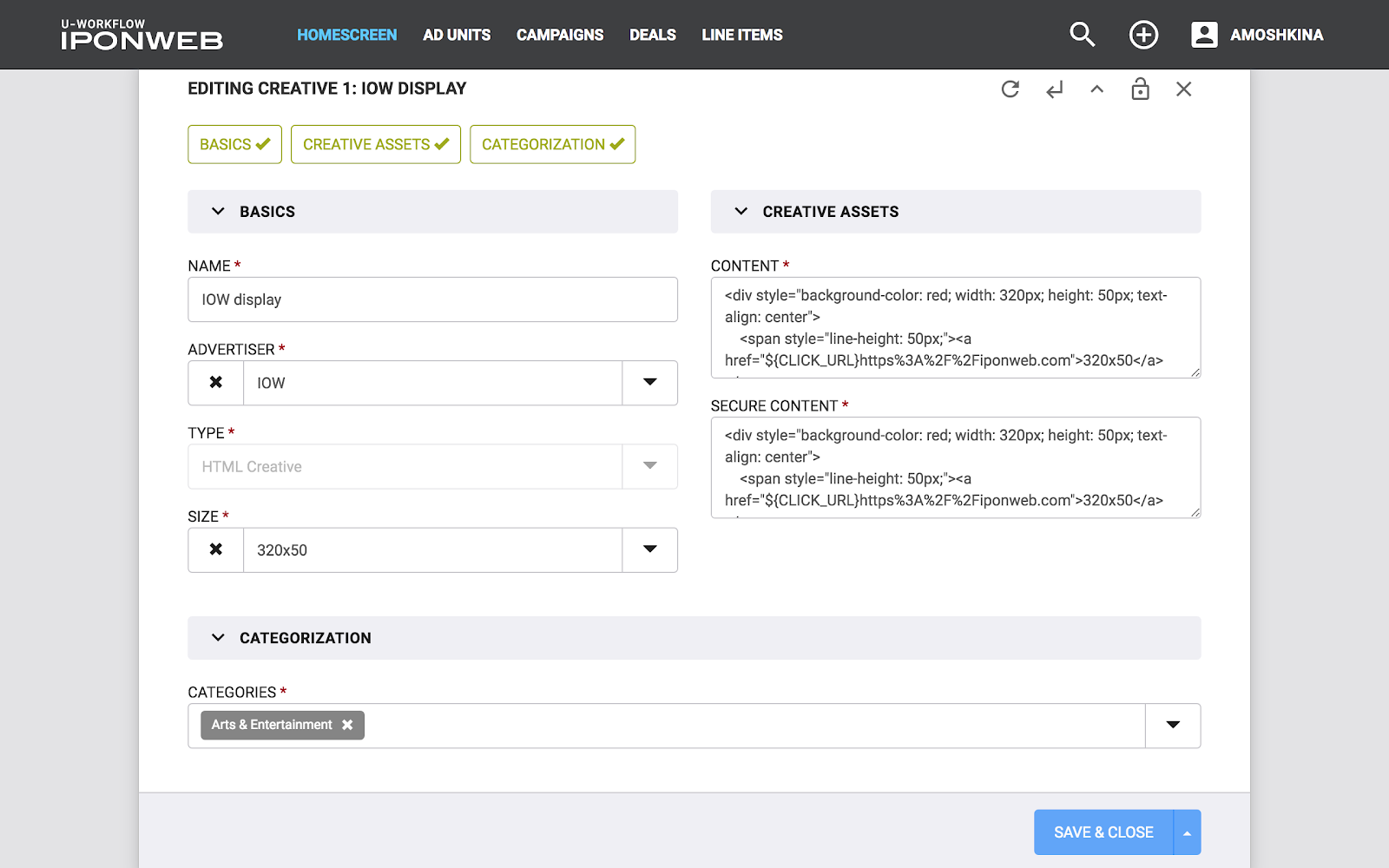
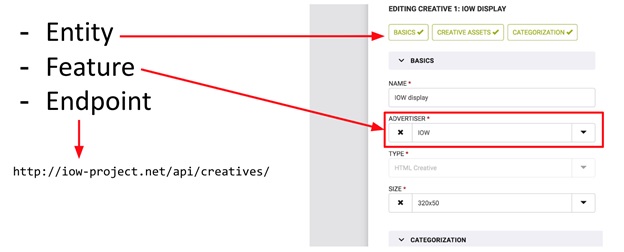
Esses conceitos - Entidade e Recurso - estão bem ilustrados no formulário de entrada de dados (veja a figura). O formulário inteiro é Entidade, e os campos individuais são Recurso. A imagem também mostra o Endpoint (apenas por precaução). Portanto, Entidade é um objeto independente no sistema no qual as operações CRUD podem ser executadas, enquanto o Recurso é apenas parte de "algo mais", parte da Entidade. Com o Feature, você não pode executar operações CRUD sem estar vinculado a nenhuma Entidade. Por exemplo: o orçamento de uma campanha publicitária sem referência à própria campanha é simplesmente um número que não pode ser usado sem informações sobre a campanha principal.
Os mesmos conceitos podem ser encontrados na configuração JSON do projeto (veja a figura).

Estrutura de banco de dados
A parte mais interessante de nossos projetos é a estrutura do banco de dados e a mecânica que o suporta. Tendo começado a usar o PostgreSQL nas primeiras versões de nossos projetos, continuamos com essa tecnologia hoje. Junto com isso, estamos usando ativamente o Django ORM. Nas implementações iniciais, usamos o modelo padrão de relacionamento entre objetos (entidades) na Chave Externa; no entanto, essa abordagem causava dificuldades quando era necessário alterar a hierarquia dos relacionamentos. Portanto, por exemplo, na hierarquia padrão da Unidade de negócios DSP -> Anunciante -> Campanha, alguns clientes precisavam entrar no nível da agência (Unidade de negócios -> Agência -> Anunciante -> ...). Portanto, abandonamos gradualmente o uso de chave estrangeira e organizamos links entre objetos usando links Many To Many através de uma tabela separada, denominada `LinkRegistry`.
Além disso, gradualmente abandonamos o código rígido para preencher entidades e começamos a armazenar a maioria dos campos em tabelas separadas, vinculando-os também através do `LinkRegistry` (veja a figura). Por que isso foi necessário? Para cada cliente, o conteúdo da entidade pode variar - alguns campos serão adicionados ou excluídos. Acontece que teremos de armazenar em cada entidade um superconjunto de campos para todos os nossos clientes. Ao mesmo tempo, todos terão que ser opcionais, para que os campos obrigatórios "alienígenas" não interfiram no trabalho.

Considere o exemplo da figura: aqui a estrutura do banco de dados para o criativo com um campo adicional é descrita - `image_url`. Somente seu ID é armazenado na tabela de criativos e image_url é armazenado em uma tabela separada, o relacionamento deles é descrito por outra entrada na tabela LinkRegistry. Portanto, esse criativo será descrito por três entradas, uma em cada uma das tabelas. Dessa forma, para salvar um criativo, você precisa fazer uma entrada em cada um deles e lê-lo da mesma maneira, visitando 3 tabelas. Seria muito inconveniente escrever esse processamento sempre do zero, para que nossa biblioteca abstraia todos esses detalhes do programador. Para trabalhar com dados, o Django e o DRF usam modelos e serializadores descritos pelo código. Em nossos projetos, o conjunto de campos em modelos e serializadores é determinado em tempo de execução pela configuração JSON, as classes de modelo são criadas dinamicamente (usando a função type) e armazenadas em um registro especial, de onde estão disponíveis durante a operação do aplicativo. Também usamos classes base especiais para esses modelos e serializadores, que ajudam no trabalho com estrutura base não padrão.
Ao salvar um novo objeto (ou atualizar um existente), os dados recebidos do front-end entram no serializador, onde são validados - não há nada de incomum, os mecanismos DRF padrão funcionam. Mas salvar e atualizar são redefinidos aqui. O serializador sempre sabe com qual modelo ele trabalha e, de acordo com a representação interna de nosso modelo dinâmico, pode entender em qual tabela os dados do próximo campo devem ser colocados. Codificamos essas informações nos campos de modelo personalizado (lembre-se de como a `ForeignKey` é descrita no Django - um modelo relacionado é passado dentro do campo, fazemos o mesmo). Nesses campos especiais, também resumimos a necessidade de adicionar um terceiro registro de ligação ao LinkRegistry usando o mecanismo do descritor - no código que você escreve `creative.image_url = 'http: // foo.bar' 'e no método substituído __set__ que escrevemos para `LinkRegistry`.
Isso se aplica à gravação no banco de dados. E agora vamos lidar com a leitura. Como uma tupla é retirada de um banco de dados convertida em uma instância de modelo do Django? No modelo base do Django, existe um método `from_db`, que é chamado para cada tupla recebida ao executar uma consulta no` queryset`. Na entrada, ele recebe uma tupla e retorna a instância do modelo Django. Redefinimos esse método em nosso modelo base, onde, de acordo com a tupla do modelo principal (onde apenas `id` entra), obtemos dados de outras tabelas relacionadas e, tendo esse conjunto completo, instanciamos o modelo. Obviamente, também trabalhamos para otimizar o mecanismo de pré-busca do Django para o nosso caso de uso não padrão.
Teste
Nossa estrutura é bastante complexa, por isso escrevemos muitos testes. Temos testes para o front-end e o back-end. Vou me debruçar sobre os testes de back-end em detalhes.
Para executar os testes, usamos pytest. No back-end, temos duas grandes classes de testes: testes de nossa estrutura (também denominamos "núcleo") e testes de projeto.
No kernel, escrevemos testes de unidade isolados e funcionais para testar pontos de extremidade usando o plugin pytest-django. Em geral, todo o trabalho com o banco de dados é testado principalmente por meio de solicitações à API - como acontece na produção.
Testes funcionais podem especificar uma configuração JSON. Para não se apegar à terminologia do design, usamos nomes "fictícios" para entidades com as quais testamos nossos Recursos no kernel ("Emma", "Alla", "Karl", "Maria" e assim por diante). Como, ao escrever o recurso image_url, não queremos limitar a consciência do desenvolvedor ao fato de que ele pode ser usado apenas com a entidade Criativa - os recursos e as entidades são universais e podem ser conectados entre si em qualquer combinação relevante para um cliente em particular.
Quanto aos projetos de teste, todos os casos de teste são executados com a configuração de produção, sem entidades fictícias, pois é importante verificar exatamente com o que o cliente trabalhará. No projeto, você pode escrever qualquer teste que cubra os recursos da lógica de negócios do projeto. Ao mesmo tempo, testes básicos de CRUD podem ser conectados ao projeto a partir do kernel. Eles são escritos de maneira geral e podem ser conectados a qualquer projeto: um teste de recurso pode ler a configuração JSON de um projeto, determinar a quais entidades esse recurso está conectado e executar verificações apenas nas entidades necessárias. Para facilitar a preparação dos dados de teste, desenvolvemos um sistema de auxiliares que também podem preparar conjuntos de dados de teste com base na configuração JSON. Um lugar especial nos testes do projeto é ocupado pelos testes E2E no Transferidor, que testam todas as funções básicas do projeto. Esses testes também são descritos usando JSON, eles são escritos e suportados por desenvolvedores de front-end.
Posfácio
Neste artigo, examinamos a abordagem de design modular desenvolvida pelo IPONWEB no departamento de interface do usuário. Esta solução opera com sucesso na produção há três anos. No entanto, essa solução ainda possui várias limitações que não nos permitem descansar sobre os louros. Em primeiro lugar, nossa base de código ainda é bastante complexa. Em segundo lugar, o código básico que suporta modelos dinâmicos está associado a componentes críticos como pesquisa, carregamento em massa de objetos, direitos de acesso e outros. Por esse motivo, as alterações em um dos componentes podem afetar significativamente os outros. Em um esforço para nos livrar dessas restrições, continuamos processando ativamente nossa biblioteca, dividindo-a em várias partes independentes e reduzindo a complexidade do código. Vamos falar sobre os resultados nos seguintes artigos.
Este artigo é uma transcrição estendida da minha apresentação no MoscowPythonConf ++ 2019, então eu também compartilho links para
vídeos e
slides .