Em teoria, o uso do aprendizado de máquina (ML) ajuda a reduzir o envolvimento humano em processos e operações, realocar recursos e reduzir custos. Como isso funciona em uma empresa e setor específicos? Como mostra nossa experiência, funciona.
Em um certo estágio de desenvolvimento, nós da VTB Capital enfrentamos uma necessidade urgente de reduzir o tempo necessário para processar solicitações de suporte técnico. Após analisar as opções, decidiu-se usar a tecnologia ML para categorizar chamadas de usuários comerciais da Calypso, a principal plataforma de investimentos da empresa. O processamento rápido de tais solicitações é crucial para a alta qualidade do serviço de TI. Pedimos aos nossos principais parceiros,
EPAM, para ajudar a resolver este problema.

Portanto, as solicitações de suporte são recebidas por email e transformadas em tickets em Jira. Em seguida, os especialistas em suporte os classificam manualmente, priorizam-nos, inserem dados adicionais (por exemplo, de qual departamento e local onde uma solicitação foi recebida, em qual unidade funcional do sistema a que pertence) e nomeiam artistas. No total, são usadas cerca de 10 categorias de consultas. Por exemplo, isso pode ser uma solicitação para analisar alguns dados e fornecer informações ao solicitante, adicionar um novo usuário etc. Além disso, as ações podem ser padrão ou não padrão, portanto, é muito importante determinar imediatamente corretamente o tipo de solicitação e atribuir a execução ao especialista certo.
É importante observar: a VTB Capital queria não apenas desenvolver uma solução tecnológica aplicada, mas também avaliar as capacidades de várias ferramentas e tecnologias no mercado. Uma tarefa, duas abordagens diferentes, duas plataformas de tecnologia e três semanas e meia: qual foi o resultado?
Protótipo nº 1: tecnologias e modelos
A base para o desenvolvimento do protótipo foi a abordagem proposta pela equipe do EPAM e dados históricos - cerca de 10.000 ingressos de Jira. A atenção principal foi focada nos três campos obrigatórios que cada ticket contém: Tipo de problema (tipo de problema), Resumo ("cabeçalho" da carta ou assunto da solicitação) e Descrição (descrição). Dentro da estrutura do projeto, foi planejado resolver o problema de analisar o texto dos campos Resumo e Descrição e determinar automaticamente o tipo de solicitação com base em seus resultados.
São as características do texto nesses dois campos de ticket que se tornaram a principal dificuldade técnica na análise de dados e no desenvolvimento de modelos de ML. Portanto, o campo Resumo pode conter texto bastante "limpo", mas incluindo palavras e termos específicos (por exemplo,
relatórios do CWS não em execução). O campo Descrição, pelo contrário, é caracterizado por um texto mais "sujo", com uma abundância de caracteres especiais, símbolos, barras invertidas e resíduos de elementos que não são de texto:
Colegas de Dera,
Você poderia nos explicar qual é a diferença entre as medidas de risco FX_Opt_delta_all e FX_Opt_delta_cash?
! 01D39C59.62374C90_image001.png! )
Além disso, o texto geralmente combina vários idiomas (principalmente, naturalmente, russo e inglês), terminologia de negócios, áspero e gíria de programador. E, é claro, como as solicitações costumam ser escritas às pressas, em ambos os casos, erros de digitação e ortografia não são descartados.
As tecnologias escolhidas pela equipe do EPAM incluíam Python 3.5 para desenvolvimento de protótipos, NLTK + Gensim + Re para processamento de texto, Pandas + Sklearn para análise de dados e desenvolvimento de modelos e Keras + Tensorflow como uma estrutura de aprendizado profundo e back-end.
Levando em consideração as possíveis características dos dados iniciais, três representações foram construídas para a extração de caracteres no campo Resumo: no nível do símbolo, combinação de símbolos e palavras individuais. Cada uma das representações foi usada como entrada para uma rede neural recorrente.
Por sua vez, as estatísticas de caracteres de serviço (importantes para o processamento de texto usando pontos de exclamação, barras, etc.) e os valores médios das cadeias após filtrar os caracteres de serviço e o lixo (para preservação compacta da estrutura do texto) foram escolhidos como uma representação para o campo Descrição; bem como representação no nível da palavra após a filtragem das palavras de parada. Cada representação serviu de entrada para uma rede neural: estatísticas de maneira totalmente conectada, linha por linha e no nível das palavras - de forma recursiva.
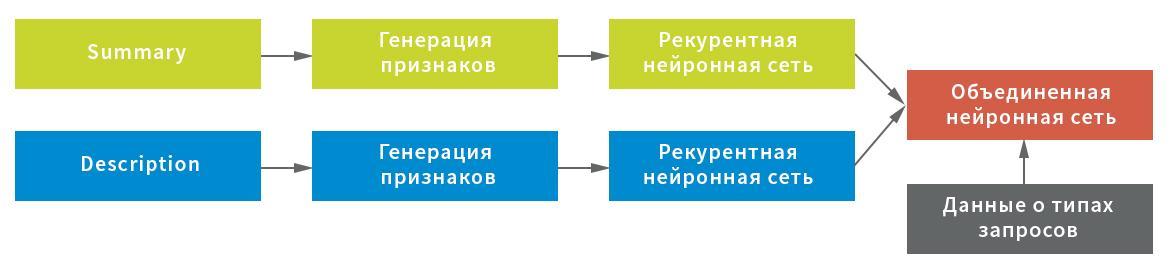
Nesse esquema, uma rede neural foi usada como uma rede recorrente, consistindo em uma camada GRU bidirecional com uma saída recorrente e normal, um conjunto de estados ocultos da rede recorrente usando a camada GlobalMaxPool1D e uma camada de saída totalmente conectada (Densa). Para cada uma das entradas, sua própria “cabeça” da rede neural foi construída e, em seguida, foram combinadas por concatenação e bloqueadas na variável de destino.
Para obter o resultado final, a rede neural combinada retornou as probabilidades de uma solicitação específica pertencente a cada tipo. Os dados foram divididos em cinco blocos sem interseções: o modelo foi construído em quatro deles e testado no quinto. Como cada solicitação pode receber apenas um tipo de solicitação, a regra para tomar uma decisão era simples - pelo valor máximo de probabilidade.
Protótipo nº 2: algoritmos e princípios de trabalho
O segundo protótipo, para o qual a proposta preparada pela equipe da VTB Capital foi aceita, é um aplicativo no Microsoft .NET Core com bibliotecas Microsoft.ML para implementar algoritmos de aprendizado de máquina e no Atlassian.Net SDK para interagir com o Jira por meio da API REST. A base para a construção de modelos ML também se tornou dados históricos - 50.000 bilhetes Jira. Como no primeiro caso, o aprendizado de máquina abrangeu os campos Resumo e Descrição. Antes do uso, os dois campos também foram "limpos". Saudações, assinaturas, histórico de correspondência e elementos não textuais (por exemplo, imagens) foram excluídos da carta do usuário. Além disso, usando a funcionalidade interna do Microsoft ML, as palavras de parada que não eram relevantes para o processamento e análise do texto foram apagadas do texto em inglês.
O Perceptron médio (classificação binária) foi escolhido como um algoritmo de aprendizado de máquina, complementado pelo método One Versus All para fornecer classificação em várias classes
Avaliação dos resultados
Nenhum modelo de ML pode (possivelmente ainda) fornecer 100% de precisão do resultado.
O protótipo de algoritmo n ° 1 fornece o compartilhamento da classificação correta (precisão), igual a 0,883 do número total de solicitações, ou 80%. Além disso, o valor de uma métrica semelhante em uma situação em que se assume que a resposta correta será escolhida pela pessoa dentre as duas apresentadas pela solução atinge 0,901, ou 90%. Obviamente, há casos em que a solução desenvolvida funciona pior ou não pode dar a resposta correta - em regra, devido a um conjunto muito curto de palavras ou à especificidade das informações na própria solicitação. O papel ainda é desempenhado pela quantidade insuficientemente grande de dados usados no processo de aprendizagem. De acordo com estimativas preliminares, um aumento no volume de informações processadas permitirá aumentar a precisão da classificação em outros 0,01-0,03 pontos.
Os resultados do melhor modelo nas métricas de precisão (Precisão) e completude (Rechamada) são avaliados da seguinte forma:

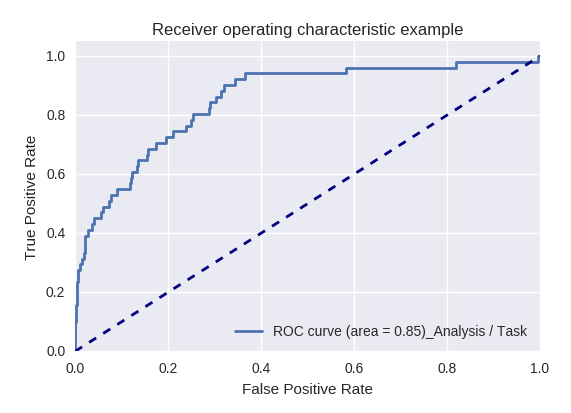
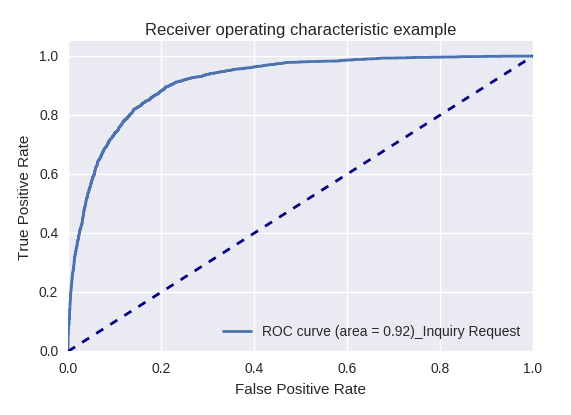
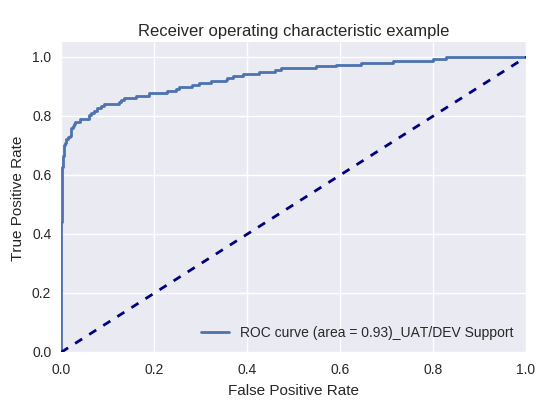
Se avaliarmos a qualidade do modelo como um todo para vários tipos de consultas usando curvas ROC-AUC, os resultados serão os seguintes.
Pedidos de ação (solicitação de ação) e análise de informações (solicitação de análise / tarefa)
 Pedidos de alterações nos dados corporativos (Solicitação de Dados Corporativos) e de alterações (Solicitação de Mudança)
Pedidos de alterações nos dados corporativos (Solicitação de Dados Corporativos) e de alterações (Solicitação de Mudança)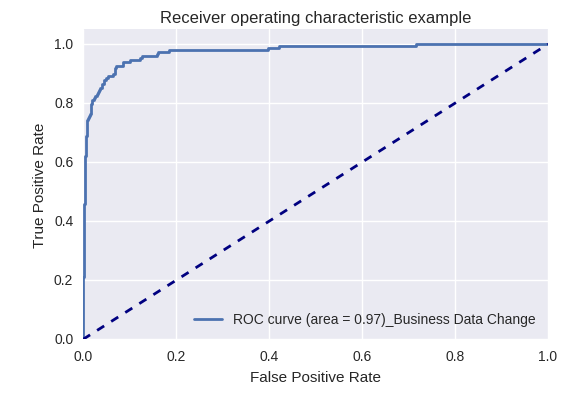
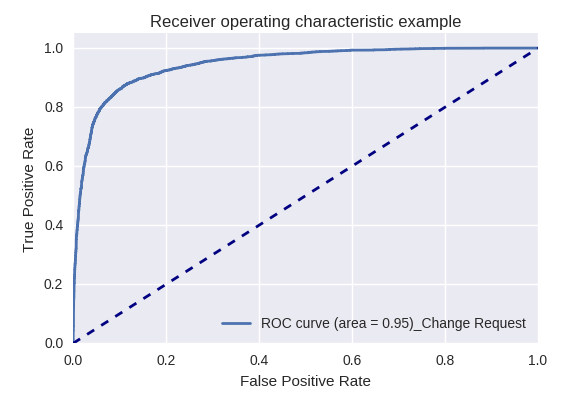 Solicitação de desenvolvimento e solicitação de consulta
Solicitação de desenvolvimento e solicitação de consulta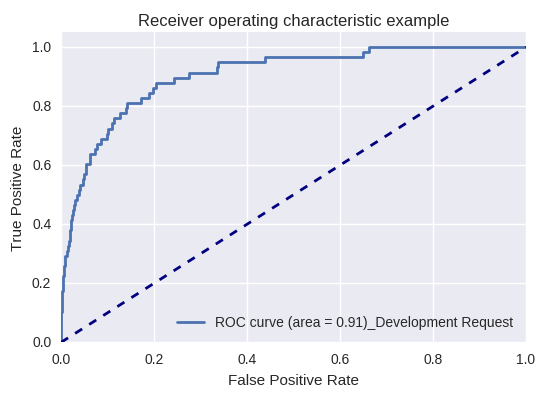
 Solicitações para criar um novo objeto (Nova Solicitação de Objeto) e adicionar um novo usuário (Nova Solicitação de Usuário)
Solicitações para criar um novo objeto (Nova Solicitação de Objeto) e adicionar um novo usuário (Nova Solicitação de Usuário)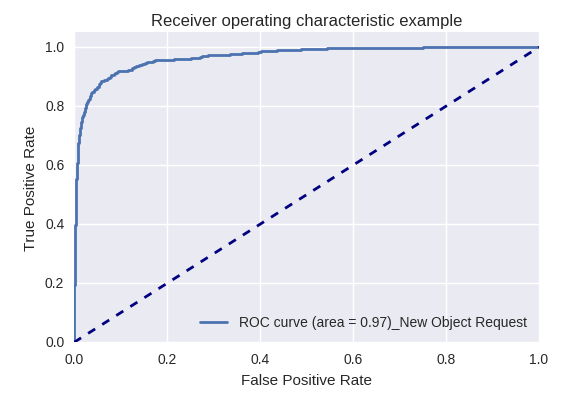
 Solicitação de produção e solicitação de suporte UAT / DEV (solicitação de suporte UAT / Dev)
Solicitação de produção e solicitação de suporte UAT / DEV (solicitação de suporte UAT / Dev)
Exemplos de classificação correta e incorreta para alguns tipos de consultas são fornecidos abaixo:
Pedido de consulta
Solicitação de mudança
Classificação correta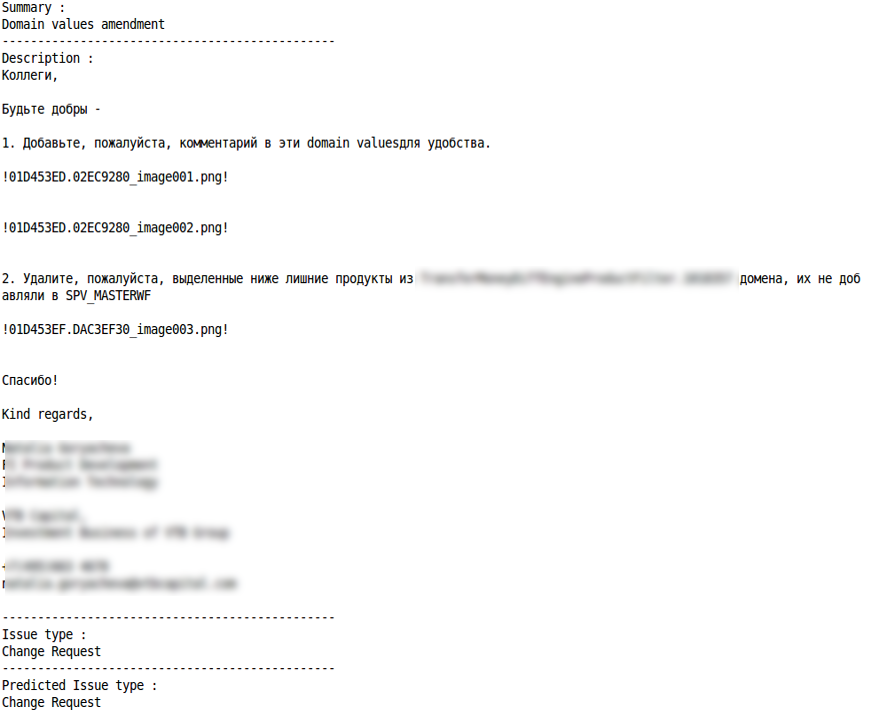 Classificação incorreta
Classificação incorreta Pedido de açãoClassificação correta
Pedido de açãoClassificação correta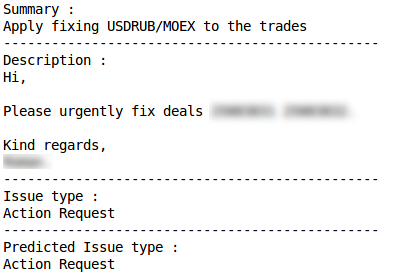 Classificação incorretaProblema de produçãoClassificação correta
Classificação incorretaProblema de produçãoClassificação correta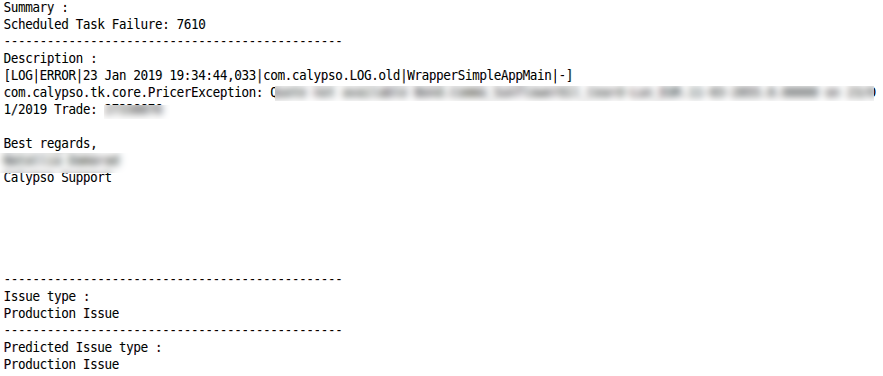 Classificação incorreta
Classificação incorreta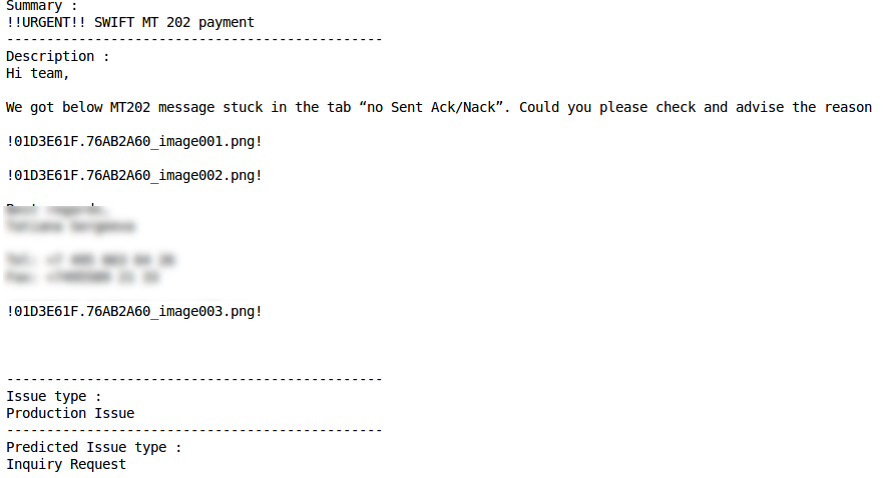
O segundo protótipo também apresentou bons resultados: em aproximadamente 75% dos casos, o ML determina corretamente o tipo de consulta (métrica de precisão). A oportunidade de melhorar o indicador está associada à melhoria da qualidade dos dados de origem, em particular a eliminação de casos em que as mesmas consultas foram atribuídas a diferentes tipos.
Resumir
Cada um dos protótipos implementados mostrou sua eficácia e agora uma combinação de dois protótipos desenvolvidos foi lançada na produção piloto da VTB Capital. Um pequeno experimento com ML em menos de um mês e a um custo mínimo permitiu que a empresa se familiarizasse com as ferramentas de aprendizado de máquina e resolvesse um importante problema de aplicativo para classificar as solicitações dos usuários.
A experiência adquirida pelos desenvolvedores do EPAM e VTB Capital - além de usar algoritmos implementados para processar solicitações de usuários para desenvolvimento adicional - pode ser reutilizada na solução de uma variedade de problemas relacionados ao processamento de informações em fluxo. O movimento em pequenas iterações e a cobertura de um processo após o outro permitem que você domine e combine gradualmente várias ferramentas e tecnologias, escolhendo opções comprovadas e abandonando as menos eficazes. Isso é interessante para a equipe de TI e, ao mesmo tempo, ajuda a obter resultados importantes para o gerenciamento e os negócios.