 Parte 1. Sobre a CPUParte 3. Sobre o armazenamento
Parte 1. Sobre a CPUParte 3. Sobre o armazenamentoNeste artigo, falaremos sobre os contadores de desempenho de RAM no vSphere.
Parece que a memória é cada vez mais inequívoca do que com o processador: se houver problemas de desempenho na VM, é difícil não notá-los. Mas se eles aparecerem, lidar com eles é muito mais difícil. Mas as primeiras coisas primeiro.
Pouco de teoria
A RAM das máquinas virtuais é obtida da memória do servidor no qual as VMs estão sendo executadas. Isso é bastante óbvio :). Se a RAM do servidor não for suficiente para todos, o ESXi começará a aplicar técnicas de recuperação de memória. Caso contrário, os sistemas operacionais da VM travariam com erros de acesso à RAM.
Quais técnicas de uso do ESXi decidem dependendo da carga de RAM:
FonteminFree é a RAM necessária para o hypervisor funcionar.
Antes do ESXi 4.1, inclusive, o minFree era corrigido por padrão - 6% da RAM do servidor (a porcentagem podia ser alterada através da opção Mem.MinFreePct no ESXi). Nas versões posteriores, devido ao aumento dos volumes de memória nos servidores minFree, ele começou a ser calculado com base no tamanho da memória do host e não como um valor percentual fixo.
O valor minFree (padrão) é calculado da seguinte maneira:
FontePor exemplo, para um servidor com 128 GB de RAM, o valor MinFree seria:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 MB = 1,88 GB
O valor real pode diferir em algumas centenas de MB, depende do servidor e da RAM.
Normalmente, para estandes produtivos, apenas Alto pode ser considerado normal. Para bancadas de teste e desenvolvimento, condições Clear / Soft podem ser aceitáveis. Se houver menos de 64% de MinFree de RAM restante no host, as VMs em execução nele definitivamente enfrentarão problemas de desempenho.
Em cada estado, certas técnicas de recuperação de memória são aplicadas começando com o TPS, o que praticamente não afeta o desempenho da VM, terminando com Swapping. Vou falar mais sobre eles.
Compartilhamento de página transparente (TPS). O TPS é, grosso modo, a desduplicação das páginas de RAM das máquinas virtuais em um servidor.
O ESXi pesquisa por páginas idênticas da RAM da máquina virtual, contando e comparando a soma de hash de páginas e remove páginas duplicadas, substituindo-as por links para a mesma página na memória física do servidor. Como resultado, o consumo de memória física é reduzido e é possível obter uma nova subscrição de memória com pouca ou nenhuma perda de desempenho.
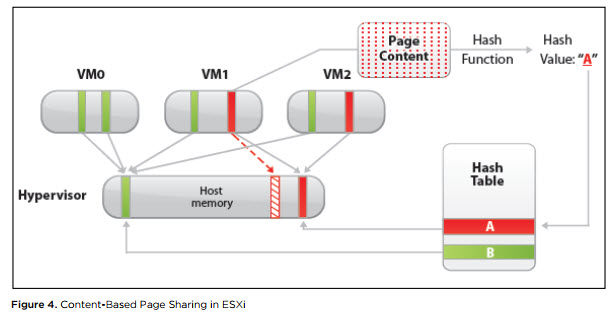 Fonte
FonteEste mecanismo funciona apenas para páginas de 4 kB (páginas pequenas). Páginas com tamanho de 2 MB (páginas grandes), o hipervisor nem tenta deduplicar: a chance de encontrar páginas idênticas desse tamanho não é grande.
Por padrão, o ESXi aloca memória para páginas grandes. A quebra de páginas grandes em pequenas começa quando o limite do estado Alto é atingido e é forçado quando o estado Limpar é atingido (consulte a tabela de estados do hypervisor).
Se você deseja que o TPS comece a trabalhar sem aguardar o preenchimento da RAM do host, nas Opções avançadas ESXi, defina o valor
“Mem.AllocGuestLargePage” como 0 (o padrão é 1). A alocação de páginas grandes de memória para máquinas virtuais será desativada.
Desde dezembro de 2014, em todas as versões do ESXi, o TPS entre VMs foi desativado por padrão, pois foi encontrada uma vulnerabilidade que teoricamente permite acessar a RAM de outra VM a partir de uma VM. Detalhes aqui. Informações sobre a implementação prática da exploração da vulnerabilidade do TPS que não conheci.
A política do TPS é controlada pela opção avançada
“Mem.ShareForceSalting” no ESXi:
0 - TPS entre VMs. O TPS funciona para páginas de diferentes VMs;
1 - TPS para VMs com o mesmo valor “sched.mem.pshare.salt” no VMX;
2 (padrão) - Intra-VM TPS. O TPS funciona para páginas dentro de uma VM.
Definitivamente, faz sentido desativar páginas grandes e ativar o Inter-VM TPS em bancos de teste. Também pode ser usado para estandes com um grande número de VMs do mesmo tipo. Por exemplo, em estandes com VDI, a economia de memória física pode atingir dezenas de por cento.
Balão de memória. O balão não é mais uma técnica tão inofensiva e transparente para o sistema operacional da VM como o TPS. Mas, com o uso adequado do balão, você pode viver e até trabalhar.
Juntamente com o Vmware Tools, um driver especial é instalado na VM, chamado Balloon Driver (também conhecido como vmmemctl). Quando o hipervisor começa a ficar sem memória física e entra no estado Soft, o ESXi solicita à VM que retorne a RAM não utilizada através desse driver de balão. O driver, por sua vez, trabalha no nível do sistema operacional e solicita memória livre dele. O hypervisor vê quais páginas da memória física o Balloon Driver utilizou, pega a memória da máquina virtual e a retorna ao host. Não há problemas com a operação do sistema operacional, pois no nível do sistema operacional a memória é ocupada pelo driver do balão. Por padrão, o Balloon Driver pode ocupar até 65% da memória da VM.
Se o VMware Tools não estiver instalado na VM ou o Ballooning estiver desativado (eu não recomendo, mas há
KB :), o hipervisor muda imediatamente para métodos mais rigorosos de remoção de memória. Conclusão: verifique se o VMware Tools na VM está.
 A operação do driver do balão pode ser verificada no sistema operacional via VMware Tools
A operação do driver do balão pode ser verificada no sistema operacional via VMware Tools .
Compressão de memória Essa técnica é usada quando o ESXi atinge Hard. Como o nome sugere, o ESXi está tentando compactar 4 KB de páginas de RAM para 2 KB e, assim, liberar algum espaço na memória física do servidor. Essa técnica aumenta significativamente o tempo de acesso ao conteúdo das páginas da memória RAM da VM, pois a página deve ser limpa primeiro. Às vezes, nem todas as páginas podem ser compactadas e o processo em si leva algum tempo. Portanto, essa técnica não é muito eficaz na prática.
Troca de memória. Após uma fase curta, o Memory Compression ESXi quase inevitavelmente (se as VMs não foram para outros hosts ou desligaram) passa para Swapping. E se houver muito pouca memória restante (estado baixo), o hipervisor também interromperá a alocação de páginas de memória da VM, o que pode causar problemas nas VMs convidadas.
É assim que o Swapping funciona. Quando você liga a máquina virtual, um arquivo com a extensão .vswp é criado para ela. Em tamanho, é igual à RAM não reservada da VM: esta é a diferença entre a memória configurada e a reservada. Ao trabalhar com troca, o ESXi descarrega as páginas de memória da máquina virtual nesse arquivo e começa a trabalhar com ela em vez da memória física do servidor. Obviamente, essa memória "RAM" é várias ordens de magnitude mais lenta que a memória real, mesmo que .vswp esteja em armazenamento rápido.
Ao contrário do Balonismo, quando páginas não usadas são selecionadas em uma VM, as páginas que são ativamente usadas pelo SO ou aplicativos dentro da VM podem ir para o disco durante a Troca. Como resultado, o desempenho da VM diminui até travar. A VM funciona formalmente e pelo menos pode ser desabilitada corretamente no sistema operacional. Se você for paciente;)
Se as VMs foram para Trocar, é uma situação anormal que é melhor evitar, se possível.
Contadores básicos de desempenho de memória da máquina virtual
Então chegamos à coisa principal. Para monitorar o status da memória na VM, os seguintes contadores estão disponíveis:
Ativo - mostra a quantidade de RAM (Kbytes) à qual a VM obteve acesso no período de medição anterior.
O uso é o mesmo que Ativo, mas como uma porcentagem da memória da VM configurada. É calculado usando a seguinte fórmula: ativo size tamanho da memória configurada da máquina virtual.
Alto uso e ativo, respectivamente, nem sempre são indicativos de problemas de desempenho da VM. Se uma VM usa agressivamente a memória (pelo menos obtém acesso a ela), isso não significa que não há memória suficiente. Pelo contrário, esta é uma ocasião para ver o que está acontecendo no sistema operacional.
Há um alarme padrão no uso de memória para VMs:
 Compartilhada
Compartilhada - a quantidade de RAM em uma VM deduplicada usando o TPS (dentro de uma VM ou entre VMs).
Concedido - a quantidade de memória física do host (Kbytes) fornecida à VM. Inclui compartilhado.
Consumida (concedida - compartilhada) - a quantidade de memória física (Kbytes) que a VM consome do host. Não inclui compartilhado.
Se parte da memória da VM não for alocada a partir da memória física do host, mas do arquivo de permuta ou a memória tiver sido retirada da VM através do Driver Balloon, esse valor não será levado em consideração em Concedido e Consumido.
Valores altos de Concedido e Consumido são perfeitamente normais. O sistema operacional gradualmente retira a memória do hypervisor e não retribui. Com o tempo, com uma VM trabalhando ativamente, os valores desses contadores se aproximam da quantidade de memória configurada e permanecem lá.
Zero - a quantidade de RAM na VM (Kbytes), que contém zeros. Essa memória é considerada hypervisor livre e pode ser fornecida a outras máquinas virtuais. Depois que o SO convidado o recebeu, ele gravou algo na memória nula, vai para Consumido e não retorna.
Sobrecarga reservada - a quantidade de RAM na VM (Kbytes) reservada pelo hypervisor para a VM funcionar. Essa é uma quantidade pequena, mas deve estar disponível no host, caso contrário, a VM não será iniciada.
Balão - a quantidade de RAM (KB) capturada da VM usando o Driver de balão.
Compactado - a quantidade de RAM (KB) que pôde ser compactada.
Trocado - a quantidade de RAM (Kbytes) que, por falta de memória física no servidor, foi movida para o disco.
Os contadores de balão e outras técnicas de recuperação de memória são zero.
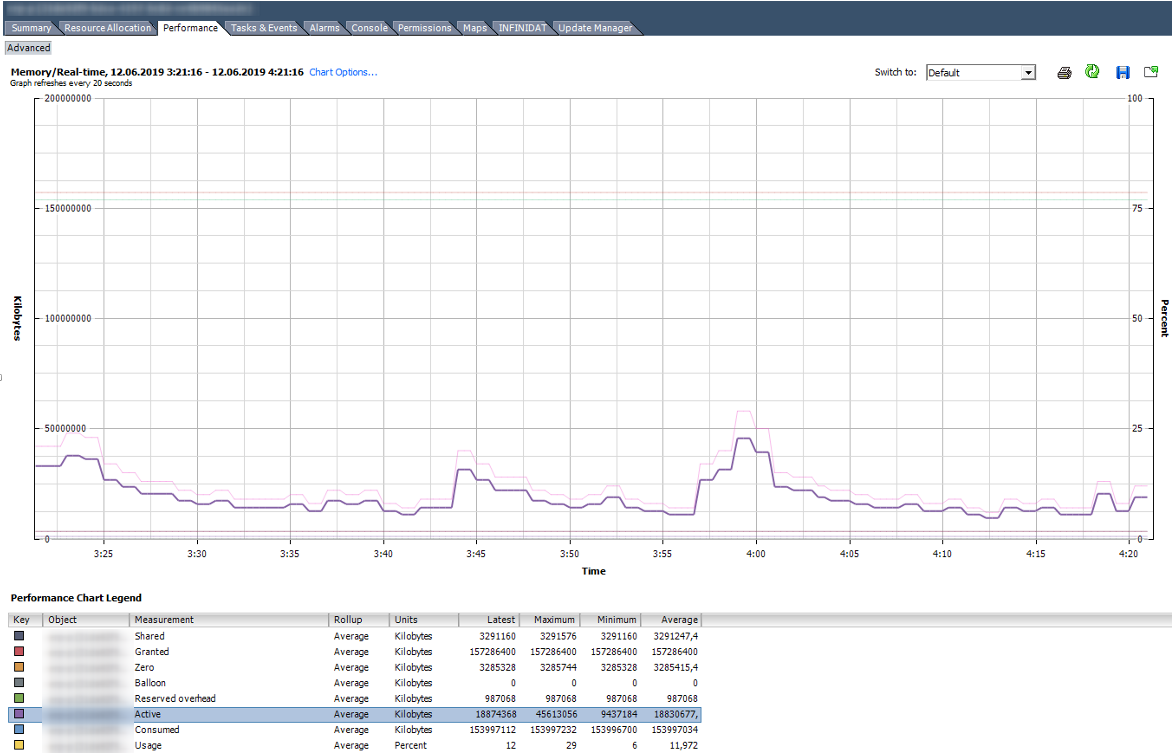
É assim que o gráfico se parece com os contadores de memória de uma VM normalmente funcionando com 150 GB de RAM.
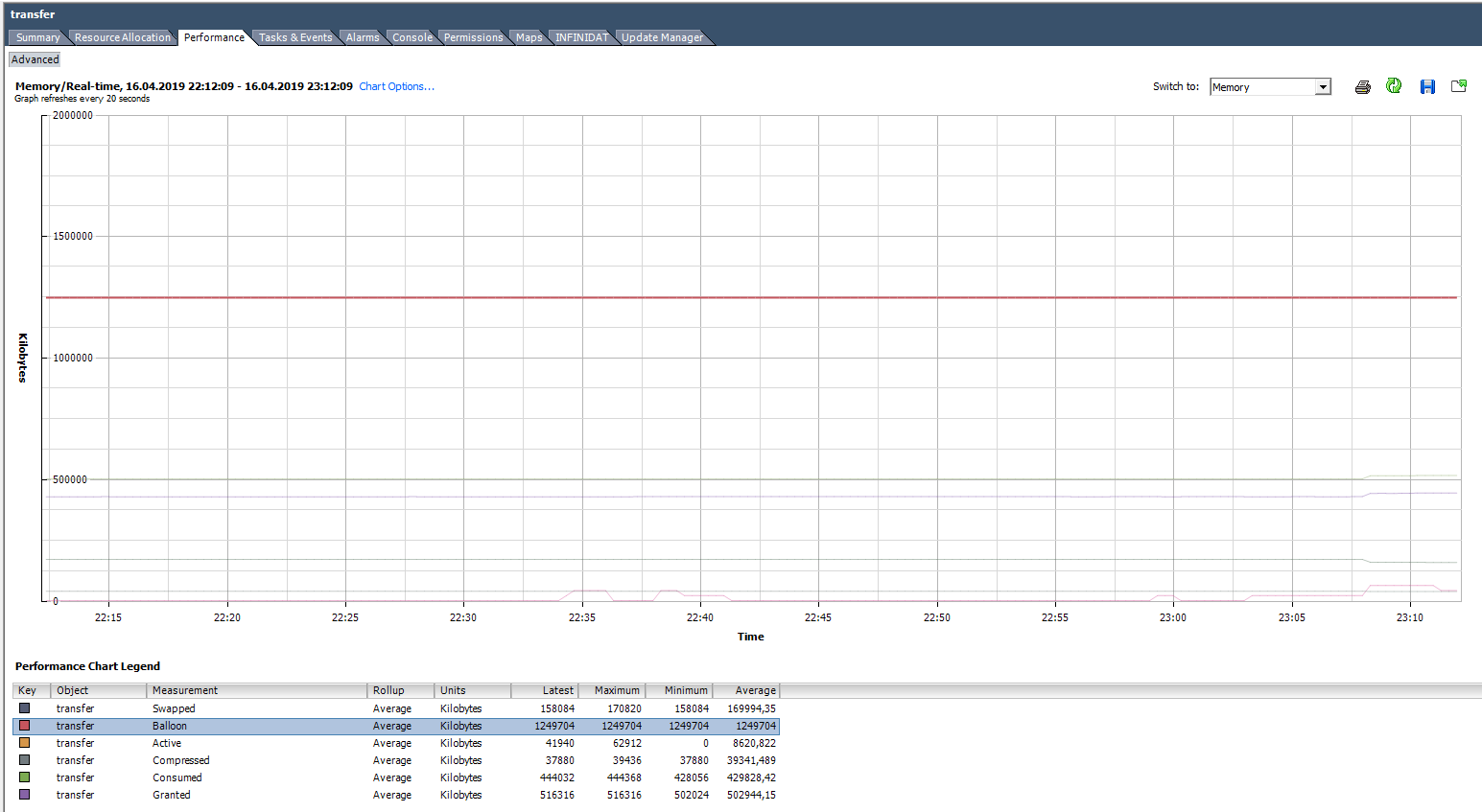
No gráfico abaixo, a VM tem problemas óbvios. O gráfico mostra que para esta VM foram usadas todas as técnicas descritas para trabalhar com RAM. O balão desta VM é muito maior que o Consumido. De fato, a VM provavelmente está mais morta do que viva.
ESXTOP
Assim como na CPU, se você deseja avaliar rapidamente a situação no host, bem como sua dinâmica com um intervalo de até 2 segundos, vale a pena usar o ESXTOP.
A tela ESXTOP Memory é chamada com a tecla “m” e se parece com isso (campos B, D, H, J, K, L, O selecionados):

Os seguintes parâmetros serão interessantes para nós:
Mem overcommit avg - o valor médio da assinatura
excessiva de memória no host por 1, 5 e 15 minutos. Se acima de zero, então é uma ocasião para ver o que acontece, mas nem sempre um indicador da presença de problemas.
Nas linhas
PMEM / MB e
VMKMEM / MB - informações sobre a memória física do servidor e a memória disponível para o VMkernel. A partir do interessante aqui você pode ver o valor minfree (em MB), o estado do host da memória (no nosso caso, alto).
Na linha
NUMA / MB, você pode ver a distribuição da RAM pelos nós NUMA (soquetes). Neste exemplo, a distribuição é desigual, o que, em princípio, não é muito bom.
A seguir, é apresentado um resumo das estatísticas do servidor para técnicas de recuperação de memória:
PSHARE / MB são estatísticas do TPS;
SWAP / MB - estatísticas sobre o uso de Swap;
ZIP / MB - estatísticas de compactação de páginas de memória;
MEMCTL / MB - Estatísticas de uso do driver de balão.
Para VMs individuais, podemos estar interessados nas seguintes informações. Eu escondi os nomes das VMs para não embaraçar o público :). Se a métrica ESXTOP for a mesma do contador no vSphere, cito o contador correspondente.
MEMSZ é a quantidade de memória configurada na VM (MB).
MEMSZ = GRANT + MCTLSZ + SWCUR + intocado.
CONCESSÃO - Concedida em MB.
TCHD - Ativo em MB.
MCTL? - está instalado no VM Balloon Driver.
MCTLSZ - Balão em MB.
MCTLGT é a quantidade de RAM (MB) que o ESXi deseja remover da VM por meio do driver de balão (Memctl Target).
MCTLMAX - a quantidade máxima de RAM (MB) que o ESXi pode remover da VM através do driver de balão.
SWCUR - a quantidade atual de RAM (MB) fornecida à VM a partir do arquivo Swap.
SWGT - a quantidade de RAM (MB) que o ESXi deseja fornecer às VMs de um arquivo de troca (destino de troca).
Também através do ESXTOP, você pode ver informações mais detalhadas sobre a topologia da NUMA VM. Para fazer isso, selecione os campos D, G:
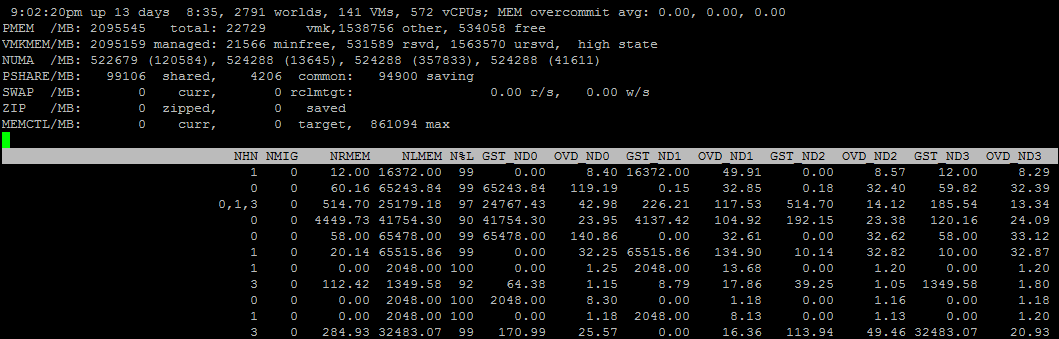
Nós
NHN - NUMA nos quais a VM está localizada. Aqui você pode notar imediatamente uma ampla vm que não se encaixa em um nó NUMA.
NRMEM - quantos megabytes de memória a VM retira do nó NUMA remoto.
NLMEM - quantos megabytes de memória a VM retira do nó NUMA local.
N% L - porcentagem de memória da VM no nó NUMA local (se for menor que 80%, podem ocorrer problemas de desempenho).
Memória no hypervisor
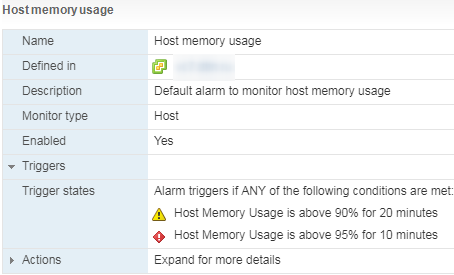
Se os contadores de CPU no hipervisor geralmente não são de interesse especial, a situação é o oposto na memória. Um alto uso de memória na VM nem sempre indica um problema de desempenho, mas um alto uso de memória no hipervisor apenas inicia o técnico de gerenciamento de memória e causa problemas com o desempenho da VM. Os alarmes de uso da memória do host devem ser monitorados e as VMs não podem entrar no Swap.
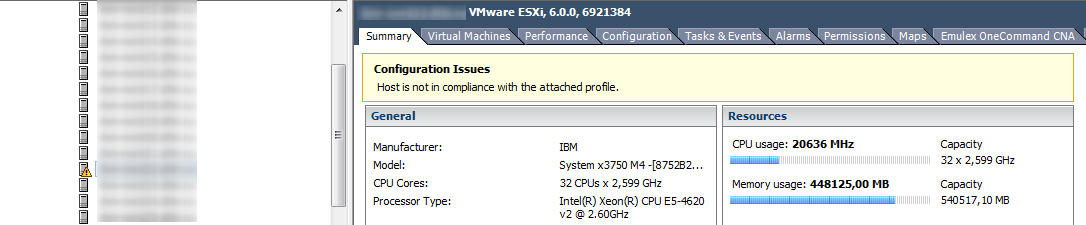
Desfazer trocas
Se a VM entrou no Swap, seu desempenho é bastante reduzido. Os traços de balão e compactação desaparecem rapidamente após o aparecimento de RAM livre no host, mas a máquina virtual não tem pressa em retornar do Swap para a RAM do servidor.
Antes do ESXi 6.0, a única maneira rápida e confiável de tirar as VMs do Swap era pela reinicialização (mais precisamente, desligando / ligando o contêiner). A partir do ESXi 6.0, apareceu uma maneira não tão oficial, mas funcional e confiável de tirar VMs do Swap. Em uma das conferências, consegui conversar com um dos engenheiros da VMware responsável pelo CPU Scheduler. Ele confirmou que o método é bastante funcional e seguro. Em nossa experiência, problemas com ele também não foram percebidos.
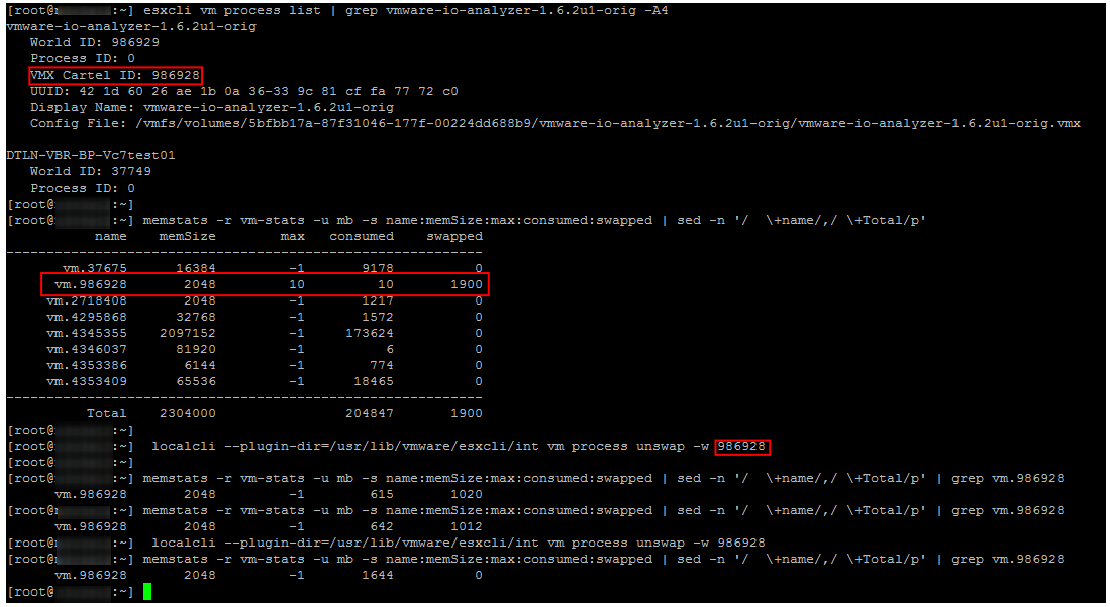
Os comandos reais para a saída de VMs do Swap foram
descritos por Duncan Epping. Não repetirei a descrição detalhada, apenas dê um exemplo de seu uso. Como pode ser visto na captura de tela, algum tempo após a execução dos comandos Swap especificados na VM desaparece.
Dicas para gerenciar RAM no ESXi
Concluindo, darei algumas dicas para ajudar a evitar problemas com o desempenho da VM devido à RAM:
- Evite o excesso de inscrições na RAM em clusters produtivos. É sempre aconselhável ter ~ 20 a 30% de memória livre no cluster, para que o DRS (e o administrador) tenha espaço de manobra e as VMs não sejam trocadas durante a migração. Também não esqueça a margem para tolerância a falhas. É desagradável quando, quando um servidor falha e a VM é reinicializada usando HA, algumas das máquinas também vão para Swap.
- Em infraestruturas altamente consolidadas, tente NÃO criar VMs com mais da metade da memória do host. Isso, novamente, ajudará o DRS a distribuir máquinas virtuais entre os servidores de cluster sem problemas. Esta regra, é claro, não é universal :).
- Cuidado com o alarme de uso de memória do host.
- Não se esqueça de colocar o VMware Tools na VM e não desative o balão.
- Considere ativar o TPS entre VMs e desativar páginas grandes em ambientes de teste e VDI.
- Se a VM estiver com problemas de desempenho, verifique se está usando memória de um nó NUMA remoto.
- Tire VMs do Swap o mais rápido possível! Entre outras coisas, se a VM estiver em Swap, por razões óbvias, o sistema de armazenamento sofre.
Isso é tudo para RAM. Abaixo estão artigos relacionados para quem deseja se aprofundar nos detalhes.
O próximo artigo será dedicado à história.