Artigos sobre visão computacional, interpretabilidade, PNL - visitamos a conferência AISTATS no Japão e queremos compartilhar uma visão geral dos artigos. Esta é uma grande conferência sobre estatística e aprendizado de máquina, e este ano será realizada em Okinawa, uma ilha perto de Taiwan. Neste post, Yulia Antokhina ( Yulia_chan ) preparou uma descrição dos artigos brilhantes da seção principal; no próximo, juntamente com Anna Papeta, ela falará sobre os relatórios de palestrantes convidados e estudos teóricos. Também falaremos um pouco sobre como a própria conferência ocorreu e sobre o Japão "não japonês". Defesa contra ataques adversos do Whitebox via discretização aleatória
Defesa contra ataques adversos do Whitebox via discretização aleatóriaYuchen Zhang (Microsoft); Percy Liang (Universidade de Stanford)
→
Artigo→
CódigoVamos começar com um artigo sobre proteção contra ataques adversários na visão computacional. Estes são ataques direcionados a modelos, quando o objetivo do ataque é cometer um erro, até um resultado predeterminado. Algoritmos de visão computacional podem ser confundidos, mesmo com pequenas alterações na imagem original de uma pessoa. A tarefa é relevante, por exemplo, para a visão de máquina, que em boas condições reconhece os sinais de trânsito mais rapidamente que uma pessoa, mas funciona muito pior durante os ataques.
Ataque adversário claramente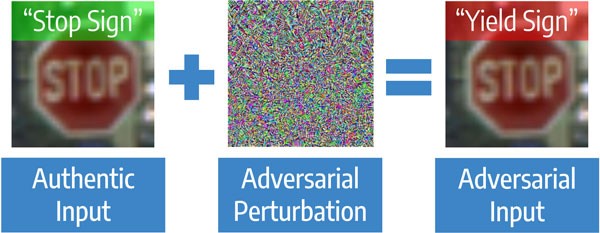
Os ataques são Blackbox - quando o invasor não sabe nada sobre o algoritmo, e o Whitebox é a situação inversa. Existem duas abordagens principais para proteger modelos. A primeira abordagem é treinar o modelo em fotos regulares e "atacadas" - é chamado de treinamento antagônico. Essa abordagem funciona bem em imagens pequenas como MNIST, mas há artigos que mostram que ela não funciona bem em imagens grandes como o ImageNet. O segundo tipo de proteção não requer reciclagem do modelo. Basta pré-processar a imagem antes de enviá-la ao modelo. Exemplos de conversões: compactação JPEG, redimensionamento. Esses métodos exigem menos computação, mas agora funcionam apenas contra ataques do Blackbox, pois se a conversão for conhecida, o oposto poderá ser aplicado.
MétodoNo artigo, os autores propõem um método que não requer overtraining do modelo e funciona para ataques do Whitebox. O objetivo é reduzir a distância Kullback - Leibner entre exemplos comuns e exemplos "mimados" usando uma transformação aleatória. Acontece que basta adicionar ruído aleatório e, em seguida, amostrar aleatoriamente as cores. Ou seja, uma qualidade de imagem "prejudicada" é alimentada na entrada do algoritmo, mas ainda é suficiente para o algoritmo funcionar. E devido ao acaso, existe o potencial de suportar ataques do Whitebox.
À esquerda, a imagem original; no meio, um exemplo de agrupamento de cores de pixel no espaço do laboratório; à direita, uma imagem em várias cores (por exemplo, em vez de 40 tons de azul - um) Resultados
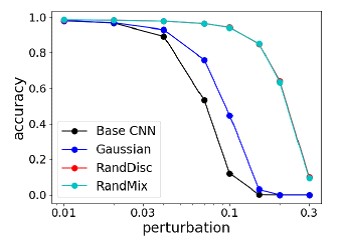
ResultadosEsse método foi comparado aos ataques mais fortes da competição NIPS 2017 Adversarial Attacks & Defenses, e mostra em média a melhor qualidade e não é treinado novamente no "atacante".
Comparação dos métodos de defesa mais fortes contra os ataques mais fortes à competição NIPS Comparação da precisão dos métodos no MNIST com diferentes alterações de imagem
Comparação da precisão dos métodos no MNIST com diferentes alterações de imagem
 Viés atenuante em vetores do Word
Viés atenuante em vetores do WordSunipa Dev (Universidade de Utah); Jeff Phillips (Universidade de Utah)
→
ArtigoA palestra “na moda” foi sobre vetores de palavras não tendenciosos. Nesse caso, Viés significa preconceito por gênero ou nacionalidade nas representações das palavras. Qualquer órgão regulador pode se opor a essa "discriminação" e, portanto, cientistas da Universidade de Utah decidiram estudar a possibilidade de "equalização de direitos" para a PNL. De fato, por que um homem não pode ser "glamouroso" e uma mulher um "cientista de dados"?
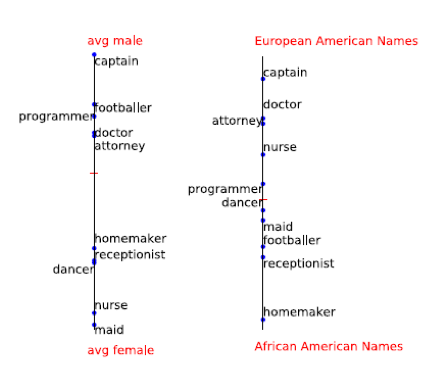
Original - o resultado que está sendo obtido agora, o resto - os resultados do algoritmo imparcial

O artigo discute um método para encontrar esse viés. Eles decidiram que gênero e nacionalidade são bem caracterizados por nomes. Portanto, se você encontrar o deslocamento pelo nome e subtraí-lo, provavelmente poderá se livrar do viés do algoritmo.
Um exemplo de palavras mais "masculinas" e "femininas":
 Nomes para encontrar compensações de gênero:
Nomes para encontrar compensações de gênero:
Curiosamente, um método tão simples funciona. Os autores treinaram uma luva imparcial e foram apresentados no Git.
O que fez você fazer isso? Entendendo decisões de caixa preta com subconjuntos de entrada suficientesBrandon Carter (MIT CSAIL); Jonas Mueller (Amazon Web Services); Sidarta Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→
Artigo→
Codifique uma e
duas vezesO artigo a seguir fala sobre o algoritmo Sufficient Input Subset. SIS são os subconjuntos mínimos de recursos nos quais o modelo produzirá um determinado resultado, mesmo se todos os outros recursos forem redefinidos. Essa é outra maneira de interpretar os resultados de modelos complexos. Trabalha em textos e imagens.
Algoritmo de pesquisa do SIS em detalhes: Exemplo de aplicação no texto com críticas sobre cerveja:
Exemplo de aplicação no texto com críticas sobre cerveja: Exemplo de aplicação no MNIST:
Exemplo de aplicação no MNIST: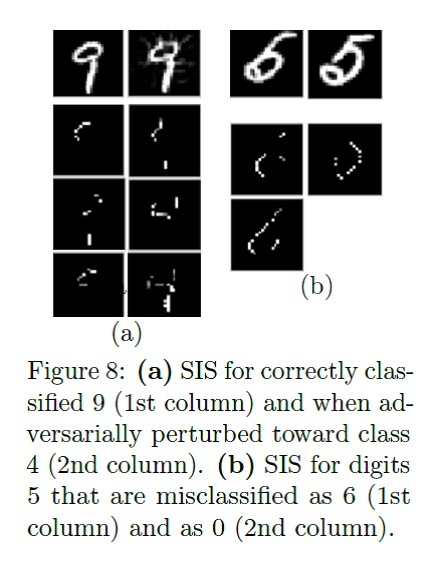 Comparação dos métodos de "interpretação" da distância Kullback - Leibler em relação ao resultado "ideal":
Comparação dos métodos de "interpretação" da distância Kullback - Leibler em relação ao resultado "ideal":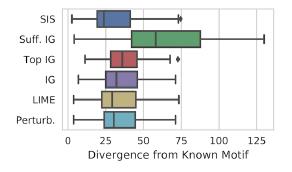
Os recursos são classificados primeiro pelo impacto no modelo e, em seguida, divididos em subconjuntos disjuntos, começando pelos mais influentes. Funciona com força bruta e, em um conjunto de dados rotulado, o resultado interpreta melhor que LIME. Existe uma implementação conveniente da pesquisa SIS do Google Research.
Minimização empírica de riscos e descida estocástica de gradiente para dados relacionaisVictor Veitch (Universidade de Columbia); Morgane Austern (Universidade de Columbia); Wenda Zhou (Universidade de Columbia); David Blei (Universidade de Columbia); Peter Orbanz (Universidade Columbia)
→
Artigo→
CódigoNa seção de otimização, houve um relatório sobre Minimização Empírica de Riscos, onde os autores exploraram maneiras de aplicar a descida do gradiente estocástico nos gráficos. Por exemplo, ao criar um modelo em dados de redes sociais, você pode usar apenas recursos fixos do perfil (o número de assinantes), mas as informações sobre as conexões entre os perfis (aos quais está inscrito) são perdidas. Além disso, o gráfico inteiro geralmente é difícil de processar - por exemplo, não cabe na memória. Quando essa situação ocorre em dados tabulares, o modelo pode ser executado em subamostras. E como escolher o análogo da subamostra no gráfico não ficou claro. Os autores fundamentaram teoricamente a possibilidade de usar subgráficos aleatórios como um análogo de subamostras, e isso acabou sendo "Não é uma idéia maluca". Existem exemplos reproduzíveis do artigo no Github, incluindo o exemplo da Wikipedia.
Categoria Incorporação nos dados da “Wikipedia”, levando em consideração sua estrutura gráfica, os artigos selecionados são os que mais se aproximam do tópico “Físicos franceses”: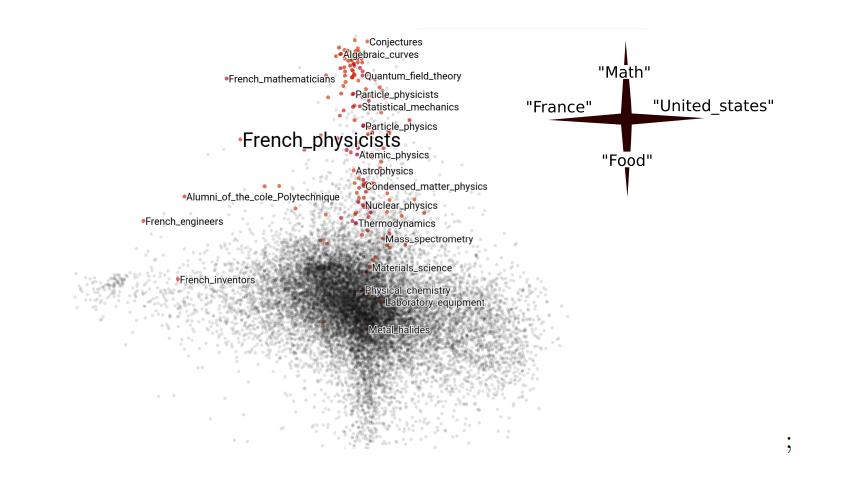
→
Ciência de dados para dados em redeOs gráficos de dados discretos foram outro relatório de revisão da Data Science for Networked Data do palestrante convidado Poling Loh (Universidade de Wisconsin-Madison). A apresentação abordou os tópicos de inferência estatística, alocação de recursos, algoritmos locais. Na inferência estatística, por exemplo, tratava-se de como entender a estrutura do gráfico sobre os dados sobre doenças infecciosas. É proposto o uso de estatísticas sobre o número de conexões entre nós infectados - e o teorema é comprovado para o teste estatístico correspondente.
Em geral, o relatório é mais interessante de assistir, provavelmente, para aqueles que não estão envolvidos em modelos de gráficos, mas gostariam de tentar e estão interessados em como testar corretamente hipóteses para gráficos.
Como foi a conferênciaAISTATS 2019 é uma conferência de três dias em Okinawa. Este é o Japão, mas a cultura de Okinawa está mais próxima da China. A principal rua comercial é uma reminiscência de uma Miami tão pequena, há carros compridos nas ruas, música country e você fica um pouco ao lado - uma selva com cobras, manguezais retorcidos por tufões. O sabor local é criado pela cultura de Ryukyu - um reino localizado em Okinawa, mas primeiro se tornou um parceiro comercial e vassalo da China e depois foi capturado pelos japoneses.
E em Okinawa, aparentemente, eles costumam realizar casamentos, porque existem muitos salões de casamento, e a conferência foi realizada nas instalações do Wedding Hall.
Mais de 500 pessoas reuniram cientistas, autores de artigos, ouvintes e palestrantes. Em três dias você pode ter tempo para conversar com quase todo mundo. Embora a conferência tenha sido realizada "nos confins do mundo" - representantes de todo o mundo chegaram. Apesar da ampla geografia, os interesses de todos nós são semelhantes. Foi uma surpresa para nós, por exemplo, que cientistas da Austrália resolvessem os mesmos problemas de ciência de dados e os mesmos métodos que nós em nossa equipe. Mas, afinal, vivemos em lados quase opostos do planeta ... Não havia tantos participantes do setor: Google, Amazon, MTS e várias outras empresas importantes.
Havia representantes de empresas patrocinadoras japonesas, que na maioria das vezes assistiam e ouviam e, provavelmente, procuravam alguém, apesar do fato de os “não japoneses” serem muito difíceis de trabalhar no Japão.
Artigos submetidos à conferência sobre os tópicos:
Tudo o resto está em nosso próximo post. Não perca!
Anúncio: