Olá Habr! Apresento a você a tradução gratuita do “Guide to app architecture” do
JetPack . Peço que você deixe todos os comentários sobre a tradução nos comentários, e eles serão corrigidos. Além disso, comentários daqueles que usaram a arquitetura apresentada com recomendações para seu uso serão úteis para todos.
Este guia aborda as práticas recomendadas e a arquitetura recomendada para a criação de aplicativos robustos. Esta página pressupõe uma introdução básica ao Android Framework. Se você é novo no desenvolvimento de aplicativos Android, consulte nossos
guias para
desenvolvedores para começar e aprender mais sobre os conceitos mencionados neste guia. Se você estiver interessado em arquitetura de aplicativos e quiser se familiarizar com os materiais deste guia em termos de programação no Kotlin, consulte o curso Udacity,
"Desenvolvendo aplicativos para Android com Kotlin" .
Experiência do usuário de aplicativos para dispositivos móveis
Na maioria dos casos, os aplicativos de área de trabalho têm um único ponto de entrada na área de trabalho ou no iniciador e, em seguida, são executados como um único processo monolítico. Os aplicativos Android têm uma estrutura muito mais complexa. Um aplicativo Android típico contém vários
componentes de aplicativos , incluindo
Atividades ,
Fragmentos ,
Serviços ,
ContentProviders e
BroadcastReceivers .
Você declara todos ou alguns desses componentes do aplicativo no
manifesto do aplicativo. O Android usa esse arquivo para decidir como integrar seu aplicativo à interface de usuário comum do dispositivo. Como um aplicativo Android bem escrito contém vários componentes, e os usuários geralmente interagem com vários aplicativos em um curto período de tempo, os aplicativos devem se adaptar a diferentes tipos de fluxos de trabalho e tarefas orientadas ao usuário.
Por exemplo, considere o que acontece quando você compartilha uma foto em seu aplicativo de mídia social favorito:
- O aplicativo aciona a intenção da câmera. O Android inicia um aplicativo de câmera para processar a solicitação. No momento, o usuário deixou o aplicativo para redes sociais e sua experiência como usuário é impecável.
- Um aplicativo de câmera pode acionar outras intenções, como iniciar um seletor de arquivos, que pode iniciar outro aplicativo.
- No final, o usuário retorna ao aplicativo de rede social e compartilha a foto.
A qualquer momento do processo, o usuário pode ser interrompido por uma ligação ou notificação. Após a ação associada a essa interrupção, o usuário espera poder retornar e retomar esse processo de compartilhamento de fotos. Esse comportamento de troca de aplicativos é comum em dispositivos móveis, portanto, seu aplicativo deve lidar corretamente com esses pontos (tarefas).
Lembre-se de que os dispositivos móveis também têm recursos limitados; portanto, a qualquer momento, o sistema operacional pode destruir alguns processos de aplicativos, a fim de liberar espaço para novos.
Dadas as condições desse ambiente, os componentes do seu aplicativo podem ser iniciados individualmente e não em ordem, e o sistema operacional ou o usuário pode destruí-los a qualquer momento. Como esses eventos não estão sob seu controle,
você não deve armazenar dados ou estados nos componentes do aplicativo e os componentes do aplicativo não devem depender um do outro.
Princípios gerais de arquitetura
Se você não deve usar componentes do aplicativo para armazenar dados e estado do aplicativo, como deve desenvolver seu aplicativo?
Divisão de responsabilidade
O princípio mais importante a seguir é
o compartilhamento de responsabilidades . Um erro comum é quando você escreve todo o seu código em
Atividade ou
Fragmento . Essas são classes de interface do usuário que devem conter apenas lógica processando a interação da interface com o usuário e do sistema operacional. Ao compartilhar a responsabilidade o máximo possível nessas classes
(SRPs) , você pode evitar muitos dos problemas associados ao ciclo de vida do aplicativo.
Controle de interface do usuário do modelo
Outro princípio importante é que você deve
controlar sua interface com o usuário a partir de um modelo , de preferência de um modelo permanente. Modelos são os componentes responsáveis pelo processamento dos dados para o aplicativo. Eles são independentes dos objetos
View e dos componentes do aplicativo, portanto, não são afetados pelo ciclo de vida do aplicativo e pelos problemas relacionados.
Um modelo permanente é ideal pelos seguintes motivos:
- Seus usuários não perderão dados se o sistema operacional Android destruir seu aplicativo para liberar recursos.
- Seu aplicativo continua funcionando quando a conexão de rede está instável ou indisponível.
Ao organizar a base do seu aplicativo em classes de modelo com uma responsabilidade claramente definida pelo gerenciamento de dados, seu aplicativo se torna mais testável e suportado.
Arquitetura de aplicativo recomendada
Esta seção demonstra como estruturar um aplicativo usando
componentes de arquitetura , trabalhando em um
cenário de uso de ponta a ponta .
Nota Não é possível ter uma maneira de escrever aplicativos que funcionem melhor para cada cenário. No entanto, a arquitetura recomendada é um bom ponto de partida para a maioria das situações e fluxos de trabalho. Se você já possui uma boa maneira de escrever aplicativos Android que atendam aos princípios gerais de arquitetura, não deve alterá-lo.Imagine que estamos criando uma interface de usuário que exibe um perfil de usuário. Usamos uma API privada e uma API REST para recuperar dados do perfil.
Revisão
Para começar, considere o esquema de interação dos módulos da arquitetura do aplicativo finalizado:
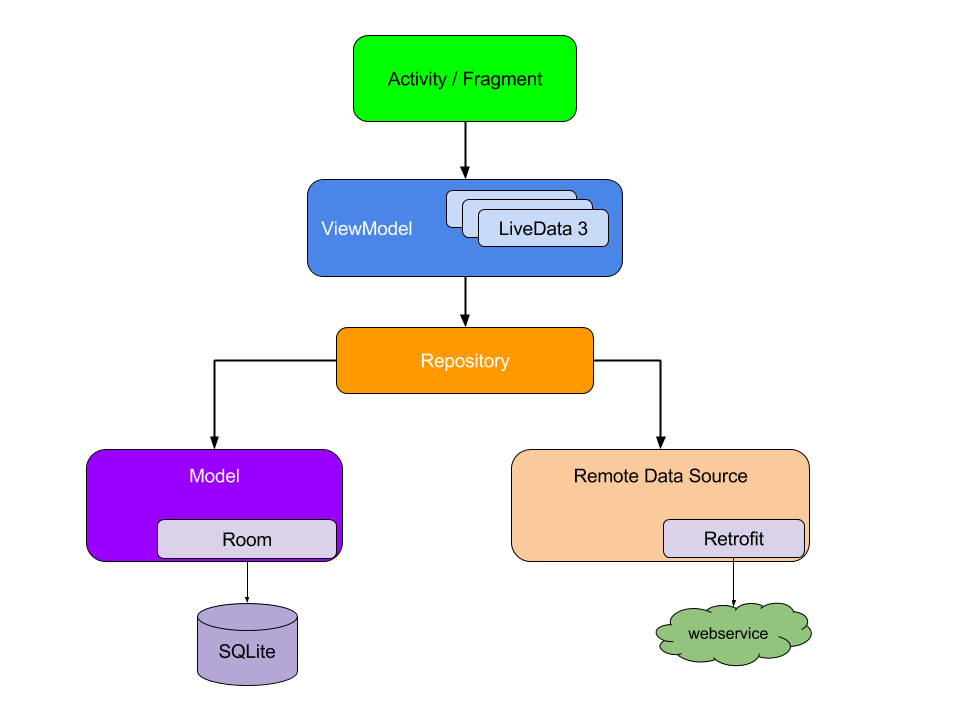
Observe que cada componente depende apenas do componente um nível abaixo dele. Por exemplo, Atividade e Fragmentos dependem apenas do modelo de exibição. Repositório é a única classe que depende de muitas outras classes; neste exemplo, o armazenamento depende de um modelo de dados persistente e de uma fonte de dados interna remota.
Esse padrão de design cria uma experiência do usuário consistente e agradável. Independentemente de o usuário retornar ao aplicativo alguns minutos depois de fechá-lo ou alguns dias depois, ele verá instantaneamente as informações do usuário de que o aplicativo foi salvo localmente. Se esses dados estiverem desatualizados, o módulo de armazenamento do aplicativo começará a atualizar os dados em segundo plano.
Crie uma interface de usuário
A interface do usuário consiste no fragmento
UserProfileFragment e no
user_profile_layout.xml layout
user_profile_layout.xml correspondente.
Para gerenciar a interface do usuário, nosso modelo de dados deve conter os seguintes elementos de dados:
- ID do usuário : ID do usuário. A melhor solução é passar essas informações para o fragmento usando os argumentos do fragmento. Se o sistema operacional Android destruir nosso processo, essas informações serão salvas, para que o identificador fique disponível na próxima vez que iniciarmos nosso aplicativo.
- Objeto de usuário: uma classe de dados que contém informações do usuário.
Usamos um
UserProfileViewModel baseado em um componente da arquitetura ViewModel para armazenar essas informações.
O objeto ViewModel fornece dados para um componente específico da interface com o usuário, como fragmento ou Atividade, e contém lógica de processamento de dados corporativos para interagir com o modelo. Por exemplo, o ViewModel pode chamar outros componentes para carregar dados e encaminhar solicitações de usuário para alterações de dados. O ViewModel não conhece os componentes da interface do usuário e, portanto, não é afetado por alterações na configuração, como recriar Activity quando o dispositivo é girado.Agora, identificamos os seguintes arquivos:
user_profile.xml : layout da interface do usuário definido.UserProfileFragment : descreveu um controlador de interface do usuário responsável por exibir informações ao usuário.UserProfileViewModel : uma classe responsável por preparar os dados para exibi-los em UserProfileFragment e responder à interação do usuário.
Os seguintes trechos de código mostram o conteúdo inicial desses arquivos. (O arquivo de layout é omitido por simplicidade.)
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } class UserProfileFragment : Fragment() { private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } }
Agora que temos esses módulos de código, como os conectamos? Depois que o campo do usuário é definido na classe UserProfileViewModel, precisamos de uma maneira de informar a interface do usuário.
Nota SavedStateHandle permite que o ViewModel acesse o estado salvo e os argumentos do fragmento ou ação associado.
Agora precisamos informar nosso fragmento quando o objeto de usuário for recebido. É aqui que o componente da arquitetura LiveData aparece.
LiveData é um detentor de dados observável. Outros componentes em seu aplicativo podem rastrear alterações nos objetos usando esse suporte, sem criar caminhos explícitos e difíceis de dependência entre eles. O componente LiveData também leva em consideração o estado do ciclo de vida dos componentes do seu aplicativo, como Atividades, Fragmentos e Serviços, e inclui lógica de limpeza para evitar vazamento de objetos e consumo excessivo de memória.
Nota Se você já usa bibliotecas como RxJava ou Agera, pode continuar a usá-las em vez do LiveData. No entanto, ao usar bibliotecas e abordagens semelhantes, lembre-se de lidar adequadamente com o ciclo de vida do seu aplicativo. Em particular, verifique se você suspendeu seus fluxos de dados quando o LifecycleOwner associado for parado e destrua esses fluxos quando o LifecycleOwner associado tiver sido destruído. Você também pode adicionar o artefato android.arch.lifecycle: jet streams para usar o LiveData com outra biblioteca de jet stream, como RxJava2.Para incluir o componente LiveData em nosso aplicativo, alteramos o tipo de campo em
UserProfileViewModel para LiveData.
UserProfileFragment agora
UserProfileFragment informado sobre atualizações de dados. Além disso, como esse campo do
LiveData suporta o ciclo de vida, ele limpa automaticamente os links quando não são mais necessários.
class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() }
Agora, modificamos o
UserProfileFragment para observar os dados no
ViewModel e atualizar a interface do usuário de acordo com as alterações:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) {
Sempre que os dados do perfil do usuário são atualizados, o retorno de chamada
onChanged () é chamado e a interface do usuário é atualizada.
Se você estiver familiarizado com outras bibliotecas que usam retornos de chamada observáveis, talvez tenha percebido que não redefinimos o método
onStop () do fragmento para interromper a observação dos dados. Esta etapa é opcional para o LiveData, pois suporta o ciclo de vida, o que significa que ele não chamará o retorno de chamada
onChanged() se o fragmento estiver em um estado inativo; isto é, ele recebeu uma ligação para
onStart () , mas ainda não recebeu
onStop() ). O LiveData também remove automaticamente o observador ao chamar o método
onDestroy () no fragmento.
Não adicionamos nenhuma lógica para lidar com as alterações na configuração, como girar a tela do dispositivo pelo usuário.
UserProfileViewModel restaurado automaticamente quando a configuração é alterada. Assim que um novo fragmento é criado, ele recebe a mesma instância do
ViewModel e o retorno de chamada é chamado imediatamente usando os dados atuais. Como os objetos
ViewModel são projetados para sobreviver aos objetos
View correspondentes que eles atualizam, você não deve incluir referências diretas aos objetos
View na sua implementação do ViewModel. Para obter mais informações sobre a vida útil do
ViewModel corresponde ao ciclo de vida dos componentes da interface do usuário, consulte
Ciclo de vida do ViewModel.Recuperação de dados
Agora que usamos o LiveData para conectar o
UserProfileViewModel ao
UserProfileFragment , como podemos obter dados do perfil do usuário?
Neste exemplo, assumimos que nosso back-end fornece uma API REST. Usamos a biblioteca Retrofit para acessar nosso back-end, embora você possa usar uma biblioteca diferente que atenda ao mesmo objetivo.
Aqui está a nossa definição de um serviço da
Webservice vinculado ao nosso back-end:
interface Webservice { @GET("/users/{user}") fun getUser(@Path("user") userId: String): Call<User> }
Uma primeira idéia para implementar um
ViewModel pode envolver chamar o serviço da
Webservice para recuperar os dados e atribuí-
LiveData ao nosso objeto
LiveData . Esse design funciona, mas usá-lo torna nosso aplicativo mais difícil de manter à medida que cresce. Isso atribui muita responsabilidade à classe
UserProfileViewModel , que viola o princípio da
separação de interesses . Além disso, o escopo do ViewModel está associado ao ciclo de vida da
Atividade ou
Fragmento , o que significa que os dados do serviço da
Webservice perdidos quando o ciclo de vida do objeto da interface do usuário associado termina. Esse comportamento cria uma experiência indesejável para o usuário.
Em vez disso, nosso
ViewModel delega o processo de recuperação de dados para um novo módulo de armazenamento.
Os módulos de repositório lidam com operações de dados. Eles fornecem uma API limpa para que o restante do aplicativo possa obter esses dados com facilidade. Eles sabem de onde obter os dados e o que a API chama para fazer ao atualizar os dados. Você pode pensar nos repositórios como intermediários entre diferentes fontes de dados, como modelos persistentes, serviços da web e caches.Nossa classe
UserRepository , mostrada no seguinte trecho de código, usa uma instância do
WebService para recuperar dados do usuário:
class UserRepository { private val webservice: Webservice = TODO()
Embora o módulo de armazenamento pareça desnecessário, ele serve a um propósito importante: abstrai as fontes de dados do restante do aplicativo. Agora, nosso
UserProfileViewModel não sabe recuperar dados, para que possamos fornecer aos modelos de apresentação dados obtidos de várias implementações diferentes de extração de dados.
Nota Perdemos o caso de erros de rede por simplicidade. Para uma implementação alternativa que expõe erros e status de download, consulte o Apêndice: Divulgação do status da rede.
Gerenciando dependências entre componentesA classe
UserRepository acima precisa de uma instância do
Webservice para recuperar dados do usuário. Ele poderia apenas criar uma instância, mas para isso ele também precisa conhecer as dependências da classe de serviço da
Webservice . Além disso,
UserRepository provavelmente não é a única classe que precisa de um serviço da web. Essa situação exige a duplicação do código, pois toda classe que precisa de um link para o serviço da
Webservice precisa saber como criá-lo e suas dependências. Se cada classe criar um novo
WebService , nosso aplicativo poderá se tornar muito intensivo em recursos.
Para resolver esse problema, você pode usar os seguintes padrões de design:
- Injeção de Dependência (DI) . A injeção de dependência permite que as classes definam suas dependências sem criá-las. Em tempo de execução, outra classe é responsável por fornecer essas dependências. Recomendamos a biblioteca Dagger 2 para implementar a injeção de dependência em aplicativos Android. O Dagger 2 cria automaticamente objetos, ignorando a árvore de dependências e fornece garantias em tempo de compilação para dependências.
- (Local do serviço) Localizador de serviço : O modelo do localizador de serviço fornece um registro no qual as classes podem obter suas dependências em vez de construí-las.
A implementação de um registro de serviço é mais fácil do que usar o DI; portanto, se você é novo no DI, use o modelo: localização do serviço.
Esses modelos permitem escalar seu código porque fornecem modelos claros para gerenciar dependências sem duplicar ou complicar o código. Além disso, esses modelos permitem alternar rapidamente entre implementações de teste e produção de amostragem de dados.
Nosso aplicativo de amostra usa o
Dagger 2 para gerenciar as dependências do objeto
Webservice .
Conecte o ViewModel e armazenamento
Agora modificamos nosso
UserProfileViewModel para usar o objeto
UserRepository :
class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = userRepository.getUser(userId) }
Armazenamento em cache
A implementação
UserRepository abstrai a chamada do objeto
Webservice , mas como conta apenas com uma fonte de dados, não é muito flexível.
O principal problema com a implementação do
UserRepository é que, depois de receber dados do nosso back-end, esses dados não são armazenados em nenhum lugar. Portanto, se o usuário sair do
UserProfileFragment e retornar a ele, nosso aplicativo deverá recuperar os dados, mesmo que eles não tenham sido alterados.
Esse design não é ideal pelos seguintes motivos:
- Gasta recursos valiosos de tráfego.
- Isso faz com que o usuário aguarde a conclusão de uma nova solicitação.
Para resolver essas deficiências, adicionamos uma nova fonte de dados ao nosso
UserRepository , que armazena em cache objetos de
User na memória:
Dados persistentes
Usando nossa implementação atual, se o usuário girar o dispositivo ou sair e retornar imediatamente ao aplicativo, a interface do usuário existente ficará imediatamente visível, porque a loja recupera dados do nosso cache na memória.
No entanto, o que acontece se um usuário sair do aplicativo e retornar algumas horas depois que o sistema operacional Android concluir o processo? Contando com nossa implementação atual nessa situação, precisamos obter dados da rede novamente. Esse processo de atualização não é apenas uma experiência ruim para o usuário; também é um desperdício porque consome dados móveis valiosos.
Você pode resolver esse problema armazenando em cache solicitações da Web, mas isso cria um novo problema importante: o que acontece se os mesmos dados do usuário são exibidos em um tipo diferente de solicitação, por exemplo, ao receber uma lista de amigos? O aplicativo exibirá dados conflitantes, o que é confuso na melhor das hipóteses. Por exemplo, nosso aplicativo pode exibir duas versões diferentes dos dados do mesmo usuário se o usuário enviou uma solicitação de lista de amigos e uma solicitação de usuário único em momentos diferentes. Nosso aplicativo precisaria descobrir como combinar esses dados conflitantes.
A maneira correta de lidar com essa situação é usar um modelo constante. A Biblioteca de Dados Permanentes da
Sala (DB) vem em nosso auxílio.
Room é uma biblioteca de mapeamento de objetos que fornece armazenamento de dados local com um código padrão mínimo. No momento da compilação, ele verifica cada consulta quanto à conformidade com seu esquema de dados; portanto, consultas SQL quebradas resultam em erros durante a compilação e não travam no tempo de execução. Resumos de sala de alguns detalhes básicos da implementação de tabelas e consultas SQL brutas. Também permite observar alterações nos dados do banco de dados, incluindo solicitações de coleta e conexão, expondo essas alterações usando objetos LiveData. Ele mesmo define explicitamente restrições de execução que resolvem problemas comuns de encadeamento, como acesso ao armazenamento no encadeamento principal.
Nota Se seu aplicativo já usa outra solução, como o ORM (SQLite Object Relational Mapping), você não precisa substituir a solução existente por Room. No entanto, se você estiver escrevendo um novo aplicativo ou reorganizando um aplicativo existente, recomendamos o uso do Room para salvar os dados do aplicativo. Assim, você pode tirar proveito da abstração da biblioteca e validação de consulta.Para usar o Room, precisamos definir nosso layout local. Primeiro, adicionamos a anotação
@Entity à nossa classe de modelo de dados do
User e a anotação
@PrimaryKey no campo de
id da classe. Essas anotações marcam
User como uma tabela em nosso banco de dados e
id como a chave primária da tabela:
@Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String )
Em seguida, criamos a classe de banco de dados implementando o
RoomDatabase para nosso aplicativo:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase()
Observe que o
UserDatabase é abstrato. A biblioteca da sala fornece isso automaticamente. Consulte a documentação do
quarto para obter detalhes.
Agora precisamos de uma maneira de inserir dados do usuário no banco de dados. Para esta tarefa, criamos
um objeto de acesso a dados (DAO) .
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): LiveData<User> }
Observe que o método
load retorna um objeto do tipo LiveData. A sala sabe quando o banco de dados é alterado e notifica automaticamente todos os observadores ativos de alterações de dados. Como o Room usa o
LiveData , essa operação é eficiente; ele atualiza os dados apenas se houver pelo menos um observador ativo.
Nota: A sala verifica a invalidação com base nas modificações da tabela, o que significa que ele pode enviar notificações de falsos positivos.Após definir nossa classe
UserDao , fazemos referência ao DAO da nossa classe de banco de dados:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao }
Agora podemos alterar nosso
UserRepository para incluir a fonte de dados da sala:
Observe que, mesmo se alteramos a fonte de dados no
UserRepository , não precisamos alterar nosso
UserProfileViewModel ou
UserProfileFragment . Esta pequena atualização demonstra a flexibilidade que nossa arquitetura de aplicativos oferece. Também é ótimo para teste, porque podemos fornecer um
UserRepository falso e testar nosso
UserProfileViewModel produção ao mesmo tempo.
Se os usuários retornarem em alguns dias, é provável que um aplicativo que use essa arquitetura exiba informações desatualizadas até que o repositório receba informações atualizadas. Dependendo do seu caso de uso, você pode não exibir informações desatualizadas. Em vez disso, você pode exibir dados de
espaço reservado , o que mostra valores ilegais e indica que seu aplicativo está baixando e carregando informações atualizadas.
A única fonte de verdade:normalmente, diferentes pontos de extremidade da API REST retornam os mesmos dados. Por exemplo, se nosso back-end tiver outro ponto de extremidade que retorne uma lista de amigos, o mesmo objeto de usuário poderá vir de dois pontos de extremidade da API diferentes, possivelmente até usando diferentes níveis de detalhe. Se UserRepositoryretornarmos a resposta da solicitação Webservicecomo está, sem verificar a consistência, nossas interfaces com o usuário poderão mostrar informações confusas, porque a versão e o formato dos dados do armazenamento dependerão do último ponto final chamado.Por esse motivo, nossa implementação UserRepositoryarmazena respostas de serviço da web em um banco de dados. Alterações no banco de dados acionam retornos de chamada para objetos ativos do LiveData. Usando esse modelo, o banco de dados serve como a única fonte de verdade e outras partes do aplicativo acessam-no através do nosso UserRepository. Independentemente de você usar um cache de disco, recomendamos que seu repositório identifique a fonte de dados como a única fonte de verdade para o restante do seu aplicativo.Mostrar progresso da operação
Em alguns casos de uso, como puxar para atualizar, é importante que a interface do usuário mostre ao usuário que uma operação de rede está em andamento no momento. É recomendável que a ação da interface do usuário seja separada dos dados reais, pois os dados podem ser atualizados por vários motivos. Por exemplo, se recebermos uma lista de amigos, o mesmo usuário poderá ser selecionado novamente programaticamente, o que levará a uma atualização para o LiveData. Do ponto de vista da interface do usuário, o fato de ter uma solicitação em andamento é apenas outro ponto de dados, semelhante a qualquer outra parte de dados no próprio objeto User.Podemos usar uma das seguintes estratégias para exibir o status de atualização de dados acordado na interface do usuário, independentemente de onde a solicitação de atualização de dados veio:Na seção sobre separação de interesses, mencionamos que uma das principais vantagens de seguir esse princípio é a testabilidade.A lista a seguir mostra como testar cada módulo de código do nosso exemplo estendido:- Interface do usuário e interação : use o Android UI Test Toolkit . A melhor maneira de criar esse teste é usar a biblioteca Espresso . Você pode criar um fragmento e fornecer um layout
UserProfileViewModel. Como o fragmento está associado apenas a UserProfileViewModel, a imitação (imitação) dessa classe é suficiente para testar completamente a interface do usuário do seu aplicativo. - ViewModel:
UserProfileViewModel JUnit . , UserRepository . - UserRepository:
UserRepository JUnit. Webservice UserDao . :
Webservice , UserDao , .- UserDao: DAO . - , . , , , …
: Room , DAO, JSQL SupportSQLiteOpenHelper . , SQLite SQLite . - -: . , -, . , MockWebServer , .
- : maven .
androidx.arch.core : JUnit:
InstantTaskExecutorRule: .CountingTaskExecutorRule: . Espresso .
A programação é um campo criativo e a criação de aplicativos Android não é exceção. Existem várias maneiras de resolver o problema, seja transferir dados entre várias ações ou fragmentos, recuperar dados excluídos e armazená-los localmente offline, ou qualquer número de outros cenários comuns encontrados por aplicativos não triviais.Embora as recomendações a seguir não sejam necessárias, nossa experiência mostra que sua implementação torna sua base de código mais confiável, testável e suportada a longo prazo:Evite designar os pontos de entrada do seu aplicativo - como ações, serviços e receptores de transmissão - como fontes de dados.Em vez disso, eles só precisam se coordenar com outros componentes para obter um subconjunto dos dados relacionados a esse ponto de entrada. Cada componente do aplicativo é de curta duração, dependendo da interação do usuário com seu dispositivo e do estado atual geral do sistema.Crie linhas de responsabilidade claras entre os vários módulos do seu aplicativo.Por exemplo, não distribua código que baixa dados da rede para várias classes ou pacotes em sua base de códigos. Da mesma forma, não defina várias responsabilidades não relacionadas - como cache de dados e ligação de dados - na mesma classe.Exponha o mínimo possível de cada módulo.Resista à tentação de criar um rótulo “apenas um” que revele os detalhes de uma implementação interna de um módulo. Você pode ganhar algum tempo no curto prazo, mas terá uma dívida técnica muitas vezes à medida que sua base de código se desenvolver.Pense em como tornar cada módulo testável isoladamente.Por exemplo, ter uma API bem definida para recuperar dados da rede facilita o teste de um módulo que armazena esses dados em um banco de dados local. Se, em vez disso, você misturar a lógica desses dois módulos em um único local ou distribuir seu código de rede por toda a base de códigos, o teste se tornará muito mais difícil - em alguns casos, nem mesmo impossível.Concentre-se no núcleo exclusivo do seu aplicativo para se destacar de outros aplicativos.Não reinvente a roda escrevendo o mesmo padrão repetidamente. Em vez disso, concentre seu tempo e energia no que torna seu aplicativo único e deixe que os componentes da arquitetura Android e outras bibliotecas recomendadas lidem com um padrão repetitivo.Mantenha o máximo possível de dados relevantes e atualizados.Assim, os usuários podem aproveitar a funcionalidade do seu aplicativo, mesmo que o dispositivo esteja offline. Lembre-se de que nem todos os usuários usam uma conexão constante de alta velocidade.Designe uma única fonte de dados como a única fonte verdadeira.Sempre que seu aplicativo precisar acessar esses dados, sempre deve vir dessa fonte única de verdade.Adendo: divulgação do status da rede
Na seção acima da arquitetura de aplicativo recomendada, ignoramos erros de rede e estados de inicialização para simplificar trechos de código.Esta seção mostra como exibir o status da rede usando a classe Resource, que encapsula os dados e seu estado.O seguinte snippet de código fornece um exemplo de implementaçãoResource:
Como o download de dados da rede ao exibir uma cópia desses dados é uma prática comum, é útil criar uma classe auxiliar que possa ser reutilizada em vários locais. Para este exemplo, nós criamos uma classe chamada NetworkBoundResource.O diagrama a seguir mostra a árvore de decisão para NetworkBoundResource: Começa observando o banco de dados do recurso. Quando um registro é baixado do banco de dados pela primeira vez, ele
Começa observando o banco de dados do recurso. Quando um registro é baixado do banco de dados pela primeira vez, ele NetworkBoundResourceverifica se o resultado é bom o suficiente para ser enviado ou se precisa ser recuperado da rede. Observe que essas duas situações podem ocorrer simultaneamente, já que você provavelmente deseja mostrar dados em cache ao atualizá-los da rede.Se a chamada de rede for bem-sucedida, ela armazena a resposta no banco de dados e reinicializa o fluxo. No caso de uma NetworkBoundResourcefalha na solicitação de rede , ela envia a falha diretamente.. . , .Lembre-se de que confiar em um banco de dados para enviar alterações envolve o uso de efeitos colaterais relacionados, o que não é muito bom, pois o comportamento indefinido desses efeitos colaterais pode ocorrer se o banco de dados não enviar as alterações porque os dados não foram alterados.Além disso, não envie resultados recebidos da rede, pois isso viola o princípio de uma única fonte de verdade. No final, é possível que o banco de dados contenha gatilhos que alterem os valores dos dados durante a operação de salvamento. Da mesma forma, não envie `SUCESSO` sem novos dados, pois o cliente receberá a versão incorreta dos dados.O seguinte snippet de código mostra a API aberta fornecida pela classe NetworkBoundResourcepara suas subclasses:
Preste atenção aos seguintes detalhes importantes da definição de classe:- Ele define dois parâmetros de tipo
ResultTypee , RequestTypecomo o tipo de dados retornado da API pode não corresponder ao tipo de dados usado localmente. - Ele usa uma classe
ApiResponsepara solicitações de rede. ApiResponseÉ um invólucro simples para uma classe Retrofit2.Callque converte respostas em instâncias LiveData.
A implementação completa da classe NetworkBoundResourceaparece como parte do projeto GitHub android-Architecture-components .Uma vez criado, NetworkBoundResourcepodemos usá-lo para escrever nossas implementações de disco e conectadas à rede Userna classe UserRepository: