
Olá leitores do Habr! O tópico deste artigo será a implementação da tolerância a desastres nos sistemas de armazenamento do AERODISK Engine. Inicialmente, queríamos escrever em um artigo sobre os dois meios: replicação e o cluster metro, mas, infelizmente, o artigo acabou sendo muito grande, então dividimos o artigo em duas partes. Vamos do simples ao complexo. Neste artigo, iremos configurar e testar a replicação síncrona - descartar um data center e também cortar o canal de comunicação entre os data centers e ver o que acontece.
Nossos clientes geralmente nos fazem perguntas diferentes sobre replicação; portanto, antes de prosseguir com a configuração e o teste da implementação de réplicas, falaremos um pouco sobre o que é replicação nos sistemas de armazenamento.
Pouco de teoria
A replicação no armazenamento é um processo contínuo de garantir a identidade dos dados em vários sistemas de armazenamento simultaneamente. Tecnicamente, a replicação é realizada por dois métodos.
Replicação síncrona é a cópia de dados do sistema de armazenamento principal para o de backup, seguida pela confirmação obrigatória de ambos os sistemas de armazenamento de que os dados são registrados e confirmados. Após a confirmação de ambos os lados (nos dois sistemas de armazenamento), os dados são considerados registrados e você pode trabalhar com eles. Isso garante uma identidade de dados garantida em todos os sistemas de armazenamento participantes da réplica.
As vantagens deste método:
- Os dados são sempre idênticos em todos os sistemas de armazenamento.
Contras:
- Alto custo da solução (canais de comunicação rápidos, fibra cara, transceptores de ondas longas, etc.)
- Restrições de distância (dentro de algumas dezenas de quilômetros)
- Não há proteção contra corrupção de dados lógicos (se os dados estiverem corrompidos (intencionalmente ou acidentalmente) no sistema de armazenamento principal, eles serão automaticamente e imediatamente corrompidos no armazenamento de backup, pois os dados são sempre idênticos (isso é um paradoxo)
A replicação assíncrona também está copiando dados do armazenamento principal para o backup, mas com um certo atraso e sem a necessidade de confirmar o registro do outro lado. Você pode trabalhar com os dados imediatamente após gravar no armazenamento principal e, no armazenamento de backup, os dados estarão disponíveis após algum tempo. A identidade dos dados nesse caso, é claro, não é fornecida. Os dados no armazenamento de backup estão sempre um pouco "no passado".
Vantagens da replicação assíncrona:
- Baixo custo da solução (qualquer canal de comunicação, óptica opcional)
- Sem limite de distância
- Os dados no armazenamento de backup não serão corrompidos se estiverem corrompidos no principal (pelo menos por algum tempo); se os dados estiverem corrompidos, você sempre poderá interromper a réplica para impedir a corrupção de dados no armazenamento de backup.
Contras:
- Os dados em diferentes data centers nem sempre são idênticos
Portanto, a escolha do modo de replicação depende das tarefas do negócio. Se for crítico para você que o data center de backup tenha exatamente os mesmos dados que os dados principais (ou seja, requisito de negócios para RPO = 0), você terá que se esforçar e suportar as limitações da réplica síncrona. E se o atraso no estado dos dados for permitido ou simplesmente não houver dinheiro, então, definitivamente, você deverá usar o método assíncrono.
Também distinguimos separadamente esse regime (mais precisamente, já uma topologia) como um cluster metropolitano. O modo Metrocluster usa replicação síncrona, mas, diferentemente de uma réplica regular, o metrocluster permite que ambos os sistemas de armazenamento funcionem no modo ativo. I.e. você não possui uma separação de data centers em espera ativa. Os aplicativos funcionam simultaneamente com dois sistemas de armazenamento localizados fisicamente em diferentes datacenters. Os tempos de inatividade de acidentes em tal topologia são muito pequenos (RTO, geralmente minutos). Neste artigo, não consideraremos nossa implementação do cluster metropolitano, pois esse é um tópico muito amplo e amplo; portanto, dedicaremos um artigo separado a seguir na continuação deste.
Muitas vezes, quando falamos de replicação usando sistemas de armazenamento, muitos têm uma pergunta razoável:> "Muitos aplicativos têm suas próprias ferramentas de replicação, por que usar a replicação em sistemas de armazenamento? Está melhor ou pior?
Não há uma resposta única, então aqui estão os prós e contras:
Argumentos PARA replicação de armazenamento:
- A simplicidade da solução. De uma maneira, você pode replicar uma matriz inteira de dados, independentemente do tipo de carga ou aplicativo. Se você usar uma réplica de aplicativos, precisará configurar cada aplicativo separadamente. Se houver mais de dois deles, será extremamente demorado e caro (a replicação de aplicativos requer, em regra, uma licença separada e não gratuita para cada aplicativo. Mas mais sobre isso abaixo).
- Você pode replicar qualquer coisa - qualquer aplicativo, qualquer dado - e eles sempre serão consistentes. Muitos (a maioria) aplicativos não possuem recursos de replicação, e as réplicas do lado do armazenamento são a única maneira de fornecer proteção contra desastres.
- Não é necessário pagar a mais pela funcionalidade de replicação de aplicativos. Como regra, custa muito, assim como licenças para um sistema de armazenamento de réplicas. Mas você precisa pagar pela licença de replicação de armazenamento apenas uma vez e comprar a licença para a réplica do aplicativo para cada aplicativo separadamente. Se houver muitos desses aplicativos, custará um centavo e o custo das licenças para replicação do armazenamento se tornará uma gota no balde.
Argumentos contra a replicação de armazenamento:
- A réplica que utiliza as ferramentas de aplicativo tem mais funcionalidade do ponto de vista dos próprios aplicativos; o aplicativo conhece melhor seus dados (o que é óbvio); portanto, há mais opções para trabalhar com eles.
- Os fabricantes de alguns aplicativos não garantem a consistência de seus dados se a replicação for feita por ferramentas de terceiros. *
* - uma tese controversa. Por exemplo, uma conhecida empresa de manufatura de DBMS declarou, por muito tempo, oficialmente que seu DBMS normalmente pode ser replicado apenas por seus meios, e o restante da replicação (incluindo SHD-shnaya) "não é verdade". Mas a vida mostrou que não é assim. Provavelmente (mas isso não é exato), essa simplesmente não é a tentativa mais honesta de vender mais licenças para os clientes.
Como resultado, na maioria dos casos, a replicação do lado do armazenamento é melhor, porque Essa é uma opção mais simples e mais barata, mas há casos complexos em que você precisa de funcionalidade específica do aplicativo e precisa trabalhar com a replicação no nível do aplicativo.
Com a teoria finalizada, agora pratique
Vamos configurar uma réplica em nosso laboratório. No laboratório, emulamos dois data centers (de fato, dois racks adjacentes que parecem estar em edifícios diferentes). O suporte consiste em dois sistemas de armazenamento Engine N2, que são interconectados por cabos ópticos. Um servidor físico executando o Windows Server 2016 usando Ethernet de 10 Gb está conectado aos dois sistemas de armazenamento. A posição é bastante simples, mas não muda a essência.
Esquematicamente, fica assim:
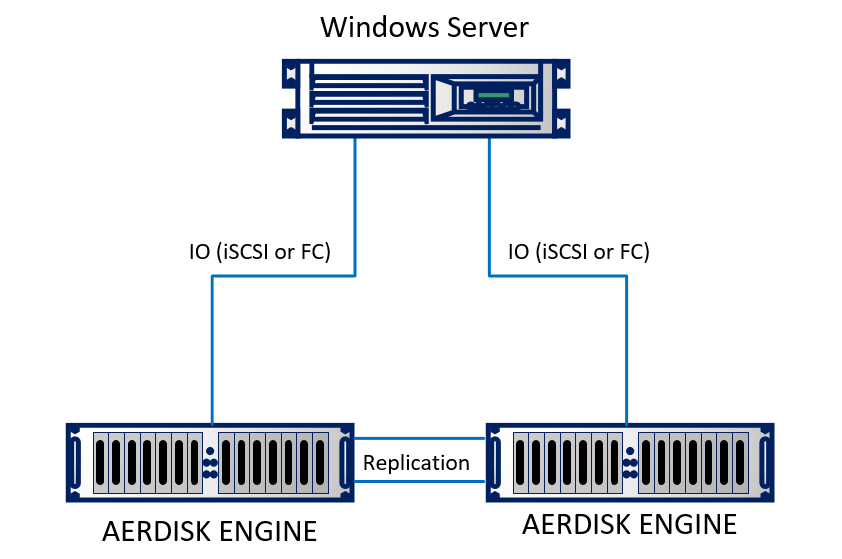
A replicação lógica é organizada da seguinte maneira:
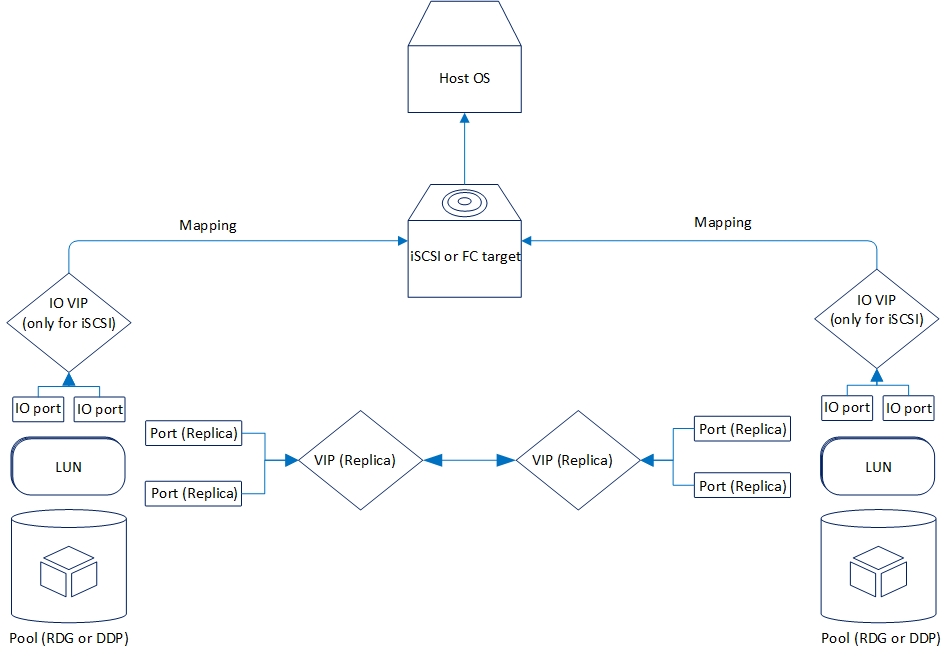
Agora, vejamos a funcionalidade de replicação que temos agora.
Dois modos são suportados: assíncrono e síncrono. É lógico que o modo síncrono seja limitado pela distância e pelo canal de comunicação. Em particular, o modo síncrono requer o uso de fibra como física e Ethernet de 10 gigabits (ou superior).
A distância suportada para replicação síncrona é de 40 quilômetros; o atraso do canal óptico entre os data centers é de até 2 milissegundos. Em geral, ele funcionará com grandes atrasos, mas haverá fortes freios durante a gravação (o que também é lógico); portanto, se você estiver pensando em replicação síncrona entre data centers, verifique a qualidade da ótica e dos atrasos.
Os requisitos de replicação assíncrona não são tão sérios. Mais precisamente, eles não são de todo. Qualquer conexão Ethernet funcionando é adequada.
No momento, o armazenamento do AERODISK ENGINE suporta replicação para dispositivos de bloco (LUNs) usando o protocolo Ethernet (cobre ou óptica). Para projetos que exigem necessariamente replicação por meio da fábrica SAN Fibre Channel, agora estamos concluindo a solução apropriada, mas até agora ela não está pronta, portanto, no nosso caso, apenas Ethernet.
A replicação pode funcionar entre qualquer sistema de armazenamento da série ENGINE (N1, N2, N4), dos sistemas inferiores aos antigos e vice-versa.
A funcionalidade dos dois modos de replicação é completamente idêntica. Abaixo está mais sobre o que é:
- Replicação "um para um" ou "um para um", ou seja, a versão clássica com dois data centers, o principal e o de backup
- A replicação é "um para muitos" ou "um para muitos", ou seja, um LUN pode ser replicado para vários sistemas de armazenamento de uma só vez
- Ativação, desativação e "reversão" da replicação, respectivamente, para ativar, desativar ou alterar a direção da replicação
- A replicação está disponível para os conjuntos RDG (Raid Distributed Group) e DDP (Dynamic Disk Pool). No entanto, o LUN do pool RDG só pode ser replicado para outro RDG. C DDP é semelhante.
Existem muitos outros recursos pequenos, mas listá-los não faz muito sentido; nós os mencionaremos durante a instalação.
Configuração de replicação
O processo de instalação é bastante simples e consiste em três estágios.
- Configuração de rede
- Configuração de armazenamento
- Configurando Regras (Links) e Mapeamento
Um ponto importante na configuração da replicação é que os dois primeiros estágios devem ser repetidos em um sistema de armazenamento remoto, o terceiro estágio - apenas no principal.
Configuração de recursos de rede
A primeira etapa é configurar as portas de rede através das quais o tráfego de replicação será transmitido. Para fazer isso, você precisa habilitar as portas e definir endereços IP nelas na seção Adaptadores front-end.
Depois disso, precisamos criar um pool (no nosso caso, RDG) e um IP virtual para replicação (VIP). VIP é um endereço IP flutuante vinculado a dois endereços "físicos" dos controladores de armazenamento (as portas que acabamos de configurar). Será a interface de replicação principal. Você também pode operar não com VIP, mas com VLAN, se precisar trabalhar com tráfego marcado.
O processo de criação de um VIP para uma réplica não é muito diferente de criar um VIP para E / S (NFS, SMB, iSCSI). Nesse caso, criamos um VIP (sem VLAN), mas devemos indicar que é para replicação (sem esse ponteiro, não poderemos adicionar VIP à regra na próxima etapa).
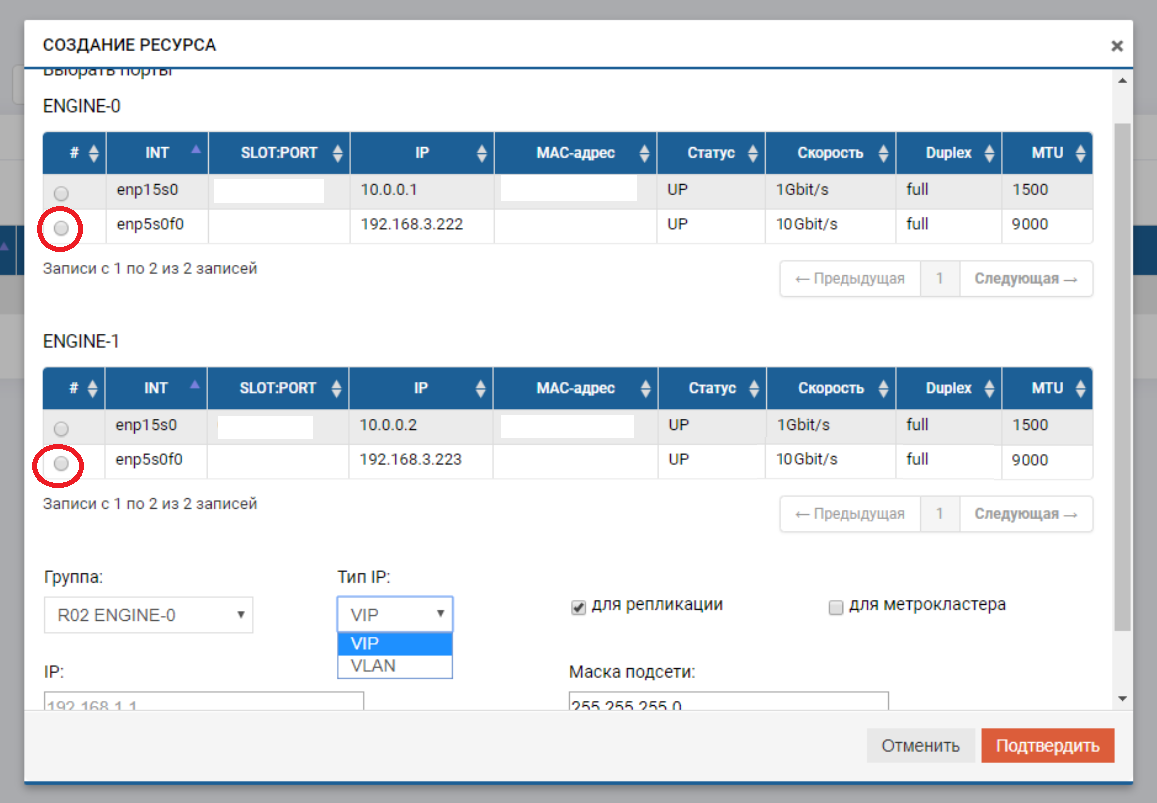
O VIP deve estar na mesma sub-rede que as portas IP entre as quais "flutua".

Repetimos essas configurações no sistema de armazenamento remoto, com outro IP-shnik, por si só.
VIPs de diferentes sistemas de armazenamento podem estar em sub-redes diferentes, o principal é que deve haver roteamento entre eles. No nosso caso, este exemplo é apenas mostrado (192.168.3.XX e 192.168.2.XX)

Com isso, a preparação da parte da rede é concluída.
Configurar armazenamento
A configuração do armazenamento para uma réplica difere da usual apenas no mapeamento por meio do menu especial "Mapeamento de replicação". Caso contrário, tudo será o mesmo da configuração usual. Agora em ordem.
No pool R02 criado anteriormente, você precisa criar um LUN. Crie, chame-o de LUN1.
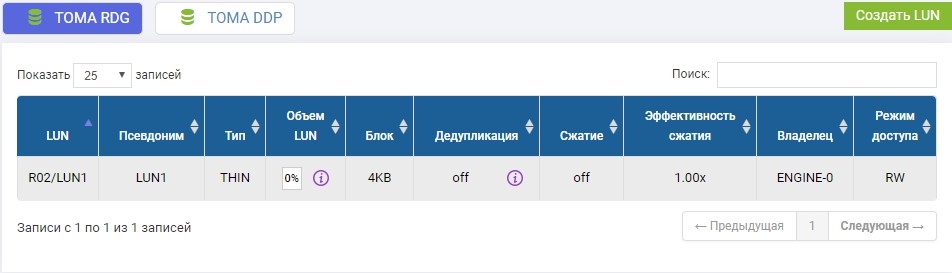
Também precisamos criar o mesmo LUN em um sistema de armazenamento remoto de volume idêntico. Nós criamos. Para evitar confusão, o LUN remoto será chamado LUN1R
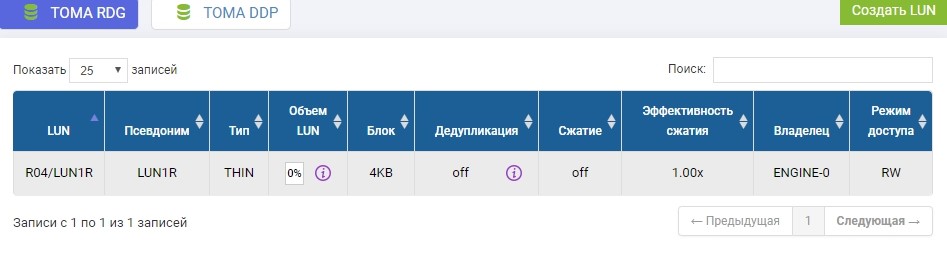
Se precisássemos usar um LUN que já existe, no momento da configuração da réplica, esse LUN produtivo precisaria ser desmontado do host e, no sistema de armazenamento remoto, basta criar um LUN vazio de tamanho idêntico.
A configuração de armazenamento está concluída, prosseguimos para a criação da regra de replicação.
Configurar regras de replicação ou links de replicação
Depois de criar LUNs no armazenamento, que será o principal no momento, configuramos a regra de replicação LUN1 no SHD1 no LUN1R no SHD2.
A configuração é feita no menu Replicação Remota.
Crie uma regra. Para fazer isso, especifique o destinatário da réplica. Também especificamos o nome da conexão e o tipo de replicação (síncrona ou assíncrona).
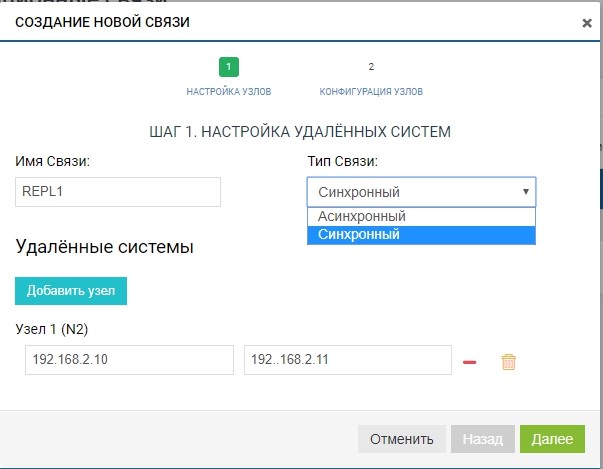
No campo "sistemas remotos", adicione nosso SHD2. Para adicionar, você precisa usar o gerenciamento de armazenamento IP (MGR) e o nome do LUN remoto para o qual iremos replicar (no nosso caso, LUN1R). O gerenciamento de IPs é necessário apenas no estágio de adição da comunicação; o tráfego de replicação por meio deles não será transmitido; para isso, o VIP configurado anteriormente será usado.
Já nesta fase, podemos adicionar mais de um sistema remoto para a topologia “um para muitos”: clique no botão “adicionar nó”, como na figura abaixo.
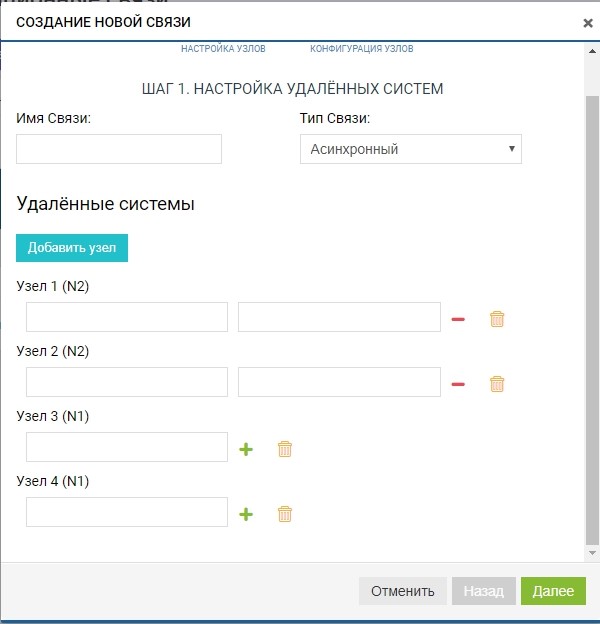
No nosso caso, o sistema remoto é um, então estamos limitados a isso.
A regra está pronta. Observe que ele é adicionado automaticamente a todos os participantes da replicação (no nosso caso, existem dois). Você pode criar quantas regras quiser, para qualquer número de LUNs e em qualquer direção. Por exemplo, para equilibrar a carga, podemos replicar parte dos LUNs de SHD1 para SHD2 e a outra parte, pelo contrário, de SHD2 para SHD1.
SHD1. Imediatamente após a criação, a sincronização começou.
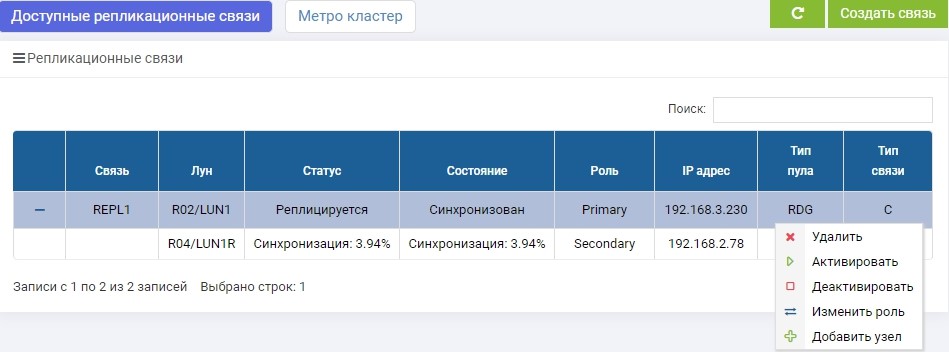
SHD2. Vemos a mesma regra, mas a sincronização já terminou.
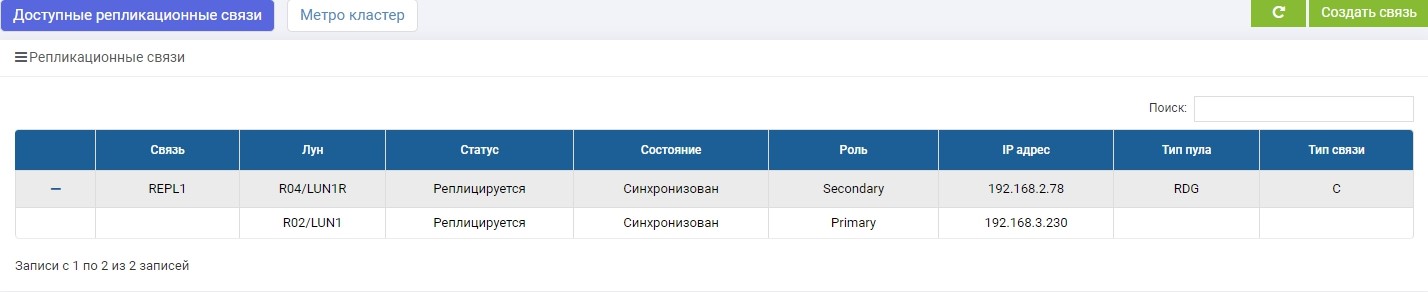
LUN1 no SHD1 está no papel de Primário, ou seja, está ativo. O LUN1R no SHD2 está no papel de Secundário, ou seja, está em espera, em caso de falha do SHD1.
Agora podemos conectar nosso LUN ao host.
Faremos a conexão via iSCSI, embora isso possa ser feito via FC. A configuração do mapeamento para o iSCSI LUN em uma réplica praticamente não é diferente do cenário usual, portanto, não discutiremos isso em detalhes aqui. Se houver, esse processo é descrito no artigo Instalação rápida .
A única diferença é que criamos o mapeamento no menu "Mapeamento de replicação".
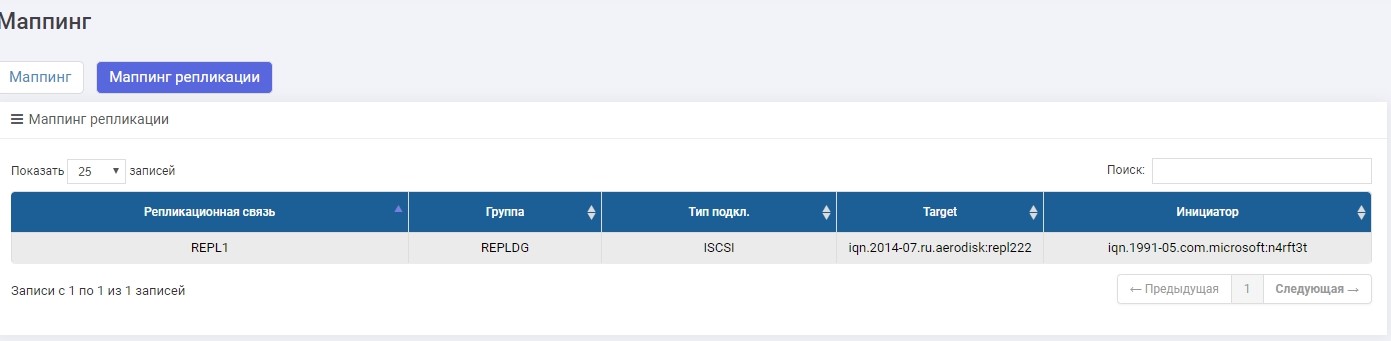
Configure o mapeamento, forneça o LUN ao host. O anfitrião viu um LUN.
Formate-o para o sistema de arquivos local.
É isso aí, a configuração está concluída. Em seguida irá testes.
Teste
Vamos testar três cenários principais.
- Funções de troca de equipe Secundário> Primário. Uma troca de função regular é necessária caso, por exemplo, precisemos principalmente de um data center para executar algumas operações preventivas e, durante esse período, para que os dados estejam disponíveis, transfira a carga para o data center de backup.
- Failover de funções Secundário> Primário (falha do datacenter). Esse é o cenário principal para o qual existe replicação, o que pode ajudar a sobreviver a uma falha completa do data center sem parar a empresa por um longo tempo.
- Canais de comunicação quebrados entre data centers. Verificar o comportamento correto de dois sistemas de armazenamento sob condições quando, por algum motivo, o canal de comunicação entre os datacenters estiver indisponível (por exemplo, uma escavadeira cavou no lugar errado e rasgou a ótica escura).
Para começar, começaremos a gravar dados em nosso LUN (gravamos arquivos com dados aleatórios). Vimos imediatamente que o canal de comunicação entre os sistemas de armazenamento está sendo utilizado. Isso é fácil de entender se você abrir o monitoramento de carga das portas responsáveis pela replicação.
Nos dois sistemas de armazenamento agora existem dados "úteis", podemos iniciar o teste.
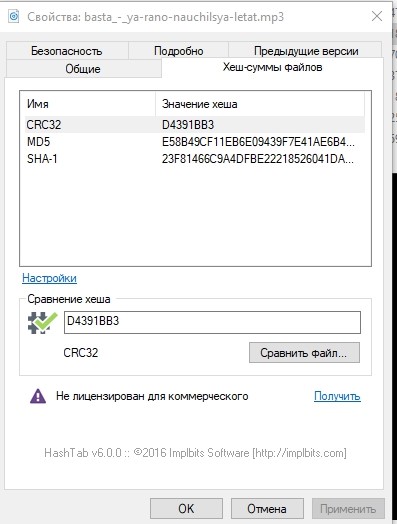
Apenas no caso, vamos examinar as somas de hash de um dos arquivos e anotá-las.
Troca de função de equipe
A operação de alternar funções (alterando a direção da replicação) pode ser feita a partir de qualquer sistema de armazenamento, mas você ainda precisa ir para ambos, pois será necessário desativar o mapeamento no Primário e ativá-lo no Secundário (que se tornará Primário).
Talvez agora surja uma pergunta razoável: por que não automatizar isso? Respondemos: tudo é simples, a replicação é uma ferramenta simples de tolerância a desastres baseada apenas em operações manuais. Para automatizar essas operações, existe um modo de cluster de metrô, é totalmente automatizado, mas sua configuração é muito mais complicada. Escreveremos sobre a configuração do cluster metro no próximo artigo.
Desative o mapeamento no armazenamento principal para garantir que a gravação seja interrompida.
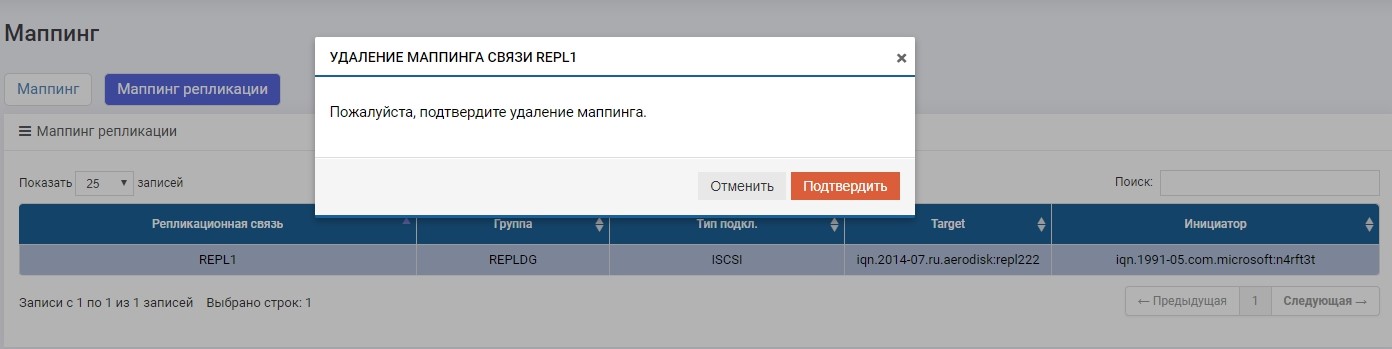
Em um dos sistemas de armazenamento (não importa, no principal ou no backup) no menu Replicação remota, selecione nossa conexão REPL1 e clique em "Alterar função".
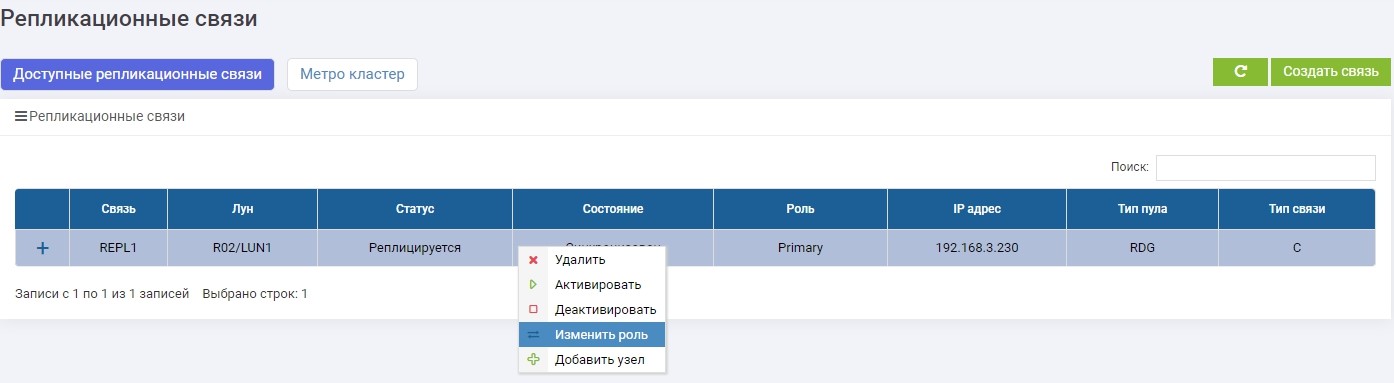
Após alguns segundos, o LUN1R (armazenamento de backup) se torna Primário.
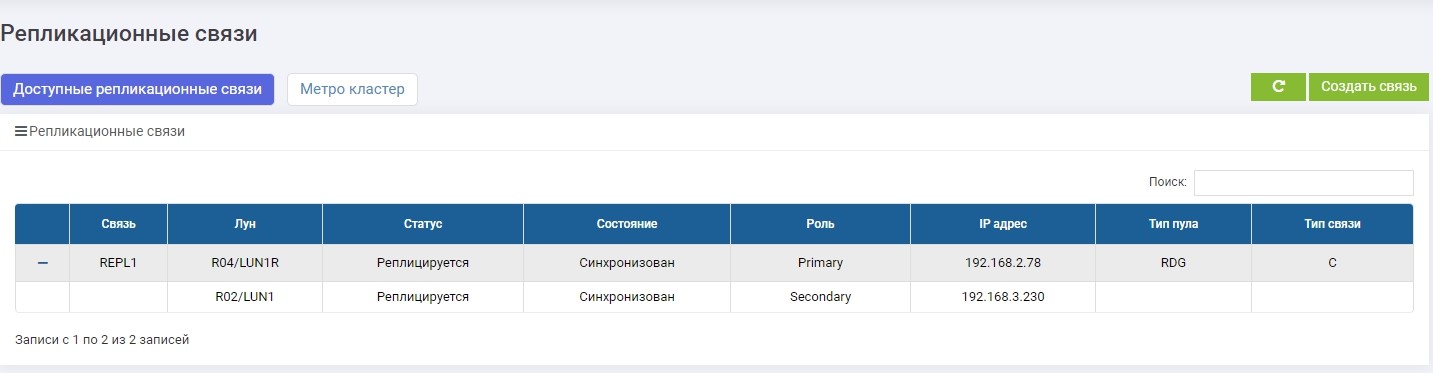
Fazemos o mapeamento de LUN1R com SHD2.
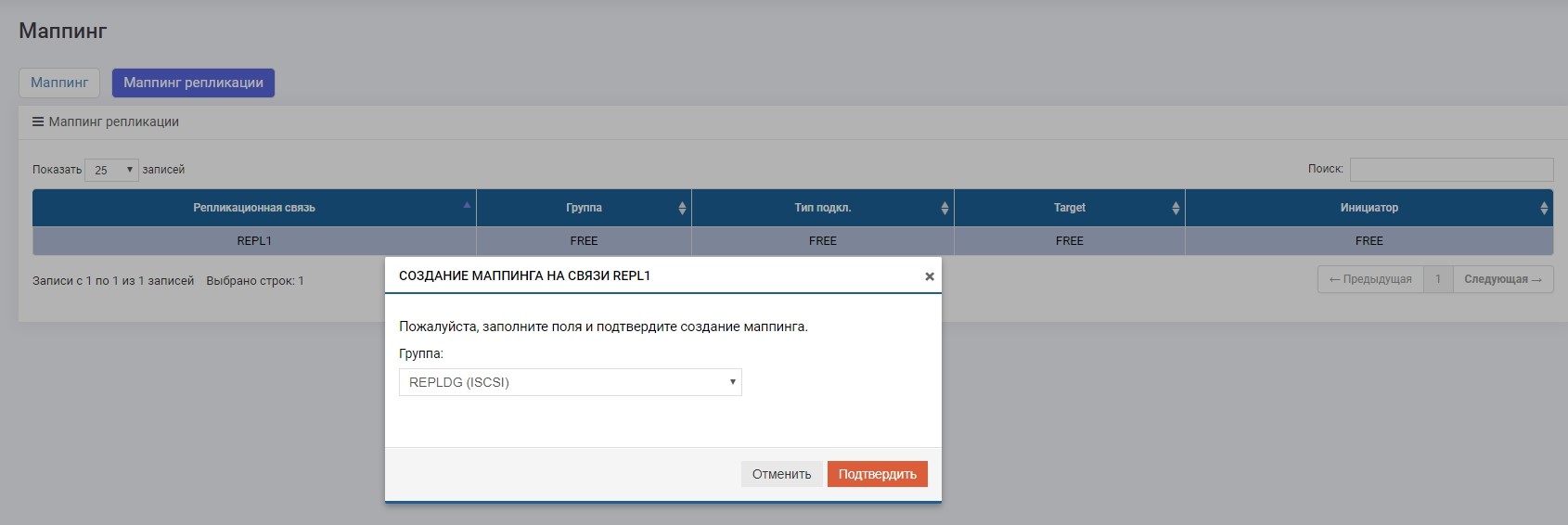
Depois disso, nosso drive E: se apega automaticamente ao host, só que desta vez "voou" com o LUN1R.
Apenas no caso, compare os valores de hash.
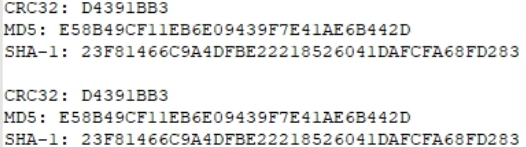
Idêntico. Teste aprovado.
Failover Falha no Data Center
No momento, o armazenamento principal após a troca regular é SHD2 e LUN1R, respectivamente. Para simular um acidente, desligamos os dois controladores SHD2.
O acesso a ele não é mais.
Observamos o que está acontecendo no armazenamento 1 (backup no momento).

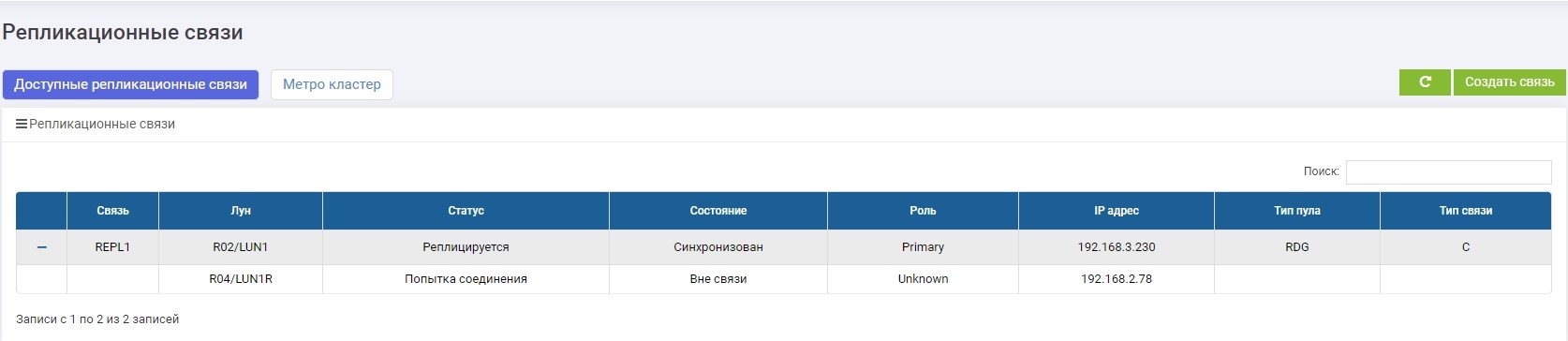
Vemos que o LUN Primário (LUN1R) não está disponível. Uma mensagem de erro apareceu nos logs, no painel de informações e na própria regra de replicação. Consequentemente, os dados do host estão indisponíveis no momento.
Altere a função do LUN1 para Primário.
Assuntos mapeados para o host.

Verifique se a unidade E aparece no host.
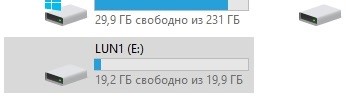
Verifique o hash.
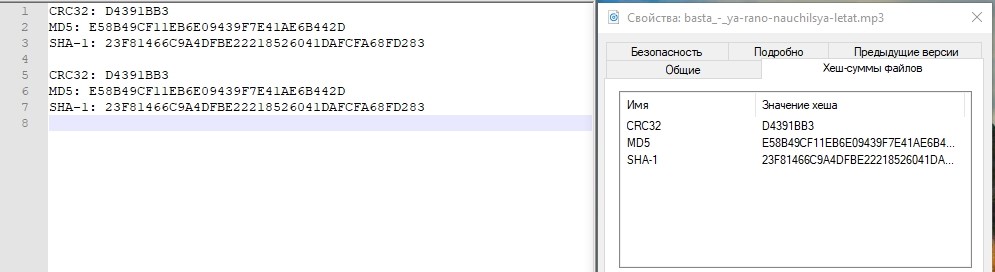
Está tudo bem. O centro de armazenamento sofreu uma queda no data center, que estava ativo. O tempo aproximado que gastamos na conexão da “reversão” da replicação e na conexão do LUN do datacenter de backup foi de aproximadamente 3 minutos. Está claro que no produto real tudo é muito mais complicado e, além de ações com sistemas de armazenamento, você precisa executar muito mais operações na rede, em hosts e em aplicativos. E na vida, esse período será muito mais longo.
Aqui eu quero escrever que tudo, o teste foi concluído com sucesso, mas não vamos nos apressar. O armazenamento principal "mente", sabemos que quando ela "caiu", ela estava no papel de Primária. O que acontece se ela ligar de repente? Haverá duas funções Primárias, que são iguais à corrupção de dados? Vamos verificar agora.
De repente, vamos ativar o armazenamento subjacente.
Carrega por vários minutos e depois retorna à operação após uma breve sincronização, mas já no papel de Secundário.

Está tudo bem. Cérebro dividido não aconteceu. Nós pensamos sobre isso, e sempre após a queda do sistema de armazenamento aumenta o papel de Secundário, independentemente de qual papel ele tenha "na vida". Agora podemos dizer com certeza que o teste de falha do data center foi bem-sucedido.
Falha nos canais de comunicação entre os data centers
A principal tarefa deste teste é garantir que o sistema de armazenamento não comece a surtar se perder temporariamente os canais de comunicação entre os dois sistemas de armazenamento e reaparecer.
Então Desconectamos os fios entre os sistemas de armazenamento (imagine que uma escavadeira os tenha escavado).
Na Primária, vemos que não há conexão com a Secundária.
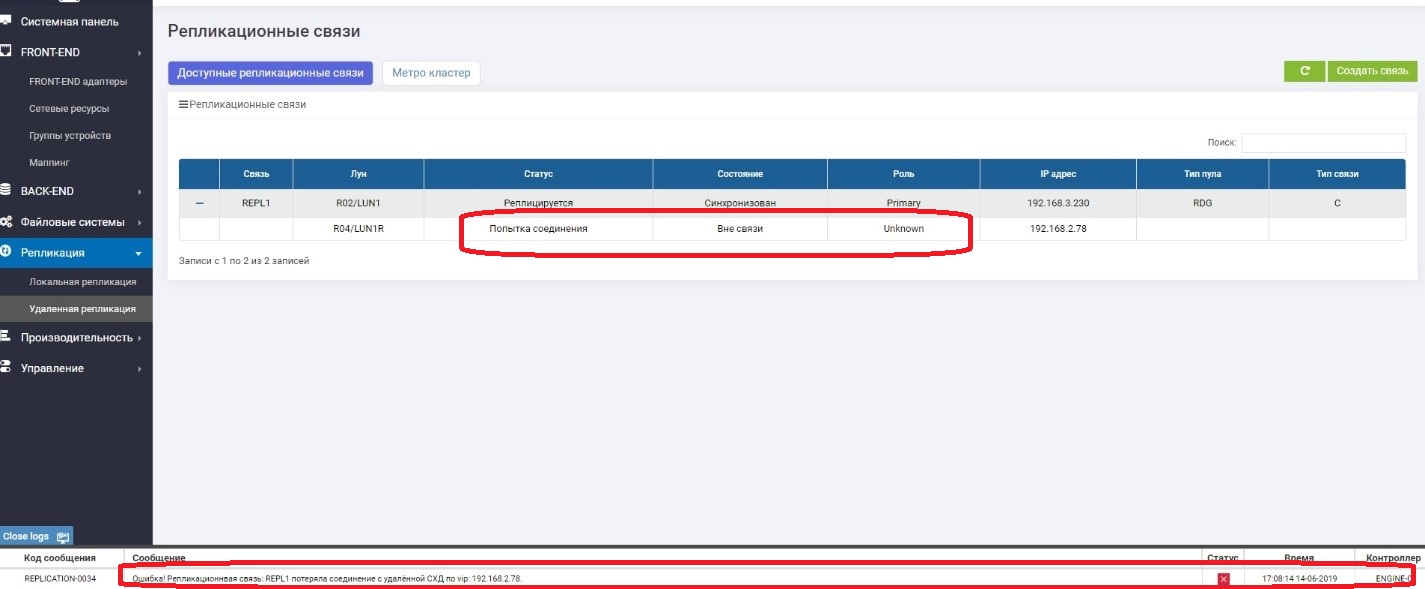
No secundário, vemos que não há conexão com o primário.
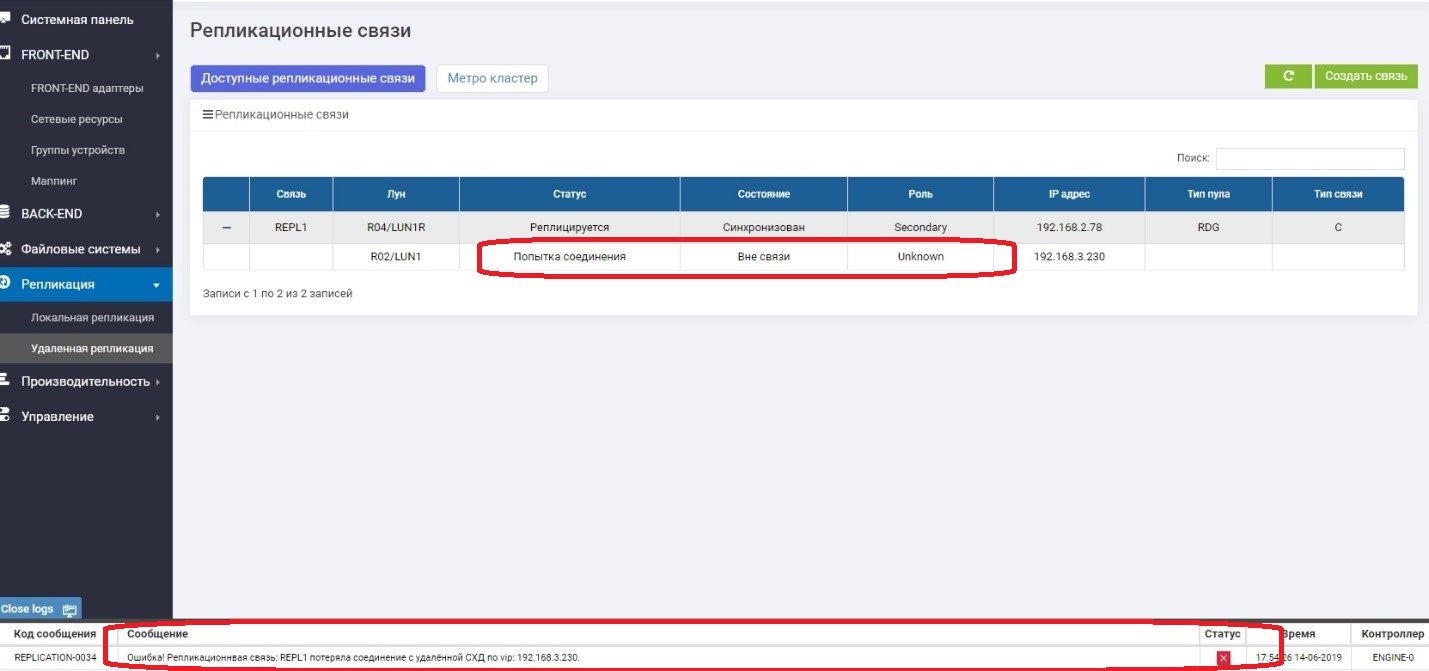
Tudo funciona bem, e continuamos a gravar dados no sistema de armazenamento principal, ou seja, eles já garantem que diferem do sistema de backup, ou seja, eles "saíram".
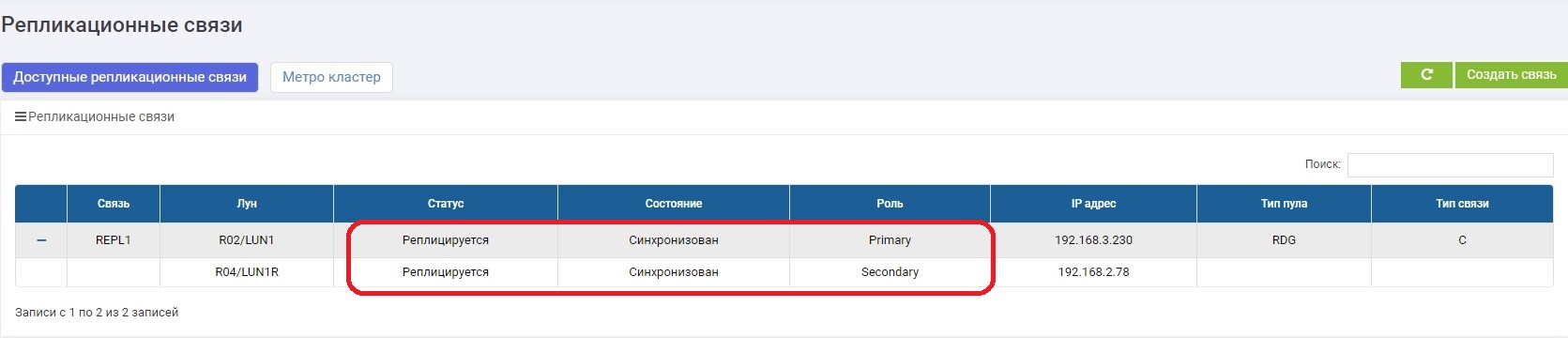
Em alguns minutos, estamos consertando o canal de comunicação. Assim que os sistemas de armazenamento se vêem, a sincronização de dados é ativada automaticamente. Não é necessário nada do administrador.

.
, , .
– , , . .
, - . . , .
active-active, , .
, .
Vejo você de novo.