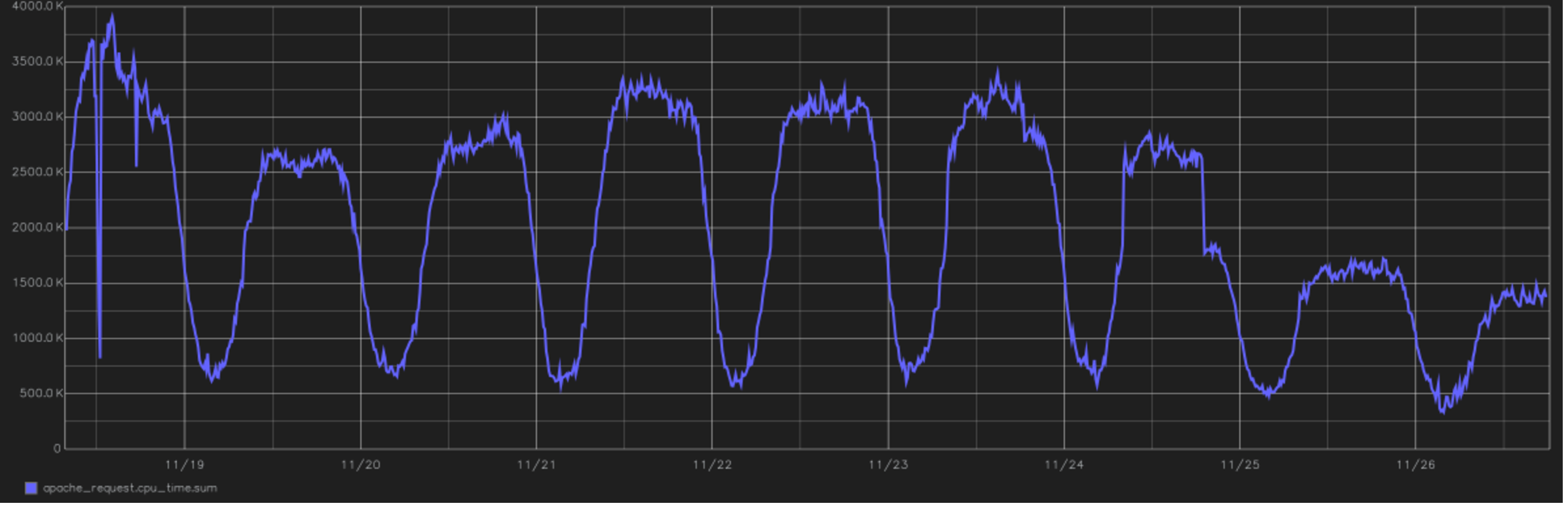
 Este é um dos relevos mais legais do projeto. Na figura - um gráfico do tempo total gasto pela CPU para processar todas as solicitações do usuário. No final, você pode ver a transição para o PHP 7.0. desde a versão 5.6. Este é o ano de 2016, mudando à tarde de 24 de novembro.
Este é um dos relevos mais legais do projeto. Na figura - um gráfico do tempo total gasto pela CPU para processar todas as solicitações do usuário. No final, você pode ver a transição para o PHP 7.0. desde a versão 5.6. Este é o ano de 2016, mudando à tarde de 24 de novembro.Do ponto de vista dos cálculos, o Tutu.ru é principalmente uma oportunidade de comprar uma passagem do ponto A ao ponto B. Para fazer isso, processamos um grande número de horários, armazenamos em cache as respostas de muitos sistemas de companhias aéreas e periodicamente fazemos consultas de junção incrivelmente longas ao banco de dados. Em geral, estamos escritos em PHP e até recentemente estávamos completamente nele (se a linguagem foi preparada corretamente, você pode até construir sistemas em tempo real). Recentemente, as áreas críticas de desempenho foram refatoradas no Go.
Temos constantemente uma dívida técnica . E isso acontece mais rápido do que gostaríamos. A boa notícia: você não precisa cobrir tudo. Ruim: à medida que a funcionalidade suportada aumenta, a dívida técnica também aumenta proporcionalmente.
Em geral, a dívida técnica é o custo de cometer um erro ao tomar uma decisão. Você não previu algo como o arquiteto, ou seja, cometeu um erro de previsão ou tomou uma decisão nas condições de informações insuficientes. Em algum momento, você entende que precisa alterar algo no código (geralmente no nível da arquitetura). Então você pode mudar imediatamente, mas pode esperar. Se você esperar - os juros correram para a dívida tecnológica. Portanto, é uma boa prática reestruturá-lo de tempos em tempos. Bem, ou declare-se falido e escreva o bloco inteiro novamente.
Como tudo começou: monólito e funções gerais
O projeto Tutu.ru começou em 2003 como um site regular de Runet da época. Ou seja, havia um monte de arquivos em vez de um banco de dados, uma página PHP na frente do HTML + JS. Houve alguns hacks excelentes do meu colega Yuri, mas é melhor ele contar um dia. Entrei para o projeto em 2006, primeiro como consultor externo que poderia ajudar com conselhos e um código e, em 2009, fui transferido para o estado como diretor técnico. Antes de tudo, era necessário arrumar as coisas na direção das passagens aéreas: era a parte mais carregada e complexa da arquitetura.
Em 2006, lembro que havia uma programação de trens e uma oportunidade de comprar uma passagem de trem. Decidimos fazer a seção de passagens aéreas como um projeto separado, ou seja, tudo isso foi unido apenas na frente. Todos os três projetos (horários de trem, transporte ferroviário e aéreo) foram finalmente escritos à sua maneira. Naquela época, o código parecia normal para nós, mas um pouco inacabado. Não perfeccionista. Depois ficou velho, cobriu-se de muletas e, na direção da ferrovia, transformou-se em abóbora em 2010.
No setor ferroviário, não tivemos tempo para dar dívidas técnicas. A refatoração não era realista: os problemas estavam na arquitetura. Decidimos demolir e refazer tudo de novo, mas também era difícil em um projeto ao vivo. Como resultado, apenas os URLs antigos foram deixados na frente e, em seguida, bloco por bloco foram reescritos. Como base, adotamos as abordagens usadas um ano antes no desenvolvimento do setor de aviação.
Reescrito em PHP. Então ficou claro que esse não era o único caminho, mas não havia alternativas razoáveis para nós. Eles escolheram porque já tinham experiência e realizações, ficou claro que essa é uma boa linguagem nas mãos dos desenvolvedores seniores. Das alternativas, C e C ++ eram insanamente produtivas, mas qualquer reconstrução ou introdução de alterações a elas parecia um pesadelo. Ok, não lembrou. Foi um pesadelo.
A Microsoft e todo o .NET do ponto de vista de um projeto de alta carga nem sequer foram considerados. Então não havia outras opções além do Linux. O Java é uma boa opção, mas exige recursos da memória, nunca perdoa erros juniores e, portanto, não possibilitou o lançamento rápido de lançamentos - bem, ou não sabíamos disso. Mesmo agora, não consideramos o Python como um back-end, apenas para tarefas de manipulação de dados. JS - puramente sob a frente. Não havia desenvolvedores do Ruby on Rails na época (e agora). Go se foi. Ainda havia o Perl, mas os especialistas o classificaram como pouco promissor para o desenvolvimento da web, então eles também o abandonaram. O PHP é deixado.
A próxima história holiv é PostgreSQL vs. MySQL. Em algum lugar melhor, em outro lugar. Em geral, era uma boa prática escolher o que era melhor, então escolhemos o MySQL e seus garfos.
A abordagem de desenvolvimento era monolítica, então simplesmente não havia outras abordagens, mas com a estrutura ortogonal das bibliotecas. Estes são os primórdios da abordagem moderna centrada na API, quando cada biblioteca tem uma fachada externa, para a qual você pode extrair diretamente o código de outras partes do projeto. As bibliotecas foram escritas em "camadas" quando cada nível tem um formato específico na entrada e passa um certo formato para o código, e os testes de unidade alternam entre eles. Ou seja, algo como desenvolvimento orientado a teste, mas pixelizado e assustador.
Tudo isso foi hospedado em vários servidores, o que possibilitou escalar sob carga. Mas, ao mesmo tempo, a base de código de diferentes projetos se cruzou fortemente no nível do sistema. De fato, isso significava que mudanças no projeto ferroviário poderiam afetar nossas próprias aeronaves. E tocou frequentemente. Por exemplo, na ferrovia, era necessário expandir o trabalho com pagamentos - esta é uma revisão da biblioteca compartilhada. E a aeronave trabalha com ela, portanto, testes conjuntos são necessários. Examinamos as dependências com testes, e isso era mais ou menos normal. Mesmo em 2009, o método era bastante avançado. Mas, ainda assim, a carga pode adicionar outra de um recurso. Houve uma interseção nos bancos de dados, o que levou a efeitos desagradáveis na forma de freios em todo o site, com problemas locais em um produto. O Railway matou a aeronave várias vezes no disco devido a consultas pesadas ao banco de dados.
Escalamos adicionando instâncias e equilibrando entre elas. Monólito como está.
Idade dos pneus
Então seguimos um caminho bastante marginal. Por um lado, começamos a isolar serviços (hoje essa abordagem é chamada microsserviço, mas não conhecíamos a palavra "micro"), mas, para a interação, começamos a usar o barramento para transferência de dados, em vez de REST ou gRPC, como fazem agora. Escolhemos o AMQP como protocolo e o RabbitMQ como o intermediário de mensagens. Naquela época, já dominávamos o lançamento de daemons para PHP (sim, há uma implementação de fork totalmente funcional () e tudo o mais para trabalhar com processos), pois durante muito tempo no monólito usamos o Gearman para paralelizar solicitações de sistemas de reservas .
Eles fizeram um corretor em cima do coelho, e acabou que tudo isso realmente não vive sob carga. Algum tipo de perda de rede, retransmissões, atrasos. Por exemplo, um cluster de vários corretores “prontos para o uso” se comporta de maneira um pouco diferente do declarado pelo desenvolvedor (isso nunca aconteceu antes e novamente). Em geral, eles aprenderam muito. Mas, no final, obtivemos os SLAs necessários para os serviços. Por exemplo, o serviço RPS mais carregado possui 400 rps, o 99º percentil de ida e volta de cliente para cliente, incluindo o processamento de barramento e serviço da ordem de 35 ms. Agora, no total, observamos cerca de 18 krps.
Então veio a direção dos ônibus. Nós o escrevemos imediatamente sem um monólito na arquitetura de serviço. Como tudo foi escrito do zero, o resultado foi muito bom, rápido e conveniente, embora fosse necessário refinar constantemente as ferramentas para uma nova abordagem. Sim, tudo isso girava em máquinas virtuais, dentro das quais os daemons PHP se comunicam via barramento. Os demônios começaram dentro dos contêineres do Docker, mas não havia soluções para orquestração como o Openshift ou o Kubernetes. Em 2014, estávamos apenas começando a falar sobre isso, mas não consideramos essa abordagem de vendas.
Se você comparar quantas passagens de ônibus são vendidas em comparação com passagens de avião ou trem, você terá uma gota no balde. E em trens e aviões, era difícil mudar para uma nova arquitetura, porque havia funcionalidade de trabalho, uma carga real e sempre havia uma escolha entre fazer algo novo ou gastar dinheiro em pagar uma dívida técnica.
Mudar para serviços é uma coisa boa, mas longa, mas você precisa lidar com a carga e a confiabilidade agora. Portanto, paralelamente, eles começaram a tomar medidas direcionadas para melhorar a vida do monólito. Os back-ends foram divididos em tipos de produtos, ou seja, passaram a controlar com mais flexibilidade o roteamento de solicitações, dependendo do seu tipo: ar separadamente da ferrovia, etc. Foi possível prever a carga, dimensionar de forma independente. Quando eles sabiam que nas ferrovias, por exemplo, o pico das vendas de Ano Novo, várias instâncias de máquinas virtuais foram adicionadas. Começou exatamente 45 dias antes do último dia útil do ano e nos dias 14 e 15 de novembro tivemos uma carga dupla. Agora, a FPK e outras operadoras fizeram muitos bilhetes com o início das vendas por 60, 90 e até 120 dias, e esse pico se espalhou. Mas no último dia útil de abril sempre haverá uma carga em trens elétricos antes de maio, e ainda há picos. Mas sobre a sazonalidade dos bilhetes e os modos de migração da desmobilização, meus colegas da ferrovia dirão melhor, e continuarei sobre a arquitetura.
Em algum lugar em 2014, eles começaram a desbanhar um grande banco de dados de muitos pequenos. Isso foi importante porque estava crescendo perigosamente e a queda foi crítica. Começamos a alocar pequenos bancos de dados separados (de 5 a 10 tabelas) para uma funcionalidade específica, para que outros serviços afetassem menos interrupções e para que tudo isso pudesse ser escalado mais facilmente. Vale ressaltar que, para balanceamento de carga e dimensionamento, usamos réplicas para leitura. Recuperar réplicas para uma base grande após uma falha de replicação pode levar horas, e todo esse tempo eu tive que "voar em liberdade condicional e em uma ala". Memórias de tais períodos ainda causam um calafrio desagradável em algum lugar entre os ouvidos. Agora, temos cerca de 200 instâncias de bases diferentes, e administrar tantas instalações com nossas mãos é um negócio trabalhoso e não confiável. Portanto, usamos o Github Orchestrator, que automatiza o trabalho com réplicas e proxySql para distribuir a carga e proteger contra falhas de um banco de dados específico.
Como agora
Em geral, gradualmente começamos a alocar tarefas assíncronas e separamos seus lançamentos no manipulador de eventos para que um não interfira no outro.
Quando o PHP 7 foi lançado, vimos nos testes um grande progresso no desempenho e redução no consumo de recursos. A mudança ocorreu com um pouco de hemorróidas, todo o projeto, desde o início dos testes até a tradução completa de toda a produção, demorou pouco mais de seis meses, mas depois o consumo de recursos caiu quase pela metade. Linha do tempo de carregamento da CPU - na parte superior da postagem.
O monólito sobreviveu até hoje e, na minha opinião, é de aproximadamente 40% da base de código. Vale dizer que a tarefa de substituir todo o monólito por serviços não está explicitamente definida. Estamos nos movendo de maneira pragmática: tudo o que é novo é feito em microsserviços, se você precisar refinar a funcionalidade antiga em um monólito, tentamos transferi-la para a arquitetura de serviço, se apenas o refinamento não for realmente muito pequeno. Ao mesmo tempo, o monólito é abordado em testes para que possamos implantar duas vezes por semana com um nível de qualidade suficiente. Os recursos são abordados de diferentes maneiras, os testes de unidade são bastante completos, os testes de interface do usuário e os testes de aceitação cobrem quase toda a funcionalidade do portal (temos cerca de 15.000 casos de teste), os testes de API são mais ou menos completos. Quase não fazemos testes de carga. Mais precisamente, nosso estadiamento é semelhante ao estímulo na estrutura, mas não no poder, e é alinhado com o mesmo monitoramento. Geramos uma carga, se percebermos que a execução anterior na versão antiga difere em tempos, veremos o quanto ela é crítica. Se o novo lançamento e o antigo forem aproximadamente iguais, então os lançaremos no prod. De qualquer forma, todos os recursos são desativados sob o comutador para que você possa desativá-lo a qualquer segundo, se algo der errado.
Recursos pesados são sempre testados para 1% dos usuários. Então vamos para 2%, 5%, 10% e, assim, alcançamos todos os usuários. Ou seja, sempre podemos ver a carga atípica antes do surto matar os servidores e desconectar com antecedência.
Onde necessário, levamos (e levamos) 4-5 meses para um projeto de reengenharia, quando a equipe se concentra em uma tarefa específica. Essa é uma boa maneira de cortar o nó górdio quando a refatoração local não ajuda mais. Assim, fizemos alguns anos atrás com o ar: refizemos a arquitetura, conseguimos - imediatamente obtivemos aceleração instantânea no desenvolvimento, conseguimos lançar muitos novos recursos. Dois meses após a reengenharia, eles cresceram em uma ordem de magnitude para os clientes devido aos recursos. Eles começaram a gerenciar com mais precisão os preços, conectando parceiros, tudo ficou mais rápido. Alegria. Devo dizer que agora é hora de fazer a mesma coisa novamente, mas este é o destino: as maneiras de criar aplicativos estão mudando, novas soluções, abordagens, ferramentas estão aparecendo. Para permanecer no negócio, você precisa crescer.
A principal tarefa da reengenharia para nós é acelerar ainda mais o desenvolvimento. Se nada de novo for necessário, a reengenharia não será necessária. Não há necessidade de inventar um novo: não faz sentido investir em modernização. E assim, enquanto mantém uma pilha e arquitetura modernas, as pessoas entram no trabalho mais rapidamente, uma nova se conecta mais rapidamente, o sistema se comporta de maneira mais previsível, os desenvolvedores estão mais interessados em trabalhar em um projeto. Agora, existe uma tarefa para concluir o monólito sem descartá-lo completamente, para que cada produto possa fazer upload de atualizações, não dependendo de outros. Ou seja, obtenha um IC / CD específico em um monólito.
Hoje usamos não apenas o coelho, mas também o REST e o gRPC para trocar informações entre serviços. Alguns dos microsserviços estão escritos em Golang: a velocidade computacional e a manipulação de memória são excelentes lá. Houve uma chamada para implementar o suporte ao nodeJS, mas no final deixamos o nó apenas para renderização do servidor, e a lógica de negócios foi deixada no PHP e Go. Em princípio, a abordagem escolhida nos permite desenvolver serviços em praticamente qualquer idioma, mas decidimos limitar o zoológico para não aumentar a complexidade do sistema.
Agora vamos aos microsserviços que funcionarão em contêineres do Docker sob a orquestração OpenShift. A tarefa dentro de um ano e meio - 90% de tudo gira dentro da plataforma. Porque Portanto, é mais rápido implementar, verificar versões mais rapidamente, há menos diferenças nas vendas no ambiente de desenvolvimento. O desenvolvedor pode pensar mais sobre o recurso que ele implementa, e não sobre como implantar o ambiente, como configurá-lo, por onde iniciá-lo, ou seja, mais benefícios. Novamente - questões operacionais: existem muitos microsserviços, eles precisam ser automatizados pelo gerenciamento. Manualmente - custos muito altos, riscos de erros no controle manual e a plataforma fornece dimensionamento normal.
Todos os anos, temos um aumento na carga de trabalho - em 30 a 40%: mais e mais pessoas estão dominando truques com a Internet, parando de ir a caixas de dinheiro físicas, estamos adicionando novos produtos e recursos aos já existentes. Agora, cerca de 1 milhão de usuários por dia chegam ao portal. Obviamente, nem todos os usuários geram a mesma carga. Algo não requer recursos computacionais e, por exemplo, as pesquisas são um componente bastante intensivo em recursos. Lá, um único tique "mais ou menos três dias" na aviação aumenta a carga em 49 vezes (ao olhar para frente e para trás, a matriz é de 7 por 7). Tudo o resto em comparação com a busca de uma passagem dentro dos sistemas ferroviários e aéreos é bastante simples. A coisa mais fácil em recursos é a
aventura e a
pesquisa de passeios (não há o cache mais fácil em termos de arquitetura, mas ainda há muito menos passeios do que combinações de bilhetes), depois
a programação do trem (é facilmente armazenada em cache por meios padrão) e só então todo o resto .
Obviamente, a dívida técnica ainda se acumula. Por todos os lados. O principal é entender no tempo em que você pode refatorar e tudo ficará bem, onde você não precisa tocar em nada (às vezes acontece: vivemos com o Legacy se não houver mudanças planejadas), mas em algum lugar precisamos nos apressar e nos reengenhar, porque sem esse futuro não será. É claro que cometemos erros, mas, em geral, o Tutu.ru existe há 16 anos e eu gosto da dinâmica do projeto.