Quem você acha que melhor configuraria o algoritmo PostgreSQL - DBA ou ML? E se for o segundo, então é hora de pensarmos no que fazer quando os carros nos substituirem. Ou não chegará a isso, e decisões importantes ainda devem ser tomadas pelas pessoas. Provavelmente, o nível de isolamento e os requisitos para a estabilidade da transação devem permanecer com o administrador. Mas em breve os índices podem ser confiáveis para determinar você mesmo a máquina.

Andy Pavlo no
HighLoad ++ falou sobre o DBMS do futuro, no qual você pode "tocar" agora. Se você perdeu esse discurso ou prefere receber informações em russo - abaixo do corte está a tradução do discurso.
Será sobre o projeto da Universidade Carnegie Mellon sobre a criação de DBMS autônomo. O termo "autônomo" significa um sistema que pode implantar, configurar e configurar automaticamente sem nenhuma intervenção humana. Pode levar cerca de dez anos para desenvolver algo assim, mas é isso que Andy e seus alunos estão fazendo. Obviamente, são necessários algoritmos de aprendizado de máquina para criar um DBMS autônomo; no entanto, neste artigo, focaremos apenas o lado de engenharia do tópico. Considere como projetar software para torná-lo independente.
Sobre o palestrante: Andy Pavlo, professor associado da Carnegie Mellon University, sob sua liderança cria um
DBMS PelotonDB "autogerenciado" , além do
ottertune , que ajuda a ajustar as configurações do PostgreSQL e MySQL usando o aprendizado de máquina. Andy e sua equipe agora são verdadeiros líderes em bancos de dados autogerenciados.
A razão pela qual queremos criar um DBMS autônomo é óbvia. O gerenciamento dessas ferramentas de DBMS é um processo muito caro e demorado. O salário médio do DBA nos Estados Unidos é de aproximadamente 89 mil dólares por ano. Traduzido em rublos, são obtidos 5,9 milhões de rublos por ano. Essa quantia realmente grande que você paga às pessoas apenas fica de olho no seu software. Cerca de 50% do custo total da utilização do banco de dados é pago pelo trabalho desses administradores e equipe relacionada.
Quando se trata de projetos realmente grandes, como discutimos no HighLoad ++ e que usam dezenas de milhares de bancos de dados, a complexidade de sua estrutura vai além da percepção humana. Todos abordam esse problema superficialmente e tentam alcançar o desempenho máximo investindo o mínimo de esforço no ajuste do sistema.
Você pode salvar uma soma arredondada se configurar o DBMS no nível do aplicativo e do ambiente para garantir o desempenho máximo.
Bancos de dados auto-adaptáveis, 1970–1990
A idéia de DBMSs autônomos não é nova; seu histórico remonta à década de 1970, quando os bancos de dados relacionais começaram a ser criados. Eles foram chamados de bancos de dados auto-adaptáveis (bancos de dados auto-adaptativos) e, com sua ajuda, tentaram resolver os problemas clássicos do design de bancos de dados, sobre os quais as pessoas ainda lutam até hoje. Essa é a escolha dos índices, a partição e construção do esquema do banco de dados, bem como a localização dos dados. Naquele momento, foram desenvolvidas ferramentas que ajudaram os administradores de banco de dados a implantar o DBMS. Essas ferramentas, de fato, funcionavam exatamente como as contrapartes modernas de hoje.
Os administradores rastreiam solicitações executadas pelo aplicativo. Eles então passam essa pilha de consultas para o algoritmo de ajuste, que cria um modelo interno de como o aplicativo deve usar o banco de dados.
Se você criar uma ferramenta que o ajude a selecionar automaticamente índices, crie gráficos a partir dos quais poderá ver com que frequência cada coluna é acessada. Depois, passe essas informações para o algoritmo de pesquisa, que examinará muitos locais diferentes - tentará determinar quais das colunas podem ser indexadas no banco de dados. O algoritmo usará o modelo de custo interno para mostrar que este em particular fornecerá melhor desempenho em comparação com outros índices. Em seguida, o algoritmo dará uma sugestão sobre quais alterações nos índices devem ser feitas. Neste momento, é hora de participar da pessoa, considerar esta proposta e não apenas decidir se está certa, mas também escolher a hora certa para sua implementação.

Os DBAs devem saber como o aplicativo é usado quando houver uma queda na atividade do usuário. Por exemplo, no domingo, às 3:00 da manhã, o nível mais baixo de consultas ao banco de dados, para que você possa recarregar os índices.
Como eu disse, todas as ferramentas de design da época funcionavam da mesma maneira -
esse é
um problema muito antigo . O supervisor científico do meu supervisor científico escreveu um artigo sobre a seleção automática de índices em 1976.
Bancos de dados de autoajuste, 1990–2000
Na década de 1990, as pessoas, de fato, trabalhavam no mesmo problema, apenas o nome mudou de bancos de dados adaptativos para auto-ajustáveis.
Os algoritmos ficaram um pouco melhores, as ferramentas ficaram um pouco melhores, mas em um nível alto eles funcionaram da mesma maneira que antes. A única empresa na vanguarda do movimento de sistemas de autoajuste foi a Microsoft Research com seu projeto de administração automática. Eles desenvolveram soluções realmente maravilhosas e, no final dos anos 90 e início dos anos 2000, apresentaram novamente um conjunto de recomendações para configurar seu banco de dados.
A ideia principal apresentada pela Microsoft era diferente do que era no passado - em vez de as ferramentas de personalização suportarem seus próprios modelos, elas simplesmente reutilizaram o modelo de custo do otimizador de consultas para ajudar a determinar os benefícios de um índice contra outro. Se você pensar sobre isso, faz sentido. Quando você precisa saber se um único índice pode realmente acelerar as consultas, não importa o tamanho dele, se o otimizador não o seleciona. Portanto, o otimizador é usado para descobrir se ele realmente escolherá algo.

Em 2007, a Microsoft Research publicou
um artigo que estabeleceu uma retrospectiva da pesquisa em dez anos. E abrange bem todas as tarefas complexas que surgiram em todos os segmentos do caminho.
Outra tarefa que foi destacada na era dos bancos de dados de autoajuste é
como fazer ajustes automáticos nos reguladores. Um controlador de banco de dados é algum tipo de parâmetro de configuração que altera o comportamento do sistema de banco de dados em tempo de execução. Por exemplo, um parâmetro presente em quase todos os bancos de dados é o tamanho do buffer. Ou, por exemplo, você pode gerenciar configurações como políticas de bloqueio, frequência de limpeza de disco e similares. Devido ao aumento significativo da complexidade dos reguladores DBMS nos últimos anos, esse tópico se tornou relevante.
Para mostrar como as coisas estão ruins, farei uma revisão que meu aluno fez depois de estudar várias versões do PostgreSQL e MySQL.
Nos últimos 15 anos, o número de reguladores no PostgreSQL aumentou 5 vezes, e no MySQL - 7 vezes.
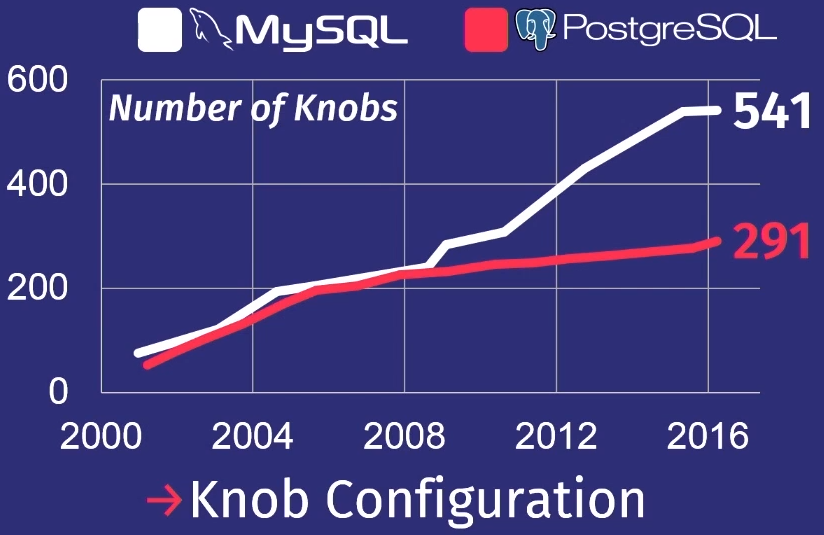
Obviamente, nem todos os reguladores realmente controlam o processo de execução da tarefa. Alguns, por exemplo, contêm caminhos de arquivos ou endereços de rede, para que apenas uma pessoa possa configurá-los. Mas algumas dezenas deles podem realmente afetar o desempenho. Nenhum homem pode segurar tanto em sua cabeça.
Cloud DB, 2010–…
Além disso, nos encontramos na era dos anos 2010, em que estamos até hoje. Eu chamo de era dos bancos de dados em nuvem. Durante esse período, muito trabalho foi feito para automatizar a implantação de um grande número de bancos de dados na nuvem.
A principal coisa que preocupa os principais provedores de nuvem é como hospedar um inquilino ou migrar de um para outro. Como determinar quantos recursos cada inquilino precisará e, em seguida, tente distribuí-los entre as máquinas para maximizar a produtividade ou combinar os SLAs com um custo mínimo.
Amazon, Microsoft e Google resolvem esse problema, mas principalmente no nível operacional. Somente recentemente, os provedores de serviços em nuvem começaram a pensar na necessidade de configurar sistemas de banco de dados individuais. Este trabalho não é visível para usuários comuns, mas determina o alto nível da empresa.
Resumindo a pesquisa de 40 anos de bancos de dados com sistemas autônomos e não autônomos, podemos concluir que esse trabalho ainda não é suficiente.
Por que hoje não podemos ter um sistema verdadeiramente autônomo de autogoverno? Existem três razões para isso.

Primeiro, todas essas ferramentas, exceto a distribuição de cargas de trabalho de provedores de serviços em nuvem, são apenas de
natureza consultiva . Ou seja, com base na opção calculada, uma pessoa deve tomar uma decisão final subjetiva se a proposta está correta. Além disso, é necessário observar a operação do sistema por algum tempo para decidir se a decisão tomada permanece correta à medida que o serviço se desenvolve. E depois aplique o conhecimento ao seu próprio modelo interno de tomada de decisões no futuro. Isso pode ser feito para um banco de dados, mas não para dezenas de milhares.
O próximo problema é que
qualquer medida é apenas uma reação a alguma coisa . Em todos os exemplos que examinamos, o trabalho acompanha dados da carga de trabalho anterior. Há um problema, os registros são transferidos para o instrumento e ele diz: "Sim, eu sei como resolver esse problema". Mas a solução diz respeito apenas a um problema que já ocorreu. A ferramenta não prevê eventos futuros e, portanto, não oferece ações preparatórias. Uma pessoa pode fazer isso, e manualmente, mas as ferramentas não.
A última razão é que em nenhuma das soluções
há transferência de conhecimento . Aqui está o que eu quero dizer: por exemplo, vamos usar uma ferramenta que funcionou em um aplicativo na primeira instância de banco de dados, se você a colocar em outro mesmo aplicativo em outra instância de banco de dados, poderia, com base no conhecimento adquirido ao trabalhar com o primeiro banco de dados Os dados ajudam a configurar um segundo banco de dados. De fato, todas as ferramentas começam a funcionar do zero, elas precisam recuperar todos os dados sobre o que está acontecendo. O homem trabalha de uma maneira completamente diferente. Se eu sei configurar um aplicativo de uma certa maneira, posso ver os mesmos padrões em outro aplicativo e, possivelmente, configurá-lo muito mais rapidamente. Mas nenhum desses algoritmos, nenhuma dessas ferramentas ainda funciona dessa maneira.
Por que tenho certeza de que é hora de mudar? A resposta a esta pergunta é quase a mesma que a de por que as super-matrizes de dados ou aprendizado de máquina se tornaram populares.
Os equipamentos estão se tornando de melhor qualidade : os recursos de produção estão aumentando, a capacidade de armazenamento está aumentando, a capacidade de hardware está aumentando, o que acelera os cálculos para o aprendizado de modelos de aprendizado de máquina.
Ferramentas de software avançadas tornaram-se disponíveis para nós. Antes, você precisava ser um especialista em MATLAB ou álgebra linear de baixo nível para escrever alguns algoritmos de aprendizado de máquina. Agora temos o Torch e o Tenso Flow, que disponibilizam o ML e, é claro, aprendemos a entender melhor os dados. As pessoas sabem que tipo de dados podem ser necessários para a tomada de decisões no futuro; portanto, eles não descartam tantos dados quanto antes.
O objetivo de nossa pesquisa é fechar esse círculo em DBMSs autônomos. Podemos, como as ferramentas anteriores, propor soluções, mas, em vez de confiar na pessoa - se a solução está correta quando você precisa implantá-la especificamente - o algoritmo fará isso automaticamente. E então, com a ajuda do feedback, ele estudará e se tornará melhor com o tempo.
Quero falar sobre os projetos em que estamos trabalhando atualmente na Universidade Carnegie Mellon. Neles, abordamos o problema de duas maneiras diferentes.
No primeiro - OtterTune -, procuramos maneiras de ajustar o banco de dados, tratando-os como caixas pretas. Ou seja, maneiras de
ajustar os DBMSs existentes sem controlar a parte interna do sistema e observar apenas a resposta.
O projeto Peloton trata da
criação de novos bancos de dados do zero , do zero, considerando o fato de que o sistema deve funcionar de forma autônoma. Quais ajustes e algoritmos de otimização precisam ser estabelecidos - que não podem ser aplicados aos sistemas existentes.
Vamos considerar os dois projetos em ordem.
Ottertune
O projeto de ajuste de sistema existente que desenvolvemos é chamado OtterTune.
Imagine que o banco de dados esteja configurado como um serviço. A idéia é que você faça o download das métricas de tempo de execução de operações pesadas de banco de dados que consomem todos os recursos, e a configuração recomendada dos reguladores vem em resposta, o que, em nossa opinião, aumentará a produtividade. Pode ser um atraso, largura de banda ou qualquer outra característica que você especificar - tentaremos encontrar a melhor opção.

A principal novidade do projeto OtterTune é a
capacidade de usar os dados das sessões de ajuste
anteriores e aumentar a eficiência das sessões subseqüentes. Por exemplo, considere a configuração do PostgreSQL, que possui um aplicativo que nunca vimos antes. Mas se ele possui certas características ou usa o banco de dados da mesma maneira que os bancos de dados que já vimos em nossos aplicativos, já sabemos como configurá-lo com mais eficiência.
Em um nível superior, o algoritmo de trabalho é o seguinte.
Digamos que exista um banco de dados de destino: PostgreSQL, MySQL ou VectorWise. Você deve instalar o controlador no mesmo domínio, que executará duas tarefas.
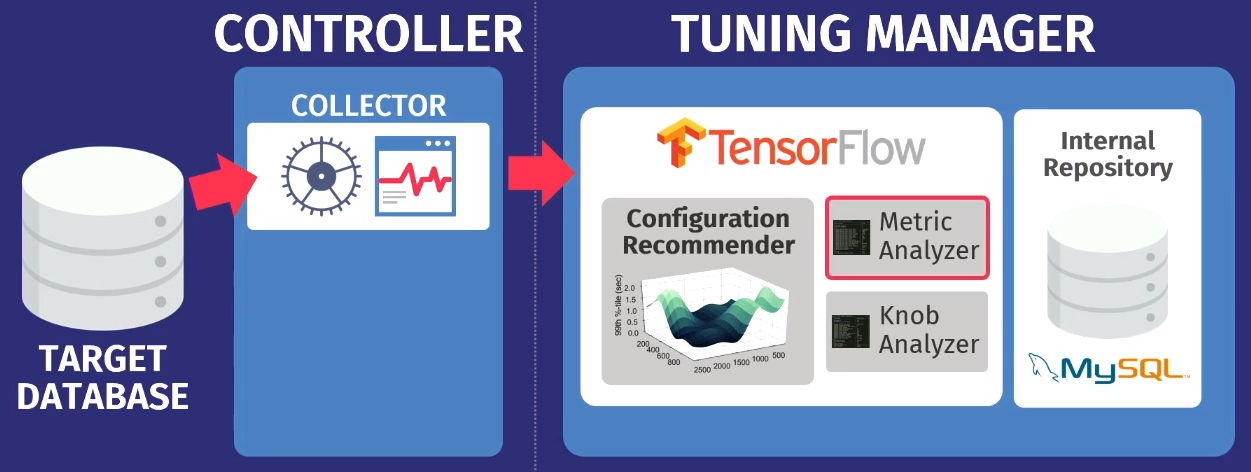
O primeiro é realizado pelo chamado coletor - uma ferramenta que coleta dados sobre a configuração atual, ou seja, consultar métricas de tempo de execução de aplicativos para o banco de dados. Os dados coletados pelo coletor são carregados no Tuning Manager, um serviço de ajuste. Não importa se o banco de dados funciona localmente ou na nuvem. Após o download, os dados são armazenados em nosso próprio repositório interno, que armazena todas as sessões de configuração de teste já realizadas.
Antes de dar recomendações, você precisa executar duas etapas. Primeiro, você precisa examinar as métricas de tempo de execução e descobrir quais são realmente importantes. O exemplo a seguir mostra as métricas retornadas pelo MySQL, mas o
SHOW_GLOBAL_STATUS no InnoDB. Nem todos são úteis para nossa análise. Sabe-se que no aprendizado de máquina uma grande quantidade de dados nem sempre é boa. Porque, então, são necessários ainda mais dados para separar o grão do joio. Como neste caso,
é importante livrar-se de entidades que realmente não importam .
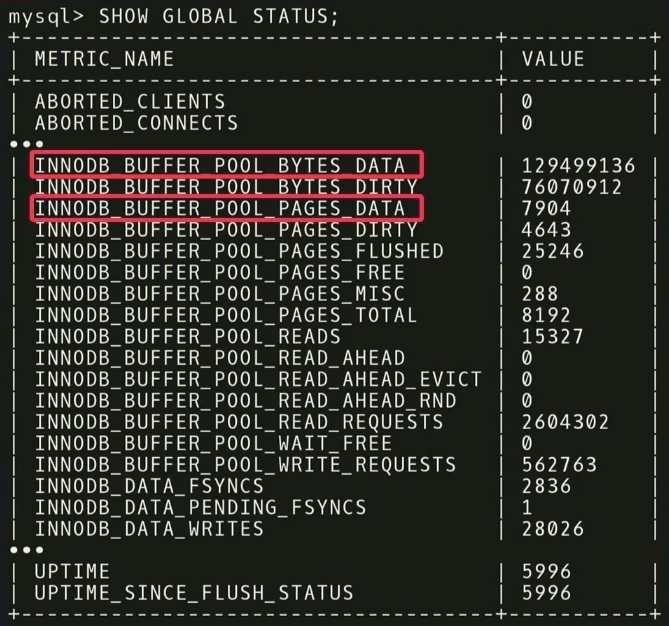
Por exemplo, existem duas métricas:
INNODB_BUFFER_POOL_BYTES_DATA e
INNODB_BUFFER_POOL_PAGES_DATA . De fato, essa é a mesma métrica, mas em unidades diferentes. Você pode realizar uma análise estatística, verificar se as métricas estão altamente correlacionadas e concluir que o uso de ambas é redundante para análise. Se você descartar um deles, a dimensão da tarefa de aprendizado diminuirá e o tempo para receber uma resposta será reduzido.
Na segunda etapa, fazemos o mesmo, apenas em relação aos reguladores.
Existem 500 reguladores no MySQL e, é claro, nem todos são realmente significativos, mas aplicativos diferentes são importantes para aplicativos diferentes. É necessário realizar outra análise estatística para descobrir quais reguladores realmente afetam a função alvo.
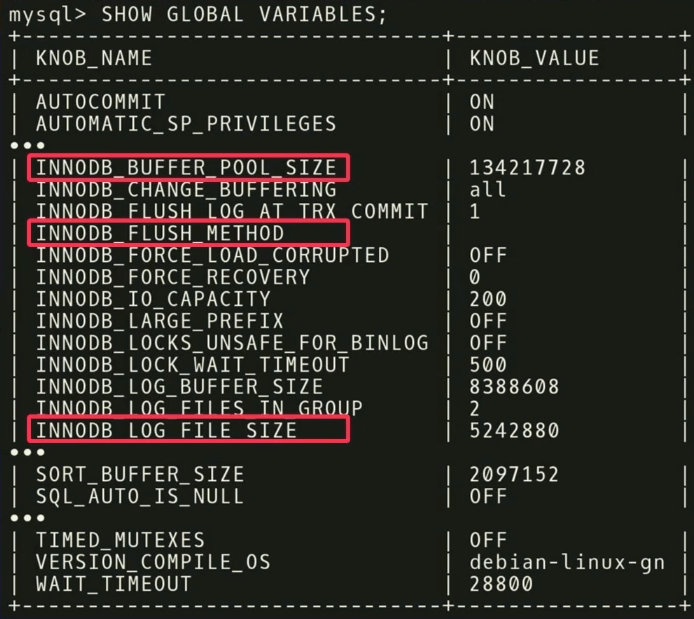
Em nosso exemplo, descobrimos que os três
INNODB_BUFFER_POOL_SIZE ,
FLUSH_METHOD e
LOG_FILE_SIZE têm o maior impacto no desempenho. Eles reduzem o tempo de atraso para uma carga de trabalho transacional.
Existem outros pontos interessantes relacionados aos reguladores. Na captura de tela, há um regulador chamado
TIMED_MUTEXES . Se você consultar a documentação de trabalho do MySQL, na seção 45.7, será indicado que este regulador está desatualizado. Mas
o algoritmo de aprendizado de máquina não é capaz de ler a documentação , portanto, não o conhece. Ele sabe que existe um regulador que pode ser ligado ou desligado, e levará muito tempo para entender que isso não afeta nada. Mas você pode fazer cálculos com antecedência e descobrir que o regulador não faz nada e não perde tempo configurando-o.
Após a análise, os dados são transferidos para o nosso algoritmo de configuração usando
o modelo de processo Gaussiano - um método bastante antigo. Você provavelmente já ouviu falar de aprendizado profundo, estamos fazendo algo semelhante, mas sem redes profundas. Usamos o
GPflow , um pacote para trabalhar com modelos de processo gaussianos desenvolvidos na Rússia com base no TensorFlow. O algoritmo emite uma recomendação que deve melhorar a função objetivo; esses dados são transferidos de volta para o agente de instalação que trabalha dentro do controlador. O agente aplica as alterações executando uma redefinição - infelizmente, ele precisará reiniciar o banco de dados - e o processo se repete novamente. Mais algumas métricas de tempo de execução são coletadas, transferidas para o algoritmo, uma análise da possibilidade de melhorar e aumentar a produtividade é realizada, uma recomendação é emitida e assim por diante, repetidamente.
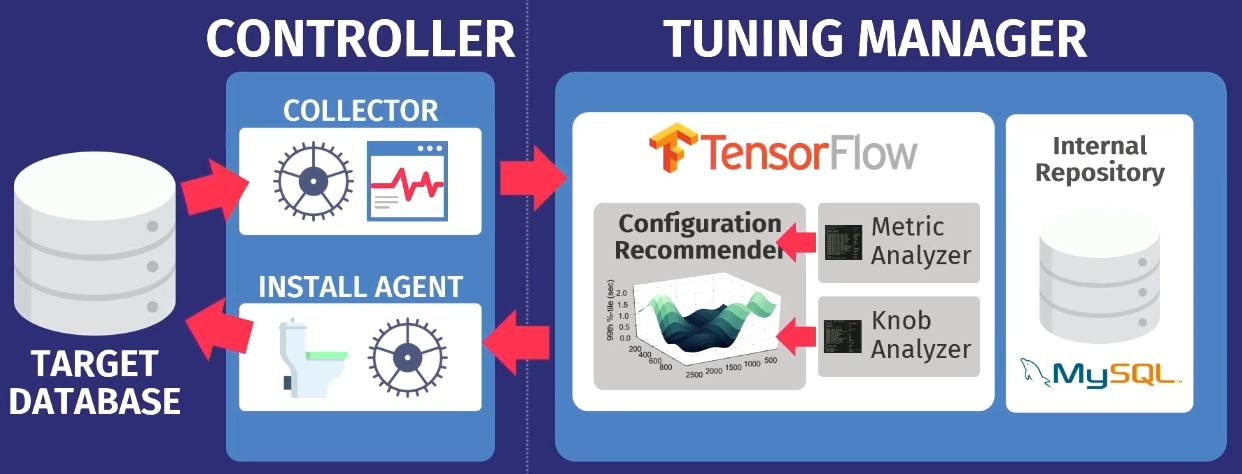
Um recurso importante do OtterTune é que os algoritmos precisam apenas de informações sobre métricas de tempo de execução como entrada. Não precisamos ver seus dados e solicitações de usuário. Só precisamos rastrear operações de leitura e gravação. Esse é um argumento poderoso - os dados pertencentes a você ou a seus clientes não serão divulgados a terceiros. Não precisamos ver nenhuma solicitação, o algoritmo funciona com base apenas em métricas de tempo de execução, porque fornece recomendações para reguladores e não para design físico.
Vamos dar uma olhada na demonstração OtterTune. No site do projeto, executaremos o Postgres 9.6 e carregaremos o sistema com o teste TPC-C. Vamos começar com a configuração inicial do PostgreSQL, que é implantada quando instalada no Ubuntu.
Primeiro, execute o teste TPC-C por cinco minutos, colete as métricas de tempo de execução necessárias, carregue-as no serviço OtterTune, obtenha recomendações, aplique as alterações e repita o processo. Voltaremos a isso mais tarde. O sistema de banco de dados é executado em um computador, o serviço Tensor Flow em outro e carrega os dados aqui.
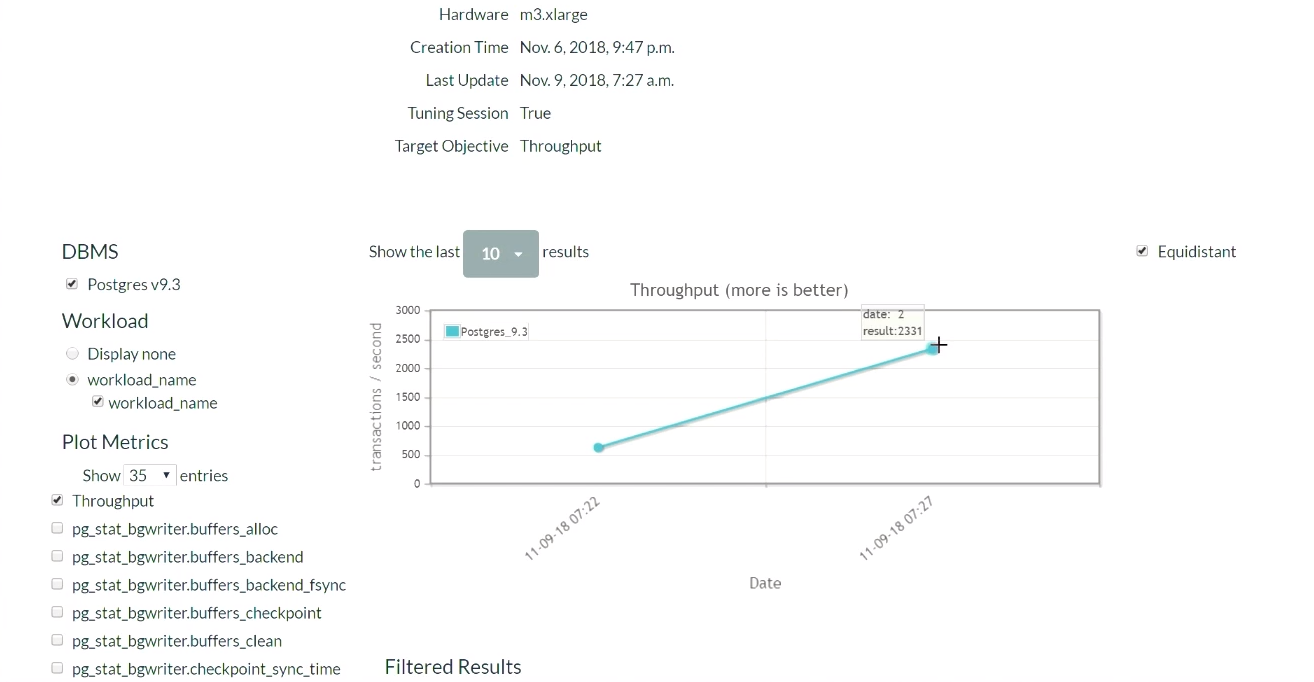
Cinco minutos depois, atualizamos a página (uma demonstração dessa parte dos resultados começa
neste momento ). Quando começamos, na configuração padrão do PostgreSQL, havia 623 transações por segundo. Depois de receber a recomendação e aplicar as alterações uma vez, o número de transações
aumentou para 2300 por segundo . Vale a pena reconhecer que esta demonstração já foi iniciada várias vezes, portanto o sistema já possui um conjunto de dados coletados anteriormente. É por isso que a solução é tão rápida. O que aconteceria se o sistema não tivesse esses dados coletados anteriormente? Esse algoritmo é um tipo de função passo a passo e, gradualmente, chegaria a esse nível.

Depois de algum tempo e cinco iterações, o melhor resultado foi 2600. Passamos de 600 transações por segundo e conseguimos atingir um valor de 2600. Uma pequena queda apareceu porque o algoritmo decidiu tentar uma maneira diferente de ajustar os reguladores depois de obter bons resultados. O resultado foi uma margem, portanto, uma grande queda no desempenho não ocorreu. Tendo recebido um resultado negativo, o algoritmo se reconfigurou e começou a procurar outras formas de regulação.
Concluímos que você não deve ter medo de iniciar uma má estratégia no trabalho, porque o algoritmo irá explorar o espaço da solução e experimentar várias configurações para alcançar as condições do contrato de SLA. Embora você sempre possa configurar o serviço para que o algoritmo selecione apenas soluções aprimoradas. E com o tempo, você receberá todos os melhores e melhores resultados.
Agora, de volta ao tópico da nossa conversa. Vou falar sobre os resultados existentes de um
artigo publicado na Sigmod. Configuramos o MySQL e o PostgreSQL para TPC-C usando o OtterTune, a fim de aumentar a taxa de transferência.
Compare as configurações desses DBMSs, implantados por padrão durante a primeira instalação no Ubuntu. Em seguida, execute alguns scripts de configuração de código aberto que você pode obter da Percona e de outras empresas de consultoria que trabalham com o PostgreSQL. Esses scripts usam procedimentos heurísticos, como a regra em que você deve definir um determinado tamanho de buffer para o seu hardware. Também temos uma configuração do Amazon RDS, que já possui predefinições da Amazon para o equipamento em que você está trabalhando. Em seguida, compare isso com o resultado da configuração manual de DBAs caros, mas com a condição de que eles tenham 20 minutos e a capacidade de definir os parâmetros desejados. E o último passo é iniciar o OtterTune.
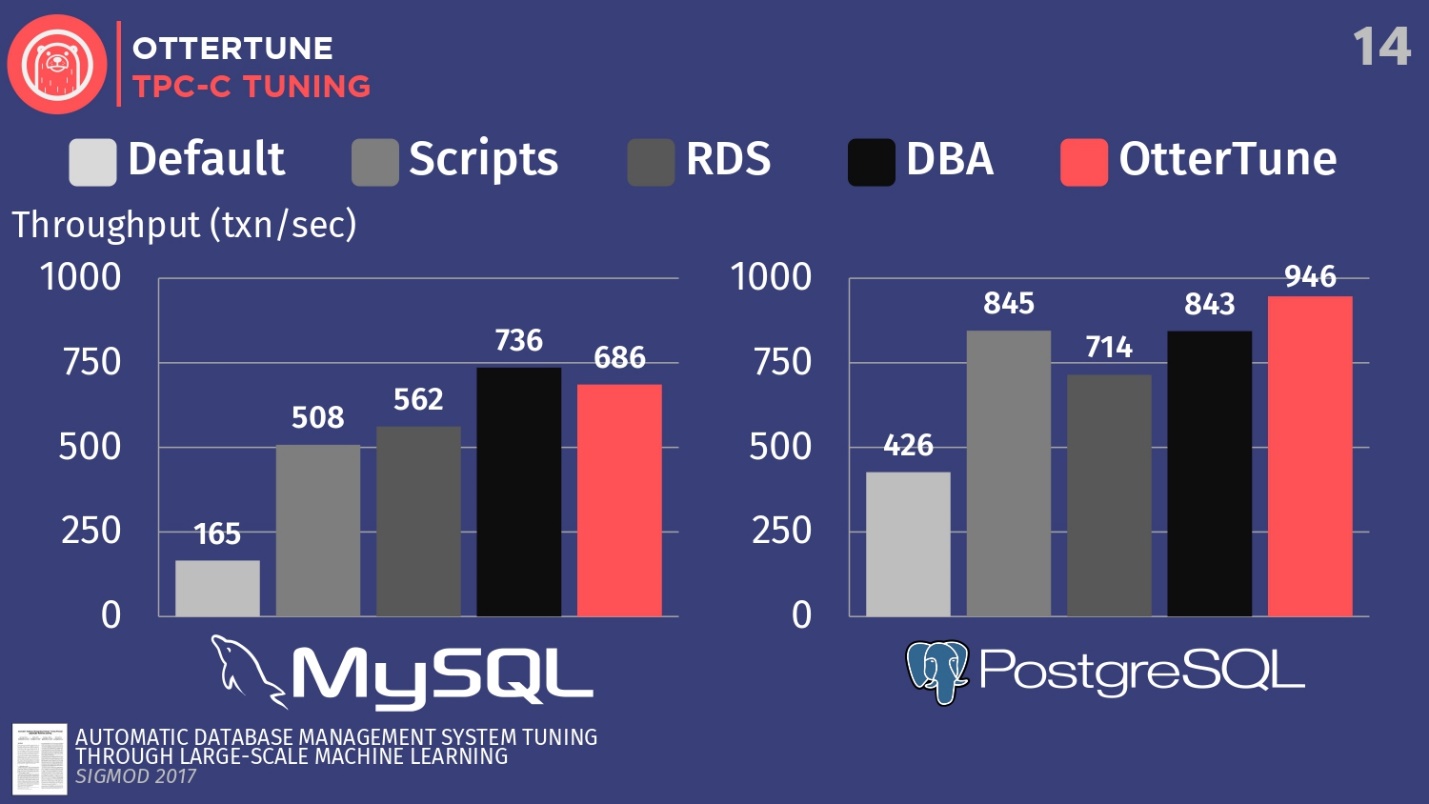
Para o MySQL, você pode ver que a configuração padrão está muito atrasada, os scripts funcionam um pouco melhor, o RDS é um pouco melhor. Nesse caso, o melhor resultado foi mostrado pelo administrador do banco de dados - o principal administrador do MySQL do Facebook.
OtterTune perdeu para o homem . Mas o fato é que existe um certo regulador que desativa a sincronização da limpeza de logs, e isso não é importante para o Facebook. No entanto, negamos o acesso a esse regulador OtterTune porque os algoritmos não sabem se você concorda em perder os últimos cinco milissegundos de dados. Em nossa opinião, essa decisão deve ser tomada por uma pessoa. Talvez o Facebook concorde com essas perdas, não sabemos disso. Se ajustarmos esse regulador da mesma maneira, podemos competir com a pessoa.
Este exemplo mostra como tentamos ser conservadores, pois a decisão final deve ser tomada pela pessoa. Porque existem certos aspectos dos bancos de dados dos quais o algoritmo ML não está ciente.
No caso do PostgreSQL, os scripts de configuração funcionam bem. RDS faz um pouco pior. Mas, é importante notar que os indicadores OtterTune superaram a pessoa. O histograma mostra os resultados obtidos após a instalação do banco de dados pelo Expert Advisor do Wisconsin Senior PostgreSQL. Neste exemplo, o OtterTune conseguiu encontrar o equilíbrio ideal entre o tamanho do arquivo de log e o tamanho do buffer pool, equilibrando a quantidade de memória usada por esses dois componentes e garantindo o melhor desempenho.
A principal conclusão é que o serviço OtterTune usa tais algoritmos e aprendizado de máquina que podemos obter o mesmo ou melhor desempenho em comparação com os DBAs muito, muito caros. E isso se aplica não apenas a uma instância do banco de dados, mas podemos dimensionar o trabalho para dezenas de milhares de cópias, porque é apenas software, apenas dados.
Peloton
O segundo projeto que eu gostaria de falar se chama Peloton. Este é um sistema de dados completamente novo que construímos do zero na Carnegie Mellon. Chamamos isso de DBMS autogerenciado.
A idéia é descobrir quais mudanças para melhor podem ser feitas se você controlar toda a pilha de software. Como melhorar as configurações do que o OtterTune pode, devido ao conhecimento sobre cada fragmento do sistema, sobre todo o ciclo do programa.

Como funcionará: integramos os
componentes do aprendizado de máquina com reforço ao sistema de banco de dados e podemos observar todos os aspectos de seu comportamento em tempo de execução e, em seguida, dar recomendações. E não estamos limitados a recomendações sobre o ajuste de reguladores, como acontece no serviço OtterTune, gostaríamos de executar todo o conjunto padrão de ações de que falei anteriormente: seleção de índices, escolha de esquemas de partição, dimensionamento vertical e horizontal, etc.
É provável que o nome do sistema Peloton mude. Não sei como na Rússia, mas nos EUA, o termo " peloton" significa "destemido" e "final", e em francês significa "pelotão". Mas nos EUA há uma empresa de bicicletas ergométricas da Peloton que tem muito dinheiro. Toda vez que uma menção a eles aparece, por exemplo, a abertura de uma nova loja ou um novo anúncio na TV, todos os meus amigos escrevem para mim: "Olha, eles roubaram sua ideia, roubaram seu nome". Os anúncios mostram pessoas bonitas que andam de bicicleta ergométrica e simplesmente não podemos competir com isso. E, recentemente, o Uber anunciou um novo planejador de recursos chamado Peloton, para que não possamos mais chamá-lo de nosso sistema. Mas ainda não temos um novo nome, portanto, nesta história, ainda usarei a versão atual do nome.Considere como esse sistema funciona em um nível alto. Por exemplo, pegue o banco de dados de destino, repito, este é o nosso software, é com isso que trabalhamos. Coletamos o mesmo histórico de carga de trabalho que mostrei anteriormente. A diferença é que vamos gerar modelos de previsão que nos permitem prever quais serão os futuros ciclos de carga de trabalho, quais serão os requisitos futuros de carga de trabalho. É por isso que chamamos esse sistema de DBMS autogerenciado.
A idéia básica de um DBMS autogerenciado é semelhante à idéia de um carro com controle automático.
Um veículo não tripulado olha à sua frente e pode ver o que está localizado à sua frente na estrada, pode prever como chegar ao seu destino. Um sistema de banco de dados independente funciona da mesma maneira. Você deve poder olhar para o futuro e tirar conclusões sobre a aparência da carga de trabalho em uma semana ou uma hora. Em seguida, passamos esses dados previstos para o componente de planejamento - chamamos de cérebro - rodando no fluxo tensor.
O processo ecoa o trabalho do AlphaGo de Londres como parte do projeto Google Deep Mind, no nível superior, tudo funciona em um cenário semelhante: Monte Carlo pesquisa a árvore, o resultado da pesquisa são várias ações que devem ser executadas para alcançar o objetivo desejado.
O algoritmo a seguir determina aproximadamente o esquema de operação:
- Os dados de origem são um conjunto de ações necessárias, por exemplo, excluir um índice, adicionar um índice, dimensionamento vertical e horizontal e similares.
- Uma sequência de ações é gerada, o que leva à realização da função objetiva máxima.
- Todos os critérios, exceto o primeiro, são descartados e as alterações são aplicadas.
- O sistema analisa o efeito resultante e o processo se repete novamente.

Não recorra constantemente à metáfora de um carro não tripulado, mas é assim que eles funcionam. Isso é chamado de horizonte de planejamento.
Depois de olhar para o horizonte na estrada, estabelecemos um ponto imaginário para alcançar e depois começamos a planejar uma sequência de ações para alcançar esse ponto no horizonte: acelerar, diminuir a velocidade, virar à esquerda, virar à direita, etc. Em seguida, descartamos mentalmente todas as ações, exceto a primeira que precisa ser executada, executamos e repetimos o processo novamente. Os UAVs executam esse algoritmo 30 vezes por segundo. Para bancos de dados, esse processo é um pouco mais lento, mas a ideia permanece a mesma.
Decidimos criar nosso próprio sistema de banco de dados a
partir do zero, em vez de criar algo sobre o PostgreSQL ou MySQL , porque, para ser sincero, eles são muito lentos em comparação com o que gostaríamos de fazer. O PostgreSQL é lindo, eu adoro e uso nos meus cursos universitários, mas leva muito tempo para criar índices, porque todos os dados vêm de discos.
Em analogias com automóveis, um DBMS autônomo no PostgreSQL pode ser comparado com um vagão não tripulado. O caminhão será capaz de reconhecer o cachorro em frente à estrada e contorná-lo, mas não se ele correr para a estrada diretamente em frente ao carro. Então uma colisão é inevitável, porque o caminhão não é suficientemente manobrável. Decidimos criar um sistema do zero para poder aplicar as alterações o mais rápido possível e descobrir qual é a configuração correta.
Agora, resolvemos o primeiro problema e publicamos
um artigo sobre a combinação de aprendizado profundo e regressão linear clássica para seleção automática e previsão de cargas de trabalho.
Mas há um problema maior, para o qual ainda não temos uma boa solução -
catálogos de ações . A questão não é como escolher ações, porque os caras da Microsoft já fizeram isso. A questão é como determinar se uma ação é melhor que outra, em termos do que acontece antes e depois da implantação. Como reverter uma ação se o índice criado pelo comando de uma pessoa não é o ideal, como você pode cancelar essa ação e indicar o motivo do cancelamento. Além disso, existem várias outras tarefas em termos de interação de nosso próprio sistema com o mundo exterior, para as quais ainda não temos uma solução, mas estamos trabalhando nelas.
A propósito, contarei uma história divertida sobre uma empresa de banco de dados bem conhecida. Esta empresa tinha uma ferramenta de seleção automática de índice, e a ferramenta tinha um problema. Um cliente cancelou constantemente todos os índices que a ferramenta recomendou e aplicou. Esse cancelamento ocorreu com tanta frequência que a ferramenta travou. Ele não sabia qual deveria ser a estratégia adicional de comportamento, porque qualquer solução oferecida a uma pessoa recebia uma avaliação negativa. Quando os desenvolvedores se voltaram para o cliente e perguntaram: "Por que você cancela todas as recomendações e sugestões sobre os índices?", O cliente respondeu que simplesmente não gostava dos nomes. As pessoas são estúpidas, mas você tem que lidar com elas. E para esse problema, também não tenho solução.Projetando um DBMS autônomo
Dadas duas abordagens diferentes para a criação de sistemas de banco de dados autônomos, vamos falar agora sobre como projetar um DBMS para que seja autônomo.
Vamos nos debruçar sobre três tópicos:
- como ajustar os reguladores,
- como coletar métricas internas,
- como projetar ações.
Mais uma vez, voltemos aos pontos principais: o sistema de banco de dados deve fornecer as informações corretas aos algoritmos de aprendizado de máquina para a adoção subsequente de melhores decisões. A quantidade de dados inúteis que transmitimos deve ser reduzida para aumentar a velocidade de recebimento de respostas.
, , , .
PG_SETTINGS , .
, , , .. , .
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , .

, , , .
, , open source. , .
, ,
. MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — ., , , Oracle. , .
,
— , , , - .
—
, . , , , 2000- . , Oracle , . , : , — - .
, . , , .
—
. , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .