
O artigo é mais técnico do que sobre negócios, mas também tiraremos algumas conclusões do ponto de vista dos negócios. Será dada mais atenção à comparação automática de mercadorias de diferentes fontes.
O trabalho da loja online consiste em um número bastante grande de componentes. E não importa qual seja o plano, obter lucro agora ou crescer e procurar investidores, ou, por exemplo, desenvolver áreas relacionadas, pelo menos você deve fechar estas perguntas:
- Trabalhe com fornecedores. Para vender algo desnecessário, você deve primeiro comprar algo desnecessário.
- Gerenciamento de Diretório. Alguém tem uma especialização estreita, enquanto alguém vende centenas de milhares de mercadorias diferentes.
- Gerenciamento de preços de varejo. Aqui você terá que levar em consideração os preços dos fornecedores, os preços dos concorrentes e os instrumentos financeiros acessíveis.
- Trabalhe com o armazém. Em princípio, é possível não ter seu próprio armazém, mas retirar as mercadorias dos armazéns dos parceiros, mas de uma forma ou de outra a questão é.
- Marketing. Aqui, o site é preenchido com conteúdo, posicionamento em sites, publicidade (online e offline), promoções e muito mais.
- Recepção e processamento de pedidos. Central de atendimento, cesta no site, pedidos através de mensagens instantâneas, pedidos através de plataformas e mercados.
- Entrega.
- Contabilidade e outros sistemas internos.
A loja, sobre a qual falaremos, não tem uma especialização estreita, mas oferece um monte de tudo, de cosméticos a um mini-trator. Vou lhe dizer como trabalhamos com fornecedores, monitorando concorrentes, gerenciamento de catálogos e preços (atacado e varejo), trabalhando com clientes atacadistas. Um pequeno toque no tópico do armazém.
Para entender melhor algumas das soluções técnicas, não será supérfluo saber que, em
em algum momento, decidimos que coisas tecnológicas, se possível, seriam feitas não por nós mesmos, mas por universais. E, talvez, depois de várias tentativas, ele saia para desenvolver um novo negócio. Acontece que, condicionalmente, uma startup dentro da empresa.
Portanto, estamos considerando um sistema separado, mais ou menos universal, com o qual o restante da infraestrutura da empresa está integrado.
Qual é o problema de trabalhar com fornecedores?
E existem muitos deles, de fato. Só para dar um pouco:
- Existem muitos fornecedores em si. Temos cerca de 400. Todo mundo precisa de um tempo.
- Não existe uma maneira única de obter ofertas de fornecedores. Alguém envia para o correio dentro do prazo, alguém sob solicitação, alguém envia para a hospedagem de arquivos, alguém coloca no site. Existem várias maneiras, até o envio do arquivo pelo skype.
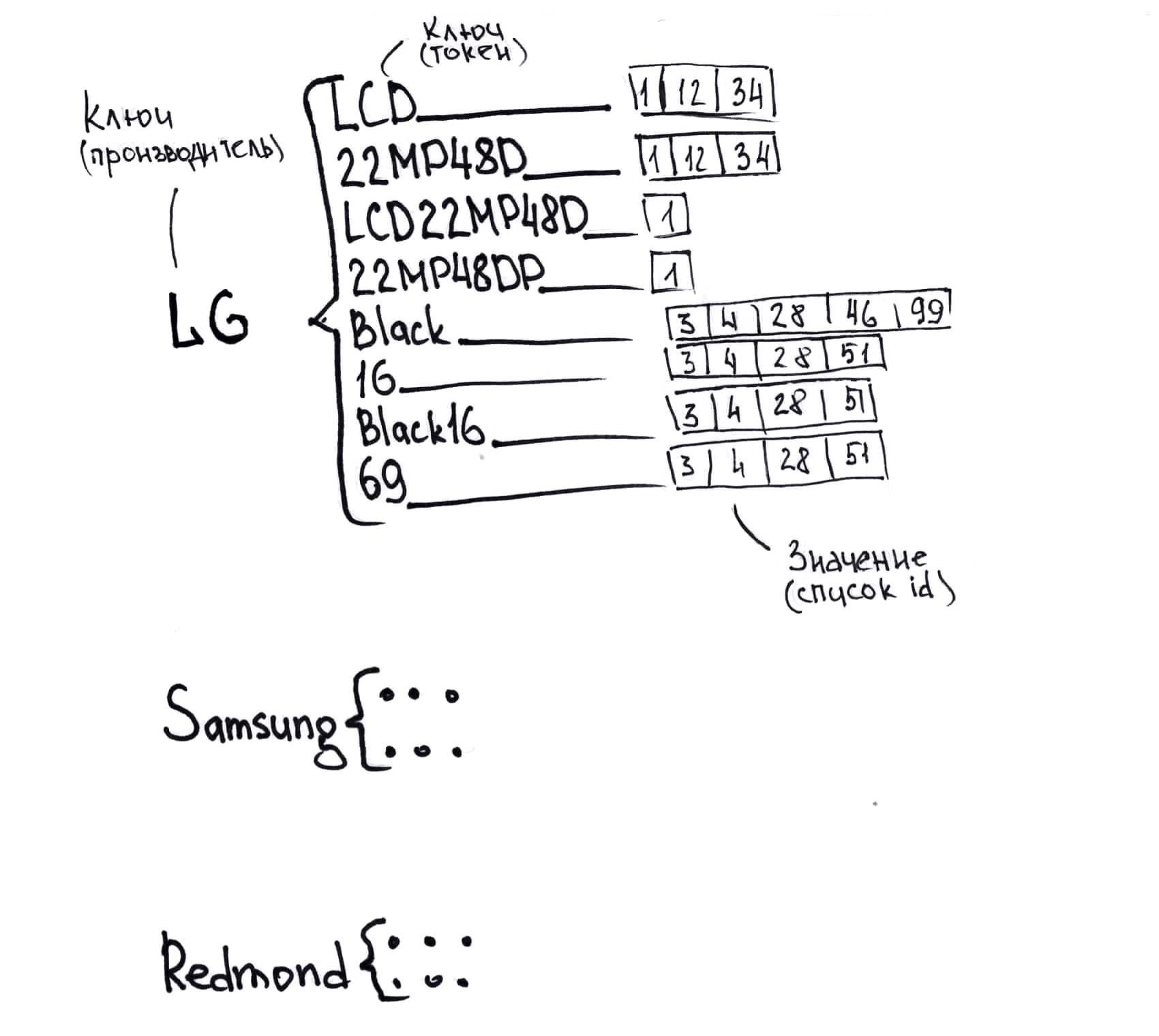
- Não há um formato de dados único. Até tirei uma foto sobre esse assunto (é mais baixo, as tabelas simbolizam diferentes formatos).
- Existe o conceito de preços mínimos de varejo e atacado mínimos que devem ser observados para continuar trabalhando com o fornecedor. Muitas vezes, eles são fornecidos em seu próprio formato.
- A nomenclatura de cada fornecedor é diferente. Como resultado, o mesmo produto é chamado de maneira diferente e não existe uma chave única com a qual eles possam ser comparados facilmente. Portanto, nós comparamos isso difícil.
- O sistema de fazer um pedido com o fornecedor não é automatizado. Solicitamos de alguém no Skype, de alguém da sua conta, para alguém que enviamos um arquivo exel todas as noites com uma lista de pedidos.

Nós aprendemos a lidar com esses problemas. Além do último, o trabalho sobre o último está em andamento. Agora haverá detalhes técnicos e considere a lista a seguir.
Coletando dados
Como estava
Os arquivos do fornecedor foram coletados manualmente de várias fontes e preparados. A preparação incluiu renomear de acordo com um modelo específico e editar o conteúdo. Dependendo do arquivo, era necessário remover mercadorias não padronizadas, mercadorias que não estão em estoque, renomear colunas ou converter moeda, coletar dados de diferentes guias em uma.
Como
Antes de tudo, aprendemos a checar e-mails e receber cartas com anexos de lá. Em seguida, eles automatizaram o trabalho com links diretos e links para os drives Yandex e Google. Isso resolveu o problema de receber ofertas de aproximadamente 75% de nossos fornecedores. Também percebemos que é através desses canais que as ofertas são atualizadas com mais frequência, para que o percentual real de automação seja maior. Ainda temos alguns preços em mensageiros.
Em segundo lugar, não processamos mais arquivos manualmente. Para isso, inserimos perfis de fornecedores, nos quais você pode especificar qual coluna e guia usar, como determinar a moeda e disponibilidade, tempo de entrega e o cronograma de trabalho do fornecedor.
Acabou sendo flexível. Naturalmente, não levamos tudo em conta na primeira vez, mas agora há flexibilidade suficiente para configurar o processamento de todos os 400 provedores, já que todos têm diferentes formatos de arquivo.
Quanto aos formatos de arquivo, entendemos xls, xlsx, csv, xml (yml). No nosso caso, isso foi suficiente.
Eles também descobriram como filtrar registros. Fizemos uma lista de palavras de parada e, se a oferta do fornecedor a contiver, não a processamos. Os detalhes técnicos são os seguintes: em uma pequena lista, você pode, e ainda melhor "de frente", em grandes listas, um filtro Bloom mais rápido. Experimentamos com ele e deixamos tudo como está, porque o ganho é sentido na lista em uma ordem de magnitude maior que a nossa.
Outra coisa importante é o cronograma de trabalho do fornecedor. Nossos fornecedores trabalham com horários diferentes, além disso, estão localizados em países diferentes, nos quais os finais de semana não coincidem. E o tempo de entrega geralmente é indicado como um número ou intervalo de números em dias úteis. Quando formamos os preços de varejo e atacado, teremos que avaliar de alguma forma o tempo em que podemos entregar a mercadoria ao cliente. Para isso, criamos calendários configuráveis e, nas configurações de cada provedor, você pode especificar em qual dos calendários trabalha.
Eu tive que fazer uma configuração de descontos e margens, dependendo da categoria e do fabricante. Acontece que o fornecedor possui um arquivo comum para todos os parceiros, mas existem contratos de desconto com alguns parceiros. Graças a isso, ainda era possível adicionar ou subtrair o IVA, se necessário.
A propósito, a configuração das regras de desconto e marcação nos leva ao próximo tópico. Afinal, antes de usá-los, você precisa descobrir que tipo de produto é.
Como o mapeamento funciona
Um pequeno exemplo de como o mesmo produto pode ser chamado de diferentes fornecedores, para entender com o que você deve trabalhar:
Monitor LG LCD 22MP48D-P
LG 22MP48D-P de 21,5 "preto (16: 9, 1920x1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Periféricos de computador - Monitores LG 22MP48D-P
monitor LG inclusivo de 22 "LG 22MP48D-P (21,5", preto, IPS LED 5ms 16: 9 DVI fosco 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Monitores LG 22 "LG 22MP48D-P preto brilhante (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI)
Monitores LCD LG Monitor LCD 22 "IPS 22MP48D-P LG 22MP48D-P
LG Monitor 21,5 "LG 22MP48D-P gl. IPS preto, 1920x1080, 5ms, 250 cd / m2, 1000: 1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
LG Monitor LG 22MP48D-P Preto 22MP48D-P.ARUZ
Monitor LG 22MP48D-P 22MP48D-P
Monitores LG 22MP48D-P Brilhante-Preto 22MP48D-P
Monitor 21,5 "LG Flatron 22MP48D-P gl. Preto (IPS, 1920x1080, 16: 9, 178/178, 250cd / m2, 1000: 1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Monitor 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21,5 "22MP48D-P IPS LED, 1920x1080, 5ms, 250cd / m2, 5Mln: 1, 178 ° / 178 °, D-Sub, DVI, inclinação, VESA, preto brilhante 22MP48D-P
LG 21,5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Monitor 21.5 '' LG 22MP48D-P Preto
LG MONITOR 21,5 "LG 22MP48D-P preto brilhante (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) 22MP48D-P
Monitor LCD da LG 21,5 '' [16: 9] IPS 1920x1080 (FHD), não-BRANCO, 250cd / m2, H178 ° / V178 °, 1000: 1, 16,7M cores, 5ms, VGA, DVI, inclinação, 2Y, preto OK 22MP48D -P
LCD LG 21,5 "22MP48D-P preto {LED IPS 1920x1080 5ms 16: 9 250cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitores LG LG 22 "LCD 22MP48D 22MP48D-P
21,5 "16x9 LG Monitor LG 21,5" 22MP48D-P preto IPS LED 5ms 16: 9 DVI fosco 250cd 1920x1080 D-Sub FHD 2,7kg 22MP48D-P.ARUZ
Monitor 21,5 "LG 22MP48D-P [Preto]; 5ms; 1920x1080, DVI, IPS
Como estava
A comparação envolveu 1C (módulo pago de terceiros). Quanto à conveniência / velocidade / precisão, esse sistema possibilitou a manutenção de um catálogo com 60 mil produtos disponíveis nesse nível por 6 pessoas. Ou seja, todos os dias desatualizados e desapareceram das ofertas dos fornecedores, tantos produtos correspondentes quanto novos foram criados. Muito aproximadamente - 0,5% do tamanho do catálogo, ou seja, 300 produtos.
Como se tornou: uma descrição geral da abordagem
Um pouco mais alto, dei um exemplo do que precisamos igualar. Explorando o tópico da correspondência, fiquei um pouco surpreso que o ElasticSearch seja popular para a tarefa de correspondência, na minha opinião, possui limitações conceituais. Quanto à nossa pilha de tecnologia, usamos o MS SQL Server para armazenamento de dados, mas a comparação funciona em nossa própria infraestrutura e, como há muitos dados e precisamos processá-los rapidamente, usamos estruturas de dados otimizadas para uma tarefa específica e tentamos não acessar o disco ou o banco de dados sem a necessidade e outros sistemas lentos.
Obviamente, o problema de comparação pode ser resolvido de várias maneiras e, obviamente, nenhuma delas fornecerá precisão absoluta. Portanto, a idéia principal é tentar combinar esses métodos, classificá-los por precisão e velocidade e aplicá-los em ordem decrescente de precisão, levando em consideração a velocidade.
O plano de execução para cada um de nossos algoritmos (com uma reserva sobre casos degenerados) pode ser brevemente representado pela seguinte seqüência geral:
Tokenização Dividimos a linha da fonte em partes independentes significativas. Isso pode ser feito uma vez e mais utilizado em todos os algoritmos.
Normalização de tokens. De uma maneira boa, você precisa trazer as palavras da linguagem natural para o número e declinação geral, e identificadores como “ABC15MX” (isto é cirílico, se houver) devem ser convertidos para latim. E traga tudo para o mesmo registro.
Categorização de token. Tentando entender o que cada parte significa. Por exemplo, você pode selecionar uma categoria, fabricante, cor e assim por diante.
Procure o melhor candidato para uma partida.
Uma estimativa da probabilidade de que a linha original e o melhor candidato indiquem o mesmo produto.
Os dois primeiros pontos são comuns a todos os algoritmos atualmente disponíveis e, em seguida, as improvisações começam.
Tokenização Aqui fizemos exatamente isso, dividimos a linha em partes de acordo com caracteres especiais como espaço, barra e assim por diante. O conjunto de caracteres ao longo do tempo acabou sendo significativo, mas não usamos nada complicado no próprio algoritmo.
Então precisamos normalizar os tokens. Converta-os em minúsculas. Em vez de levar tudo ao caso nominativo, simplesmente cortamos os finais. Também temos um pequeno dicionário e traduzimos nossos tokens para o inglês. Entre outras coisas, a tradução nos salva de sinônimos, com significado semelhante. As palavras em russo são traduzidas para o inglês da mesma maneira. Onde falhamos na tradução, alteramos os caracteres cirílicos parecidos com a ortografia para o alfabeto latino. (Não é de todo supérfluo, como se viu. Mesmo onde você não espera um truque sujo, por exemplo, na linha "Samsung U43NU7100U", o cirílico E pode atender).

Categorização de token. Podemos destacar a categoria, fabricante, modelo, artigo, EAN, cor. Temos um diretório onde os dados estão estruturados. Temos dados sobre concorrentes que as plataformas de negociação nos fornecem. Ao processá-los, sempre que possível, estruturamos os dados. Podemos corrigir erros ou erros de digitação, por exemplo, o fabricante ou a cor, que ocorrem apenas uma vez em todas as nossas fontes, para não considerar o fabricante e a cor, respectivamente. Como resultado, temos um grande dicionário de possíveis fabricantes, modelos, artigos, cores e categorização de tokens, apenas uma pesquisa de dicionário para O (1). Teoricamente, você pode ter uma lista aberta de categorias e algum tipo de algoritmo de classificação inteligente, mas nossa abordagem básica funciona bem e a categorização não é um gargalo.
Deve-se observar que, às vezes, o fornecedor já fornece dados estruturados, por exemplo, o artigo está em uma célula separada da tabela ou o fornecedor faz um desconto no varejo nas vendas no atacado, e os preços no varejo podem ser obtidos no formato yml (xml). Em seguida, salvamos a estrutura de dados e dividimos heuristicamente os tokens em categorias apenas a partir de dados não estruturados.
E agora sobre quais algoritmos e em que ordem usamos.
Correspondências exatas e quase exatas
O caso mais simples. As linhas foram divididas em fichas, elas as levaram a uma forma. Em seguida, eles criaram uma função de hash que não é sensível à ordem dos tokens. Além disso, combinando por hash, podemos manter todos os dados na memória, podemos pagar 16 megabytes por dicionário com um milhão de chaves. Na prática, o algoritmo teve um desempenho melhor do que simples comparações de strings.
Quanto ao hash, o uso de "exclusivo ou" se sugere, e uma função como esta:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
A coisa mais interessante nessa fase é obter um hash de uma única linha. Na prática, verificou-se que 32 bits são pequenos, muitas colisões são obtidas. E também - como você não pode simplesmente pegar o código fonte da função da estrutura e alterar o tipo do valor de retorno, há menos colisões para linhas individuais, mas após o "exclusivo ou" elas ainda ocorrerem, escrevemos a nossa. De fato, eles simplesmente adicionaram à função a partir da estrutura de não linearidade dos dados de entrada. Definitivamente foi melhor, com a nova função com uma colisão, nos encontramos apenas uma vez em nossos milhões de discos, gravados e adiados para tempos melhores.
Assim, procuramos correspondências sem levar em consideração a ordem das palavras e sua forma. Essa pesquisa funciona para O (1).
Infelizmente, raramente, mas também acontece: “ABC 42 Type 16” e “ABC 16 Type 42”, e esses são dois produtos diferentes. Também aprendemos a lidar com essas coisas, mas mais sobre isso mais tarde.
Produtos humanos confirmados correspondentes
Temos produtos com correspondência manual (na maioria das vezes são produtos com correspondência automática, mas que foram verificados manualmente). De fato, estamos fazendo a mesma coisa neste caso, apenas agora adicionamos um dicionário de hashes correspondentes, cuja pesquisa não alterou a complexidade de tempo do algoritmo.
As linhas correspondidas manualmente simplesmente estão no banco de dados; no caso, esses dados brutos permitirão alterar o algoritmo de hash no futuro, recalcular tudo e não perder nada.
Mapeamento de Atributos
Os dois primeiros algoritmos são rápidos e precisos, mas não o suficiente. Em seguida, aplicamos a correspondência de atributos.
Anteriormente, já apresentávamos os dados na forma de tokens normalizados e até os classificávamos em categorias. Neste capítulo, chamo atributos de categorias de token.
O atributo mais confiável é o EAN (https://ru.wikipedia.org/wiki/European_Article_Number). As correspondências EAN oferecem quase 100% de garantia de que são o mesmo produto. A incompatibilidade de EAN, no entanto, não diz nada, porque um produto pode ter EANs diferentes. Tudo ficaria bem, mas em nossos dados o EAN é raro, portanto, sua influência na comparação no nível de erro.
O artigo é menos confiável. Algo estranho geralmente obtém diretamente dos dados estruturados do fornecedor, mas, em qualquer caso, nesse estágio, nós os usamos.
Como no último estágio, aqui usamos dicionários (procure por O (1)), e o hash de (fabricante + modelo + artigo) é usado como chave. O hash permite executar todas as operações na memória. Nesse caso, também levamos em conta a cor, se ela corresponde ou não existe, acreditamos que a mercadoria coincidiu.
Procure a melhor correspondência
As etapas anteriores eram simples, rápidas e razoavelmente confiáveis, mas infelizmente cobrem menos da metade das comparações.
Na busca pela melhor correspondência, existe uma idéia simples: a coincidência de tokens raros tem um peso grande, a coincidência de tokens frequentes é pequena. Os tokens que contêm números têm mais valor que os tokens de letras. Os tokens que correspondem na mesma ordem têm mais valor que os tokens reorganizados. Partidas longas são melhores que as curtas.
Agora resta criar uma estrutura de dados rápida que possa levar tudo isso em consideração ao mesmo tempo e se encaixe na memória de um diretório de alguns milhões de registros.
Tivemos a ideia de apresentar nosso catálogo na forma de um dicionário de dicionários; no primeiro nível, a chave será um hash do fabricante (os dados no catálogo são estruturados, conhecemos o fabricante), o valor é o dicionário. Agora o segundo nível. A chave no segundo nível será o hash do token, o valor é a lista de itens de identificação do catálogo em que esse token é encontrado. E, nesse caso, usamos a inclusão de combinações de tokens na ordem em que aparecem em nosso catálogo. Decidimos o que usar como uma combinação e o que não é, dependendo do número de tokens, seu comprimento e assim por diante, esse é um compromisso entre velocidade, precisão e memória necessária. Na figura, simplifiquei essa estrutura, sem hashes e sem normalização.
Se, em média, 20 tokens forem usados para cada produto, em nossas listas, que possuem os valores do dicionário incluído, um link para o produto ocorrerá em média 20 vezes. Não haverá mais de 20 vezes tokens diferentes do que existem mercadorias no catálogo. Aproximadamente, você pode calcular a memória necessária para um catálogo de um milhão de registros: 20 milhões de chaves, 4 bytes cada, 20 milhões de identificação do produto 4 bytes cada, sobrecarga para organizar dicionários e listas (a ordem é a mesma, mas desde o tamanho das listas e dicionários) não sabemos antecipadamente, mas aumentamos em movimento, multiplique por dois). Total - 480 megabytes. Na realidade, resultou um pouco mais de tokens para mercadorias, e precisamos de até 800 megabytes por catálogo em um milhão de mercadorias. O que é aceitável, os recursos do ferro moderno permitem armazenar simultaneamente na memória mais de uma centena de diretórios desse tamanho.
De volta ao algoritmo. Tendo uma string que precisamos corresponder, podemos determinar o fabricante (temos um algoritmo de categorização) e, em seguida, obter tokens usando o mesmo algoritmo que para mercadorias do catálogo. Aqui quero dizer, incluindo combinações de tokens.
Então tudo é relativamente simples. Para cada token, podemos encontrar rapidamente todos os produtos nos quais ele é encontrado, estimar o peso de cada correspondência, levando em conta tudo o que falamos anteriormente - duração, frequência, presença de números ou caracteres especiais e avaliar a “similaridade” de todos os candidatos encontrados. Na realidade, também há otimizações aqui, não consideramos todos os candidatos, primeiro criamos uma pequena lista de correspondências de tokens com um peso grande e não aplicamos correspondências de tokens com um peso baixo em todos os produtos, mas apenas nesta lista.
Selecionamos a melhor correspondência, observamos a coincidência dos tokens que acabaram sendo categorizados e consideramos a pontuação da comparação. Além disso, temos dois valores-limite P1 e P2, P1 <P2. Se a avaliação for superior ao valor limite P2 - a participação humana não é necessária, tudo acontece automaticamente. Se estiver entre dois valores - oferecemos ver a comparação manualmente, antes disso ela não participará dos preços. Se menos de P1 - provavelmente esse produto não está no catálogo, não devolvemos nada.
Volte às linhas “ABC 42 Type 16” e “ABC 16 Type 42”. A solução é surpreendentemente simples - se vários produtos tiverem os mesmos hashes, não os combinaremos por hash. E o último algoritmo levará em conta a ordem dos tokens. Teoricamente, essas linhas na lista de preços do fornecedor não podem ser combinadas com nada arbitrário, onde os números 16 e 42 não ocorrem de forma alguma. De fato, não encontramos tal necessidade.
Velocidade e precisão
Agora, para a velocidade de tudo. O tempo necessário para preparar os dicionários linearmente depende do tamanho do catálogo. O tempo necessário diretamente para a comparação depende linearmente do número de mercadorias que estão sendo comparadas. Todas as estruturas de dados envolvidas na pesquisa não são alteradas após a criação. Isso nos dá a oportunidade de usar o multithreading no estágio correspondente. O trabalho preparatório para o catálogo de um milhão de registros leva cerca de 40 a 80 segundos. A comparação funciona a uma velocidade de 20 a 40 mil registros por segundo e não depende do tamanho do diretório. Então, no entanto, você precisa salvar os resultados. A abordagem escolhida geralmente é benéfica para grandes volumes, mas um arquivo com uma dúzia de registros será desproporcionalmente longo. Portanto, usamos o cache e recontamos nossas estruturas de pesquisa uma vez a cada 15 minutos.
É verdade que os dados para comparação precisam ser lidos em algum lugar (na maioria das vezes, esse é um arquivo do Excel), e as frases correspondentes precisam ser salvas em algum lugar, e isso também leva tempo. Portanto, o número total é de 2 a 4 mil registros por segundo.
Para avaliar a precisão, preparamos um conjunto de testes de aproximadamente 20.000 comparações verificadas manualmente de diferentes fornecedores de diferentes categorias. Após cada alteração, o algoritmo foi testado nesses dados. Os resultados são os seguintes:
- os produtos estão no catálogo e foram comparados corretamente - 84%
- o produto está no catálogo, mas não foi correspondido, é necessária correspondência manual - 16%
- as mercadorias estão no catálogo e foram comparadas incorretamente - 0,2%
- o produto não está no catálogo e o programa o identificou corretamente - 98,5%
- o produto não está no catálogo, mas o programa correspondeu a um dos produtos - 1,5%
Em 80% dos casos em que o produto foi correspondido, a confirmação manual não é necessária (confirmamos automaticamente a comparação), entre essas ofertas confirmadas automaticamente estão 0,1% de erros.
A propósito, 0,1% dos erros é muito, ao que parece. Para um milhão de registros correspondentes, são mil registros correspondentes incorretamente. E isso é muito porque os compradores encontram exatamente esses registros melhores. Bem, como não pedir um trator pelo preço dos faróis deste trator. No entanto, esses milhares de erros estão no início do trabalho em um milhão de propostas, eles foram gradualmente corrigidos. A quarentena por preços suspeitos, que encerra esse problema, apareceu mais tarde, nos primeiros dois meses em que trabalhamos sem ela.
Há outra categoria de erros que não está relacionada à comparação: esses são os preços incorretos de nossos fornecedores. É em parte por isso que não consideramos o preço em comparação. Decidimos que, como possuímos informações adicionais na forma de um preço, usá-las para tentar determinar não apenas nossos próprios erros, mas também os de outros.
Procure os preços errados
Esta é a parte em que estamos experimentando ativamente. A versão básica é e não permite que você venda o telefone pelo preço de um estojo, mas tenho a sensação de que é melhor.
Para cada produto, encontramos os limites de preços aceitáveis para fornecedores. Dependendo dos dados disponíveis, levamos em consideração os preços dos fornecedores deste produto, os preços dos concorrentes, os preços dos fornecedores de produtos deste fabricante nesta categoria. Os preços que não caem dentro das fronteiras são colocados em quarentena e ignorados em todos os nossos algoritmos. Manualmente, você pode marcar um preço suspeito como normal, lembramos disso para este produto e recontamos os limites de preços aceitáveis.
O algoritmo direto para calcular os preços máximos e mínimos aceitáveis agora está mudando constantemente. Estamos procurando um compromisso entre o número de falsos positivos e o número de preços incorretos detectados.
Usamos valores medianos nos cálculos (as médias dão o pior resultado) e ainda não analisamos a forma de distribuição. A análise da forma de distribuição é apenas o local onde, ao que me parece, o algoritmo pode ser aprimorado.
Trabalhar com o banco de dados
Com base no exposto, podemos concluir que atualizamos os dados sobre fornecedores e concorrentes com frequência e de várias maneiras, e trabalhar com o banco de dados pode se tornar um gargalo. Em princípio, inicialmente chamamos a atenção para isso e tentamos alcançar o desempenho máximo. Ao trabalhar com um grande número de registros, fazemos o seguinte:
- excluímos índices da tabela com a qual trabalhamos
- desativar a indexação de texto completo nesta tabela
- excluir todos os registros com uma determinada condição (por exemplo, todas as ofertas de fornecedores específicos que estamos processando no momento)
- insira novos registros com BULK COPY
- recriar índices
- ativar a indexação de texto completo
A cópia em massa opera a uma velocidade de 10 a 40 mil registros por segundo, por que um spread tão grande ainda não foi visto, mas é tão aceitável.
A exclusão de registros leva aproximadamente o mesmo tempo que a inserção. Ainda é necessário algum tempo para recriar os índices.
A propósito, para cada diretório, temos um banco de dados separado. Nós os criamos rapidamente. E agora vou explicar por que temos mais de um catálogo.
Qual é o problema da catalogação
E há muitos deles também. Agora vamos listar:
- O catálogo contém cerca de 400 mil produtos de categorias completamente diferentes. É impossível entender profissionalmente cada uma das categorias.
- Você precisa seguir um certo estilo, seguir as regras gerais para o nome do catálogo, subcategorias de nomes e assim por diante. Portanto, estamos tentando obter uma estrutura de diretórios coerente e lógica.
- Você pode criar o mesmo produto várias vezes, e isso é um problema. Sem uma ferramenta que analisa nomes semelhantes, duplicatas são constantemente criadas.
- É razoável adicionar ao catálogo os bens que os fornecedores possuem em estoque. Nesse caso, você precisa ter prioridades para categorias de produtos.
- Precisamos de vários diretórios. Um de nós próprios, nós o conduzimos, o outro - o catálogo agregador, atualizamos por API. O significado do segundo catálogo é que a plataforma agregadora funciona apenas com seu próprio catálogo e, portanto, aceita ofertas em sua nomenclatura. Este é outro lugar em que você precisa de uma comparação.
Achamos lógico e correto manter um diretório no mesmo local em que as comparações são feitas. Portanto, podemos dizer aos usuários que administram o diretório o que o fornecedor possui, mas não no diretório.
Como mantemos um catálogo
Será sobre o catálogo sem características detalhadas, as características são uma grande história separada, sobre isso em outra ocasião.
Como propriedades básicas, escolhemos o seguinte:
- produtor
- categoria
- o modelo
- número do item
- cor
- Ean
Primeiro, criamos a API para obter o catálogo de uma fonte externa e, em seguida, trabalhamos na conveniência de criar, editar e excluir registros.
Como a pesquisa funciona
A conveniência de gerenciar um catálogo, em primeiro lugar, é a capacidade de encontrar rapidamente um produto em um catálogo ou na oferta de um fornecedor, e existem nuances. Por exemplo, você precisa procurar a linha "LG 21.5" 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P "para" 2MP48 ".
Uma pesquisa de servidor sql de texto completo pronta para o uso não é adequada, porque não sabe como fazê-lo, e a pesquisa com LIKE '% 2MP48%' é muito lenta.
Nossa solução é bastante padrão, usamos N-gramas. Mais precisamente, então trigramas. E já por trigramas, construímos um índice de texto completo e realizamos uma pesquisa de texto completo. Não tenho certeza de que usamos o espaço de maneira muito racional nesse caso, mas em termos de velocidade, essa solução surgiu, dependendo da solicitação, funciona de 50 a 500 milissegundos, às vezes até um segundo em uma matriz de três milhões de registros.
Deixe-me explicar, a linha “LG 21.5” 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P ”é convertida na linha“ lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22 ”, que é armazenado em um campo separado que participa do índice de texto completo.
A propósito, trigramas ainda são úteis para nós.
Crie um novo produto
Na maioria das vezes, os produtos no catálogo são criados por sugestão do fornecedor. Ou seja, já temos informações que o fornecedor oferece “LG LCD Monitor 21,5 '' [16: 9] IPS 1920x1080 (FHD), sem brilho, 250cd / m2, H178 ° / V178 °, 1000: 1, 16,7M cores, 5ms, VGA, DVI, inclinação, 2Y, preto OK 22MP48D-P ”a um preço de US $ 120, e ele tem de 5 a 10 unidades em estoque.
Ao criar um produto, primeiro, precisamos garantir que esse produto ainda não tenha sido criado no catálogo. Resolvemos esse problema em quatro etapas.
Em primeiro lugar, se tivermos um produto no catálogo, é muito provável que a proposta do fornecedor seja correspondida automaticamente a esse produto.
Em segundo lugar, antes de mostrar ao usuário o formulário para criar um novo produto, faremos uma pesquisa por trigramas e mostraremos os resultados mais relevantes. (tecnicamente, isso é feito usando CONTAINSTABLE).
Em terceiro lugar, ao preencher os campos de um novo produto, mostraremos produtos existentes semelhantes. Isso resolve dois problemas: ajuda a evitar duplicatas e mantém o estilo nos nomes; produtos similares podem ser usados como modelo.
E quarto, lembre-se, dividimos as linhas em fichas, normalizamos, contamos hashes? Faremos o mesmo e simplesmente não deixaremos criar mercadorias com os mesmos hashes.
Nesta fase, tentamos ajudar o usuário. Pela linha que está na lista de preços, tentaremos determinar o fabricante, categoria, artigo, EAN e cor dos produtos. Primeiro, por tokens (podemos dividi-los em categorias) e, se não der certo, encontraremos o produto mais semelhante por trigramas. E, se for semelhante o suficiente, preencha o fabricante e a categoria.
A edição do produto funciona quase da mesma forma, mas nem tudo é aplicável.
Como definimos nossos preços
A tarefa é a seguinte: manter um equilíbrio entre a quantidade e a margem de vendas, de fato - para obter o lucro máximo. Todos os outros aspectos do trabalho da loja também são sobre isso, mas exatamente o que acontece na fase de precificação tem o maior impacto.
No mínimo, precisaremos de informações sobre ofertas de fornecedores e concorrentes. Também vale a pena considerar os preços mínimos de varejo e atacado e os custos de entrega, além de instrumentos financeiros - empréstimos e parcelamentos.
Coletamos preços de concorrentes
Para começar, temos muitos perfis de nossos próprios preços. Há um perfil para o varejo, há vários para clientes no atacado. Todos eles são criados e configurados em nosso sistema.
Por conseguinte, os concorrentes para cada perfil são diferentes. No varejo - outras lojas de varejo, nas vendas no atacado - nossos mesmos fornecedores.
Tudo fica claro para os fornecedores, mas para o varejo, coletamos os dados dos concorrentes de várias maneiras. Em primeiro lugar, alguns agregadores fornecem informações sobre todos os preços de todos os produtos que estão no site. Em nossa própria nomenclatura, mas podemos combinar produtos, para que funcione automaticamente. E isso é quase o suficiente por enquanto. Em segundo lugar, temos analisadores de concorrentes. Como eles ainda não são automatizados e existem na forma de aplicativos de console (que às vezes travam), raramente os usamos.
Personalize seu perfil
No perfil, temos a oportunidade de configurar diferentes faixas de margens, dependendo do preço dos produtos do fornecedor, categoria, fabricante, fornecedor. , , — , .
, , .
, -, , -. , , .
, . , .
, . , ( , , , ) .
, ( ) .
— b2b . , .
,
. .
, : ORM, . ( EF Core API ), .
, , , .
, . , , , .
, , . , , .
, , , , , . , , .
- ASP.NET Core , Windows — .
, , , — . QRS , . , , , / / . BULK COPY. , , . , ORM, , ( ), N + 1. DTO.
ASP.NET Core, nuget- MS SQL Server. , . , , SQL Server, . , . , - .
. . , , , . CI/CD .
. , .
7 . , . .
, , 70 230 , — 60 140 . , , , . 106 40 . , , .
425 , . . — , , .
, , , . , . , . , - , , .
— , , . , . , , . , , “ ”, “ ”, , , . . . , , . — .
, , . , , , .
