Muitos que trabalharam com o Spark ML sabem que algumas das coisas que fizeram lá "não são totalmente bem-sucedidas"
ou não foi feito. A posição dos desenvolvedores do Spark é que o SparkML é a plataforma base e todas as extensões devem ser pacotes separados. Mas isso nem sempre é conveniente, porque a Data Scientist e os analistas querem trabalhar com ferramentas familiares (Jupter, Zeppelin), onde há mais do que é necessário. Eles não desejam coletar arquivos JAR de 500 megabytes com montagem maven ou fazer download de dependências em suas mãos e adicioná-los aos parâmetros de inicialização do Spark. Um trabalho melhor com os sistemas de criação de projetos da JVM pode exigir muitos esforços adicionais de analistas e DataScientists acostumados ao Jupyter / Zeppelin. Pedir que o DevOps e os administradores de cluster coloquem vários pacotes nos nós de computação é claramente uma má idéia. Qualquer pessoa que tenha escrito extensões para o SparkML por conta própria sabe quantas dificuldades ocultas existem com classes e métodos importantes (que por algum motivo são privados [ml]), restrições sobre os tipos de parâmetros armazenados etc.
E parece que agora, com a biblioteca MMLSpark, a vida será um pouco mais fácil, e o limite para entrar no aprendizado de máquina escalável com SparkML e Scala é um pouco menor.
1. Introdução
Devido a várias dificuldades, bem como a um conjunto escasso de métodos e soluções prontas no SparkML, muitas empresas escrevem suas extensões para o Spark. Um exemplo é o PravdaML , que está sendo desenvolvido em Odnoklassniki e que, a julgar por uma avaliação superficial do que está no GitHub, parece muito promissor. Infelizmente, a maioria dessas soluções geralmente é fechada ou aberta, mas não tem a capacidade de instalar através do Maven / sbt e da documentação da API, o que dificulta o trabalho com elas.
Hoje, olhamos para a biblioteca MMLSpark .
Vamos considerar, como sempre, o exemplo da tarefa de classificar os passageiros do Titanic. O objetivo é mostrar o maior número possível de recursos da biblioteca MMLSpark, não nocauteie o SOTA no ImageNet mostre aprendizado de máquina legal. Então o Titanic fará.

A própria biblioteca possui uma API nativa para Scala ( documentação ), API Python ( documentação ) e, a julgar por alguns lugares no repositório GitHub, em breve terá uma API para R.
Existem bons exemplos de laptops no projeto GitHub (PySpark + Jupyter) , mas iremos para o outro lado. Como escreveu Dmitry Bugaychenko, se você desenvolve para o Spark, ou seja, você tem todos os motivos para usar o Scala para isso, além disso, o Scala permite que você defina com muito mais eficiência e flexibilidade o seu próprio Transformer e Estimator para incorporá-los no SparkML Pipeline, mas quão lentamente numpy funciona O código / pandas em UDF (chamado de executáveis da JVM) já foi muito escrito.
Resumo da instalação
O laptop inteiro está disponível aqui . Para trabalhar com o Titanic, a imagem do Zeppelin Docker em execução localmente em um laptop com configurações padrão é suficiente para os olhos. Docker pode ser encontrado aqui . A biblioteca MMLSpark não está no Maven Central, mas nos pacotes spark e, para adicioná-lo ao Zeppelin, você deve executar o seguinte bloco no início do laptop:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
Vale dizer que a biblioteca possui excelente compatibilidade com versões anteriores: ao contrário, por exemplo, do XGBoost4j-spark, que requer um mínimo de Spark 2.3+, esse item entrou no Spark 2.2.1, que acompanha a imagem do Zeppelin Docker, e quaisquer dificuldades Eu não percebi.
Nota: a maior parte da biblioteca MMLSpark é dedicada à inferência de grades no cluster, para a qual o CNTK está presente (que, a julgar pela documentação, deve ler modelos cntk prontos) e um enorme bloco OpenCV. Vamos nos concentrar em tarefas mais comuns e tentar "simular" o caso quando tivermos enormes matrizes de dados tabulares que estão no HDFS na forma de .csv, tabelas ou em outro formato. Portanto, precisamos pré-processá-los e criar um modelo, enquanto esses dados não cabem na memória de uma máquina. Portanto, executaremos todas as ações no cluster.
Análise de Leitura e Inteligência
Em geral, o Spark + Zeppelin não é ruim e pode lidar com a tarefa da EDA, mas tentaremos expandir seus recursos. Primeiro, importamos as classes necessárias:
- Tudo no spark.sql.types para declarar um esquema e ler os dados corretamente
- Tudo a partir do spark.sql.functions para acessar colunas e usar funções internas
- com.microsoft.ml.spark.SummarizeData , que pode ser chamado de análogo de pandas.DataFrame.describe
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
Lemos o nosso arquivo:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
E agora vamos ver os dados em si, bem como seu tamanho:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
Nota: Realmente não há necessidade de usar createOrReplaceTempView quando você pode simplesmente escrever .show (5). Mas o show tem um problema: quando os dados são "amplos", a representação textual da placa "flutua" e nada fica claro.
Obtenha o tamanho dos nossos dados: A Train shape is: 891 x 12
E agora, na célula sql, podemos observar as 5 primeiras linhas:
%sql select * from trainHead
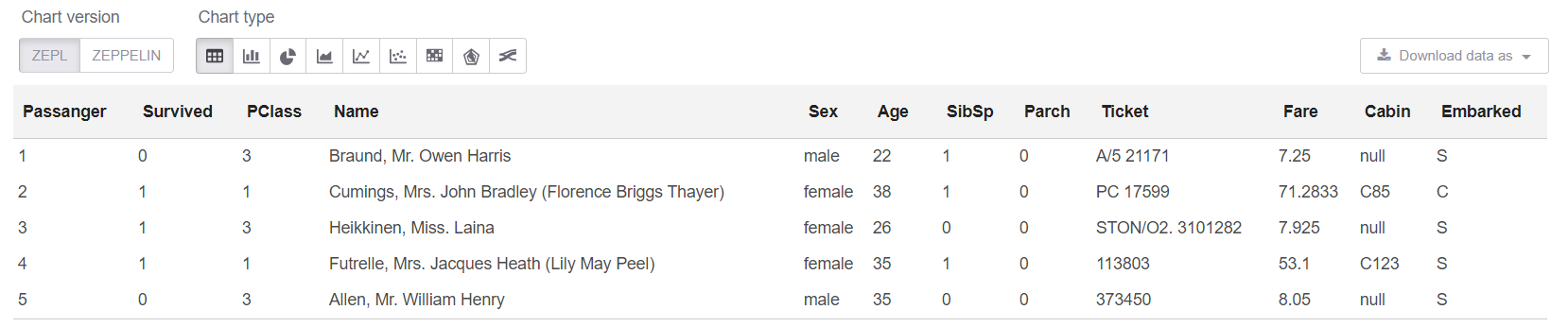
Bem, vamos ver o resumo em nossa tabela:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
A classe SummarizeData tem várias vantagens sobre o simples Dataset.describe, pois permite contar o número de valores ausentes e exclusivos e também especificar a precisão do cálculo de quantis. Isso pode ser crítico para dados realmente grandes.

Alguns pensamentos pessoaisEm geral, pessoalmente me pareceu que o Odnoklassniki no PravdaML tinha uma melhor implementação do analógico SummarizeData. A Microsoft seguiu o caminho mais fácil e usa org.apache.spark.sql.functions , apenas que tudo é convenientemente agrupado em uma única classe. Para o Odnoklassniki, isso é implementado por meio do VectorStatCollector , que requer um código um pouco mais complexo quando chamado (você deve primeiro adicionar todos os recursos a um vetor) e pode exigir operações adicionais (por exemplo, o VectorAssembler geralmente se recusa a digerir DecimalType ). Mas suponho, com base na minha experiência com o Spark, que SummarizeData do MMLSpark possa falhar com erros como StackOverflow em org.apache.spark.sql.catalyst se houver realmente muitas colunas e o gráfico de cálculo não for pequeno no momento do lançamento ( embora especialmente para esses fãs de "extremo" no Spark 2.4, eles tenham adicionado a capacidade de reduzir o otimizador de gráficos Catalyst ). Bem, parece que, com um número realmente grande de colunas, a versão da Microsoft será mais lenta. Mas isso, é claro, deve ser verificado separadamente.
Limpeza de dados
No Titanic, tudo está como sempre - um monte de colunas de string está faltando valores. E algum tipo de restrição nos dados (parece que essa versão específica dos dados não é muito específica) - 25 linhas a partir dos valores ausentes. Primeiro, corrija isso:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
Processamento de dados de string
Tanto quanto me lembro, os atributos trazidos dos campos Name e Cabin foram os melhores trazidos no Titanic. Você pode fornecê-los muito, mas nos limitaremos a alguns, apenas para não dar exemplos de quase o mesmo código.
Geralmente é conveniente usar expressões regulares para essas coisas.
Mas queremos neste caso:
- tudo foi distribuído, os dados foram processados no mesmo local em que estavam;
- tudo foi projetado como classes SpakrML Transformer ou Spark ML Estimator, para que posteriormente pudesse ser montado no Pipeline.
Nota: O pipeline, em primeiro lugar, garante que sempre aplicamos as mesmas transformações no trem e no teste e também nos permite detectar o erro de "olhar para o futuro" na validação cruzada. E também nos fornece recursos simples para salvar, carregar e prever usando nosso pipeline.
O SparkML possui uma classe "quase universal" para essas tarefas - SQLTranformer , mas escrever no SQL é claramente pior do que escrever no Scala, apenas por causa da capacidade de capturar sintaxe ou erros típicos no estágio de compilação e destaque de sintaxe no Idea. E aqui o MMLSpark vem em nosso auxílio, onde um UDFTransformer verdadeiramente universal é implementado :
import com.microsoft.ml.spark.UDFTransformer
Para começar, criaremos nossa função de transformação, que é muito simples até o limite, mas nosso objetivo agora é mostrar o processo de criação do UDFTransformer. Em princípio, com base em exemplos tão simples, qualquer pessoa pode adicionar lógica a qualquer nível de complexidade.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(Você pode ver imediatamente como Scala é conveniente trabalhar com valores ausentes, que, a propósito, não são apenas null , mas também Double.NaN , mas existem uma piada coisa rara como omissões nas variáveis BooleanType etc.)
Agora declare nossa UserDefinedFunction e crie imediatamente um Transformer base nela:
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
Nota: Em um laptop Zeppelin, é tudo a mesma coisa, mas quando tudo se reúne mais tarde no código de produção, é importante que todos os UDFs estejam em classes ou objetos que extends Serializable . O óbvio que às vezes você pode esquecer e se aprofundar por um longo tempo é o que há de errado em ler os rastros de pilha longa dos erros do Spark.
Agora ainda temos o campo Cabin . Vamos dar uma olhada mais de perto:

Vemos que existem muitos valores ausentes, letras, números, combinações diferentes etc. Vamos pegar o número de cabines (se houver mais de uma), bem como os números - eles provavelmente têm algum tipo de lógica, por exemplo, se a numeração for de uma extremidade do navio, as cabines na proa terão menos chance. Também criaremos funções e, com base nelas, UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
Agora vamos começar com os valores ausentes, a saber idade. Primeiro, vamos aproveitar os recursos de visualização do Zeppelin:
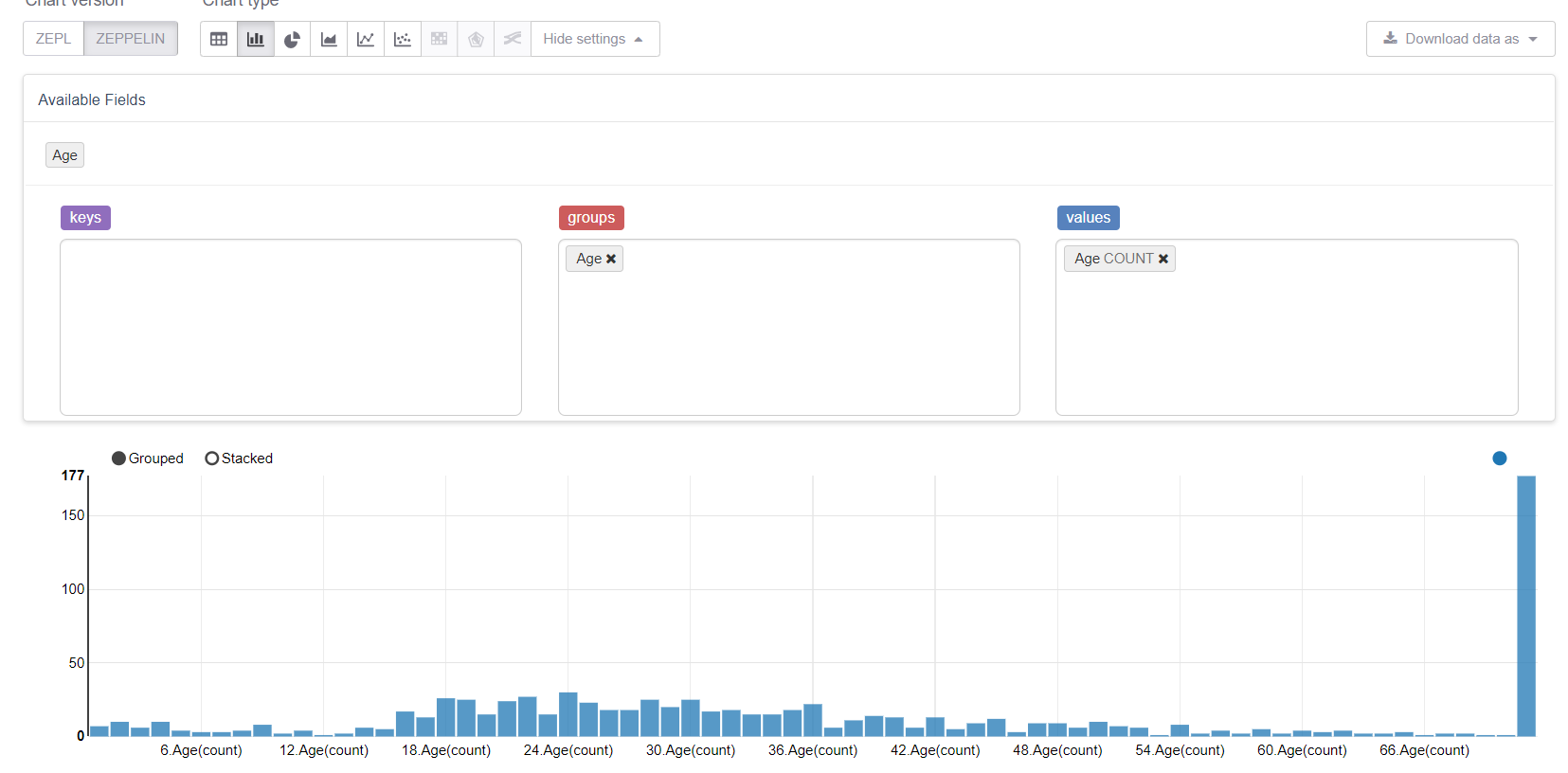
E veja como os valores ausentes estragam tudo. Seria lógico substituí-los por um meio (ou mediana), mas nosso objetivo é considerar todos os recursos da biblioteca MMLSpark. Portanto, escreveremos nosso próprio Estimator , que considerará as médias / grupos na amostra de treinamento e as substituirá pelas lacunas correspondentes.
Vamos precisar de:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
Vamos prestar atenção ao ConstructorWritable , que simplifica bastante a vida. Se nosso Model é um modelo "treinado" que o método fit(), retorna, que é completamente determinado por seu construtor (e isso é provavelmente 99% dos casos), não podemos escrever serialização com as mãos. Isso realmente simplifica e acelera o desenvolvimento, elimina erros e também reduz o limite de entrada para o DataScientist e analistas que geralmente não são programadores profissionais.
Defina nossa classe Estimator . De fato, a coisa mais importante aqui é o método de fit , o restante são pontos técnicos:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
Nota: Eu não usei defaultCopy, porque quando liguei, por algum motivo, jurou que não tinha um construtor. \ <init> (java.lang.String), embora pareça que isso não deveria ter acontecido. Bem, em qualquer caso, implementar a copy fácil.
Agora você precisa implementar Model - uma classe que descreve o modelo treinado e implementa o método de transform . Vamos construí-lo com base na função de coalesce criada em org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
O último objeto que precisamos declarar é um Reader , que implementamos usando a classe MMLSpark ConstructorReadable :
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
Criação de Pipeline
No Pipeline, eu gostaria de mostrar as classes usuais SparkML e a coisa incrivelmente conveniente do MMLSpark - MultiColumnAdapter , que permite aplicar transformadores SparkML a muitas colunas de uma só vez (para referência, por exemplo, StringIndexer e OneHotEncoder levam exatamente uma coluna à entrada, o que as transforma anúncio com dor):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
Primeiro, declararemos quais colunas temos:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
Agora crie um codificador de string:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
Nota: Ao contrário do scikit-learn no SparkML, o StringIndexer trabalha com o princípio do codificador de frequência e pode ser usado para especificar um relacionamento de ordem (ou seja, categoria 0 <categoria 1, e isso faz sentido) - essa abordagem geralmente funciona bem para árvores decisivas.
Imputer nosso Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
E VectorAssembler , já que os classificadores SparkML são mais confortáveis ao trabalhar com o VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
Agora usaremos o aumento de gradiente fornecido com o MMLSpark - LightGBM, incluído nos "Três Grandes" das melhores implementações desse algoritmo, juntamente com o XGBoost e o CatBoost. Ele funciona muitas vezes mais rápido, melhor e mais estável do que a implementação do GBM que o SparkML possui (mesmo levando em consideração que a porta da JVM ainda está em desenvolvimento ativo):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
Nota: O LightGBM suporta o trabalho com variáveis categóricas (quase como catboost), portanto, indicamos previamente onde estão os atributos de categoria em nosso vetor, e ele próprio descobrirá o que fazer com eles e como codificá-los.
Mais sobre os recursos LightGBM para Spark- Nos nós executando o RadHat LightGBM, qualquer versão, exceto a mais recente, falhará devido ao fato de ele não gostar da versão
glibc . Isso foi corrigido recentemente , no entanto, ao instalar via Maven, o MMLSpark retira a penúltima versão do LightGBM ao instalar via Maven; portanto, você precisa adicionar a dependência da versão mais recente do RadHat com as mãos. - O LightGBM, em seu trabalho, cria um soquete no driver para comunicação com executivos, e isso é feito usando o
new java.net.ServerSocket(0) e, portanto, uma porta aleatória das portas efêmeras do sistema operacional é usada. Se o intervalo de portas efêmeras diferir do intervalo de portas abertas pelo firewall, pode queimar muito Você pode obter um efeito interessante quando o LightGBM às vezes funciona (quando escolhi uma boa porta), e às vezes não. E haverá erros como o ConnectionTimeOut , que também pode indicar, por exemplo, a opção quando o GC fica pendurado nos executivos ou algo assim. Em geral, não repita meus erros.
Bem, finalmente, declare nosso pipeline:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
Treinamento
Vamos dividir nosso conjunto de treinamento em um trem e um teste e verificar nosso pipeline. Aqui é apenas possível avaliar a conveniência do pipeline, uma vez que é completamente independente da partição e garante que aplicaremos as mesmas transformações para treinar e testar, e todos os parâmetros de transformação serão "aprendidos" no trem:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
Para um cálculo conveniente das métricas, usaremos outra classe do MMLSpark - ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
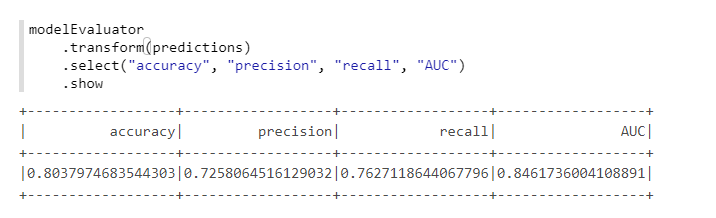
Nada mal, já que não alteramos as configurações padrão.
Seleção de hiperparâmetros
Para selecionar hiperparâmetros no MMLSpark, existe um TuneHyperparameters legal TuneHyperparameters separado, que implementa uma pesquisa aleatória na grade. No entanto, infelizmente, ele ainda não suporta o Pipeline , portanto, usaremos o SparkML CrossValidator usual:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
Infelizmente, não achei uma maneira conveniente de como você pode ver os resultados juntamente com os parâmetros em que foram obtidos. Portanto, é necessário usar designs "monstruosos":
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
O que nos dá algo como isto:
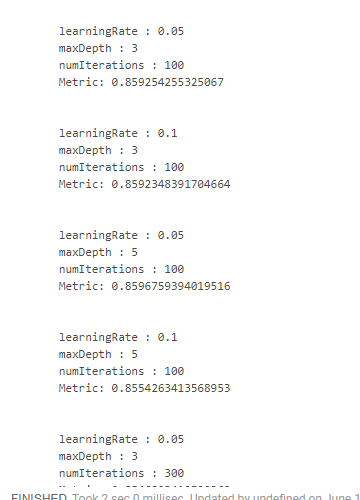
Obtivemos o melhor resultado, reduzindo a velocidade do aprendizado e aumentando a profundidade das árvores. Com base nisso, seria possível ajustar o espaço de pesquisa e obter um resultado ainda mais ideal, mas simplesmente não temos esse objetivo.
Conclusão
De fato, enquanto o MMLSpark possui a versão 0.17 e ainda contém bugs separados. Mas de todas as extensões do Spark que eu já vi, o MMLSpark, na minha opinião, possui a documentação mais abrangente e o processo de instalação e implementação mais compreensível. A Microsoft ainda não o promoveu, havia apenas um relatório sobre o Databricks , mas havia mais sobre o DeepLearning, e não sobre as coisas rotineiras sobre as quais escrevi.
Pessoalmente, em nossas tarefas, essa biblioteca ajudou muito, permitindo-me passar um pouco menos da selva de fontes Spark e não usar o reflect para acessar métodos privados [ml], e um dos meus colegas encontrou a biblioteca quase por acidente. Ao mesmo tempo, devido ao fato de a biblioteca estar em desenvolvimento ativo, a estrutura do arquivo de origem mingau cheio um pouco confuso. Bem, devido ao fato de não haver exemplos especiais ou outra documentação (exceto o scaladoc), primeiro tivemos que rastrear o código-fonte constantemente.
Portanto, espero realmente que este mini-tutorial (apesar de toda a sua obviedade e simplicidade) seja útil para alguém e ajude a economizar muito tempo e esforço!