O artigo discutirá os benefícios do log. Vou falar sobre os logs no PSR. Vou adicionar algumas recomendações pessoais sobre como trabalhar com o nível, a mensagem e o contexto do evento registrado. Um exemplo será fornecido sobre como organizar o log e o monitoramento usando o ELK em um aplicativo escrito no Laravel e iniciado pelo Docker em várias instâncias. Assinarei uma regra importante do sistema de alerta. Vou dar um exemplo de um script que gera toda a pilha de monitoramento com um comando.
Os benefícios do log
O registro bem organizado permite pelo menos o seguinte:
- Saber que algo não está indo como o esperado (há erros)
- Conheça os detalhes do erro, o que ajudará a dizer com quem e onde o erro ocorreu e evite a repetição
- Saber que tudo está indo como planejado (access.log, debug-, info-levels)
O registro por si só não informa tudo isso, mas com a ajuda dos logs será possível descobrir os detalhes dos eventos por conta própria ou configurar um sistema de monitoramento de logs que poderá notificar problemas. Se as mensagens nos logs forem acompanhadas por uma quantidade suficiente de contexto, isso simplificará bastante a depuração, porque você terá mais dados disponíveis sobre a situação em que o evento ocorreu.
O que escrever e o que escrever
Parte da comunidade php desenvolveu recomendações para algumas tarefas de escrita de código. Uma dessas recomendações é a interface do PSR-3 Logger . Apenas descreve o que você precisa registrar. Para isso, a Psr\Log\LoggerInterface do pacote " Psr\Log\LoggerInterface / log" é desenvolvida. Ao usá-lo, você precisa conhecer os três componentes do evento:
- Nível - Importância do Evento
- Mensagem - texto que descreve o evento
- Contexto - uma matriz de informações adicionais sobre o evento
Níveis de evento PSR-3
Os níveis são emprestados da RFC 5424 - The Syslog Protocol, cuja descrição aproximada é a seguinte:
- debug - Detalhes para depuração
- info - Eventos interessantes
- aviso - Eventos materiais, mas não erros
- warning - Casos excepcionais, mas não erros
- error - Erros de execução que não requerem intervenção momentânea
- crítico - condições críticas (o componente do sistema está indisponível, exceção inesperada)
- alerta - Ação requer intervenção imediata
- emergência - O sistema não está funcionando
Existe uma descrição, mas nem sempre é fácil de seguir, devido à dificuldade em determinar a importância de certos eventos. Por exemplo, no contexto de uma única solicitação, não foi possível acessar o recurso conectado. Ao gravar este evento, não sabemos se uma dessas solicitações falhou ou se apenas um usuário falhou. Depende da necessidade de intervenção imediata ou, se este for um caso raro, pode esperar ou até ser ignorado. Esses problemas são resolvidos na estrutura dos logs de monitoramento. Mas você ainda precisa determinar o nível. Portanto, os níveis de registro na equipe podem ser acordados. Um exemplo:
- emergência é o nível para sistemas externos que podem examinar seu sistema e determinar com certeza que ele não está funcionando completamente ou se o autodiagnóstico não está funcionando.
- alerta - o próprio sistema pode diagnosticar seu estado, por exemplo, com uma tarefa agendada e, como resultado, registrar um evento com esse nível. Pode ser verificações de recursos conectados ou algo específico, por exemplo, um saldo na conta de um recurso externo usado.
- crítico - um evento em que uma falha fornece um componente do sistema que é muito importante e deve sempre funcionar. Já depende muito do que o sistema faz. Adequado para eventos importantes para descobrir rapidamente, mesmo que isso tenha acontecido apenas uma vez.
- error - ocorreu um evento sobre o qual, ao repetir em breve, é necessário relatar. Falha ao concluir a ação, que deve ser executada, mas essa ação não se enquadra na descrição de crítico. Por exemplo, não foi possível salvar a foto do perfil de um usuário a seu pedido, mas o sistema não é um serviço de imagem do perfil, mas um sistema de bate-papo.
- warning - events, para notificação imediata sobre a qual você precisa discar um número significativo deles durante um período de tempo. Falha ao executar uma ação, cuja falha não quebra nada sério. Esses ainda são erros, mas cuja correção pode esperar pelo horário de trabalho. Por exemplo, não foi possível salvar o avatar do usuário, e o sistema era uma loja online. É necessária uma notificação sobre eles (em alta frequência) para aprender sobre anomalias repentinas, pois podem ser sintomas de problemas mais sérios.
- aviso - são eventos que relatam desvios fornecidos pelo sistema que fazem parte do funcionamento normal do sistema. Por exemplo, o usuário especificou a senha errada na entrada, o usuário não preencheu o nome do meio, mas não é necessário, o usuário comprou o pedido de 0 rublos, mas isso é fornecido em casos raros. Uma notificação sobre eles em alta frequência também é necessária, pois um aumento acentuado no número de desvios pode ser o resultado de um erro que precisa ser corrigido com urgência.
- info - eventos cuja ocorrência reporta o funcionamento normal do sistema. Por exemplo, um usuário se registrou, um usuário comprou um produto, um usuário deixou um feedback. A notificação para esses eventos precisa ser configurada da maneira oposta: se um número insuficiente desses eventos ocorrer durante um período de tempo, será necessário notificá-lo, pois sua diminuição pode ser causada como resultado de um erro.
- debug - eventos para depurar um processo no sistema. Ao adicionar dados suficientes ao contexto do evento, você pode diagnosticar o problema ou concluir que o processo está funcionando corretamente no sistema. Por exemplo, um usuário abriu uma página de produto e recebeu uma lista de recomendações. Aumenta significativamente o número de eventos enviados, portanto, é permitido remover o log de tais eventos depois de um tempo. Como resultado, o número de tais eventos na operação normal será variável, e o monitoramento da notificação neles poderá ser omitido.
Mensagem de evento
Pelo PSR-3, uma mensagem deve ser uma sequência ou um objeto com o método __toString() . Além disso, de acordo com o PSR-3, uma linha de mensagem pode conter espaços reservados no formato ”User {username} created” , que pode ser substituído por valores da matriz de contexto. Ao usar o Elasticsearch e o Kibana para monitoramento, eu recomendo não usar espaços reservados, mas escrever linhas fixas, porque isso simplificará a filtragem de eventos e o contexto sempre estará lá. Além disso, proponho prestar atenção a requisitos adicionais para a mensagem:
- O texto deve ser curto, mas significativo. É isso que virá em alertas e o que estará nas listas de eventos que ocorreram.
- O texto é melhor para ser exclusivo para diferentes partes do programa. Isso tornará possível a partir do alerta, sem examinar o contexto, entender em que parte o evento ocorreu.
Contexto do evento
O contexto do evento para PSR-3 é uma matriz (possivelmente aninhada) de valores de variáveis, por exemplo, IDs de entidade. O contexto pode ser deixado em branco se a mensagem estiver clara sobre o evento. No caso de registrar uma exceção, você deve passar a exceção inteira, não apenas getMessage() . Ao usar o Monolog através do NormalizerFormatter, dados úteis serão extraídos automaticamente da exceção e adicionados ao contexto do evento, incluindo o rastreamento de pilha. Ou seja, você precisa
[ 'exception' => $exception->getMessage(), ]
usar
[ 'exception' => $exception, ]
No Laravel, você pode inserir automaticamente dados para eventos em eventos. Isso pode ser feito através do contexto de log global (apenas para exceções sem êxito ou através de report() ) ou através do LogFormatter (para todos os eventos). Normalmente, as informações são adicionadas com o ID do usuário atual, solicitação de URI, IP, solicitação de UUID e similares.
Ao usar o Elasticsearch como um repositório de logs, lembre-se de que ele usa tipos de dados fixos. Ou seja, se você passou customer_id no contexto de um número, ao tentar salvar um evento com um tipo diferente, por exemplo, uma string (uuid), essa mensagem não será gravada. Os tipos no índice são fixos quando o valor é recebido pela primeira vez. Se índices forem criados todos os dias, o novo tipo será gravado apenas no dia seguinte. Mas mesmo isso não resolverá todos os problemas, porque para o Kibana os tipos serão misturados e parte das operações associadas ao tipo não estarão disponíveis enquanto houver índices mistos.
Para evitar esse problema, recomendo que você siga as regras:
- Não use nomes de chave muito genéricos, que podem ser de tipos diferentes
- Faça a conversão explícita para um tipo de valor se não tiver certeza do seu tipo
Exemplo: em vez disso
[ 'response' => $response->all(), 'customer_id' => $id, 'value' => $someValue, ]
usar
[ 'smsc_response_data' => json_encode($response->all()), 'customer_id' => (string) $customer_id, 'smsc_request_some_value' => (string) $someValue, ]
Chamando um registrador de código
Para registrar rapidamente um evento no log, você pode criar várias opções. Vamos considerar alguns deles.
- Declare a função global
log() e chame-a de diferentes partes do programa. Essa abordagem tem muitas desvantagens. Por exemplo, nas classes em que acessamos essa função, uma dependência implícita é formada. Isso deve ser evitado. Além disso, é difícil configurar esse criador de logs quando o sistema precisa ter vários diferentes. Outra desvantagem, se estivermos falando sobre trabalhar com o Laravel, é que não usamos os recursos fornecidos pela estrutura para resolver esse problema. - Use a fachada do Laravel \ Log. Com essa abordagem, as partes do sistema que acessam essa fachada começam a depender da estrutura. Em partes do sistema que não removeremos da estrutura, essa solução é bastante adequada. Por exemplo, escreva a partir de algumas instâncias de um comando do console, tarefa em segundo plano, controlador. Ou quando já existe uma estrutura complexa de serviços, e não é tão simples jogar uma instância de um criador de logs neles.
- Resolva a dependência do criador de logs através dos auxiliares da estrutura
app() e resolve() . A abordagem tem as mesmas desvantagens do uso da fachada, mas você precisa escrever um pouco mais de código. - Especifique a dependência no criador de logs no construtor da classe que esse criador de logs usará. Ao mesmo tempo, o mesmo
LoggerInterface deve ser especificado como o tipo para estar em conformidade com o DIP . Graças às estruturas de ligação automática, as dependências serão resolvidas automaticamente na implementação de suas abstrações declaradas. No Laravel, algumas classes de dependência podem ser especificadas em um método separado, em vez de serem especificadas no construtor de toda a classe.
Onde no código para chamar o logger
Ao organizar o código no projeto, pode surgir a pergunta em qual classe devo escrever no log. Deveria ser um serviço? Ou deve ser feito de onde o serviço é chamado: controlador, tarefa em segundo plano, comando do console? Ou cada exceção deve decidir o que gravar no log usando seu método de report (Laravel)? Não há uma resposta simples para todas as perguntas de uma só vez.
Considere a oportunidade dada pelo Laravel para delegar à classe de exceção a tarefa de registrar-se. Uma exceção não pode saber o quão crítico é para o sistema determinar o nível de um evento. Além disso, uma exceção não tem acesso ao contexto, a menos que seja especificamente adicionada quando essa exceção é chamada. Para chamar o método render em uma exceção, você não deve capturar a exceção (o ErrorHandler global será usado) ou capturar e usar o assistente global report() . Esse método nos permite não ligar para o registrador PSR-3 sempre que capturarmos essa exceção. Mas acho que não vale a pena dar à exceção essa responsabilidade.
Pode parecer que sempre podemos efetuar logon apenas em serviços. De fato, em alguns serviços, você pode fazer o log. Mas considere um serviço que não depende do projeto e, em geral, planejamos colocá-lo em um pacote separado. Portanto, este serviço não sabe sobre sua importância no projeto e, portanto, não poderá determinar o nível de registro. Por exemplo, um serviço de integração com um gateway SMS específico. Se recebermos um erro de rede, isso não significa que seja muito sério. Talvez o sistema tenha um serviço de integração com outro gateway SMS através do qual haverá uma segunda tentativa de envio; o erro do primeiro pode ser relatado como aviso e o erro do segundo como erro. Somente agora todas essas integrações devem ser chamadas de outro serviço, que efetuará login exatamente. Acontece que o erro está em um serviço e efetuamos login em outro. Mas, às vezes, não temos um wrapper de serviço sobre outro serviço - chamamos isso diretamente do controlador. Nesse caso, considero permitido gravar no log no controlador em vez de escrever um decorador de serviço para o log.
Um exemplo mostrando o uso de dependência e passagem de contexto:
<?php namespace App\Console\Commands; use App\Services\ExampleService; use Illuminate\Console\Command; use Psr\Log\LoggerInterface; class Example extends Command { protected $signature = 'example'; public function handle(ExampleService $service, LoggerInterface $logger) { try { $service->example(); } catch (\Exception $exception) { $logger->critical('Example error', [ 'exception' => $exception, ]); } } }
Onde escrever
Considere as seguintes opções.
- De acordo com o aplicativo de 12 fatores e algumas outras recomendações, você precisa escrever em stdout, stderr do tempo de execução do aplicativo. Para fazer isso, você pode especificar no log de configuração
php://stdout *. - Ignore 12 fatores, docker-way e grave em arquivos. O Laravel (Monolog) ainda permite configurar a rotação de logs. Outras mensagens dos arquivos podem ser coletadas usando o Filebeat e enviadas ao Logstash para análise.
- Envie logs do aplicativo diretamente ainda mais, por exemplo, via UDP para aumentar o desempenho.
- Combine soluções. Escreva nos arquivos que usando o Filebeat serão coletados e enviados para o Logstash. Escreva no stderr do contêiner para poder usar os comandos
docker logs do docker logs e estar pronto para coletar convenientemente logs do ambiente de orquestração do contêiner. Nesse caso, você pode gravar alguns canais apenas localmente, alguns enviam pela rede.
* No php-fpm 7.2, ao gravar logs no stdout, obtemos "WARNING: [pool www] o filho X disse no stdout ...", e as mensagens longas são truncadas. Uma solução para esse problema está aqui . Não existe esse problema no php-fpm 7.3.
Opções de formato de gravação:
- Legível por humanos (quebras de linha, recuos etc.)
- Legível por máquina (geralmente json)
- Ambos os formatos ao mesmo tempo: legível por máquina no stdout para roteamento adicional, legível por humanos em caso de problemas súbitos de roteamento e depuração rápida
Qualquer uma das opções pressupõe que os logs sejam roteados - pelo menos, eles são enviados para um único sistema de processamento (armazenamento) de logs pelos seguintes motivos:
- Armazenamento e arquivamento a longo prazo
- Tendências em larga escala
- Sistema flexível de notificação de eventos
O Docker tem a capacidade de especificar um gerenciador de logs. O padrão é json-file , ou seja, a janela de encaixe adiciona a saída do contêiner ao json-file no host. Se selecionarmos um gerenciador de logs que enviará registros para algum lugar da rede, não será mais possível usar o docker logs . Se stdout / stderr do contêiner foi escolhido como o único local para registrar logs de aplicativos, em caso de problemas de rede ou problemas com um único repositório, talvez não seja possível extrair rapidamente registros para depuração.
Podemos usar a janela de encaixe json-file e o Filebeat. Receberemos logs locais e roteamento adicional. Vale a pena notar aqui é outro recurso da janela de encaixe. Ao gravar um evento com mais de 16 KB, a janela de encaixe quebra o registro com o símbolo \n , que confunde muitos coletores de logs. Há um problema sobre isso. O problema da parte da janela de encaixe não pôde ser resolvido, portanto foi resolvido pelos coletores. Em algumas versões, o Filebeat suporta esse comportamento do docker e combina eventos corretamente.
Que combinação de todas as possibilidades de destinos e formatos de gravação você pode escolher para o seu projeto.
Usando Filebeat + ELK + Elastalert
Resumidamente, o papel de cada serviço pode ser descrito da seguinte maneira:
- Filebeat - coleta eventos de arquivos e envia
- Logstash - analisa eventos e envia
- Elasticsearch - armazena eventos estruturados
- Kibana - exibe eventos (gráficos, agregações, etc.)
- Elastalert - envia alertas com base em solicitações
Além disso, você pode: zabbix, metricbeat, grafana e muito mais.
Agora mais sobre cada um.
Filebeat
Você pode executar como um serviço separado no host, pode usar um contêiner de janela de encaixe separado. Para trabalhar com o fluxo de eventos da janela de encaixe, ele usa o caminho do host /var/lib/docker/containers/*/*.log . O Filebeat possui uma ampla variedade de opções com as quais você pode definir o comportamento em várias situações (o arquivo é renomeado, o arquivo é excluído e similares). A própria filebeat pode analisar json dentro do evento, mas não o json também pode entrar em eventos, o que levará a um erro. Todo o processamento de eventos é melhor realizado em um só lugar.
Configuração de fragmento para Filebeat 6 filebeat.inputs: - type: docker containers: ids: - "*" processors: - add_docker_metadata: ~
Logstash
Capaz de aceitar eventos de várias fontes, mas aqui estamos considerando o Filebeat.
Em todos os eventos, além do próprio evento de stdout / stderr, há metadados (host, contêiner etc.). Existem muitos filtros de processamento internos: analise por intervalos regulares, analise json, modifique, adicione, exclua campos etc. Adequado para analisar os logs de aplicativos e o nginx access.log em qualquer formato. Capaz de transferir dados para diferentes repositórios, mas aqui consideramos o Elasticsearch.
Fragmento de configuração do filtro Logstash if [status] { date { match => ["timestamp_nginx_access", "dd/MMM/yyyy:HH:mm:ss Z"] target => "timestamp_nginx" remove_field => ["timestamp_nginx_access"] } mutate { convert => { "bytes_sent" => "integer" "body_bytes_sent" => "integer" "request_length" => "integer" "request_time" => "float" "upstream_response_time" => "float" "upstream_connect_time" => "float" "upstream_header_time" => "float" "status" => "integer" "upstream_status" => "integer" } remove_field => [ "message" ] rename => { "@timestamp" => "event_timestamp" "timestamp_nginx" => "@timestamp" } } }
Elasticsearch
O Elasticsearch é uma ferramenta muito poderosa para uma ampla variedade de tarefas, mas com o objetivo de monitorar logs, ele pode ser usado sabendo apenas um mínimo.
Eventos salvos são um documento, documentos são armazenados em índices.
Cada índice é um esquema no qual um tipo é definido para cada campo do documento. Você não pode salvar um evento no índice se pelo menos um campo tiver o tipo errado.
Tipos diferentes permitem realizar operações diferentes em um grupo de documentos (para números - soma, min, max, média, etc., para seqüências de caracteres - pesquisa difusa etc.).
Para logs, o gerenciamento geralmente recomenda o uso de índices diários - um novo índice todos os dias.
Garantir a operação estável do Elasticsearch com o crescimento do volume de dados é uma tarefa que requer conhecimento mais profundo sobre essa ferramenta. Mas uma solução rápida para o problema de estabilidade, você pode optar por excluir automaticamente dados obsoletos. Para fazer isso, sugiro dividir os níveis de evento no logstash em diferentes índices. Isso permitirá armazenar mais eventos raros, mas mais importantes.
Snippet de configuração de saída do logstash output { if [fields][log_type] == "app_log" { if [level] in ["DEBUG", "INFO", "NOTICE"] { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-debug-%{+YYYY.MM.dd}" } } else { elasticsearch { hosts => "${ES_HOST}" index => "logstash-app-log-error-%{+YYYY.MM.dd}" } } } }
Para remover automaticamente índices obsoletos, sugiro usar um programa do Elastic Curator . O lançamento do programa é adicionado à programação do Cron, a própria configuração pode ser armazenada em um arquivo separado.
Um fragmento da configuração para remover índices obsoletos action: delete_indices description: logstash-app-log-error options: ignore_empty_list: True filters: - filtertype: pattern kind: prefix value: logstash-app-log-error- - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: months unit_count: 6
, Filebeat Logstash, . Elasticsearch -- , , .
Kibana
Kibana . -, Elasticsearch. .
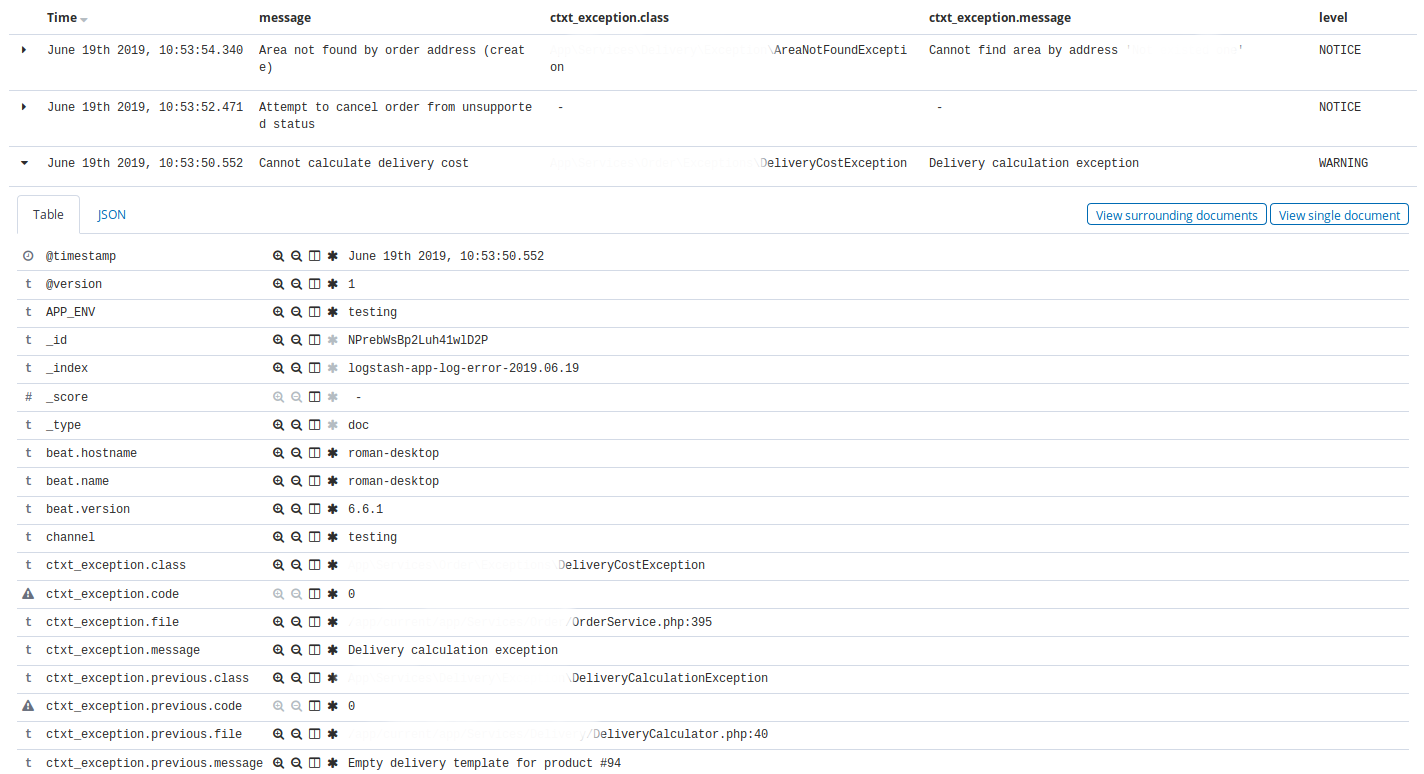
Kibana — Discovery . , Discovery app warning , time, message, exception class, host, client_id.
, Discovery nginx, 404 time, message, request, status.
Kibana , : , , . , ( ).
Elastalert
Elastalert Elasticsearch . , . , .
, (), .
:
- ALERT, EMERGENCY. — 10
- CRITICAL. — 30
- , N X M
- 10 INFO 3
- nginx 200, 201, 304 75% , 50
name: Blacklist ALERT, EMERGENCY type: blacklist index: logstash-app-* compare_key: "level" blacklist: - "ALERT" - "EMERGENCY" realert: minutes: 5 alert: - "slack"
— . , , . Kibana.
, , http- 75% , , , , . - , , , .
, , , , Kibana, .
5 . , , , , , .
, . .
Kibana . .
docker-. , , staging- production-, .
, Elastalert, . Elastalert ,
envsubst < /opt/elastalert/config.dist.yaml > /opt/elastalert/config.yaml entrypoint- , .
, , , .
Makefile build: docker build -t some-registry/elasticsearch elasticsearch docker build -t some-registry/logstash logstash docker build -t some-registry/kibana kibana docker build -t some-registry/nginx nginx docker build -t some-registry/curator curator docker build -t some-registry/elastalert elastalert push: docker push some-registry/elasticsearch docker push some-registry/logstash docker push some-registry/kibana docker push some-registry/nginx docker push some-registry/curator docker push some-registry/elastalert pull: docker pull some-registry/elasticsearch docker pull some-registry/logstash docker pull some-registry/kibana docker pull some-registry/nginx docker pull some-registry/curator docker pull some-registry/elastalert prepare: docker network create -d bridge elk-network || echo "ok" stop: docker rm -f kibana || true docker rm -f logstash || true docker rm -f elasticsearch || true docker rm -f nginx || true docker rm -f elastalert || true run-logstash: docker rm -f logstash || echo "ok" docker run -d --restart=always --network=elk-network --name=logstash -p 127.0.0.1:5001:5001 -e "LS_JAVA_OPTS=-Xms256m -Xmx256m" -e "ES_HOST=elasticsearch:9200" some-registry/logstash run-kibana: docker rm -f kibana || echo "ok" docker run -d --restart=always --network=elk-network --name=kibana -p 127.0.0.1:5601:5601 --mount source=elk-kibana,target=/usr/share/kibana/optimize some-registry/kibana run-elasticsearch: docker rm -f elasticsearch || echo "ok" docker run -d --restart=always --network=elk-network --name=elasticsearch -e "ES_JAVA_OPTS=-Xms1g -Xmx1g" --mount source=elk-esdata,target=/usr/share/elasticsearch/data some-registry/elasticsearch run-nginx: docker rm -f nginx || echo "ok" docker run -d --restart=always --network=elk-network --name=nginx -p 80:80 -v /root/elk/.htpasswd:/etc/nginx/.htpasswd some-registry/nginx run-elastalert: docker rm -f elastalert || echo "ok" docker run -d --restart=always --network=elk-network --name=elastalert --env-file=./elastalert/.env some-registry/elastalert run: prepare run-elasticsearch run-kibana run-logstash run-elastalert delete-old-indices: docker run --rm --network=elk-network -e "ES_HOST=elasticsearch:9200" some-registry/curator curator --config /curator/curator.yml /curator/actions.yml
:
- 80 nginx, basic auth Kibana
- Logstash . ssh-
- nginx
- , docker-
- , .env- nginx-
- *_JAVA_OPTS , 4GB RAM ( ES).
, xpack-.
docker-compose. , , Dockerfile-, Filebeat, Logstash, , , , , VCS.
. . , ( Laravel scheduler), , 5 . ALERT. , . , , .
Conclusão
, , , . . , - . . , , .