O curso completo em russo pode ser encontrado neste link .
O curso de inglês original está disponível neste link .

Novas palestras são agendadas a cada 2-3 dias.
Conteúdo
- Entrevista com Sebastian Trun
- 1. Introdução
- Conjunto de dados Cães e Gatos
- Imagens de vários tamanhos
- Imagens coloridas. Parte 1
- Imagens coloridas. Parte 2
- Operação de convolução em imagens coloridas
- A operação de subamostragem pelo valor máximo em imagens coloridas
- CoLab: gatos e cães
- Softmax e sigmoid
- Verifique
- Extensão de imagem
- Exceção
- CoLab: cães e gatos. Repetição
- Outras técnicas para evitar a reciclagem
- Exercícios: classificação de imagens coloridas
- Solução: classificação da imagem colorida
- Sumário
Entrevista com Sebastian Trun
- Então, hoje estamos aqui de novo, junto com Sebastian e falaremos sobre reciclagem. Este tópico é muito interessante para nós, especialmente nas partes práticas do curso atual sobre o trabalho com o TensorFlow.
- Sebastian, você já encontrou overfitting - over, fit? Se você diz que não encontrou, eu definitivamente direi que não posso acreditar em você!
- Portanto, o motivo da reciclagem é o chamado trade-off de desvio de desvio (um compromisso entre os valores do parâmetro de desvio e seu spread). Uma rede neural na qual um pequeno número de pesos não é capaz de aprender um número suficiente de exemplos, uma situação semelhante no aprendizado de máquina é chamada distorção.
Sim.
- Uma rede neural com tantos parâmetros pode escolher arbitrariamente uma solução que você não gosta, apenas por causa de um número tão grande desses parâmetros. O resultado da escolha de uma solução de rede neural depende da variabilidade dos dados de origem. Assim, uma regra simples pode ser formulada: quanto mais parâmetros houver na rede em relação ao tamanho (quantidade) dos dados, maior a probabilidade de obter uma solução aleatória em vez da correta. Por exemplo, você se pergunta: "Quem é o homem nesta sala e quem é a mulher?" Uma rede neural complexa pode dizer que, por exemplo, todos aqueles cujos nomes começam com T são homens e nunca se treinam novamente. Existem duas soluções. O primeiro deles usa um conjunto de dados de validação (uma pequena quantidade do conjunto de treinamento para validar a precisão do modelo). Você pode pegar os dados, dividi-los em duas partes - 90% para treinamento e 10% para testar e realizar a chamada validação cruzada, onde você verifica a precisão do modelo nos dados que a rede neural não viu - assim que o valor do erro começa crescer após um certo ciclo de treinamento - é hora de parar de aprender. A segunda solução é introduzir restrições na rede neural. Por exemplo, para limitar os valores dos parâmetros de deslocamentos e pesos, aproximando-os cada vez mais de zero. Quanto mais limitados os pesos, menos treinado o modelo será.
- Entendo corretamente que podemos ter conjuntos de dados para treinamento e teste e validação, certo?
Isso mesmo. Se você possui um conjunto de dados para validação, deve ter um conjunto de dados que nunca tocou ou mostrou à sua rede neural. Se você mostrou ao modelo um determinado conjunto de dados várias vezes, é claro que o processo de reciclagem será iniciado, o que é muito ruim para nós.
- Talvez você se lembre dos casos mais interessantes quando seu modelo foi treinado novamente?
- Ah, sim ... houve um incidente desse tipo quando eu estava desenvolvendo uma rede neural para jogar xadrez. Foi em 1993. O interessante foi que, a partir dos dados do xadrez nos quais a rede neural foi treinada, a rede rapidamente determinou que, se um especialista move a rainha para o centro do tabuleiro de xadrez, há 60% de chance de ganhar. O que ela começou a fazer foi abrir a "passagem" com um peão e mover a rainha para o centro do tabuleiro de xadrez. Foi uma decisão tão estúpida para qualquer jogador de xadrez, que testemunhou claramente a reciclagem do modelo.
Ótimo! Então, discutimos várias técnicas sobre como melhorar nossos modelos. O que você acha que é o lado mais subestimado do aprendizado profundo?
- 90% do seu trabalho está subestimado, porque 90% do seu trabalho consistirá em limpeza de dados.
- Aqui eu concordo plenamente com você!
- Como mostra a prática, qualquer conjunto de dados contém algum tipo de lixo. É muito difícil trazer os dados para o tipo certo, para torná-los consistentes; é um processo muito trabalhoso.
- Sim, mesmo se você trabalhar com conjuntos de dados como imagens ou vídeos, onde, ao que parece, todas as informações já estão lá, dentro, ainda é necessário pré-processar as imagens.
- As únicas pessoas para quem os dados são ideais são os professores, porque eles têm a oportunidade de fingir em uma apresentação no PowerPoint que tudo está exatamente como deveria e tudo está perfeito! Na realidade, 90% do seu tempo será ocupado pela limpeza de dados.
Ótimo. Então, vamos descobrir mais sobre reciclagem e técnicas que nos permitirão melhorar nossos modelos de aprendizado profundo.
1. Introdução
oi! E novamente, bem-vindo ao curso!
“Na última lição, desenvolvemos uma pequena rede neural convolucional para classificar imagens de itens de vestuário em tons de cinza a partir do conjunto de dados FASHION MNIST. Vimos na prática que nossa pequena rede neural pode classificar imagens recebidas com precisão bastante alta. No entanto, no mundo real, temos que trabalhar com imagens de alta resolução e vários tamanhos. Uma das grandes vantagens do SNA é o fato de poderem funcionar igualmente bem com imagens coloridas. Portanto, começaremos nossa lição atual, explorando como o SNA funciona com imagens coloridas.
- Mais tarde, na mesma frequência, você criará uma rede neural convolucional que pode classificar imagens de cães e gatos. No caminho para a implementação de uma rede neural convolucional capaz de classificar imagens de cães e gatos, também aprenderemos como usar várias técnicas para resolver um dos problemas mais comuns das redes neurais - a reciclagem. E no final desta lição, na parte prática, você desenvolverá sua própria rede neural convolucional para classificar imagens coloridas. Vamos começar!
Conjunto de dados de cães e gatos
Até aquele momento, trabalhamos apenas com imagens em escala de cinza e tamanhos 28x28 do conjunto de dados FASHION MNIST.

Em aplicativos reais, somos forçados a encontrar imagens de vários tamanhos, por exemplo, as mostradas abaixo:

Como mencionamos no início desta lição, nesta lição, desenvolveremos uma rede neural convolucional que pode classificar imagens coloridas de cães e gatos.
Para implementar nossos planos, usaremos imagens de cães e gatos do conjunto de dados Microsoft Asirra. Cada imagem neste conjunto de dados é rotulada como 1 ou 0 se houver um cachorro ou gato na imagem, respectivamente.

Apesar do conjunto de dados Microsoft Asirra conter mais de 3 milhões de imagens marcadas de cães e gatos, apenas 25.000 estão disponíveis ao público. Treinar nossa rede neural convolucional nessas 25.000 imagens levará muito tempo. É por isso que usaremos um pequeno número de imagens para treinar nossa rede neural convolucional a partir dos 25.000 disponíveis.
Nosso subconjunto de imagens de treinamento consiste em 2.000 e 1.000 peças de imagens para validação do modelo. No conjunto de dados de treinamento, 1.000 imagens contêm gatos e as outras 1.000 imagens contêm cães. Falaremos sobre o conjunto de dados para validação um pouco mais adiante nesta parte da lição.
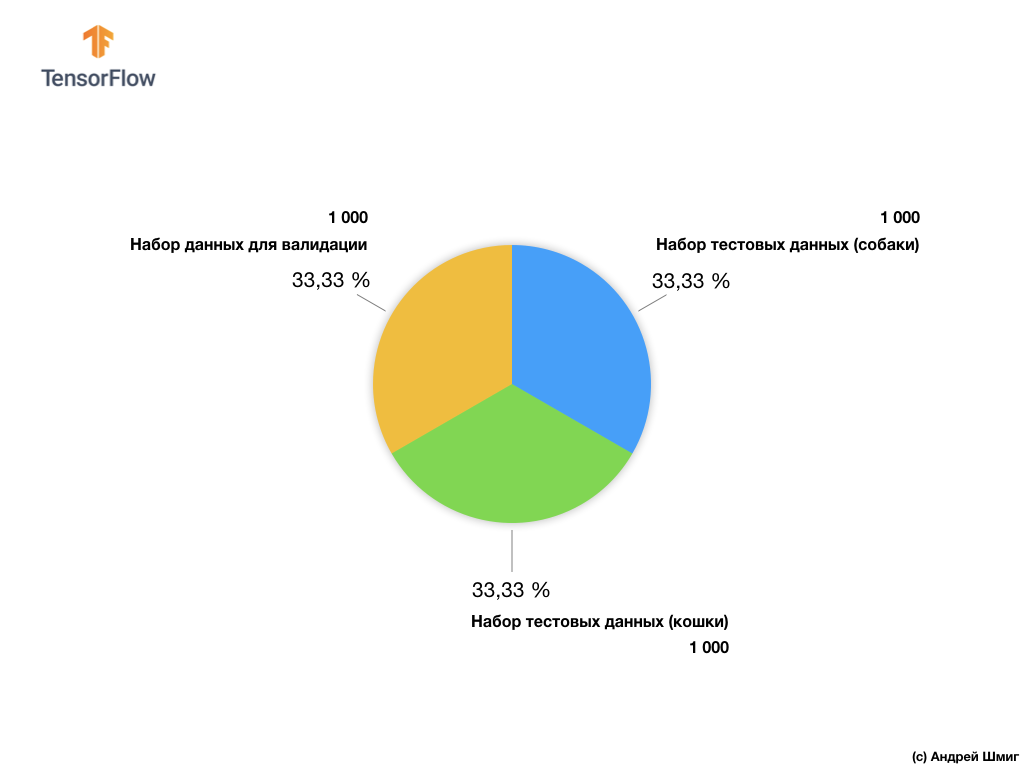
Trabalhando com esse conjunto de dados, encontraremos duas dificuldades principais - trabalhar com imagens de tamanhos diferentes e trabalhar com imagens coloridas.
Vamos começar a explorar como trabalhar com imagens de vários tamanhos.
Imagens de vários tamanhos
Nosso primeiro teste será resolver o problema de processar imagens de vários tamanhos. Isso ocorre porque uma rede neural na entrada precisa de dados de tamanho fixo.
Como exemplo, você pode se lembrar de nossas partes anteriores usando o parâmetro input_shape ao criar uma camada Flatten :

Antes de transmitir a imagem de um elemento de vestuário para uma rede neural, nós a convertemos em uma matriz 1D de tamanho fixo - 28x28 = 784 elementos (pixels). Como as imagens no conjunto de dados Fashion MNIST eram do mesmo tamanho, a matriz unidimensional resultante era do mesmo tamanho e consistia em 784 elementos.
No entanto, trabalhando com imagens de vários tamanhos (altura e largura) e transformando-as em matrizes unidimensionais, obtemos matrizes de tamanhos diferentes.
Como as redes neurais na entrada exigem dados do mesmo tamanho, não basta simplesmente se safar da conversão em uma matriz unidimensional de valores de pixel.
Resolvendo os problemas de classificação de imagens, sempre recorremos a uma das opções para unificar os dados de entrada - reduzindo o tamanho das imagens a valores comuns (redimensionamento).
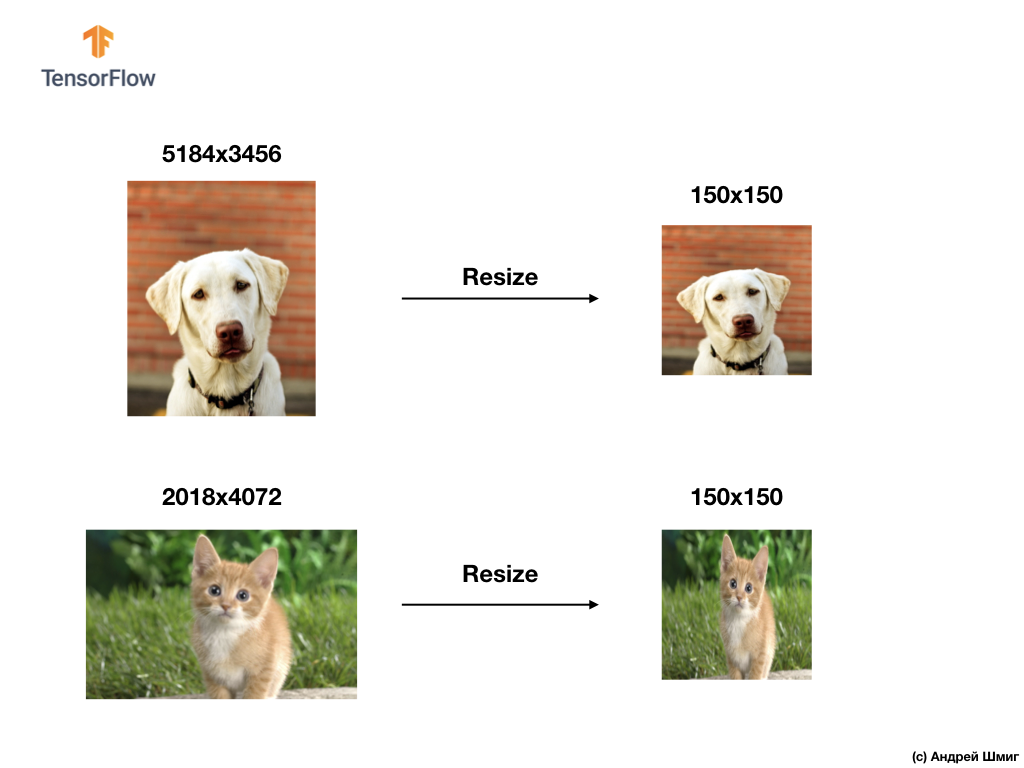
Neste tutorial, recorreremos ao redimensionamento de todas as imagens para tamanhos de 150 pixels de altura e 150 pixels de largura. Convertendo imagens para um tamanho único, garantimos que a imagem do tamanho certo chegue à entrada da rede neural e, quando transferida para uma camada flatten , obtemos uma matriz unidimensional do mesmo tamanho.
tf.keras.layers.Flatten(input_shape(150,150,1))
Como resultado, obtivemos uma matriz unidimensional que consiste em 150x150 = 22.500 valores (pixels).
O próximo problema que enfrentaremos será o problema das imagens coloridas. Falaremos sobre eles na próxima parte.
Imagens coloridas. Parte 1
Para entender e entender como as redes neurais convolucionais funcionam com imagens coloridas, devemos investigar como exatamente o SNA funciona em geral. Vamos atualizar o que já sabemos.
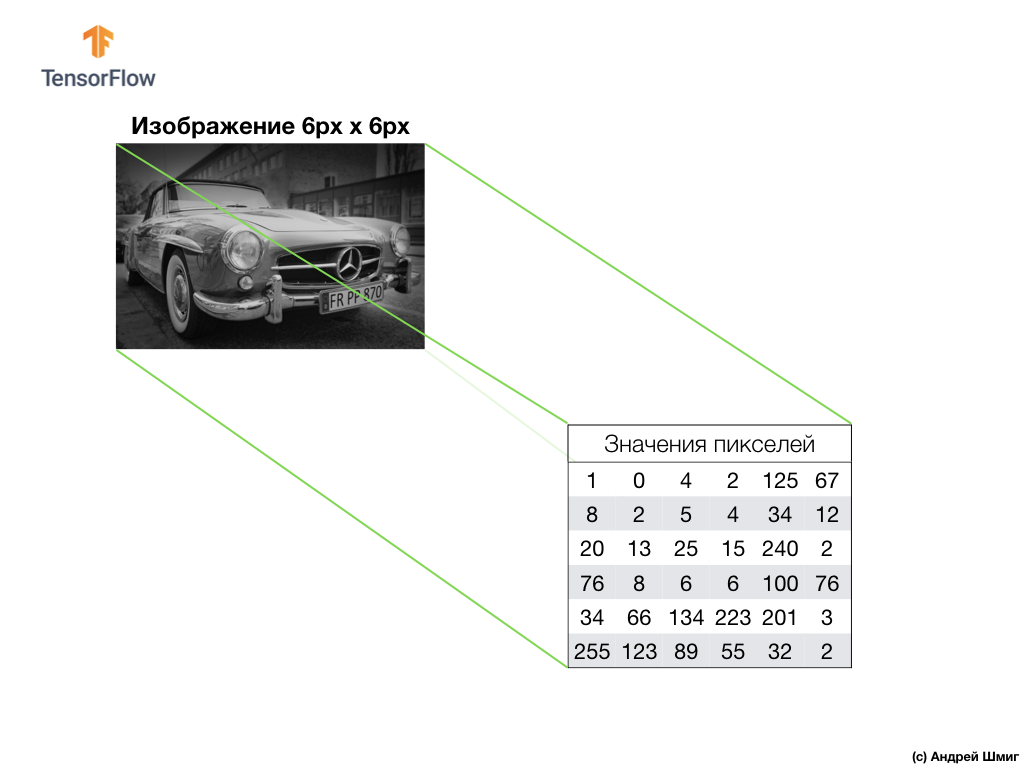
Um exemplo acima é uma imagem em escala de cinza e como o computador a interpreta como uma matriz bidimensional de valores de pixel.
Um exemplo abaixo é uma imagem, desta vez uma cor, e como o computador a interpreta como uma matriz tridimensional de valores de pixel.
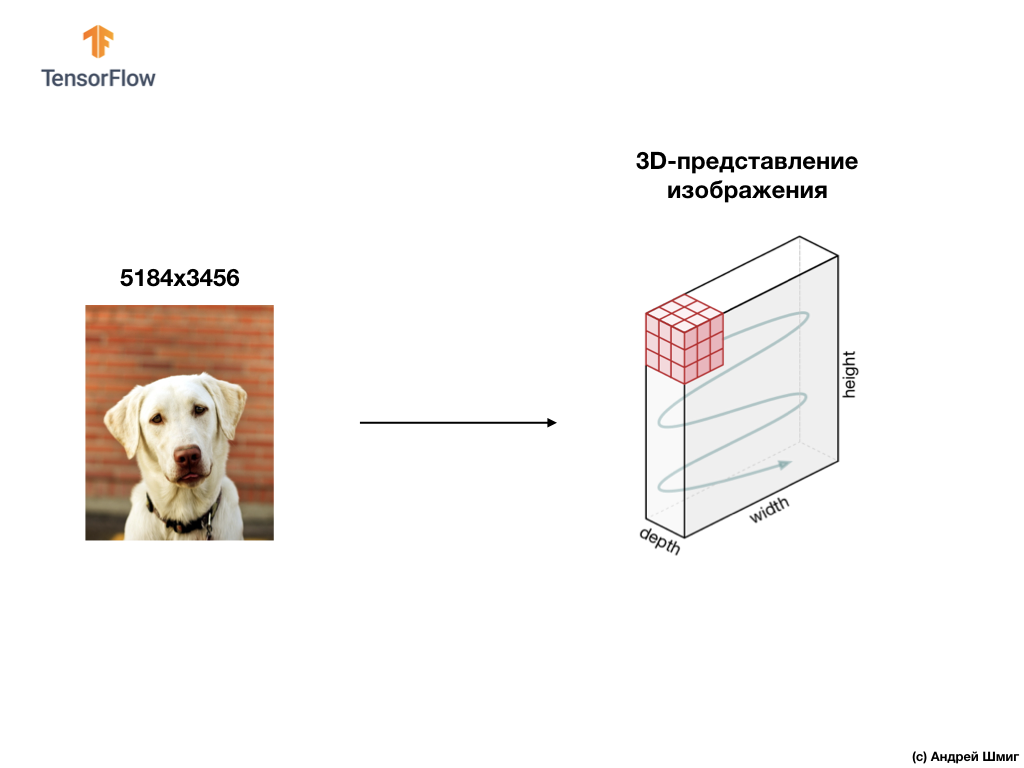
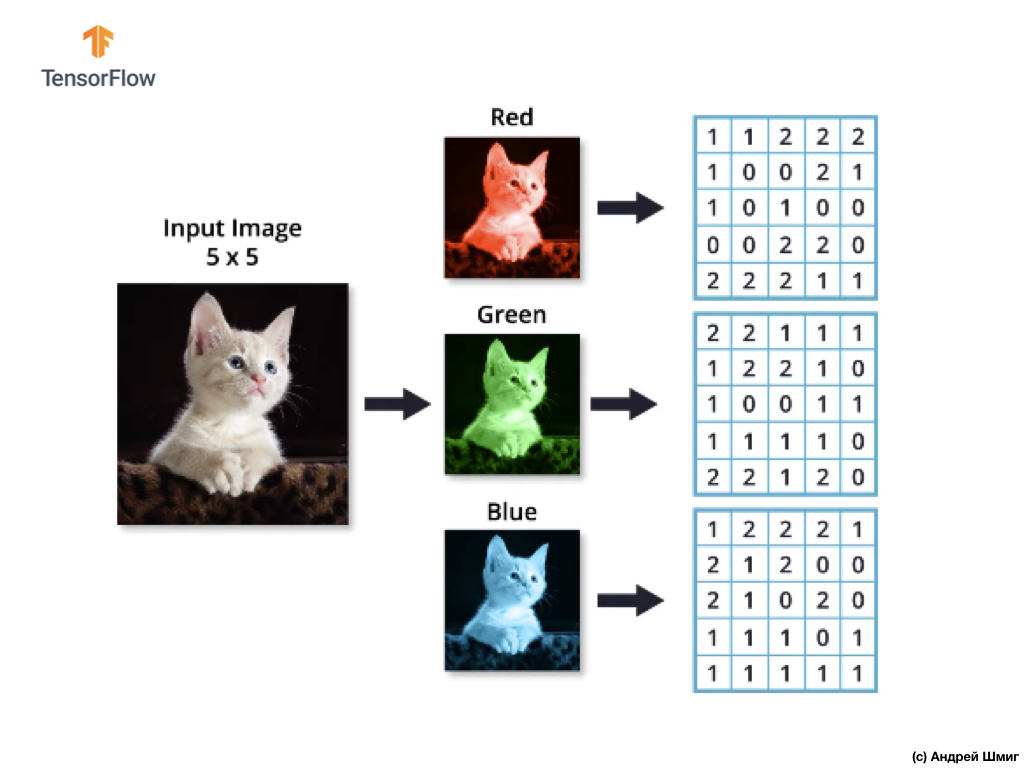
A altura e a largura da matriz 3D serão determinadas pela altura e largura da imagem, e a profundidade (profundidade) determina o número de canais de cores da imagem.
A maioria das imagens coloridas pode ser representada por três canais de cores - vermelho (vermelho), verde (verde) e azul (azul).

As imagens que consistem em canais vermelho, verde e azul são chamadas de imagens RGB. A combinação desses três canais resulta em uma imagem colorida. Em cada uma das imagens RGB, cada canal é representado por uma matriz bidimensional separada de pixels.
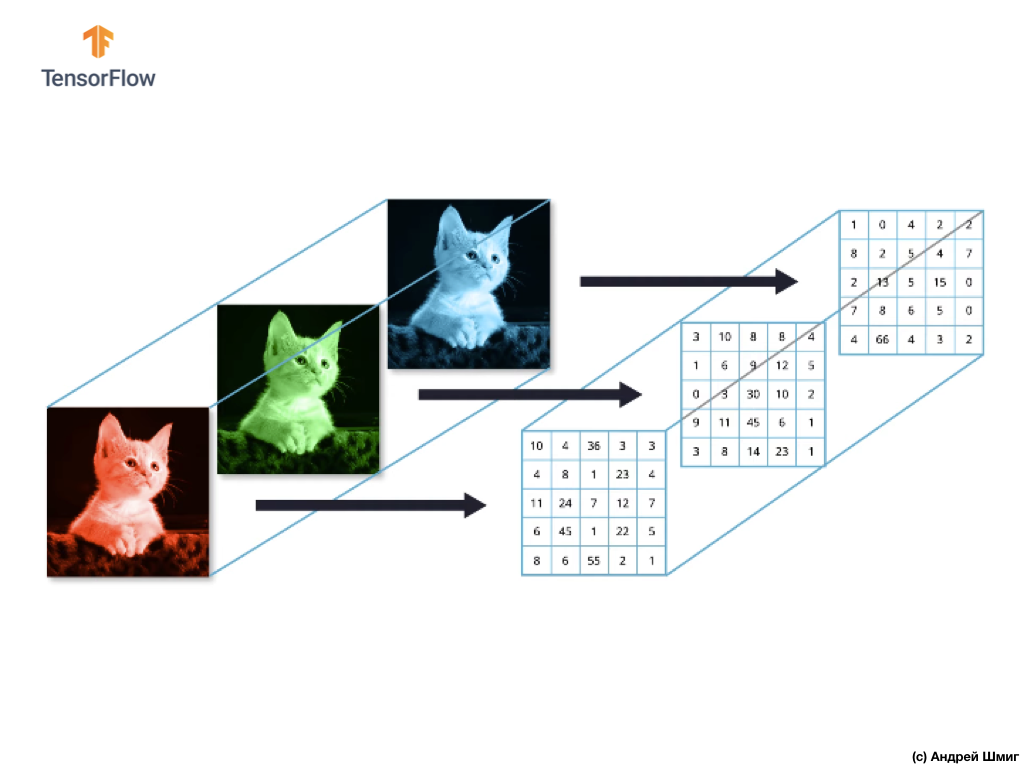
Como o número de canais que temos é três, como resultado, teremos três matrizes bidimensionais. Assim, uma imagem colorida composta por 3 canais de cores terá a seguinte representação:

Imagens coloridas. Parte 2
Portanto, como nossa imagem agora consiste em 3 cores, o que significa que será uma matriz tridimensional de valores de pixels, nosso código precisará ser alterado de acordo.
Se você observar o código que usamos em nossa última lição, quando resolvemos o problema de classificar elementos de roupas em imagens, podemos ver que indicamos a dimensão dos dados de entrada:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
Os dois primeiros parâmetros da tupla (28,28,1) são os valores da altura e largura da imagem. As imagens no conjunto de dados Fashion MNIST tinham tamanho de 28x28 pixels. O último parâmetro na tupla (28,28,1) indica o número de canais de cores. No conjunto de dados Fashion MNIST, as imagens eram apenas em tons de cinza - 1 canal de cores.
Agora que a tarefa se tornou um pouco mais complicada, e nossas imagens de cães e gatos se tornaram de tamanhos diferentes (mas convertidas em uma única - 150x150 pixels) e contêm 3 canais de cores, a tupla de valores também deve ser diferente:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
Na próxima parte, veremos como a convolução é calculada na presença de três canais de cores na imagem.
Operação de convolução em imagens coloridas
Nas lições anteriores, aprendemos como executar uma operação de convolução em imagens em escala de cinza. Mas como executar uma operação de convolução em imagens coloridas? Vamos começar repetindo como a operação de convolução é executada em imagens em escala de cinza.
Tudo começa com um filtro (núcleo) de um determinado tamanho.
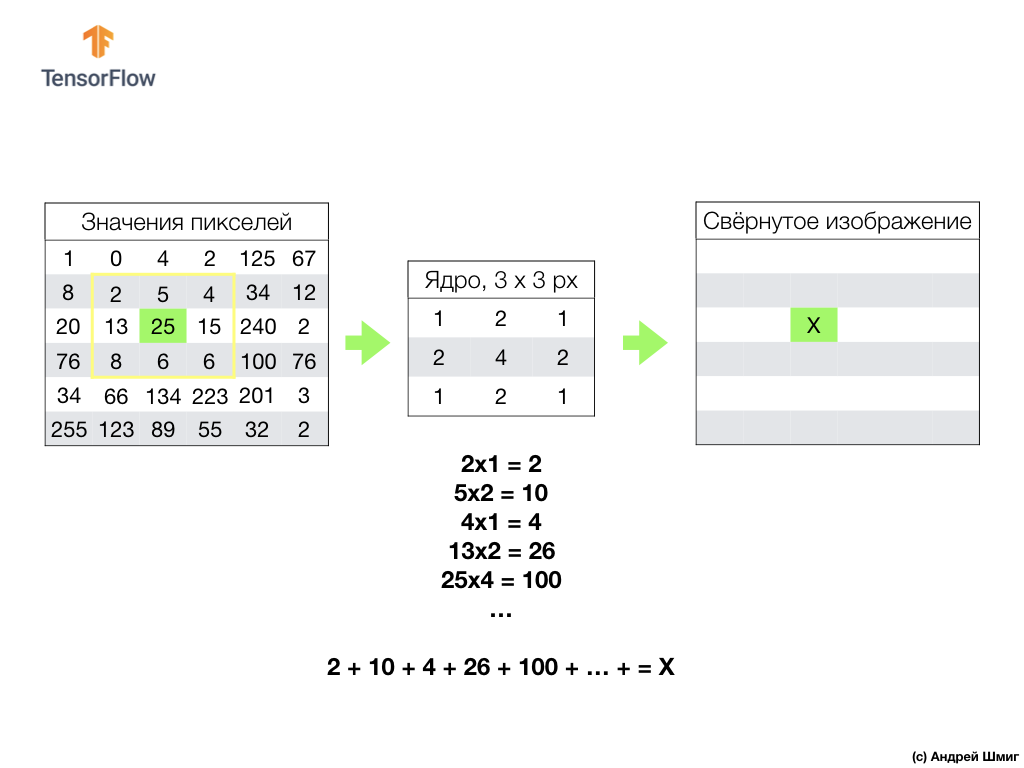
O filtro está localizado em um pixel de imagem específico a ser convertido, então cada valor de filtro é multiplicado pelo valor de pixel correspondente na imagem e todos esses valores são somados. O valor final do pixel é definido na nova imagem no local em que o pixel original convertido estava localizado. A operação é repetida para cada pixel da imagem original.
Também é importante lembrar que, durante a operação de convolução, para não perder informações nas bordas da imagem, podemos aplicar o alinhamento e preencher as bordas da imagem com zeros:

Agora vamos descobrir como podemos executar a operação de convolução em imagens coloridas.
Assim como ao converter uma imagem em tons de cinza, começamos escolhendo o tamanho do filtro (núcleo) de um determinado tamanho.

A única diferença agora será que agora o filtro em si será tridimensional e o valor do parâmetro de profundidade será igual ao valor do número de canais de cores na imagem - 3 (no nosso caso, RGB). Para cada "camada" do canal de cores, também aplicaremos a operação de convolução com um filtro do tamanho selecionado. Vamos ver como será um exemplo.
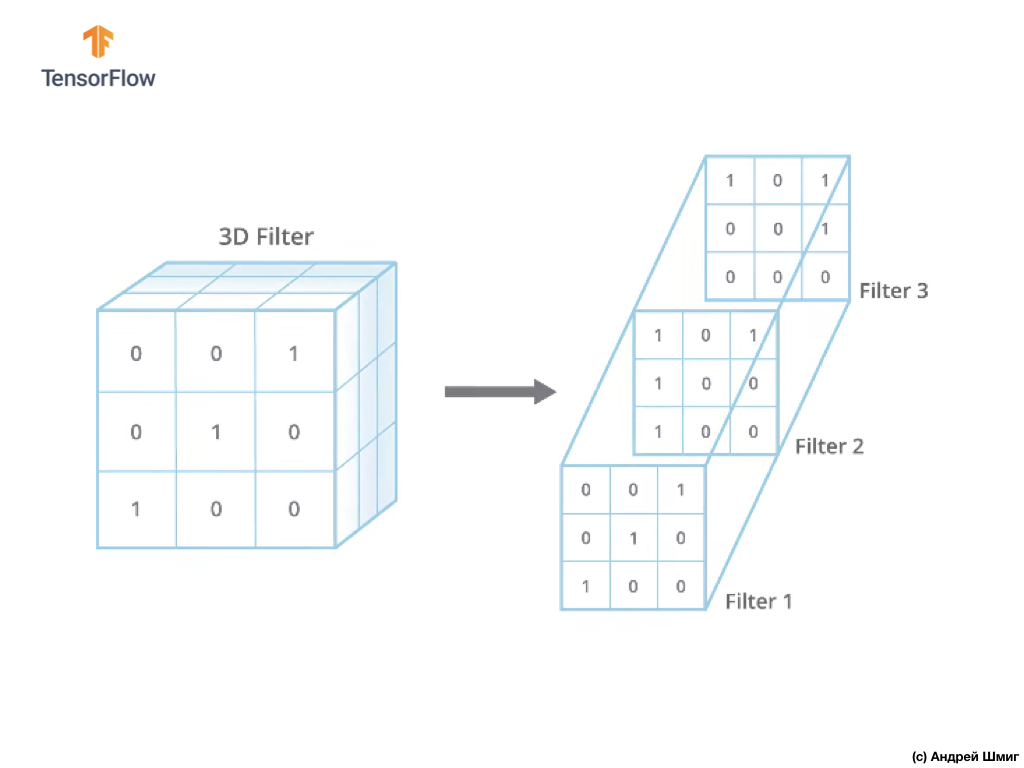
Imagine que temos uma imagem RGB e queremos aplicar a operação de convolução com o próximo filtro 3D. Vale a pena prestar atenção ao fato de que nosso filtro é composto por 3 filtros bidimensionais. Para simplificar, vamos imaginar que nossa imagem RGB tenha tamanho de 5x5 pixels.

Lembre-se também de que cada canal de cores é uma matriz bidimensional de valores de cores de pixels.
Assim como na operação de convolução sobre imagens em tons de cinza, bem como com imagens coloridas - faremos o alinhamento e suplementaremos a imagem nas bordas com zeros para evitar a perda de informações nas bordas.
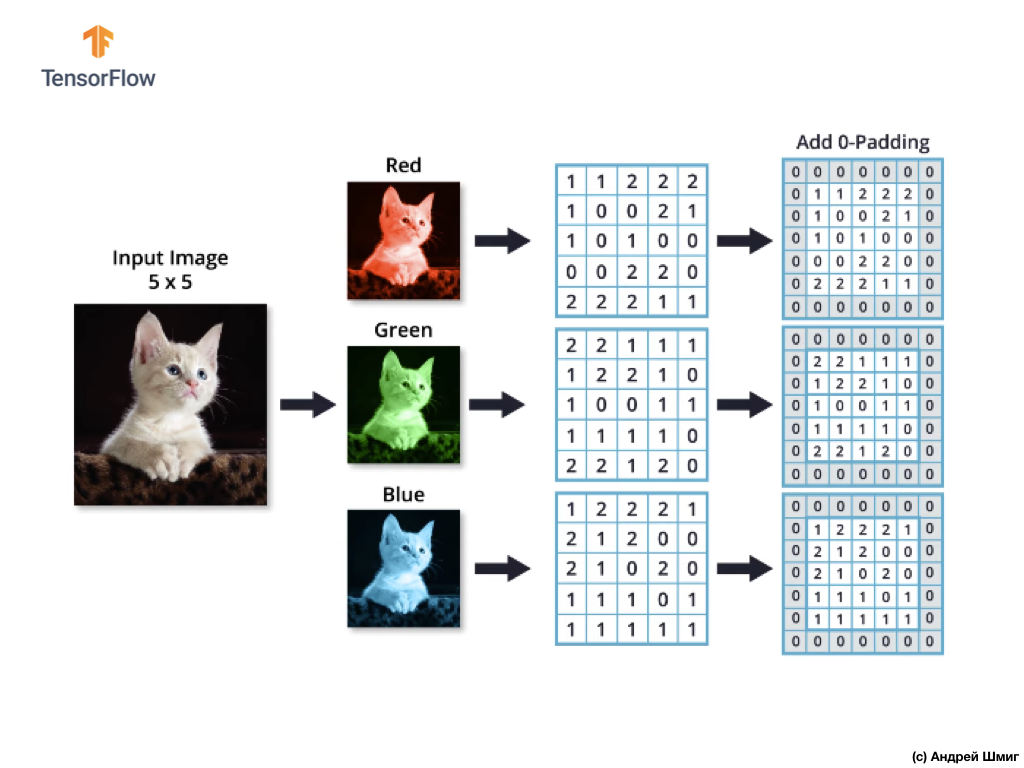
Agora estamos prontos para a operação de convolução!
O mecanismo de convolução para imagens coloridas será semelhante ao processo que realizamos com imagens em escala de cinza. A única diferença entre as operações executadas em imagens em escala de cinza e em cores é que a operação de convolução agora precisa ser executada 3 vezes para cada canal de cores.
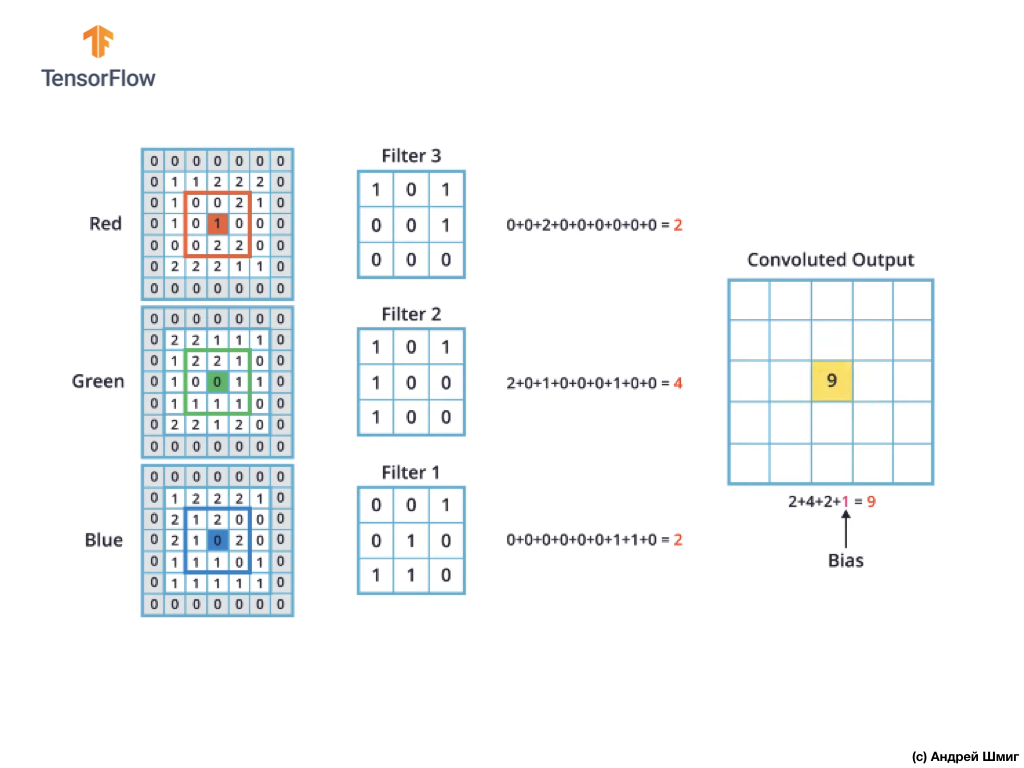
Depois de realizar a operação de convolução em cada canal de cor, adicione os três valores obtidos e adicione 1 a eles (o valor padrão usado ao executar operações desse tipo). O novo valor resultante é fixado na mesma posição na nova imagem, na qual o pixel convertido atual estava.
Realizamos uma operação de conversão semelhante (uma operação de convolução) para cada pixel em nossa imagem original e para cada canal de cores.
Neste exemplo em particular, a imagem resultante tem o mesmo tamanho em altura e largura da imagem RGB original.
Como você pode ver, a aplicação da operação de convolução com um único filtro 3D resulta em um único valor de saída.
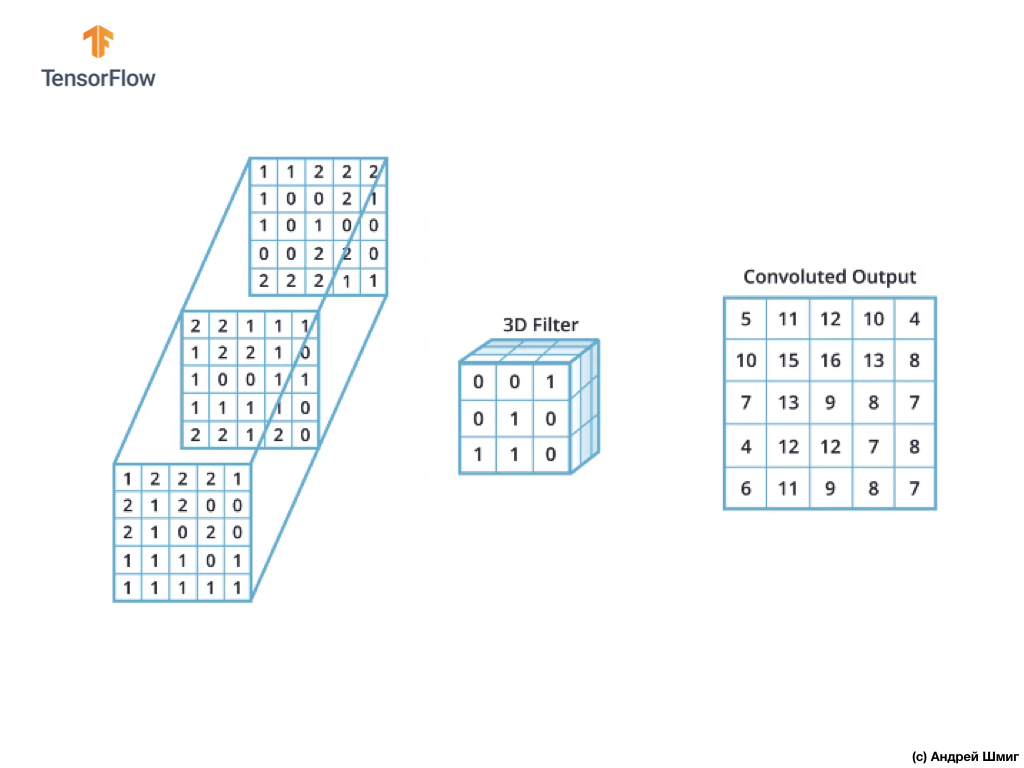
No entanto, ao trabalhar com redes neurais convolucionais, é prática comum usar mais de um filtro 3D. Se usarmos mais de um filtro 3D, o resultado será vários valores de saída - cada valor é o resultado de um filtro.
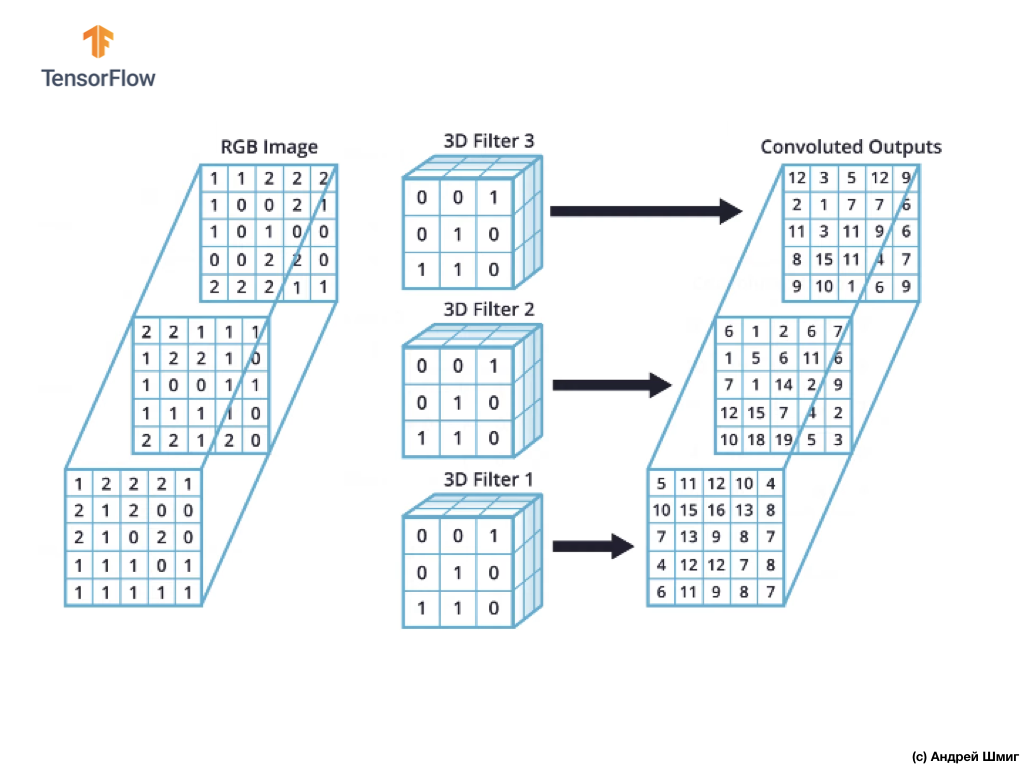
No exemplo acima, como usamos 3 filtros, a representação 3D resultante terá uma profundidade de 3 - cada camada corresponderá ao valor de saída da conversão de um filtro acima da imagem com todos os seus canais de cores.
Se, por exemplo, em vez de três filtros, decidirmos usar 16, a representação 3D de saída conterá 16 camadas de profundidade.
No código, podemos controlar o número de filtros criados, passando o valor apropriado para o parâmetro de filters :
tf.keras.layers.Conv2D(filters, kernel_size, ...)
Também podemos especificar o tamanho do filtro através do parâmetro kernel_size . Por exemplo, para criar três filtros de tamanho 3x3, como foi o caso no exemplo acima, podemos escrever o código da seguinte maneira:
tf.keras.layers.Conv2D(3, (3,3), ...)
Lembre-se de que durante o treinamento da rede neural convolucional, os valores nos filtros 3D serão atualizados para minimizar o valor da função de perda.
Agora que sabemos como executar a operação de convolução em imagens coloridas, é hora de descobrir como aplicar a operação de subamostragem ao resultado máximo pelo valor máximo (o mesmo pool máximo).
A operação de subamostragem pelo valor máximo em imagens coloridas
Vamos agora aprender como executar a operação de subamostragem no valor máximo em imagens coloridas. De fato, a operação de subamostragem pelo valor máximo funciona da mesma maneira que trabalha com imagens em tons de cinza com uma pequena diferença - a operação de subamostragem agora precisa ser aplicada a cada representação de saída que recebemos como resultado da aplicação de filtros. Vejamos um exemplo.
Para simplificar, vamos imaginar que nossa visualização de saída seja assim:
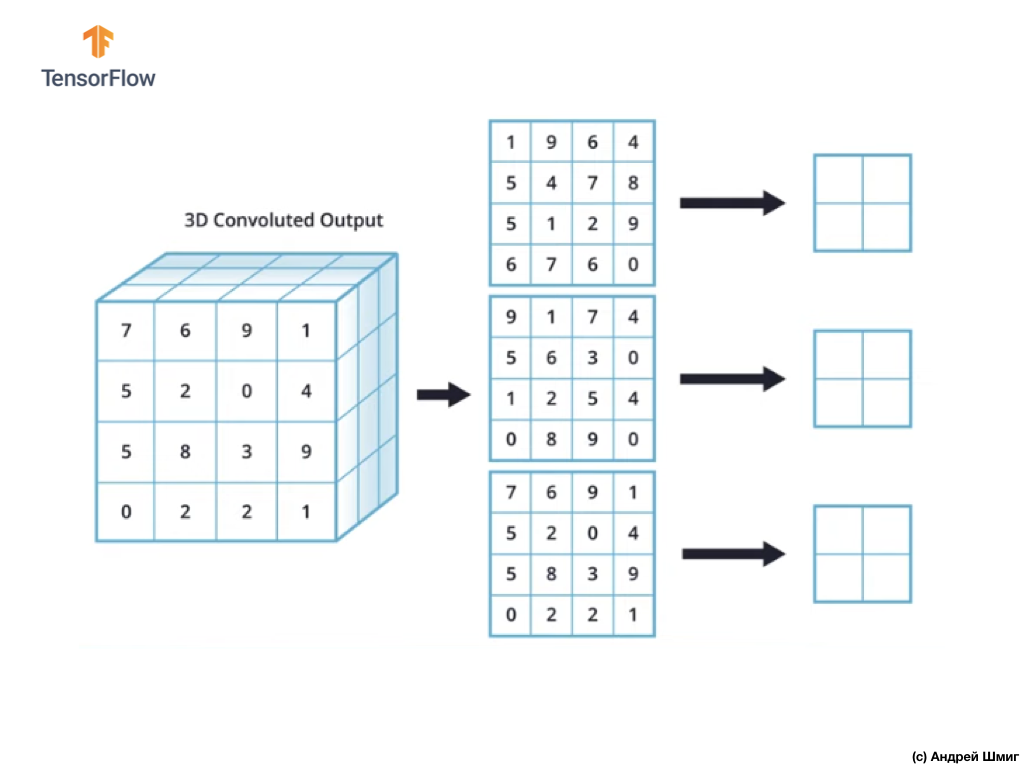
Como antes, usaremos um kernel 2x2 e a etapa 2 para executar a operação de subamostragem no valor máximo. A operação de subamostragem pelo valor máximo começa com a “instalação” de um kernel 2x2 no canto superior esquerdo de cada representação de saída (a representação que foi obtida após a aplicação da operação de convolução).

Agora podemos iniciar a operação de subamostragem no valor máximo. Por exemplo, em nossa primeira representação de saída, os seguintes valores caíram no kernel 2x2 - 1, 9, 5, 4. Como o valor máximo nesse kernel é 9, é ele que é enviado para a nova representação de saída. Uma operação semelhante é repetida para cada representação de entrada.
Como resultado, devemos obter o seguinte resultado:

Depois de executar a operação de subamostragem pelo valor máximo, o resultado é 3 matrizes bidimensionais, cada uma das quais é 2 vezes menor que a representação de entrada original.
Assim, nesse caso em particular, ao executar a operação de subamostragem pelo valor máximo sobre a representação tridimensional de entrada, obtemos uma representação tridimensional de saída da mesma profundidade, mas com os valores de altura e largura com metade dos valores iniciais.
Portanto, essa é toda a teoria de que precisamos para mais trabalho. Agora vamos ver como isso funciona no código!
CoLab: gatos e cães
O CoLab original em inglês está disponível neste link .
O CoLab em russo está disponível neste link .
Neste tutorial, discutiremos como categorizar imagens de cães e gatos. Vamos desenvolver um classificador de imagens usando o modelo tf.keras.Sequential e usar tf.keras.Sequential para carregar os dados.
Ideias a serem abordadas nesta parte:
Adquiriremos experiência prática no desenvolvimento de um classificador e desenvolveremos uma compreensão intuitiva dos seguintes conceitos:
- Construindo um modelo de fluxo de dados ( pipelines de entrada de dados ) usando a classe
tf.keras.preprocessing.image.ImageDataGenerator (Como trabalhar com eficiência com dados em disco interagindo com o modelo?) - Reciclagem - o que é e como determiná-la?
Antes de começarmos ...
Antes de iniciar o código no editor, recomendamos que você redefina todas as configurações em Tempo de execução -> Redefinir tudo no menu superior. Essa ação ajudará a evitar problemas com falta de memória, se você trabalhou em paralelo ou está trabalhando com vários editores.
Pacotes de importação
Vamos começar importando os pacotes que você precisa:
os - leia arquivos e estruturas de diretórios;numpy - para algumas operações de matriz fora do TensorFlow;matplotlib.pyplot - plotando e exibindo imagens de um conjunto de dados de teste e validação.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
TensorFlow importação
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Carregamento de dados
Iniciamos o desenvolvimento do nosso classificador carregando um conjunto de dados. O conjunto de dados que usamos é uma versão filtrada do conjunto de dados Dogs vs Cats do serviço Kaggle (no final, esse conjunto de dados é fornecido pela Microsoft Research).
No passado, o CoLab e eu usamos um conjunto de dados do próprio módulo TensorFlow Dataset , o que é extremamente conveniente para trabalho e teste. Neste CoLab, no entanto, usaremos a classe tf.keras.preprocessing.image.ImageDataGenerator para ler dados do disco. Portanto, primeiro precisamos fazer o download do conjunto de dados Dog VS Cats e descompactá-lo.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
O conjunto de dados que baixamos tem a seguinte estrutura:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Para obter uma lista completa de diretórios, você pode usar o seguinte comando:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
Como resultado, obtemos algo semelhante:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Agora atribua os caminhos corretos aos diretórios com os conjuntos de dados para treinamento e validação para as variáveis:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Compreendendo dados e sua estrutura
Vamos ver quantas imagens de cães e gatos temos nos conjuntos de dados de teste e validação (diretórios).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
A saída do último bloco será a seguinte:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Configurando parâmetros do modelo
Por conveniência, colocaremos a instalação das variáveis necessárias para mais processamento de dados e treinamento de modelos em um anúncio separado:
BATCH_SIZE = 100
Preparação de dados
Antes que as imagens possam ser usadas como entrada para nossa rede, elas devem ser convertidas em tensores com valores de ponto flutuante. Lista de etapas a serem seguidas para fazer isso:
- Ler imagens do disco
- Decodifique o conteúdo da imagem e converta para o formato desejado, levando em consideração o perfil RGB
- Converter em tensores com valores de ponto flutuante
- Para normalizar os valores do tensor do intervalo de 0 a 255 ao intervalo de 0 a 1, uma vez que as redes neurais funcionam melhor com pequenos valores de entrada.
Felizmente, todas essas operações podem ser executadas usando a classe tf.keras.preprocessing.image.ImageDataGenerator .
Podemos fazer tudo isso usando várias linhas de código:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
Depois de definir geradores para um conjunto de dados de teste e validação, o método flow_from_directory carregará imagens do disco, normalizará os dados e redimensionará as imagens com apenas uma linha de código:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusão:
Found 2000 images belonging to 2 classes.
Gerador de dados de validação:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusão:
Found 1000 images belonging to 2 classes.
Visualize as imagens do conjunto de treinamento.
Podemos visualizar imagens de um conjunto de dados de treinamento usando matplotlib :
sample_training_images, _ = next(train_data_gen)
A next função retorna um bloco de imagens do conjunto de dados. Um bloco é uma tupla de (muitas imagens, muitos rótulos) . No momento, vamos largar os rótulos, já que não precisamos deles - estamos interessados nas próprias imagens.
plotImages(sample_training_images[:5])
Exemplo de saída (2 imagens em vez de todas as 5):

Criação de modelo
Nós descrevemos o modelo
O modelo consiste em 4 blocos de convolução, após cada um dos quais existe um bloco com uma camada de subamostra. Em seguida, temos uma camada totalmente conectada com 512 neurônios e uma relu ativação relu . O modelo fornecerá uma distribuição de probabilidade para duas classes - cães e gatos - usando o softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Compilação do modelo
Como antes, usaremos o otimizador do adam . Usamos sparse_categorical_crossentropy como uma função de perda. Também queremos monitorar a precisão do modelo em cada iteração de treinamento, para que passemos o valor da accuracy ao parâmetro de metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Vista modelo
Vamos dar uma olhada na estrutura do nosso modelo por níveis usando o método de resumo :
model.summary()
Conclusão:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
Conclusão:
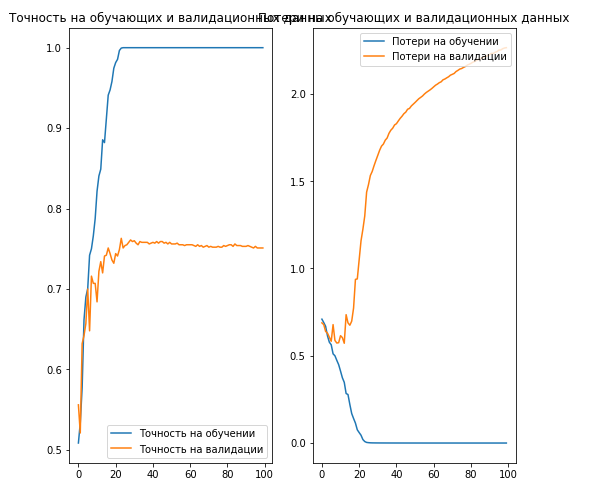
, 70% ( ).
. , .
… .
... e call to action padrão - inscreva-se, coloque um plus e compartilhe :)
YouTube
Telegram
VKontakte