
A comunidade moderna de desenvolvedores agora está mais do que nunca sujeita a moda e tendências, e isso é especialmente verdadeiro para o mundo do desenvolvimento front-end. Nossas estruturas e novas práticas são o principal valor, e a maioria dos currículos, vagas e programas de conferências consiste em listá-las. E embora o desenvolvimento de idéias e ferramentas não seja negativo por si só, mas devido ao desejo constante dos desenvolvedores de seguir tendências ilusórias, começamos a esquecer a importância do conhecimento teórico geral sobre arquitetura de aplicativos.
A prevalência do valor de ajuste sobre o conhecimento da teoria e das melhores práticas levou ao fato de que a maioria dos novos projetos hoje tem um nível extremamente baixo de manutenção, criando assim um inconveniente significativo para os desenvolvedores (a complexidade consistentemente alta do estudo e modificação do código) e para os clientes (taxas baixas e alto custo de desenvolvimento).
Para influenciar de alguma forma a situação atual, hoje eu gostaria de falar sobre o que é uma boa arquitetura, como é aplicável às interfaces da Web e, o mais importante, como ela evolui ao longo do tempo.
NB : Como exemplos no artigo, apenas as estruturas com as quais o autor lidou diretamente serão usadas, e atenção significativa será dada a React e Redux aqui. Mas, apesar disso, muitas das idéias e princípios descritos aqui são de natureza geral e podem ser projetados com mais ou menos sucesso em outras tecnologias de desenvolvimento de interface.Arquitetura para manequins
Para começar, vamos lidar com o próprio termo. Em palavras simples, a arquitetura de qualquer sistema é a definição de seus componentes e o esquema de interação entre eles. Esse é um tipo de base conceitual sobre a qual a implementação será posteriormente construída.
A tarefa da arquitetura é satisfazer os requisitos externos para o sistema projetado. Esses requisitos variam de projeto para projeto e podem ser bastante específicos, mas, no caso geral, são para facilitar os processos de modificação e expansão das soluções desenvolvidas.
Quanto à qualidade da arquitetura, ela geralmente é expressa nas seguintes propriedades:
-
Capacidade de acompanhamento : a predisposição do sistema já mencionada para estudo e modificação (dificuldade em detectar e corrigir erros, expandir a funcionalidade, adaptar a solução a outro ambiente ou condições)
-
Substituibilidade : a capacidade de alterar a implementação de qualquer elemento do sistema sem afetar outros elementos
-
Testabilidade : a capacidade de verificar a operação correta do elemento (a capacidade de controlar o elemento e observar seu estado)
-
Portabilidade : a capacidade de reutilizar um elemento em outros sistemas
-
Usabilidade : o grau geral de conveniência do sistema quando operado pelo usuário final
Também é feita menção separada a um dos princípios fundamentais da construção de uma arquitetura de qualidade: o princípio da
separação de preocupações . Consiste no fato de que qualquer elemento do sistema deve ser responsável exclusivamente por uma única tarefa (aplicada, aliás, ao código do aplicativo: consulte o
princípio da responsabilidade única ).
Agora que temos uma idéia do conceito de arquitetura, vamos ver o que os padrões de design de arquitetura podem nos oferecer no contexto de interfaces.
As três palavras mais importantes
Um dos padrões mais famosos do desenvolvimento de interfaces é o MVC (Model-View-Controller), cujo conceito principal é dividir a lógica da interface em três partes separadas:
1.
Modelo - é responsável por receber, armazenar e processar dados
2.
View - responsável pela visualização de dados
3.
Controlador - controla Modelo e Visão
Esse padrão também inclui uma descrição do esquema de interação entre eles, mas aqui essas informações serão omitidas devido ao fato de que, após certo tempo, o público em geral tenha recebido uma modificação aprimorada desse padrão chamada MVP (Model-View-Presenter), que esse esquema original interação bastante simplificada:
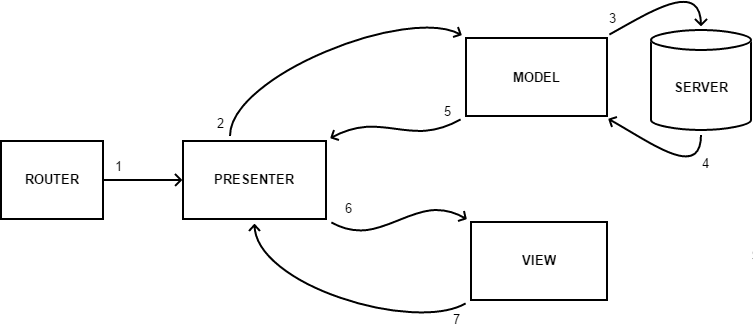
Como falamos especificamente sobre interfaces da web, usamos outro elemento bastante importante que geralmente acompanha a implementação desses padrões - um roteador. Sua tarefa é ler o URL e chamar os apresentadores associados a ele.
O esquema acima funciona da seguinte maneira:
1. O roteador lê o URL e chama o Presenter associado
2-5. O apresentador se volta para o modelo e obtém os dados necessários.
6. O Presenter transfere dados do Model para o View, o que implementa sua visualização.
7. Durante a interação do usuário com a interface, o View notifica o Presenter sobre isso, o que nos leva ao segundo ponto
Como a prática demonstrou, o MVC e o MVP não são uma arquitetura ideal e universal, mas ainda fazem uma coisa muito importante - indicam três áreas principais de responsabilidade, sem as quais nenhuma interface pode ser implementada de uma forma ou de outra.
NB: Em geral, os conceitos de Controller e Presenter significam a mesma coisa, e a diferença em seu nome é necessária apenas para diferenciar os padrões mencionados, que diferem apenas na implementação das comunicações .MVC e renderização do servidor
Apesar do MVC ser um padrão para implementar um cliente, ele também encontra seu aplicativo no servidor. Além disso, é no contexto do servidor que é mais fácil demonstrar os princípios de sua operação.
Nos casos em que lidamos com sites de informações clássicas, em que a tarefa do servidor da web é gerar páginas HTML para o usuário, o MVC também nos permite organizar uma arquitetura de aplicativos bastante concisa:
- O roteador lê os dados da solicitação HTTP recebida
(GET / user-profile / 1) e chama o Controller associado
(UsersController.getProfilePage (1))- O controlador chama o Model para obter as informações necessárias do banco de dados
(UsersModel.get (1))- O controlador passa os dados recebidos para View
(View.render ('users / profile', user)) e recebe a marcação HTML a partir dele, que os transmite de volta ao cliente
Nesse caso, o View geralmente é implementado da seguinte maneira:
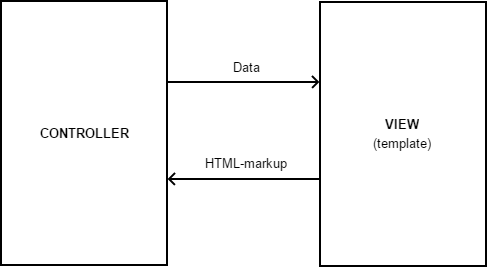
const templates = { 'users/profile': ` <div class="user-profile"> <h2>{{ name}}</h2> <p>E-mail: {{ email }}</p> <p> Projects: {{#each projects}} <a href="/projects/{{id}}">{{name}}</a> {{/each}} </p> <a href=/user-profile/1/edit>Edit</a> </div> ` }; class View { render(templateName, data) { const htmlMarkup = TemplateEngine.render(templates[templateName], data); return htmlMarkup; } }
Nota: o código acima é intencionalmente simplificado para uso como exemplo. Em projetos reais, os modelos são exportados para separar arquivos e passar pelo estágio de compilação antes do uso (consulte Handlebars.compile () ou _.template () ).Aqui são utilizados os chamados mecanismos de modelo, que nos fornecem ferramentas para uma descrição conveniente de modelos de texto e mecanismos para substituir dados reais neles.
Essa abordagem para a implementação do View não apenas demonstra uma separação ideal de responsabilidades, mas também fornece um alto grau de testabilidade: para verificar a correção da exibição, basta comparar a linha de referência com a linha que obtivemos do mecanismo de modelo.
Assim, usando o MVC, obtemos uma arquitetura quase perfeita, onde cada um de seus elementos tem um objetivo muito específico, conectividade mínima e também possui um alto nível de testabilidade e portabilidade.
Quanto à abordagem com a geração de marcação HTML usando ferramentas de servidor, devido ao baixo UX, essa abordagem começou a ser substituída gradualmente pelo SPA.
Backbone e MVP
Uma das primeiras estruturas a trazer totalmente a lógica de exibição para o cliente foi o
Backbone.js . A implementação do roteador, apresentador e modelo é bastante padrão, mas a nova implementação do View merece nossa atenção:

const UserProfile = Backbone.View.extend({ tagName: 'div', className: 'user-profile', events: { 'click .button.edit': 'openEditDialog', }, openEditDialog: function(event) {
Obviamente, a implementação do mapeamento se tornou muito mais complicada - a escuta de eventos do modelo e do DOM, bem como a lógica de seu processamento, foi adicionada à padronização elementar. Além disso, para exibir alterações na interface, é altamente desejável não renderizar novamente o View completamente, mas fazer um trabalho mais refinado com elementos DOM específicos (geralmente usando jQuery), o que exigiu a criação de muito código adicional.
Devido à complicação geral da implementação do View, seus testes ficaram mais complicados - já que agora estamos trabalhando diretamente com a árvore DOM, para testar, precisamos usar ferramentas adicionais que forneçam ou emulem o ambiente do navegador.
E os problemas com a nova implementação do View não terminaram aí:
Além do acima, é bastante difícil usar aninhados um no outro. Com o tempo, esse problema foi resolvido com a ajuda de
Regiões no
Marionette.js , mas, antes disso, os desenvolvedores tinham que inventar seus próprios truques para resolver esse problema bastante simples e frequentemente surgido.
E o último. As interfaces desenvolvidas dessa maneira eram predispostas a dados fora de sincronia - uma vez que todos os modelos existiam isolados no nível de diferentes apresentadores, então, quando os dados eram alterados em uma parte da interface, eles geralmente não eram atualizados em outra.
Mas, apesar desses problemas, essa abordagem era mais do que viável, e o desenvolvimento do Backbone mencionado anteriormente na forma de
Marionette ainda pode ser aplicado com sucesso no desenvolvimento do SPA.
Reagir e anular
É difícil de acreditar, mas no momento do seu lançamento inicial, o
React.js causou muito ceticismo na comunidade de desenvolvedores. Esse ceticismo foi tão grande que, por muito tempo, o seguinte texto foi publicado no site oficial:
Dê cinco minutos
A reação desafia muita sabedoria convencional e, à primeira vista, algumas das idéias podem parecer loucas.
E isso apesar do fato de que, diferentemente da maioria de seus concorrentes e antecessores, o React não era uma estrutura completa e era apenas uma pequena biblioteca para facilitar a exibição de dados no DOM:
React é uma biblioteca JavaScript para criar interfaces de usuário pelo Facebook e Instagram. Muitas pessoas optam por pensar em React como o V no MVC.
O principal conceito que o React nos oferece é o conceito de um componente que, de fato, nos fornece uma nova maneira de implementar o View:
class User extends React.Component { handleEdit() {
Reagir foi incrivelmente agradável de usar. Entre suas vantagens inegáveis estavam até hoje:
1)
Declaração e reatividade . Não é mais necessário atualizar manualmente o DOM ao alterar os dados exibidos.
2)
A composição dos componentes . Construir e explorar a árvore View tornou-se uma ação completamente elementar.
Infelizmente, porém, o React tem vários problemas. Um dos mais importantes é o fato de o React não ser uma estrutura completa e, portanto, não nos oferecer qualquer tipo de arquitetura de aplicativo ou ferramentas completas para sua implementação.
Por que isso está escrito em falhas? Sim, porque agora o React é a solução mais popular para o desenvolvimento de aplicativos da Web (
prova ,
outra prova e outra prova ), é um ponto de entrada para novos desenvolvedores de front-end, mas, ao mesmo tempo, não oferece nem promove nenhum arquitetura, nem abordagens e práticas recomendadas para criar aplicativos completos. Além disso, ele inventa e promove suas próprias abordagens personalizadas, como
HOC ou
Hooks , que não são usadas fora do ecossistema React. Como resultado, cada aplicativo React resolve problemas típicos da sua maneira e geralmente não faz isso da maneira mais correta.
Esse problema pode ser demonstrado com a ajuda de um dos erros mais comuns dos desenvolvedores do React, que consiste no abuso de componentes:
Se a única ferramenta que você tem é um martelo, tudo começa a parecer um prego.
Com sua ajuda, os desenvolvedores resolvem uma gama completamente impensável de tarefas que vão muito além do escopo da visualização de dados. Na verdade, com a ajuda dos componentes, eles implementam absolutamente tudo - desde
consultas de mídia desde CSS até
roteamento .
Reagir e Redux
A restauração da ordem na estrutura dos aplicativos React foi muito facilitada pela aparência e popularização do
Redux . Se React é uma View do MVP, o Redux nos ofereceu uma variação bastante conveniente do Model.
A principal idéia do Redux é a transferência de dados e a lógica de trabalhar com eles em um único data warehouse centralizado - a chamada Store. Essa abordagem resolve completamente o problema de duplicação e dessincronização de dados, sobre o qual falamos um pouco antes, e também oferece muitas outras comodidades, que, entre outras coisas, incluem a facilidade de estudar o estado atual dos dados no aplicativo.
Outro recurso igualmente importante é o meio de comunicação entre a loja e outras partes do aplicativo. Em vez de acessar diretamente a loja ou seus dados, somos oferecidos a usar as chamadas ações (objetos simples que descrevem o evento ou comando), que fornecem um nível fraco de
acoplamento fraco entre a loja e a fonte do evento, aumentando significativamente o grau de manutenção do projeto. Portanto, o Redux não apenas força os desenvolvedores a usar abordagens arquitetônicas mais corretas, mas também permite que você aproveite várias vantagens da
fonte de
eventos - agora, no processo de depuração, podemos visualizar facilmente o histórico de ações no aplicativo, seu impacto nos dados e, se necessário, todas essas informações podem ser exportadas , o que também é extremamente útil ao analisar erros de produção.
O esquema geral do aplicativo usando React / Redux pode ser representado da seguinte maneira:
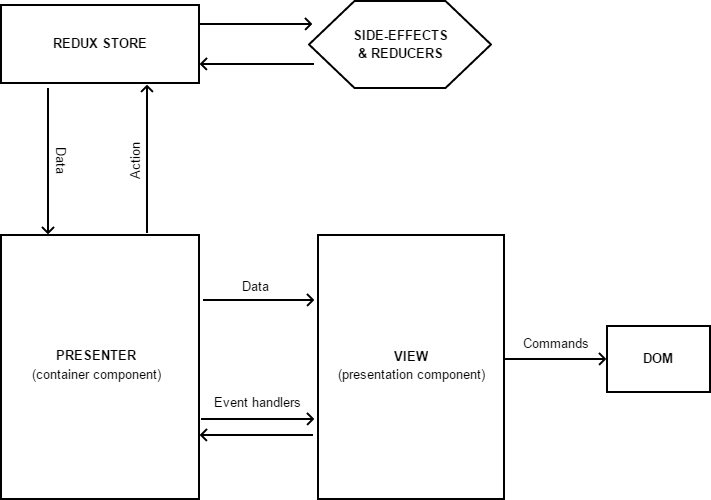
Os componentes de reação ainda são responsáveis pela exibição de dados. Idealmente, esses componentes devem ser limpos e funcionais, mas, se necessário, podem ter um estado local e lógica associada (por exemplo, para implementar ocultar / exibir um elemento específico ou pré-processamento básico de uma ação do usuário).
Quando um usuário executa uma ação na interface, o componente simplesmente chama a função manipuladora correspondente, que recebe de fora junto com os dados para exibição.
Os chamados componentes de contêiner atuam como apresentador para nós - eles exercem controle sobre os componentes de exibição e sua interação com os dados. Eles são criados usando a função
connect , que estende a funcionalidade do componente passado a ele, adicionando uma assinatura para alterar dados no Store e permitindo determinar quais manipuladores de dados e eventos devem ser passados para ele.
E se tudo estiver claro com os dados aqui (simplesmente mapeamos os dados do armazenamento para os "adereços" esperados)), gostaria de me concentrar nos manipuladores de eventos com mais detalhes - eles não apenas enviam Ações para a Loja, mas também podem conter lógica adicional para processar o evento - por exemplo, inclua ramificação, execute redirecionamentos automáticos e execute qualquer outro trabalho específico para o apresentador.
Outro ponto importante em relação aos componentes do contêiner: devido ao fato de serem criados por meio do HOC, os desenvolvedores frequentemente descrevem os componentes de exibição e os componentes do contêiner em um único módulo e exportam apenas o contêiner. Essa não é a abordagem correta, pois para a possibilidade de testar e reutilizar o componente de exibição, ele deve ser completamente separado do contêiner e, de preferência, retirado em um arquivo separado.
Bem, a última coisa que ainda não consideramos é a loja. Ele nos serve como uma implementação bastante específica do Modelo e consiste em vários componentes: Estado (um objeto que contém todos os nossos dados), Middleware (um conjunto de funções que pré-processa todas as Ações recebidas), Redutor (uma função que modifica os dados no Estado) e alguns ou um manipulador de efeitos colaterais responsável pela execução de operações assíncronas (acesso a sistemas externos etc.).
A questão mais comum aqui é a forma do nosso Estado. Formalmente, o Redux não nos impõe nenhuma restrição e não fornece recomendações sobre o que esse objeto deve ser. Os desenvolvedores podem armazenar absolutamente quaisquer dados nele (incluindo o
estado dos formulários e
informações do roteador ), esses dados podem ser de qualquer tipo (não é
proibido armazenar funções nem instâncias de objetos) e ter qualquer nível de aninhamento. De fato, isso novamente leva ao fato de que, de projeto para projeto, temos uma abordagem completamente diferente do uso do Estado, que mais uma vez causa confusão.
Para começar, concordamos que não precisamos manter absolutamente todos os dados do aplicativo no Estado - isso é claramente
indicado pela documentação . Embora armazenar parte dos dados dentro do estado dos componentes crie certos inconvenientes ao navegar pelo histórico de ações durante o processo de depuração (o estado interno dos componentes sempre permanece inalterado), a transferência desses dados para o Estado cria ainda mais dificuldades - isso aumenta significativamente seu tamanho e requer a criação de ainda mais Ações e redutores.
Quanto ao armazenamento de quaisquer outros dados locais no Estado, geralmente lidamos com algumas configurações gerais da interface, que são um conjunto de pares de valores-chave. Nesse caso, podemos fazer facilmente com um objeto simples e um redutor para ele.
E se estamos falando sobre o armazenamento de dados de fontes externas, com base no fato de que, no desenvolvimento de interfaces, na grande maioria dos casos, estamos lidando com o CRUD clássico, para armazenar dados do servidor, faz sentido tratar o Estado como um RDBMS: chaves são o nome e atrás deles estão matrizes armazenadas de objetos carregados (
sem aninhamento ) e informações opcionais para eles (por exemplo, o número total de registros no servidor para criar paginação). A forma geral desses dados deve ser o mais uniforme possível - isso permitirá simplificar a criação de redutores para cada tipo de recurso:
const getModelReducer = modelName => (models = [], action) => { const isModelAction = modelActionTypes.includes(action.type); if (isModelAction && action.modelName === modelName) { switch (action.type) { case 'ADD_MODELS': return collection.add(action.models, models); case 'CHANGE_MODEL': return collection.change(action.model, models); case 'REMOVE_MODEL': return collection.remove(action.model, models); case 'RESET_STATE': return []; } } return models; };
Bem, outro ponto que eu gostaria de discutir no contexto do uso do Redux é a implementação de efeitos colaterais.
Antes de tudo, esqueça completamente o
Redux Thunk - a transformação das Ações propostas por ele em funções com efeitos colaterais, embora seja uma solução funcional, mas que mistura os conceitos básicos de nossa arquitetura e reduz suas vantagens a nada.
O Redux Saga oferece uma abordagem muito mais correta para a implementação de efeitos colaterais, embora existam algumas perguntas sobre sua implementação técnica.
Em seguida - tente unificar, tanto quanto possível, os efeitos colaterais que acessam o servidor. Assim como o formulário State e redutores, quase sempre podemos implementar a lógica de criar solicitações para o servidor usando um único manipulador. Por exemplo, no caso da API RESTful, isso pode ser alcançado ouvindo ações generalizadas como:
{ type: 'CREATE_MODEL', payload: { model: 'reviews', attributes: { title: '...', text: '...' } } }
... e criando as mesmas solicitações HTTP generalizadas nelas:
POST /api/reviews { title: '...', text: '...' }
Ao seguir conscientemente todas as dicas acima, você pode obter, se não uma arquitetura ideal, pelo menos próximo a ela.
Futuro brilhante
O desenvolvimento moderno de interfaces da Web realmente deu um passo significativo, e agora estamos vivendo uma época em que uma parte significativa dos principais problemas já foi resolvida de uma maneira ou de outra. Mas isso não significa que, no futuro, não haverá novas revoluções.
Se você tentar olhar para o futuro, provavelmente veremos o seguinte:
1. Abordagem de componentes sem JSXO conceito de componentes provou ser extremamente bem-sucedido e, provavelmente, veremos sua popularização ainda maior. Mas o próprio JSX pode e deve morrer. Sim, é realmente muito conveniente de usar, mas, no entanto, não é um padrão geralmente aceito nem um código JS válido. As bibliotecas para implementar interfaces, por melhores que sejam, não devem inventar novos padrões, que devem ser implementados repetidamente em todos os kits de ferramentas de desenvolvimento possíveis.
2. Contêineres de Estado sem ReduxO uso de um data warehouse centralizado, proposto pela Redux, também foi uma solução extremamente bem-sucedida e, no futuro, deve se tornar um tipo de padrão no desenvolvimento de interfaces, mas sua arquitetura e implementação internas podem sofrer certas alterações e simplificações.
3. Aprimorando a permutabilidade da bibliotecaAcredito que, com o tempo, a comunidade de desenvolvedores front-end perceberá os benefícios de maximizar a intercambiabilidade de bibliotecas e não mais se trancará em seus pequenos ecossistemas. Todos os componentes dos aplicativos - roteadores, contêineres de estado etc. - devem ser extremamente universais e sua substituição não deve exigir uma refatoração ou reescrita maciça do aplicativo a partir do zero.
Por que tudo isso?
Se tentarmos generalizar as informações apresentadas acima e reduzi-las para uma forma mais simples e mais curta, obteremos alguns pontos bastante gerais:
- Para o desenvolvimento bem-sucedido de aplicativos, o conhecimento da linguagem e da estrutura não é suficiente, deve-se prestar atenção a aspectos teóricos gerais: arquitetura de aplicativos, melhores práticas e padrões de design.
"A única constante é a mudança." As abordagens de lavoura e desenvolvimento continuarão a mudar; portanto, projetos grandes e de longa duração devem prestar atenção adequada à arquitetura - sem ela, a introdução de novas ferramentas e práticas será extremamente difícil.
E isso é provavelmente tudo para mim. Muito obrigado a todos que encontraram forças para ler o artigo até o fim. Se você tiver alguma dúvida ou comentário, convido você a comentar.